生成式 AI 全景图:从基础到进阶的全链路能力生态
摘要:本文提出生成式AI学习的"全景图"框架,打破碎片化学习困境。该框架包含七大核心模块:1)AI/ML基础理论;2)NLP核心技术;3)Transformer架构;4)模型优化方法;5)RAG与编排系统;6)智能体与多模态前沿;7)评估与治理体系。文章强调生成式AI的本质是生态协同,各模块相互支撑构成完整能力栈。通过系统化学习路径,帮助开发者从"工具使用者"
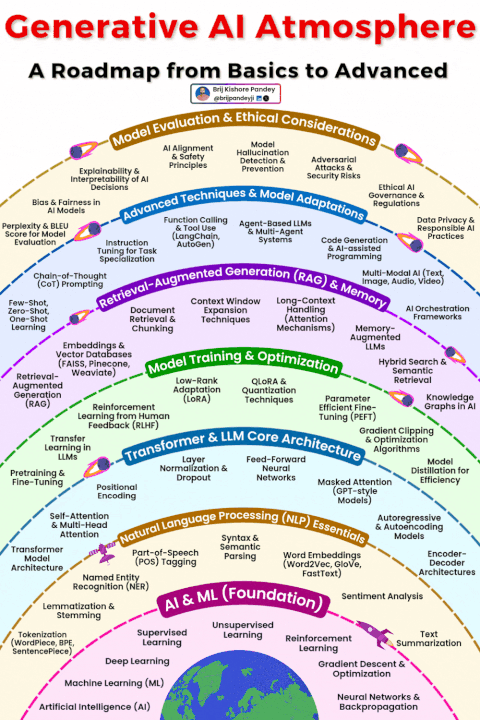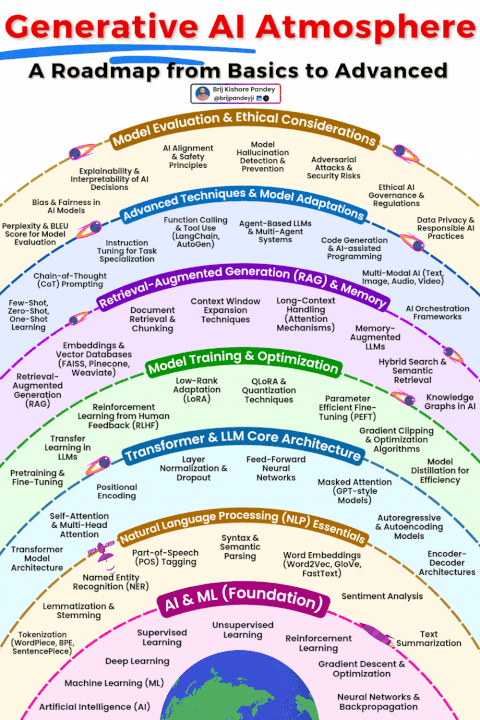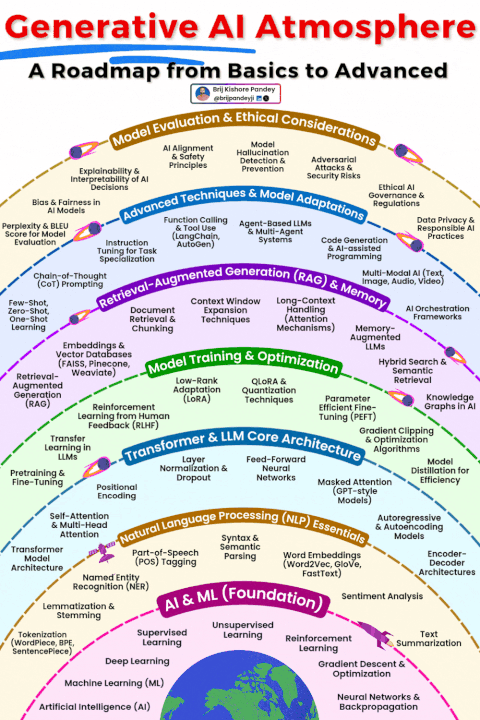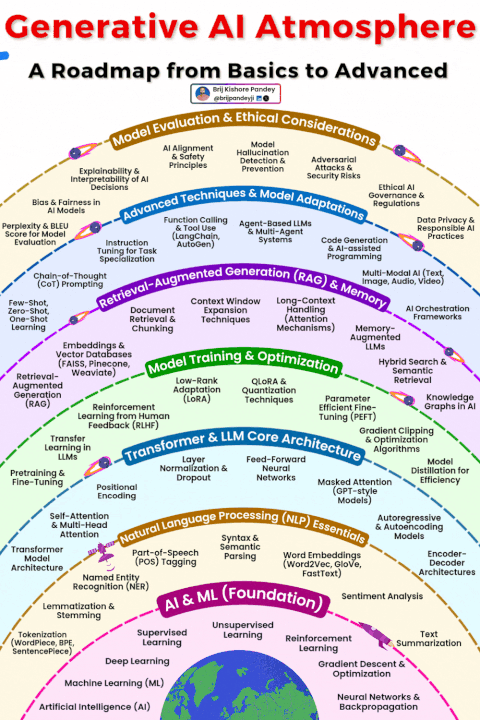
在生成式 AI(GenAI)的学习浪潮中,多数人陷入了 “碎片化困境”:今天跟风学 Prompt 工程,明天尝试 RAG 搭建,后天又钻研智能体框架,却始终无法将这些零散的技术点串联成可落地的系统。真正的 mastery 从来不是 “掌握多少工具”,而是看清生成式 AI 的完整生态 —— 它是一个从基础理论、核心架构到工程落地、前沿应用的有机整体,每个环节都相互支撑,缺一不可。
这份 “生成式 AI 全景图”(Generative AI Atmosphere),正是为了打破碎片化学习的壁垒,将 AI&ML 基础、NLP 核心、Transformer 架构、模型优化、RAG 与编排、智能体与多模态、评估与治理七大核心模块串联成完整路径。本文将深入拆解这个生态系统的每一层,揭示各模块的内在关联,帮你构建从 “工具使用者” 到 “系统构建者” 的全栈认知。
一、地基:AI 与机器学习基础 —— 智能的起点
生成式 AI 并非空中楼阁,其底层逻辑深深扎根于 AI 与机器学习(ML)的基础理论。跳过这一层直接学习模型和工具,就像没有地基的建筑,看似高大却不堪一击。这一层的核心价值,是让我们理解 “智能如何产生”,而非仅知道 “智能能做什么”。
核心内容
- 传统机器学习算法:掌握监督学习(分类、回归)、无监督学习(聚类、降维)的核心逻辑,理解数据特征、过拟合、偏差 - 方差权衡等基础概念 —— 这些是判断模型效果、优化数据处理的关键。常用工具包括 scikit-learn,通过实践 “电商销量预测”“用户分群” 等项目,建立 “数据→模型→预测” 的思维框架。
- 深度学习基础:理解神经网络的基本结构(输入层、隐藏层、输出层)、激活函数(ReLU、Sigmoid)、反向传播与梯度下降的优化逻辑。掌握 TensorFlow/PyTorch 等框架的基础使用,能独立搭建简单的神经网络,为后续理解 Transformer 架构打下基础。
- 数据工程能力:学会用 NumPy、Pandas 处理数据,用 Matplotlib/Seaborn 可视化分析,理解数据清洗、特征工程的核心方法 —— 生成式 AI 的效果上限,永远由数据质量决定,这一层正是培养 “数据思维” 的关键。
为什么重要?
当你遇到 “大模型生成结果偏差”“RAG 检索准确率低” 等问题时,底层基础能帮你快速定位根源:是数据特征提取不足?还是模型优化方向错误?而非只能停留在 “调整 Prompt”“更换工具” 的表面尝试。
二、桥梁:NLP 核心知识 —— 机器理解语言的钥匙
生成式 AI 的核心场景(文本生成、对话交互、知识问答)都离不开自然语言处理(NLP)。这一层是连接 “通用 AI 基础” 与 “生成式 AI 专属能力” 的桥梁,让我们理解 “机器如何读懂人类语言”,为后续掌握 LLM 架构铺路。
核心内容
- 语言的数学表示:理解词嵌入(Word2Vec、GloVe、BERT Embedding)的原理 —— 将文本转化为计算机可理解的高维向量,是所有 NLP 任务的基础。掌握词袋模型、TF-IDF 等传统文本表示方法,理解其局限性,才能更深刻体会 BERT 等预训练模型的突破。
- 句法与语义分析:了解分词、词性标注、句法树、命名实体识别(NER)、语义角色标注等核心技术 —— 这些是机器 “拆解语言结构” 的关键,比如 LLM 能生成连贯文本,本质是对句法规则和语义关联的深度学习。
- NLP 经典任务:实践文本分类、情感分析、机器翻译、问答系统等基础任务,理解 “输入→模型→输出” 的 NLP 工作流 —— 生成式 AI 本质是 NLP 任务的 “进阶形态”,从 “分析文本” 升级为 “生成文本”。
关键价值
NLP 核心知识能帮你理解 LLM 的 “能力边界”:为什么 LLM 能处理多轮对话?因为它掌握了语义关联;为什么 LLM 会出现 “语法错误”?可能是对复杂句法结构的学习不足。这些认知,是优化生成效果、设计合理应用场景的前提。
三、引擎:Transformer 与 LLM 架构 —— 生成式 AI 的核心动力
如果说 AI&ML 基础是地基、NLP 是桥梁,那么 Transformer 架构就是生成式 AI 的 “发动机”。自 2017 年 Google 提出 Transformer 以来,它彻底改变了 NLP 领域,成为所有主流 LLM(GPT、Claude、Llama)的核心架构。理解这一层,才能从 “调用模型” 升级为 “理解模型”。
核心内容
- Transformer 核心原理:聚焦自注意力机制(Self-Attention)—— 这是 Transformer 的灵魂,能让模型在处理文本时,同时关注上下文的所有词,捕捉长距离依赖关系。无需深入推导数学公式,但要理解 “Query、Key、Value” 的交互逻辑,以及 “多头注意力” 如何提升模型的语义捕捉能力。
- Encoder-Decoder 与衍生架构:理解 Transformer 的完整结构(编码器负责理解输入,解码器负责生成输出),以及三大衍生架构的差异:
- 编码器 - only(BERT、RoBERTa):擅长理解任务(文本分类、嵌入生成);
- 解码器 - only(GPT、Llama):擅长生成任务(文本续写、对话);
- 编码器 - 解码器(T5、BART):擅长文本转换任务(翻译、摘要)。
- LLM 的训练与 scaling:了解预训练(在海量文本上学习语言规律)、微调(适配特定领域)的流程,理解模型参数规模(百亿、千亿级)与能力的关系 —— 并非参数越大越好,但足够的规模是复杂推理能力的基础。
关键价值
掌握 Transformer 架构,能让你做出更合理的技术选型:比如做企业知识库问答,选择编码器 - only 模型生成嵌入(BERT)+ 解码器 - only 模型生成回答(GPT)的组合;做文本摘要,选择编码器 - 解码器模型(T5)。这比盲目跟风 “最新模型” 更能解决实际问题。
四、优化:模型训练与效率提升 —— 让智能更可靠、更高效
训练一个基础 LLM 需要海量算力和数据,多数开发者无需从零训练,但掌握 “模型优化” 技术,能让通用模型适配特定场景,同时提升运行效率、降低成本 —— 这是生成式 AI 落地的核心工程能力。
核心内容
- 高效微调技术:掌握参数高效微调(PEFT)、LoRA(低秩适配)、QLoRA 等核心方法 —— 无需训练模型全部参数,仅微调少量参数就能让模型适配金融、医疗等垂直领域,大幅降低算力成本。
- 模型量化与压缩:了解 INT8、INT4 量化技术,通过减少模型参数的精度,降低显存占用和推理延迟 —— 比如将 Llama 2 70B 模型量化为 INT4 后,可在单张 GPU 上运行,满足边缘部署需求。
- 推理效率优化:掌握动态批处理(vLLM)、投机解码(Speculative Decoding)等技术,提升模型推理速度 —— 比如 vLLM 能将大模型推理吞吐量提升 10 倍以上,支撑高并发场景(如智能客服)。
- 训练数据优化:学习数据清洗、去重、过滤的方法,理解 “数据质量比数量更重要”—— 优质的领域数据能让微调效果翻倍,而噪声数据只会让模型性能下降。
关键价值
模型优化是生成式 AI 从 “实验室” 走向 “生产环境” 的关键:比如某医疗企业用 LoRA 微调 Llama 2,仅用 500MB 医疗数据就让模型的专业问答准确率提升 40%;某电商平台用 vLLM 优化推理,将智能推荐的延迟从 500ms 降至 100ms。
五、连接:RAG、记忆与编排 —— 让 AI 对接现实世界
LLM 的核心局限是 “幻觉” 和 “知识过时”,而 RAG(检索增强生成)、记忆模块与编排框架,正是解决这些问题的关键 —— 它们让 AI 能对接外部知识库、保留上下文、协同工具,实现 “现实世界的智能”。
核心内容
- RAG 全流程:掌握 “数据加载→分块→向量化→存储→检索→生成” 的完整链路,理解向量数据库(Pinecone、Chroma)的作用,以及混合检索(向量检索 + 关键词检索)、重排等优化技巧 ——RAG 能将 LLM 的幻觉率降低 40% 以上,是企业级应用的必备方案。
- 记忆模块设计:区分短期记忆(当前对话上下文)和长期记忆(用户偏好、历史交互),掌握记忆的存储、检索、过期规则 —— 比如智能客服通过长期记忆记住用户的历史订单,提供个性化服务。
- 编排框架应用:熟练使用 LangChain、LlamaIndex 等框架,实现模型、工具、RAG 的协同 —— 比如通过 LangChain 将 LLM 与数据库、API、RAG 引擎串联,搭建 “查询订单→调用支付接口→生成报销报告” 的自动化工作流。
关键价值
这一层让 AI 从 “封闭的模型” 变成 “开放的系统”:比如企业搭建智能知识库,通过 RAG 对接最新的产品文档,让 AI 始终提供准确信息;智能体通过记忆和编排,自主完成多步骤任务,无需人工介入。
六、前沿:智能体、多模态与进阶技术 —— 迈向自主智能
生成式 AI 的未来方向,是从 “被动生成” 走向 “主动自主”,从 “单一文本” 走向 “多模态融合”。这一层是技术的前沿阵地,也是构建高价值应用的核心竞争力。
核心内容
- AI 智能体(Agent):掌握智能体的核心能力 —— 任务规划(拆解复杂任务)、工具调用(对接 API、浏览器、数据库)、记忆管理(短期 + 长期)、反馈迭代(自主优化行为)。熟悉 LangGraph、CrewAI 等框架,理解多智能体协同(如 “研究员 + 分析师 + 撰稿人” 分工协作)的逻辑。
- 多模态生成:了解文本、图像、音频、视频的融合技术,掌握 Diffusion 模型(图像生成)、CLIP(图文对齐)、LLaVA(多模态对话)等核心工具 —— 比如用 Midjourney 生成产品图,用 GPT-4o 实现图文问答,用 Runway 生成视频。
- 进阶技术探索:关注强化学习(RLHF,基于人类反馈的强化学习)、AI 对齐(让模型符合人类价值观)、边缘 AI(在边缘设备部署生成式模型)等前沿方向 —— 这些技术将定义下一代生成式 AI 的能力边界。
关键价值
前沿技术能让你构建 “高壁垒应用”:比如某科研团队用多智能体协同完成 “文献检索→数据处理→论文生成” 的全流程,效率提升 60%;某教育企业用多模态模型搭建 “图文结合的智能辅导系统”,大幅提升学习体验。
七、保障:评估、安全与治理 —— 构建负责任的 AI
生成式 AI 的落地,不能只追求效果,还要确保 “可靠、安全、合规”。这一层是 AI 应用的 “安全网”,也是企业信任的基础 —— 没有评估,就无法优化;没有安全,就无法上线;没有治理,就无法持续。
核心内容
- 评估体系构建:掌握生成式 AI 的核心评估指标 —— 幻觉率(事实准确性)、相关性(与需求匹配度)、流畅度(语言自然度)、延迟、成本。使用 TruLens、Ragas 等工具,建立自动化评估流程,避免 “主观判断” 的偏差。
- 安全护栏搭建:实现输入过滤(防止恶意 Prompt)、输出审核(避免违规内容)、权限控制(限制工具调用范围)。比如用 LlamaGuard 过滤有害内容,用 API 密钥管理限制模型访问权限,防止数据泄露。
- 合规与治理:了解 GDPR、数据安全法等法规要求,规范数据收集、模型训练、应用部署的全流程。建立模型日志记录、审计机制,确保 AI 的决策可追溯 —— 比如金融 AI 的贷款审批,必须记录每一步的推理过程,满足合规要求。
关键价值
评估、安全与治理是生成式 AI “长治久安” 的保障:比如某金融机构通过严格的安全护栏和合规审计,让生成式 AI 客服上线后零数据泄露、零违规输出;某企业用自动化评估工具,每周监控模型效果,及时发现并解决 “幻觉率上升” 的问题。
结语:生成式 AI 的本质是生态协同
生成式 AI 从来不是 “单一模型” 或 “某个工具” 的胜利,而是整个能力生态的协同结果:AI&ML 基础提供理论支撑,NLP 搭建语言理解桥梁,Transformer 架构提供核心动力,模型优化提升效率,RAG 与编排对接现实世界,智能体与多模态拓展能力边界,评估与治理保障安全合规。
学习生成式 AI,最忌讳 “只见树木,不见森林”。按照这份全景图,先夯实基础,再逐步深入各模块,最后串联成系统,才能真正从 “碎片化学习” 走向 “全栈掌握”。
最后,回到最初的问题:这份生成式 AI 生态中,是否遗漏了重要的模块?或许是 “低代码工具链”(降低开发门槛),或许是 “行业解决方案”(垂直领域的落地实践),又或许是 “人机协同”(AI 与人类的高效配合模式)。但无论如何,核心逻辑不变 —— 生成式 AI 的价值,永远藏在 “生态协同” 之中。
如果你正在搭建生成式 AI 应用,不妨对照这份全景图,检查自己的能力短板:是基础不牢?还是工程化能力不足?或是前沿技术储备不够?补齐这些短板,才能构建出真正有价值、可落地的生成式 AI 系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)