RT-2:Google DeepMind的机器人革命——如何让AI从网页知识中学会操控现实世界
Google DeepMind推出的RT-2模型将互联网知识与机器人控制相结合,通过视觉-语言-动作(VLA)架构实现智能操控。该模型将机器人动作转化为"文本Token",利用预训练视觉语言模型(VLM)的常识推理能力,显著提升泛化性能。实验显示,RT-2在6000多次测试中,对未见任务的执行成功率比前代提升3倍,能理解"捡起灭绝动物"等复杂指令。其涌现能力
大家好,我是数据与算法架构提升之路,一个专注AI和机器人技术的博主。今天,我们来聊聊Google DeepMind在2023年推出的重磅模型——RT-2 (Robotic Transformer 2)。这个模型不是简单的聊天机器人,而是将互联网上的海量知识直接转化为机器人动作控制的“超级大脑”。想象一下,一个机器人能理解“捡起像锤子一样的东西”(比如石头),或者根据“我累了”自动递上能量饮料?这不是科幻,而是RT-2的真实能力!
如果你是AI爱好者、机器人工程师或科技投资者,这篇文章绝对值得一读。我们将从原理、架构、创新点到实验结果,一一拆解。文末还有视频和论文链接,帮你快速上手。走起!
1.为什么RT-2是机器人领域的游戏改变者?
传统机器人学习依赖于海量的演示数据:工程师手动操作机器人,记录动作,然后AI模仿。但这效率低下——要让机器人适应新物体、新环境,就得从头收集数据。RT-2的创新在于,它借力视觉-语言模型 (VLM) 的预训练知识,将网页上的常识(如物体识别、语义推理)直接迁移到机器人控制中。
简单来说,RT-2是一个视觉-语言-动作 (VLA) 模型:
- 视觉:处理摄像头图像。
- 语言:理解自然语言指令。
- 动作:直接生成机器人控制命令。
根据DeepMind的论文,RT-2在6000多次实验中,泛化能力提升了3倍以上!它能处理训练数据中从未见过的物体、场景和指令,比如“把南瓜移到数字2上”或“捡起灭绝动物”(如恐龙玩具)。这得益于它从互联网数据中学到的“世界知识”。
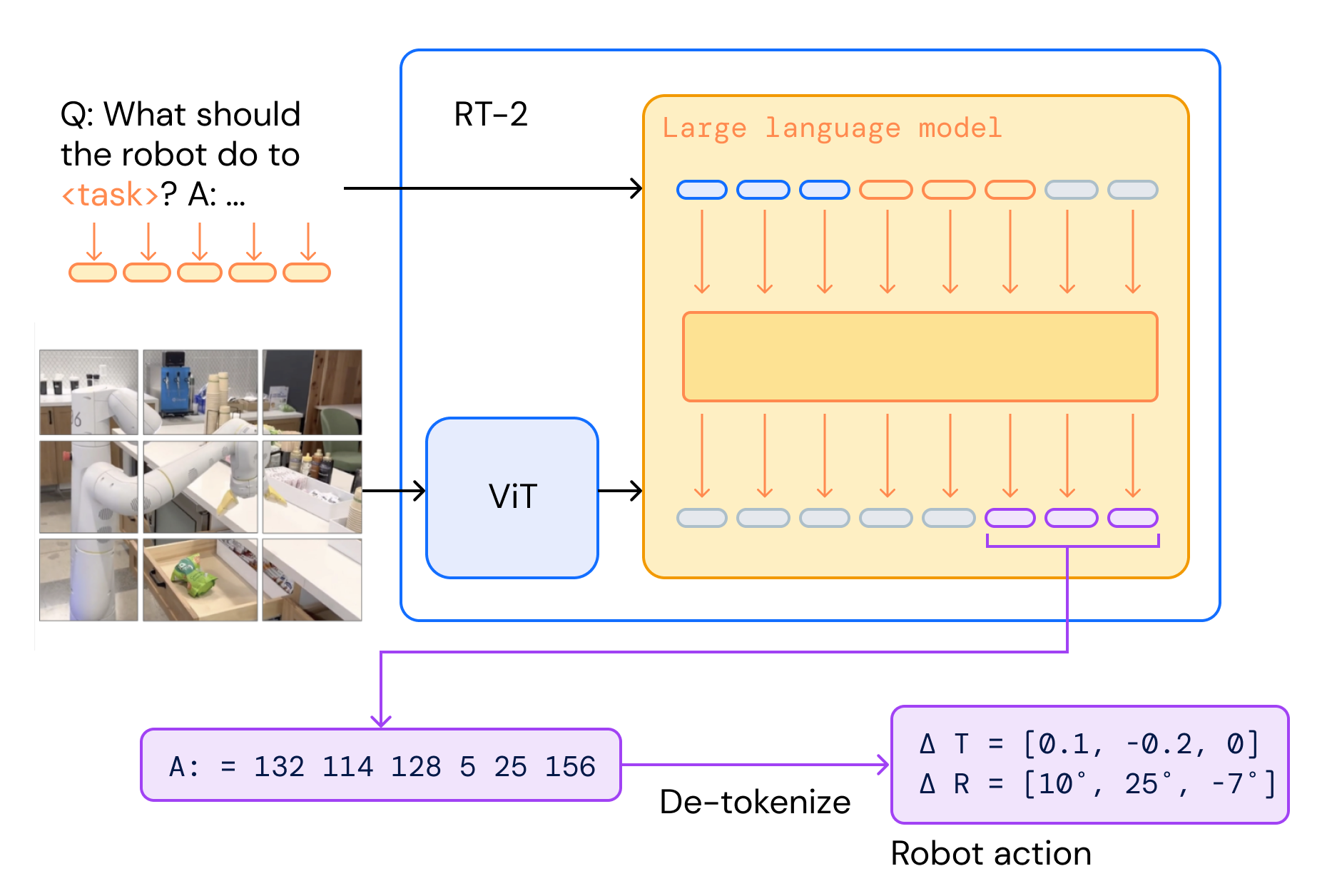
2.RT-2的核心原理:动作就是另一种“语言”
RT-2的魔法在于Token化。传统VLM(如PaLM-E)输入图像+文本,输出文本描述。RT-2则扩展了输出空间:将机器人动作也视为Token。
- 动作空间离散化:机器人动作(如手臂移动、夹爪开合)是连续的。RT-2将它们均匀分成256个区间(Bins),每个区间对应一个整数(0-255)。一个完整动作序列(如位置变化、旋转、夹爪状态)就变成8个数字的字符串,例如:“1 128 91 241 5 101 127 217”。
- Token映射:这些数字映射到模型的词汇表中,成为“动作Token”。模型像预测下一个单词一样,预测下一个动作。
训练时,RT-2使用协同微调 (Co-fine-tuning):
- 数据来源:互联网VLM数据(图像+文本,用于常识学习)+ RT-1机器人演示数据(13台机器人、17个月厨房环境数据)。
- 输入格式:图像 + 指令(如“Q: What should the robot do to pick apple?”)。
- 输出:动作字符串Token。
结果?模型不仅学会了基本动作,还继承了VLM的语义理解。比如,它知道“能量饮料”适合“累了的人”,因为互联网数据教了它这些常识。
RT-2:Google DeepMind的机器人革命
3.技术架构:基于顶级VLM的升级版
RT-2不是从零开始,而是站在巨人的肩膀上:
- RT-2-PaLM-E:基于PaLM-E(120亿参数),擅长多模态具身推理。
- RT-2-PaLI-X:基于PaLI-X(550亿参数),在图像-文本任务上更强。
模型大小从5B到55B参数,确保高效推理(1-5Hz频率)。DeepMind使用TPU云服务运行大型模型,支持多机器人并行控制。
与RT-1对比:
- RT-1:仅用机器人数据,泛化差(未见场景成功率32%)。
- RT-2:加入VLM预训练,成功率飙升到62%,涌现出新能力。

4.涌现能力:从常识到链式推理
RT-2最酷的地方是涌现能力 (Emergent Capabilities)——超出训练数据的智能表现。论文中分类为三类:
- 符号理解 (Symbol Understanding):
- 示例:指令“把VW移到德国”(VW是大众车,德国是其发源地)。RT-2能识别图像中的国旗或图标,并放置物体。
- 为什么?互联网数据教了它符号含义。
- 推理能力 (Reasoning):
- 示例: “捡起不同颜色的物体”或“把香蕉移到2+1的位置”(即3)。
- RT-2能进行基本数学和关系推理。
- 人类识别 (Human Recognition):
- 示例: “捡起快掉下的袋子”或“给我适合累人的饮料”(选能量饮料)。
- 它理解人类状态和意图。
更高级的:链式思维 (Chain-of-Thought)。
- RT-2先用自然语言规划(如“累了需要提神,选择能量饮料”),再生成动作Token。
- 这让它处理多步任务,比如“用石头当锤子砸钉子”。
实验证明:在涌现任务上,RT-2成功率是RT-1的3倍。在Language Table基准上,模拟成功率90%(远超前SOTA 77%),真实世界也能泛化到新物体如香蕉、番茄酱瓶。
5.实验结果:从实验室到现实世界
DeepMind进行了6000+次真实机器人实验:
- 已见任务:性能与RT-1相当。
- 未见任务:物体泛化(新玩具)、背景(新桌面)、环境(新厨房),成功率翻倍。
- 基准对比:优于MOO(用VLM识别物体)和VC-1(视觉预训练)。
在开放世界中,RT-2还能处理多语言指令(如法语),证明其跨文化适应性。
6.RT-2的未来影响:通往通用机器人的钥匙?
RT-2不是终点,而是起点。它证明:大型模型 + 互联网知识 = 更智能的机器人。未来,可能用于家务、医疗、工业,甚至太空探索。
但挑战仍存:计算成本高(55B参数需云端运行),安全问题(机器人出错后果严重)。DeepMind强调,这是向“通用物理机器人”的迈进——一个能推理、解决问题、在现实中执行多样任务的AI。
如果你是开发者,试试RT-2的开源基准如Language Table。论文链接:RT-2 Paper。
7.结语:AI机器人时代已来,你准备好了吗?
RT-2让我想起科幻电影《机器人总动员》——机器人不再是笨拙的工具,而是有“常识”的伙伴。Google DeepMind的这项工作,标志着AI从虚拟走向物理世界的突破。你觉得RT-2会如何改变生活?欢迎评论区讨论!如果喜欢,点赞+分享,让更多人看到。
8.参考资料
https://deepmind.google/blog/rt-2-new-model-translates-vision-and-language-into-action/
https://robotics-transformer2.github.io/
(Google DeepMind官网、RT-2论文。图片来源于官网,如有侵权请联系删除。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)