Denoising Diffusion Probabilistic Models (Diffusion)
本文介绍了去噪扩散概率模型(DDPM)的基本原理。DDPM通过前向扩散和反向去噪两个过程实现图像生成:前向过程逐步添加高斯噪声破坏图像,反向过程则通过神经网络学习逐步去噪。模型利用马尔可夫链性质简化计算,通过变分推断优化目标函数,最小化真实数据分布与生成分布的差异。核心在于使用贝叶斯公式推导理想后验分布,并通过KL散度约束模型学习的反向过程。实验结果表明,DDPM能够有效生成高质量图像,为AI绘画
文章目录
Denoising Diffusion Probabilistic Models(DDPM)
challenge & Background
当下很多图片需要去码去噪,还原本身的图像性质。或者当下AI绘画很火热,许多算法通过输入文字描述,最终便可以得到一张生成图像。
theory
分为前向扩散过程和反向去噪过程两部分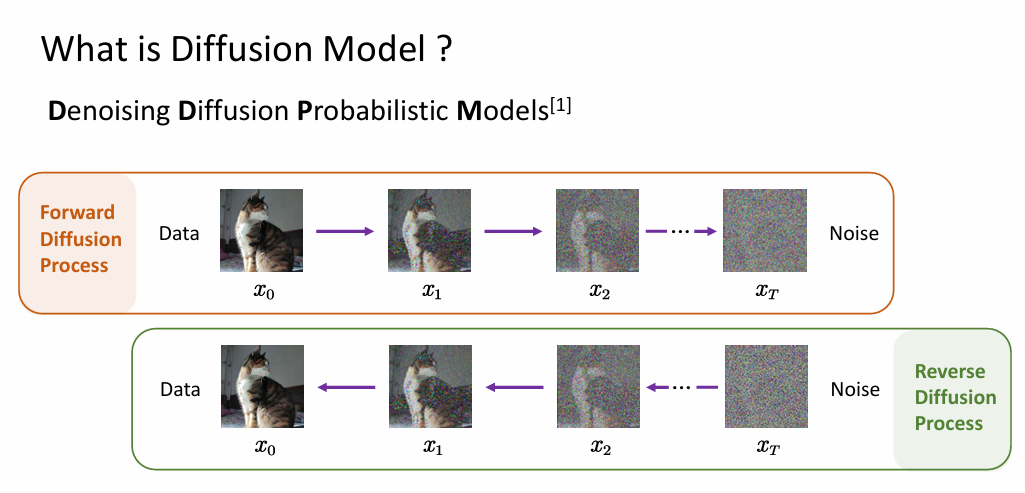
前向扩散过程
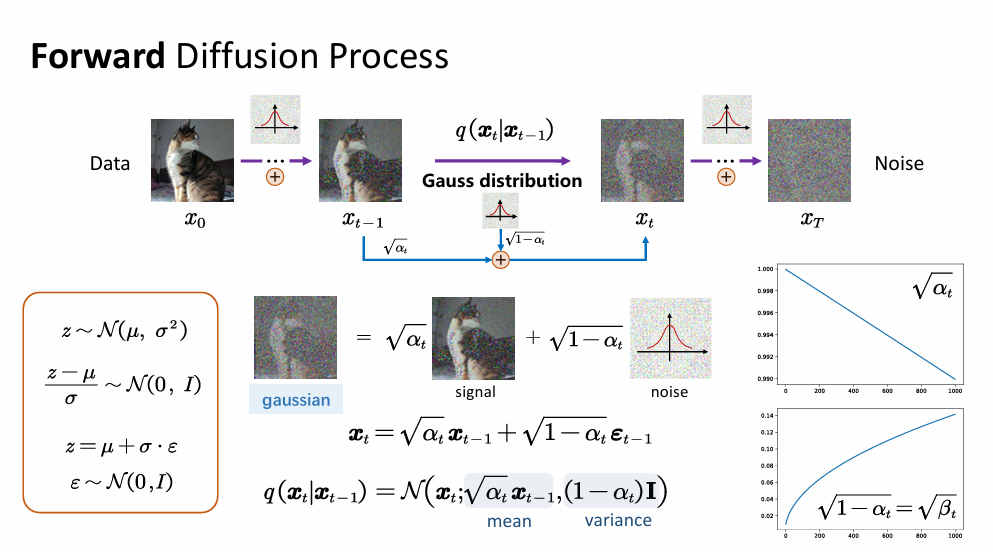
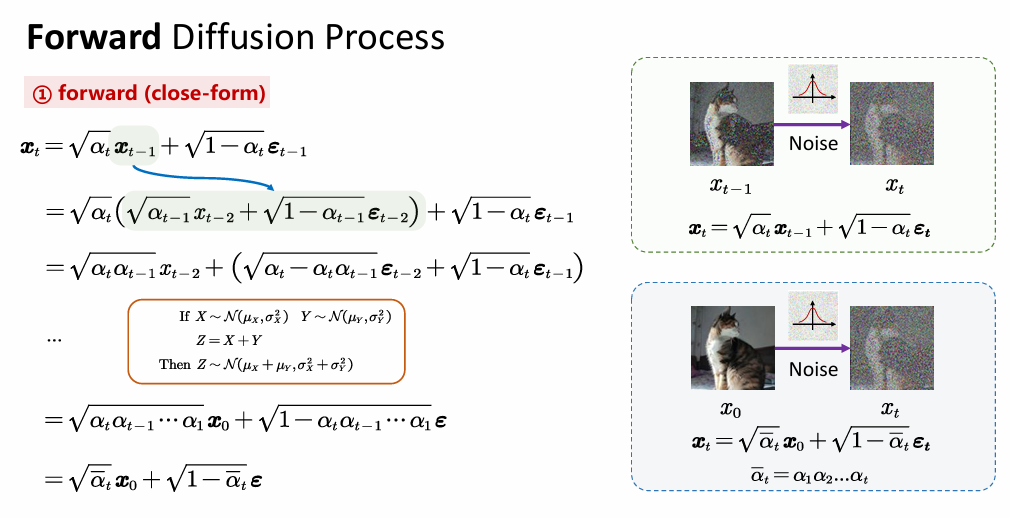
核心公式-加噪: x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon xt=αˉtx0+1−αˉtϵ任一时刻的分布都可以通过 x 0 x_0 x0得到, α t {\alpha}_t αt是噪声,仍服从高斯分布,Diffusion的核心便是利用马尔可夫正向过程一步到位。
马尔可夫链:描述的是一种状态序列,它最显著的特征是:下一时刻的状态只取决于当前状态,而与更早之前的状态无关,在扩散模型中把加噪和去噪的过程看作一条马尔科夫链 x 0 → x 1 → x 2 → . . . → x T x_0 \to x_1 \to x_2 \to ... \to x_T x0→x1→x2→...→xT,当我们想生成 x 2 x_2 x2 时,我们只需要看 x 1 x_1 x1 长什么样。我们不需要知道原始图片 x 0 x_0 x0 是什么。这大大简化了计算。模型只需要学习如何从“现在的状态”推到“前一步的状态”,而不需要背负沉重的历史包袱。
至此正向过程已经得到了,即通过前一时刻得到后一时刻的信息,写作 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1)。真正的目的是为了实现反向过程(去噪),即计算 q ( x 0 ∣ x T ) q(x_0|x_{T}) q(x0∣xT)。反向的过程是复杂的,需要逐步反向向前计算,即计算 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_{t}) q(xt−1∣xt)
优化目标
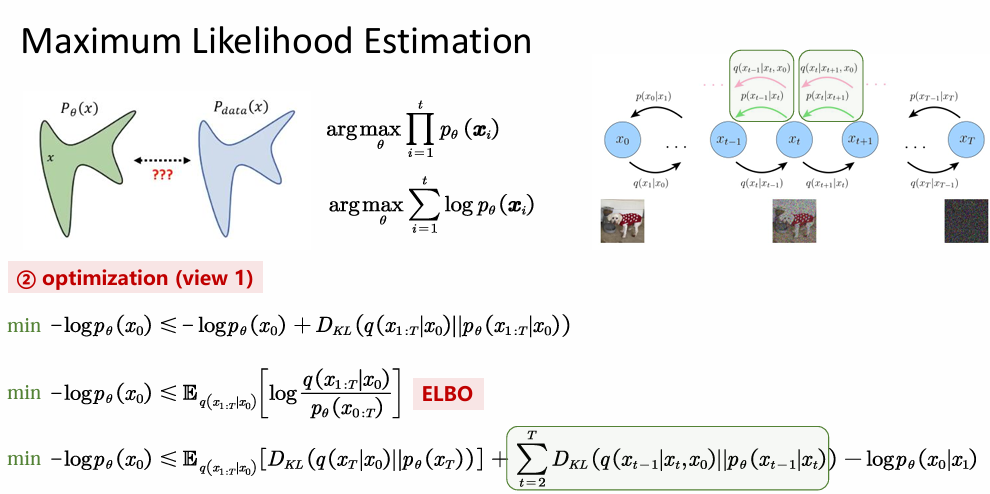
我们的终极目标是最小化负对数似然 − log p θ ( x 0 ) -\log p_\theta(x_0) −logpθ(x0),即让模型生成的分布尽可能接近真实数据分布 p d a t a ( x ) p_{data}(x) pdata(x)。
由于直接计算 p θ ( x 0 ) p_\theta(x_0) pθ(x0) 涉及高维积分不可行因此引入变分推断中的
ELBO(Evidence Lower Bound,证据下界): min − log p θ ( x 0 ) ≤ E q ( x 1 : T ∣ x 0 ) [ log q ( x 1 : T ∣ x 0 ) p θ ( x 0 : T ) ] \min -\log p_\theta(x_0) \le \mathbb{E}_{q(x_{1:T}|x_0)} \left[ \log \frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T})} \right] min−logpθ(x0)≤Eq(x1:T∣x0)[logpθ(x0:T)q(x1:T∣x0)]
通过 KL 散度的展开,ELBO 被拆解为三项:
- D K L ( q ( x T ∣ x 0 ) ∣ ∣ p θ ( x T ) ) D_{KL}(q(x_T|x_0)||p_\theta(x_T)) DKL(q(xT∣x0)∣∣pθ(xT)):先验匹配项。确保前向最后一步得到的噪声服从标准高斯分布。
- ∑ t = 2 T D K L ( q ( x t − 1 ∣ x t , x 0 ) ∣ ∣ p θ ( x t − 1 ∣ x t ) ) \sum_{t=2}^T D_{KL}(q(x_{t-1}|x_t, x_0)||p_\theta(x_{t-1}|x_t)) ∑t=2TDKL(q(xt−1∣xt,x0)∣∣pθ(xt−1∣xt)):这是扩散模型的核心(图中绿色框)。它要求模型学习的反向过程 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt) 尽可能接近由贝叶斯推导出的理想后验分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0)。
- − log p θ ( x 0 ∣ x 1 ) -\log p_\theta(x_0|x_1) −logpθ(x0∣x1):重建项。最后一步从 x 1 x_1 x1 恢复到 x 0 x_0 x0 的质量。
反向去噪过程
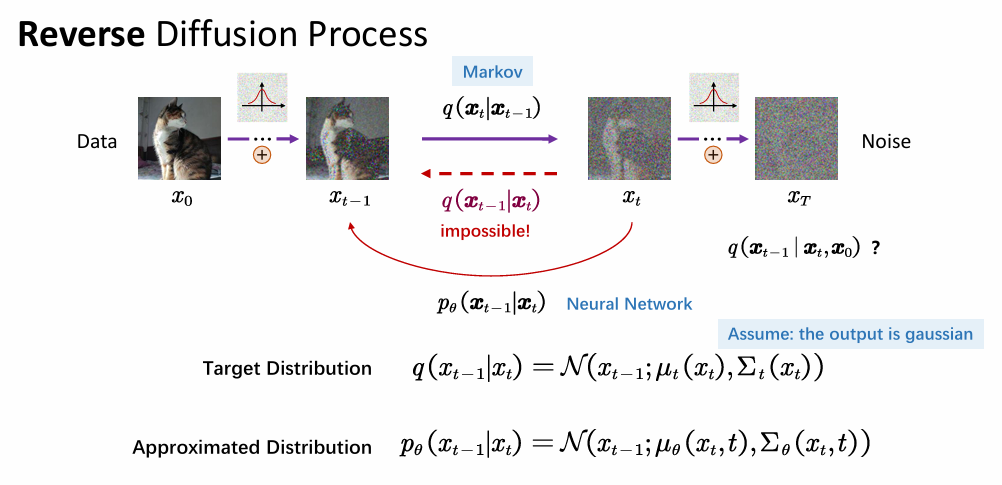


KL 散度是衡量两个概率分布之间差异的标尺,我们需要让模型学习的反向路径 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt) 尽可能地去模仿那个“理想的、利用贝叶斯公式推导出的”反向路径 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0)。可以约束中间每一步去噪的准确性

我们要算的是 q ( x t − 1 ∣ x t ) q(x_{t-1} | x_t) q(xt−1∣xt)。但这个直接算不出来,所以我们引入一个已知条件 x 0 x_0 x0(也就是我们最终想要的清晰图),这个过程我们要用到贝叶斯公式。
贝叶斯公式的核心在于执果索因。它通过“似然”和“先验”来计算“后验”: P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A)
在机器学习的语境下,我们通常将其写作:
- P ( z ∣ x ) P(z|x) P(z∣x) (后验概率):在观测到数据 x x x 的情况下,隐变量 z z z 的概率。
- P ( x ∣ z ) P(x|z) P(x∣z) (似然):给定隐变量 z z z,生成观测数据 x x x 的概率。
- P ( z ) P(z) P(z) (先验概率):在观测到数据之前,对隐变量的预判。
根据贝叶斯公式: q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(x_{t-1} | x_t, x_0) = q(x_t | x_{t-1}, x_0) \frac{q(x_{t-1} | x_0)}{q(x_t | x_0)} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
- q ( x t ∣ x t − 1 , x 0 ) q(x_t | x_{t-1}, x_0) q(xt∣xt−1,x0):这是前向过程的似然估计。
- q ( x t − 1 ∣ x 0 ) q(x_{t-1} | x_0) q(xt−1∣x0) 和 q ( x t ∣ x 0 ) q(x_t | x_0) q(xt∣x0):分别为先验概率和证据。
在扩散模型中,我们已知以下高斯分布(假设 α t = 1 − β t \alpha_t = 1 - \beta_t αt=1−βt 且 α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod_{i=1}^t \alpha_i αˉt=∏i=1tαi):
- 前向单步加噪: q ( x t ∣ x t − 1 ) = N ( x t ; α t x t − 1 , ( 1 − α t ) I ) q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1-\alpha_t)I) q(xt∣xt−1)=N(xt;αtxt−1,(1−αt)I)
- 从 x 0 x_0 x0 步跳到 x t x_t xt: q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)I) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
- 从 x 0 x_0 x0 步跳到 x t − 1 x_{t-1} xt−1: q ( x t − 1 ∣ x 0 ) = N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) q(x_{t-1} | x_0) = \mathcal{N}(x_{t-1}; \sqrt{\bar{\alpha}_{t-1}}x_0, (1-\bar{\alpha}_{t-1})I) q(xt−1∣x0)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)
将这些高斯概率密度函数( ∝ exp ( − ( x − μ ) 2 2 σ 2 ) \propto \exp(-\frac{(x-\mu)^2}{2\sigma^2}) ∝exp(−2σ2(x−μ)2))代入贝叶斯公式,指数部分相加减,会得到一个新的二次型。
具体推导过程如下:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q(x_{t-1}|x_t, x_0) = \frac{q(x_t|x_{t-1}, x_0)q(x_{t-1}|x_0)}{q(x_t|x_0)} q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1,x0)q(xt−1∣x0)
= N ( x t ; α t x t − 1 , ( 1 − α t ) I ) N ( x t − 1 ; α ˉ t − 1 x 0 , ( 1 − α ˉ t − 1 ) I ) N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) = \frac{\mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1 - \alpha_t)\mathbf{I})\mathcal{N}(x_{t-1}; \sqrt{\bar{\alpha}_{t-1}}x_0, (1 - \bar{\alpha}_{t-1})\mathbf{I})}{\mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1 - \bar{\alpha}_t)\mathbf{I})} =N(xt;αˉtx0,(1−αˉt)I)N(xt;αtxt−1,(1−αt)I)N(xt−1;αˉt−1x0,(1−αˉt−1)I)
∝ exp { − 1 2 [ ( x t − α t x t − 1 ) 2 1 − α t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ] } \propto \exp \left\{ -\frac{1}{2} \left[ \frac{(x_t - \sqrt{\alpha_t}x_{t-1})^2}{1 - \alpha_t} + \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}}x_0)^2}{1 - \bar{\alpha}_{t-1}} - \frac{(x_t - \sqrt{\bar{\alpha}_t}x_0)^2}{1 - \bar{\alpha}_t} \right] \right\} ∝exp{−21[1−αt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2]}(带入高斯分布密度函数)
= exp { − 1 2 [ ( x t − α t x t − 1 ) 2 1 − α t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 + C ( x t , x 0 ) ] } = \exp \left\{ -\frac{1}{2} \left[ \frac{(x_t - \sqrt{\alpha_t}x_{t-1})^2}{1 - \alpha_t} + \frac{(x_{t-1} - \sqrt{\bar{\alpha}_{t-1}}x_0)^2}{1 - \bar{\alpha}_{t-1}} + C(x_t, x_0) \right] \right\} =exp{−21[1−αt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2+C(xt,x0)]}(提取指数部分,忽略归一化常数)
∝ exp { − 1 2 [ − 2 α t x t x t − 1 + α t x t − 1 2 1 − α t + x t − 1 2 − 2 α ˉ t − 1 x t − 1 x 0 1 − α ˉ t − 1 + C ′ ( x t , x 0 ) ] } \propto \exp \left\{ -\frac{1}{2} \left[ \frac{-2\sqrt{\alpha_t}x_tx_{t-1} + \alpha_tx_{t-1}^2}{1 - \alpha_t} + \frac{x_{t-1}^2 - 2\sqrt{\bar{\alpha}_{t-1}}x_{t-1}x_0}{1 - \bar{\alpha}_{t-1}} + C'(x_t, x_0) \right] \right\} ∝exp{−21[1−αt−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1xt−1x0+C′(xt,x0)]}
= exp { − 1 2 [ ( α t 1 − α t + 1 1 − α ˉ t − 1 ) x t − 1 2 − 2 ( α t x t 1 − α t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) x t − 1 ] } = \exp \left\{ -\frac{1}{2} \left[ \left( \frac{\alpha_t}{1 - \alpha_t} + \frac{1}{1 - \bar{\alpha}_{t-1}} \right)x_{t-1}^2 - 2\left( \frac{\sqrt{\alpha_t}x_t}{1 - \alpha_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1 - \bar{\alpha}_{t-1}} \right)x_{t-1} \right] \right\} =exp{−21[(1−αtαt+1−αˉt−11)xt−12−2(1−αtαtxt+1−αˉt−1αˉt−1x0)xt−1]}(合并)
= exp { − 1 2 [ α t ( 1 − α ˉ t − 1 ) + 1 − α t ( 1 − α t ) ( 1 − α ˉ t − 1 ) x t − 1 2 − 2 ( α t x t 1 − α t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) x t − 1 ] } = \exp \left\{ -\frac{1}{2} \left[ \frac{\alpha_t(1 - \bar{\alpha}_{t-1}) + 1 - \alpha_t}{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}x_{t-1}^2 - 2\left( \frac{\sqrt{\alpha_t}x_t}{1 - \alpha_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1 - \bar{\alpha}_{t-1}} \right)x_{t-1} \right] \right\} =exp{−21[(1−αt)(1−αˉt−1)αt(1−αˉt−1)+1−αtxt−12−2(1−αtαtxt+1−αˉt−1αˉt−1x0)xt−1]}
= exp { − 1 2 [ α t − α ˉ t + 1 − α t ( 1 − α t ) ( 1 − α ˉ t − 1 ) x t − 1 2 − 2 ( α t x t 1 − α t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) x t − 1 ] } = \exp \left\{ -\frac{1}{2} \left[ \frac{\alpha_t - \bar{\alpha}_t + 1 - \alpha_t}{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}x_{t-1}^2 - 2\left( \frac{\sqrt{\alpha_t}x_t}{1 - \alpha_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1 - \bar{\alpha}_{t-1}} \right)x_{t-1} \right] \right\} =exp{−21[(1−αt)(1−αˉt−1)αt−αˉt+1−αtxt−12−2(1−αtαtxt+1−αˉt−1αˉt−1x0)xt−1]}
= exp { − 1 2 [ 1 − α ˉ t ( 1 − α t ) ( 1 − α ˉ t − 1 ) x t − 1 2 − 2 ( α t x t 1 − α t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) x t − 1 ] } = \exp \left\{ -\frac{1}{2} \left[ \frac{1 - \bar{\alpha}_t}{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}x_{t-1}^2 - 2\left( \frac{\sqrt{\alpha_t}x_t}{1 - \alpha_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1 - \bar{\alpha}_{t-1}} \right)x_{t-1} \right] \right\} =exp{−21[(1−αt)(1−αˉt−1)1−αˉtxt−12−2(1−αtαtxt+1−αˉt−1αˉt−1x0)xt−1]}
= exp { − 1 2 ( 1 − α ˉ t ( 1 − α t ) ( 1 − α ˉ t − 1 ) ) [ x t − 1 2 − 2 ( α t x t 1 − α t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) 1 − α ˉ t ( 1 − α t ) ( 1 − α ˉ t − 1 ) x t − 1 ] } = \exp \left\{ -\frac{1}{2} \left( \frac{1 - \bar{\alpha}_t}{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})} \right) \left[ x_{t-1}^2 - 2 \frac{\left( \frac{\sqrt{\alpha_t}x_t}{1 - \alpha_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1 - \bar{\alpha}_{t-1}} \right)}{\frac{1 - \bar{\alpha}_t}{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}}x_{t-1} \right] \right\} =exp⎩ ⎨ ⎧−21((1−αt)(1−αˉt−1)1−αˉt) xt−12−2(1−αt)(1−αˉt−1)1−αˉt(1−αtαtxt+1−αˉt−1αˉt−1x0)xt−1 ⎭ ⎬ ⎫
= exp { − 1 2 ( 1 ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t ) [ x t − 1 2 − 2 α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x 0 1 − α ˉ t x t − 1 ] } = \exp \left\{ -\frac{1}{2} \left( \frac{1}{\frac{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t}} \right) \left[ x_{t-1}^2 - 2 \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})x_t + \sqrt{\bar{\alpha}_{t-1}}(1 - \alpha_t)x_0}{1 - \bar{\alpha}_t}x_{t-1} \right] \right\} =exp{−21(1−αˉt(1−αt)(1−αˉt−1)1)[xt−12−21−αˉtαt(1−αˉt−1)xt+αˉt−1(1−αt)x0xt−1]}
∝ N ( x t − 1 ; α t ( 1 − α ˉ t − 1 ) x t + α ˉ t − 1 ( 1 − α t ) x 0 1 − α ˉ t ⏟ μ q ( x t , x 0 ) , ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t ⏟ Σ q ( t ) I ) \propto \mathcal{N}\left(x_{t-1}; \underbrace{\frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})x_t + \sqrt{\bar{\alpha}_{t-1}}(1 - \alpha_t)x_0}{1 - \bar{\alpha}_t}}_{\mu_q(x_t, x_0)}, \underbrace{\frac{(1 - \alpha_t)(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t}}_{\Sigma_q(t)}\mathbf{I}\right) ∝N xt−1;μq(xt,x0) 1−αˉtαt(1−αˉt−1)xt+αˉt−1(1−αt)x0,Σq(t) 1−αˉt(1−αt)(1−αˉt−1)I
在数学上,两个正态分布相乘,其指数部分(均值和方差)会发生融合。经过一通化简计算,我们会得到 x t − 1 x_{t-1} xt−1 的后验均值 μ ~ t \tilde{\mu}_t μ~t: μ ~ t ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 ( 1 − α t ) 1 − α ˉ t x 0 \tilde{\mu}_t(x_t, x_0) = \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t} x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}(1-\alpha_t)}{1-\bar{\alpha}_t} x_0 μ~t(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1(1−αt)x0,后验方差 β ~ t = ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t ⋅ β t \tilde{\beta}_t = \frac{(1-{\alpha}_t)(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t} \cdot \beta_t β~t=1−αˉt(1−αt)(1−αˉt−1)⋅βt
下面我们继续化简均值,由于 x t = α ˉ t x 0 + 1 − α ˉ t ϵ x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1 - \bar{\alpha}_t}\epsilon xt=αˉtx0+1−αˉtϵ,反解出 x 0 = 1 α ˉ t ( x t − 1 − α ˉ t ϵ ) x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(x_t - \sqrt{1 - \bar{\alpha}_t}\epsilon) x0=αˉt1(xt−1−αˉtϵ),
带入原式得 μ ~ t = 1 α t ( x t − β t 1 − α ˉ t ϵ ) \tilde{\mu}_t = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon \right) μ~t=αt1(xt−1−αˉtβtϵ)至此,均值和方差就都有了
Algorithm (traing and sampling)

在training的过程中,我们只需要去预测噪声,就能在数学上使得模型学到的分布和真实的图片分布不断逼近。而当我们使用模型做sampling,即去测试模型能生成什么质量的图片时,由上面得推导结论我们从 x t x_t xt推导 x t − 1 x_{t-1} xt−1直到还原出 x 0 x_0 x0。
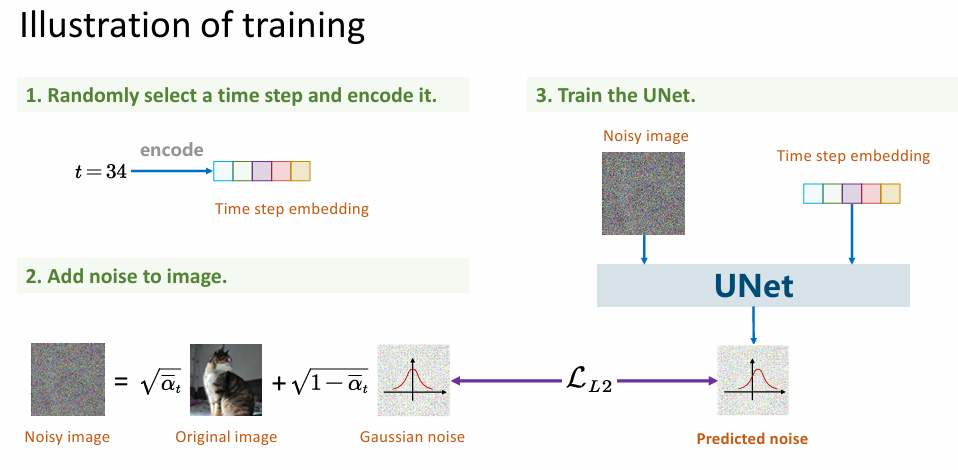
训练过程我们先随机选一个时间步进行编码,再给原始图像加噪,最后用UNet训练(输入时间步和噪声图,来预测一个噪声)我们希望这个噪声与我们最初加噪的噪声相近,对这两个噪声做L2的loss
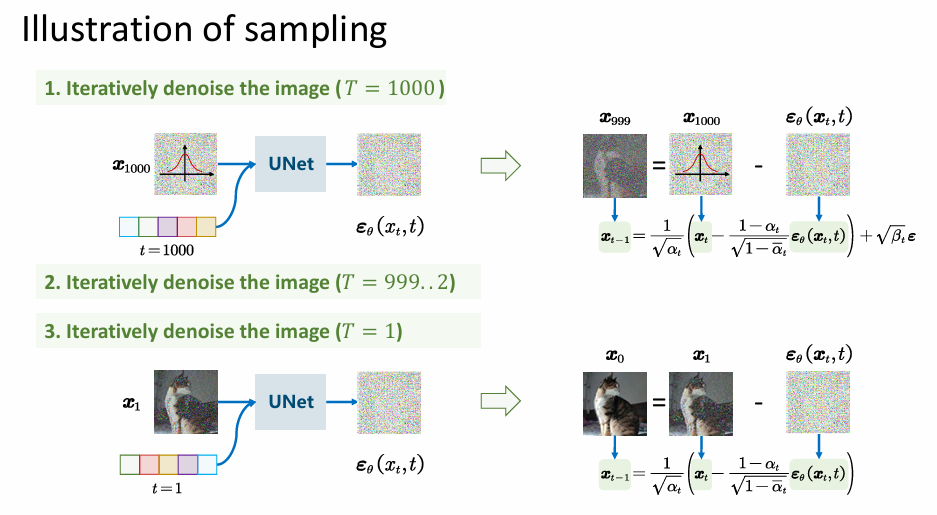
这是一个逐步的去噪过程,把噪声和时间步输入到UNet后输出预测的噪声图,使用这个噪声与原图进行相减,中间有999次这个过程,到T=1时,输入 x 1 x_1 x1的图和时间步给UNet预测噪声,最后将这个噪声与原始图片的相减处理即可
关于扰动项 σ t z \sigma_t z σtz:如果没有这个随机扰动,生成过程将变成确定性的 ODE(常微分方程),虽然能出图,但样本的多样性和分布覆盖能力(Recall)会下降。扰动项确保了模型能探索数据生成空间的不同分支
参考
-
Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. NeuraIPS, 2020.
-
Luo C. Understanding diffusion models: A unified perspective. arXiv, 2022

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)