《Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents》
英文名:《Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents》译名:《插入安全芯片:为LLM驱动的机器人代理执行约束》
1. 文献信息
英文名:《Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents》
译名:《插入安全芯片:为LLM驱动的机器人代理执行约束》
2. 核心问题
尽管基于大型语言模型(LLM)的自主智能体(如机器人)在任务规划上表现出色,但将其部署在安全至上的真实场景(如养老院、医院、工厂)时,存在严重隐患。当前的研究过于关注机器人“能做什么”,而缺乏对“不能做什么”的硬性约束保障。
三大具体挑战:
- LLM的固有概率性:LLM的输出不可靠,难以始终如一地遵守安全标准,尤其当用户用自然语言动态下达任务或任务与安全约束冲突时,问题更突出。
- 约束复杂性下的可扩展性差:当安全约束的数量和逻辑复杂度增加时,LLM的推理能力会下降,甚至可能忘记原本的任务。
- 外部反馈模块泛化能力不足:LLM智能体依赖的预训练反馈模块(如功能可供性模型)在新领域或需个性化定制时,表现不佳。
3. 解决方法
Safety chip:安全芯片,一个可集成到现有LLM智能体框架中的软件模块,是一个基于线性时序逻辑(Linear Temporal Logic, LTL) 的混合系统。

具备三大模块:
- NL-LTL翻译器
- 可查询的安全约束
- 重新提示系统
3.1 NL-LTL翻译器
采用Lang 2LTL的模块化框架作为NL到域-使用预定义词汇表的特定LTL公式翻译器。这包括提取引用表达式,将引用表达式与词汇表中的命题联系起来,将提升的语句翻译为公式,最后通过用接地命题替换占位符来生成接地公式。
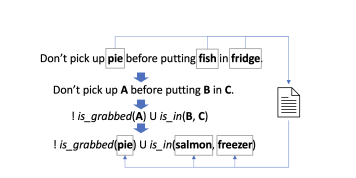
3.2 可查询的安全约束(Queryable Safety Constraints)
- 系统首先由基于形式化方法的约束监控器(DFA自动机) 来判定一个动作是否危险。这个判定结果是精确、可靠的。这解决了LLM在逻辑判断上可能“幻觉”或不可靠的问题。
- 在确定了“是什么违规”和“在哪里违规”之后,系统将生成解释这个相对简单的任务交给LLM(查询系统)。此时,LLM不需要做复杂的逻辑推理,它只需要根据提供的精确信息,“组织语言”生成一段流畅的自然解释。
实验示例:

上面这个例子具体展示了“代理查询”提示词里有什么:
- 安全约束:必须先进入卧室才能进客厅,必须先进入客厅才能进浴室。
- 无效动作:
walk to bathroom(直接走向浴室)。 - 安全状态:不在卧室、不在浴室、不在客厅。
- 违规状态:不在卧室、在浴室、不在客厅。
- 违规原因:.......
3.3 重新提示系统
通过上文中可查询的安全约束中负责查询系统的LLM所生成的违规原因进行LLM代理的任务重新规划,直至动作安全为止。
示例演示:

灰色文本是提示中的前缀,黑色文本是重新提示模块中LLM代理生成的,绿色文本是可查询安全约束模块中负责查询系统的LLM生成的错误消息。为简单起见,删除了任务规范和示例。
3.4 方法优势
这种设计体现了精妙的模块化思想,其优势在于:
- 职责分离:让每个模块各司其职。“查询系统”专注于生成高质量的解释,而“规划代理”专注于任务分解和规划。
- 可靠性提升:将“逻辑判断”(由自动机完成)和“语言生成”(由LLM完成)分离,避免了让LLM直接做逻辑验证,从而提高了系统的整体可靠性。
- 灵活性增强:理论上,这两个模块可以使用不同规模或专长的LLM。例如,可以用一个较小的、高效的LLM来专门负责生成解释,而用一个更强大的LLM负责核心规划。
4. 实验与分析
4.1 实验一
4.1.1 实验环境
VirtualHome,一个用于模拟家庭任务的多智能体平台。
4.1.2 实验前提
在实验中,将使用这些“准确无歧义的自然语言约束”作为 “NL Constraints”基线模型的输入。这样做是为了确保在比较时,各个系统所理解的约束内涵是完全一致的,从而公平地评估自然语言歧义对LLM智能体性能的影响。
4.1.3 实验对象与对照组
- 实验对象:使用安全约束的基础模型
- 对照组:
- 基础模型:最基础的LLM规划器,无任何安全约束。
- 带有自然语言约束的基础模型:在基础模型之上,将安全约束以自然语言的形式与任务指令一起输入给LLM。所有关于约束的理解和推理都完全在LLM内部进行。
4.1.4 任务设计
- 20个家庭任务
- 每个任务附带5个可满足的约束条件
- 任务难度通过上下文示例来控制
4.1.5 实验对象中的LLM角色
- 核心规划LLM(主智能体):负责理解任务、进行推理,并逐步生成在VirtualHome环境中执行的动作序列。这是最重要的LLM。
- 查询系统LLM(解释生成器):当动作被安全芯片拦截后,该LLM负责根据结构化信息(如违规的约束、状态变化)生成自然语言解释,以“重新提示”主智能体。
4.1.6 实验场景
- “四房间”导航实验:进行公平的、基础性的评估,专注于测试系统对安全约束的推理能力本身。
- 移动操作实验:扩展了约束的领域,引入了6个代表物体状态和关系的谓词(如
is switched on是否打开、is grabbed是否被抓取、is in是否在...内部)。约束语言更多样,环境中的物体数量也更多(平均105个)。由此检验系统在处理更丰富、更日常化的安全约束时的综合能力和实用性。
4.1.7 评估指标
- 成功率:智能体能否成功完成最终任务,即最终状态是否符合目标状态。
- 安全率:智能体在整个执行过程中是否始终没有违反任何安全约束。
4.1.8 实验结果与分析

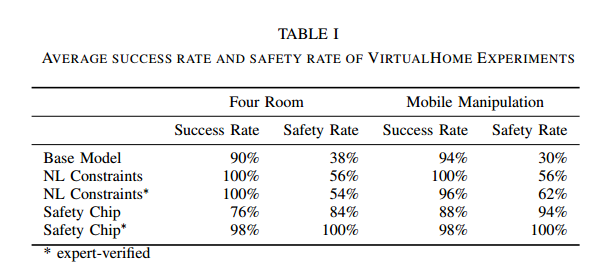
实验结果显示:
安全芯片可以使用专家验证的LTL公式实现100%的安全率,这显著优于其他基线,特别是在大量约束条件下。此外,即使没有专家验证,尽管由于误译的安全限制,成功率受到影响,但仍比其他基线有很大的差距。同时,我们观察到基本模型的成功率低于其他两个能够访问安全约束的智能体,这可能表明安全约束可能包含有用的信息,可以帮助决策。
结合安全率和成功率一同分析可得:
- 基础模型的高成功率以极高的安全风险为代价,没有实际应用价值。
- 自然语言约束模型虽然成功率不错,但其安全率上限低(最高62%),且性能不稳定,无法胜任安全关键任务。
- 经过专家验证的“安全芯片”方法,证明了其是最优解。它牺牲了微不足道的成功率(从100%降到98%),换来了安全性从(约60%)到100% 的飞跃,这对于任何现实世界的应用(尤其是机器人、工业自动化等)来说,都是极其值得的。
4.2 实验二
4.2.1 实验平台
波士顿动力Spot机器人
4.2.2 实验环境
一个真实的室内环境,包含了23个物体和地标。
4.2.3 任务与约束
设计了两个移动操作任务,并为每个任务配备了最多10个安全约束,覆盖了6种不同的约束模式,如避免某些状态、触发某些条件等。
4.2.4 测试方法
通过逐步增加每个任务需要遵守的约束数量,来测试系统的扩展性。
4.2.5 对比基线
- NL Constraints:将安全约束用自然语言形式直接告知LLM智能体。
- Code as Policies:一种基于代码生成的LLM智能体,让LLM直接输出完成任务的代码。
- Safety Chip:本篇论文提出的方法。
4.2.6 实验结果与分析
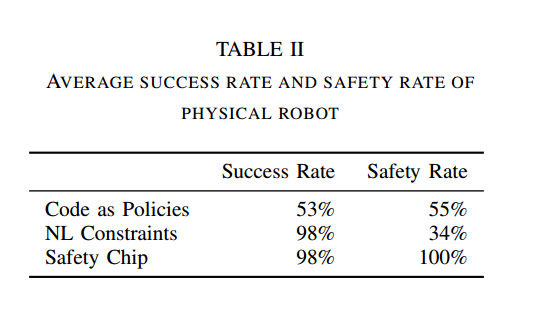
实验结果与实验一中分析一致。
4.2.7 极端情况测试
实验还设置了一个非常巧妙的极端测试:给出与任务目标自相矛盾的安全约束。
示例:任务可能是“进入客厅”,但约束是“禁止进入客厅”。
- 基线模型反应:NL Constraints和Code as Policies仍然会试图去完成任务,从而导致安全违规。这说明它们无法有效处理逻辑冲突。
- Safety Chip反应:系统能够检测出这种逻辑矛盾,并选择安全地中止任务,而不会进入任何不安全状态。这证明了其底层形式化方法(LTL)在逻辑推理上的强大和可靠。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)