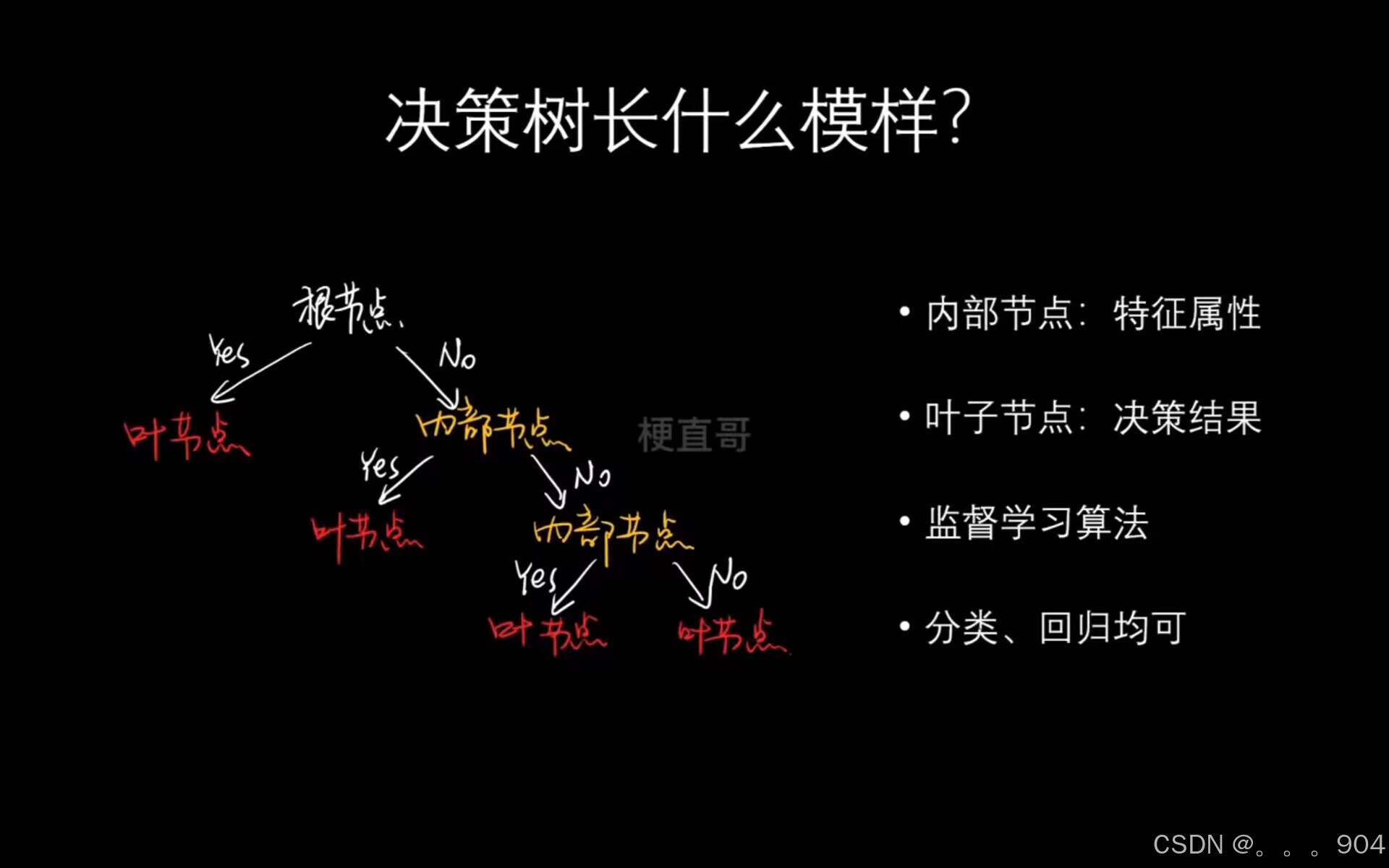
决策树——DecisionTree
就是不断确定分裂点,将数据分开的过程。这个过程通过找到使得信息增益最大的数据特征及其特征值来确定分裂点,将数据分别左子树和右子树,然后不断对左右子树递归这个过程,直至达到我们对决策树的要求(比如限定了决策树的层数,限制了叶子节点的最小数据量之类的),叶子节点中样本数最多的类别就为这个叶子节点所属的类别。由于机器学习中,研究的都是一大堆数据,所以这里举一个包含多个数据的系统的信息熵,比如,这个系统中
决策树

一、决策树核心思想和原理
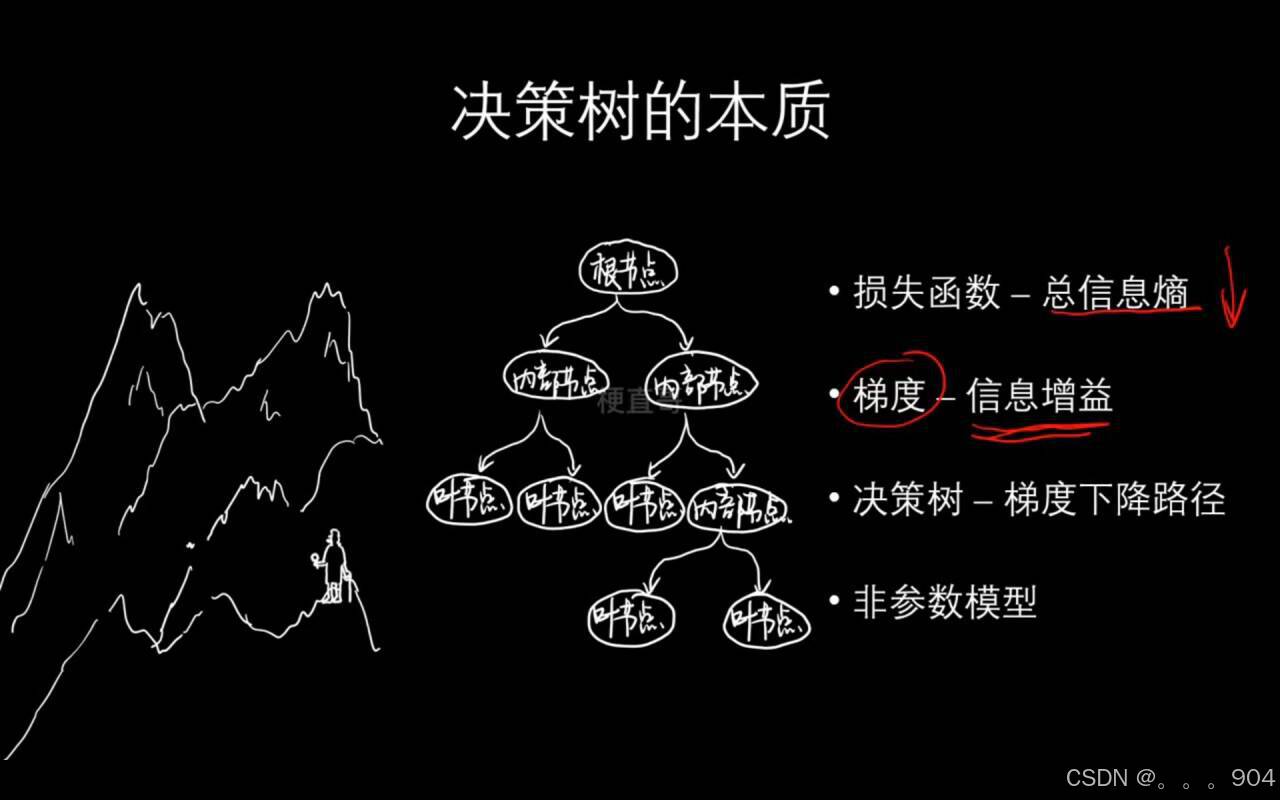
有一堆数据和各自的标签,利用这些数据的特征和特征值将这堆数据进行不断分堆(根据信息增益来选择),尽可能使得具有相同标签的数据分在同一个小堆里面(也就是使得整体的信息熵越小)。
二、信息熵
熵用来量化分布的混乱程度或分散程度
1、单个变量的信息熵
公式:
H(X)=−∑inp(xi)logp(xi)这个公式表示,对于一个离散的随机变量X,其可能的取值为x1,x2,…,xnx1,x2,…,xn的概率分别为P(x1),P(x2),…,P(xn),这个X的信息熵可以用公式H(X)表示 H(X)=-\sum_i^np(x_i)\mathrm{log}p(x_i)\\ 这个公式表示,对于一个离散的随机变量 X ,其可能的取值为 x1,x2,…,xn\\ x1,x2,…,xn的概率分别为 P(x1),P(x2),…,P(xn),这个X的信息熵可以用公式H(X)表示 H(X)=−i∑np(xi)logp(xi)这个公式表示,对于一个离散的随机变量X,其可能的取值为x1,x2,…,xnx1,x2,…,xn的概率分别为P(x1),P(x2),…,P(xn),这个X的信息熵可以用公式H(X)表示
由于机器学习中,研究的都是一大堆数据,所以这里举一个包含多个数据的系统的信息熵,比如,这个系统中,我有100个数据,其中80个数据的标签为1,20个数据的标签为0,那么这个系统的信息熵该如何计算呢?
1、首先计算每个类别样本数所占总体数据的比例N=100,P(1)=0.8,p(2)=0.22、然后根据信息熵公式计算信息熵H=−∑iP(i)log2P(i)H=−(0.8log20.8+0.2log20.2)=0.7219 1、首先计算每个类别样本数所占总体数据的比例\\ N = 100,P(1)=0.8,p(2)=0.2\\ 2、然后根据信息熵公式计算信息熵\\ H=-\sum_iP(i)\log_2P(i)\\ H=-\left(0.8\log_20.8+0.2\log_20.2\right)\text=0.7219\\ 1、首先计算每个类别样本数所占总体数据的比例N=100,P(1)=0.8,p(2)=0.22、然后根据信息熵公式计算信息熵H=−i∑P(i)log2P(i)H=−(0.8log20.8+0.2log20.2)=0.7219
信息熵衡量的信息的混乱程度,如果一个信息的概率越小,所含的信息量越大;在机器学习的数据中,如果一堆数据都是相同的种类,这个系统越稳定,那么这个系统信息熵越小,相反,如果一个系统中各个类别的数据量差不多,那么这个系统越混乱,这个系统的信息熵越大。
代码:
def cal_entropy(y):
counter = Counter(y)
sum_entropy = 0
for i in counter:
p = counter[i]/len(y)
entropy = -(p*np.log2(p))
sum_entropy += entropy
return sum_entropy
2、联合熵
对于两个离散随机变量X和Y,联合熵表示X,Y同时出现的平均信息量H(X,Y)=−∑x∈X∑y∈YP(x,y)log2P(x,y)其中P(x,y)表示X取x,Y取y时的概率 对于两个离散随机变量 X和Y,联合熵表示X,Y同时出现的平均信息量\\ H(X,Y)=-\sum_{x\in X}\sum_{y\in Y}P(x,y)\log_2P(x,y)\\ 其中P(x,y)表示X取x,Y取y时的概率 对于两个离散随机变量X和Y,联合熵表示X,Y同时出现的平均信息量H(X,Y)=−x∈X∑y∈Y∑P(x,y)log2P(x,y)其中P(x,y)表示X取x,Y取y时的概率


三、基尼系数
用于衡量数据不纯度或者混乱度的指标,帮助决策树确定分裂点,以便数据在经历分裂点后,变得尽可能纯净。
四、决策树分类
1、训练过程
就是不断确定分裂点,将数据分开的过程。这个过程通过找到使得信息增益最大的数据特征及其特征值来确定分裂点,将数据分别左子树和右子树,然后不断对左右子树递归这个过程,直至达到我们对决策树的要求(比如限定了决策树的层数,限制了叶子节点的最小数据量之类的),叶子节点中样本数最多的类别就为这个叶子节点所属的类别。这个过程的时间复杂度为:N * M * 树的深度。其中N是样本数、M是特征数
2、分裂点确定的具体细节
以第一个分裂点确定的过程为例,模型首先计算当前所有数据的信息熵,然后遍历模型的特征以及每个特征值的中间值(可以通过取某个特征下相邻大小的特征值的平均值,这样才可以根据这个值将数据分开),然后计算每种情况下的加权平均信息熵((len(x_left) * entropy_left + len(x_right) * entropy_right) / x.shape[0]),遍历完后找到分裂点的特征及取值。这样就完成了第一个分裂点的确定,然后对左右子树重复这个过程就确定了我们最终的决策树。
3、预测过程:一个输入的数据不断根据分裂点来找到自己的归属(叶子节点),时间复杂度为树的深度
4、代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
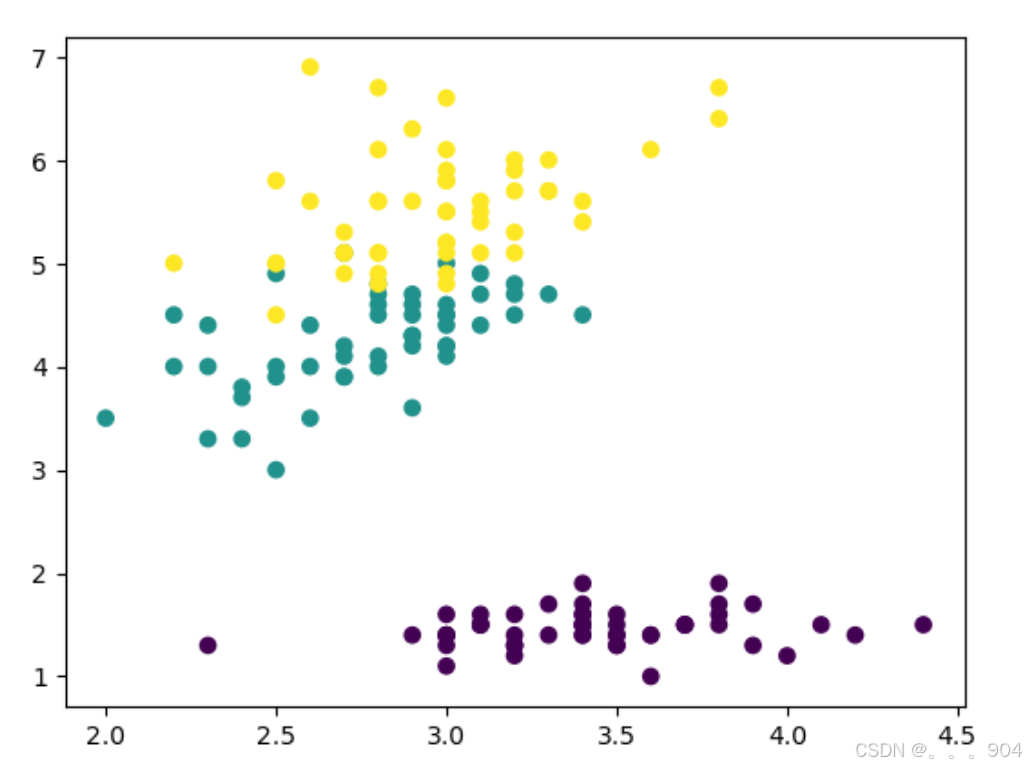
iris = load_iris()
data = iris.data
target = iris.target
X = data[:,1:3]
y = target
X.shape,y.shape
plt.scatter(X[:,0],X[:,1],c=y)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7)
dtree = DecisionTreeClassifier(max_depth=2,criterion='entropy')
dtree.fit(X_train,y_train)
y_predict = dtree.predict(X_test)
dtree.score(X_test,y_test)
from sklearn.tree import plot_tree
print(y_predict)
plot_tree(dtree)

自己实现决策树分类过程
from collections import Counter
counter = Counter(y)
# 计算信息熵
def cal_entropy(y):
counter = Counter(y)
sum_entropy = 0
for i in counter:
p = counter[i]/len(y)
entropy = -(p*np.log2(p))
sum_entropy += entropy
return sum_entropy
# 根据特征和特征值对数据进行分裂的函数
def split_data(X,y,feature,value):
X_left = X[X[:,feature]<value]
X_right = X[X[:,feature]>value]
y_left = y[X[:,feature]<value]
y_right = y[X[:,feature]>value]
return X_left,X_right,y_left,y_right
# 找到最佳分类的一个分裂节点
def find_best_split(X,y):
best_entropy = np.inf
best_dim = -1
best_value = -np.inf
depth_counter = 0
best_left_entropy = np.inf
best_right_entopy =np.inf
# 遍历每个特征和每个特征值
for dim in range(X.shape[1]):
sort_index = np.argsort(X[:,dim])
for i in range(X.shape[0]-1):
value = (X[sort_index[i],dim]+X[sort_index[i+1],dim])/2
X_left,X_right,y_left,y_right = split_data(X,y,dim,value)
left_entropy = cal_entropy(y_left)
right_entropy = cal_entropy(y_right)
# entropy = (len(y_left)*left_entropy+len(y_right)*right_entropy)/X.shape[0] # 加权熵
entropy = cal_entropy(y_left)+cal_entropy(y_right) # 计算这个特征和特征值下的总熵
if entropy<best_entropy:
best_dim = dim
best_value = value
best_entropy = entropy
best_left_entropy = left_entropy
best_right_entropy = right_entropy
return [best_dim,best_value,best_left_entropy,best_right_entropy,best_entropy]
def decision_tree(X, y, depth, splits):
# 终止条件:达到深度限制、数据量太少或所有样本属于同一类
if (depth == 0) or (len(X) < 2) or (len(np.unique(y)) == 1):
return np.argmax(np.bincount(y)) # 返回当前叶子节点的类别
best_entropy = cal_entropy(y)
best_dim = -1
best_value = None
best_left_entropy = np.inf
best_right_entropy = np.inf
# 遍历每个特征和特征值,寻找最佳分裂点
for dim in range(X.shape[1]):
sort_index = np.argsort(X[:, dim])
for i in range(X.shape[0] - 1):
value = (X[sort_index[i], dim] + X[sort_index[i + 1], dim]) / 2
X_left, X_right, y_left, y_right = split_data(X, y, dim, value)
if len(y_left) == 0 or len(y_right) == 0: # 避免空子集
continue
left_entropy = cal_entropy(y_left)
right_entropy = cal_entropy(y_right)
entropy = (len(y_left) * left_entropy + len(y_right) * right_entropy) / X.shape[0]
if entropy < best_entropy:
best_dim = dim
best_value = value
best_entropy = entropy
best_left_entropy = left_entropy
best_right_entropy = right_entropy
if best_dim == -1: # 如果没有找到有效划分,返回叶子节点
return np.argmax(np.bincount(y))
# 记录当前分裂点信息
splits.append({
'dim': best_dim,
'value': best_value,
'left_entropy': best_left_entropy,
'right_entropy': best_right_entropy,
'entropy': best_entropy
})
# 构建左右子树
X_left, X_right, y_left, y_right = split_data(X, y, best_dim, best_value)
decision_tree(X_left, y_left, depth - 1, splits)
decision_tree(X_right, y_right, depth - 1, splits)
return splits
五、决策树回归
决策树回归就是以叶子节点中数据的平均数作为模型预测的结果,有时候也可以根据实际情况,选择叶子节点中数据的其他指标,比如中位数等。
代码:
六、决策树剪枝
1、为什么要进行剪枝?
一是复杂度过高,因为训练复杂度为N * M * 树的深度,所以我们可以通过限制树的深度来减少训练复杂度
二是容易过拟合,如果不进行剪枝容易模型过拟合
2、如何剪枝
限制数的深度和广度。广度就是叶子节点的数量
代码:
clf_2 = DecisionTreeClassifier(max_depth=3,min_samples_split=10,min_samples_leaf=5)
七、决策树的优缺点
1、优点
可解释性强,通过决策树我们可以清晰地看出结果是如何得来的;
符合人类直观思维,很多时候我们也是按照决策树的方式来对一个事物进行判断的;
能够进行回归和分类任务;
能够处理多输出问题,比如我想要同时获取一个人的体重和身高,可以训练一个决策树,每个叶子节点都返回身高和体重的均值
2、缺点
容易产生过拟合,树的深度设置不恰当,容易过拟合;
决策边界只能是水平或者竖直方向,没有办法形成斜着的分割,

不稳定,容易受到噪声的影响,数据的微小变化可能形成完全不同的树。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)