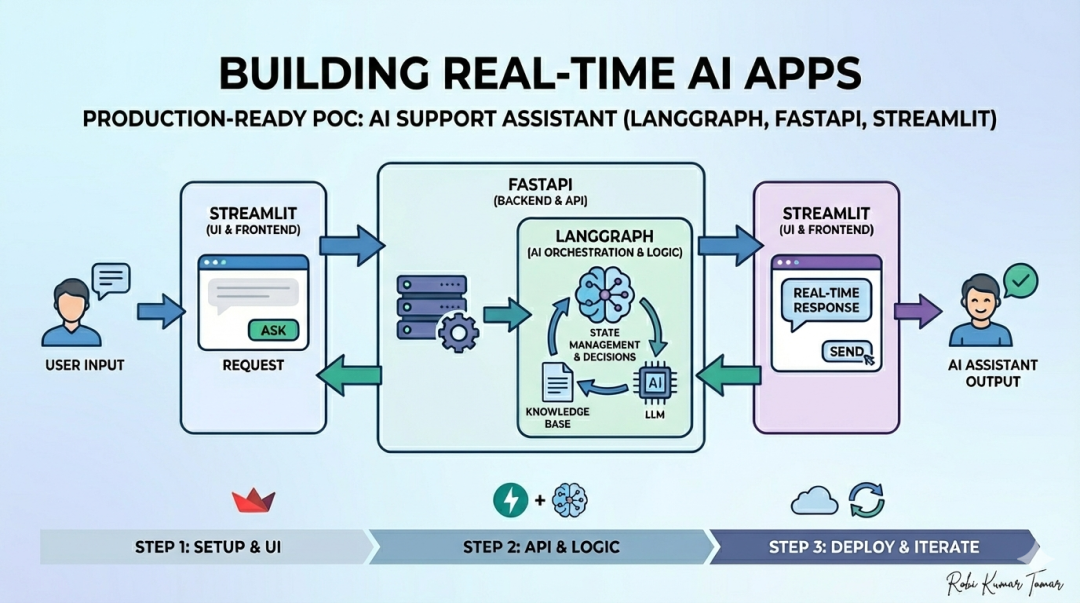
使用LangGraph、FastAPI和Streaml构建状态化AI应用的完整架构
没有清晰的状态模型,工作流会变得难以调试与推理。
本文详解如何使用LangGraph、FastAPI和Streamlit构建生产级AI助手POC。系统采用三层架构:Streamlit前端、FastAPI后端API、LangGraph AI工作流引擎。文章重点讲解强类型状态定义、多节点工作流设计、前后端分离、可观测性等关键技术,提供完整项目结构与代码实现。该POC功能简单但架构遵循生产级原则,可作为构建可扩展AI应用的基础。
一个可用于生产环境的概念验证(逐步详解)
- 引言
大多数 AI 演示在第一眼看上去令人印象深刻,但在真实场景中往往难以落地。它们通常存在以下问题:
- • 只能处理单次 Prompt
- • 无法在多轮交互中保持上下文
- • 将 UI 与 AI 逻辑混在一起
- • 随着复杂度提升迅速失控
真正的 AI 应用需要 状态管理(state)、结构化设计(structure) 以及 显式控制流(explicit control flow)。
在本文中,我们将构建一个小型但具备生产思维的概念验证(POC),使用以下技术栈:
- • LangGraph —— 用于建模具备状态的多步骤 AI 工作流
- • FastAPI —— 将 AI 逻辑封装为清晰的后端服务
- • Streamlit —— 构建响应式、实时的用户界面
这个 POC 在功能上刻意保持简单,但在架构设计上遵循真实生产级 AI 系统所采用的原则。
- 我们要构建什么?
—— 一个面向 SaaS 产品的实时(请求–响应式)AI 支持助手
问题(Problem)
- • 客服团队反复回答相同问题
- • 用户期望即时响应
- • 传统聊天机器人在多轮追问中容易失效
解决方案(Solution)
构建一个实时 AI 助手,它能够:
- • 理解用户意图(Intent Understanding)
- • 进行多步骤推理(Multi-step Reasoning)
- • 维护对话状态(Conversation State)
- • 通过 UI 实时返回响应
为什么这个用例重要
- • 在 SaaS、内部工具和 AI 平台中需求极高
- • 表面简单,但正确实现难度很大
- • 是展示 LangGraph 优势的理想场景
- 为什么选择 LangGraph + FastAPI + Streamlit?
LangGraph(AI 工作流引擎)
LangGraph 允许你:
- • 将 AI 逻辑表示为图结构(Graph),而不是线性链式流程
- • 在多个步骤之间维护状态(Stateful Execution)
- • 添加验证(Validation)、路由(Routing)和控制逻辑(Control Flow)
- • 对每一个推理步骤进行调试与可观测分析
它本质上是一个 具备显式控制流的 AI 工作流编排引擎。
FastAPI(后端 API 层)
FastAPI 提供:
- • 高性能(基于 ASGI)
- • UI 与 AI 逻辑的清晰分离
- • 易于部署与横向扩展
它负责将 AI 能力封装为标准 API 服务。
Streamlit(前端 UI 层)
Streamlit 支持:
- • 快速构建交互式界面
- • 实时用户交互
- • 极低的前端开发复杂度
适合快速构建可运行的产品级 POC。
三者协同架构
Streamlit(UI) → FastAPI(API 层) → LangGraph(AI 逻辑层)
这种分层解耦对于生产环境至关重要:
- • UI 不承担 AI 逻辑
- • 后端不混入展示代码
- • AI 工作流可独立演进
此外,LangGraph 提供了节点级(node-level)的日志记录与调试能力,非常适合做系统可观测性(Observability)。
- 高层架构(High-Level Architecture)
+--------------+
| Streamlit UI |
+------+-------+
|
v
+------------------+
| FastAPI Server |
+--------+---------+
|
v
+------------------+
| LangGraph Engine |
+------------------+
|
v
LLM Provider
- 端到端数据流(End-to-End Data Flow)
User Input
|
v
[Streamlit UI]
|
v
[FastAPI Endpoint]
|
v
[Intent Node]
|
v
[Response Node]
|
v
[Safety / Post-Process Node]
|
v
[Final AI Response]
- 项目结构
realtime_ai_poc/
│
├── backend/
│ ├── __init__.py
│ ├── main.py # FastAPI application
│ ├── graph.py # LangGraph workflow definition
│ ├── config.py # Environment & settings management
│ └── logging_config.py # Logging configuration
│
├── frontend/
│ ├── app.py # Streamlit UI
│ └── api_client.py # Backend communication layer
│
├── .env # Local environment variables (not committed)
├── .gitignore
├── requirements.txt
└── README.md
# Note: backend/config.py:定义并管理 BaseSettings(统一配置入口)
# backend/logging_config.py:集中化管理日志配置(Centralized Logging Configuration)
- 环境搭建
创建虚拟环境
mamba create -n venv python=3.10
mamba activate venv
安装依赖项
pip install -r requirements.txt
### requirements.txt
fastapi>=0.110
uvicorn[standard]>=0.27
streamlit>=1.32
requests>=2.31
langgraph>=0.0.30
langchain-openai>=0.1.0
langchain-community>=0.0.1 # if using langchain_community vectorstores
chromadb>=0.3.0 # Chroma backing store
python-dotenv>=1.0
pydantic>=2.0
设置您的 API 密钥:
OPENAI_API_KEY=your_api_key_here
添加.gitignore:
.env
__pycache__/
.venv/
- LangGraph:强类型状态(Typed State)
为什么强类型状态很重要?
- • 使数据流显式化(Explicit Data Flow)
- • 防止隐式错误(Silent Bugs)
- • 提升代码可读性与调试效率
在基于 LangGraph 构建的工作流中,状态(State)是贯穿多个节点的核心载体。使用强类型定义状态,可以:
- • 明确每个节点的输入与输出
- • 在编译阶段捕获类型错误
- • 避免运行时因字段缺失或格式错误导致的问题
相关实现位于:backend/graph.py
# backend/graph.py
from __future__ import annotations
import logging
import os
from typing import Optional, Dict, Any, List
from dotenv import load_dotenv
try:
from typing import TypedDict
except ImportError:
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
load_dotenv()
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# ============================================================
# Model Initialization
# ============================================================
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
llm = ChatOpenAI(
model=os.getenv("LLM_MODEL", "gpt-4o-mini"),
temperature=float(os.getenv("LLM_TEMPERATURE", "0.0")),
api_key=OPENAI_API_KEY or None,
)
# ============================================================
# Vector Store (RAG Setup)
# ============================================================
EMBEDDINGS_MODEL = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
VECTOR_DB_DIR = os.getenv("VECTOR_DB_DIR", "./chroma_db")
vectorstore = Chroma(
persist_directory=VECTOR_DB_DIR,
embedding_function=EMBEDDINGS_MODEL,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
# ============================================================
# State Definition
# ============================================================
VALID_INTENTS = {"billing", "technical", "account", "general"}
class ChatState(TypedDict, total=False):
message: str
intent: Optional[str]
context: Optional[str]
response: Optional[str]
# ============================================================
# Helper: Extract text safely from LLM result
# ============================================================
def _extract_text_from_result(res: Any) -> str:
if res is None:
return ""
if hasattr(res, "content"):
return (res.content or "").strip()
if hasattr(res, "text"):
return (res.text or "").strip()
try:
d = res.dict()
if isinstance(d, dict):
return (d.get("content") or d.get("text") or "").strip()
except Exception:
pass
return str(res).strip()
async def _llm_ainvoke_safe(prompt: str) -> str:
if hasattr(llm, "ainvoke"):
try:
res = await llm.ainvoke(prompt)
return _extract_text_from_result(res)
except Exception:
logger.exception("ainvoke failed")
if hasattr(llm, "apredict"):
try:
res = await llm.apredict(prompt)
if isinstance(res, str):
return res.strip()
return _extract_text_from_result(res)
except Exception:
logger.exception("apredict failed")
if hasattr(llm, "invoke"):
try:
res = llm.invoke(prompt)
return _extract_text_from_result(res)
except Exception:
logger.exception("invoke failed")
return ""
# ============================================================
# Node 1: Intent Classification
# ============================================================
async def intent_node(state: ChatState) -> Dict[str, str]:
message = state.get("message", "").strip()
if not message:
raise ValueError("Empty message received in intent_node")
prompt = (
"You are an intent classifier for a SaaS support system.\n"
"Classify the user message into exactly one of:\n"
"billing, technical, account, general.\n\n"
"Return ONLY the single word category.\n\n"
f"User message:\n{message}\n\nCategory:"
)
raw = await _llm_ainvoke_safe(prompt)
intent = raw.lower().strip()
if intent not in VALID_INTENTS:
intent = "general"
logger.info("Intent classified: %s", intent)
return {"intent": intent}
# ============================================================
# Node 2: Retrieval (RAG)
# ============================================================
async def retrieve_node(state: ChatState) -> Dict[str, str]:
message = state.get("message", "").strip()
if not message:
return {"context": ""}
try:
docs = retriever.get_relevant_documents(message)
context_chunks: List[str] = [doc.page_content for doc in docs]
context = "\n\n".join(context_chunks)
logger.info("Retrieved %d context documents", len(context_chunks))
return {"context": context}
except Exception:
logger.exception("Retrieval failed")
return {"context": ""}
# ============================================================
# Node 3: Response Generation (Grounded)
# ============================================================
async def response_node(state: ChatState) -> Dict[str, str]:
message = state.get("message", "").strip()
intent = state.get("intent", "general")
context = state.get("context", "")
prompt = (
"You are a professional SaaS support assistant.\n\n"
"Use ONLY the provided product documentation to answer.\n"
"If the documentation does not contain the answer, say:\n"
"'I couldn't find this in our documentation. Let me connect you with support.'\n\n"
"============================\n"
"Product Documentation:\n"
f"{context}\n"
"============================\n\n"
f"User intent: {intent}\n"
f"User message: {message}\n\n"
"Provide a concise, accurate, actionable answer."
)
raw = await _llm_ainvoke_safe(prompt)
response = raw.strip()
logger.info("Response generated (len=%d)", len(response))
return {"response": response}
# ============================================================
# Node 4: Safety Layer
# ============================================================
def safety_node(state: ChatState) -> Dict[str, str]:
response = state.get("response", "")
restricted_keywords = ["medical advice", "legal advice"]
if any(keyword in response.lower() for keyword in restricted_keywords):
return {
"response": (
"I'm unable to provide medical or legal advice. "
"Please consult a qualified professional."
)
}
return {"response": response}
# ============================================================
# Build LangGraph Workflow
# ============================================================
graph = StateGraph(ChatState)
graph.add_node("intent", intent_node)
graph.add_node("retrieve", retrieve_node)
graph.add_node("response", response_node)
graph.add_node("safety", safety_node)
graph.set_entry_point("intent")
graph.add_edge("intent", "retrieve")
graph.add_edge("retrieve", "response")
graph.add_edge("response", "safety")
graph.set_finish_point("safety")
app_graph = graph.compile()
- FastAPI Backend
# backend/main.py
import asyncio
import logging
import uuid
from typing import Optional
from fastapi import FastAPI, HTTPException, Request
from pydantic import BaseModel, BaseSettings
from fastapi.middleware.cors import CORSMiddleware
# Ensure backend/__init__.py exists
from .graph import app_graph
# ============================================================
# Logging Setup
# ============================================================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
)
logger = logging.getLogger("realtime_ai_backend")
# ============================================================
# Settings
# ============================================================
class Settings(BaseSettings):
ALLOWED_ORIGINS: list[str] = ["http://localhost:8501"]
TIMEOUT_SECONDS: int = 20
MAX_INPUT_LENGTH: int = 2000
class Config:
env_file = ".env"
settings = Settings()
# ============================================================
# FastAPI App
# ============================================================
app = FastAPI(
title="Real-Time AI Support Assistant API",
version="1.0.0",
)
app.add_middleware(
CORSMiddleware,
allow_origins=settings.ALLOWED_ORIGINS,
allow_credentials=True,
allow_methods=["POST", "OPTIONS"],
allow_headers=["*"],
)
# ============================================================
# Models
# ============================================================
class Query(BaseModel):
message: str
class ChatResponse(BaseModel):
response: str
request_id: str
# ============================================================
# Health Check (Production Standard)
# ============================================================
@app.get("/health")
async def health():
return {"status": "ok"}
# ============================================================
# Chat Endpoint
# ============================================================
@app.post("/chat", response_model=ChatResponse)
async def chat(query: Query, request: Request):
request_id = str(uuid.uuid4())
logger.info("Request %s received", request_id)
text = query.message.strip()
# ---- Input Validation ----
if not text:
raise HTTPException(status_code=400, detail="Please enter a valid question.")
if len(text) > settings.MAX_INPUT_LENGTH:
raise HTTPException(
status_code=400,
detail=f"Message too long (max {settings.MAX_INPUT_LENGTH} characters).",
)
# ---- Invoke Graph ----
try:
if hasattr(app_graph, "ainvoke"):
result = await asyncio.wait_for(
app_graph.ainvoke({"message": text}),
timeout=settings.TIMEOUT_SECONDS,
)
else:
loop = asyncio.get_running_loop()
result = await loop.run_in_executor(
None, app_graph.invoke, {"message": text}
)
except asyncio.TimeoutError:
logger.exception("Request %s timed out", request_id)
raise HTTPException(
status_code=504,
detail="Processing timed out. Please try again.",
)
except Exception:
logger.exception("Request %s failed internally", request_id)
raise HTTPException(
status_code=500,
detail="Internal server error.",
)
# ---- Extract Response ----
response_text: Optional[str] = None
if isinstance(result, dict):
response_text = result.get("response")
else:
response_text = getattr(result, "response", None)
if not response_text:
logger.error("Request %s returned empty response", request_id)
raise HTTPException(
status_code=500,
detail="No response from model pipeline.",
)
logger.info("Request %s completed successfully", request_id)
return ChatResponse(
response=response_text,
request_id=request_id,
)
- Streamlit Frontend
# frontend/app.py
import streamlit as st
import requests
from requests.exceptions import RequestException
# ============================================================
# Configuration
# ============================================================
API_URL = "http://localhost:8000/chat"
TIMEOUT_SECONDS = 25 # Slightly higher than backend timeout
MAX_INPUT_LENGTH = 2000 # Keep aligned with backend
# ============================================================
# Page Setup
# ============================================================
st.set_page_config(
page_title="Real-Time AI Support Assistant",
page_icon="🤖",
layout="centered",
)
st.title("🤖 Real-Time AI Support Assistant")
st.caption("Intent-aware • Retrieval-augmented • SaaS-ready architecture")
# ============================================================
# Session State
# ============================================================
if "history" not in st.session_state:
st.session_state.history = []
if "last_request_id" not in st.session_state:
st.session_state.last_request_id = None
# ============================================================
# Input Form
# ============================================================
with st.form("chat_form", clear_on_submit=True):
user_input = st.text_input(
"Ask your question",
max_chars=MAX_INPUT_LENGTH,
placeholder="e.g., How do I upgrade my billing plan?",
)
submitted = st.form_submit_button("Send")
# ============================================================
# Submit Handling
# ============================================================
if submitted:
if not user_input or not user_input.strip():
st.warning("Please enter a valid question.")
else:
placeholder = st.empty()
try:
with placeholder.container():
st.info("Sending request to backend...")
response = requests.post(
API_URL,
json={"message": user_input.strip()},
timeout=TIMEOUT_SECONDS,
)
response.raise_for_status()
data = response.json()
answer = data.get("response", "No response returned.")
request_id = data.get("request_id")
# Store conversation
st.session_state.history.append(("You", user_input.strip()))
st.session_state.history.append(("Assistant", answer))
st.session_state.last_request_id = request_id
except RequestException as e:
st.error("Backend request failed.")
st.exception(e)
finally:
placeholder.empty()
# ============================================================
# Chat History Rendering
# ============================================================
if st.session_state.history:
st.divider()
st.subheader("Conversation")
for speaker, text in st.session_state.history:
if speaker == "You":
st.markdown(f"**🧑 You:** {text}")
else:
st.markdown(f"**🤖 Assistant:** {text}")
# ============================================================
# Footer Info
# ============================================================
if st.session_state.last_request_id:
st.divider()
st.caption(f"Request ID: `{st.session_state.last_request_id}`")
注意:关键词过滤仅用于演示级别。生产环境中应使用专业的内容审核(Moderation)API。
- 运行 POC
🔹 第 1 步:激活虚拟环境
在项目根目录执行:
mamba activate venv
🔹 第 2 步:启动后端(在项目根目录)
uvicorn backend.main:app --reload
为什么这样做?
- • 确保 backend 被视为 Python 包
- • 避免相对导入错误
- • 在不同环境下保持一致行为
后端服务运行地址:
http://localhost:8000
🔹 第 3 步:启动前端(在项目根目录)
打开一个新的终端窗口:
streamlit run frontend/app.py
前端访问地址:
http://localhost:8501
🔹 第 4 步:验证系统是否正常运行
打开:
📘 API 文档 → http://localhost:8000/docs
💬 UI 界面 → http://localhost:8501
- 关于“实时”的说明
本 POC 实际提供的能力
该实现提供的是近实时(near real-time)的请求–响应式 AI 交互,具体流程如下:
-
- 前端向 FastAPI 后端发送请求
-
- 后端调用 LangGraph 工作流
-
- 模型生成完整响应
-
- 返回结果并在 UI 中渲染
⚠ 注意:
- • 不支持逐 token 流式输出
- • 只有在生成完成后才返回完整响应
- 可观测性与调试(Observability & Debugging)
优秀的 AI 系统必须具备可观测性。
在本 POC 中:
- • 每个节点都会记录状态变更
- • 意图识别、响应生成与安全检查步骤可追踪
- • 可以轻松扩展接入 LangSmith 或 OpenTelemetry
在真实系统中,这一点至关重要。
- 性能优化建议
- • 保持 Prompt 简洁
- • 避免不必要的 LLM 调用
- • 缓存高频问题
- • 对简单请求进行短路处理(short-circuit)
- • 控制图结构复杂度
- 安全注意事项
- • 永远不要在前端暴露 API Key
- • 验证用户输入
- • 防御 Prompt 注入攻击
- • 为后端接口设置限流(Rate Limiting)
- • 避免记录敏感信息到日志
- 常见误区
❌ 误区 1:用 LangGraph 处理简单单步任务
如果只有单步 Prompt,LangGraph 会增加不必要的复杂性。
❌ 误区 2:UI 与 AI 逻辑强耦合
让 Streamlit 专注展示层,推理与编排逻辑交给后端。
❌ 误区 3:没有显式状态定义
没有清晰的状态模型,工作流会变得难以调试与推理。
❌ 误区 4:缺乏可观测性与日志
当系统出问题时,无法定位是哪个节点出错。
❌ 误区 5:模糊使用“实时”概念
需要明确区分:
- • 低延迟
- • 流式输出
- • 异步执行
- 什么时候不需要 LangGraph?
不适用场景:
- • 单次 Prompt
- • 无状态或无分支逻辑
- • 简单文本生成
适用场景:
- • 状态至关重要
- • 决策依赖前序步骤
- • 需要可控性与可靠性
- 如何将 POC 扩展为生产系统?
你可以通过以下方式升级该系统:
1️⃣ 流式响应
- • 使用 LangGraph 的
astream() - • 在 FastAPI 中返回
StreamingResponse - • 在 Streamlit 中逐 token 渲染
2️⃣ 会话记忆
- • 扩展
ChatState增加历史记录 - • 使用 Redis 或数据库持久化会话
- • 支持多轮上下文对话
3️⃣ 知识库(RAG)
- • 在响应生成前添加检索节点
- • 集成向量搜索(如 FAISS、Pinecone 等)
- • 基于公司真实数据进行回答
4️⃣ 身份认证与多用户支持
- • 在 FastAPI 中接入 JWT 或 OAuth
- • 将对话与用户 ID 关联
- • 添加限流机制
5️⃣ 容器化与部署
- • 为前后端创建 Dockerfile
- • 使用 Docker Compose 本地开发
- • 部署到云平台(AWS、GCP、Azure 等)
6️⃣ 分析与监控
- • 添加结构化日志
- • 集成 LangSmith 或 OpenTelemetry
- • 监控延迟、Token 使用量、成本与错误率
- 总结
这个 POC 展示了真实 AI 应用的构建方式:
- • 有状态的工作流,而非临时拼接 Prompt
- • 基于 LangGraph 节点的显式控制流
- • 清晰的前后端分离
- • 带超时控制的异步执行
- • 内建可观测性与安全意识
它规模不大,但设计遵循生产级原则。
如果你能够构建并理解这个系统,那么你不仅是在做一个聊天机器人。
你是在构建一个可扩展、实时 AI 应用的工程基础架构。
无状态或无分支逻辑
- • 简单文本生成
适用场景:
- • 状态至关重要
- • 决策依赖前序步骤
- • 需要可控性与可靠性
- 如何将 POC 扩展为生产系统?
你可以通过以下方式升级该系统:
1️⃣ 流式响应
- • 使用 LangGraph 的
astream() - • 在 FastAPI 中返回
StreamingResponse - • 在 Streamlit 中逐 token 渲染
2️⃣ 会话记忆
- • 扩展
ChatState增加历史记录 - • 使用 Redis 或数据库持久化会话
- • 支持多轮上下文对话
3️⃣ 知识库(RAG)
- • 在响应生成前添加检索节点
- • 集成向量搜索(如 FAISS、Pinecone 等)
- • 基于公司真实数据进行回答
4️⃣ 身份认证与多用户支持
- • 在 FastAPI 中接入 JWT 或 OAuth
- • 将对话与用户 ID 关联
- • 添加限流机制
5️⃣ 容器化与部署
- • 为前后端创建 Dockerfile
- • 使用 Docker Compose 本地开发
- • 部署到云平台(AWS、GCP、Azure 等)
6️⃣ 分析与监控
- • 添加结构化日志
- • 集成 LangSmith 或 OpenTelemetry
- • 监控延迟、Token 使用量、成本与错误率
- 总结
这个 POC 展示了真实 AI 应用的构建方式:
- • 有状态的工作流,而非临时拼接 Prompt
- • 基于 LangGraph 节点的显式控制流
- • 清晰的前后端分离
- • 带超时控制的异步执行
- • 内建可观测性与安全意识
它规模不大,但设计遵循生产级原则。
如果你能够构建并理解这个系统,那么你不仅是在做一个聊天机器人。
你是在构建一个可扩展、实时 AI 应用的工程基础架构。
从这里开始,扩展规模只是工程问题,而不再是风险博弈。
大模型入门学习教程 (附PDF文档,文末获取)
现在国内外关于大模型入门教程做的比较好的并不多,这其实也是一件好事,有难度和有门槛才能避免烂大街,现在大模型入门教程热度最高的包括李宏毅老师、吴恩达老师、Datawhale开源社区等
选择合适的入门学习教程,能少走弯路,抓住核心内容,快速达到前沿的水平,甚至是发表大模型相关的论文都是可以的
这一期主要是给大家推荐李宏毅老师的最新课程:大模型入门学习教程
这个教程的主要内容如下(总共11讲):
第1讲:总体介绍
这一讲主要介绍现在大模型作为生成式人工智能,其发展的历史过程,以及大模型落地的主要应用方向,了解大模型主要学习什么内容,难度不大,简单看一下就行
第2讲:提示词和AI代理人
首先介绍什么是提示词工程,提示词就是人类和大模型交互的语言,对于大模型的引导需要通过提示词来完成,然后介绍如何引导模型进行思考,比如COT是什么,在模型训练过程中提供额外信息
第3讲:生成策略
同一个问题,多次询问大模型,大模型会给出不同的回答,如何提高回复的准确率以及稳定性,是一个重要的大模型生成策略。了解大模型的生成概率与什么有关,比如top_p, top_k,temperature等
第4讲:深度学习和Transformer
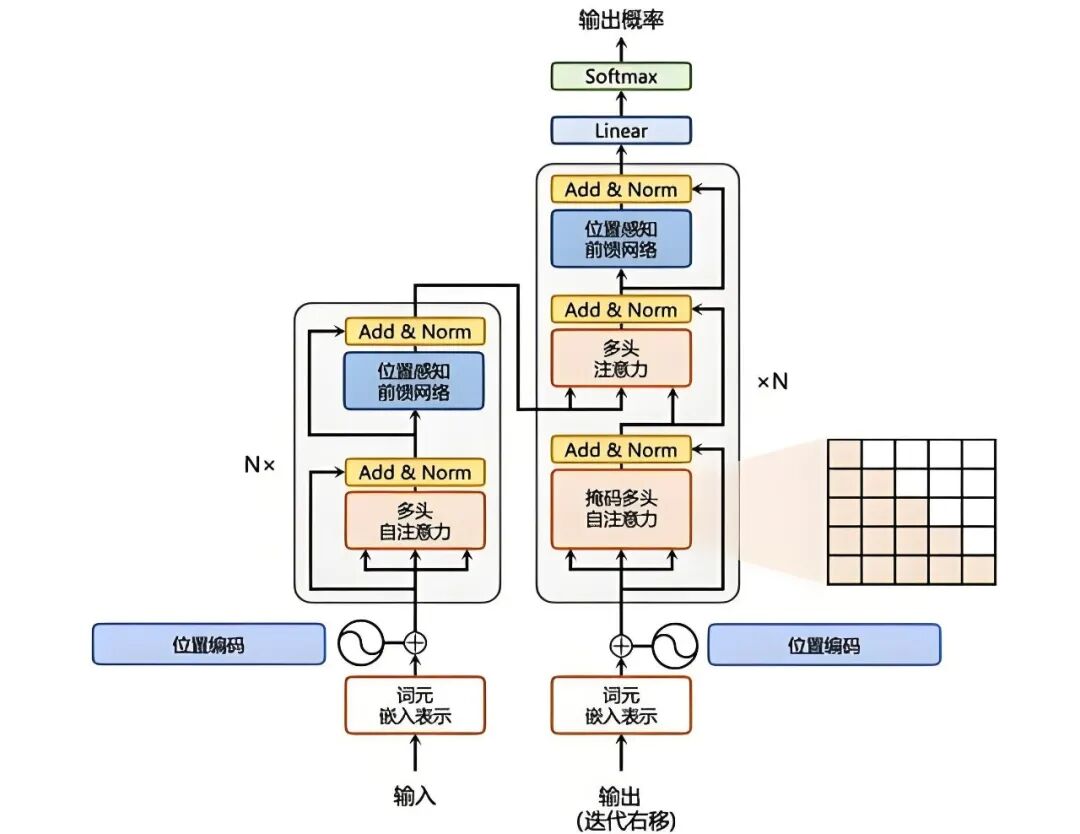
这一部分先介绍一些深度学习基础内容,大模型的模型都是深度学习模型,了解深度学习中基础内容是有必要的,比如损失函数,反向传播,梯度下降等,然后介绍大模型的基础框架transformer,transformer模型结构一定要非常熟悉,很重要
第5讲:大模型评估和道德问题
这一部分先介绍大模型的评估标准,现在有很多benchmark从各个方面来评测大模型的不同能力,评估指标很多,开源的模型往往会选择有利于自己的指标进行展示,然后介绍大模型中存在的道德问题,因为大模型不能随意生成一些不符合道德社会文明的内容
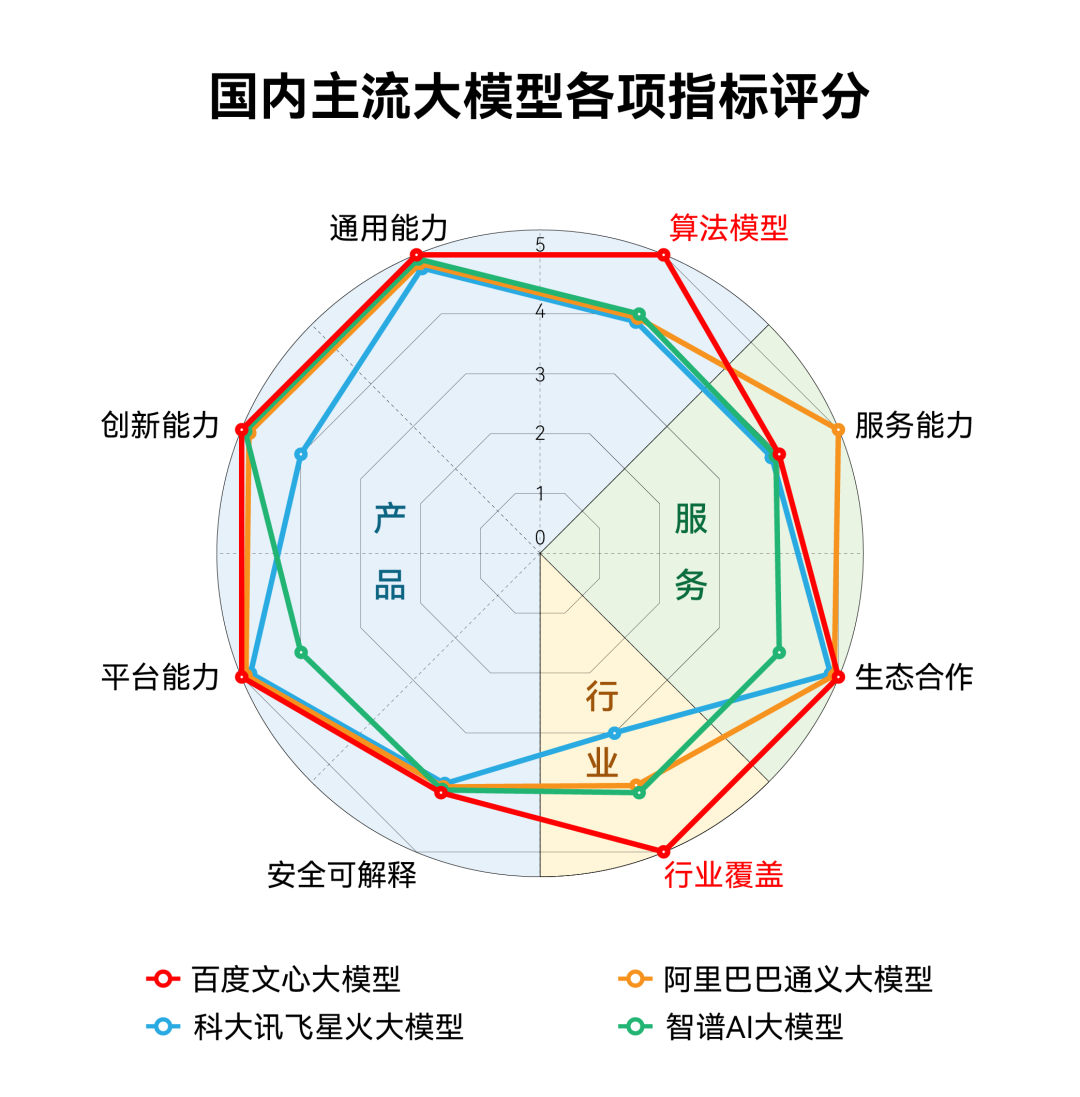
第6讲:AI的可解释性
给大模型一个输入,只能得到一个输出,但是我们并不清楚大模型的思考过程是怎么样的,这个问题,大模型是怎么思考的,提升大模型的可解释性有助于后续研究如何提升大模型的推理性能,像COT就是显式展示大模型的思考过程,然后还可以让语言模型来解释语言模型
第7讲:视觉大模型
常说的大模型,都指的是文本大模型,输入是文本,输出也是文本,而现实世界中,可能我们的输入既有文本,又有图片和视频,输出也可能是多样化的,视觉大模型就是能解决文本和视觉两种模态的大模型
第8讲:GPT-4o
前面都是关于大 模型的理论,这一部分是拆解一个完整的大模型是怎么样的,以GPT-4o为例进行说明,GPT**-4o是首个端到端多模态通用模型**,是迈向AGI的一步,能够实现文本,音频和图片的多模态交互
上面就是大模型的入门教程的所有内容,学完这些可以去看看关于大模型微调,大模型训练,大模型推理加速,RAG和Agent等相关的内容,后面最好整一两个项目来实践一下
上述资料获取:
1. 关注公众号【大模型应用开发LLM】领取即可获取
2. 这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献169条内容
已为社区贡献169条内容

所有评论(0)