告别 LLM 的“金鱼记忆”:AuraMate 的 IKTS 认知引擎与 GraphRAG 实践
·
文章目录
摘要:大语言模型(LLM)的上下文窗口(Context Window)虽然在不断扩大,但“长短期记忆缺失”依然是阻碍智能体(Agent)从玩具迈向生产力的核心瓶颈。AuraMate 引入了独创的 IKTS(Integrated Knowledge Tree System) 认知架构,通过四层记忆模型、GraphRAG 图谱关联以及类人脑的“做梦”整理机制,赋予了 AI 真正的长期记忆与自我进化能力。本文将硬核拆解 AuraMate 的记忆系统实现原理。
1. 痛点:LLM 的“金鱼记忆”困境
在构建复杂的 AI 助手时,开发者常面临以下挑战:
- Token 成本与限制:虽然 Context Window 达到了 128k 甚至 1M,但每次全量携带历史记录不仅昂贵,还会导致模型注意力分散(Lost in the Middle)。
- 知识碎片化:用户在不同会话中提供的零散信息(如:“我习惯用 Python 3.10”、“项目数据库是 PostgreSQL”),无法被系统有效整合。
- 缺乏时间观念:传统的 RAG(检索增强生成)只是静态查询,无法像人类一样随着时间推移遗忘无关信息或加深重要记忆。
AuraMate 的解决方案是构建一个拥有生命周期的认知引擎(Cognitive Engine)。
2. 核心架构:IKTS 四层记忆模型
AuraMate 的记忆系统不仅仅是向量数据库的简单封装,而是一个分层的知识树系统(Integrated Knowledge Tree System, IKTS)。
2.1 记忆分层设计
我们参考人类认知心理学,将记忆划分为四个层级,存储于 knowledge_tree 表中:
| 层级 (Layer) | 名称 | 描述 | 存储内容示例 | 更新频率 |
|---|---|---|---|---|
| L1 | Core (核心层) | 智能体的自我认知与核心指令 | 身份定义、最高优先级规则 | 极低 |
| L2 | Domain (领域层) | 沉淀的方法论与专业知识 | 编程规范、项目架构模式 | 低 |
| L3 | Knowledge (知识层) | 事实性知识与概要 | “用户偏好 Go 语言”、“API Key 是 xxx” | 中 |
| L4 | Episodic (情景层) | 原始的交互流水与短期记忆 | 具体的对话日志、报错信息 | 高 |
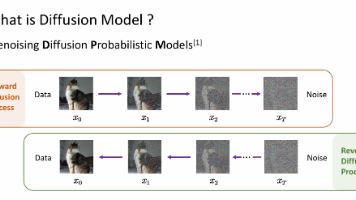
2.2 架构图解
3. 关键技术实现
3.1 混合检索 (Hybrid Search)
为了兼顾语义理解与关键词匹配,AuraMate 采用了 Vector + FTS + Graph 的混合检索策略。
- 向量检索 (Semantic):使用 Embedding 模型(如
text-embedding-v3或aliyun)计算余弦相似度,召回语义相关的记忆。 - 全文检索 (FTS):利用 SQLite 的 FTS5 模块进行 BM25 关键词匹配,确保专有名词(如函数名、错误码)的精确命中。
- GraphRAG:通过
knowledge_edges表维护记忆节点间的关联(Relation),实现“顺藤摸瓜”式的联想回忆。
// 伪代码示例:混合检索逻辑
func (s *Service) Search(query string) []Memory {
// 1. 向量检索召回 Top-K
vecResults := s.vectorSearch(query, limit=20)
// 2. FTS 关键词召回
ftsResults := s.ftsSearch(query, limit=20)
// 3. Rerank 重排序
finalResults := rerank(vecResults, ftsResults)
// 4. Graph 扩展 (获取关联记忆)
for _, mem := range finalResults {
related := s.GetRelated(mem.ID)
finalResults.append(related...)
}
return finalResults
}
3.2 记忆合成与做梦 (Synthesis & Dreaming)
AuraMate 引入了生命周期状态机,包含 Waking(清醒)、Dreaming(做梦/整理)等状态。
- Synthesis (合成):在系统空闲时,后台任务会扫描 L4(情景层)的碎片化记忆,将其聚类并总结为 L3(知识层)的条目。例如,从多次“修改 Python 代码”的对话中,提炼出“用户偏好使用 Type Hint”这一规则。
- Decay (遗忘机制):模仿人脑的遗忘曲线。每个记忆节点都有
confidence(置信度)和access_count(访问次数)。长期未被激活的记忆会逐渐降低置信度,最终被归档或清理,防止知识库无限膨胀导致检索信噪比下降。
4. 实际应用案例
场景:跨会话的代码风格保持
- Day 1:用户要求“代码中所有的变量名必须使用蛇形命名法(snake_case)”。
- 系统动作:将此要求存入 L4,并在夜间 Dreaming 阶段将其升级为 L2 领域的 Coding Standard。
- Day 30:用户让 AuraMate 写一个新的 Python 脚本。
- 系统动作:检索器通过上下文感知,自动召回 L2 层级的“蛇形命名法”规则。
- 结果:生成的代码完美符合用户的个性化习惯,无需用户重复强调。
5. 结语
AuraMate 的记忆系统不仅是存储,更是一种动态的认知过程。通过 IKTS 架构,我们试图让 AI 拥有“经验”,而不仅仅是“数据”。这种从数据到智慧的升维,正是数字生命进化的必经之路。
目前 AuraMate 已在 Windows 客户端中完整实装了该记忆系统,欢迎下载体验。
📥 资源下载
- 官方下载地址:https://www.auramate.cn
- 开发者社区:https://www.auramate.cn/community
AuraMate Cognitive Team

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)