AAAI 2026 Oral 之江实验室等提出MoEGCL:在6大基准数据集上刷新SOTA,聚类准确率最高提升超8%!
本文针对多视图聚类中普遍存在的粗粒度信息融合问题,提出了一个名为MoEGCL的创新框架。理论上,它通过MoEGF模块实现了前所未有的样本级动态图融合,并设计了EGCL模块来优化对比学习的目标,使之更符合聚类任务的本质。实验上,模型在六个基准数据集上全面超越了当前最先进的方法。这项研究对后续工作的启示在于,未来的多视图学习可以更多地关注样本间的异质性,设计更为精细和动态的融合策略,而不仅仅停留在视图
在数字时代,我们常常从不同角度或来源获取关于同一个事物的数据,比如一个新闻事件的文字报道、图片和视频。如何整合这些不同来源(即“多视图”)的数据,并自动地将相似的事物归为一类,是多视图聚类 (Multi-View Clustering) 要解决的核心问题。当前的研究方法在融合这些多视图信息时,通常采用一种较为粗糙的策略,即为每个视图的整体信息分配一个固定的权重再进行融合,这忽略了不同样本之间存在的差异性,导致聚类效果受限。
为了解决这一难题,本论文提出了一种名为自我图混合对比表示学习框架。它不再对整个视图进行宏观融合,而是深入到每个数据样本的层面,为每个样本在不同视图下的局部关联性(即自我图)进行动态、精细的融合。通过这种方式,模型获得了对数据结构更深刻的理解,最终在多个公开数据集上取得了业界领先的聚类效果。
另外我整理了AAAI 2025计算机视觉相关论文合集,感兴趣的自取!

一、论文基本信息

论文标题: MoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
作者姓名: Jian Zhu, Xin Zou, Jun Sun, Cheng Luo, Lei Liu, Lingfang Zeng, Ning Zhang, Bian Wu, Chang Tang, Lirong Dai
作者单位/机构: 之江实验室、香港科技大学(广州)、中国科学技术大学、华中科技大学
论文链接: https://arxiv.org/abs/2511.05876
论文代码: https://github.com/HackerHyper/MoEGCL
录用会议: AAAI 2026 Oral
二、主要贡献与创新
- 提出了MoEGF模块,首次将混合专家网络 (Mixture-of-Experts) 思想引入多视图图融合,实现了样本级的精细化融合。
- 设计了EGCL模块,优化了对比学习的目标,将簇内样本作为正例,从而学习到更具判别性的图表示。
- 模型在六个主流的公开数据集上进行了全面测试,其聚类性能显著超越了现有的八种前沿方法。
三、研究方法与原理
该模型的核心思路是:为每个样本在各个视图中构建其专属的局部连接图(自我图),然后利用一个专家决策系统(混合专家网络)来智能地判断并融合这些自我图,最终形成一个高质量的全局图用于聚类。
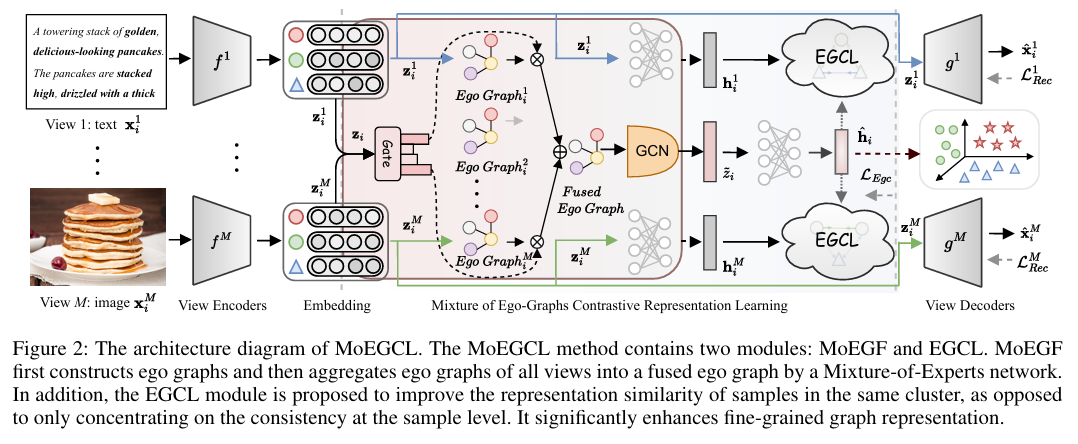
如上图所示,MoEGCL模型主要由自动编码器 (Autoencoder) 网络、**自我图混合融合(MoEGF)模块和自我图对比学习(EGCL)**模块三大部分构成。
首先,模型使用一个自动编码器网络对每个视图的原始数据 X m X^m Xm 进行特征提取。对于第 m m m 个视图中的第 i i i 个样本 x i m x_i^m xim,编码器 f m f^m fm 将其映射为一个低维表示 z i m z_i^m zim:
z i m = f m ( x i m ) z_i^m = f^m(x_i^m) zim=fm(xim)
同时,解码器 g m g^m gm 会尝试从 z i m z_i^m zim 中重建原始样本 x ^ i m \hat{x}_i^m x^im。这个过程通过最小化重建损失 L Rec L_{\text{Rec}} LRec 来进行优化,确保提取的特征 z i m z_i^m zim 能够保留原始数据的主要信息。重建损失定义为所有视图和所有样本的原始数据与重建数据之间的 Frobenius 范数差:
L Rec = ∑ m = 1 M ∥ X m − X ^ m ∥ F 2 = ∑ m = 1 M ∑ i = 1 N ∥ x i m − g m ( z i m ) ∥ 2 2 L_{\text{Rec}} = \sum_{m=1}^{M} \|X^m - \hat{X}^m\|_F^2 = \sum_{m=1}^{M} \sum_{i=1}^{N} \|x_i^m - g^m(z_i^m)\|_2^2 LRec=m=1∑M∥Xm−X^m∥F2=m=1∑Mi=1∑N∥xim−gm(zim)∥22
接下来是模型的核心创新——**自我图混合融合(MoEGF)**模块,它负责实现精细化的图融合。
1. 自我图网络(Ego Graph Networks)
传统方法通常为每个视图构建一个全局图,而MoEGF则更进一步。它首先利用样本的特征表示 Z m = [ z 1 m ; z 2 m ; . . . ; z N m ] Z^m = [z_1^m; z_2^m; ... ; z_N^m] Zm=[z1m;z2m;...;zNm],为每个视图构建一个KNN图 (k-nearest neighbors graph) ,该图的邻接矩阵为 S m S^m Sm。构建方式如下:
S i j m = { 1 if j ∈ K i m 0 otherwise S_{ij}^m = \begin{cases} 1 & \text{if } j \in \mathcal{K}_i^m \\ 0 & \text{otherwise} \end{cases} Sijm={10if j∈Kimotherwise
其中, K i m \mathcal{K}_i^m Kim 表示在第 m m m 个视图中,基于欧氏距离找到的样本 i i i 的 k k k 个最近邻居。这里的关键在于,邻接矩阵 S m S^m Sm 的第 i i i 行向量 V i m V_i^m Vim ,可以被看作是样本 i i i 在第 m m m 个视图中的自我图 (ego graph) ,它描述了该样本的局部连接关系。
2. 混合专家网络(Mixture-of-Experts Network)
这是实现样本级精细化融合的关键。对于每一个样本 i i i,模型不再使用固定的权重来融合来自不同视图的信息,而是动态地决定每个视图的“发言权”。具体来说,模型将样本 i i i 在所有 M M M 个视图下的特征表示拼接起来,得到 z i = cat ( z 1 i ; z 2 i ; . . . ; z M i ) z_i = \text{cat}(z_1^i; z_2^i; ... ; z_M^i) zi=cat(z1i;z2i;...;zMi)。然后,将 z i z_i zi 输入一个门控网络 (gating network)(一个多层感知机 mlp1),通过 softmax 函数生成一组权重系数 C i = [ C i 1 , C i 2 , . . . , C i M ] C_i = [C_i^1, C_i^2, ..., C_i^M] Ci=[Ci1,Ci2,...,CiM]:
C i = softmax ( mlp 1 ( z i ) ) i C_i = \text{softmax}(\text{mlp}_1(z_i))_i Ci=softmax(mlp1(zi))i
这里的 C i m C_i^m Cim 就代表了对于样本 i i i 而言,第 m m m 个视图的自我图 V i m V_i^m Vim 的重要性或可信度。将每个视图的自我图看作一个“专家”,门控网络就是那个决定听取哪个专家意见的决策者。最终,样本 i i i 的融合后的邻接向量 V i V_i Vi 通过对所有视图的自我图进行加权求和得到:
V i = ∑ m = 1 M C i m V i m V_i = \sum_{m=1}^{M} C_i^m V_i^m Vi=m=1∑MCimVim
将所有样本的融合邻接向量 V i V_i Vi 堆叠起来,就得到了最终的全局融合邻接矩阵 S = [ V 1 ; V 2 ; . . . ; V N ] T S = [V_1; V_2; ... ; V_N]^T S=[V1;V2;...;VN]T。这个矩阵 S S S 不再是简单地对视图级图谱的平均或加权,而是为每个样本都量身定制了其邻居关系。
3. 图卷积网络(Graph Convolutional Network, GCN)
获得高质量的融合图 S S S 后,模型利用一个两层的图卷积网络 (Graph Convolutional Network, GCN) 来进一步优化节点表示。GCN能够聚合邻居节点的信息,使得在图上连接紧密的样本在特征空间中也更加接近。这个过程可以表示为:
Z ~ = ( D ~ − 1 2 S ~ D ~ − 1 2 ) ReLU ( ( D ~ − 1 2 S ~ D ~ − 1 2 ) Z W 0 ) W 1 \tilde{Z} = \left(\tilde{D}^{-\frac{1}{2}} \tilde{S} \tilde{D}^{-\frac{1}{2}}\right) \text{ReLU}\left(\left(\tilde{D}^{-\frac{1}{2}} \tilde{S} \tilde{D}^{-\frac{1}{2}}\right)ZW_0\right)W_1 Z~=(D~−21S~D~−21)ReLU((D~−21S~D~−21)ZW0)W1
其中 S ~ = I N + S \tilde{S} = I_N + S S~=IN+S 是加入了自连接的邻接矩阵, D ~ \tilde{D} D~ 是其对应的度矩阵, W 0 W_0 W0 和 W 1 W_1 W1 是可训练的权重。通过GCN,我们得到了融合了精细图结构信息的增强表示 Z ~ \tilde{Z} Z~。
最后是模型的另一个创新点——**自我图对比学习(EGCL)**模块。
传统的对比学习方法在多视图聚类中,通常将同一样本在不同视图下的表示视为正样本对,旨在拉近它们。然而,这种做法只关注了样本自身的一致性,而忽略了聚类的最终目标——让属于同一个簇的样本都聚集在一起。EGCL模块正是为了解决这个问题。它将从GCN得到的融合表示 z ~ i \tilde{z}_i z~i 和来自各视图的原始表示 z i m z_i^m zim 经过 mlp 降维后,得到统一维度的表示 h ^ i \hat{h}_i h^i 和 h i m h_i^m him。其对比损失函数 L Egc L_{\text{Egc}} LEgc 定义如下:
L Egc = − 1 2 N ∑ i = 1 N ∑ m = 1 M log e C ( h ^ i , h i m ) / τ ∑ j = 1 N e ( 1 − S i j ) C ( h ^ i , h j m ) / τ − e 1 / τ L_{\text{Egc}} = -\frac{1}{2N} \sum_{i=1}^{N} \sum_{m=1}^{M} \log \frac{e^{\text{C}(\hat{h}_i, h_i^m)/\tau}}{\sum_{j=1}^{N} e^{(1-S_{ij})\text{C}(\hat{h}_i, h_j^m)/\tau} - e^{1/\tau}} LEgc=−2N1i=1∑Nm=1∑Mlog∑j=1Ne(1−Sij)C(h^i,hjm)/τ−e1/τeC(h^i,him)/τ
这里的 τ \tau τ 是温度系数, C ( ⋅ , ⋅ ) \text{C}(\cdot, \cdot) C(⋅,⋅) 是余弦相似度。该公式最精妙之处在于分母中的 ( 1 − S i j ) (1-S_{ij}) (1−Sij) 项。 S i j S_{ij} Sij 来自于我们精心融合的图矩阵。当样本 i i i 和样本 j j j 在融合图上被认为是同类(即 S i j S_{ij} Sij 较大)时, ( 1 − S i j ) (1-S_{ij}) (1−Sij) 的值会变小,从而减弱了 h j m h_j^m hjm 作为负样本的惩罚力度。反之,如果 S i j S_{ij} Sij 很小,说明它们很可能不属于一类,那么惩罚力度就会很大。通过这种方式,EGCL促使模型不仅学习样本间的一致性,更重要的是学习簇内样本的聚集性,使得最终的表示更适合聚类任务。
模型的总损失函数由重建损失和EGCL损失加权构成: L = L Rec + λ L Egc L = L_{\text{Rec}} + \lambda L_{\text{Egc}} L=LRec+λLEgc。训练分为预训练(仅使用 L Rec L_{\text{Rec}} LRec)和微调(使用总损失 L L L)两个阶段。训练完成后,使用k-means算法对最终的表示 H ^ \hat{H} H^进行聚类。
四、实验设计与结果分析
论文在六个广泛使用的公开数据集上进行了实验,包括 Caltech5V, WebKB, LGG, MNIST, RBGD, 和 LandUse。这些数据集涵盖了不同的样本数量、视图数量和类别。评价指标采用了聚类任务中标准的准确率(ACC)、归一化互信息(NMI)和纯度(PUR),数值越高代表聚类效果越好。
对比实验
论文将MoEGCL与八个最新的深度多视图聚类方法进行了比较。
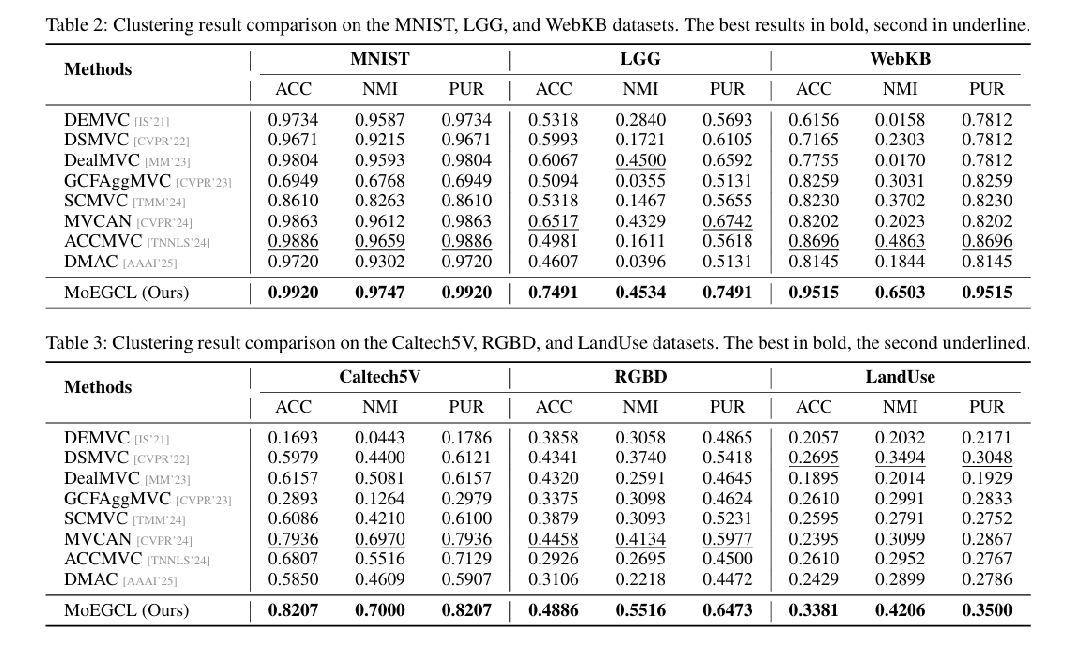
从 表2 和 表3 的结果可以看出,MoEGCL在所有六个数据集上的全部三个评价指标都达到了当前最佳(State-of-the-Art)水平。特别是在一些挑战性较高的数据集上,优势尤为明显。例如,在WebKB数据集上,MoEGCL的ACC达到了95.15%,相比次优方法ACCMVC(86.96%)提升了8.19%,这是一个非常显著的进步。在Caltech5V和RGBD数据集上,ACC也分别比次优方法高出2.71%和4.28%。
这些结果充分证明了MoEGCL模型强大的性能和良好的泛化能力,其核心的精细化图融合与簇内对比学习策略是极其有效的。
可视化对比
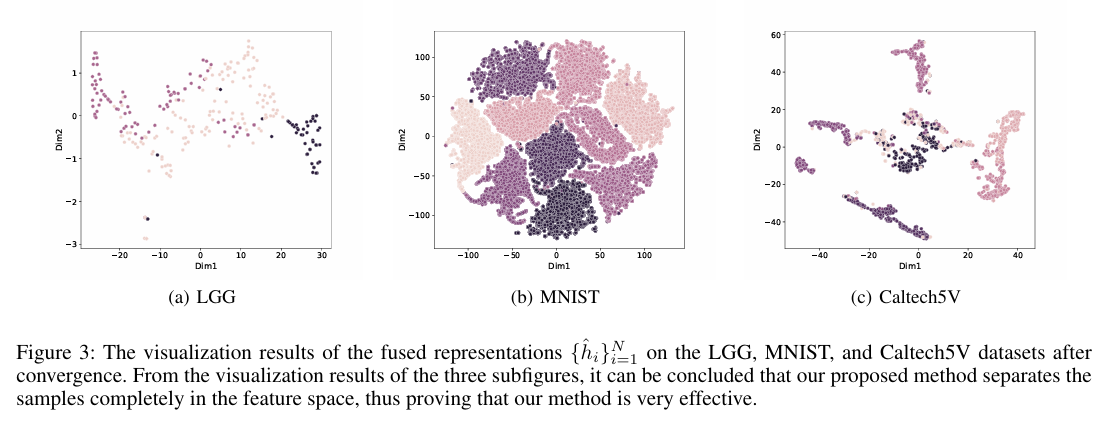
为了直观地展示聚类效果,论文使用t-SNE技术对模型在LGG、MNIST和Caltech5V数据集上学习到的融合表示 { h ^ i } i = 1 N \{\hat{h}_i\}_{i=1}^N {h^i}i=1N 进行了降维可视化。从 图3 中可以清晰地看到,不同颜色的点(代表不同真实类别)形成了高度内聚、边界清晰的簇,不同簇之间几乎没有重叠。例如,在(a) LGG数据集中,样本被完美地分成了3个独立的群组,这与数据集的真实类别数相符。这表明MoEGCL学习到的特征表示具有非常强的判别力,使得简单的聚类算法(如k-means)也能轻松地将它们分离开。
消融实验
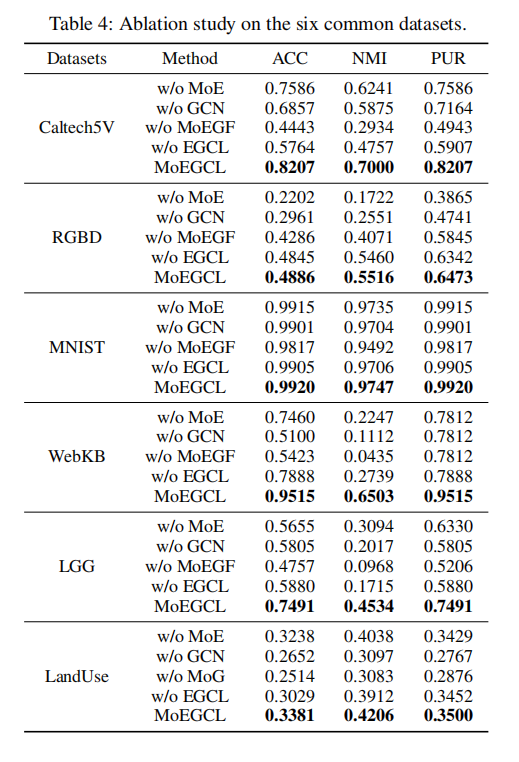
消融实验的目的是验证模型中各个创新模块的必要性。如 表4 所示,作者设计了几个变体模型进行对比:
- w/o MoEGF:移除了整个自我图混合融合模块,直接拼接各视图特征。结果显示,性能出现了断崖式下跌,例如在WebKB和LGG上ACC分别下降了40.92%和27.34%。这强力证明了基于MoE的样本级精细化图融合是模型取得成功的关键。
- w/o EGCL:移除了自我图对比学习模块。性能同样出现明显下降,尤其是在Caltech5V和LGG数据集上,ACC分别降低了24.43%和16.11%。这说明了引入簇结构信息的对比学习目标对于提升表示质量至关重要。
- w/o MoE:保留了图融合的框架,但用简单的平均法替代了混合专家网络。性能同样不如完整的MoEGCL,尤其在WebKB上,ACC、NMI、PUR分别下降了20.55%、42.56%和17.03%,证明了MoE动态加权机制的优越性。
- w/o GCN:移除了图卷积网络。性能也有所下降,表明GCN在平滑特征、聚合邻域信息方面发挥了积极作用。
综上,消融实验系统地验证了MoEGF、EGCL以及MoE等核心组件都对最终的优异性能做出了不可或缺的贡献。
五、论文结论与评价
总结
本文针对多视图聚类中普遍存在的粗粒度信息融合问题,提出了一个名为MoEGCL的创新框架。理论上,它通过MoEGF模块实现了前所未有的样本级动态图融合,并设计了EGCL模块来优化对比学习的目标,使之更符合聚类任务的本质。实验上,模型在六个基准数据集上全面超越了当前最先进的方法。这项研究对后续工作的启示在于,未来的多视图学习可以更多地关注样本间的异质性,设计更为精细和动态的融合策略,而不仅仅停留在视图层面。
优点
- 融合机制创新:MoEGF模块的核心思想非常巧妙,它将混合专家网络应用于图融合,实现了从“宏观调控”到“精准滴灌”的转变,极大地提升了融合图的质量。
- 学习目标更优:EGCL模块对传统对比学习的改进直击痛点。通过在损失函数中巧妙地融入图结构信息,引导模型学习簇级别的内聚性,这比仅仅学习样本自身的一致性更具实际意义。
- 性能优势显著:模型不仅在理论上新颖,在实践中也表现出色,其实验结果在多个数据集上都取得了大幅领先,证明了其有效性和鲁棒性。
缺点
- 计算复杂度较高:为每个样本构建和融合自我图,并在对比学习中计算所有样本对的相似性,使得模型的计算开销和内存消耗相对较大,这可能会限制其在超大规模数据集上的应用。
- 对初始图构建的敏感性:模型的性能在一定程度上依赖于初始KNN图的质量。如果原始特征空间中类别边界模糊,导致KNN图构建不佳,可能会影响后续MoE融合的效果。
- 两阶段流程:模型采用的是先学习表示,再用k-means进行聚类的两阶段方法。虽然这是该领域的常见做法,但与完全端到端的聚类模型相比,在理论上不够优雅,并且k-means本身对初始中心敏感。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)