OpenAI开源神器Whisper!99种语言高精度转录,重塑语音识别新标准
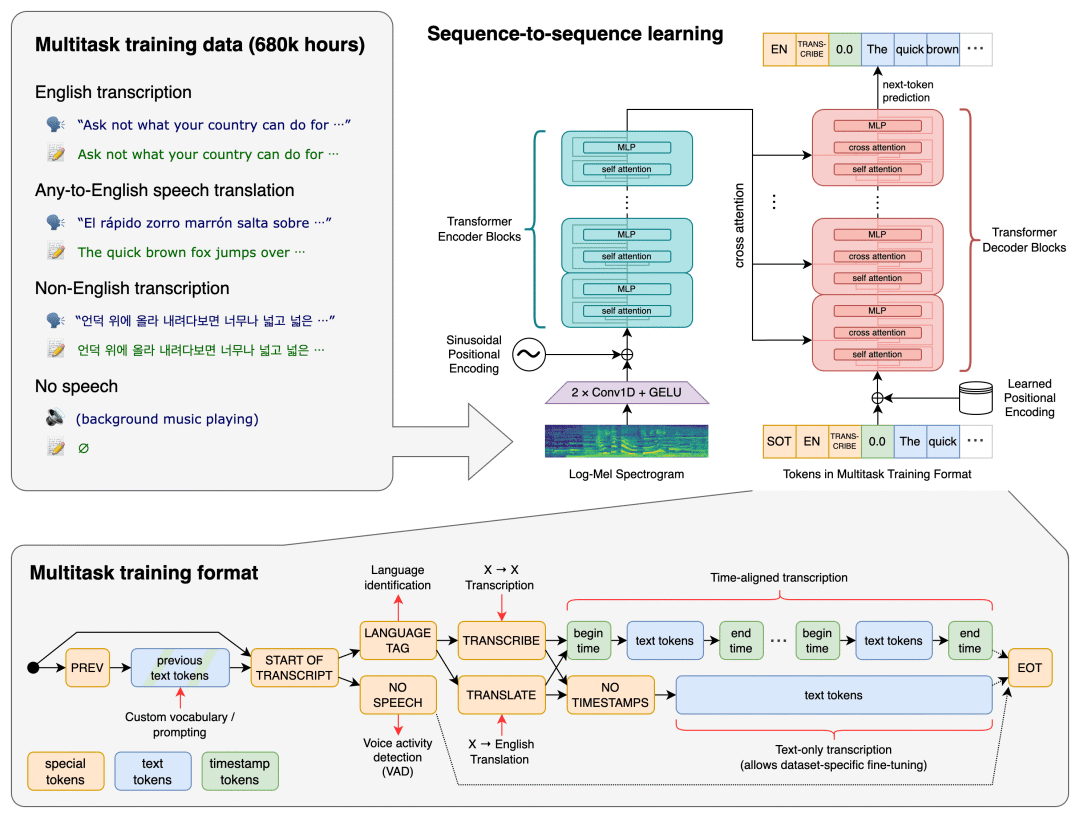
Whisper是OpenAI推出的开源通用语音识别系统,它采用端到端的Transformer架构,在68万小时的多语言和多任务监督数据上进行训练,赋予了模型强大的泛化能力。与其他语音识别系统相比,Whisper的独特之处在于其多任务学习能力——单个模型即可完成多语言语音识别、语音翻译到英语以及语言识别等任务。该项目的设计理念是简化传统复杂的语音处理流程。通过将各种语音处理任务统一表示为解码器需要预
OpenAI Whisper:开源语音识别模型的全面解析与应用指南
一款集多语言识别、语音翻译、高抗噪能力于一身的开源语音识别系统,正以惊人的准确率和易用性成为开发者和企业的首选。
在人工智能迅猛发展的今天,语音识别技术已成为人机交互的核心环节。OpenAI开源的Whisper模型,作为一款通用的语音识别系统,自2022年发布以来便以其卓越的多语言支持和高准确率脱颖而出。该项目基于Transformer架构,在大量多样化音频数据上训练而成,不仅能够进行多语言语音识别,还支持语音翻译和语言识别,为开发者构建语音应用提供了强大的基础能力。
项目简介:重新定义语音识别
Whisper是OpenAI推出的开源通用语音识别系统,它采用端到端的Transformer架构,在68万小时的多语言和多任务监督数据上进行训练,赋予了模型强大的泛化能力。与其他语音识别系统相比,Whisper的独特之处在于其多任务学习能力——单个模型即可完成多语言语音识别、语音翻译到英语以及语言识别等任务。
该项目的设计理念是简化传统复杂的语音处理流程。通过将各种语音处理任务统一表示为解码器需要预测的token序列,Whisper可以用单一模型替代传统语音处理流程中的多个环节。这种简洁而强大的设计,使得开发者无需具备深厚的语音识别专业知识,也能轻松构建高质量的语音应用。
核心功能亮点
Whisper的功能生态丰富而全面,涵盖了现代语音识别应用的各个方面。
多语言语音识别
Whisper支持超过100种语言的语音转文本任务,包括中文、英语、西班牙语、法语、德语、日语、韩语等主流语言。其训练数据覆盖了广泛的语言和口音,确保了在不同语言环境下的高识别准确率。用户可以通过设置语言参数来指定识别语言,也可以让模型自动检测音频中的语言类型。
语音翻译与转录
除了将语音转换为同语言文本外,Whisper还能够将非英语语音翻译成英语文本。这一功能对于跨语言沟通和内容理解具有重要意义。无论是会议记录、讲座转录还是视频内容翻译,Whisper都能提供高质量的英文化输出。
高精度转录与抗噪能力
Whisper在嘈杂环境下仍能保持高准确率的转录能力,这得益于其在多样化音频数据上的训练。模型对背景噪音、不同口音和录音条件的变化都表现出良好的鲁棒性,使其能够适应从专业录音到日常环境的多种应用场景。
灵活的输出格式
Whisper提供带时间戳的文本输出,这对于视频字幕生成、会议记录整理等需要精确定位的场景尤为有用。用户可以获取转录文本的精确开始和结束时间,便于后续的编辑和同步处理。
模型选择与性能平衡
Whisper提供五种不同规模的模型,满足从移动设备到服务器环境的各种需求。
模型规格对比
| 模型规模 | 参数量 | 内存占用 | 相对速度 | 英语识别准确率 | 多语言支持 |
|---|---|---|---|---|---|
|
tiny |
39 M |
~75 MB |
~32x |
低 |
是 |
|
base |
74 M |
~142 MB |
~16x |
中等 |
是 |
|
small |
244 M |
~466 MB |
~6x |
高 |
是 |
|
medium |
769 M |
~1.5 GB |
~2x |
很高 |
是 |
|
large |
1550 M |
~3 GB |
1x |
最高 |
是 |
数据基于OpenAI发布的模型规格
模型选择建议
-
资源受限环境(如移动设备、嵌入式系统):推荐使用
tiny或base版本,它们在保持合理准确率的同时大幅减少资源消耗。 -
平衡型应用:
small和medium模型在准确率和速度之间取得了良好平衡,适合大多数桌面和服务端应用。 -
最高精度场景:对准确率有极致要求的专业场景,如医学转录、法律记录等,建议使用
large模型。
对于仅需英语识别的应用,可以选择带.en后缀的英语专用模型,这些模型在英语任务上表现更优,尤其是tiny.en和base.en版本。
安装与使用方法
安装步骤
Whisper的安装过程简单快捷,可通过Python包管理器pip直接安装:
pip install openai-whisper
安装完成后,系统会自动安装所有必要的依赖。如需GPU加速,需要额外安装PyTorch的CUDA版本。
基础使用示例
以下是一个完整的语音转录示例,展示如何使用Whisper进行语音转文本:
import whisper
# 加载模型,首次使用时会自动下载权重
model = whisper.load_model("medium")
# 转录音频文件
result = model.transcribe("audio.wav")
# 输出转录结果
print(result["text"])
# 获取带时间戳的详细结果
for segment in result["segments"]:
print(f"[{segment['start']:.2f}s -> {segment['end']:.2f}s] {segment['text']}")
高级功能使用
Whisper支持多种高级参数,满足不同场景的需求:
# 高级转录配置
result = model.transcribe(
"audio.wav",
language="zh", # 指定语言为中文
task="transcribe", # 任务类型:transcribe或translate
temperature=0.0, # 控制随机性,0.0表示确定性输出
best_of=5, # 束搜索数量
beam_size=5, # 束搜索大小
fp16=True # 使用半精度推理加速
)
# 强制翻译为英语
translation = model.transcribe(
"french_audio.mp3",
language="fr",
task="translate" # 将法语翻译为英语
)
实战应用场景
Whisper的灵活性使其在多个领域都能发挥重要作用。
会议记录与转录
企业可以利用Whisper自动生成会议记录,大幅提升工作效率。通过集成实时音频流处理,可以实现会议内容的实时转录。
视频字幕生成
内容创作者可以使用Whisper为视频自动生成字幕,支持多语言输出。其时间戳功能确保字幕与视频画面的精确同步。
实时语音识别
通过技术优化,Whisper能够实现近乎实时的语音转文本功能,端到端延迟可控制在500毫秒以内。这使得它在直播字幕、实时语音助手等场景中具有重要价值。
教育领域应用
在教育场景中,Whisper可以用于讲座转录、语言学习辅助工具等,帮助学生更好地理解和复习课程内容。
性能优化与部署策略
硬件加速方案
-
GPU推理:使用CUDA加速可以大幅提升转录速度,特别是对大型模型。
-
量化技术:通过INT8/INT4量化可以在几乎不损失精度的情况下将模型体积缩小45%,延迟降低19%。
-
专用推理引擎:集成faster-whisper(基于CTranslate2的实现)可以获得高达4倍的速度提升。
部署方案对比
| 部署方式 | 适用场景 | 优势 | 限制 |
|---|---|---|---|
|
本地部署 |
数据隐私要求高的场景 |
零延迟,数据不外传 |
硬件成本高 |
|
云服务器 |
中等规模应用 |
弹性扩展,维护简单 |
持续成本 |
|
边缘计算 |
工业物联网场景 |
低延迟,网络依赖小 |
开发复杂度高 |
实时处理优化
对于实时语音识别场景,可以采用流式处理技术:
import whisper
from pydub import AudioSegment
import queue
import threading
class RealTimeWhisper:
def __init__(self, model_size="medium"):
self.model = whisper.load_model(model_size)
self.audio_queue = queue.Queue(maxsize=10)
self.stop_event = threading.Event()
def audio_callback(self, indata, frames, time, status):
"""音频输入回调函数"""
if status:
print(status)
self.audio_queue.put(indata.copy())
def transcribe_worker(self):
"""后台转写线程"""
buffer = bytearray()
chunk_size = 3200 # 对应200ms音频(16kHz采样率)
while not self.stop_event.is_set():
try:
data = self.audio_queue.get(timeout=0.1)
buffer.extend(data.tobytes())
while len(buffer) >= chunk_size:
chunk = buffer[:chunk_size]
buffer = buffer[chunk_size:]
# 转换为numpy数组并预处理
audio = np.frombuffer(chunk, dtype=np.float32)
result = self.model.transcribe(audio, language="zh", task="transcribe")
print("实时结果:", result["text"])
except queue.Empty:
continue
技术优势与生态对比
在众多语音识别方案中,Whisper展现出独特的竞争优势:
| 对比维度 | Whisper | 传统ASR方案 | 商业语音API |
|---|---|---|---|
| 多语言支持 |
100+种语言 |
通常有限 |
因供应商而异 |
| 准确率 |
嘈杂环境下仍高 |
环境敏感 |
通常较高 |
| 成本 |
免费开源 |
授权费用 |
按使用量付费 |
| 隐私保护 |
可完全离线运行 |
因方案而异 |
数据需上传 |
| 定制性 |
支持微调 |
有限 |
通常不可定制 |
除了表格中的优势,Whisper的其他技术亮点还包括:
-
零样本学习能力:无需针对特定领域进行微调即可在各种场景中获得良好表现。
-
强大的抗噪性能:在背景噪音、口音变化等挑战性环境下仍保持稳定识别效果。
-
活跃的开源生态:拥有丰富的社区贡献,包括各种优化版本和扩展工具。
总结与展望
OpenAI Whisper作为一款开源语音识别系统,以其卓越的多语言支持、高准确率和强大的泛化能力,正在改变开发者和企业构建语音应用的方式。从简单的音频转录到复杂的实时语音交互系统,Whisper提供了一个可靠且易于使用的基础模型。
随着语音技术的不断发展,Whisper也在持续进化。社区推出了诸多优化版本,如faster-whisper提供4倍速度提升,量化技术在边缘设备上实现高效部署,以及对低资源语言的持续优化。这些进步使得Whisper能够在更多场景中发挥作用,从智能客服到实时翻译,从无障碍技术到工业监控。
对于正在寻找高性能、可定制且成本效益高的语音识别解决方案的开发者而言,无论是构建下一代语音交互产品、开发多语言内容处理系统,还是为现有应用添加语音功能,Whisper都提供了一个理想的技术基础。其开源特性意味着技术的透明性和社区驱动的无限潜力,未来有望持续进化,成为语音识别领域的重要基础设施。
项目地址:
https://github.com/openai/whisper

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)