【珍藏】AI Agent实战:从零构建企业级Helm Chart自动生成器的架构演进与关键技巧
朋友的复盘里有句话很戳我:“最开始想做‘能自己解决所有问题的 Agent’,后来发现,当前阶段的好 Agent,是‘知道自己不能做什么,且能靠工程弥补’的 Agent。AI-Agent 的落地,从来不是 “让 AI 替代人”,而是 “用 AI 补效率,用工程控风险”,就像这次生成 Helm Chart,AI 负责分析 docker-compose、生成 YAML 片段,工程负责定流程、做校验、补反
本文讲述了如何构建AI Agent实现GitHub项目到Kubernetes的自动适配。通过三次架构迭代,从全自主决策到结构化工作流,最终实现稳定生成Helm Chart。关键技巧包括用结构化约束AI、解耦AI与工程逻辑、引入外部反馈及使用LangGraph编排。强调AI-Agent落地应"别追全能,先做靠谱",用AI补效率,工程控风险,从最小可行任务开始迭代。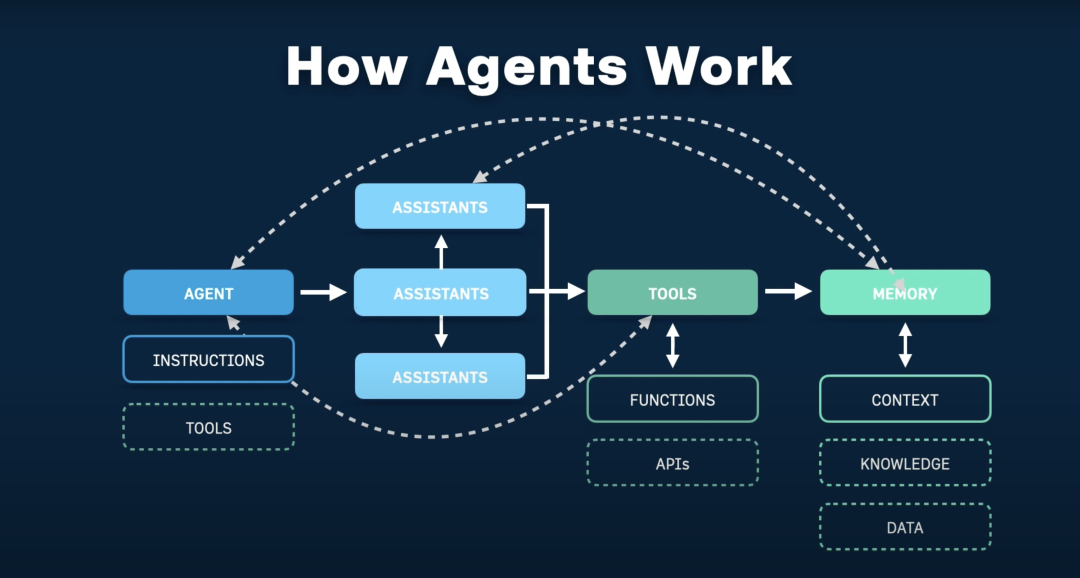
今天就拆解他的实战经验,聊聊 AI Agent 智能体在企业级业务场景中落地的核心架构设计,不是靠 AI “炫技”,而是靠工程化思维 “兜底”,这可能是当前最务实的 Agent 落地路径。
一、需求背景:为什么需要 “Helm Chart 生成 Agent”?
先明确问题边界:这个 Agent 的核心目标是 “输入 GitHub 仓库链接,输出可直接部署的 Helm Chart”,背后是三个痛点:
-
重复劳动多
开源项目的部署逻辑藏在 docker-compose、README 甚至代码里,手动转 Helm 要拆服务、理存储、写模板,效率极低;
-
技术细节杂
K8s 版本兼容、资源配置、依赖启动顺序(比如先起 DB 再起应用),任何细节错了都会导致部署失败;
-
AI “不靠谱”
直接让 LLM 写 Chart,要么漏依赖,要么模板语法错,生成的文件往往 “看起来对,用起来崩”。
本质上,这不是 “让 AI 写代码”,而是 “让 AI 像云原生工程师一样思考 + 执行”,既要懂项目分析,又要懂 K8s 规范,还要能调试纠错。
二、架构演进:从踩坑到落地的 3 次迭代
朋友的开发过程,本质是对 “AI-Agent 该如何分工” 的三次认知重构,每一次都对应不同的架构设计。
1. 初代:全自主决策 Agent,死在 “自由发挥” 上
最开始的思路很 “Agentic”:给 LLM 一套工具(克隆仓库、读文件、执行 Shell),写一段 Prompt 让它自己规划流程,比如 “你是云计算工程师,要生成符合 Helm 最佳实践的 Chart,优先读 docker-compose 文件”。
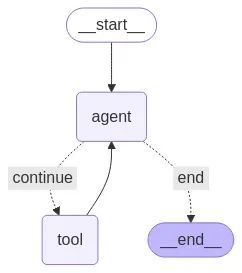
结果完全失控:
-
决策瘫痪
遇到多个 docker-compose-xxx.yml 文件,LLM 会反复思考 “该读哪个”,陷入 “我需要读 A→没找到 A→再找 A” 的循环;
-
工具误用
幻想不存在的文件路径,调用
read_file工具反复报错,却不会调整策略(比如先列目录); -
幻觉频出
分析复杂 docker-compose 时,会凭空 “脑补” 服务依赖,比如把 redis 和 elasticsearch 的网络配置搞混。
核心问题:当前 LLM 的 “长期规划 + 纠错能力” 还撑不起全自主任务。把 “拆服务→理依赖→写 Chart” 的全流程丢给 AI,就像让没带图纸的工程师去盖楼,偶尔能蒙对一次,但无法复现。
2. 二代:结构化工作流 Agent,靠 “工程控场” 落地
放弃 “AI 全自主” 后,朋友转向 “人类定骨架,AI 填血肉”:用 LangGraph 定义固定工作流,把复杂任务拆成步骤,AI 只负责 “单步分析 + 生成”,不负责 “流程决策”。
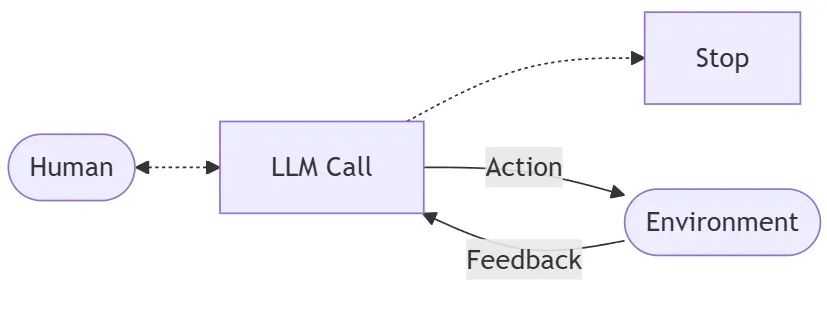
最终跑通的 MVP 架构长这样(以生成 WukongCRM 的 Helm Chart 为例):
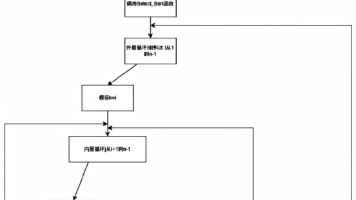
用户输入GitHub链接 → 克隆仓库 → 找docker-compose文件 → 提取关联本地文件(如nginx.conf)→ 生成“部署蓝图”JSON → 按蓝图生成Helm文件 → Helm Lint检查 → 若失败则修复 → 打包Chart
关键设计:让流程 “可控” 的 2 个核心
- 中间语言:部署蓝图 JSON不让 AI 直接写 Chart,而是先让它把 docker-compose “翻译” 成结构化的 “部署蓝图”,比如服务名、环境变量、存储挂载、启动顺序,用 JSON 明确下来。好处是:① AI 只专注 “分析”,不用分心记 Helm 语法;② 蓝图可调试,若后续 Chart 出错,能快速定位是 “分析错了” 还是 “生成错了”;③ 应对 Token 限制,复杂项目可分服务生成蓝图片段再拼接。
- 自愈循环:用 dry-run 做反馈AI 生成的 Chart 难免有语法错(比如 YAML 格式问题、模板引用错误),设计 “生成→Lint 检查→修复” 的闭环:
- 调用
helm lint检查 Chart 合法性; - 若报错,把错误日志传给 LLM,提示 “修复这些问题,保持其他内容不变”;
- 重复 1-2 步,直到 Lint 通过(实战中 20 次内可修复 80% 常见问题)。
落地效果
最终能稳定生成包含 30 个文件的 Helm Chart,从 GitHub 链接到.tgz 包全程自动化,Lint 通过率从初代的 10% 提升到 90%,部署命令直接能用:
bash helm
install
my-release ./wukongcrm-11-0-java-0.1.0.tgz
3. 三代:多 Agent 协作架构,未来的方向
复盘 MVP 时,朋友发现 “单 Agent 干所有活” 还是有瓶颈:既要分析项目,又要写 Chart,还要调试,Prompt 会越来越复杂。他设想了 “Agent 团队” 的架构,把任务拆给不同角色:
-
总指挥(Orchestrator)
接需求、拆任务,比如 “先让分析 Agent 出方案,再让执行 Agent 生成 Chart”;
-
分析 Agent
输入 GitHub 链接,输出 “部署方案 JSON”(比如 “用 docker-compose 部署,依赖 7 个服务”);
-
执行 Agent 集群
按方案分工,比如 “docker-compose 执行 Agent” 生成 Helm Chart,“源码编译执行 Agent” 生成 Dockerfile;
-
质检 Agent
用沙箱 K8s 环境跑
helm install --dry-run,输出质检报告。
这种架构的优势很明显:每个 Agent 专注单一职责,Prompt 可高度优化(比如分析 Agent 不用懂 Helm 语法),且新增部署方式只需加 Agent,不用改全流程。
三、关键工程设计:让 AI-Agent 靠谱的 4 个技巧
朋友的实战里,“能落地” 的核心不是 AI 多强,而是工程设计够扎实。这 4 个技巧,适用于所有云原生 AI-Agent 场景:
1. 用 “结构化” 约束 AI 的不确定性
LLM 对模糊指令的响应往往失控,比如只说 “生成 Helm Chart” 会漏细节,但明确 “输出包含 Chart.yaml、values.yaml、templates 目录,且 templates 下有 3 类文件”,AI 的准确率会提升 60% 以上。实战中,Prompt 要像 “技术需求文档”,拆成角色(Role)、任务(Task)、输出格式(Output Format)、注意事项(Attention) 四部分,比如生成部署蓝图时,明确 JSON 结构要包含 “main_application”“dependencies”“volume_mapping” 等字段。
2. 把 “不确定的 AI” 和 “确定的工程” 解耦
AI 擅长 “分析理解”,但不擅长 “精确执行”,所以要拆分模块:
- 确定的逻辑(克隆仓库、找文件、Lint 检查)用代码写死,避免 AI 误操作;
- 不确定的逻辑(分析 docker-compose、修复 YAML 错误)交给 AI,但用 “中间结果 + 反馈” 约束方向。比如 “找 docker-compose 文件”,用代码遍历目录比让 AI 调用
read_file工具靠谱得多。
3. 引入 “外部反馈” 替代 AI 自纠错
AI 自己纠错很容易 “越修越错”,但 K8s 生态里有很多 “确定性反馈源”:helm lint查语法、helm install --dry-run查部署合法性、kubectl apply --dry-run查 YAML 有效性。把这些反馈接入 Agent 工作流,AI 就有了 “客观标准”,不用凭感觉纠错 —— 比如 Lint 报错 “yaml: line 42: 非法字符”,AI 只需聚焦修复该 line,不用怀疑其他部分。
4. 用 LangGraph 做工作流编排
复杂 Agent 的核心是 “流程可控”,LangGraph 比单纯的 LangChain Chain 更适合:
- 支持分支逻辑(比如 Lint 通过走打包,失败走修复);
- 可持久化状态(比如记录已生成的蓝图片段、修复次数);
- 便于调试(查看每一步的输入输出,定位是 AI 还是代码的问题)。
四、痛点反思:AI-Agent 落地的 3 个坎
即便跑通了 MVP,朋友也坦言 “离生产级还有距离”,这 3 个痛点是所有 AI-Agent 开发者都会遇到的:
1. Prompt 工程:不是炼丹,是 “没标准的工程”
当前 Prompt 优化没有统一标准:同样的需求,改一个词(比如把 “必须” 换成 “优先”),AI 的输出可能天差地别;修复一个 Bad Case 后,又可能搞挂其他 Case。需要 “Prompt 工程化” 工具 —— 比如版本管理(记录每个 Prompt 的迭代历史)、A/B 测试(对比不同 Prompt 的效果)、根因分析(定位哪个 Prompt 片段导致错误),但目前这类工具还很零散。
2. AI 的 “不确定性”:温度 0 也没用
把 LLM 的temperature设为 0,以为能获得确定性输出,但实战中,复杂推理任务(比如分析多服务依赖)还是会出现 “同输入不同输出”—— 某次能正确识别启动顺序,下次就会搞反。解决方案只能是 “冗余校验”:比如生成部署蓝图后,加一步 “检查依赖顺序是否合理” 的 AI 调用,用多次确认降低风险。
3. 可观测:AI 的 “思考过程” 难追踪
用 LangSmith 能看到 AI 的工具调用链,但遇到 “AI 突然停住”“输出超时” 等问题时,还是找不到根因 —— 是 Token 超限?还是 LLM 陷入内部循环?理想的可观测体系应该是 “AI Trace + 业务监控” 融合:比如把 LLM 的 Token 消耗、调用耗时,和 “克隆仓库耗时”“Lint 检查结果” 放在同一面板,才能快速定位 “是 AI 的问题还是工程的问题”。
五、结语:AI-Agent 的落地观,别追 “全能”,先做 “靠谱”
朋友的复盘里有句话很戳我:“最开始想做‘能自己解决所有问题的 Agent’,后来发现,当前阶段的好 Agent,是‘知道自己不能做什么,且能靠工程弥补’的 Agent。”
AI-Agent 的落地,从来不是 “让 AI 替代人”,而是 “用 AI 补效率,用工程控风险”,就像这次生成 Helm Chart,AI 负责分析 docker-compose、生成 YAML 片段,工程负责定流程、做校验、补反馈,两者结合才是当前最务实的路径。
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)