基于 Vue 3 + Spring Boot 3 的 AI 面试辅助系统:实时语音识别 + 大模型智能回答
摘要 本文介绍了一个基于Vue 3和Spring Boot 3的AI面试辅助系统,该系统具有以下核心功能: 实时语音识别:通过浏览器录音和Whisper API实现语音转文字,支持静音检测自动停止 智能回答生成:结合简历、公司信息和岗位JD,利用大模型(GPT-4o-mini/DeepSeek-V3/Groq Llama 3)生成个性化回答 多模态输入:支持语音识别和屏幕截图OCR两种方式获取面试
基于 Vue 3 + Spring Boot 3 的 AI 面试辅助系统:实时语音识别 + 大模型智能回答
前言
面试是求职过程中最关键也是最令人紧张的环节。你是否有过这样的经历——面试官抛出一个问题,你明明有相关经验,却一时组织不好语言?
本文介绍一个我开发的 AI 面试辅助系统,它能在面试过程中实时捕获面试官的问题(语音识别 / 屏幕截图 OCR),结合你的简历和目标公司信息,利用 AI 大模型秒级生成高质量的回答建议,并以流式打字机效果展示。整个过程对面试官完全无感知。
技术栈:Vue 3 + TypeScript + Element Plus + Spring Boot 3 + Spring Security + JPA + MySQL + OpenAI / DeepSeek / Groq
一、项目亮点
| 特性 | 说明 |
|---|---|
| 🎙️ 实时语音识别 | 浏览器录音 → Whisper API 转文字,支持自动 VAD 静音检测 |
| 🤖 AI 智能回答 | 基于简历 + 公司 + 岗位 JD 的个性化 Prompt,SSE 流式输出 |
| 📸 屏幕截图识别 | 共享屏幕 → 截图 → 视觉模型(Llama 4 Scout)提取题目文字 |
| 📄 简历管理 | PDF 上传 + Apache PDFBox 自动解析内容 |
| 🏢 公司/知识库管理 | 保存目标公司背景信息,给 AI 更多上下文 |
| 📝 面试记录 | 完整问答历史,支持回顾与反馈 |
| 🔐 JWT 认证 | Spring Security + JWT 令牌,完整的用户体系 |
| ⚡ 多模型支持 | 自由切换 GPT-4o-mini / DeepSeek-V3 / Groq Llama 3(免费) |
二、系统架构
┌────────────────────────────────────────────────────┐
│ 客户端(浏览器) │
│ Vue 3 + Element Plus + Pinia + Web Audio API │
└──────────────────────┬─────────────────────────────┘
│ HTTP / SSE
▼
┌────────────────────────────────────────────────────┐
│ Spring Boot 后端 │
│ Controller → Service → Repository → MySQL │
│ │ │
│ ┌─────────┴──────────┐ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ AI 服务 │ │ ASR 服务 │ │
│ │ GPT/DeepSeek │ │ Whisper │ │
│ │ /Groq Llama │ │ /Groq │ │
│ └──────────────┘ └──────────────┘ │
└────────────────────────────────────────────────────┘
核心数据流:
- 用户点击"开始录音" → 浏览器
MediaRecorder+Web Audio API录制音频 - VAD 自动检测静音 → 自动停止录音 → 上传音频到后端
- 后端调用 Whisper API 语音转文字 → 返回识别结果
- 前端自动触发 AI 回答 → 后端构建 Prompt(简历 + 公司 + 问题)
- 后端调用 AI 模型 → SSE 流式推送回答 → 前端打字机效果展示
三、技术栈详解
3.1 前端
| 技术 | 版本 | 用途 |
|---|---|---|
| Vue 3 | 3.4+ | Composition API + <script setup> |
| TypeScript | 5.x | 全量类型安全 |
| Vite | 5.x | 极速 HMR 开发体验 |
| Element Plus | 2.x | UI 组件库 |
| Pinia | 2.x | 状态管理 |
| Axios | 1.x | HTTP 请求封装 |
3.2 后端
| 技术 | 版本 | 用途 |
|---|---|---|
| Spring Boot | 3.2 | 后端框架(Java 17) |
| Spring Security | 6.x | JWT 无状态认证 |
| Spring Data JPA | 3.x | ORM 数据访问 |
| MySQL | 8.0+ | 关系型数据库 |
| OkHttp + SSE | 4.x | 调用 AI/ASR 外部 API |
| Apache PDFBox | 3.x | PDF 简历内容解析 |
| JJWT | 0.12+ | JWT Token 生成与验证 |
3.3 AI & ASR 服务
| 服务 | 提供商 | 特点 |
|---|---|---|
| AI 对话 | OpenAI GPT-4o-mini | 推荐,性价比高 |
| AI 对话 | DeepSeek-V3 | 中文能力强 |
| AI 对话 | Groq Llama 3.3 70B | 免费,延迟极低 |
| 语音识别 | OpenAI Whisper | 精度高 |
| 语音识别 | Groq Whisper | 免费,速度快 |
| 视觉识别 | Groq Llama 4 Scout | 截图 OCR 提取题目 |
四、核心功能实现
4.1 语音录制与 VAD 静音检测
前端使用 Vue 3 Composable 封装了 useAudioRecorder,核心特性:
- Web Audio API 获取实时音频数据
- 频域分析(
AnalyserNode)计算平均音量 - 智能 VAD 逻辑:连续 5 次采样(500ms)高于阈值 → 确认说话开始;静音持续 2.5 秒 → 自动停止
- 噪音过滤:说话时长低于 1 秒自动丢弃
// 核心 VAD 检测逻辑
if (!hasSpeechStarted.value) {
if (average > speechThreshold) {
speechConfirmCounter++
if (speechConfirmCounter >= SPEECH_CONFIRM_NEEDED) {
hasSpeechStarted.value = true // 确认开始说话
}
}
}
if (hasSpeechStarted.value && average < silenceThreshold) {
if (Date.now() - silenceStart > silenceDuration) {
autoStop() // 静音超时,自动停止
}
}
4.2 SSE 流式 AI 回答
后端使用 Spring 的 SseEmitter + OkHttp 读取 AI API 的流式响应,实时推送给前端:
// 后端 SSE 流式推送
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(response.body().byteStream()))) {
String line;
while ((line = reader.readLine()) != null) {
if (line.startsWith("data: ")) {
String data = line.substring(6).trim();
if ("[DONE]".equals(data)) break;
JsonNode chunk = objectMapper.readTree(data);
String content = chunk.path("choices").path(0)
.path("delta").path("content").asText("");
if (!content.isEmpty()) {
// 实时推送每个 token 到前端
emitter.send(SseEmitter.event()
.data("{\"type\":\"content\",\"text\":\"" + content + "\"}"));
}
}
}
}
前端使用 fetch + ReadableStream 实现 SSE 接收:
// 前端 SSE 接收
const reader = response.body?.getReader()
const decoder = new TextDecoder()
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
for (const line of lines) {
if (line.startsWith('data:')) {
const event = JSON.parse(line.slice(5))
if (event.type === 'content') {
content.value += event.text // 打字机效果
}
}
}
}
4.3 屏幕截图识别(OCR)
除了语音,系统还支持屏幕共享截图识别面试题目:
- 使用
getDisplayMediaAPI 共享屏幕 - 利用 Canvas 截取当前画面
- 将图片发送到后端 → 调用 Llama 4 Scout 视觉模型提取文字
async function takeScreenshot(): Promise<Blob | null> {
const canvas = document.createElement('canvas')
canvas.width = video.videoWidth
canvas.height = video.videoHeight
const ctx = canvas.getContext('2d')
ctx.drawImage(video, 0, 0)
return new Promise(resolve => canvas.toBlob(resolve, 'image/png'))
}
4.4 AI Prompt 工程
系统的核心在于精心设计的 Prompt,结合用户简历、公司信息、岗位描述生成个性化回答:
## System Prompt
你是一位专业的面试辅助助手。
要求:
1. 回答自然流畅,像真人回答,不要有AI痕迹
2. 紧密结合候选人的实际经历和技能
3. 针对目标公司和岗位特点突出相关优势
4. 使用 STAR 法则组织行为面试类回答
5. 技术问题要专业准确,适当展示深度
6. 回答长度控制在 200-500 字
7. 使用第一人称回答
## User Prompt
候选人简历:{resumeContent}
公司背景信息:{companyInfo}
面试岗位:{jobTitle}
面试官的问题:{question}
五、数据库设计
系统包含 5 张核心表:
┌──────────┐ 1:N ┌──────────┐
│ users │──────────→│ resumes │
│ │ 1:N ┌───────────┐
│ │──────────→│ companies │
│ │ 1:N ┌────────────────────┐ 1:N ┌──────────────────────┐
│ │──────────→│ interview_sessions │──────────→│ interview_questions │
└──────────┘ └────────────────────┘ └──────────────────────┘
关键设计决策:
| 设计点 | 说明 |
|---|---|
parsed_content 存 DB |
避免每次 AI 调用重新解析 PDF |
job_title + job_description |
让 AI 回答更有针对性 |
response_time_ms |
监控 AI 响应性能 |
user_feedback |
收集用户反馈,优化 Prompt |
外键 ON DELETE SET NULL |
删除简历/公司后面试记录不丢失 |
六、项目结构
├── frontend/ # Vue 3 前端
│ └── src/
│ ├── pages/ # 8 个页面组件
│ │ ├── Login.vue # 登录
│ │ ├── Register.vue # 注册
│ │ ├── Dashboard.vue # 工作台
│ │ ├── InterviewMode.vue# 面试模式(核心)
│ │ ├── ResumeManagement.vue
│ │ ├── CompanyManagement.vue
│ │ ├── InterviewHistory.vue
│ │ └── KnowledgeBase.vue
│ ├── composables/ # 组合式函数
│ │ ├── useAudioRecorder.ts # 录音 + VAD
│ │ ├── useScreenCapture.ts # 屏幕截图
│ │ └── useSSE.ts # SSE 流式
│ ├── services/ # API 调用
│ ├── stores/ # Pinia 状态管理
│ └── types/ # TypeScript 类型
│
├── backend/ # Spring Boot 后端
│ └── src/main/java/com/aiinterview/
│ ├── controller/ # REST 控制器(5个)
│ ├── service/ # 业务逻辑(9个)
│ │ ├── AIService.java # AI 模型调用
│ │ ├── ASRService.java # 语音识别
│ │ └── PDFParserService.java
│ ├── entity/ # JPA 实体(6个)
│ ├── repository/ # 数据访问(6个)
│ ├── dto/ # 数据传输对象
│ ├── config/ # Security + CORS
│ └── exception/ # 全局异常处理
│
└── docs/ # 开发文档
七、快速启动
7.1 环境要求
- Node.js 18+
- JDK 17+
- Maven 3.9+
- MySQL 8.0+
7.2 数据库初始化
mysql -u root -p -e "CREATE DATABASE ai_interview DEFAULT CHARSET utf8mb4;"
7.3 启动后端
cd backend
# 配置环境变量(至少配一个 AI 服务的 API Key)
export GROQ_API_KEY=your_groq_key # 推荐,免费
# export OPENAI_API_KEY=sk-xxx
# export DEEPSEEK_API_KEY=xxx
mvn spring-boot:run
# 服务运行在 http://localhost:8080
7.4 启动前端
cd frontend
npm install
npm run dev
# 访问 http://localhost:5173
八、核心 API 设计
8.1 统一响应格式
{
"code": 0,
"message": "success",
"data": { },
"timestamp": 1707206400000
}
8.2 主要接口
| 方法 | 路径 | 说明 |
|---|---|---|
| POST | /api/v1/auth/register |
用户注册 |
| POST | /api/v1/auth/login |
用户登录 |
| POST | /api/v1/resumes/upload |
上传简历(PDF) |
| POST | /api/v1/interviews/sessions |
创建面试会话 |
| POST | /api/v1/interviews/transcribe |
语音转文字 |
| POST | /api/v1/interviews/ask/stream |
AI 流式回答(SSE) |
| POST | /api/v1/interviews/analyze-screenshot |
截图识别 |
8.3 SSE 流式响应示例
data: {"type":"start","questionId":1}
data: {"type":"content","text":"面试官"}
data: {"type":"content","text":"您好,"}
data: {"type":"content","text":"我叫张三"}
...
data: {"type":"done","responseTimeMs":1200}
九、面试模式界面设计
面试模式是系统的核心页面,采用左右分栏布局:
┌───────────────────┐ ┌──────────────────────────┐
│ 左侧:面试控制 │ │ 右侧:AI 回答展示 │
│ │ │ │
│ [选择简历 ▼] │ │ Q: 请介绍一下你自己 │
│ [选择公司 ▼] │ │ A: 面试官您好,我叫... │
│ [岗位名称___] │ │ │
│ [AI模型 ▼] │ │ Q: 你最大的优势是什么? │
│ [ASR ▼] │ │ A: 我认为我最大的优势▮ │
│ │ │ (流式输出中...) │
│ 🎙️ [录音按钮] │ │ │
│ [自动识别开关] │ │ [👍有用] [👎无用] │
│ 识别结果: │ │ │
│ "你最大的优势是" │ │ 面试时长: 05:23 │
│ [手动输入框] │ │ │
│ [📸 截图识别] │ │ │
│ [结束面试] │ │ │
└───────────────────┘ └──────────────────────────┘
支持三种输入方式:
- 语音输入:录音 → Whisper 识别 → 自动触发 AI 回答
- 截图输入:屏幕共享 → 截图 → 视觉模型提取题目 → AI 回答
- 手动输入:直接键入问题
十、安全设计
| 安全措施 | 实现方式 |
|---|---|
| 密码加密存储 | BCrypt 哈希 |
| JWT 无状态认证 | JJWT + HS256 签名 |
| 路由守卫 | 前端 beforeEach 拦截 + 后端 Security Filter |
| CORS 跨域 | Spring Security 配置白名单 |
| SQL 注入防护 | JPA 参数化查询 |
| 文件上传校验 | Content-Type + 大小限制 (10MB) |
| 敏感信息管理 | API Key 使用环境变量,不入库 |
十一、性能优化
| 优化项 | 方案 |
|---|---|
| AI 回答感知延迟 | SSE 流式 + 打字机效果,首 token < 500ms |
| 路由懒加载 | () => import() 按需加载页面 |
| PDF 解析缓存 | 解析结果存 DB,避免重复解析 |
| 连接池 | HikariCP(最大 20 连接) |
| AI 超时控制 | OkHttp 连接超时 15s / 读取超时 120s |
十二、总结
本项目是一个完整的全栈 AI 应用,涵盖了:
- 前端:Vue 3 Composition API、TypeScript 类型系统、SSE 流式处理、Web Audio API 录音、屏幕共享 API
- 后端:Spring Boot 3 分层架构、Spring Security JWT 认证、JPA ORM、外部 AI API 集成
- AI 工程:多模型切换、Prompt 工程、流式输出、语音识别、视觉模型 OCR
如果你也在准备面试或对 AI 应用开发感兴趣,欢迎参考本项目的设计思路,本项目的回答是能够根据你的简历内容来输出的,因为我采用的是自己个人真实简历做的截图,所以部分敏感信息打了马赛克。
结语:这个项目完全免费,我会放在github上,同时为了照顾一些小伙伴,我也放一份在gitee仓库,开源这个项目,只是为了涨粉丝,希望你们给我的github点几个star。 对于模型,有完全免费的api,我会教大家如何获取免费的api,自己本地idea运行即可,也不一定非要部署到服务器,欢迎大家加入我的qq群聊:744981684。 如果这个系列大家喜欢,可把自己的想法发到评论区或者群聊,我不定期随机抽选一个人帮他完成免费的小项目。 纯粹是为了涨粉丝,谢谢
接下来是效果图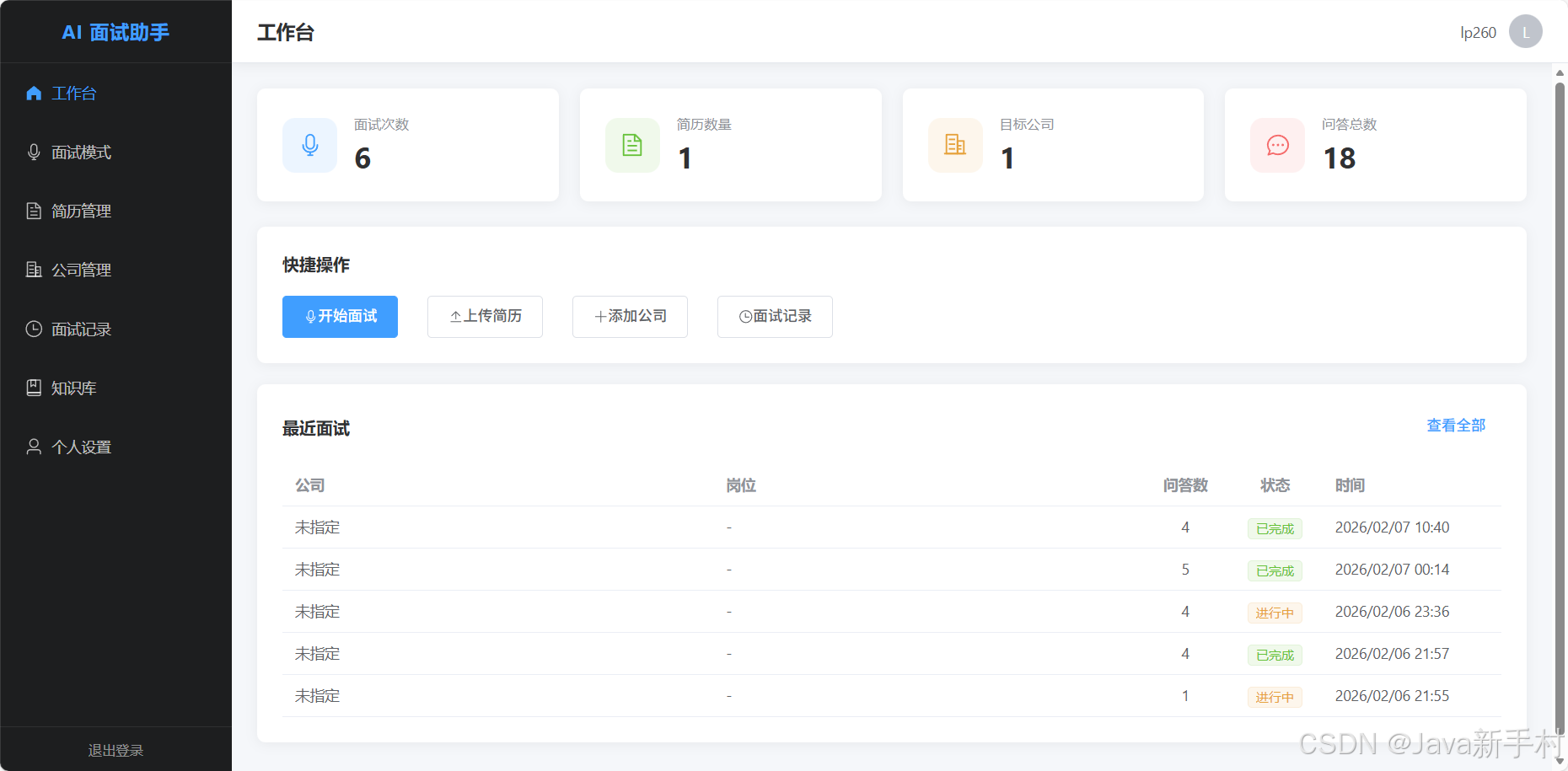
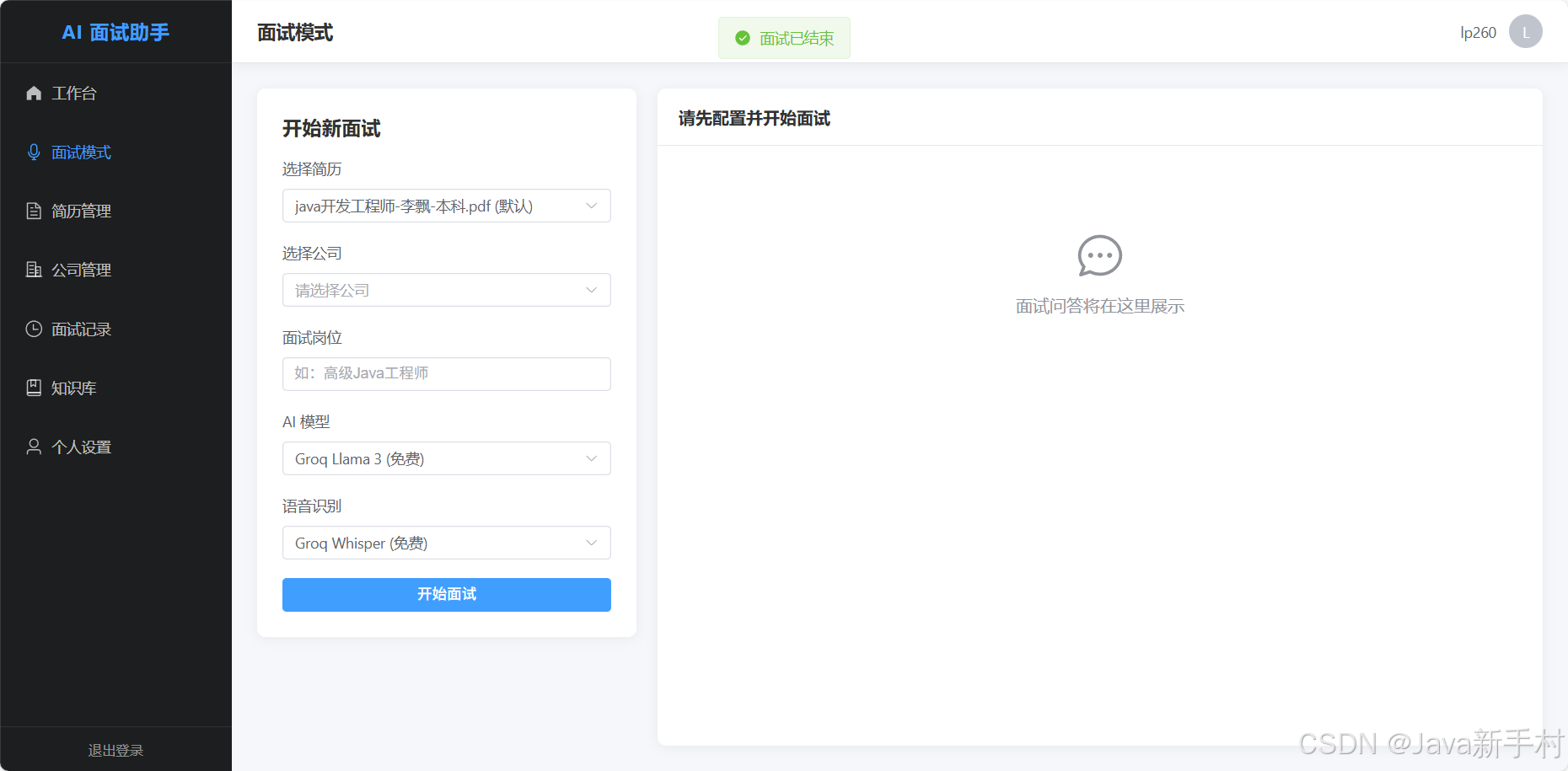
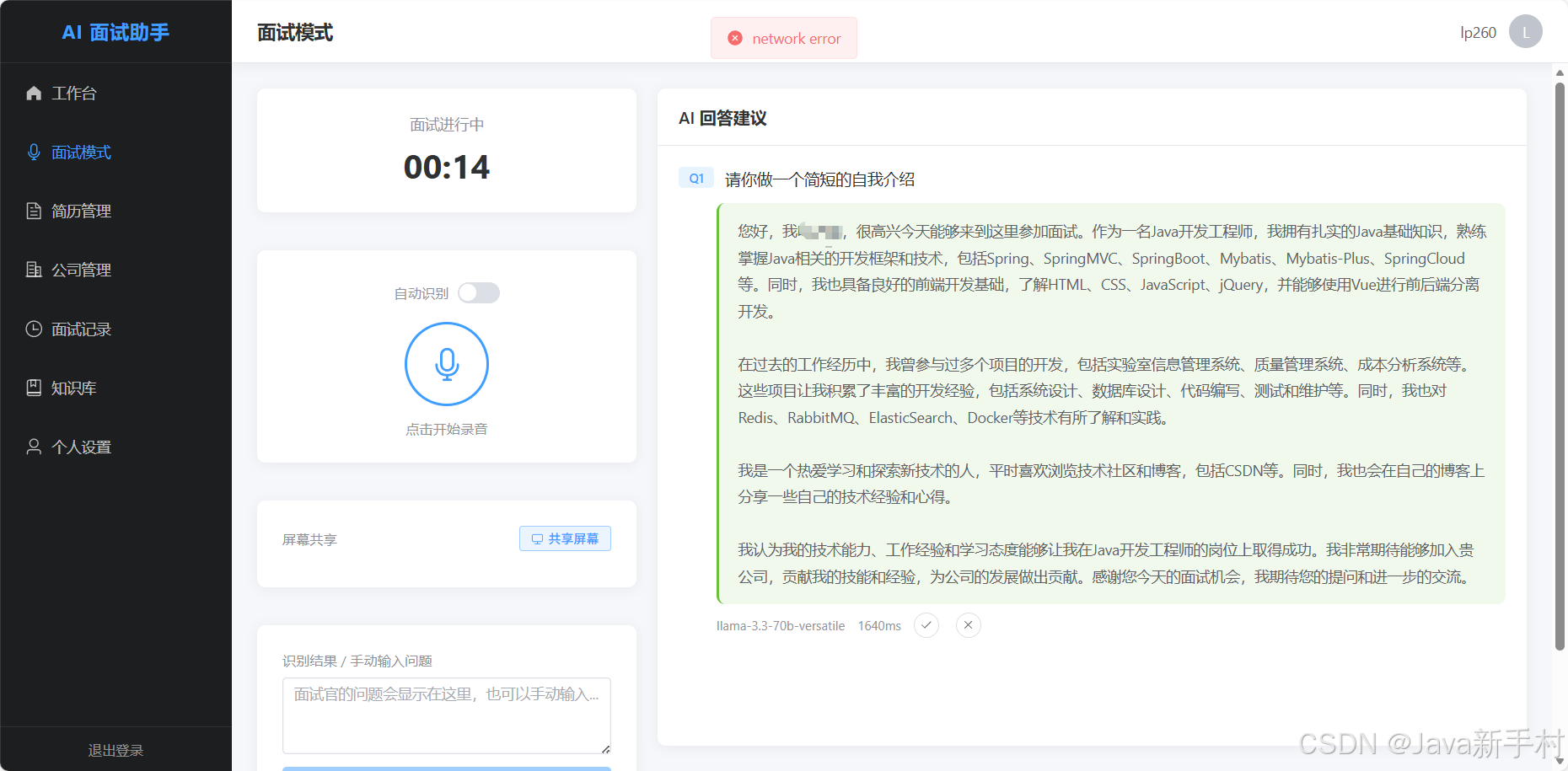
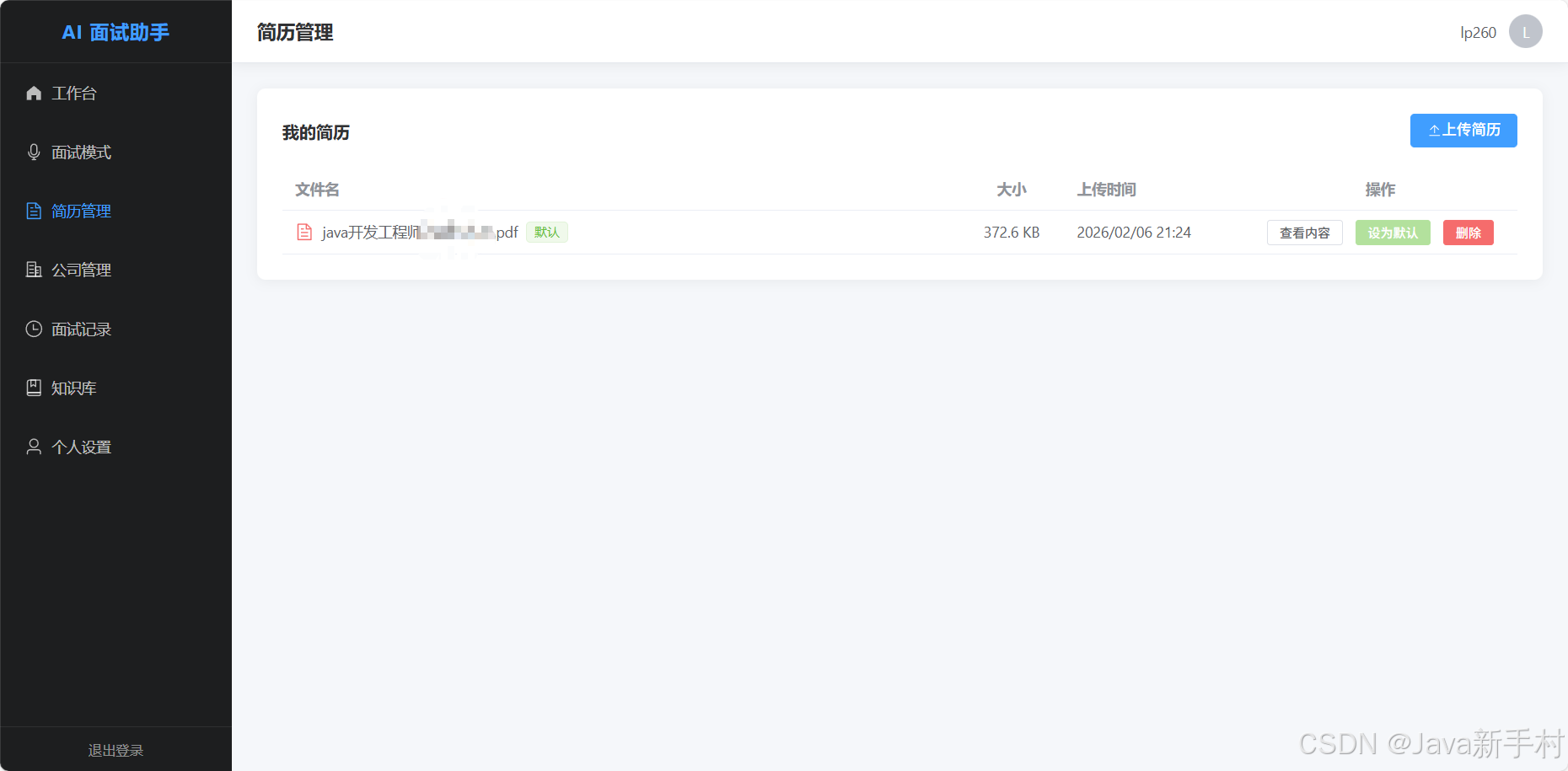
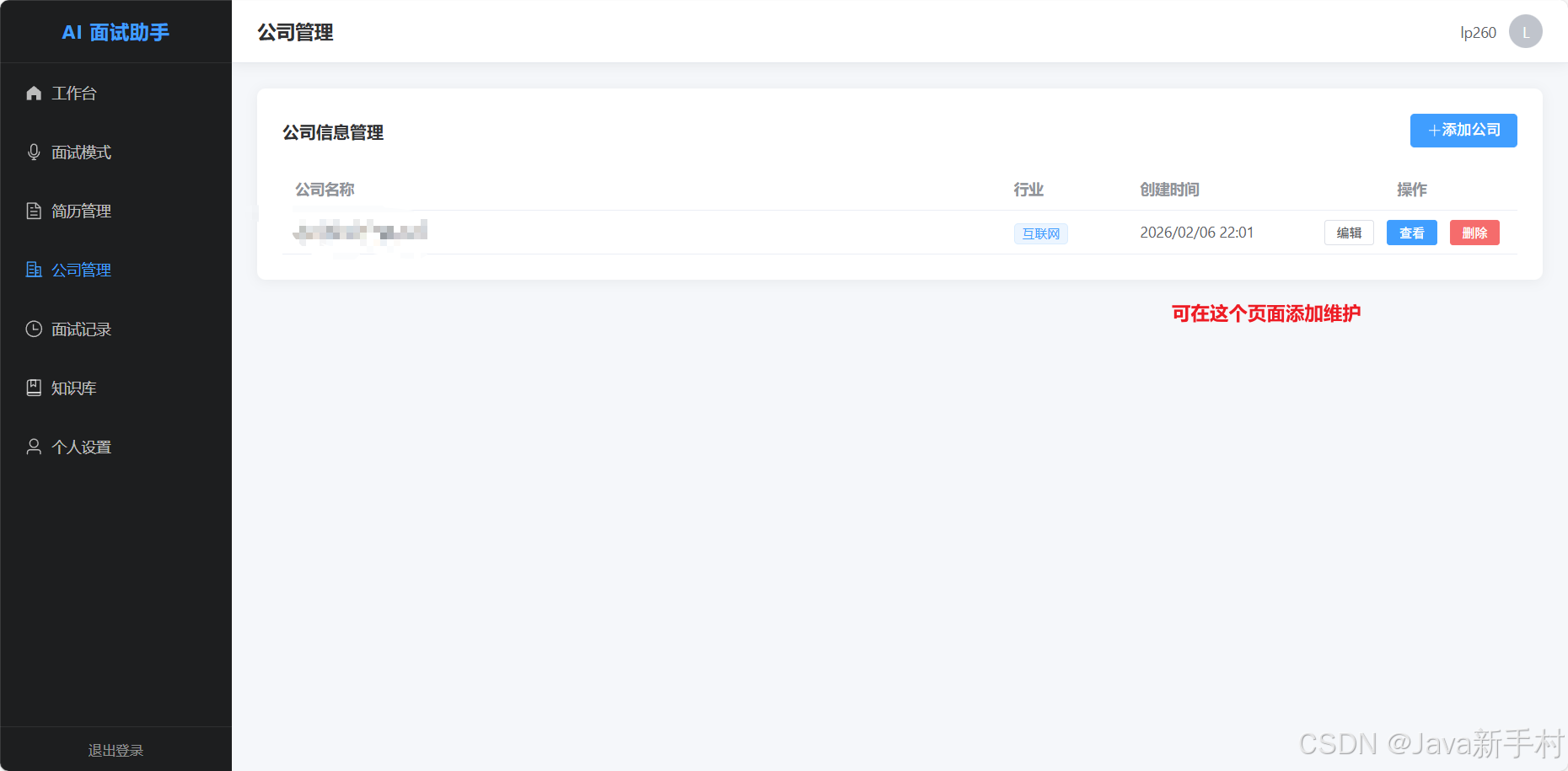
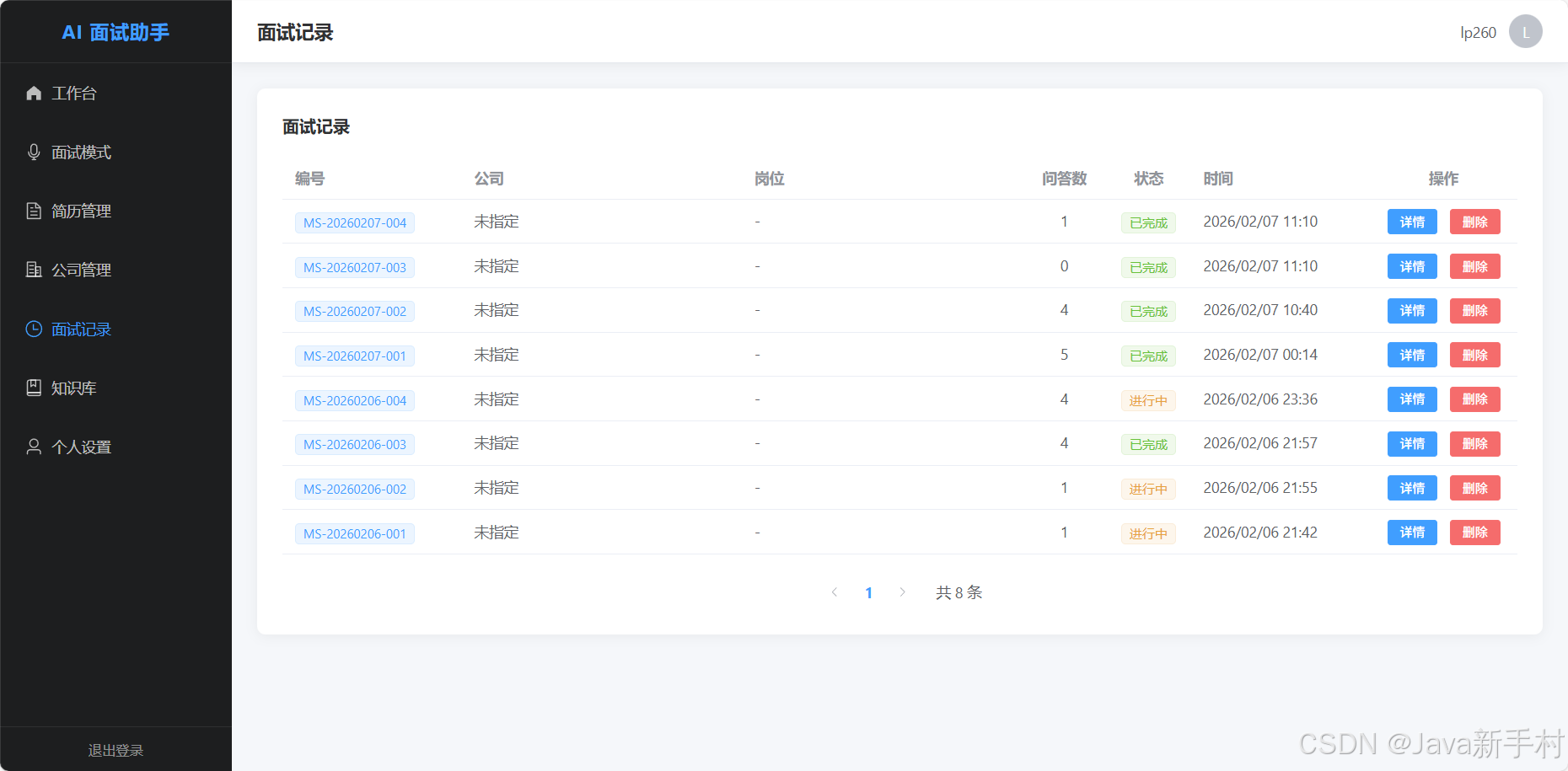
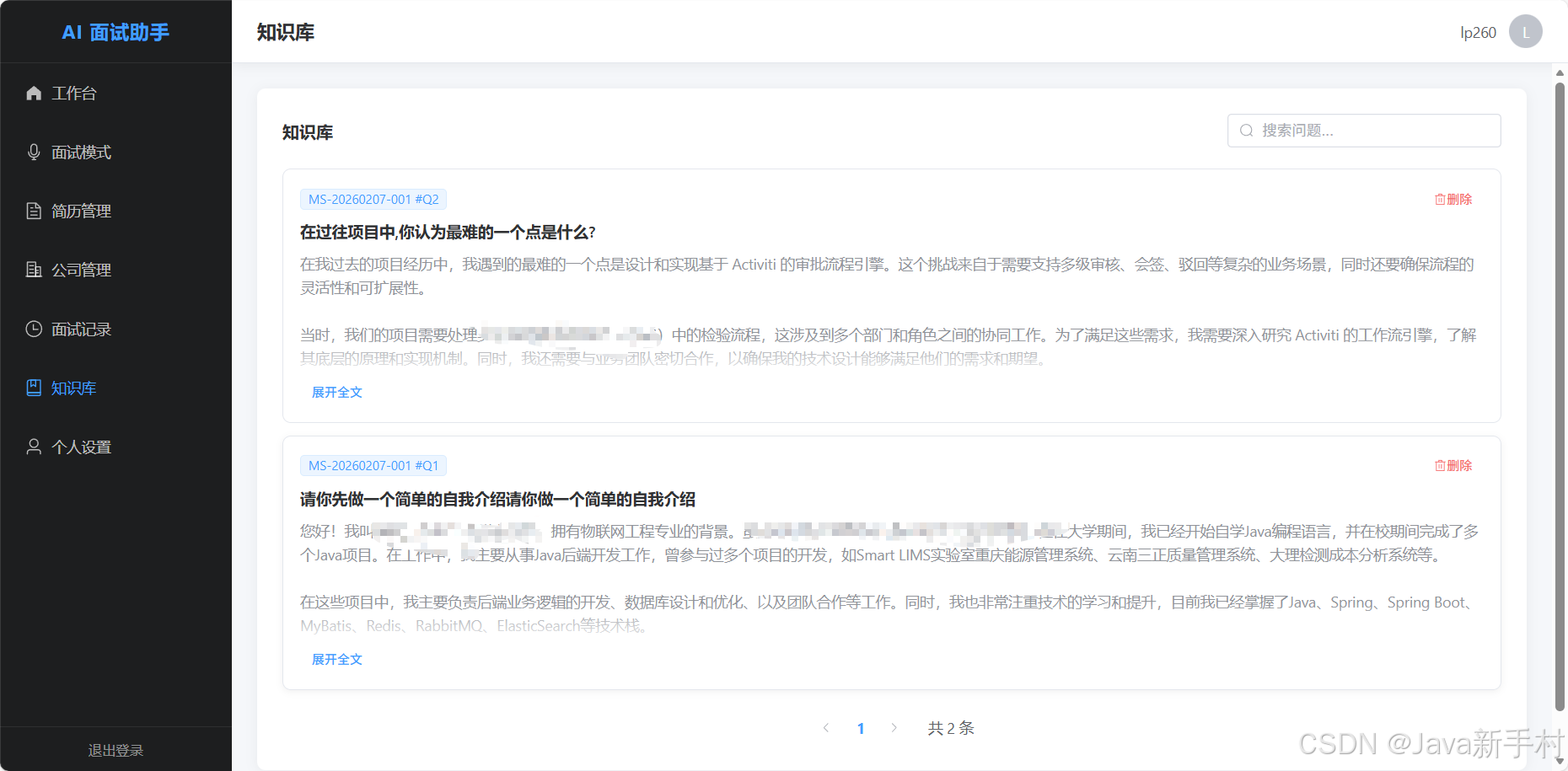
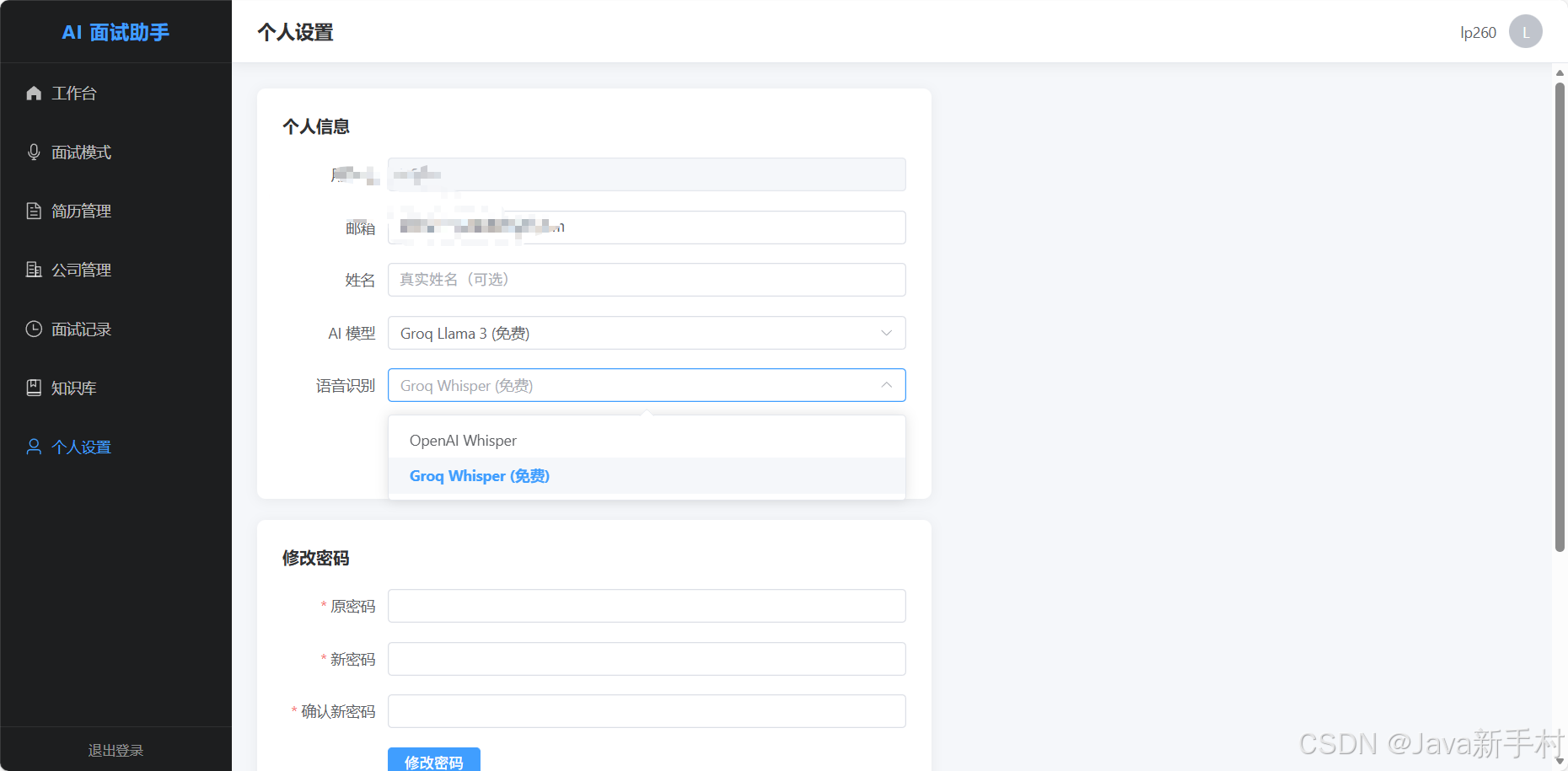
免责声明:本项目仅供学习和技术研究使用,请在合规合法的前提下使用。
如果这篇文章对你有帮助,请点赞收藏关注,你的支持是我持续创作的动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)