【大模型后训练综述】A SURVEY ON POST-TRAINING OF LARGE LANGUAGE MODELS
大型语言模型的出现从根本上改变了自然语言处理领域,使其在对话系统到科学探索的广泛领域中成为不可或缺的工具。然而,其预训练架构在专业应用场景中常显露出局限性,包括受限的推理能力、伦理不确定性以及领域特定性能欠佳等问题。这些挑战催生了需要高级后训练语言模型来应对相关不足,例如OpenAI-o1/o3与DeepSeek-R1(统称为大型推理模型)。本文首次对后训练语言模型进行全面综述,系统追溯其在五大核

摘要
大型语言模型的出现从根本上改变了自然语言处理领域,使其在对话系统到科学探索的广泛领域中成为不可或缺的工具。然而,其预训练架构在专业应用场景中常显露出局限性,包括受限的推理能力、伦理不确定性以及领域特定性能欠佳等问题。这些挑战催生了需要高级后训练语言模型来应对相关不足,例如OpenAI-o1/o3与DeepSeek-R1(统称为大型推理模型)。本文首次对后训练语言模型进行全面综述,系统追溯其在五大核心范式中的演进路径:微调范式提升任务特定精度;对齐范式确保伦理一致性并契合人类偏好;推理范式在多步推断方面取得进展(尽管面临奖励设计挑战);效率范式在复杂度增长中优化资源利用;集成与适应范式将能力扩展至多模态领域并应对连贯性问题。通过梳理从ChatGPT的基础对齐策略到DeepSeek-R1创新推理突破的发展轨迹,我们阐释了后训练语言模型如何利用数据集缓解偏见、深化推理能力、增强领域适应性。本研究的贡献包括:开创性地整合后训练语言模型演进脉络,建立技术方法与数据集的系统分类体系,并提出强调大型推理模型在提升推理能力与领域灵活性作用的战略路线图。作为该领域首个具备此广度的综述,本工作不仅整合了近期后训练语言模型的重要进展,更为未来研究构建了严谨的学术框架,推动大型语言模型在科学与社会应用场景中实现精准性、伦理稳健性与功能多样性的协同发展。
关键词 后训练,大语言模型,微调,对齐,推理,效率。
项目
1.引言
人们普遍认为,真正的智力赋予我们推理能力,使我们能够检验假设,并为未来的可能性做好准备。 ——让·卡拉法《何为智力?》(1994)
语言模型(LMs)[1, 2] 代表了一种旨在模拟和生成人类语言的复杂计算框架。这些模型通过使机器能够以高度模仿人类认知的方式理解、生成并与人类语言进行交互,彻底变革了自然语言处理(NLP)领域 [3]。与人类通过与情境环境的互动和接触自然而然地获得语言技能不同,机器必须经过大量数据驱动的训练才能发展出类似的能力 [4]。这构成了一个重大的研究挑战,因为要使机器能够理解并生成人类语言,同时进行自然且符合情境的对话,不仅需要巨大的计算资源,还需要精炼的模型开发方法 [5, 6]。
以GPT-3 [7]、InstructGPT [8]和GPT-4 [9]为代表的大型语言模型(LLMs)的出现,标志着语言模型发展进入了一个变革性阶段。这些模型以其庞大的参数量与先进的学习能力为特征,旨在从海量数据中捕捉复杂的语言结构、语境关系及细微模式。这使得LLMs不仅能够预测后续词汇,还能在翻译、问答、摘要生成等多种任务中生成连贯且语境适配的文本。LLMs的发展已引发显著的学术关注 [5, 6, 10],其开发过程主要可分为两个阶段:预训练与后训练。
预训练。预训练的概念源于计算机视觉任务中的迁移学习[10]。其主要目标是通过大规模数据集开发通用模型,从而便于针对不同下游应用进行微调。预训练的一个显著优势是能够利用任何未标注的文本语料库,从而提供丰富的训练数据来源。然而,早期的静态预训练方法,如神经网络语言模型[11]和Word2vec[12],难以适应不同的文本语义环境,这促使了BERT[2]和XLNet[13]等动态预训练技术的发展。BERT通过利用Transformer架构,并在大规模未标注数据集上采用自注意力机制,有效解决了静态方法的局限性。这项研究确立了"预训练与微调"的学习范式,启发了后续众多研究,并催生了包括GPT-2[14]和BART[15]在内的多种架构。
后训练。后训练是指在模型完成预训练后采用的技术与方法,旨在针对特定任务或用户需求对模型进行优化和适配。随着拥有1750亿参数的GPT-3[7]的发布,后训练领域迎来了显著的关注度提升与技术创新浪潮。多种提升模型性能的方法相继涌现,包括:通过标注数据集或特定任务数据调整模型参数的微调技术[16,17];优化模型以更好契合用户偏好的对齐策略[18,19,20];使模型能够融合领域特定知识的知识适应技术[21,22];以及提升模型逻辑推理与决策能力的推理改进方法[23,24]。这些技术统称为后训练语言模型(PoLMs),并催生了诸如GPT-4[9]、LLaMA-3[25]、Gemini-2.0[26]和Claude-3.5[27]等模型的诞生,标志着大语言模型能力取得了实质性进展。然而,后训练模型通常难以在不重新训练或进行显著参数调整的情况下适应新任务,这使得后训练模型的开发成为当前活跃的研究领域。
正如所述,预训练语言模型(PLMs)的主要目标是提供通用知识与能力,而专业语言模型(PoLMs)则侧重于将这些模型适配至特定任务与需求。此类适配的一个显著案例是最新的大型语言模型DeepSeek-R1 [28],它展现了专业语言模型在增强推理能力、对齐用户偏好以及提升跨领域适应性方面的演进[29]。此外,日益增多的开源大型语言模型(如LLaMA [30]、Gemma [31]和Nemotron [32])与领域特定的大规模数据集(例如PromptSource [33]和Flan [34])正在推动这一发展趋势。学术界研究人员与行业从业者正形成开发专业领域语言模型的趋势。这一趋势凸显了该领域日益认识到定制化适配的重要性。
现有文献中,预训练模型已得到广泛讨论与综述[10,35,36,37],而训练后模型却鲜有系统性的梳理。为推进相关技术发展,必须深入审视现有研究成果,以识别关键挑战、研究空白及未来改进方向。本综述旨在通过构建一个结构化框架来梳理训练后研究的演进脉络,从而填补这一空白。如图1所示,本文系统探究了训练后处理的多个阶段,并特别聚焦于从ChatGPT到DeepSeek所采用的关键技术。这些技术涵盖广泛的方法论,包括微调、大语言模型对齐、推理能力增强以及效率优化等。图中蓝色部分着重突出了DeepSeek所采用的训练后方法集合,彰显了其通过创新策略成功适应用户偏好与领域特定需求的实践路径。
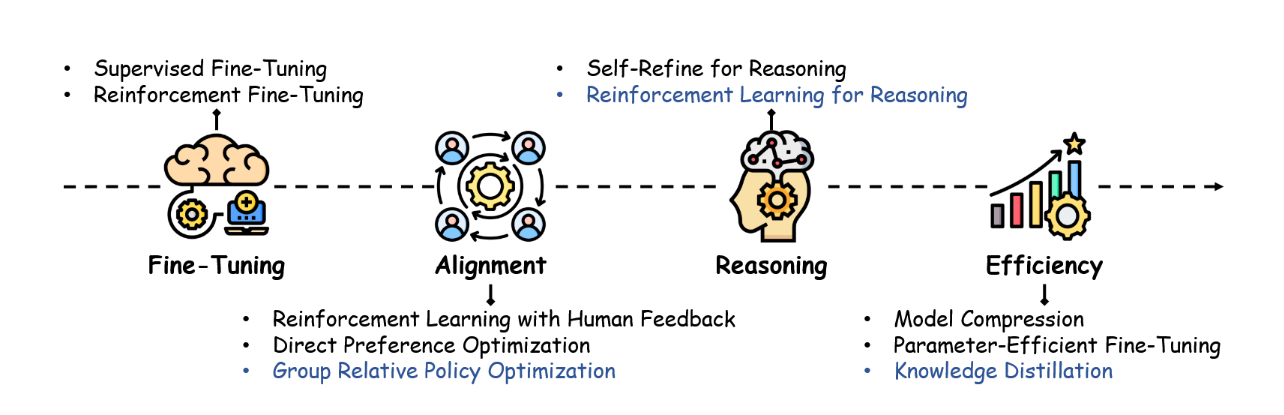
图1:大型语言模型后训练技术的演进路径,展示了从初始方法到先进方法的发展过程,重点标注了DeepSeek模型贡献(以蓝色高亮显示)。
1.1 主要贡献
本文首次对后训练大语言模型(PoLMs)进行了全面综述,对领域最新进展进行了系统化、结构化的深入探讨。过往综述通常聚焦于大语言模型发展的特定方面,例如偏好对齐[38]、参数高效微调[39]以及大语言模型基础技术[40],其关注点往往局限于狭窄的子领域。相比之下,本综述采用整体性视角,完整梳理了后训练阶段普遍采用的核心技术,并对其进行了系统分类。此外,如图2所示,我们深入研究了与这些方法紧密相关的数据集与实际应用场景,并指出了当前存在的开放性问题及未来研究的潜在方向。本综述的主要贡献如下:
• 综合性历史综述。我们首次对后训练语言模型(PoLMs)进行了深入综述,追溯其从ChatGPT最初基于人类反馈的强化学习(RLHF)到DeepSeek-R1创新的冷启动强化学习方法的演进历程。本综述涵盖关键技术(即微调、对齐、推理、效率、集成与适应),分析其发展脉络及相关挑战,如计算复杂性和伦理考量。通过将这一发展进程呈现为连贯的叙事,并辅以关键文献,我们为研究人员提供了近年后训练领域演进的全景概览,可作为该领域的基础性参考资料。
• 结构化分类体系与框架。我们提出了一个结构化分类体系(如图2所示),将后训练方法划分为五个明确类别,将数据集组织为七种类型,同时在专业、技术和交互三大应用领域内构建应用框架。该框架阐明了这些方法间的相互关联与实际影响,为其发展提供了系统化视角。通过提供清晰定义的类别与分析性见解,我们提升对初学者与专家群体的可及性与理解度,构建一套用于驾驭后训练研究复杂性的综合指南。
• 未来方向。我们着重指出新兴趋势,特别是以o1[41]和DeepSeek-R1[28]为代表的大型推理模型(LRMs)的兴起,这些模型利用大规模强化学习来拓展推理的边界。我们强调,持续的进步对于进一步提升推理能力与领域适应性至关重要。我们的分析指出了关键挑战,包括可扩展性限制、伦理对齐风险以及多模态融合障碍。我们提出了诸如自适应强化学习框架和公平性感知优化等研究路径。这些方向旨在推动后训练领域向前发展,确保大语言模型实现更高的精确度与可信度,以满足未来需求。
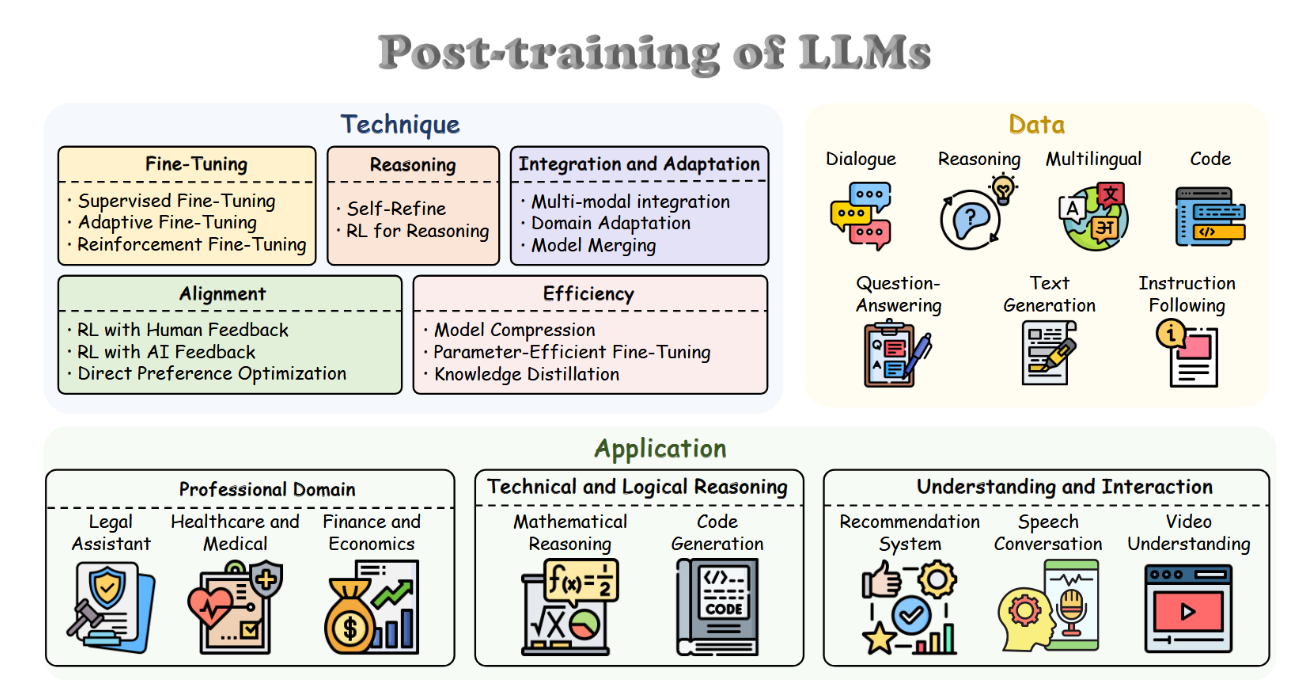
图2:本研究所综述的后训练技术结构概览,展示了方法论、数据集与应用场景的组织框架。
1.2 组织结构
本综述旨在系统性地全面探讨后训练语言模型(PoLMs),涵盖其历史演进、方法论、数据集、应用及未来发展方向。第2节概述PoLMs的历史背景。第3节探讨微调方法,包括第3.1节的有监督微调(SFT)与第3.3节的强化微调(RFT)。第4节讨论对齐技术,涵盖第4.1节的人类反馈强化学习(RLHF)、第4.2节的AI反馈强化学习(RLAIF)以及第4.3节的直接偏好优化(DPO)。第5节聚焦推理能力,包含第5.1节的自我优化方法及第5.2节的强化学习推理。第6节综述效率提升方法,包括第6.1节的模型压缩、第6.2节的参数高效微调(PEFT)与第6.3节的知识蒸馏。第7节研究集成与适配,涉及多模态方法、领域自适应及模型融合。第8节评述后训练中使用的数据集。第9节探讨大语言模型的应用场景。第10节评估现存挑战与未来方向。最后,第11节以总结与研究展望作为结语。
2 概述
2.1 PoLM 的发展历史
大型语言模型(LLM)的进展构成了自然语言处理(NLP)领域的关键篇章,而后训练方法则是推动其从通用的预训练架构演变为专业化、任务自适应系统的关键催化剂。本节梳理了后训练语言模型(PoLM)的历史脉络,追溯其从以BERT [2]和GPT [1]为代表的奠基性预训练里程碑,到以o1 [41]和DeepSeek-R1 [28]等当代模型所体现的复杂后训练范式的发展历程。如图3所示,这一演进反映了从建立广泛语言能力,到增强任务特定适应性、伦理对齐、推理精细化以及多模态集成的转变,标志着LLM能力的一次变革性旅程。
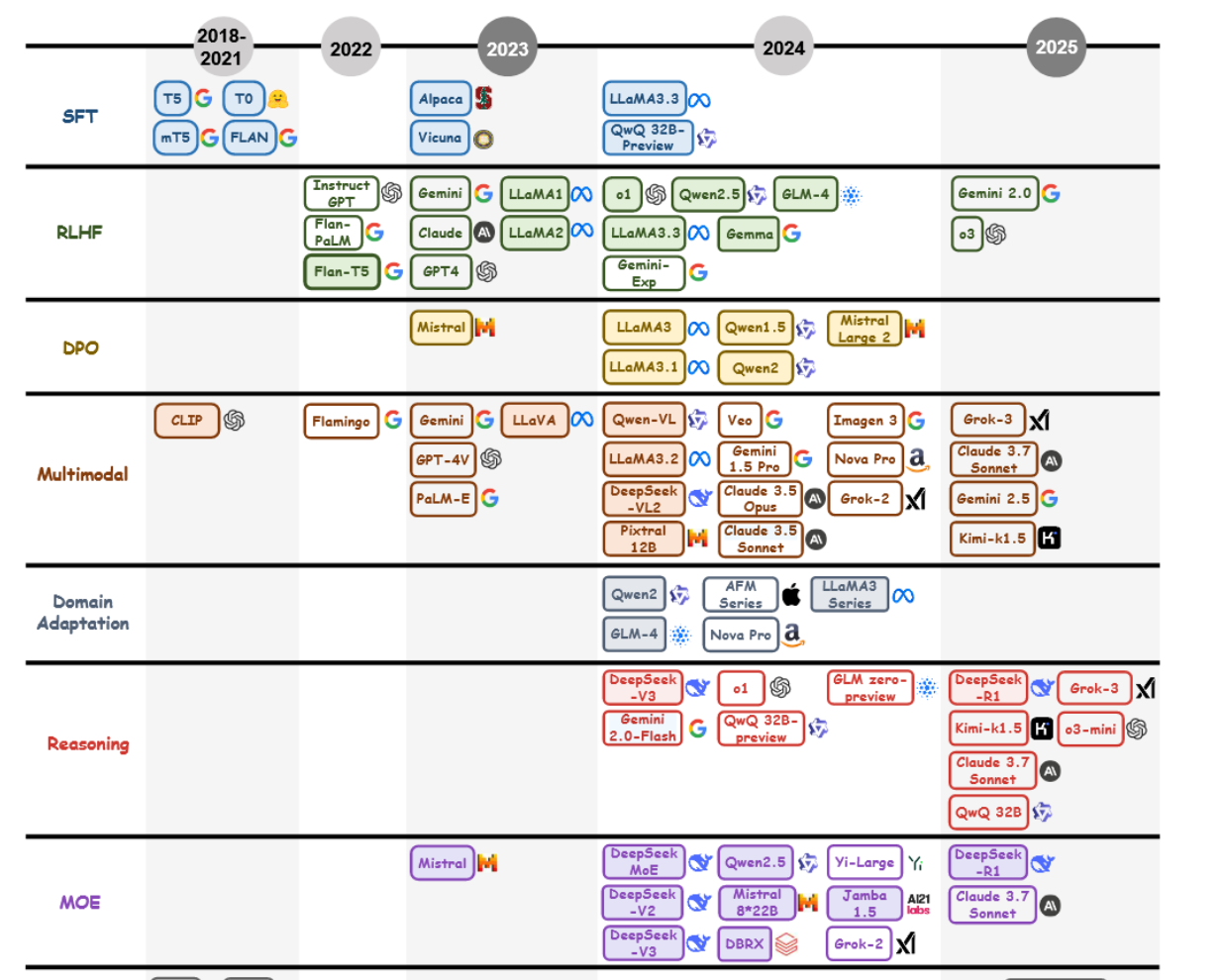
图 3:大语言模型后训练技术发展时间线(2018–2025年),描绘了其历史演进过程中的关键里程碑。
现代PoLMs的历史发端于2018年的预训练革命,其标志性事件是BERT[2]和GPT[1]的发布,它们重新定义了自然语言处理的基准。BERT采用基于Transformer架构和自注意力机制的双向自编码框架,在捕捉上下文相互依赖性方面表现出色,适用于问答等任务;而GPT的自回归设计则优先考虑生成连贯性,为文本生成确立了先例。这些模型确立了"预训练与微调"范式,随后在2019年通过T5[42]得到进一步改进。T5将多样化的任务统一到文本到文本框架下,促进了多任务学习,并为后续的训练后优化奠定了坚实基础。
2020年起,预训练语言模型(PoLMs)的发展格局开始发生深刻演变,这主要源于业界对高效适配多任务与小数据场景的迫切需求。以前缀调优[43]与提示调优[44]为代表的早期创新提出了轻量级适配策略,通过修改模型输入而非重训练整体架构,实现了多任务灵活性,在节约计算资源的同时拓宽了模型适用范围。这一时期亦见证了以人为中心的优化转向:2021年出现的基于人类反馈的强化学习(RLHF)技术[45]具有里程碑意义,该技术利用人类评估使模型输出与主观偏好对齐,显著提升了对话场景中的实用价值。至2022年,随着近端策略优化(PPO)方法的应用[46],RLHF技术趋于成熟,其对齐稳定性得到改善,并降低了对噪声反馈的过拟合风险。2022年底发布的ChatGPT[9]集中体现了这些进展,它不仅展示了RLHF在创建响应灵敏、贴合用户需求的大语言模型方面的变革潜力,更推动了PoLMs研究的热潮。与此同时,思维链(CoT)提示技术[47]作为一种推理增强策略崭露头角,通过引导模型在复杂任务中显式表达中间推理步骤,显著提升了逻辑推理与问题解决领域的透明度与准确性。
2022至2024年间,专业化语言模型(PoLMs)的发展趋于多元化,聚焦于领域特异性、伦理鲁棒性与多模态融合,反映了大规模语言模型(LLM)优化路径日益精细化。领域自适应技术在此期间兴起,例如检索增强生成(RAG)[48],通过整合外部知识库,能在无需完整重训练的情况下为专业领域生成语境丰富的输出——这对需要最新信息的专业应用至关重要。伦理对齐研究持续深化,2023年提出的直接偏好优化(DPO)[49]简化了人类反馈强化学习(RLHF),通过直接依据人类偏好优化模型输出,绕过中间奖励建模环节,从而提升效率与鲁棒性。与此同时,多模态能力探索取得显著进展:PaLM-E [50] 和 Flamingo [51] 等模型率先实现视觉-语言融合,随后 BLIP-2 [52] 和 LLaVA [53] 将此类技术拓展至医学影像等更广泛领域。效率创新与上述发展同步推进,其中专家混合(MoE)架构尤为突出:谷歌于2022年提出的 Switch-C Transformer [54] 实现了2048个专家间1.6万亿参数的稀疏激活,而 Mixtral [55] 则进一步优化该范式,在扩展性与性能间取得平衡。此期间的推理能力增强技术——如自我博弈 [56] 及蒙特卡洛树搜索(MCTS)与思维链(CoT)的结合 [57]——通过模拟迭代式推理路径,显著强化了LLM的决策能力,为面向高级推理的模型发展奠定基础。
一项重要的架构进展随着混合专家(MoE)模型的兴起而展开。这类模型区别于传统的密集架构,通过动态激活选择性参数子集来优化计算效率,同时能够容纳庞大的参数量级。该范式由谷歌的Switch-C Transformer[54]于2022年首创,其1.6万亿参数分布于2048位专家,这一突破性方法在资源需求与性能提升间实现了平衡。后续迭代模型如Mixtral[55]和DeepSeek V2.5[58]——后者利用2360亿总参数(其中210亿参数通过160位专家动态激活)——进一步优化了此框架,在LMSYS基准测试中取得领先成果,并证明稀疏混合专家架构在可扩展性和效能上均可媲美稠密模型。这些进展标志着大型语言模型向效率优先的推理语言模型转型,使其能够以更低计算开销处理复杂任务,这对拓宽其实用范围具有关键意义。至2025年,DeepSeek-R1[28]成为推理语言模型创新的里程碑,它摒弃传统监督微调依赖,转而采用思维链推理与探索性强化学习策略。以融合自我验证、反思和扩展思维链生成的DeepSeek-R1-Zero为例,该模型在开放式研究范式下验证了强化学习驱动的推理激励机制,并通过知识蒸馏技术[28]将复杂推理模式从大型架构迁移至小型架构。该方法不仅相较独立强化学习训练展现出更优性能,更预示着以推理为核心的可扩展大型语言模型范式即将到来,有望解决后训练方法中长期存在的计算效率与任务适应性挑战。
2.2 基于语言模型的优化方法公式基础
2.2.1 策略优化原理
近端策略优化算法[46]是强化学习领域的一项关键技术,在人类反馈强化学习[45]等场景中尤为重要,因其能在训练过程中保持稳定性和效率。该算法通过限制策略更新的幅度,确保模型行为的变化是渐进且受控的,从而防止性能出现灾难性偏移。这一特性在大规模语言模型微调过程中至关重要,因为激进的策略更新可能导致模型产生不可预测或不符合预期的行为。
定义。在PPO框架下,状态 s t ∈ S s_t ∈ S st∈S表示时间t时的环境,包含模型决策所需的所有相关信息。动作 a t ∈ A ( s t ) a_t ∈ A(s_t) at∈A(st)表示模型在给定状态st下所作的选择,该动作是模型决策序列的一部分。执行动作后,智能体会获得奖励 r t ∈ R r_t ∈ R rt∈R,作为来自环境的反馈信号,表明所采取动作的成功与否。优势函数 A π ( s , a ) A^π(s, a) Aπ(s,a)衡量在当前策略π下,于状态s采取动作a相比该状态下动作的期望值具有多少优势。其正式定义为动作价值函数 Q π ( s , a ) Q^π(s, a) Qπ(s,a)与状态价值函数 V π ( s ) V^π(s) Vπ(s)之差,二者定义如下:
A π ( s , a ) = Q π ( s , a ) − V π ( s ) , A^\pi(s,a)=Q^\pi(s,a)-V^\pi(s), Aπ(s,a)=Qπ(s,a)−Vπ(s),
其中 Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a) 表示在状态 s 下采取行动 a 并遵循策略 π \pi π 所获得的预期累积奖励,而 ( V π ( s ) V^{\pi}(s) Vπ(s) ) 表示从状态 ( s ) 开始并遵循策略 ( π \pi π ) 所获得的预期累积奖励。这两个函数均考虑了未来奖励,并通过折扣因子 ( γ \gamma γ ) 进行折现。
策略更新。PPO算法基于优势函数进行渐进式更新,以优化策略 π θ π_θ πθ。策略更新采用以下裁剪目标函数实现:
L C L I P ( θ ) = E ^ t [ min ( r t ( θ ) A ^ t , c l i p ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] , L^{CLIP}(\theta)=\hat{\mathbb{E}}_t\left[\min\left(r_t(\theta)\hat{A}_t,\mathrm{clip}\left(r_t(\theta),1-\epsilon,1+\epsilon\right)\hat{A}_t\right)\right], LCLIP(θ)=E^t[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)],
其中 ( r t ( θ ) r_t(\theta) rt(θ) ) 表示在给定状态下,当前策略 ( π θ \pi_\theta πθ ) 选择动作 ( a t a_t at ) 的概率与旧策略 ( π θ old \pi_{\theta_{\text{old}}} πθold ) 选择同一动作的概率之比。该比率定义为:
r t ( θ ) = π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) . r_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\mathrm{old}}}(a_t|s_t)}. rt(θ)=πθold(at∣st)πθ(at∣st).
术语 A ˆ t Aˆt Aˆt表示时间步t的估计优势值,裁剪函数 c l i p ( r t ( θ ) , 1 − ε , 1 + ε ) clip(r_t(θ), 1−ε, 1+ε) clip(rt(θ),1−ε,1+ε)通过超参数ε将策略更新限制在安全范围内。该裁剪机制确保更新不会过度偏离先前策略,从而在训练过程中保持稳定性。
价值函数更新。价值函数 V φ V_φ Vφ用于估计在策略 π θ π_θ πθ下从给定状态 s t s_t st出发的预期累积奖励。为确保价值函数提供准确估计,需通过最小化预测值与实际奖励之间的均方误差对其进行优化:
ϕ k + 1 = arg min ϕ E s t ∼ π θ k [ ( V ϕ ( s t ) − R ( s t ) ) 2 ] , \phi_{k+1}=\arg\min_\phi\mathbb{E}_{s_t\thicksim\pi_{\theta_k}}\left[\left(V_\phi(s_t)-R(s_t)\right)^2\right], ϕk+1=argϕminEst∼πθk[(Vϕ(st)−R(st))2],
其中 R ( s t ) R(s_t) R(st) 是从状态 s t s_t st 实际获得的累积奖励, V φ ( s t ) V_φ(s_t) Vφ(st) 是当前策略下的估计价值。目标是调整参数 φ,以最小化预测奖励与实际奖励之间的差异,从而提升价值函数估计的准确性。
2.2.2 基于人类反馈的强化学习原理
基于人类反馈的强化学习(RLHF)是一种通过在学习过程中利用人类生成反馈,使模型与人类偏好保持一致的关键方法。该方法引入了一个能明确捕获人类输入的奖励函数,使模型能够更好地适应用户偏好和实际应用场景。
定义。在RLHF中,语言模型 ρ 在词汇表 Σ 的记号序列上生成一个概率分布。该模型 ρ 从输入空间 X = Σ≤m 中生成一个记号序列 x₀, x₁, …, xₙ₋₁,其中每个记号都条件依赖于之前的记号。模型的输出由以下条件概率分布定义:
ρ ( x 0 ⋯ x n − 1 ) = ∏ 0 ≤ k < n ρ ( x k ∣ x 0 ⋯ x k − 1 ) . \rho\left(x_0\cdots x_{n-1}\right)=\prod_{0\leq k<n}\rho\left(x_k\mid x_0\cdots x_{k-1}\right). ρ(x0⋯xn−1)=0≤k<n∏ρ(xk∣x0⋯xk−1).
模型ρ在由输入空间X、X上的数据分布D及输出空间Y = Σ≤n定义的任务上进行训练。例如在文本摘要任务中,如文献[16]所示,GPT-2模型[14]通过RLHF方法进行训练,该任务基于CNN/DailyMail[59]和TL;DR[60]等数据集预测文本摘要。
目标函数。策略π是一个与原始模型ρ结构相同的语言模型。初始时,策略π被设置为等于ρ。其目标是通过优化策略,最大化输入输出对(x, y)的期望奖励R(x, y)。奖励函数R(x, y): X × Y → R为每个输入输出对分配一个标量值,最优策略π∗通过求解以下最大化问题获得:
π ∗ = max π E [ R ] = E x ∼ D , y ∼ π ( ⋅ ∣ x ) [ R ( x , y ) ] . \pi^*=\max_\pi\mathbb{E}[R]=\mathbb{E}_{x\sim\mathcal{D},y\sim\pi(\cdot|x)}[R(x,y)]. π∗=πmaxE[R]=Ex∼D,y∼π(⋅∣x)[R(x,y)].
该目标函数代表一个标准强化学习问题,模型通过与环境互动学习最大化期望奖励,并在人类反馈的指导下进行优化。
2.2.3 直接偏好优化原理
直接偏好优化(DPO)在RLHF的基础上更进一步,它直接基于人类偏好来优化模型输出,这些偏好通常以成对比较的形式表达。DPO省去了传统奖励函数,转而通过最大化基于偏好的奖励来优化模型行为。
目标函数。我们沿用先前方法[61, 62, 63]中的相同强化学习目标,其基于一般奖励函数r。KL约束奖励最大化目标的最优解由下式给出:
π r ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) , \pi_r(y\mid x)=\frac{1}{Z(x)}\pi_\mathrm{ref}(y\mid x)\exp\left(\frac{1}{\beta}r(x,y)\right), πr(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y)),
其中Z(x)是配分函数,用于确保在所有可能动作上的输出归一化。即使使用真实奖励函数r∗的最大似然估计rφ时,配分函数Z(x)仍可被近似计算,从而简化优化过程。该公式通过基于人类反馈直接调整策略,实现了更高效的偏好优化。
偏好模型。采用对两个输出y1和y2间偏好进行建模的布拉德利-特里模型,最优策略 π ∗ π^∗ π∗满足以下偏好模型:
p ∗ ( y 1 ≻ y 2 ∣ x ) = 1 1 + exp ( β log π ∗ ( y 2 ∣ x ) π r e f ( y 2 ∣ x ) − β log π ∗ ( y 1 ∣ x ) π r e f ( y 1 ∣ x ) ) , p^*(y_1\succ y_2\mid x)=\frac{1}{1+\exp\left(\beta\log\frac{\pi^*(y_2|x)}{\pi_{\mathrm{ref}}(y_2|x)}-\beta\log\frac{\pi^*(y_1|x)}{\pi_{\mathrm{ref}}(y_1|x)}\right)}, p∗(y1≻y2∣x)=1+exp(βlogπref(y2∣x)π∗(y2∣x)−βlogπref(y1∣x)π∗(y1∣x))1,
其中 p ∗ ( y 1 ≻ y 2 ∣ x ) p^*(y_1\succ y_2\mid x) p∗(y1≻y2∣x)表示在给定输入 x 的情况下,人类更偏好输出 y1 而非 y2 的概率。此方法有效地将人类偏好融入了模型的优化过程。
2.2.4 GRPO原则
组相对策略优化(GRPO)算法是强化学习中近端策略优化(PPO)算法的一种变体,首次在深度求索先前的工作《DeepSeekMath:突破开源语言模型数学推理的极限》[64]中被提出。GRPO省去了评论家模型,转而使用群体分数来估计基线值,相比PPO显著降低了训练资源消耗。
定义。GRPO与PPO算法最显著的区别在于优势函数的计算方法。如第2.2.1节公式1所示,PPO中优势函数 A π ( s , a ) A^π(s, a) Aπ(s,a)的值源于Q值与V值之差。
目标函数。具体而言,对于每个问题q,GRPO从旧策略 π θ o l d π_{θ_{old}} πθold中采样一组输出{o1, o2, . . . , oG},然后通过最大化以下目标来优化策略模型:
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , c l i p ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ϵ , 1 + ϵ ) A ^ i , t ] ( 8 ) − β D K L [ π θ ∥ π r e f ] } , \begin{aligned}\mathcal{J}_{GRPO}(\theta)&=\mathbb{E}[q\sim P(Q),\{o_i\}_{i=1}^G\sim\pi_{\theta_{\mathrm{old}}}(O|q)]\\&\frac{1}{G}\sum_{i=1}^G\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}\left\{\min\left[\frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,t}|q,o_{i,<t})}\hat{A}_{i,t},\mathrm{clip}\left(\frac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\theta_{\mathrm{old}}}(o_{i,t}|q,o_{i,<t})},1-\epsilon,1+\epsilon\right)\hat{A}_{i,t}\right]\right.\quad(8)\\&-\beta D_{KL}[\pi_\theta\parallel\pi_{\mathrm{ref}}]\},\end{aligned} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ϵ,1+ϵ)A^i,t](8)−βDKL[πθ∥πref]},
其中ε和β为超参数, A ^ i , t Â_{i,t} A^i,t是根据仅在各组内部输出结果的相对奖励计算的优势值,具体细节将在5.2小节详述。
3.用于微调的后训练语言模型
微调是使预训练大语言模型适应特定任务的核心方法,通过有针对性的参数调整来优化模型能力。该过程利用标注数据或特定任务数据集来提升模型性能,弥合通用预训练与领域特定需求之间的差距。本章将探讨三种主要的微调范式:监督微调(§3.1),其采用标注数据集以增强任务特定准确性;自适应微调(§3.2),通过指令微调和基于提示的方法定制模型行为;以及强化微调(§3.3),其融合强化学习技术,基于奖励信号迭代优化输出,通过动态交互实现持续改进。
3.1 监督式微调
监督微调(SFT)[45]通过利用特定任务的标注数据集,使预训练大语言模型适应具体任务。与依赖指令提示的指令微调不同,SFT直接使用标注数据调整模型参数,从而生成既精确又贴合语境、同时保留广泛泛化能力的模型。SFT弥合了预训练阶段所编码的广阔语言知识与目标应用场景的细微需求之间的鸿沟[36]。预训练大语言模型通过接触海量语料库习得通用语言模式,从而减少了对大量领域特定数据进行微调的依赖。模型选择至关重要:在数据有限、资源受限的环境中,较小模型(如T5[42])表现出色;而更大模型(如GPT-4[9])则凭借其卓越能力,在复杂且数据丰富的任务中表现优异。
3.1.1 监督微调数据集准备
构建高质量的指令微调数据集是一个多层面过程,对微调成功至关重要。指令微调数据集构建。指令微调数据集通常结构化为 D = { ( I k , X k ) } k = 1 N D = \{(I_k, X_k)\}^N _{k=1} D={(Ik,Xk)}k=1N,其中 I k I_k Ik 是指令, X k X_k Xk 是其对应的实例。这种配对方式使大语言模型能够识别任务特定模式并生成相关输出。诸如 Self-Instruct [86] 等方法通过合成新颖的指令-输出对来丰富多样性,并利用 ROUGE-L [87] 等指标过滤重复项以保持多样性。
SFT数据集筛选。筛选环节确保最终数据集中仅保留高质量的指令-实例对。通过筛选函数r(·)评估每对数据 ( I k , X k ) (I_k, X_k) (Ik,Xk)的质量,从而得到一个精校子集D′:
D ′ = { ( I k , X k ) ∈ D ∣ r ( I k , X k ) ≥ τ } , \mathcal{D}^{\prime}=\begin{Bmatrix}(I_k,X_k)\in\mathcal{D}\mid r(I_k,X_k)\geq\tau\end{Bmatrix}, D′={(Ik,Xk)∈D∣r(Ik,Xk)≥τ},
其中τ为用户定义的质量阈值。例如,指令遵循难度(IFD)指标[88]旨在量化给定指令引导模型生成预期响应的有效性程度,其函数表达式为:
r θ ( Q , A ) = ∑ i = 1 N log P ( w i A ∣ Q , w 1 A , … , w i − 1 A ; θ ) ∑ i = 1 N log P ( w i A ∣ w 1 A , … , w i − 1 A ; θ ) , r_\theta(Q,A)=\frac{\sum_{i=1}^N\log P\left(w_i^A\mid Q,w_1^A,\ldots,w_{i-1}^A;\theta\right)}{\sum_{i=1}^N\log P\left(w_i^A\mid w_1^A,\ldots,w_{i-1}^A;\theta\right)}, rθ(Q,A)=∑i=1NlogP(wiA∣w1A,…,wi−1A;θ)∑i=1NlogP(wiA∣Q,w1A,…,wi−1A;θ),
其中 Q 表示指令,A 是期望的响应,θ 代表模型的可学习参数。该指标通过对比模型在有无指令的情况下生成响应的可能性,从而为标准化的度量提供了依据,以评估指令对响应生成的有效促进作用。未达到选定 IFD 阈值的指令-实例对将被排除,最终得到精炼数据集 D ′ D' D′。
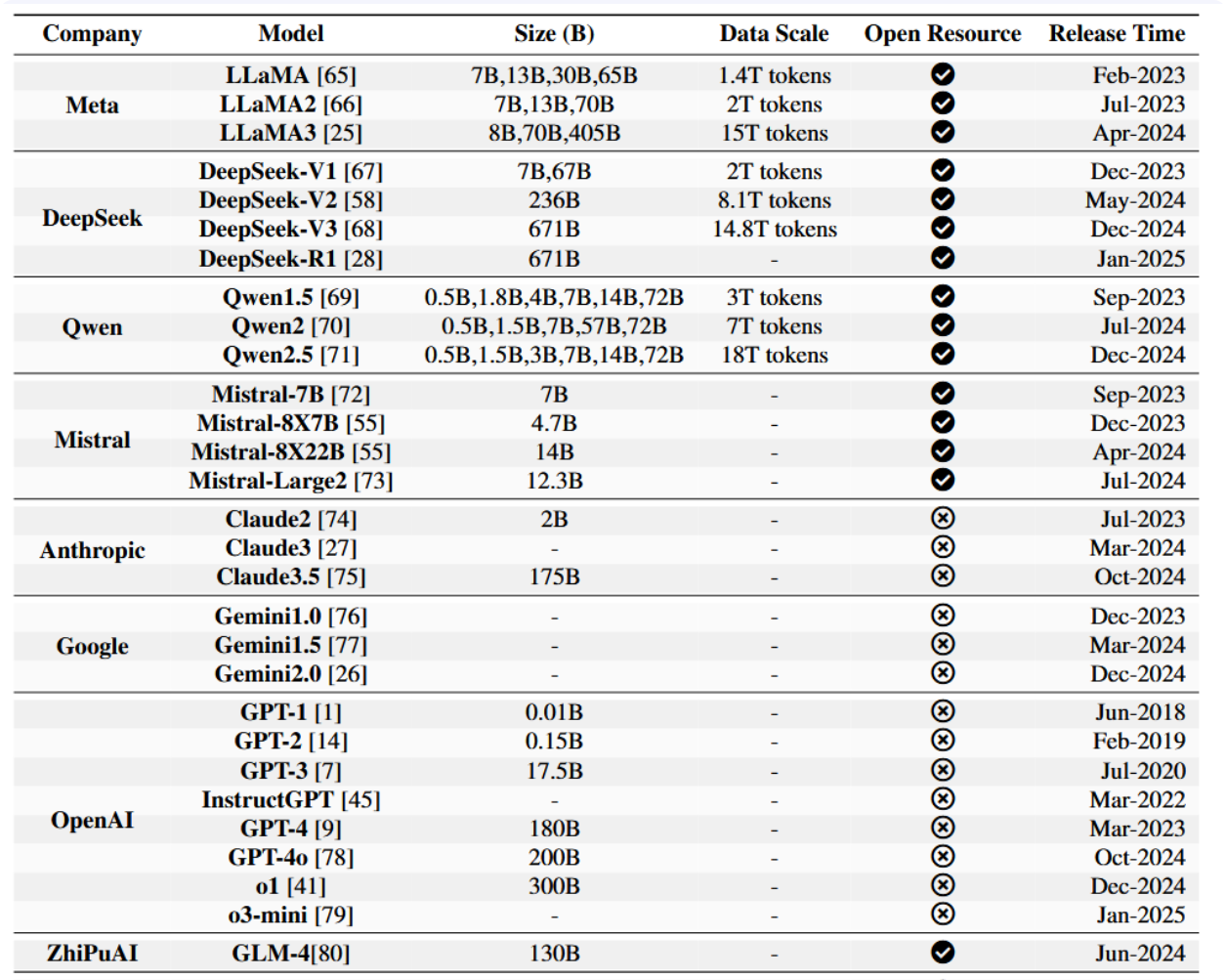
表1:各机构预训练大语言模型发布概览(2018–2025)。本表详列了Meta、DeepSeek、OpenAI等机构的关键模型,涵盖其参数量、已公开的训练数据规模、开源状态及发布时间线。开源状态以标记表示对研究社区公开可访问的模型,标记则表示闭源的专有模型。
指令精调数据集评估
评估指令精调数据集时,需选取一个高质量子集(称为评估集 D e v a l D_{eval} Deval)作为模型性能的基准。该子集可从经人工筛选的数据集 D ′ D' D′ 中抽样获得,或使用独立数据部分以确保评估的公正性。传统的指令精调评估方法(如小样本 GPT [7] 与微调策略 [89])通常资源消耗较大,而指令挖掘方法 [90] 则提供了一种更高效的替代方案。指令挖掘通过线性质量规则与一系列指标(如响应长度、平均奖励模型得分 [65])来衡量数据集质量,进而分析这些指标与数据集整体质量之间的相关性。
3.1.2 监督微调流程
如图4所示,数据集准备就绪后,微调过程始于一个预训练的大型语言模型,该模型通常通过在大规模原始数据集上进行无监督或自监督预训练获得。此预训练阶段的目标是获取适用于各类任务的通用特征表示[36]。随后,在微调阶段,使用特定任务的标注数据调整模型参数,使模型符合特定应用的要求。该阶段常用的目标函数是交叉熵损失。对于包含N个样本和C个类别的分类任务,其表达式为:
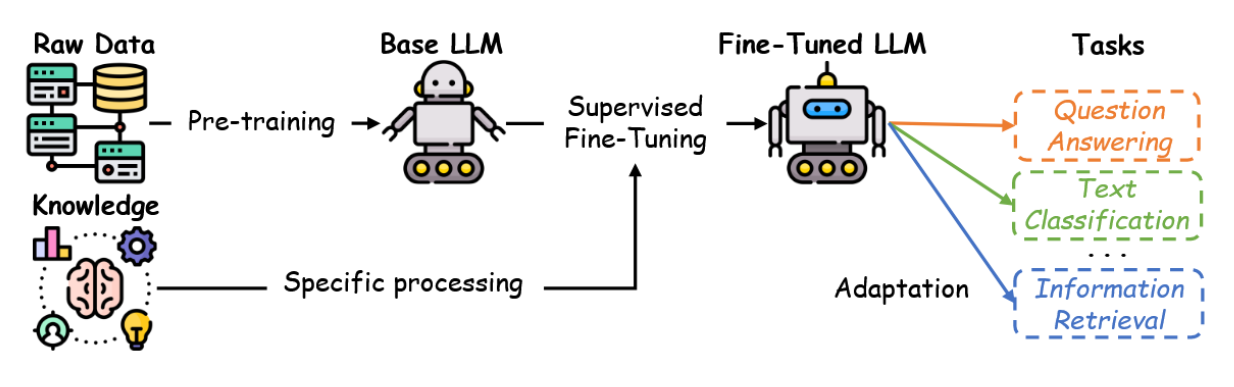
图4:监督式微调流程。
L f i n e − t u n e ( θ ) = − 1 N ∑ i = 1 N ∑ j = 1 C y i j log P ( y j ∣ x i ; θ ) , L_{\mathrm{fine-tune}}(\theta)=-\frac{1}{N}\sum_{i=1}^N\sum_{j=1}^Cy_{ij}\log P\left(y_j\mid x_i;\theta\right), Lfine−tune(θ)=−N1i=1∑Nj=1∑CyijlogP(yj∣xi;θ),
其中 y i j y_{ij} yij 表示样本 i 在类别 j 上的真实标签, P ( y j ∣ x i ; θ ) P(y_j | x_i; θ) P(yj∣xi;θ) 代表模型预测样本 i 属于类别 j 的概率。最小化此损失函数可促使模型输出与真实标签更趋一致,从而提升模型在目标任务上的性能。
一个典型的例子是BERT模型[2],该模型在广泛的语言语料库(如BooksCorpus和维基百科)上进行了大量的预训练。在微调阶段,这些广泛的表征会使用特定任务的数据(例如,用于情感分析的IMDB数据集[91])进行精炼,从而使BERT能够专注于情感分类和问答等任务。
3.1.3 全参数微调
全参数微调是指调整预训练模型全部参数的过程,与此相对的是参数高效方法(如LoRA [92]或前缀微调[43]),后者仅修改部分参数。全参数微调通常在对精度要求较高的任务中更受青睐,例如医疗和法律领域[93],但其计算开销巨大。例如,微调一个650亿参数模型可能需要超过100 GB的GPU显存,这对资源受限的环境构成了挑战。为缓解此类限制,研究者提出了如LOMO [93]等内存优化技术,以降低梯度计算和优化器状态的内存占用。模型参数按照以下规则进行更新:
θ t + 1 = θ t − η ∇ θ L ( θ t ) , \theta_{t+1}=\theta_t-\eta\nabla_\theta L(\theta_t), θt+1=θt−η∇θL(θt),
其中 θ t θ_t θt表示第t次迭代时的模型参数,η为学习率, ∇ θ L ( θ t ) ∇_θL(θ_t) ∇θL(θt)代表损失函数的梯度。混合精度训练[94]和激活检查点[95]等内存优化技术有助于降低内存需求,使得在硬件资源有限的系统上对大型模型进行微调成为可能。
从GPT-3到InstructGPT的转变是完整参数微调的一个显著案例[45]。该研究通过为指令跟随任务设计的数据集,对模型的全部参数进行了微调。这种方法能够实现最优性能,但由于需要更新所有参数,其计算成本十分高昂。
3.2 自适应微调
自适应微调通过修改预训练模型的行为,以更好地满足用户特定需求并处理更广泛的任务。该方法引入额外线索来引导模型的输出生成,为定制化模型响应提供了灵活框架。自适应微调中值得注意的方法包括指令微调和基于提示的微调,这两种技术通过引入任务特定指导,显著提升了大型语言模型的适应能力。
3.2.1 指令微调
指令调优[96]是一种通过基于专门构建的指令数据集对基础大语言模型进行微调以优化其性能的技术。该方法显著提升了模型在各类任务和领域间的泛化能力,增强了其灵活性与准确性。如图5所示,该过程首先将现有的自然语言处理数据集(例如用于文本分类、翻译和摘要的数据集)转化为包含任务描述、输入示例、预期输出和示例演示的自然语言指令。诸如Self-Instruct[86]等技术通过自动生成额外的指令-输出对,进一步增强了这些数据集的多样性,从而扩大了模型接触的任务范围。微调过程通过调整模型参数使其与这些特定任务指令对齐,最终形成一个在已见及未见任务上均能稳健执行的大语言模型。例如,InstructGPT[45]和GPT-4[7]已在广泛的应用中展现出指令遵循能力的显著提升。
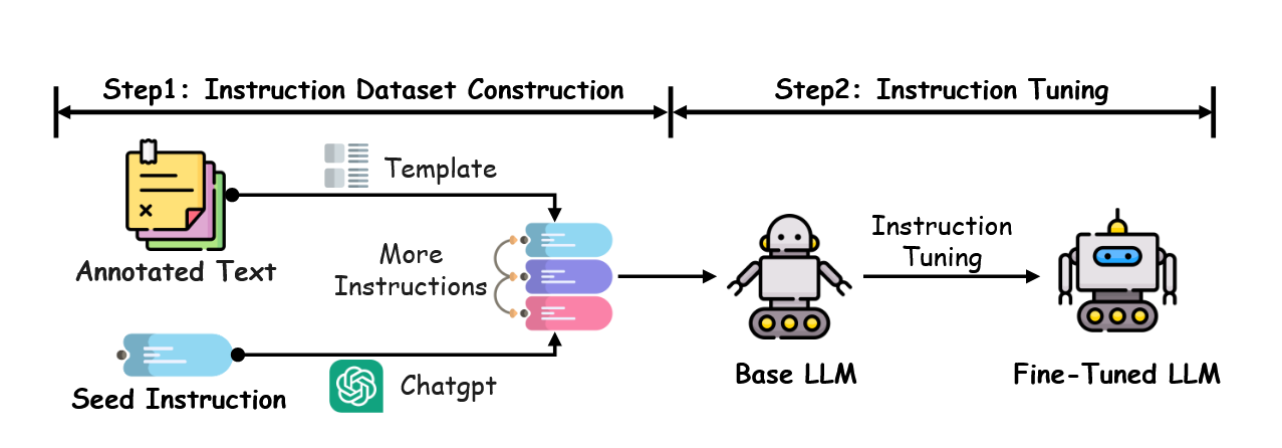
图5:指令微调工作流程,展示了大型语言模型中指令数据集构建与指令调优的一般流程。
指令微调的效果很大程度上取决于指令数据集的质量与广度。高质量数据集应涵盖广泛的语言、领域和任务复杂度,以确保模型保持普适性[96]。此外,指令的清晰度和组织结构对模型有效理解并执行任务至关重要。整合示范案例(如包含思维链提示[47]等技术)能显著提升模型在复杂推理任务中的表现。同时,在微调阶段确保任务分布的平衡至关重要,以避免因任务覆盖不均导致的过拟合或模型性能下降。比例任务抽样或加权损失函数等技术有助于解决这些问题,确保各项任务在微调过程中获得均衡贡献。因此,通过细致构建与管理指令数据集,研究者能够大幅提升微调后大语言模型的泛化能力,使其在广泛的任务和领域中表现出色[97]。
3.2.2 前缀调优
前缀调优[98]是一种参数高效的微调方法,其核心思想是在语言模型的每个Transformer层中添加一系列可训练的前缀标记(连续向量),同时保持核心模型参数固定。如图6(a)所示,这些前缀向量具有任务特异性,可视为虚拟词嵌入。为优化前缀向量,该方法采用重参数化技巧:通过学习一个小型多层感知机(MLP)函数,将较小规模的矩阵映射为前缀参数,而非直接优化前缀向量。该方法已被证明能有效稳定训练过程。当前缀向量优化完成后,映射函数即被丢弃,仅保留推导出的前缀向量用于提升特定任务性能。
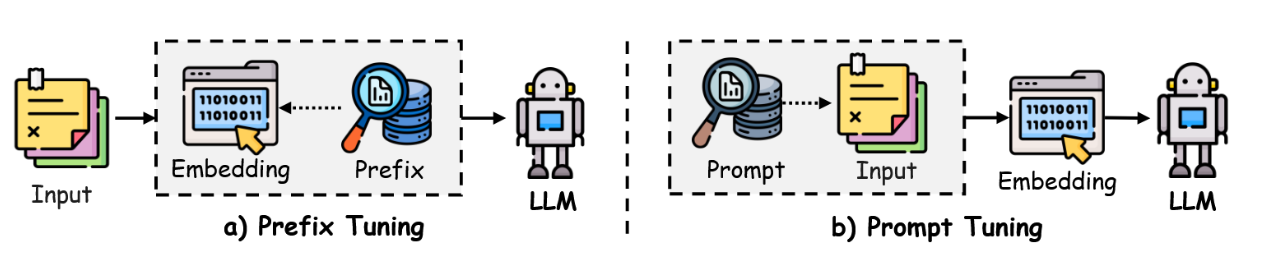
图6:前缀微调与提示微调的对比,阐述其在参数微调上的不同路径:a) 前缀微调与b) 提示微调。
通过学习在输入序列前添加连续提示并采用分层提示技术,模型的行为被导向任务特定输出,而无需进行全模型微调。由于仅需调整前缀参数,该方法实现了更高的参数效率。在此基础上,P-Tuning v2 [99] 将分层提示向量专门集成到Transformer架构中,以优化自然语言理解任务。该方法还利用多任务学习机制优化跨任务共享提示,从而在不同参数规模下提升模型性能[43]。前缀调优技术能够促进大语言模型快速高效地适应特定任务,这使其在需要灵活性与效率的应用场景中成为一种极具吸引力的策略。
3.2.3 提示词调优
提示调优(Prompt-tuning)[44, 100] 是一种旨在高效适配大语言模型的方法,其通过优化输入层的可训练向量来实现,而非修改模型的内部参数。如图6(b)所示,该技术基于离散提示方法[101, 102],通过引入软提示令牌而构建,这些令牌可采用无限制格式[44]或前缀格式[100]进行组织。这些学习到的提示嵌入会与输入文本嵌入相结合,再交由模型处理,从而在保持预训练权重冻结的前提下引导模型输出。提示调优有两个著名实现:其一是P-Tuning [44],它采用一种灵活的方法来组合上下文、提示和目标令牌,使其同时适用于理解与生成任务。该方法通过双向LSTM架构增强了软提示表示的学习。相比之下,标准提示调优[100]采用了更简单的设计,即将前缀提示添加在输入之前,且训练时仅根据任务特定的监督更新提示嵌入。
研究表明,提示调优能够在多项任务中达到与全参数微调相当的性能,同时所需训练参数量显著减少。但其成功与否与底层语言模型的能力密切相关,因为提示调优仅修改输入层少量参数[44]。基于这些进展,P-Tuning v2 [99]等新方法已证明提示调优策略可有效适配不同规模的模型,处理此前被认为需要全量微调的复杂任务。这些发现确立了提示调优作为传统微调的高效替代方案,能够以更低的计算和内存成本实现可比性能。
3.3 强化学习微调
强化微调(ReFT)[103]代表了一种将强化学习与监督微调相结合的前沿技术,旨在提升模型解决复杂动态问题的能力。与通常每个问题仅使用单一思维链标注的传统监督微调不同,ReFT使模型能够探索多种有效推理路径,从而增强其泛化能力和问题解决技巧。该过程始于标准的监督微调阶段,模型首先在标注数据上进行训练,通过监督式标注学习基础任务解决能力。在此初始微调之后,模型使用如近端策略优化(PPO)[46]等强化学习算法进行进一步优化。在强化学习阶段,模型为每个问题生成多个思维链标注,探索不同的潜在推理路径。这些生成的路径会通过对比模型预测答案与真实答案进行评估:正确输出获得奖励,错误输出则受到惩罚。这种迭代过程驱动模型调整其策略,最终优化其推理策略。
如图7所示,ReFT过程分两个阶段执行。上半部分代表SFT阶段,模型在多个训练轮次中迭代训练数据,学习每个问题的正确思维链标注。下半部分引入ReFT阶段:从经过SFT训练的模型出发,模型基于当前策略生成替代性思维链标注(e′),并将其预测答案(y′)与真实答案(y)进行比较。正确答案给予正向奖励,错误答案给予负向奖励,从而驱动模型提升性能。这些奖励信号随后通过强化学习更新模型策略,增强其生成准确且多样化思维链标注的能力。
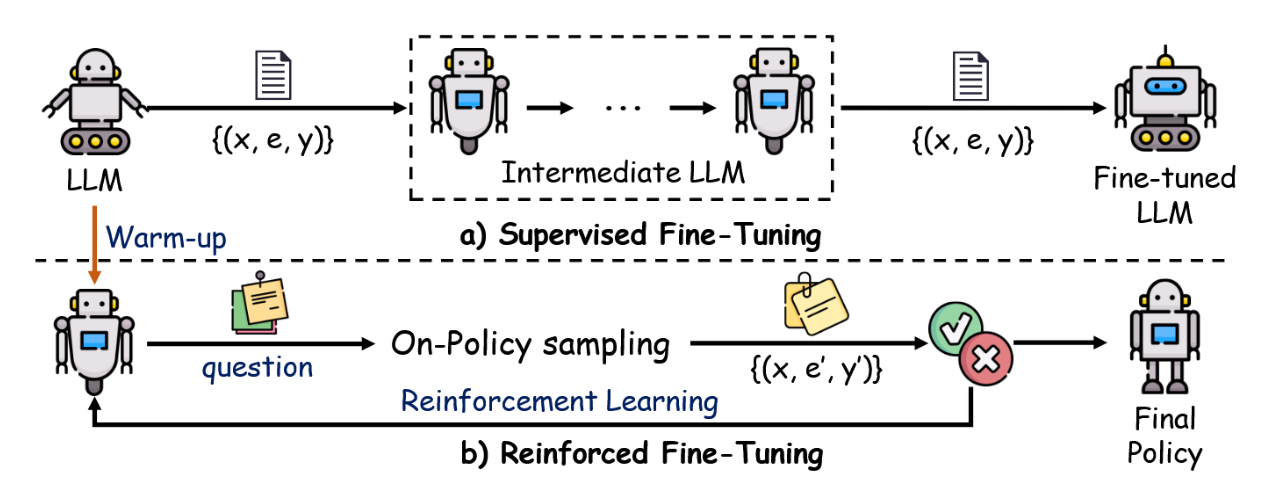
图7:强化微调(ReFT)流程,描绘了在相同数据集上进行的迭代监督微调(SFT)预热及随后的强化学习训练。
近期研究表明,ReFT方法在性能上显著超越传统的SFT方法[103]。此外,通过集成推理阶段策略(如多数投票和重排序),可进一步提升模型表现,使其在训练后能够优化输出结果。值得注意的是,ReFT在无需额外或扩增训练数据的情况下实现了这些改进,仅利用SFT阶段所使用的既有数据集进行学习。这凸显了该模型卓越的泛化能力——它能够从现有数据中更高效、更有效地学习。
4.用于对齐的PoLM
大型语言模型的对齐旨在引导模型输出符合人类期望与偏好,这在安全关键型或面向用户的应用中尤为重要。本章探讨实现对齐的三大范式:基于人类反馈的强化学习(§4.1),其使用人工标注数据作为奖励信号;基于人工智能反馈的强化学习(§4.2),利用AI生成的反馈以解决可扩展性问题;以及直接偏好优化(§4.3),该范式无需显式奖励模型,可直接从成对的人类偏好数据中学习。每种范式在追求稳健对齐的过程中都具有独特的优势、挑战与权衡。表2简要总结了这些方法及相关技术的对比。
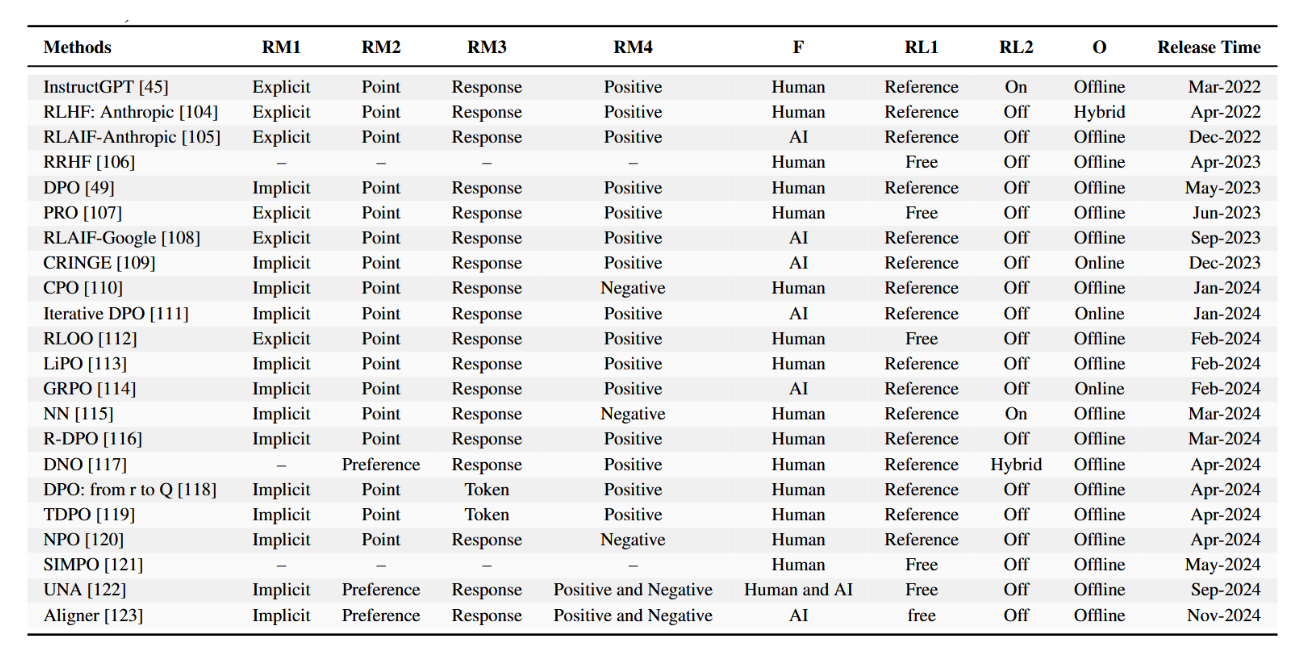
表2:大型语言模型对齐方法对比概览(2022–2024)。本表从八个指标评估主流对齐技术:RM1(显式或隐式奖励模型)、RM2(点奖励或偏好概率模型)、RM3(响应级或词元级奖励)、RM4(正向或负向奖励模型)、F(反馈类型:人工或AI)、RL1(参考模型或无参考模型强化学习)、RL2(同策略或异策略强化学习)以及O(在线/迭代或离线/非迭代优化)。
4.1 基于人类反馈的强化学习
监督微调(Supervised Fine-Tuning, SFT)[45] 一直是引导大型语言模型遵循人类指令的一项基础技术。然而,纯监督场景中标注数据的多样性和质量可能参差不齐,且监督模型在捕捉更细微或更具适应性的人类偏好方面的能力往往有限。为此,研究人员提出了基于强化学习(Reinforcement Learning, RL)的微调方法来应对这些不足。在各类强化学习方法中,基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)[104] 作为最早且最具影响力的基于RL的对齐后训练方法之一,尤为突出。
如图8所示,RLHF首先以偏好标签或奖励信号的形式汇总人类反馈,随后利用这些信息训练奖励模型。在该奖励模型的引导下,策略通过迭代调整以更好地契合人类偏好。与监督微调相比,RLHF引入了持续的、偏好驱动的更新机制,从而实现了更强的对齐效果。值得注意的是,GPT-4 [9]、Claude [27]和Gemini [76]等现代大语言模型均受益于此机制,在指令遵循、事实一致性和用户相关性方面展现出显著提升。下文我们将讨论RLHF的核心组成部分,包括反馈机制、奖励建模以及策略学习方法。
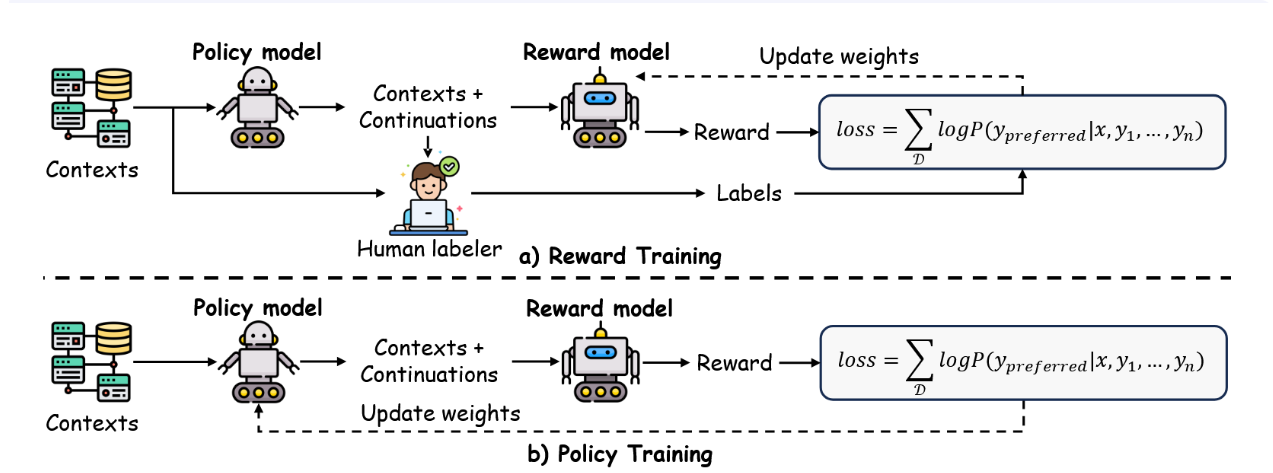
图8:人类反馈强化学习(RLHF)工作流程,阐明了将大语言模型与人类偏好对齐的总体训练过程。
4.1.1 基于人类反馈的强化学习反馈机制
人类反馈是RLHF的核心环节,它向奖励模型传递用户偏好信息并指导策略更新。本小节采纳文献[124]的分类体系,对常见的人类反馈形式进行归类。表3从粒度、参与程度及显性程度等维度展示了这些反馈类型。每种反馈模态都对模型优化的不同方面产生作用,并在可解释性、可扩展性和噪声容忍度方面呈现出不同程度的特性。
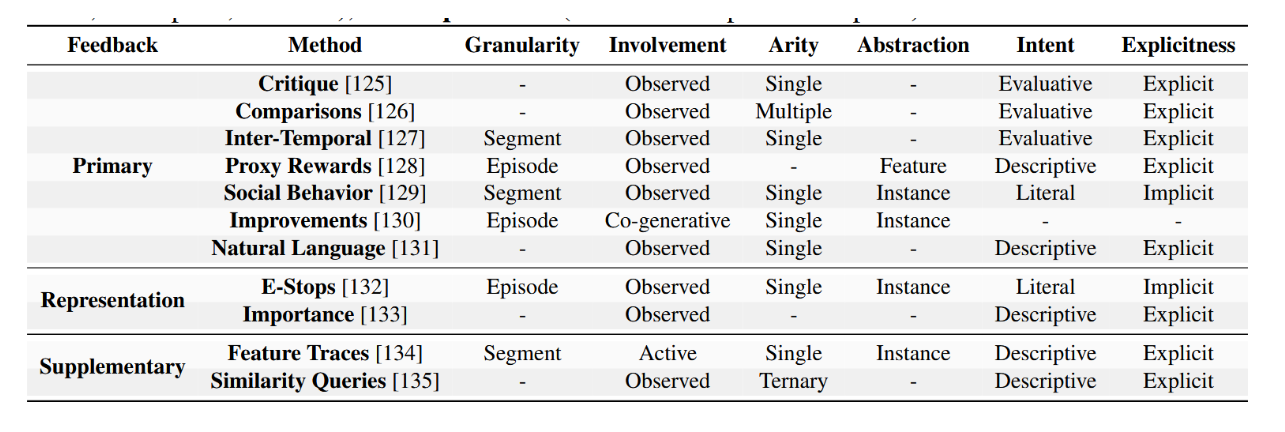
表3:大语言模型后训练方法的反馈类型分类。本表从六个维度概述常见反馈类别及其定义属性:粒度(范围:回合、片段或步骤)、介入度(参与方式:观察型、主动型或协同生成型)、元数(实例数量:单数、复数或三元)、抽象性(目标:特征或实例)、意图(目的:评估性、描述性或字面性)以及显性度(直接性:显式或隐式)。
主要反馈。这一类别包含对强化学习人类反馈(RLHF)中奖励模型塑造最为直接的反馈类型。例如,批判评估[125]侧重于对智能体行为的明确人类评估,通常通过二元或多标签注释进行细化以降低噪声。比较评估[126]允许评估者比较多个输出或轨迹;虽然更大的选择集能提供更丰富的信号,但也可能导致因果混淆。跨时间反馈[127]通过在不同时间步提供判断来细化轨迹评估,而代理奖励[128]则采用近似的奖励函数,引导模型朝向用户定义的目标。社会行为反馈[129]利用隐性线索(如面部表情)使智能体目标与用户情感保持一致。改进反馈[130]强调通过实时人工干预实现策略的渐进式优化。最后,自然语言反馈[131]利用文本信息传递偏好及改进建议。
辅助反馈。除主反馈外,另有两种机制进一步强化奖励建模过程。紧急停止机制[132]允许人类通过中断智能体行为轨迹(无需提供替代方案)来干预其行为。此类反馈具有隐含介入特性,且单一聚焦于阻止不良行为。与之相对,重要性标注[133]通过标注特定观察结果对实现目标的重要程度,提供不直接改变行为的显式反馈。此类反馈随情境变化,作为补充性输入强化奖励模型的整体学习过程。
表征特异性反馈。某些反馈类型主要强化表征学习而非直接塑造奖励函数。特征轨迹法[134]引导人类操作者展示特定特征的单调变化,从而实现特征集的动态扩展。相似性查询法[135]通过比较轨迹三元组,在轨迹空间中利用成对距离指导表征学习。借助这些表征特异性反馈形式,基于人类反馈的强化学习能够在面对新任务和场景时实现更稳健的泛化能力。
4.1.2 基于人类反馈的强化学习的奖励模型
真实的奖励函数 r ( x , y ) r(x, y) r(x,y)通常是未知的,因此需要基于人类提供的偏好构建一个可学习的奖励模型rθ(x, y)。该模型用于预测给定输入x时,候选输出y与人类期望的契合程度。为获得 r θ ( x , y ) r_θ(x, y) rθ(x,y)的训练数据,人类评估者会根据输出的相对优劣对结果进行比较或标注,模型通常使用基于这些比较的交叉熵损失进行训练。为防止策略π偏离初始模型ρ过远,奖励函数中会引入一个由超参数β控制的惩罚项:
r θ ( x , y ) = r ( x , y ) − β log π ( y ∣ x ) ρ ( y ∣ x ) , r_\theta(x,y)=r(x,y)-\beta\log\frac{\pi(y\mid x)}{\rho(y\mid x)}, rθ(x,y)=r(x,y)−βlogρ(y∣x)π(y∣x),
其中π(y | x)表示微调策略π在给定输入x时产生输出y的概率,ρ(y | x)则代表原始模型ρ下的对应概率。此项确保π在适应人类反馈的同时,始终受到ρ所捕获的先验知识的约束。
评估奖励函数 r θ ( x , y ) r_θ(x, y) rθ(x,y) 至关重要,因为它直接影响学习效能与策略性能。准确评估此函数有助于识别合适的奖励结构,以使模型输出与人类偏好对齐。然而,在安全敏感领域,标准的模拟推演方法 [136, 137] 和离线策略评估 [138, 139] 可能因在线交互风险、偏差问题以及对真实奖励的需求而难以实施。为应对这些挑战,通常采用两种主要方法:
距离函数。近期研究聚焦于考虑势能变换(如势能塑形)的奖励评估距离函数。例如,EPIC [140] 衡量了多种变换下奖励函数的等价性,而 DARD [141] 通过改进规范化过程,确保评估始终基于可行的状态转移。类 EPIC 距离 [142] 通过允许规范化、标准化及度量函数存在可变性,推广了 EPIC 的方法论;STARC [143] 则在保持 EPIC 理论特性的同时,提供了额外的灵活性。
视觉与人工检验。其他方法依赖可解释性和精细构建的数据集来衡量所学奖励函数的有效性。PRFI[144]通过预处理步骤简化奖励函数并保持等价性,从而提升其透明度。与此同时,CONVEXDA与REWARDFUSION[145]提出了专门设计的数据集,用以测试奖励模型对提示中语义变化的响应一致性。这些技术共同促进了对奖励函数更可靠的评估,强化了大语言模型与人类偏好的对齐。
4.1.3 基于人类反馈的强化学习策略习得
如图9所示,强化学习人类反馈(RLHF)中的策略学习涉及在在线与离线场景下,通过人类反馈对策略进行优化。
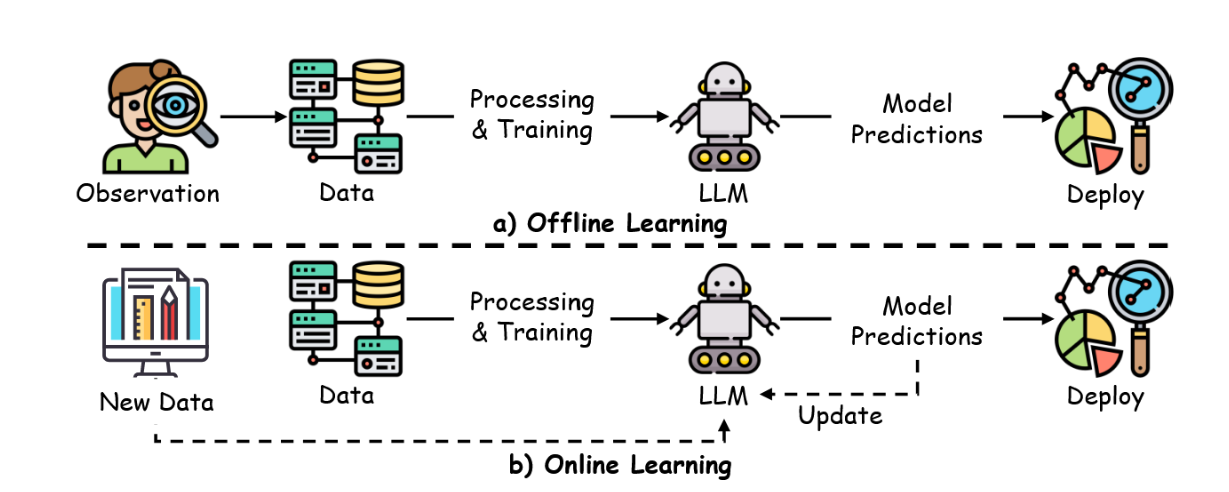
图9:在线与离线RLHF对比图,展示在线RLHF在策略执行期间持续收集反馈,而离线RLHF则利用预先收集的轨迹数据。
在线学习。在在线RLHF中,系统实时收集人类对新生成模型轨迹的偏好。DPS [146] 等算法使用贝叶斯更新来管理对决过程,而 PPS 和 PEPS [147] 则融合动态规划和赌博机思想以优化策略行为。在 LPbRL [148] 中,特征嵌入捕捉不断演化的奖励结构,PbOP [149] 则采用最小二乘估计来整合状态转移动态和偏好信号。最近的研究中,PARL [150] 通过将反馈获取视为策略优化的组成部分,旨在提升数据收集效率。
离线学习。在离线RLHF中,使用先前收集的带有偏好标注的轨迹来学习或优化策略。例如,[151] 研究了基于成对比较数据的悲观最大似然估计策略学习方法,并建立了性能边界。诸如FREEHAND [152] 和DCPPO [153] 等扩展方法将研究推广至未知偏好模型,探索离线数据覆盖与策略泛化之间的相互作用。此外,[154] 解决了成对比较中玻尔兹曼模型的过拟合问题,而DCPPO [153] 进一步研究了动态离散选择模型以提升反馈效率。
混合在线与离线学习。混合方法将离线预训练与在线偏好聚合相结合,既利用预先收集的数据,又能整合实时更新。PFERL [155] 采用两阶段方法以最小化人工查询,而PERL [156] 则探索了用于主动探索的乐观最小二乘策略。对决强化学习 [148] 及其扩展方法(如PRPRL [152] 中的REGIME)通过仔细分离数据获取与反馈收集环节,减少了人工标注需求,从而在样本效率、标注成本和策略性能之间实现了优化权衡。
4.2 基于人工智能反馈的强化学习
强化学习与人工智能反馈(RLAIF)通过利用大语言模型生成反馈信号,扩展了RLHF范式。该方法可补充或替代人类反馈,在人工标注稀缺、成本高昂或一致性不足的任务中,提供更具可扩展性、成本更低的偏好数据。
4.2.1 基于AI反馈的强化学习与基于人类反馈的强化学习对比
大规模应用RLHF的主要挑战在于其依赖人工生成的偏好标签,这需要投入大量资源进行数据收集、整理和标注。数据标注过程既耗时又昂贵,且人工评估者可能引入不一致性,从而难以对所有模型输出进行大规模、一致的标注。这些限制显著制约了RLHF的可扩展性和效率。为应对这些挑战,文献[105]提出了RLAIF方法,该方法将人类反馈与AI生成的反馈相结合,通过强化学习训练模型。通过利用大语言模型作为反馈源,RLAIF降低了对人工标注者的依赖,为传统RLHF提供了可行的替代方案。这种方法能实现持续的反馈生成,在保持人类引导模型优化灵活性的同时,显著提升了可扩展性。
如图10所示,RLHF与RLAIF的核心区别在于反馈来源:RLHF依赖人类生成的偏好数据,而RLAIF则利用AI生成的反馈来指导策略更新。[157]等实证研究表明,经人工评估员评测,RLAIF能达到与RLHF相当甚至更优的性能。值得注意的是,RLAIF不仅超越了传统的监督微调基线,而且其使用的LLM偏好标注模型与策略模型规模相同,这凸显了该方法的效率优势。
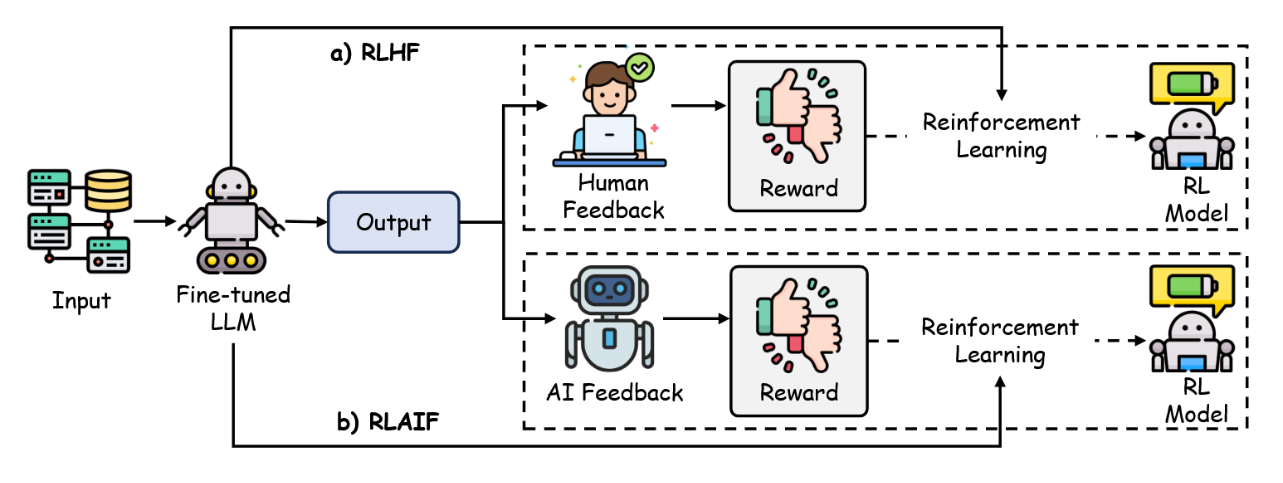
图10:RLHF与RLAIF方法对比,阐述两者在大型语言模型中实现偏好对齐的差异化方法论。
4.2.2 RLAIF训练流程
RLAIF训练流程包含若干关键阶段,其中通过迭代利用人工智能生成的反馈来优化模型行为。该流程能够将大型语言模型的输出与人类期望对齐,并实现跨任务的可扩展性,具体机制详见文献[108]。主要阶段如下:
AI反馈收集
在此阶段,AI系统基于预设标准生成反馈,这些标准可能包括任务特定指标、回答的正确性或模型输出的恰当性。与需要人工解读和标注的人类反馈不同,AI反馈能够在广泛的模型输出范围内保持一致性生成。这一特性使得AI反馈能够持续提供,从而显著扩展反馈循环的规模。
奖励模型训练。随后,人工智能生成的反馈被用于训练或优化奖励模型。该模型将输入-输出对映射到相应的奖励值,使模型输出与反馈所要求的预期结果保持一致。传统的RLHF依赖于直接的人类反馈来评估输出,而RLAIF则利用人工智能生成的标签。尽管AI生成的标签可能在一致性和偏差方面存在问题,但其在可扩展性以及脱离人力资源依赖方面具有优势。
策略更新。最后阶段基于前一步训练的奖励模型更新模型策略。通过采用强化学习算法调整模型参数,优化策略以在多种任务中实现累积奖励最大化。这一过程是迭代的,奖励模型引导模型的输出,使其更符合预期目标。
RLAIF的主要优势在于其能够扩展反馈循环,且无需持续的人工干预。通过用人工智能生成的反馈替代人类反馈,RLAIF促进了大型语言模型在多种任务上的持续改进,缓解了人工标注工作带来的瓶颈。
4.3 直接偏好优化
如前所述,RLHF [45] 通常包含三个阶段:监督微调 [17, 86]、奖励模型训练和强化学习(通常通过近端策略优化PPO实现)[46]。尽管RLHF行之有效,但其过程可能较为复杂且易出现不稳定性,尤其是在拟合奖励模型并随后使用该模型微调大语言模型的阶段。其难点在于构建一个能精确反映人类偏好的奖励模型,以及在此同时确保语言模型在优化这一估计奖励时不会过度偏离原始模型。为解决这些问题,直接偏好优化(DPO)[49] 作为一种更稳定、计算效率更高的替代方案被提出。DPO通过将奖励函数直接与最优策略相关联,简化了奖励优化过程。它将奖励最大化问题视为一个基于人类偏好数据的单阶段策略训练问题,从而避免了奖励模型拟合的复杂性以及对布拉德利-特里模型 [158] 的依赖。
4.3.1 DPO 的基础
RLHF通过训练奖励模型(RM)并利用强化学习微调语言模型(LM)。DPO简化了这一过程,它直接使用人类偏好数据训练语言模型,将奖励模型隐式地内化于策略本身。
KL正则化奖励最大化目标。直接偏好优化(DPO)始于一个已得到广泛认可的KL正则化奖励最大化框架,其目标函数如下所示:
π ∗ = arg max π E x ∼ D , y ∼ π ( ⋅ ∣ x ) [ r ( x , y ) − β K L ( π ( ⋅ ∣ x ) ∥ π r e f ( ⋅ ∣ x ) ) ] , \pi^*=\arg\max_\pi\mathbb{E}_{x\sim\mathcal{D},y\sim\pi(\cdot|x)}\left[r(x,y)-\beta\mathrm{KL}\left(\pi(\cdot\mid x)\|\pi_{\mathrm{ref}}(\cdot\mid x)\right)\right], π∗=argπmaxEx∼D,y∼π(⋅∣x)[r(x,y)−βKL(π(⋅∣x)∥πref(⋅∣x))],
其中 r(x, y) 表示奖励函数,β > 0 是控制与参考策略 π r e f π_{ref} πref 接近程度的系数,KL(·∥·) 表示 Kullback-Leibler 散度。此处,x ∼ D 表示从数据分布中抽取的输入, y ∼ π ( ⋅ ∣ x ) y ∼ π(· | x) y∼π(⋅∣x) 表示从策略中采样的输出。
推导最优策略。在适当假设下,方程(14)的解以玻尔兹曼分布的形式导出[61, 62, 63]:
π ∗ ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) , \pi^*(y\mid x)=\frac{1}{Z(x)}\pi_{\mathrm{ref}}(y\mid x)\exp\left(\frac{1}{\beta}r(x,y)\right), π∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y)),
其中配分函数
Z ( x ) = ∑ y π r e f ( y ∣ x ) exp ( 1 β r ( x , y ) ) Z(x)=\sum_y\pi_{\mathrm{ref}}(y\mid x)\exp\left(\frac{1}{\beta}r(x,y)\right) Z(x)=y∑πref(y∣x)exp(β1r(x,y))
该归一化项确保 π ∗ π^∗ π∗始终保持为有效的概率分布(即其概率总和为1)。
奖励的重参数化。对等式(15)两边取自然对数,我们可以将奖励 ( r ( x , y ) r(x, y) r(x,y) ) 与最优策略 ( π ∗ \pi^* π∗ ) 关联起来。由此得到:
r ∗ ( x , y ) = β [ log π ∗ ( y ∣ x ) − log π r e f ( y ∣ x ) ] + β log Z ( x ) , r^*(x,y)=\beta\left[\log\pi^*(y\mid x)-\log\pi_{\mathrm{ref}}(y\mid x)\right]+\beta\log Z(x), r∗(x,y)=β[logπ∗(y∣x)−logπref(y∣x)]+βlogZ(x),
其中 β l o g Z ( x ) β log Z(x) βlogZ(x)为常数,不影响奖励间的成对比较。若已知最优策略π∗,则真实奖励 r ∗ ( x , y ) r^∗(x, y) r∗(x,y)可确定至该常数项精度。
布拉德利-特里偏好模型。根据布拉德利-特里模型[158],人类对两个输出y1和y2的偏好由其奖励值之差决定。y1优于y2的概率由下式给出:
p ∗ ( y 1 ≻ y 2 ∣ x ) = exp ( r ∗ ( x , y 1 ) ) exp ( r ∗ ( x , y 1 ) ) + exp ( r ∗ ( x , y 2 ) ) . p^*\left(y_1\succ y_2\mid x\right)=\frac{\exp\left(r^*(x,y_1)\right)}{\exp\left(r^*(x,y_1)\right)+\exp\left(r^*(x,y_2)\right)}. p∗(y1≻y2∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x,y1)).
将式(17)代入式(18),得到最终的偏好模型:
p ∗ ( y 1 ≻ y 2 ∣ x ) = 1 1 + exp ( β [ log π ∗ ( y 2 ∣ x ) π r e f ( y 2 ∣ x ) − log π ∗ ( y 1 ∣ x ) π r e f ( y 1 ∣ x ) ] ) . p^*\left(y_1\succ y_2\mid x\right)=\frac{1}{1+\exp\left(\beta\left[\log\frac{\pi^*(y_2|x)}{\pi_{\mathrm{ref}}(y_2|x)}-\log\frac{\pi^*(y_1|x)}{\pi_{\mathrm{ref}}(y_1|x)}\right]\right)}. p∗(y1≻y2∣x)=1+exp(β[logπref(y2∣x)π∗(y2∣x)−logπref(y1∣x)π∗(y1∣x)])1.
该表达式将成对人类偏好概率与最优策略 π ∗ π^∗ π∗和参考策略 π r e f π_{ref} πref之比联系起来。
DPO的目标。DPO通过学习直接从偏好数据中推导策略,绕过了显式的奖励建模。给定一个由偏好三元组 { ( x , y w , y l ) } \{(x, y_w, y_l)\} {(x,yw,yl)}组成的数据集,其中 y w y_w yw是对于提示x的偏好输出, y l y_l yl是次优输出,DPO旨在最大化观测到的偏好的似然概率。形式上,DPO采用以下目标函数:
L D P O ( π θ ; π r e f ) = − E ( x , y w , y l ) ∼ D [ log σ ( β [ log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) ] − β [ log π θ ( y l ∣ x ) π r e f ( y l ∣ x ) ] ) ] , \mathcal{L}_{\mathrm{DPO}}(\pi_\theta;\pi_{\mathrm{ref}})=-\mathbb{E}_{(x,y_w,y_l)\thicksim\mathcal{D}}\left[\log\sigma\left(\beta\left[\log\frac{\pi_\theta(y_w|x)}{\pi_{\mathrm{ref}}(y_w|x)}\right]-\beta\left[\log\frac{\pi_\theta(y_l|x)}{\pi_{\mathrm{ref}}(y_l|x)}\right]\right)\right], LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(β[logπref(yw∣x)πθ(yw∣x)]−β[logπref(yl∣x)πθ(yl∣x)])],
其中 σ(·) 为逻辑西格玛函数, β l o g π θ ( y ∣ x ) / π r e f ( y ∣ x ) β log π_θ(y|x) / π_{ref}(y|x) βlogπθ(y∣x)/πref(y∣x) 表示策略 π θ π_θ πθ 与参考策略 π r e f π_{ref} πref 之间的重参数化奖励差异。通过最大化 LDPO,策略 π θ π_θ πθ 能够与人类偏好对齐,且无需单独的奖励模型。由于 DPO 目标函数继承了来自 RLHF 的 KL 正则化形式,它在保持关键理论保证(例如在明确定义的偏好假设下的一致性 [159])的同时,将训练过程统一至单阶段。因此,DPO 为语言模型与人类评估的对齐提供了更直接的路径,降低了系统复杂性并提升了训练稳定性。
4.3.2 DPO训练细节
DPO框架基于两个核心模型构建:参考策略 π r e f π_{ref} πref与目标策略 π t a r π_{tar} πtar。参考策略通常是一个经过预训练及监督微调的语言模型,在训练过程中保持固定。相比之下,目标策略以 π r e f π_{ref} πref为起点进行初始化,并基于偏好反馈进行迭代更新,从而不断提升与人类判断的对齐度。图11展示了这一整体流程。
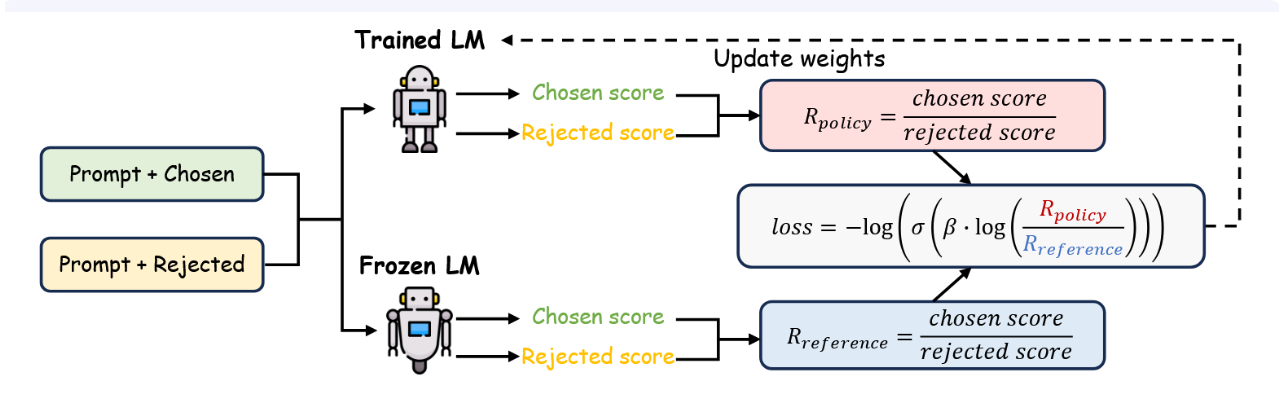
图11:直接偏好优化工作流程,展示了基于人类偏好优化大型语言模型输出的训练流程。
数据收集与准备。DPO依赖于一个经过筛选的偏好数据集,该数据集的获取方式是为每个提示 x 从参考模型 π r e f π_{ref} πref中采样多个候选回复。随后,由人工标注者根据连贯性、相关性和清晰度等标准对这些回复进行比较或排序。由此产生的偏好标签,便成为优化目标模型 π t a r π_{tar} πtar的核心训练信号。
训练流程。目标策略通过一系列基于梯度的更新进行优化,旨在最小化损失函数 LDPO。具体步骤为:1) 生成: π r e f π_{ref} πref为每个提示 x 产生候选输出。2) 标注:由人工标注者比较生成的输出,确定其相对偏好。3) 优化:利用这些成对偏好数据,迭代更新 π t a r π_{tar} πtar,以更好地模拟人类偏好的输出。在此过程中, π r e f π_{ref} πref保持不变,提供一个稳定的基线以衡量改进效果。
实用考量:选择稳健的参考策略对于有效初始化DPO通常至关重要。监督微调(SFT)通常能为参考策略 π r e f π_{ref} πref提供性能良好的基线,确保后续基于偏好的更新能专注于策略微调,而非基础技能习得。此外,偏好数据必须具有足够的多样性,以捕捉用户期望的差异,从而增强模型的适应能力,并防止其过拟合于定义狭隘的任务。
4.3.3 DPO 的变体
多种DPO变体已应运而生,旨在应对特定的对齐挑战并优化文本生成的不同维度。表2概述了这些方法,其涵盖范围从词元级生成优化到控制文本冗余度,乃至处理列表式或负向偏好。
DPO优化文本生成。词级与迭代式DPO策略可实现更细粒度或持续的人类偏好对齐。词级DPO [118] 被重构为赌博机问题,采用由 ( S , A , f , r , ρ 0 ) (S, A, f, r, ρ_0) (S,A,f,r,ρ0) 定义的马尔可夫决策过程。该方法缓解了非偏好token的KL散度过大等挑战。TDPO [119] 采用顺序前向KL散度替代反向KL散度,在提升对齐效果的同时保持了文本生成的多样性。迭代式DPO [111] 采用多轮优化方法,通过重复的偏好评估(常由模型自身执行)持续精炼输出。成对保守优化 [109] 将二元反馈扩展至成对设置,使用软间隔平衡探索与利用。分步DPO [160] 对偏好数据集进行分区并实施迭代更新,将每轮更新后的策略作为下一轮的基线。
可控且灵活的DPO方法。部分DPO变体旨在控制冗余度并减少对固定参考策略的依赖。R-DPO [116]通过在目标函数中加入正则化项来惩罚输出长度,从而解决回复过于冗长或重复的问题。SimPO [121]通过归一化回复长度并简化损失函数以同时处理期望与不期望的输出,从而取消了对参考策略的需求。RLOO [112]利用REINFORCE算法且无需训练价值模型,显著降低了计算开销。该方法将整个回复视为单一动作,并通过稀疏奖励进行学习,相较于传统的基于PPO的方法,其实现更为简化。
列表化直接偏好优化。该方法不将偏好数据局限于成对比较,而是对输出集合进行优化。列表式偏好优化(LiPO)[113]将学习排序技术直接应用于候选回复的排序列表,相较于重复的成对比较提升了效率。RRHF [106]将偏好对齐融入监督微调阶段,无需单独的参考模型。PRO [107]将列表式偏好分解为更简单的二元任务,简化了监督微调过程中的对齐操作。
负向直接偏好优化。某些任务需要从未期望或有害输出中学习:《否定负面样本》(NN)[115]摒弃正向回应,并最大化与次优输出的差异。《负向偏好优化》(NPO)[120]对负向偏好执行梯度上升,有效减少有害输出并缓解灾难性崩塌。
5.面向推理的后训练模型
推理是使大型语言模型能够处理多步骤逻辑、复杂推理和复杂决策任务的核心支柱。本章探讨两种提升模型推理能力的核心技术:用于推理的自我优化(§5.1),该方法引导模型自主检测并修正自身推理步骤中的错误;以及用于推理的强化学习(§5.2),该方法采用基于奖励的优化机制,以提升模型思维链的一致性和深度。这些方法共同增强了模型在长程决策、逻辑证明、数学推理及其他复杂任务中的稳健处理能力。
5.1 用于推理的自优化
推理能力仍然是优化大语言模型(LLM)以应对需要复杂逻辑推理和上下文相关决策任务的核心挑战。在此背景下,自我优化作为一种强大的机制,能够在文本生成过程中或生成后迭代地定位并修正错误,从而显著提升推理深度与整体可靠性。如图12所示,自我优化方法可分为四类:内在自我优化,依赖于模型内部推理循环;外在自我优化,整合外部反馈资源;微调式内在自我优化,基于自我生成的修正迭代更新模型的推理过程;以及微调式外在自我优化,利用外部信号和微调,以更具适应性、长期持续的方式精炼推理能力。表4进一步阐释了各类方法如何在不同任务中增强LLM的推理能力。
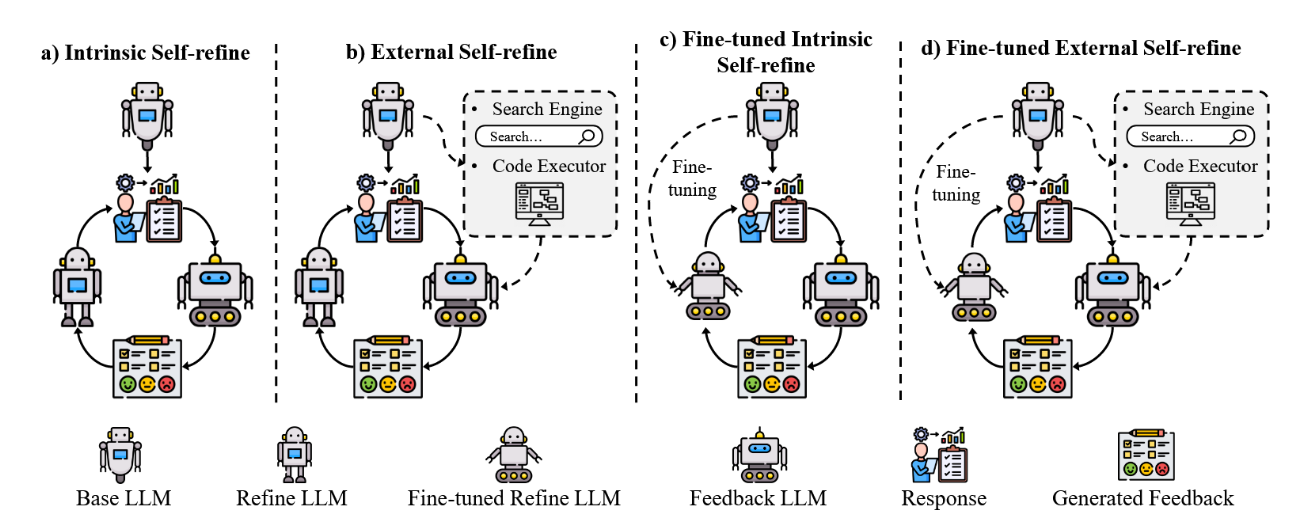
图12:自优化方法分类体系,阐述增强大型语言模型推理能力的架构变体。
内在自我精炼。内在自我精炼方法侧重于让模型自身具备在内部检测和修正错误的能力,而无需借助外部工具。例如,RCI提示法[190]仅在识别到矛盾或错误时触发修正,从而避免对微小不确定性的过度反应。CAI审查[105]提出的修正机制通过纠正不良输出(如冒犯性文本)同时教导模型实现自我调节。类似地,自我优化[164]利用从低质量提示到高保真指令的转换过程,通过精炼中间逻辑来增强一致性。链式验证[169]通过将多答案问题分解为子任务以应对挑战,并对每个子任务独立验证,从而确保整个推理链的精确性与一致性。弱到强泛化方法借助先进算法,使强大的学生模型能够从能力较弱的教师模型产生的噪声演示中有效学习[191]。该框架已在多个领域实现关键进展与应用。近期研究通过多种创新增强了W2SG方法,例如集成学习技术已成功应用于提升W2SG方法的鲁棒性与有效性[192]。[193]则采用弱到强外推法以增强大语言模型的对齐能力。
外部自我精炼。这类方法借助外部反馈源或计算工具来引导并修正模型的推理过程。CRITIC [177] 通过系统性检查逐步输出,提升复杂推理任务的可靠性。Reflexion [172] 和 Self-Debug [173] 分别将生成的答案与参考解决方案或少样本示例进行比对,以迭代方式优化逻辑。FLARE [170] 和 Logic-LM [171] 等技术则引入外部文档或符号求解器的参考信息,从而减少逻辑错误。RARR [165] 和 SelfEvolve [166] 表明,对中间状态(如编译器消息或相关知识源)进行验证,是一种早期剪除错误路径、引导模型向正确解决方案精炼的有效方式。[194] 提出了基于人类反馈的迭代偏好学习,其中包括适用于在线环境的直接偏好优化算法的迭代版本,以及面向离线场景的多步拒绝采样策略。PIT [195] 则从人类偏好数据中隐式学习改进目标。
精细调整的内在自我优化。通过专门针对内部修订对基础模型进行微调,这些方法系统性地增强了大型语言模型的自我校正循环。Self-Critique [161] 旨在通过自我审查改进摘要生成,而 SelFee [174] 利用迭代反馈循环确保更高水平的逻辑一致性。Volcano [180] 通过在大型语言模型架构内微调专用校正模块来减少多模态幻觉,RL4F [167] 则利用基于强化学习的批判循环,在需要深度推理的基准测试中将性能平均提升 10%。REFINER [176] 同样专注于中间推理路径而不改变模型原始生成过程,表明通过训练模型仔细复审其部分输出可以实现持续改进。此外,易到难泛化已成为弱到强生成的一个有前景的变体,即模型先在易于验证的示例上训练,再处理更复杂的任务 [196]。该方法的一个显著实现涉及在人类可验证的示例上训练强奖励模型,进而指导能力更强的模型在挑战性任务上进行监督学习 [197]。W2SG的有效性不仅限于大型语言模型,其在计算机视觉任务中的成功应用也得到了验证[198]。
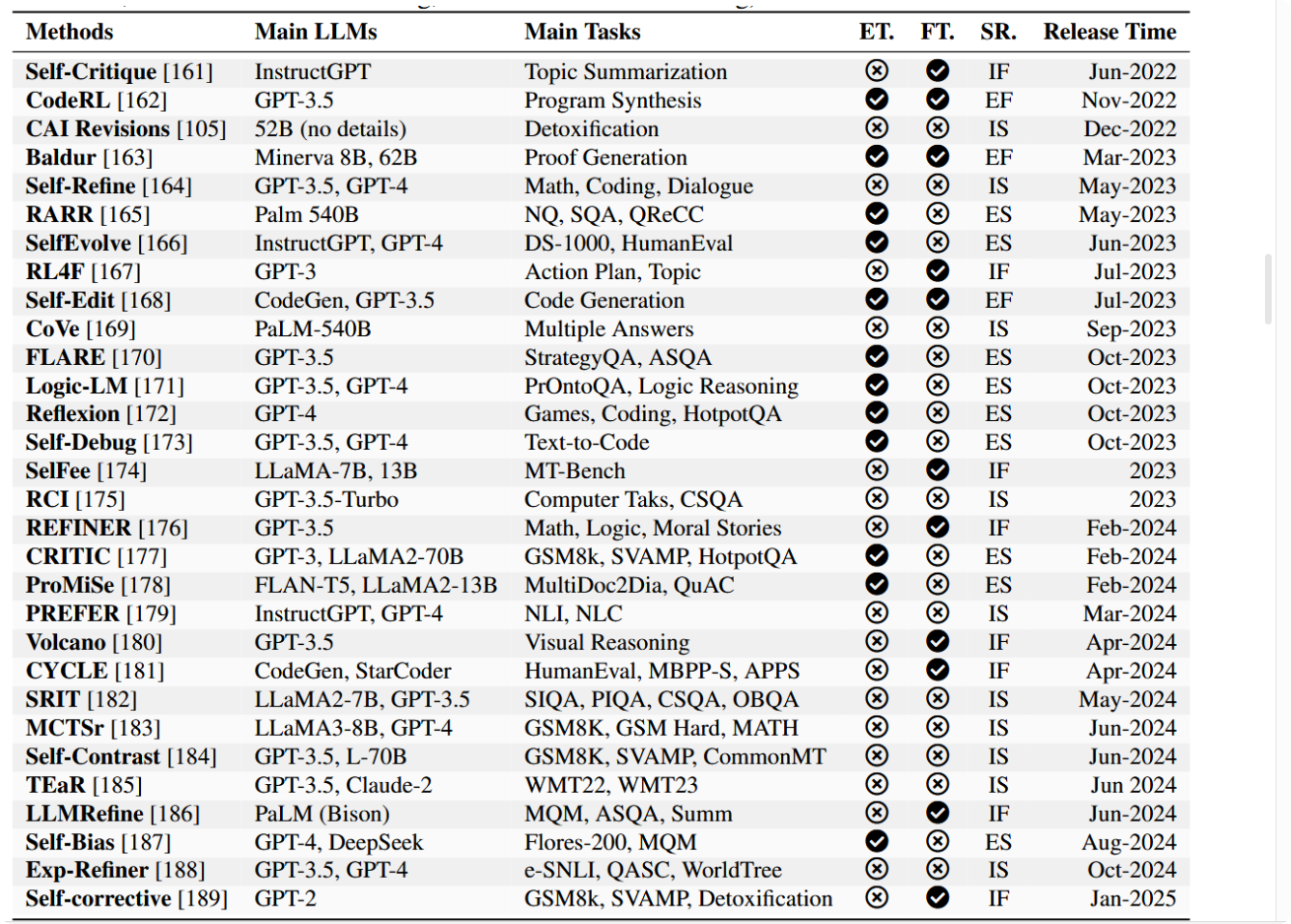
表4:大规模语言模型中的自我优化方法概览(2022–2025)。本表总结了重要的自我优化技术,详细列出了其主要使用的大型语言模型、任务及发布时间线,并依据三项指标进行分类:ET.(外部工具:¥ 表示使用,q 表示未使用)、FT.(微调:¥ 表示应用,q 表示未应用)以及SR.(自我优化类型:IS 代表内在自我优化,ES 代表外在自我优化,IF 代表内在微调,EF 代表外在微调)。
精细调优的外部自优化机制。在长期改进至关重要的应用场景中,模型参数通过外部反馈机制进行更新。例如,Self-Edit [168] 基于代码执行结果重新生成输出,从而迭代提升其正确性;Baldur [163] 通过添加或修改上下文增强定理证明能力;而 CodeRL [162] 则利用基于测试的评判机制来验证程序合成任务的功能准确性。这些技术共同表明,将外部资源与定向精细调优相结合,能够有效促进模型整体推理性能实现可靠、阶梯式的提升。
5.2 用于推理的强化学习
在5.1小节中,我们探讨了自我优化方法,这是一种通过局部调整与优化来改进大语言模型推理能力的常用技术。该方法通常应用于单步任务或输出优化,如文本生成与问答,能够快速提升推理性能。然而,它在处理需要多步逻辑的复杂长期推理任务时存在局限。OpenAI发布o1系列模型[41] 大语言模型后训练技术综述 凸显了强化学习作为一种强大的替代方案,其通过基于奖励的反馈来优化长链思维推理,从而训练大语言模型进行高级推理。这显著提升了模型在数学证明与战略规划等复杂任务中的性能。o1的成功推动了大规模强化学习的研究,诸如QwQ-32B-Preview[199]等模型在数学和编程领域表现出色,而DeepSeek-R1[28]则达到了与o1相当的能力水平。本小节将审视强化学习在增强推理能力中的作用,重点关注领先的开源模型DeepSeek-R1与DeepSeek-R1-Zero。
5.2.1 将推理过程建模为马尔可夫决策过程
大型语言模型中的推理过程可以优雅地建模为一种序列决策过程:模型为响应输入查询x,通过迭代构建一系列中间步骤a1, a2, . . . , aT,以优化获得最终正确答案的可能性。这种概念化将推理转化为适用于强化学习的结构化框架,具体通过马尔可夫决策过程(表示为 M = ( S , A , P , R , γ ) M = (S, A, P, R, γ) M=(S,A,P,R,γ))的视角实现。该MDP封装了状态、动作、转移、奖励与时间折扣的动态交互,为训练LLMs处理复杂推理任务提供了坚实的数学基础。通过将推理构建为一系列审慎选择,该方法使模型能够系统性地探索并优化其逻辑路径,其原理类似于游戏或机器人等领域中的决策过程,但已针对语言与概念推理的特殊挑战进行调整。最终目标是推导出最优策略 π ∗ ( a t ∣ s t ) π^∗(a_t|s_t) π∗(at∣st),以最大化期望累积奖励(即 J ( θ ) = E π θ [ ∑ t = 1 T γ t R ( s t , a t ) ] J(\theta)=\mathbb{E}_{\pi_\theta}\left[\sum_{t=1}^T\gamma^tR(s_t,a_t)\right] J(θ)=Eπθ[∑t=1TγtR(st,at)]),并利用如近端策略优化或优势演员-评论家等强化学习技术,基于环境反馈迭代增强模型的推理能力。
状态空间。状态空间 S 构成了此 MDP 的骨架,每个状态 s t ∈ S s_t ∈ S st∈S 代表了时间步 t 时的当前推理轨迹,它是一个丰富且由语言与结构元素组成的复合体,对于推理过程至关重要。具体而言, s t s_t st 包含了初始查询 x、先前的推理步骤序列 { a 1 , . . . , a t − 1 } \{a1, ..., a_{t-1}\} {a1,...,at−1},以及一个内部记忆表征,该表征编码了逻辑依赖和中间结论,例如部分解或推断出的关系。随着推理的展开,此状态动态演化,通过整合由生成步骤所明确表达的路径和从上下文理解中提炼的潜在知识,映射出思维的进展过程。例如,在一个数学证明中, s t s_t st 可能包含问题陈述、先前推导出的方程式以及适用定理的记忆,使得模型能够在各步骤间保持连贯性。这种多方面的状态表征确保了 LLM 能够自适应地追踪其推理上下文,这是处理需要持续逻辑连贯性的任务(如多步骤问题求解或文本生成中的叙事连贯性)的先决条件。
动作空间。动作空间A定义了每一步可能决策的范围,其中动作 a t ∈ A a_t ∈ A at∈A对应着下一个推理步骤的选择,为推进推理过程提供了一个多功能工具集。这些动作可包括:生成自然语言中的词元或短语以表述推理片段;应用预定义的逻辑或数学变换(如代数简化);从知识库中选择相关定理或规则以扩展推理链;或在获得结论性答案时终止过程。动作空间的性质因任务而异:在形式化证明中可能是离散的(如从有限逻辑规则集中选择),在开放式推理场景中则可能是连续的(如生成自由格式文本),这体现了大语言模型的生成灵活性。这种双重性使模型既能驾驭结构化领域(如符号逻辑),也能处理非结构化领域(如常识推理),在保持向解决方案连贯推进的同时,根据任务需求调整其策略。
转移函数。转移动态由函数 P ( s t + 1 ∣ s t , a t ) P(s_{t+1}|s_t, a_t) P(st+1∣st,at)所概括,它规定了每个动作如何驱动状态演化,从而在MDP框架内勾勒出推理轨迹的演进过程。与传统强化学习环境中随机性源于外部变量(如环境噪声)不同,大语言模型中的推理转移过程本质上是确定性的,由模型的自回归输出或结构化推理规则(例如在证明中应用演绎步骤)所驱动。然而,不确定性源于模型固有的局限——例如不完善的知识、模糊的中间状态或文本生成中的概率采样——这些因素引入了可变性,必须由强化学习加以处理。对于自回归大语言模型,其转移遵循可预测的序列生成过程,但错误累积或歧义解释的可能性,要求采用鲁棒的设计以确保可靠性。这种"确定性却蕴含不确定性"的动态特征,突显了对自适应策略的需求,该策略须能稳定从精确数学推导到微妙叙事构建等不同语境下的推理过程。
奖励函数。奖励函数 ( R ( s t , a t ) R(s_t, a_t) R(st,at) ) 是马尔可夫决策过程(MDP)的评估核心,它为每个推理步骤的质量提供关键反馈,以引导模型的学习过程。与具有明确奖励(如游戏中的得分)的传统强化学习任务不同,推理奖励必须精心设计,以平衡稀疏性与密集性,从而反映任务的复杂性和目标。稀疏奖励(例如仅在获得最终正确答案时赋值)具有简洁性,但在多步场景中可能延缓学习进程;而密集奖励则评估步骤的正确性、逻辑有效性或与人类偏好的一致性,提供更细粒度的指导,如 §5.2.2 中所述。这种灵活性使奖励函数能够适应多样化的推理需求——无论是奖励证明中有效推理规则的应用,还是叙事片段的连贯性——确保模型获得有意义的信号,以在短期和长期的推理范围内优化其策略。
折扣因子γ:一个标量γ∈[0, 1],用于权衡即时奖励与未来奖励。较高的γ值鼓励多步推理优化,促进深层推理链而非短期启发式策略。在此马尔可夫决策过程的框架下,目标是学习一个最优推理策略π*(at|st),以最大化期望累积奖励。
J ( θ ) = E π θ [ ∑ t = 1 T γ t R ( s t , a t ) ] . J(\theta)=\mathbb{E}_{\pi_\theta}\left[\sum_{t=1}^T\gamma^tR(s_t,a_t)\right]. J(θ)=Eπθ[t=1∑TγtR(st,at)].
该框架支持应用近端策略优化(PPO)[46]或优势演员-评论家(A2C)[200]等强化学习技术,通过根据推理环境的反馈迭代调整策略 π θ π_θ πθ,从而提升大语言模型的推理能力。
5.2.2 面向推理的奖励设计
与传统RL任务(如游戏得分)具有明确奖励不同,LLM中的推理需要反映正确性、效率和信息性的结构化奖励设计。常见方法包括:二元正确性奖励,即正确最终答案分配 r T = 1 r_T = 1 rT=1,否则为0,该方法简单但因反馈稀疏导致高方差;逐步准确性奖励,基于推理规则有效性或中间步骤一致性等指标提供增量反馈,以引导多步推理;自一致性奖励,通过衡量多推理路径的稳定性并对一致路径给予更高奖励以增强鲁棒性;以及基于偏好的奖励,源自RLHF或RLAIF,通过基于人类或AI反馈训练的模型 r φ ( s t , a t ) r_φ(s_t, a_t) rφ(st,at)评估推理质量,为复杂任务提供细致指导。
5.2.3 Base模型的大规模强化学习
大规模强化学习已成为增强大语言模型推理能力的变革性后训练范式,将焦点从传统的监督微调转向动态、自演化的优化策略。该方法利用大规模计算框架和基于奖励的迭代反馈直接优化基础模型,无需预标注数据集即可实现复杂推理能力的自主发展。通过集成大规模强化学习,大语言模型能够处理错综复杂的多步骤推理任务(如数学解题、逻辑推演与战略规划),而传统监督微调因依赖静态人工标注数据常在此类任务中表现不足[45]。DeepSeek-R1模型正是这一范式的典范,它采用先进的强化学习技术,在优化资源效率的同时实现了最先进的推理性能,如图13所示。本小节将阐述支撑DeepSeek-R1成功的关键方法论,包括新型优化算法、自适应探索与轨迹管理技术,这些要素共同重塑了强化学习驱动的大语言模型推理潜能。
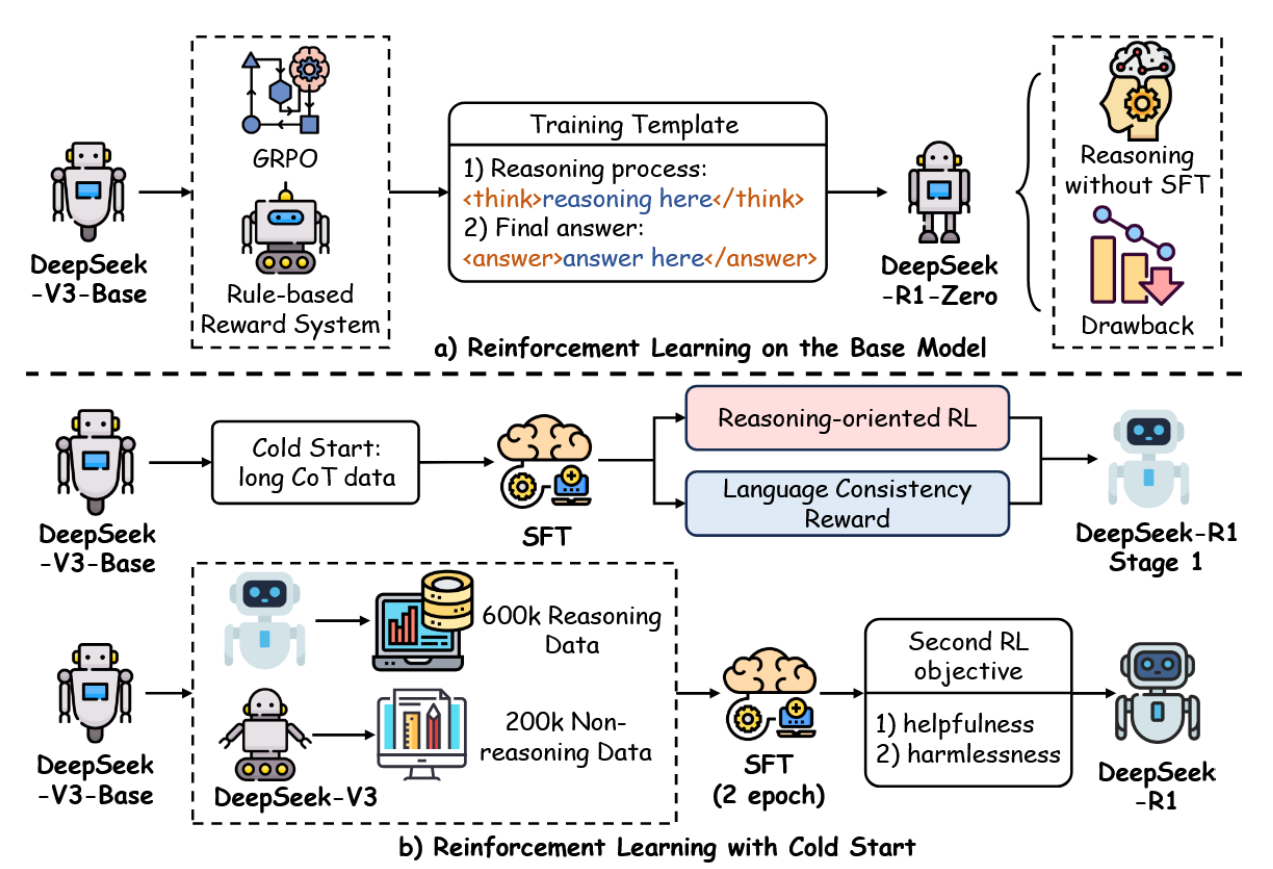
图13:DeepSeek-R1中用于推理的强化学习工作流程,展示了优化大语言模型推理能力的过程。
Group Relative Policy Optimization。DeepSeek-R1-Zero模型采用了一种名为“组相对策略优化”(GRPO)的近端策略优化(PPO)进阶变体,以缓解大型语言模型传统强化学习训练中固有的巨大计算与资源需求。与依赖庞大评判网络的标准PPO不同,GRPO采用基于组群的基线估计来实现优化流程,显著降低训练开销,同时保持策略更新的鲁棒性。这一效率使得在资源受限系统上大规模部署强化学习成为可能,从而促进在长轨迹上对推理策略进行迭代优化。通过在可控计算边界内优化策略,GRPO将DeepSeek-R1-Zero定位为增强推理能力的可扩展解决方案(如图13所示),使其成为当代强化学习驱动推理研究的基石。
DeepSeek-R1-Zero。DeepSeek-R1-Zero 例证了大规模强化学习(RL)在提升大语言模型(LLM)推理能力方面的变革潜力,它摒弃了传统上对监督微调(SFT)作为初始步骤的依赖,转而采用纯RL驱动的自我进化范式。该方法使模型能够通过奖励反馈迭代优化其内部思维链(CoT),从而自主发展出复杂的推理技能,绕过了SFT通常所需的预标注数据集。其结果是模型在复杂多步骤推理任务(例如数学问题求解和逻辑推导)上的性能显著提升,这证明了RL能够从基础模型中激发出高级推理能力。作为当前最强大的开源推理模型之一,DeepSeek-R1-Zero的成功印证了“冷启动”RL策略的可行性,它提供了一种资源高效的传统训练流程替代方案,同时在性能上达到了与最先进基准模型相当的水平。
逐步奖励建模。为了在轨迹 τ = ( s 1 , a 1 , . . . , s T , a T ) τ = (s_1, a_1, ..., s_T, a_T) τ=(s1,a1,...,sT,aT)中引导推理,DeepSeekR1采用了一种逐步奖励模型fθ,该模型在每一个时间步提供细粒度的反馈,其定义为 r t = f θ ( s t , a t ∣ D r e a s o n i n g ) r_t = f_θ(s_t, a_t | D_{reasoning}) rt=fθ(st,at∣Dreasoning)。其中, D r e a s o n i n g D_{reasoning} Dreasoning包含带有时步级正确性标签的人工标注思维链序列。这种密集的奖励结构与稀疏的序列结束奖励形成对比,它能针对每个推理步骤的质量提供即时、可操作的反馈,使模型能够精确地微调其推理策略。通过利用专家精心整理的数据,奖励模型确保了反馈与人类推理标准保持一致,从而在扩展的推理链中提升了一致性和准确性——这是处理需要长时间逻辑综合任务的关键特性。
自适应探索。DeepSeek-R1通过在其目标函数中集成自适应探索机制,增强了策略优化过程。
L P P O + = E τ [ min ( π ϕ ( a ∣ s ) π o l d ( a ∣ s ) A t , c l i p ( π ϕ ( a ∣ s ) π o l d ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A t ) ] + λ t H ( π ϕ ( ⋅ ∣ s ) ) , \begin{aligned}\mathcal{L}_{\mathrm{PPO+}}&\begin{aligned}=\mathbb{E}_\tau\left[\min\left(\frac{\pi_\phi(a|s)}{\pi_{\mathrm{old}}(a|s)}A_t,\mathrm{clip}\left(\frac{\pi_\phi(a|s)}{\pi_{\mathrm{old}}(a|s)},1-\epsilon,1+\epsilon\right)A_t\right)\right]\end{aligned}\\&+\lambda_t\mathcal{H}(\pi_\phi(\cdot|s)),\end{aligned} LPPO+=Eτ[min(πold(a∣s)πϕ(a∣s)At,clip(πold(a∣s)πϕ(a∣s),1−ϵ,1+ϵ)At)]+λtH(πϕ(⋅∣s)),
其中熵项H由一个自适应系数 λ t = α ⋅ e x p ( − β ⋅ V a r ( R ( τ 1 : t ) ) ) λ_t = α · exp(−β · Var(R(τ_{1:t}))) λt=α⋅exp(−β⋅Var(R(τ1:t)))调节,该系数基于轨迹上的奖励方差动态调整。该方法平衡了探索与利用,鼓励模型在训练早期探索多样化的推理路径,随着方差减小逐渐收敛至最优策略,从而在推理精炼过程中同步提升鲁棒性与效率。
轨迹剪枝。为优化推理过程中的计算效率,DeepSeek-R1 采用双重注意力评价器 V ψ ( s t ) = L o c a l A t t n ( s t ) + G l o b a l A t t n ( s 1 : t ) V_ψ(s_t) = LocalAttn(s_t) + GlobalAttn(s_{1:t}) Vψ(st)=LocalAttn(st)+GlobalAttn(s1:t),该评价器通过结合局部步骤评估与全局轨迹上下文来评估每个状态的价值。当 V ψ ( s t ) < γ ⋅ m a x k ≤ t V ψ ( s k ) V_ψ(s_t) < γ · max_{k≤t} V_ψ(s_k) Vψ(st)<γ⋅maxk≤tVψ(sk) 时触发剪枝,终止低价值推理路径以将资源集中于高潜力轨迹。该机制减少了无效探索,加速了收敛过程,并确保模型优先处理高质量推理序列,这为其在复杂推理任务中的卓越性能做出了贡献。
5.2.4 用于冷启动推理的强化学习
DeepSeek-R1-Zero通过采用冷启动方法进一步推进了强化学习的应用,它避开了监督微调(SFT),完全基于未经训练的基础模型进行大规模强化学习。这种自我进化策略通过迭代反馈来精炼推理过程,无需依赖预先标注的数据即可生成鲁棒的思维链序列。通过直接在推理任务上进行训练,DeepSeek-R1-Zero展现了强化学习的通用性,其性能达到甚至超越了采用SFT初始化的模型(如其对应版本DeepSeek-R1)。该方法不仅降低了对大规模标注数据集的依赖,也彰显了强化学习自主发展复杂推理能力的潜力,为未来大语言模型的发展提供了一种可扩展的范式。总体而言,强化学习为增强推理能力提供了一个前景广阔的框架,其中有效的奖励设计、策略优化(如GRPO)和探索策略仍然至关重要。未来的研究可探索结合模仿学习或自监督目标的混合方法,以进一步精炼这些能力,从而巩固强化学习在推进大语言模型推理中的重要作用。
6 面向能效优化的后训练模型
在前述章节讨论的预训练后优化技术基础上,训练后效率优化专门针对大语言模型完成初始预训练后的实际运行性能。其主要目标是优化关键部署指标(如处理速度、内存占用与资源消耗),从而使大语言模型在现实应用中更具实用性。实现训练后效率优化的方法主要分为三类:模型压缩(§6.1),通过剪枝、量化等技术降低整体计算负载;参数高效微调(§6.2),仅更新模型部分参数或采用特定适配模块,从而最大限度降低再训练成本并加速新任务适应过程;以及知识蒸馏(§6.3),将大型预训练模型的知识迁移至小型模型,使小型模型能以更低资源需求获得相近性能表现。
6.1 模型压缩
模型压缩包含一系列旨在缩小大型语言模型规模并降低其计算需求的技术,主要包括训练后量化、参数剪枝和低秩近似等方法。
6.1.1 训练后量化
LLM的一项关键压缩方法是量化,其将高精度数据类型 X H X^H XH(30位浮点数)转换为低精度格式 X L X^L XL(8位整数)[201]。此转换公式化表示为:
X L = R o u n d ( a b s m a x ( X L ) a b s m a x ( X H ) X H ) = R o u n d ( K ⋅ X H ) , X^L=\mathrm{Round}(\frac{\mathrm{absmax}(X^L)}{\mathrm{absmax}(X^H)}X^H)=\mathrm{Round}(\mathcal{K}\cdot X^H), XL=Round(absmax(XH)absmax(XL)XH)=Round(K⋅XH),
其中K代表量化常数,absmax指张量元素的绝对最大值。Round函数将浮点数转换为整数。大语言模型量化包含训练后量化(PTQ)和量化感知训练(QAT)两种方法。PTQ能够在预训练后对模型权重和激活值进行调整,利用少量校准数据集在计算效率与模型性能间进行优化,如图14所示。此外,表5展示了几种主流大语言模型量化方法的性能指标。
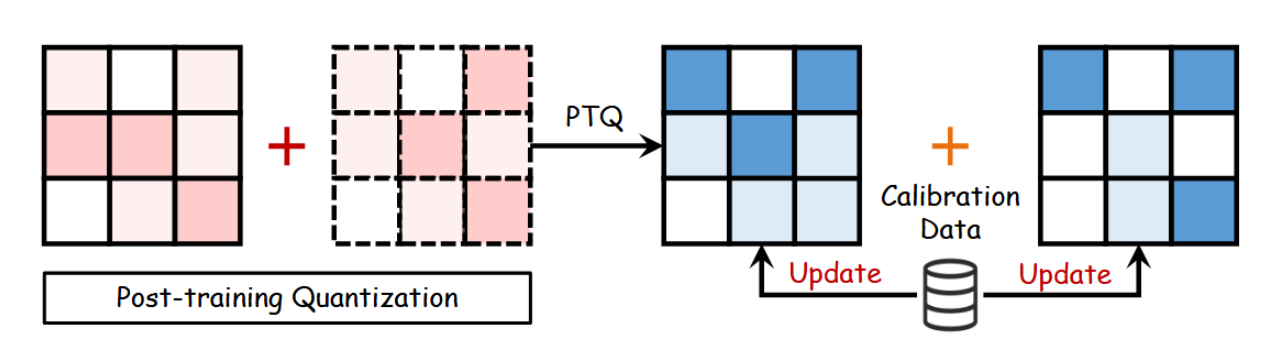
图14:大语言模型训练后量化技术示意图。
仅权重量化(WOQ)。WOQ专注于压缩模型权重以提升效率。GPTQ [230] 采用基于最优脑量化(OBQ)的逐层量化技术,将权重降至3或4比特,以减少内存占用和处理时间。为进一步提升效率,QuIP [203] 为2比特量化引入了非相干处理技术,提供了更为紧凑的表示。类似地,AWQ [204] 和 OWQ [205] 通过为特定敏感权重保持高精度来处理精度保留问题,从而最小化推理过程中潜在的精度损失。最后,SpQR [201] 将稀疏量化与解码相结合,在保持模型响应能力的同时,实现了高效的逐令牌推理。
权重-激活协同量化(WAQ)。WAQ通过整合权重与激活值来提升效率。LLM.int8()[214]采用精确存储处理激活值异常值,并实现8位量化同时保持性能。SmoothQuant[218]实施逐通道缩放,将量化难度从激活值转移至权重,实现无损结果。此外,OS+[219]通过通道级偏移与缩放缓解异常值影响,从而提升效率。OmniQuant[220]将量化障碍从激活值重定向至权重,并通过微调极值截断阈值优化处理。为进一步提升效率,RPTQ[231]对相似通道分组以确保量化参数的一致性。
KV缓存量化(KVQ)。KV缓存量化主要解决大语言模型中内存优化的挑战,尤其针对输入令牌数量增长的情况。KVQuant[224]针对长上下文推理提出定制化方法,以最小损失保持性能。KIVI[228]通过对键缓存与值缓存采用差异化量化策略优化内存节省,实现无需微调的2位量化。WKVQuant[225]进一步通过二维量化策略与跨块正则化进行优化,在实现与权重-激活量化相当内存效率的同时保持近乎一致的性能表现。
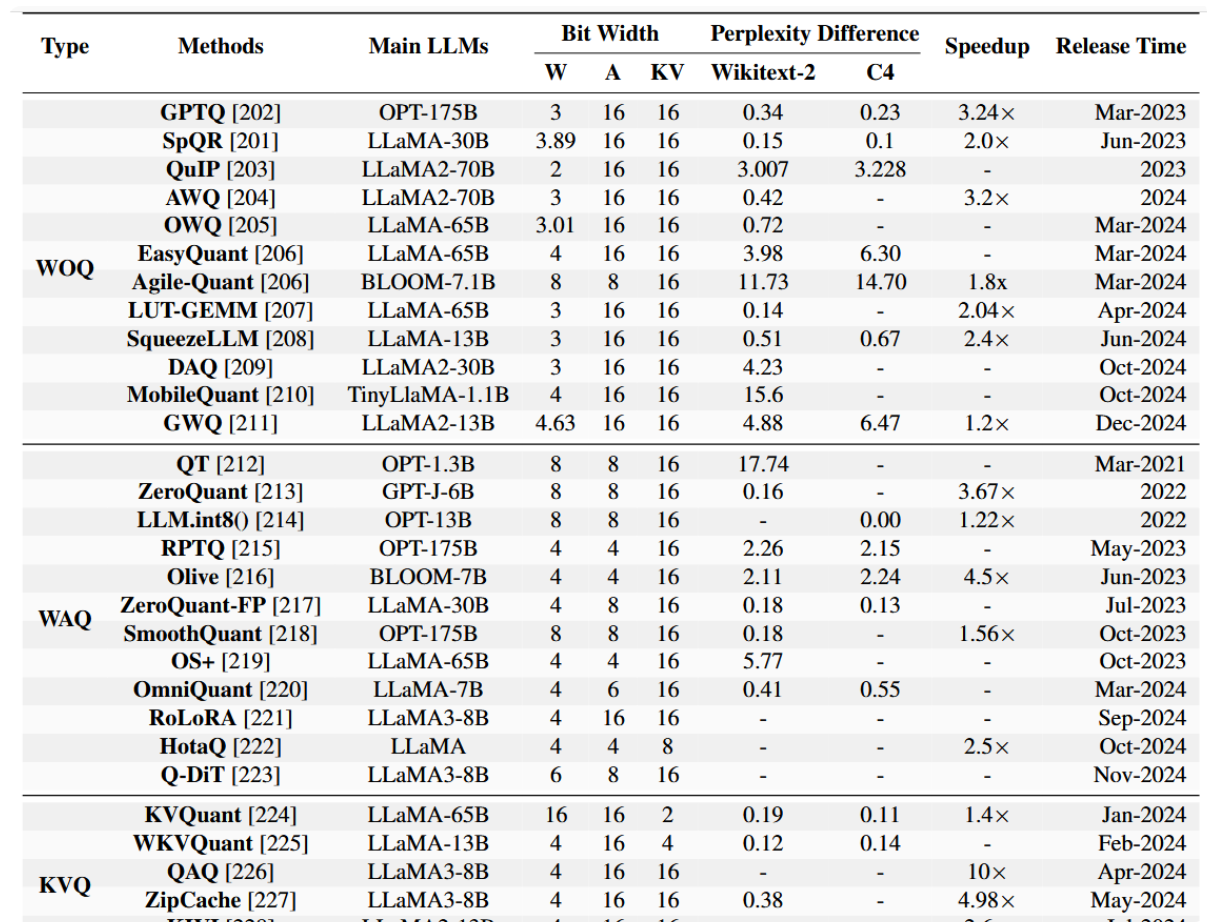
表5:大语言模型量化方法概览(2021–2025)。本表总结了代表性量化技术,详述了其主要应用的大语言模型、位宽、困惑度差异、加速比及发布时间线,涵盖三大指标:位宽(权重、激活值和KV缓存的比特数)、困惑度差异(在Wikitext-2和C4数据集上的性能变化)以及加速比(相对于基线模型的计算速度提升)。
6.1.2 参数剪枝
参数剪枝[232]是提升大语言模型效率的关键技术,它能在保持精度不损失的前提下最小化模型规模与复杂度。如图15所示,剪枝可分为非结构化剪枝与结构化剪枝。
非结构化剪枝。非结构化剪枝通过移除非关键权重来增强大型语言模型的稀疏性。被称为SparseGPT [230]的方法能通过一次剪枝实现高达60%的稀疏度。在保证最小损失的前提下进行剪枝。Wanda [233] 方法基于权重幅度和激活值进行剪枝,无需重新训练。同时,SAMSP [234] 利用海森矩阵的敏感性进行动态稀疏度调整,旨在最小化误差。DSnoT [235] 通过采用迭代剪枝循环提升性能。最后,Flash-LLM [236] 从全局内存中检索稀疏权重,并在片上缓冲器中密集重建,以实现高效计算。
结构化剪枝。该方法专注于剪枝大语言模型中的完整参数组,以提升硬件效率并简化结构。例如,LLM-runer [237] 评估了LLaMA [65]的重要性,并利用LoRA [92]在剪枝后恢复精度。FLAP [238] 采用结构化度量进行优化压缩,无需微调。此外,SliceGPT [239] 运用主成分分析进行剪枝,同时保持效率。Sheared LLaMA [240] 通过基于正则化的剪枝来优化模型形态。LoRAPrune [241] 基于LoRA重要性进行迭代式结构化剪枝,从而提升效率。进一步地,Deja Vu [242] 通过预测关键注意力头与多层感知机参数,并利用上下文稀疏性,在降低延迟的同时保持了模型精度。
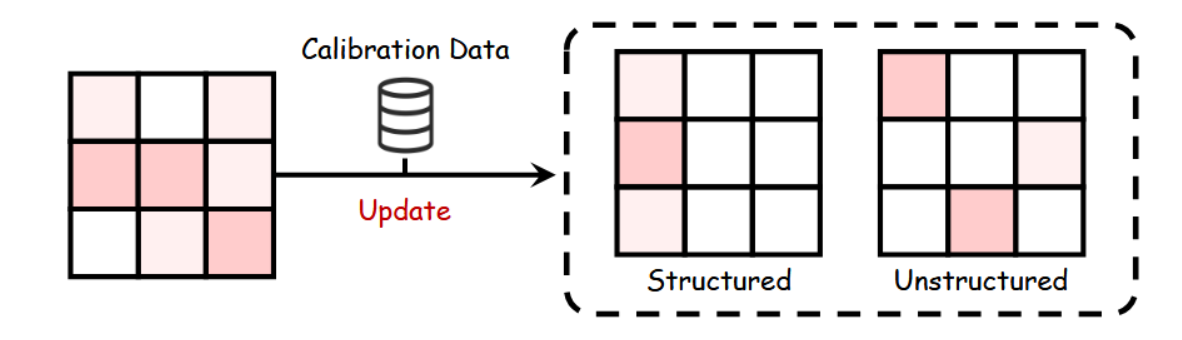
图15:大型语言模型剪枝参数技术示意图。
低秩近似。低秩近似通过使用较小矩阵U和V逼近权重矩阵W(即满足W ≈ U V ⊤),从而实现大型语言模型的压缩。该方法不仅减少了参数量,还提升了运算效率。例如,TensorGPT [243] 采用张量火车分解(TTD)来开发更高效的嵌入格式;LoSparse [244] 将低秩近似与剪枝技术相结合,专门针对相干神经元组件进行压缩;FWSVD [245] 实现了加权奇异值分解方法,而ASVD [246] 则提供了一种无需训练的奇异值分解替代方案,二者均致力于提升训练后效率。最后,SVD-LLM [247] 通过建立奇异值与压缩损失之间的直接关系,进一步优化了压缩效果。
6.2 参数高效微调
参数高效微调(PEFT)流程的核心在于冻结整个大型语言模型主干,仅对少量新增参数进行修改。如图16所示,PEFT方法可分为四类:添加型PEFT、选择性PEFT、重参数化PEFT以及混合型PEFT。
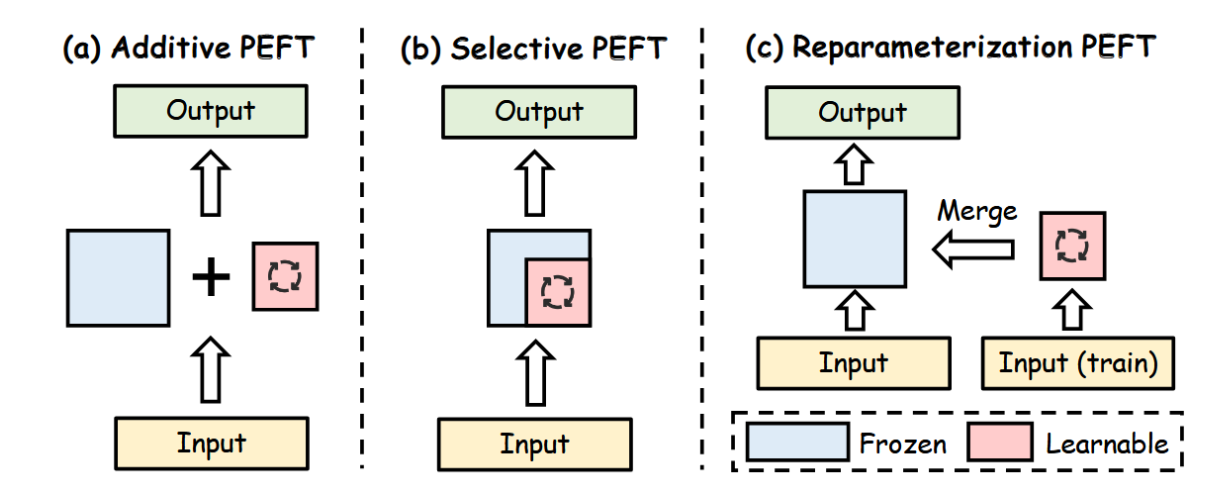
图16:参数高效微调(PEFT)方法图解,展示了大型语言模型中资源高效适配的多种途径。
6.2.1 加法参数高效微调
加性参数高效微调技术在不改变大语言模型原始参数的情况下,引入了新的可训练模块,使模型能够在保留基础模型知识的同时进行任务特定调优,从而实现高效的微调。
适配器。适配器在Transformer模块中集成紧凑型层,其定义为:
A d a p t e r ( x ) = W ир σ ( W d o w n x ) + x , \mathrm{Adapter}(x)=W_\mathrm{ир}{\sigma(W_\mathrm{down}x)}+x, Adapter(x)=Wирσ(Wdownx)+x,
其中适配器层包含降维投影矩阵 W d o w n ∈ R r × d W_{down} ∈ R^{r×d} Wdown∈Rr×d、非线性激活函数σ及升维投影矩阵 W u p ∈ R d × r W_{up} ∈ R^{d×r} Wup∈Rd×r。此处d为隐藏层维度,r为瓶颈维度,可在保持性能的同时降低复杂度。在此结构基础上,Serial Adapter[248]在每层Transformer块中引入了两个模块。AdapterFusion[249]通过将适配器置于Add&Norm层之后提升了效率。Parallel Adapter[250]使适配器与子层并行运行,而CoDA[251]则通过适配器与子层并行执行实现了优化。与AdapterFusion不同,MerA[252]采用最优传输技术对权重和激活值进行统一适配器整合。
软提示通过向输入序列添加可调向量而非优化离散词元来提升模型性能[253],该方法形式化表述为:
X ( l ) = [ s 1 ( l ) , … , s N S ( l ) , x 1 ( l ) , … , x N X ( l ) ] , X^{(l)}=[s_1^{(l)},\ldots,s_{N_S}^{(l)},x_1^{(l)},\ldots,x_{N_X}^{(l)}], X(l)=[s1(l),…,sNS(l),x1(l),…,xNX(l)],
其中 s i ( l ) s_i^{(l)} si(l)表示软提示词元, x i ( l ) x_i^{(l)} xi(l)代表原始输入词元。NS 与 NX 分别为软提示词元与原始输入词元的数量。前缀调优 [254] 在 Transformer 层间引入可学习向量,通过重参数化实现稳定优化,并由 P-Tuning v2 [99] 和 APT [255] 进一步改进。与此同时,提示调优 [44] 聚焦于初始嵌入层,以较低计算成本实现大模型优化。Xprompt [256] 与 IDPG [257] 简化了提示的生成与插入流程。随后,SPoT [258] 和 PTP [259] 等方法致力于提升稳定性与收敛速度,而 DePT [260] 和 SMoP [261] 则通过优化提示结构以降低计算需求。
其他添加方法。除早期技术外,(IA)³ [262] 与 SSF [263] 等方法通过引入极少量但高效的模型参数调整,专注于提升训练后效率。自注意力与前馈网络操作的数学定义如下:
S A ( x ) = S o f t m a x ( Q ⋅ ( l k ⊙ K ) T d h e a d ) ⋅ ( l v ⊙ V ) , SA(x)=\mathrm{Softmax}\left(\frac{Q\cdot(l_k\odot K)^T}{\sqrt{d_{head}}}\right)\cdot(l_v\odot V), SA(x)=Softmax(dheadQ⋅(lk⊙K)T)⋅(lv⊙V),
F F N t r a n s f o r m e r ( x ) = W u p ⋅ ( l f f ⊙ σ ( W d o w n x ) ) , FFN_{transformer}(x)=W_{up}\cdot(l_{ff}\odot\sigma(W_{down}x)), FFNtransformer(x)=Wup⋅(lff⊙σ(Wdownx)),
其中 ⊙ 表示哈达玛积,缩放向量 ( l_k ) 和 ( l_v ) 可以平滑地融入 ( A Q A_Q AQ ) 和 ( A W A_W AW ) 的权重矩阵中。此外,IPA [264] 能将 GPT-4 等大语言模型与用户特定需求对齐,且无需修改底层模型,因而在微调过程中保持效率。
6.2.2 选择性参数高效微调
选择性参数高效微调通过仅微调参数子集提升效率,如图16(b)所示。其核心是对参数集θ = {θ1, θ2, . . . , θn}施加二元掩码M = {m1, m2, . . . , mn},其中每个mi指示θi是否被选中参与微调。更新后的参数集可表示为:
θ i ′ = θ i − η ⋅ m i ⋅ ∂ L ∂ θ i , \theta_i^{\prime}=\theta_i-\eta\cdot m_i\cdot\frac{\partial\mathcal{L}}{\partial\theta_i}, θi′=θi−η⋅mi⋅∂θi∂L,
其中 η 为学习率,∂L/∂θi 为损失函数的梯度。仅对选定参数(mi = 1 时)进行更新,在保持有效性的同时降低了计算成本。早期方法包括 Diff pruning [265](使用可微 L0 范数对可学习二元掩码进行正则化)和 FishMask [266](基于费舍尔信息选择参数以提高相关性)。LT-SFT [267] 应用彩票假说识别关键参数。SAM [268] 采用二阶近似进行参数选择,而 Child-tuning [269] 在子网络中动态选择参数。此外,FAR [270] 和 BitFit [271] 通过专注于优化特定参数组,进一步体现了选择性参数高效微调方法。
6.2.3 重参数化的参数高效微调
重参数化的参数高效微调主要采用低秩参数化以提高效率,如图16©所示。LoRA(低秩适应)[92]引入了两个可训练矩阵 W u p ∈ R ( d × r ) W_{up} ∈ R^(d×r) Wup∈R(d×r) 与 W d o w n ∈ R ( r × k ) W_{down} ∈ R^(r×k) Wdown∈R(r×k),将输出修改为:
h o u t = W 0 h i n + α ( W u p W d o w n h i n ) , h_{\mathrm{out}}=W_0h_{\mathrm{in}}+\alpha(W_{\mathrm{up}}W_{\mathrm{down}}h_{\mathrm{in}}), hout=W0hin+α(WupWdownhin),
其中 α 为缩放因子。该方法能够在保留核心知识的同时,高效适应新任务。基于LoRA,Intrinsic SAID [272] 进一步缩小了微调参数量,降低了计算需求。动态变体包括DyLoRA [273]和AdaLoRA [274],它们能根据任务特定需求动态调整秩,其中AdaLoRA还引入了基于SVD的剪枝以提升效率。SoRA [275]通过移除正交性约束简化了流程,而Laplace-LoRA [276]则应用贝叶斯校准进行微调。Compacter [277]和VeRA [278]进一步降低了参数复杂度。此外,DoRA [279]优化了方向分量的更新,HiRA [280]则利用哈达玛积实现高秩更新,从而同时提升效率与性能。为应对多任务及演化领域,Terra [281]引入了时变矩阵,ToRA [282]则利用Tucker分解进一步改进LoRA结构。除结构设计外,PiSSA [283]和LoRA-GA [284]分别采用SVD和梯度对齐优化LoRA的初始化。同时,LoRA+ [285]、LoRA-Pro [286]和CopRA [287]进一步改进了梯度更新策略。此外,ComLoRA [288]采用竞争性学习以选择性能最佳的LoRA组件。
6.2.4 混合参数高效微调
混合参数高效微调方法通过整合或优化多种微调策略,显著提升了训练后效率。其中UniPELT[289]是一项突出技术,它将LoRA、前缀微调和适配器融合在Transformer模块中。该方法通过前馈网络管理的门控机制动态激活组件,该网络生成标量G ∈ [0, 1],最终实现参数利用的最优化。另一项创新方法MAM适配器[250]对此进行了改进:将前缀微调策略性地置于自注意力层,并在前馈层使用缩放并行适配器。此外,基于神经架构搜索的方法如NOAH[290]和AutoPEFT[291]通过针对特定任务寻找最优参数高效微调配置,有效提升了训练后效率。HeadMap[292]则采用贪心算法识别出在特定任务中起关键作用的一系列注意力头部(即知识回路),并通过将这些注意力头部的输出映射回大语言模型的残差流中,有效提升了模型性能。最后,LLM-Adapters[293]提供了一个在大语言模型中集成各类参数高效微调技术的框架,通过确保最有效的模块布局,在不同规模模型中均能保持高效性。
6.3 知识蒸馏
知识蒸馏(KD)是大型语言模型后训练优化的核心技术,它能够将大规模预训练教师模型的知识迁移至紧凑型学生模型,从而在不牺牲性能的前提下提升效率。该技术最初在模型压缩领域提出,因其能将复杂知识提炼至资源高效的架构中,在边缘设备和嵌入式系统等受限环境中实现部署而受到广泛关注。通过利用教师模型比传统硬标签更为丰富的细粒度输出分布,知识蒸馏使学生模型不仅能复制类别预测结果,还能复现教师模型表征中蕴含的类间关系与微妙模式。该过程通常通过优化复合损失函数实现,该函数在监督学习目标与蒸馏特定目标之间取得平衡,在保持泛化能力的同时显著降低计算与内存需求。
知识蒸馏的基本机制依赖于最小化混合损失函数,该函数整合了传统分类损失与蒸馏损失项。形式化表达为:给定教师模型的软输出概率分布 pt 与学生模型的预测分布 ps,结合真实标签 y 与学生模型输出 ys,知识蒸馏损失函数可表述为:
L K D = α L C E ( y , y s ) + ( 1 − α ) L K L ( p t , p s ) , \mathcal{L}_{KD}=\alpha\mathcal{L}_{CE}(\mathbf{y},\mathbf{y_s})+(1-\alpha)\mathcal{L}_{KL}(\mathbf{p_t},\mathbf{p_s}), LKD=αLCE(y,ys)+(1−α)LKL(pt,ps),
其中 LCE 代表捕捉与真实标签对齐的交叉熵损失,LKL 表示用于衡量教师模型与学生模型分布间差异的 Kullback-Leibler 散度 [294],α ∈ [0, 1] 是调控这两个目标间权衡的超参数。软目标 pt(通常通过温度参数 T 调节,即 pt = softmax(zt/T),其中 zt 为教师模型的逻辑输出)编码了更丰富的概率信息,使学生模型不仅能模仿标签准确性,还能学习教师模型决策过程中的细微差别。
知识蒸馏(KD)在资源受限场景的模型压缩和迁移学习中被广泛应用,其中预训练的教师模型用于指导特定任务的学生模型。其有效性取决于教师模型容量、学生架构及蒸馏损失设计等因素。最新进展已将KD拓展至输出蒸馏之外的领域,使大语言模型在训练后优化中更具效率与适应性。根据对教师模型的访问权限,KD方法可大致分为黑盒KD与白盒KD两类。内部参数与中间表征。如表6所示,知识蒸馏方法可大致分为两类:黑盒知识蒸馏与白盒知识蒸馏。我们系统性地总结了大型语言模型中各类知识蒸馏技术,及其对应的能力、教师模型与学生模型。
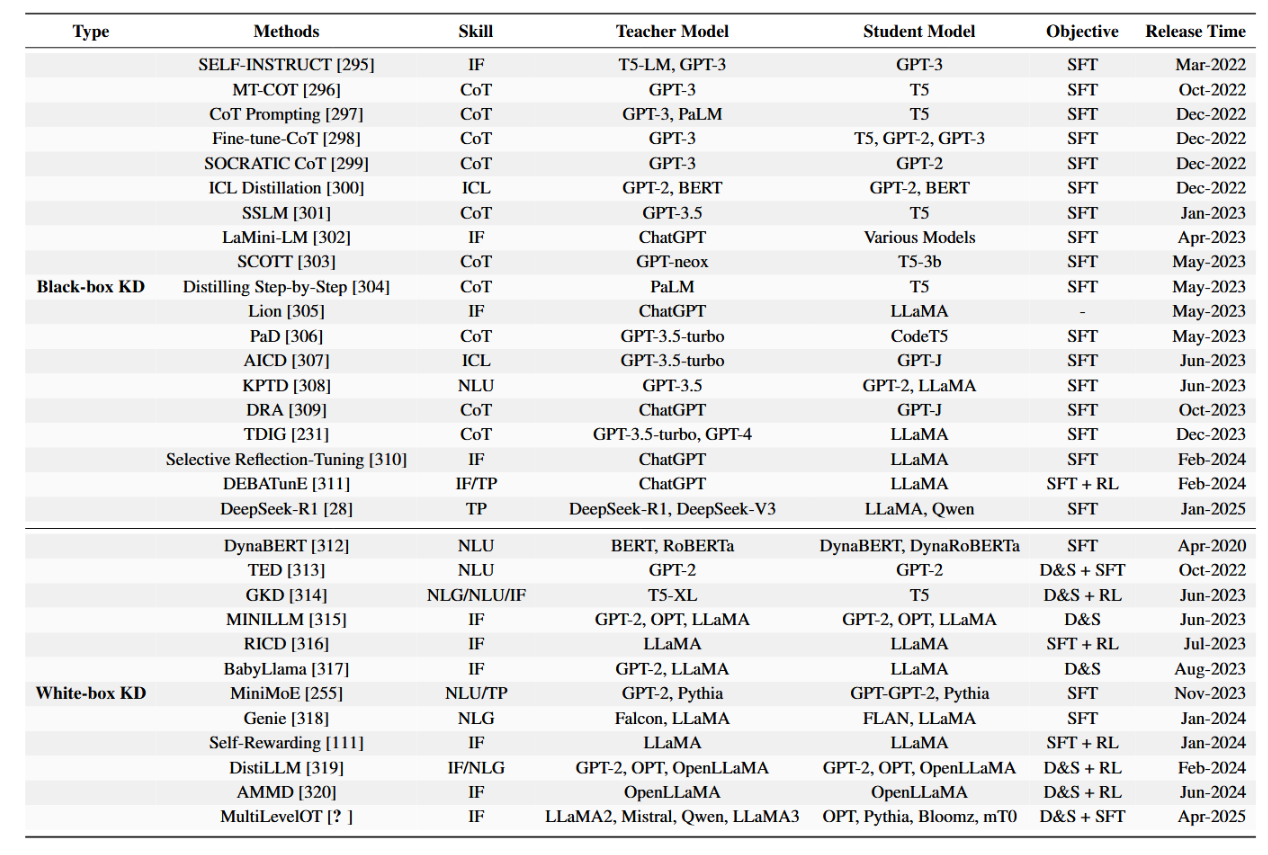
表6:大型语言模型知识蒸馏方法综述(2020–2025)。本表概述了关键的蒸馏技术,详细说明了其能力、教师与学生模型、优化目标及发布时间线,主要分为黑盒知识蒸馏(仅能访问教师模型输出,通常基于闭源大型语言模型)和白盒知识蒸馏(可访问教师模型参数或分布,通常基于开源大型语言模型)。评估指标包括:指令遵循、思维链、上下文学习、监督微调、差异性与相似性、强化学习、思维模式、自然语言理解以及自然语言生成。
黑盒知识蒸馏。黑盒知识蒸馏指学生模型仅从教师模型的输出逻辑值中学习,而无法访问其内部表示或架构细节的场景。该方法最初由Hinton[321]提出,符合经典知识蒸馏范式,并因其灵活性而被广泛采用。黑盒知识蒸馏的一个关键优势在于其将教师模型视为黑盒函数,即使教师模型是受访问限制的专有或预训练模型,也能实现知识迁移。实践中常采用大型教师大语言模型(如ChatGPT和GPT-4[9])生成高质量输出。同时,包括GPT-2[14]、T5[322]、Flan-T5[323]和CodeT5[324]在内的小型语言模型作为学生模型。这些小型语言模型在保持强大泛化能力的同时针对效率进行了优化,使其适合部署在资源受限的环境中。
白盒知识蒸馏。白盒知识蒸馏通过利用教师模型内部表征的额外洞见,扩展了传统的蒸馏范式。当教师模型的架构已知且可访问时,这种方法尤其有益,因为它允许使用更丰富的监督形式。与将教师模型视为不透明函数的黑盒知识蒸馏不同,白盒知识蒸馏使学生模型不仅能够从教师模型的输出逻辑值中学习,还能从其中间激活值、隐藏层,甚至可能包括注意力权重中学习[325]。
DeepSeek-R1:推理模式的直接蒸馏技术。DeepSeek-R1通过将大规模模型中的复杂推理模式蒸馏到紧凑架构中,充分体现了知识蒸馏的变革性潜力,显著增强了较小大型语言模型的推理能力,同时避免了在此类模型上直接进行强化学习所带来的计算负担。这种被称为"直接蒸馏"的方法,利用了由大型教师模型生成的大约80万个样本构成的精选数据集,其中包含20万个源自DeepSeek-V3的非推理实例,以及60万个由DeepSeek-R1-Stage1检查点生成的推理实例。这些样本构成了对开源基础模型(如Qwen和LLaMA迷你变体)进行监督微调的基础,使学生模型能够继承通常只有其大型对应模型才具备的复杂推理能力。
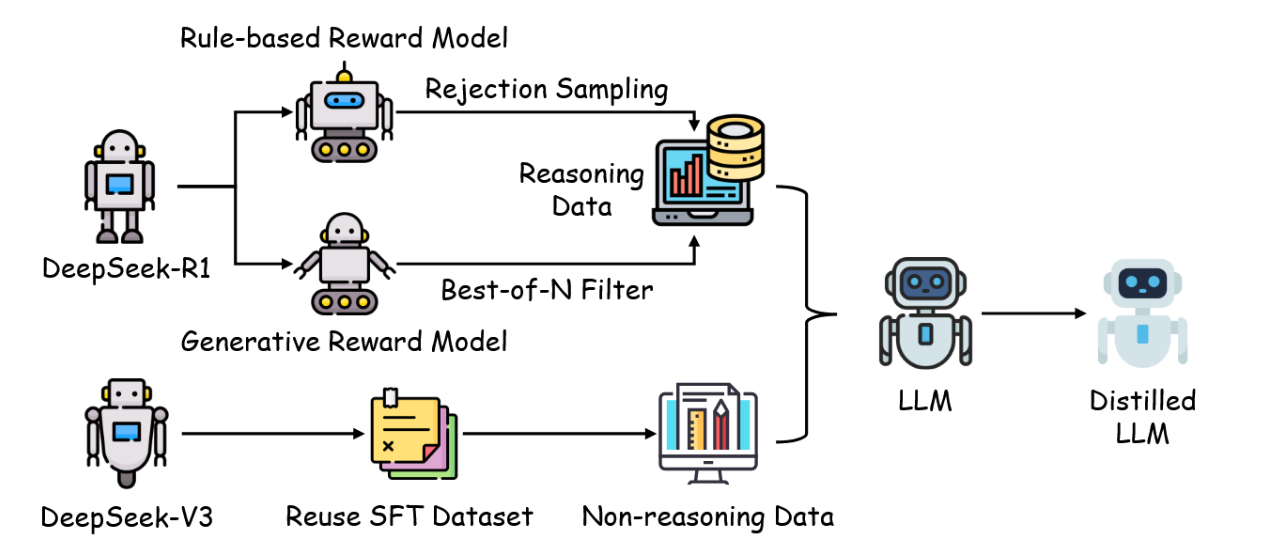
图17:DeepSeek-R1中的知识蒸馏工作流程,展示了从大型模型向紧凑模型迁移推理模式的过程。
DeepSeek-R1的直接蒸馏过程在一个结构化的管道中进行,如图17所示。首先,在大规模数据集上预训练的教师模型生成一个包含推理与非推理输出的多样化语料库,涵盖了一系列逻辑模式和事实知识。非推理数据(约20万样本)提供了通用知识的基线,而推理数据(约60万样本)则封装了多步骤推理链,这些数据经由教师模型的高级能力精炼而成。随后,该数据集被用于监督微调阶段:学生模型通过推理数据进行训练,使其输出分布与教师模型对齐,从而对较小的模型进行直接微调,以蒸馏出紧凑的推理模型。传统强化学习方法直接应用于小模型时,可能因其有限能力导致推理效果欠佳;而DeepSeek-R1的直接蒸馏通过迁移已优化的推理行为规避了此类限制,在降低资源需求的同时实现了更优的性能。
DeepSeek-R1知识蒸馏方法的一个显著特征,是其注重维持不同模型规模间的推理完整性。通过整合来自DeepSeek-R1-Stage1(一个经过大规模强化学习精炼的检查点)的推理轨迹,学生模型不仅能够复现事实准确性,还能模拟复杂的推理过程,例如数学问题求解或逻辑演绎所需的过程。这种针对性迁移与通常优先分类任务的传统知识蒸馏形成对比,凸显了DeepSeek-R1在面向推理的蒸馏方面的创新。此外,该方法最大限度地减少了对学生模型进行大量强化学习迭代的需求,利用教师模型预计算的推理输出来简化训练,从而提高了效率与可扩展性。该方法论确立了DeepSeek-R1作为将高级推理能力蒸馏至紧凑大型语言模型的范式,为未来的后训练优化工作提供了蓝图。
7 面向整合与适配的PoLM框架
集成与适应技术对于提升大语言模型(LLM)在多样化现实应用中的通用性与效能至关重要。这些方法使LLM能够无缝处理异构数据类型、适应特定领域,并融合多种架构优势,从而应对复杂多元的挑战。本章详述了三大核心策略:多模态集成(§7.1),使模型能够处理文本、图像、音频等多种数据模态;领域适应(§7.2),针对特定行业或用例优化模型;以及模型合并(§7.3),通过整合不同模型的优势能力以优化整体性能。这些方法共同增强了LLM的适应性、效率与鲁棒性,拓宽了其在各类任务与场景中的适用边界。
7.1 多模态集成
在前述章节所阐述的训练后优化策略基础上,本节探讨旨在增强大语言模型与大型多模态模型对多模态数据进行高效处理的进阶方法。尽管监督微调能够提升大语言模型在特定任务场景下的能力,但其在利用多模态完整潜力方面的局限性,要求采用更为精密的训练后优化途径。这些技术通过将多样化数据类型整合至统一框架,使大型多模态模型能够处理复杂的跨模态任务(例如根据视觉输入生成网页代码[326]、阐释如模因等细粒度文化符号[327]、以及在不依赖光学字符识别的情况下进行数学推理[50])。典型的大型多模态模型包含模态编码器、预训练大语言模型主干以及模态连接器[328],如图18所示。该架构构成了优化各组件的训练后方法之基础,从而助力实现稳健的多模态集成与性能提升。
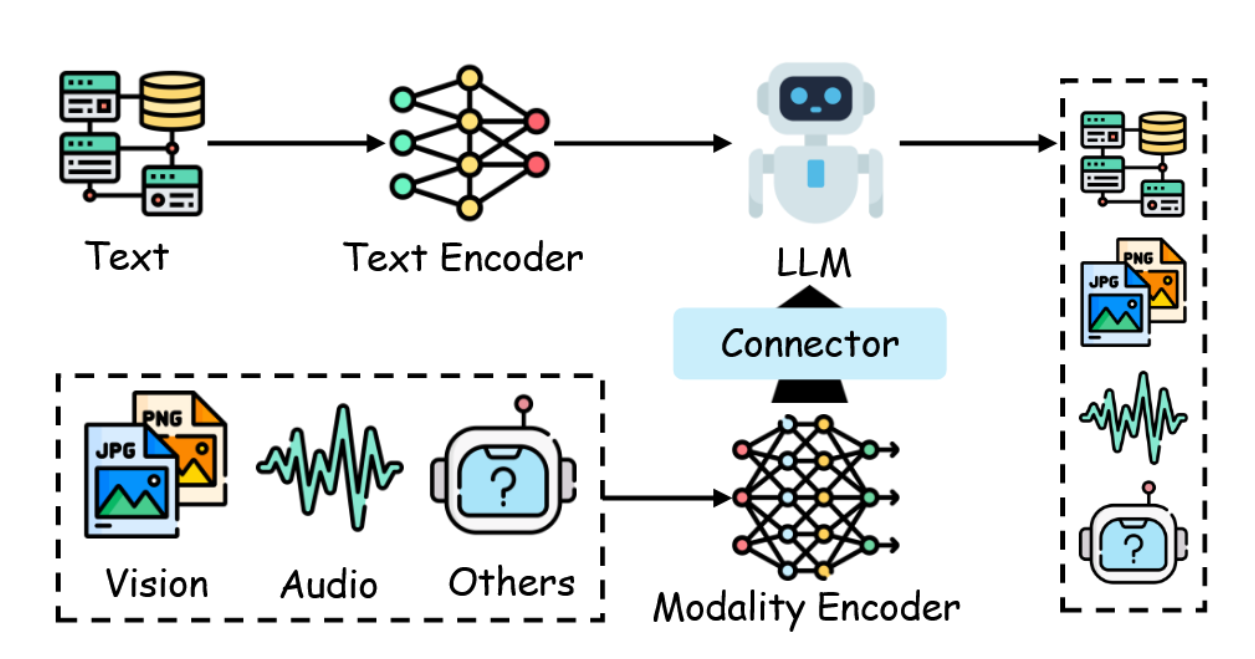
图 18:典型大型多模态模型的架构。
7.1.1 模态连接
模态连接方法在将多模态数据整合为连贯表征框架中至关重要,主要分为三类策略:基于投影、基于查询和基于融合的方法[328],如图19所示。
基于投影的模态连接。基于投影的方法将不同模态输入转换至统一的文本嵌入空间,使其特征与大型语言模型的语言维度对齐,实现无缝整合。LLaMA-Adapter[329]是此类方法的代表,通过引入图像编码器将大型语言模型扩展为多模态系统,实现图像条件指令跟踪。其后续版本LLaMA-Adapter V2[330]通过将视觉标记嵌入大型语言模型的早期层,优化了视觉知识的融合过程。FROMAGe[331]在冻结的大型语言模型和视觉编码器框架中微调输入输出层以实现跨模态交互,而LLaVA-1.5[332]则采用双线性多层感知机(MLP)增强多模态处理的鲁棒性。最新进展中,例如Shikra [333]通过整合空间坐标来增强自然语言对话,VILA [334]通过优化视觉-语言预训练实现卓越的零样本能力。DetGPT [335]进一步推进了这一范式,它将推理驱动的目标检测与自然语言交互相结合,并利用投影技术促进有效的多模态通信。SOLO [336]采用单一的Transformer架构进行统一端到端的视觉-语言建模,它同时接受原始图像块(以像素为单位)和文本作为输入,无需使用独立的预训练视觉编码器。与此同时,MiniGPT-4 [326]通过单层投影将冻结的视觉编码器与Vicuna对齐,采用两阶段训练流程实现了类GPT-4的能力。Idefics [337]凭借自回归设计和多阶段预训练在高效推理方面表现卓越。LaVIT [338]通过离散视觉分词器统一视觉与语言以实现无缝生成。DeepSeek-VL2 [339]通过动态分块和多头潜在注意力增强了高分辨率图像理解能力。最后,Qwen2.5-VL [340]凭借重新设计的Vision Transformer在多模态任务上取得进展,在感知和视频理解方面表现突出。
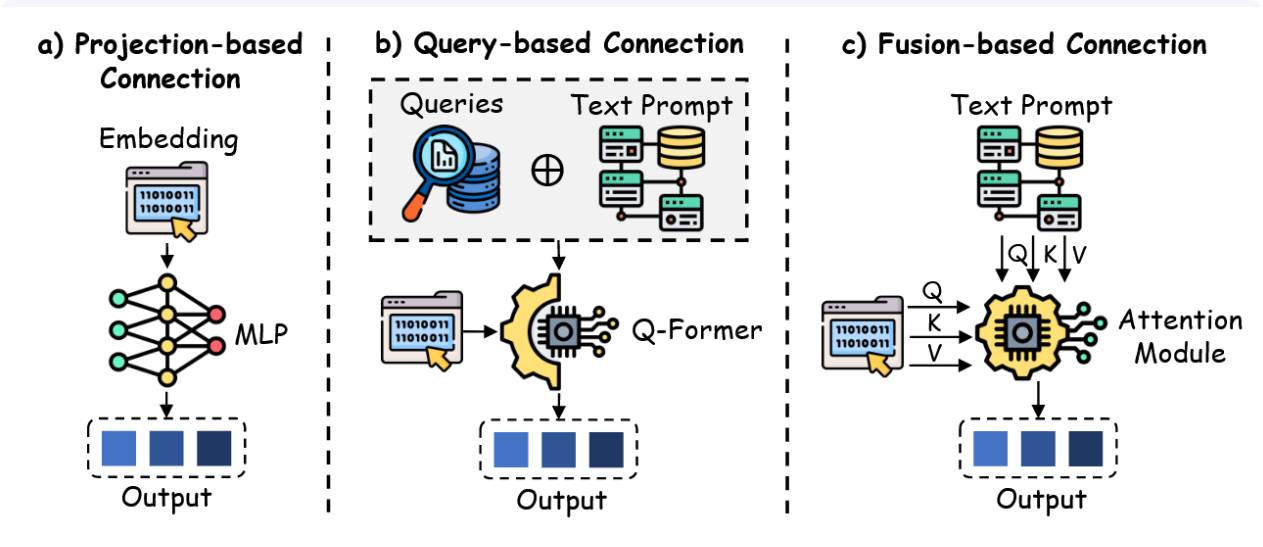
图19:多模态整合中的模态连接方法分类,涵盖基于投影、基于查询和基于融合的方法。
基于查询的模态连接。基于查询的方法通过使用可学习的查询令牌从不同模态中提取结构化信息,增强多模态整合,弥合文本与非文本数据之间的鸿沟。BLIP-2 [52] 率先采用查询变换器实现了这一方法,高效整合文本与视觉输入。Video-LLaMA [341] 通过结合视觉编码器将该技术拓展至视频理解领域,而 InstructBLIP [342] 则优化了查询机制以确保对指令的精准遵循。X-LLM [343] 通过专用接口对齐多模态输入,后续创新如 mPLUG-Owl [344] 与 Qwen-VL [345] 针对计算效率优化了 Q-Former 架构。LION [346] 通过推进视觉知识整合进一步证明了基于查询方法的有效性,彰显了其在提升大语言模型(LMM)跨任务性能方面的实用性。Qwen-VL [345] 是基于 Qwen-7B 构建的一系列大规模视觉语言模型,它包含视觉接收器、位置感知适配器以及三阶段训练流程,以实现多语言、细粒度的视觉语言理解。Lyrics [347] 是一种细粒度视觉语言预训练与指令微调框架,它通过视觉精炼器(图像标注、目标检测和语义分割)与多尺度查询变换器(MQ-Former)整合语义感知的视觉对象,从而增强大规模视觉语言模型(LVLM)的性能。
基于融合的模态连接。基于融合的技术通过将多模态特征直接嵌入LLM架构,在推理层面实现更深入的跨模态交互与更丰富的整合。Flamingo [51]采用交叉注意力层在token预测过程中融合视觉特征,实现动态多模态处理。OpenFlamingo [348]在此基础上发展,允许冻结的LLM关注视觉编码器输出,增强了灵活性。Otter [349]引入指令微调以提升多模态指令跟随能力,而CogVLM [350]在Transformer层内集成视觉专家模块,实现无缝的特征合成。Obelics [351]利用交错式图文训练数据,凸显了融合方法在实现协调统一的多模态性能方面的鲁棒性。InternVL [352]是一个大规模视觉-语言基础模型,其视觉编码器参数规模扩展至60亿,并通过语言中间件(QLLaMA)实现与LLM的渐进式对齐。Llama 3 [25]是Meta开发的新一代多语言、可使用工具的基础模型系列,其参数量最高达4050亿,上下文窗口为128K token,通过提升数据质量、更大规模训练及结构化后训练策略实现优化。
7.1.2 模态编码器
模态编码器将原始多模态输入压缩为紧凑且语义丰富的表示形式,实现对多样化任务与模态的高效处理。这些组件对于将异构数据转换为与LLM骨干网络兼容的格式至关重要,可支持从视觉推理到音频理解等多种应用场景。表7全面汇总了视觉、音频及其他模态领域常用的编码器,详细阐述了其特性及对多模态融合的贡献。
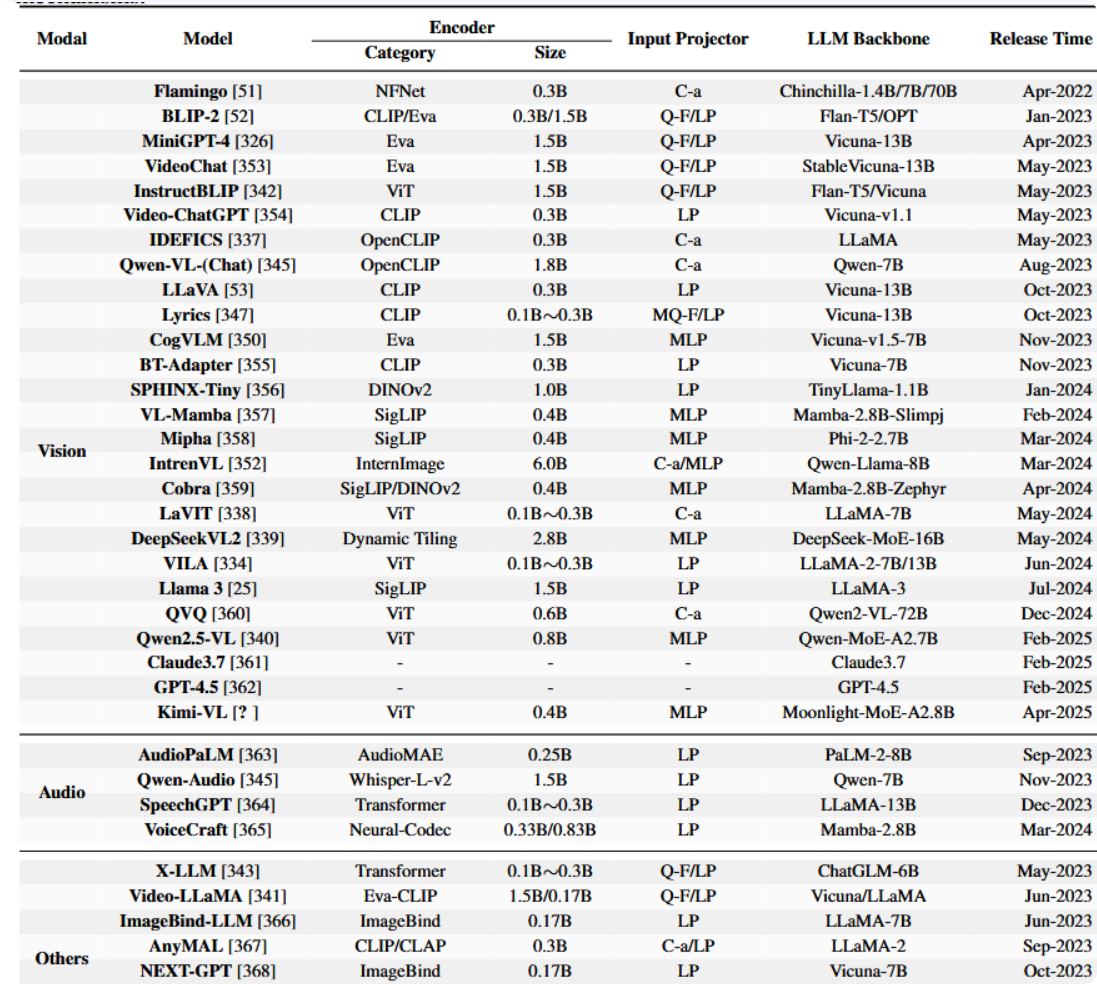
表7:跨模态编码器与大型多模态模型概览(2022–2025)。本表汇总了关键多模态模型,详述了其在视觉、音频及其他模态下的编码器类别、规模、输入投影器、大型语言模型主干及发布时间线。度量指标包括C-a(交叉注意力)、Q-F(Q-Former)、MQ-F(多查询Q-Former)及LP(线性投影器),代表输入投影机制。
视觉编码器是多模态学习的基础,能够促进大型多模态模型中对视觉数据的解释与生成。CLIP [372] 通过对比学习建立联合的图像-文本表征,增强了跨模态对齐能力。EVA [373] 改进了视觉注意力机制以提升效率,而 ImageBind [374] 构建了跨多种模态的统一嵌入空间,提升了零样本识别能力。SigLIP [375] 引入了成对Sigmoid损失来优化图像-文本预训练,DINOv2 [376] 则采用无监督学习从多样数据源中提取鲁棒的视觉特征。LLaVA [53] 采用自指导策略将图像转换为文本描述,并利用先进的大语言模型生成新颖数据集。Video-ChatGPT [354] 通过大规模指令数据集支持对话式视频理解,而 BT-Adapter [355] 则通过高效的时序建模优化视频理解能力。VideoChat [353] 专注于时空推理,并利用专业化数据集进行训练;诸如 CoDi-2 [369] 和 Mipha [358] 等模型则在多模态处理中实现了效率提升。VL-Mamba [357] 和 Cobra [359] 引入了状态空间模型以优化推理过程,SPHINX-Tiny [356] 则强调数据多样性与训练效率。
音频编码器。音频编码器增强了大型多模态模型处理与解析听觉输入的能力,从而拓宽了其多模态应用范围。SpeechGPT [364] 通过将大规模语音数据集与卷积及Transformer架构 [377] 相结合,实现了强大的指令跟随能力。AudioPaLM [363] 利用通用语音模型(USM)编码器 [378] 整合文本与语音处理,在零样本语言翻译等任务中表现卓越。WavCaps [379] 采用CNN14 [380] 和HTSAT [381] 以缓解音频-语言数据稀缺问题,并利用先进的大型语言模型提升数据集质量、强化学习效果,凸显了音频模态在多模态系统中的关键作用。
其他编码器。除视觉与音频外,针对三维理解与多模态融合等额外模态的编码器对于构建全面的多模态大模型至关重要。NEXT-GPT [368] 实现了文本、图像、视频及音频的跨模态内容生成,通过最小化参数调整推进了类人人工智能能力的发展。ImageBind-LLM [366] 通过对齐视觉与语言嵌入,提升了跨模态的指令跟随性能。LL3DA [370] 处理点云数据以进行三维推理与规划,为空间理解引入了新方法。X-LLM [343] 采用 Q-Former [52] 处理图像与视频输入,并利用 C-Former [343] 处理语音,将音频特征压缩为令牌级嵌入以提升多模态学习效率。
7.2 领域自适应
领域适应(DA)是精调大语言模型以在特定领域表现卓越的关键后训练策略,能确保其在目标应用中的效能。该方法植根于迁移学习原理[382, 383],通过适应函数 F a d a p t F_{adapt} Fadapt 将初始模型 M s o u r c e M_{source} Msource 转化为领域专用模型 M t a r g e t M_{target} Mtarget,其过程可描述为:
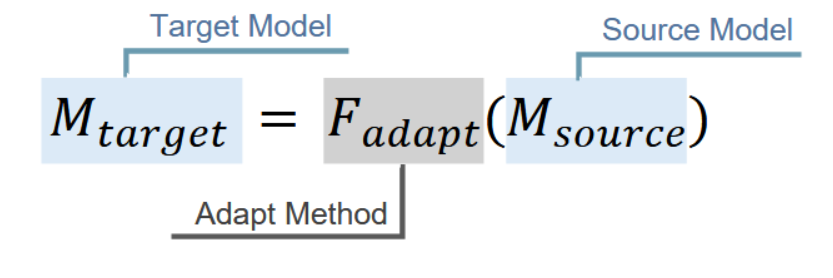
该过程针对特定领域的独特需求与复杂性,对目标模型进行定制化调整,从而优化其性能表现与领域相关性。通过提升大语言模型在编程[384, 385]与数学推理[386]等领域的专业能力,领域自适应不仅增强了领域特定功能,还提升了计算效率,有效缓解了通用模型在处理领域专业术语和推理范式时常见的局限性。此外,该方法显著降低了对大规模标注数据集和计算资源的依赖——这类资源通常是为从头训练领域专用模型所必需的[387],这使其成为后训练方法体系的基石。
7.2.1 知识编辑
知识编辑是一种复杂的后训练方法,旨在修改大型语言模型以满足领域特定需求,同时不损害其基础能力。该技术通过实现有针对性的参数调整,在保留模型原有性能的同时整合新的或更新的领域知识[388]。知识编辑能够快速适应不断演变的知识格局,因此成为后训练流程中不可或缺的组成部分。表8概述了主要方法(例如,涵盖外部知识利用、知识整合与内部编辑)。
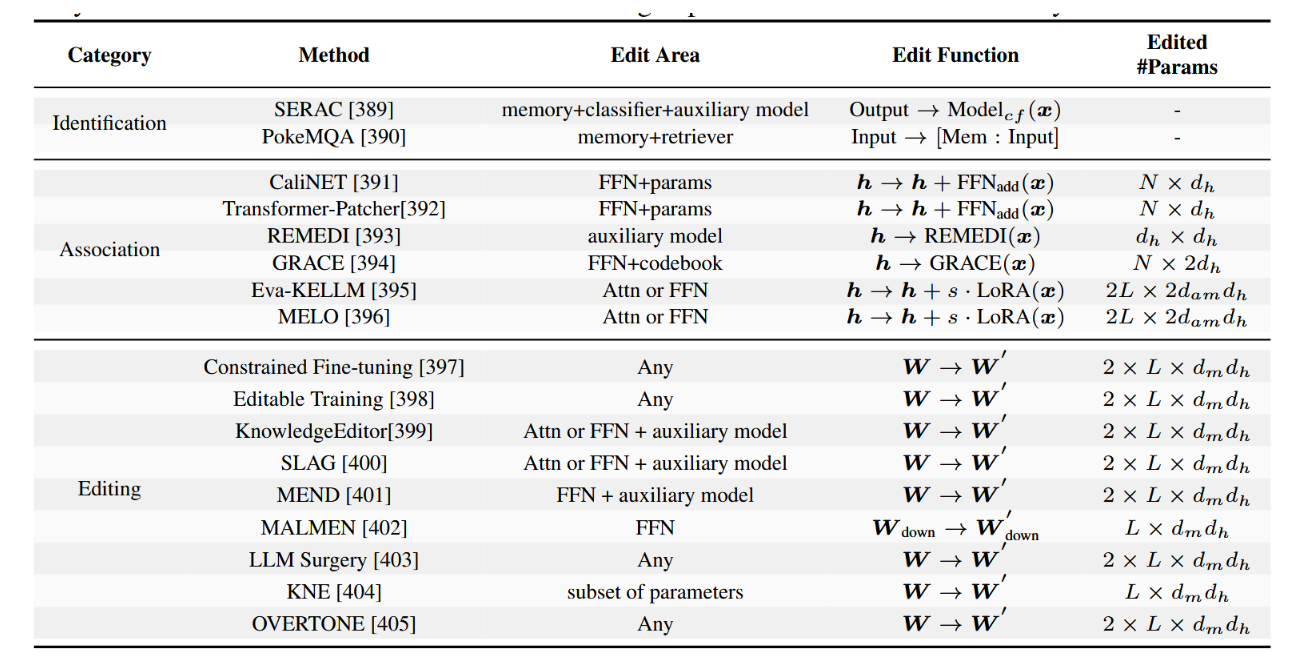
表8:大语言模型知识编辑代表方法的比较分析。编辑区域指定模型中被修改的目标组件;编辑器参数量表示编辑过程中需要更新的参数。L代表被修改的层数,dh表示Transformer架构中隐藏层的维度,dm指代上投影与下投影阶段之间的中间维度,N象征各独立层中接受更新的神经元总数。
知识编辑的形式化定义。考虑一个由参数θ描述的原始大语言模型,其预训练数据集为Dold。令Dnew表示包含新信息或更新信息∆K的数据集。知识编辑的目标是通过施加参数调整∆θ,得到修正后的参数集θ′,从而有效吸收∆K,同时最小化对Dold的性能衰退。形式化地,这被表述为一个约束优化问题,其中更新后的参数定义为:
θ ′ = θ + Δ θ , w h e r e L ( θ ′ ; D n e w ) → m i n , \theta^{\prime}=\theta+\Delta\theta,\mathrm{where~}\mathcal{L}{\left(\theta^{\prime};\mathcal{D}_{\mathrm{new}}\right)}\mathrm{~\to~min,} θ′=θ+Δθ,where L(θ′;Dnew) → min,
其中 L 代表评估模型在 Dnew 上质量的损失函数(例如交叉熵)。为确保在原始数据集上的性能,施加如下约束:
L ( θ ′ ; D o l d ) ≤ L ( θ ; D o l d ) + ϵ , \mathcal{L}(\theta^{\prime};\mathcal{D}_{\mathrm{old}})\leq\mathcal{L}(\theta;\mathcal{D}_{\mathrm{old}})+\epsilon, L(θ′;Dold)≤L(θ;Dold)+ϵ,
其中 ε 为限制在旧数据集 D_old 上性能损失的小正常数。该公式确保 θ′ 在融入 ∆K 的同时,保留了模型的先验知识库。实践中,∆θ 可被约束在特定的架构组件内(例如注意力层(Attn)或前馈网络(FFN)),通过避免全面重训练来降低计算开销并保持核心功能。
知识识别。知识编辑的初始阶段聚焦于检测新信息并使其融入模型。PokeMQA[390]采用可编程范围检测器与知识提示来解析查询,从而高效检索相关事实。与之相对,SERAC[389]将反事实模型与分类器结合,用以判断新知识源的适用性,该方法侵入性小,能在避免大规模结构改动的前提下保持基础模型的完整性。[406]分析了大型语言模型知识更新产生混乱涟漪效应的原因。现实世界中的编辑通常源于新兴事件,这些事件包含了新事实与过去事实间的逻辑关联;基于此观察,EvEdit[407]提出一种基于事件的知识编辑方法,以确定知识锚点与知识更新边界。
知识关联。在识别之后,此阶段将新获取的信息与模型现有知识框架进行关联。Transformer-Patcher[392]通过改造Transformer架构来整合更新后的事实,而CaliNET[391]则重新校准参数以对齐事实内容。诸如Eva-KELLM[395]、MELO[396]和REMEDI[393]等方法通过细化特定行为实现精准更新,GRACE[394]则在知识插入后提升预测准确性,确保其与已有表征的无缝整合。
内在知识编辑。最终阶段将关联事实嵌入模型内部结构,确保其被全面吸收。传统微调可能耗费大量资源,而先进技术能减轻此负担。约束微调[397]与元学习[399]可最小化知识损失与过拟合风险。可编辑训练[398]与KnowledgeEditor[399]能以极小性能代价实现快速参数调整;而SLAG[400]、MEND[401]和MALMEN[402]则能解决编辑冲突、支持大规模更新,在融入新领域知识的同时保持基础能力。LLM Surgery[403]通过应用反向梯度移除过时数据、梯度下降集成新事实、以及KL散度项保留现有知识,将遗忘与编辑统一起来,实现了显著的计算效率提升。KNE[404]提出一种知识神经元集成方法,仅定位并更新与新增事实强相关的神经元,在保护无关知识的同时实现更精准的编辑。OVERTONE[405]通过引入令牌级平滑技术应对知识编辑中的异构令牌过拟合问题,该技术自适应地优化训练目标,从而保留预训练知识并提升模型对新插入事实的推理能力。这些针对性技术确保模型在整合新获取信息的同时,能够保持其基础能力。
7.2.2 检索增强生成
检索增强生成(RAG)将传统信息检索与当代大语言模型相结合,以提升生成内容的相关性与事实准确性[48, 408, 409]。该方法通过动态地从外部源检索相关信息并将其嵌入生成过程,弥补了大语言模型在领域特定知识上的不足,并降低了产生幻觉内容的倾向。这一方法在需要精确、最新信息的领域尤为有效,例如问答系统[48]、科学研究[410]和医疗健康[411],在这些领域中,它能够熟练处理复杂查询和知识密集型任务。此外,RAG减少了对话系统中误导性回复的出现,提升了知识驱动自然语言生成的可靠性[411, 412]。
本小节聚焦于基于训练的RAG方法[413],认识到免训练的RAG方法[414, 415, 416]由于缺乏任务特定优化,可能影响知识利用效率。如图20所示,三种主流的训练策略——独立训练、顺序训练与联合训练——提升了模型的适应性与融合能力。
独立训练:该策略将检索器与生成器作为独立模块进行训练,便于根据任务需求灵活采用稀疏或稠密检索器。例如,DPR[417]使用双BERT网络分别编码查询与段落,并应用对比学习进行优化,而不与生成器交互。类似地,[418]提出了Reward-RAG,其利用奖励模型仅根据基于GPT的反馈对检索器进行微调,而不改动生成器。
顺序训练:顺序训练通过一次优化一个模块来提升效率,促进检索器与生成器之间的协同。它包括检索器优先的方法[419, 420, 421, 422, 423]与RETRO[424]类似——该方法在训练编码器-解码器前会预训练一个基于BERT的检索器,以无缝整合检索内容来提升性能。另一种LLM-First方法[425, 426, 427](如RA-DIT[428])则首先对语言模型进行微调,使其能有效利用检索到的知识,随后优化检索器以实现更好的对齐与连贯性[419, 425]。
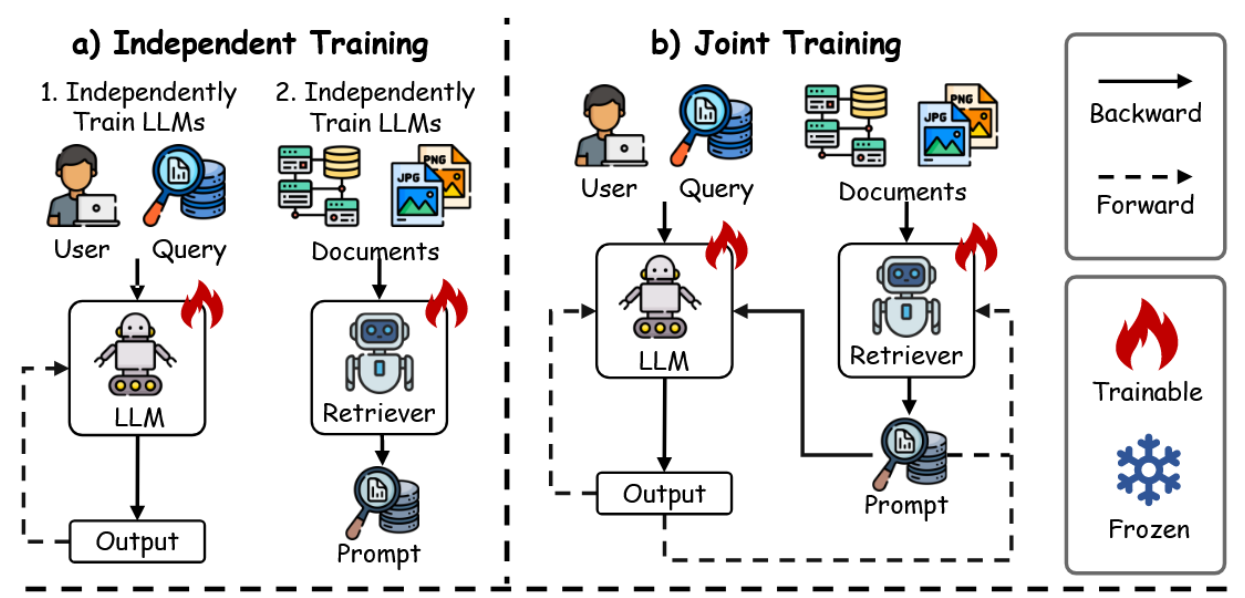
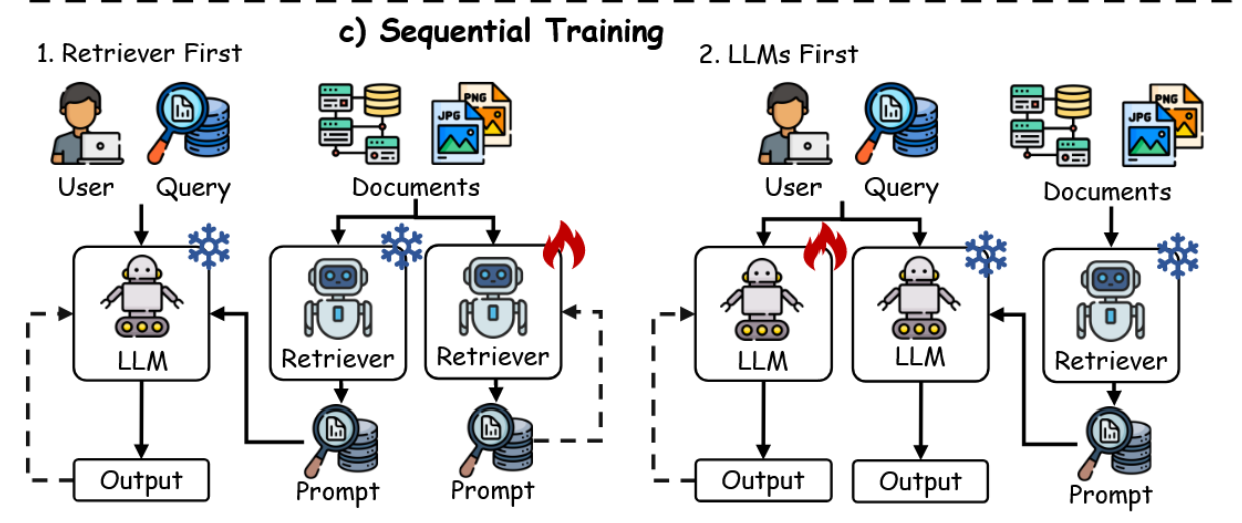
图20:检索增强生成(RAG)训练方法分类体系,涵盖独立训练、序列训练与联合训练策略。
7.3 模型合并
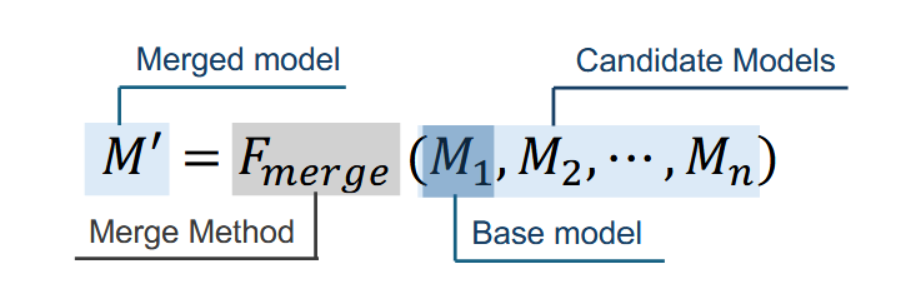
模型融合已成为提升大语言模型在训练和推理阶段性能与效率的关键后训练策略[431, 432]。该方法将多个专用模型整合为统一架构,避免了大规模重新训练的需求,并应对了大模型体量与计算要求带来的挑战。与在混合数据集上进行训练不同,模型融合将单任务模型集成为一个具备多任务能力的统一整体,为多任务学习提供了一种资源高效的范式。通过简化训练流程,并促进开发具有跨应用鲁棒泛化能力的通用模型,该技术优化了大语言模型在不同场景中的部署。给定一组候选模型 M = {M1, M2, . . . , Mn},其目标是设计一个融合函数 Fmerge,以生成一个统一模型 M′(可能以基础模型 M1 为锚点),如图所示:
7.3.1 层级模型融合
模型合并技术被系统性地划分为三个层级——权重级、输出级和模型级合并——如图21所示。
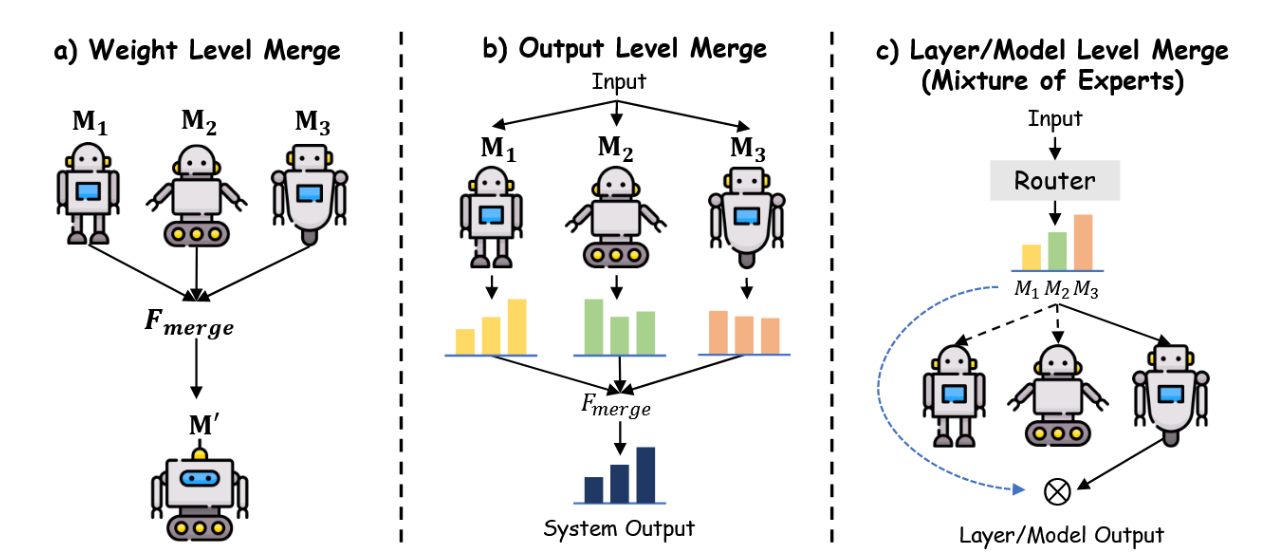
图21:大型语言模型融合技术分类体系,详细划分了权重层面、输出层面及模型层面等层级方法。
权重级模型合并。权重级合并直接在参数空间进行操作,因此对于架构相似或在相关任务上训练的模型尤为有效。形式化地,给定参数集合 θ1, θ2, . . . , θn ∈ R^d,线性合并方案将这些参数聚合为一个统一的集合 θ′,其表达式为:
θ ′ = α 1 θ 1 + α 2 θ 2 + … + α n θ n , s u b j e c t t o α k ≥ 0 , ∑ k = 1 n α k = 1. \theta^{\prime}=\alpha_{1}\theta_{1}+\alpha_{2}\theta_{2}+\ldots+\alpha_{n}\theta_{n},\quad\mathrm{subject~to}\quad\alpha_{k}\geq0,\sum_{k=1}^{n}\alpha_{k}=1. θ′=α1θ1+α2θ2+…+αnθn,subject toαk≥0,k=1∑nαk=1.
模型汤[433, 434]是这一思路的范例,它通过线性组合在不同任务上微调后的模型权重,得到一个单一且高效的模型。任务算术[435]通过对参数进行算术运算扩展了这种灵活性,从而提升了性能适应性。为缓解参数对齐问题,TIES合并[436]确保了参数一致性,而DARE[437]则通过概率性地调整参数增量来最小化干扰,从而优化合并过程的一致性与效率。
输出级模型融合。当模型在架构或初始化方面存在差异,导致权重级方法不可行时,输出级融合变得具有优势。该方法聚合的是输出分布而非内部参数,其公式表达为:
y ′ = α y 1 + ( 1 − α ) y 2 , α ∈ [ 0 , 1 ] , y^{\prime}=\alpha y_1+\left(1-\alpha\right)y_2,\quad\alpha\in[0,1], y′=αy1+(1−α)y2,α∈[0,1],
其中y₁和y₂分别代表模型M₁和M₂输出的概率分布。该方法类似于集成策略,将各模型的预测结果合成为统一输出。LLMBlender [438] 通过生成独立输出并借助排序与生成过程进行融合实现此目标,而FuseLLM [439] 则将组合输出的概率分布提炼至单一网络中以保持分布保真度。FuseChat [440] 通过将多个大语言模型的知识迁移至统一目标模型中,桥接了权重层面与输出层面的融合,从而增强了跨模型协同能力。
模型级模型合并。模型级合并通过路由机制集成了子模型或层,通常在混合专家框架内实现,其数学表达为:
M ′ = M e r g e ( M 1 , M 2 ) , M^{\prime}=\mathrm{Merge}\left(M_1,M_2\right), M′=Merge(M1,M2),
其中Merge代表硬路由或软路由函数。Switch Transformer [54] 采用离散门控机制选择性地激活专家层,虽能降低计算负荷,但固化的路由方式可能导致性能折损。SoftMoE [441] 与SMEAR [442] 则运用连续门控机制,实现专家间更平滑的过渡,从而增强组件整合性与模型内聚性。
7.3.2 预合并方法
预融合方法通过优化独立模型的权重空间、架构一致性与参数对齐,为模型融合建立兼容性基础,从而最小化后续融合阶段的冲突与干扰。这些技术提升了融合过程的效能,确保最终的统一模型保留各组成模型的优势,同时缓解可能的性能退化。
线性化微调:该方法在预训练模型的切空间内优化模型,避开原始非线性参数空间以实现权重解耦,从而降低融合过程中的干扰。例如部分线性化适配器(如TAFT [443])或注意力层线性化[444]等技术,将权重更新对齐至互不相交的输入区域,从而在融合模型中保留独立功能[445]。通过将更新约束在线性化框架内,此方法促进了不同模型间的无缝整合。
架构转换:该策略将架构异构的模型转换为适于直接参数融合的同构形式。典型方法包括知识蒸馏(如FuseChat [440])和恒等层插入(如CLAFusion [446])。GAN Cocktail [447]通过初始化目标模型以吸收异构架构的输出,实现能有效弥合结构差异的统一融合流程。
权重对齐:该方法通过置换操作将模型对齐至共享权重盆地,利用线性模式连通性(LMC)特性提升兼容性。技术涵盖最优传输(OTFusion [448])、启发式匹配(Git re-basin [449])以及基于学习的对齐(DeepAlign [450])。REPAIR [451]可缓解缺乏归一化层模型中的对齐失效问题,确保融合前实现稳健的参数收敛。
7.3.3 合并中方法
动态融合方法侧重于动态优化参数融合策略,以解决任务冲突、减轻干扰,并提升合并后模型的性能与泛化能力。这些方法应对了实时集成异质模型的挑战,增强了统一架构的适应性与鲁棒性。
基础合并。该方法利用简单的参数平均或任务向量运算,将任务向量τt定义为第t个任务微调后的参数Θ(t)与初始预训练参数Θ(0)之间的偏差:
τ t = Θ ( t ) − Θ ( 0 ) , \tau_t=\Theta^{(t)}-\Theta^{(0)}, τt=Θ(t)−Θ(0),
并通过公式 [ Θ ( m e r g e ) = Θ ( 0 ) + λ ∑ t = 1 T τ t [\Theta^{(\mathrm{merge})}=\Theta^{(0)}+\lambda\sum_{t=1}^T\tau_t [Θ(merge)=Θ(0)+λ∑t=1Tτt[435] 来促进多任务学习。尽管该方法计算高效且概念优雅,但其常因未缓解的参数交互而产生任务干扰,限制了其在需要复杂任务协调的场景中的应用。加权合并。该策略根据各模型的重要性动态分配合并系数,定制其贡献以优化融合结果。MetaGPT [452] 通过对每个任务向量的L2范数平方进行归一化来计算最优权重:
λ t ∗ = ∥ τ t ∥ 2 ∑ k = 1 T ∥ τ k ∥ 2 , \lambda_t^*=\frac{\|\tau_t\|^2}{\sum_{k=1}^T\|\tau_k\|^2}, λt∗=∑k=1T∥τk∥2∥τt∥2,
因此,为参数偏移更显著的任务分配更大影响力,具体表现为更高的 ∥τt∥₂ 值。SLERP [432] 采用球面插值确保参数平滑过渡,保持模型连续性;而层级自适应合并 [453] 通过逐层粒度优化系数来精炼此过程,提升合并架构内的任务特定精度。
子空间合并。该方法将模型参数投影至稀疏子空间,在保持计算效率的同时最小化干扰,解决参数贡献重叠问题。TIES合并 [436] 保留幅度前 20% 的参数,通过解决符号冲突保持一致性;DARE [437] 对稀疏权重进行缩放以减少冗余;Concrete [454] 利用双层优化构建自适应掩码,确保模型组件在跨任务干扰降低的情况下实现精细整合。
基于路由的合并。该技术根据输入特定属性动态融合模型,实现上下文响应式的集成过程。SMEAR [442] 计算样本依赖的专家权重以优先处理相关特征;权重集成混合专家 [455] 采用输入驱动的线性层路由实现选择性激活;Twin-Merging [456] 融合任务共享与任务私有知识,构建能适应多样化输入需求并增强多任务鲁棒性的灵活合并框架。
后校准。该技术通过将统一模型的隐层表征与独立成分模型的表征对齐,纠正合并后的表征偏差,从而缓解性能下降。表征修正 [319] 是典型代表,它通过精细化表征一致性来增强合并模型的鲁棒性与准确性。
8 数据集
后训练技术旨在精调大型语言模型对特定领域或任务的适应能力,其优化过程以数据集为核心基础。对已有研究[457, 82]的系统性分析表明,数据的质量、多样性与相关性深刻影响模型效能,往往决定着后训练实践的成败。为阐明数据集在此情境下的关键作用,本文对后训练阶段所使用的数据集进行了全面回顾与深度剖析,并依据其采集方法归纳为三大主要类型:人工标注数据、蒸馏数据与合成数据。这些类别体现了截然不同的数据构建策略,模型或采用单一类型,或融合多种类型以平衡扩展性、成本与性能。表9详尽概述了这些数据集的来源、规模、语言、任务及对应的后训练阶段(例如SFT与RLHF),我们将在后续章节深入探讨,以揭示其在提升大语言模型能力方面的贡献与挑战。
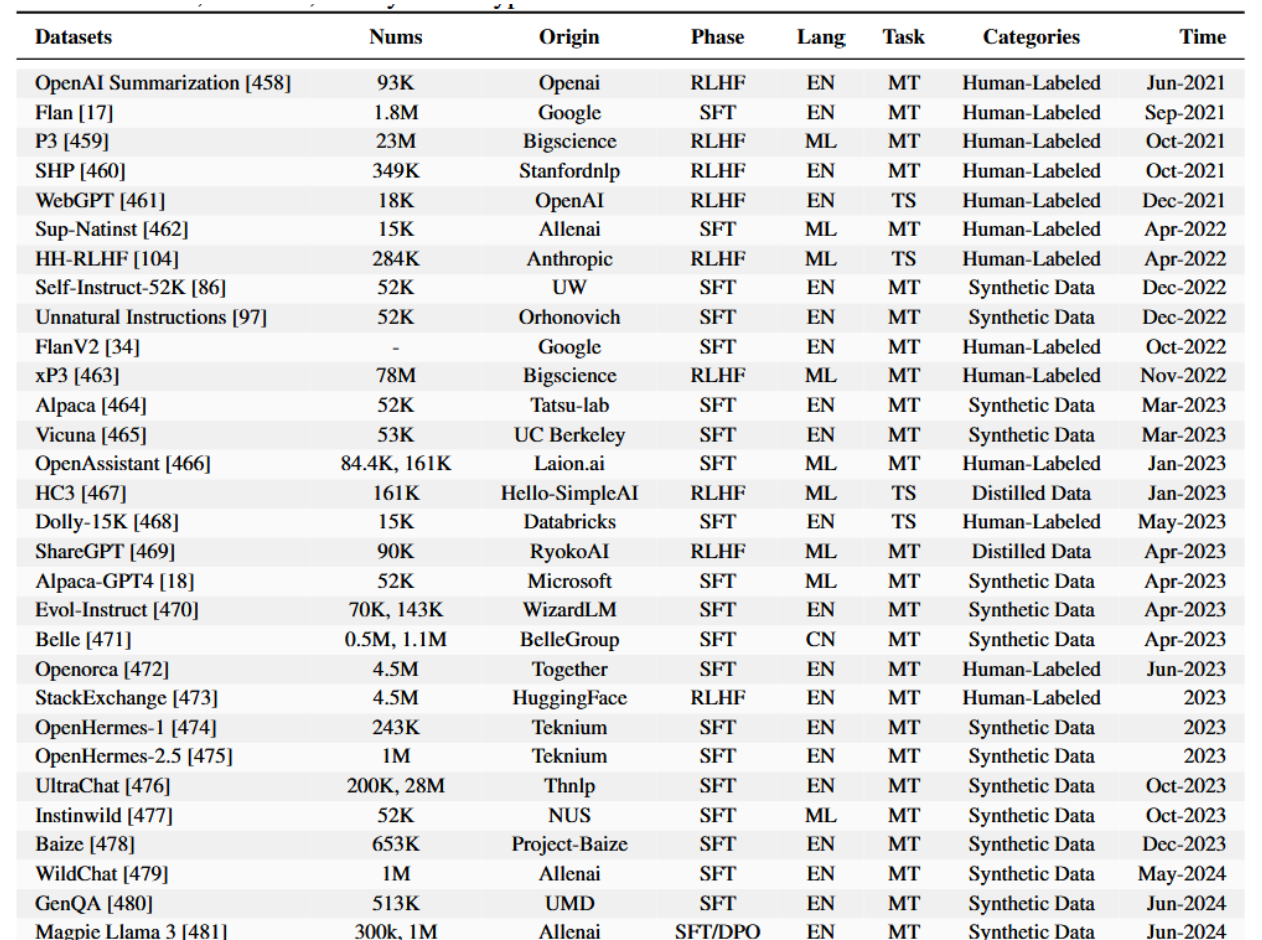
表9:大语言模型后训练使用数据集汇总(2021–2025年)。本表概述了关键数据集,详细说明了其规模、来源、发布时间线,以及三项指标的属性:Lang(语言:EN为英语,CN为中文,ML为多语言)、Task(类型:MT为多任务,TS为单任务)和Phase(用途:SFT为监督微调,RLHF为基于人类反馈的强化学习)。数据集涵盖从OpenAI Summarization到Magpie Reasoning V2,并按人类标注、蒸馏和合成三种类型进行分类。
8.1 人工标注数据集
人工标注数据集以其卓越的准确性与语境保真度著称,这些特性源于标注者对任务复杂性的细致理解及其进行精确、语境敏感调整的能力。此类数据集构成了指令微调优化的基石,通过提供高质量、经专家精心策划的训练信号,显著提升了大语言模型在多种任务上的性能。在该类别中,诸如Flan [17]、P3(公共提示池)[459]、Sup-Natinst(超自然指令集)[462]以及Dolly-15K [468]等突出范例,已成为大语言模型后训练中被广泛采用的资源,各自凭借人类专业知识为模型能力优化贡献了独特优势。
用于监督微调的人工标注数据。在监督微调阶段,人工标注数据集发挥着不可或缺的作用,Flan、Sup-Natinst和Dolly-15K的贡献便印证了这一点:它们提供了精心构建的提示-响应对及任务专属指令,从而提升了大语言模型在多样化自然语言处理基准测试中的效能。
- Flan。Flan数据集[17]是一项基础性资源,最初涵盖62个广受认可的自然语言处理基准测试——例如HellaSwag [482]、MRPC [483]和ANLI [484]——通过其180万条样本为英文多任务学习提供了有力支撑。近期,FlanV2 [34]作为进阶版本出现,通过整合Flan [17]、P3 [459]、Sup-Natinst [462]及其将众多额外数据集整合为统一、全面的语料库,从而大幅提升其在多样化语言及任务领域中用于监督式微调(SFT)的实用性。
• 超自然指令集(Sup-Natinst)[462] 提供涵盖55种语言的76种任务类型,构成广泛而多样的资源体系,成为多语言大语言模型后训练的通用基准。每个任务均与一条指令精准配对:该指令包含明确的任务定义——阐述从输入文本到期望输出的映射关系——以及一组展示正确与错误回应的示例,为引导模型精准执行任务、增强跨语言适应能力提供了坚实的框架。
• Dolly-15k。由Databricks员工开发的Dolly-15K [468]是一个精心整理的语料库,包含15,000个高质量人工生成的提示-响应对,专为大型语言模型的指令微调而设计。该数据集涵盖广泛的主题与场景——包括头脑风暴、内容生成、信息提取、开放式问答和摘要等——体现了任务类型的丰富多样性,使模型能够灵活适应不同的指令语境,并增强上下文相关性。
在监督微调中,人工标注数据集的有效性源于其对任务和场景的广泛覆盖,上述语料库正是这一特征的例证。作为补充,OpenAssistant [466]通过全球众包努力构建了一个庞大的多语言对话语料库,并免费开放以推进研究;而OpenOrca [472]则扩展了FlanV2 [34],集成了数百万条GPT-3.5和GPT-4生成的补全内容,构成了一个动态扩展的、用于微调和任务对齐的资源。然而,尽管这些数据集对模型泛化能力贡献显著,确保标注质量一致性与多样性的挑战依然存在,这需要严格的质量控制以最大化其效用。
用于RLHF的人工标注数据。在RLHF中,P3及其多语言扩展xP3[463]、SHP[460]等人为标注数据集提供了关键的人类标注评估,用于细化LLM与用户偏好的对齐,从而为奖励建模提供细致的反馈机制。
• P3。P3数据集[459]是一个精心策划的指令微调资源,汇集了来自Hugging Face Hub的2300万个多任务提示,每个提示均配有手动编写的指令,涵盖多样化的NLP任务套件,从而为RLHF提供了丰富的基础,以增强LLM在不同应用中的适应性和精确性。
• xP3。xP3(跨语言公共提示池)[463]将P3扩展为多语言框架,涵盖46种语言和16项NLP任务的提示与监督数据,旨在支持如BLOOMZ和mT0等模型的多任务提示微调。其内容整合了英文P3数据集、四项新颖的英文任务(例如翻译、程序合成)以及30个多语言NLP数据集,为跨语言RLHF优化提供了全面资源。
• SHP。SHP[460]包含349,000条针对18个主题领域的问题和指令回答的人类偏好标注,通过评估回答的有用性来训练RLHF奖励模型并评估自然语言生成质量,其显著特点在于完全依赖人类创作的数据,以此区别于HH-RLHF等混合数据集。
这些数据集通过提供多样化的人类标注评估来增强RLHF,从而优化模型与用户偏好的对齐。OpenAI摘要数据集[458]和Webgpt[461]提供了基于对比的结构化反馈和利克特量表评分,有助于使模型输出更贴近人类预期。HH-RLHF[104]进一步强化了这一框架,包含对帮助性和无害性的评估,为确保安全与伦理回应的模型奠定了坚实基础。同时,StackExchange[473]贡献了特定领域的用户生成内容,丰富了训练数据,尤其有利于需要技术领域专业知识的模型。然而,这些数据集也面临可扩展性、人工标注潜在偏差以及特定领域外适用性有限等挑战。因此,尽管这些资源具有重要价值,仍可能需要补充更广泛的数据集,以实现模型在多样现实任务中的全面对齐。
8.2 蒸馏数据集
蒸馏数据源于将庞大原始数据集精炼为紧凑、优化子集的复杂过程,这些子集保留了LLM训练所需的关键信息,在保持性能的同时提升了训练效率并降低了计算需求。该方法产出的数据集在效能上常可媲美甚至超越未精炼的原始数据,能加速模型收敛并减少资源消耗,尤其在RLHF阶段表现显著。典型案例如ShareGPT[469]和HC3(人类-ChatGPT对比语料库)[467],它们通过将真实世界交互与对比性见解提炼为可操作的训练信号,成为广泛采用的LLM微调资源。
• ShareGPT。ShareGPT[469]作为动态数据收集平台,通过其API汇集了约90,000条来自用户与ChatGPT或GPT-4真实交互的对话记录。该数据集包含真实的人类指令、查询及对应的AI回应,将自然对话模式蒸馏为高浓度资源,使RLHF能够以高相关性与质量优化LLM的对话流畅度及语境响应能力。
• HC3。HC3数据集[467]专为对比ChatGPT生成的AI回复与人工撰写的答案而构建,涵盖开放性话题、金融、医学、法律及心理学等领域,共包含161,000组问答对。此蒸馏语料库支持对回答特征与质量的比较分析,帮助研究者在RLHF过程中提升LLM输出的真实性与领域准确性,同时揭示人类与AI生成内容间的差异特性。
8.3 合成数据集
合成数据在大型语言模型的后训练监督微调阶段构成了一项变革性资产,其通过人工智能模型生成,为人工标注数据集提供了成本效益高、可扩展且保护隐私的替代方案。通过自动化创建指令-响应对话,合成数据能够构建大规模训练语料,从而增强模型的适应能力。其中Self-Instruct-52K[86]、Vicuna[465]和Baize[478]作为被广泛采用的核心范例,显著提升了大型语言模型的指令遵循与对话生成能力。
基于自指令方法的数据集。
采用自指令方法的合成数据集以少量人工编写的种子示例为起点,利用大型语言模型生成大规模的指令遵循数据,从而增强模型对多样化指令的响应能力。Self-Instruct-52K、Alpaca以及Magpie系列便是典型代表,它们通过可扩展的自动化机制共同推动了指令微调技术的进步。
• Self-Instruct-52K。Self-Instruct-52K[86]为指令遵循模型建立了基础性基准,其通过多种提示模板引导大型语言模型,从手工编写的种子中生成52,000个示例,从而显著提升了模型精准、一致地解析与执行任务特定指令的能力。
• Alpaca。Alpaca[464]与Alpaca-GPT4[18]分别利用GPT-3和GPT-4,将初始的175个种子对扩展为52,000个高质量的指令-响应对,提升了指令遵循的熟练度;而InstInWild[477]将此方法适配于多语言场景,生成了涵盖英语和中文的数据集,以增强模型的跨语言适应能力。
• Magpie数据集。Magpie数据集[481]利用经过对齐的大型语言模型,基于预定义模板生成指令-响应对,形成了多个专用数据集家族:如强调思维链推理的Magpie Reasoning V2、针对流行模型定制的Magpie Llama-3与Qwen-2系列、适配Gemma架构的Magpie Gemma-2,以及融合了偏好优化信号的变体如Magpie-Air-DPO。这些数据集共同增强了对话与推理任务中的监督微调与指令微调效果。
除此之外,诸如Unnatural Instructions[97](24万示例)、Evol-Instruct[470](通过迭代复杂度增强生成的7万至14.3万条精炼条目)和Belle[471](基于ChatGPT生成的50万至110万条中文对话)等数据集也极大拓展了指令生成的规模。然而,在质量保证、复杂度校准与偏见缓解方面仍存在持续挑战,需要不断优化以确保其在复杂应用中的可靠性。
基于自对话方法的数据集。自对话数据集采用模型内部或与同类模型模拟多轮对话的技术,以此增强对话生成能力并弥补现有语料库的不足。Baize、UltraChat 和 OpenHermes 通过自动化交互策略体现了该方法。
• Baize。Baize [478] 利用 ChatGPT 的自对话技术生成了 65.3 万轮多轮对话,整合了来自 Quora、Stack Overflow 和 Alpaca 的种子数据以提升指令遵循质量,从而优化了 LLM 在 SFT 中的对话连贯性与任务遵从性。
• UltraChat。UltraChat [476] 使用多个 ChatGPT API 生成了超过 1200 万条涵盖多元主题的高质量对话记录,克服了多轮数据集中普遍存在的质量低下与标注不准确等问题,为对话增强提供了强大的 SFT 资源。
51 大语言模型后训练综述
• OpenHermes。由 Teknium 开发的 OpenHermes 包含 OpenHermes-1 [474](24.3 万条)及其扩展版本 OpenHermes-2.5 [475](100 万条),提供了数据量更大、多样性更高的高质量 SFT 数据集,涵盖广泛的主题与任务类型,以增强对话及指令遵循能力。
这些自对话数据集使模型能够通过自我交互构建多轮对话,例如 Baize 利用 ChatGPT 配合多样化种子数据,以及 UltraChat 通过大规模 API 驱动生成的对话,显著提升了对话质量并填补了训练数据可用性的关键空白。
基于真实用户交互的数据集。源自真实用户交互的数据集利用与 LLM 的真实对话交流,捕捉多样且真实的输入,以提升模型处理现实场景的能力。Vicuna、WildChat 和 GenQA 是该方法的典型代表。
• Vicuna。Vicuna [465] 基于来自 ShareGPT 公共 API 的大约 7 万条用户共享对话进行微调,处理过程包括将 HTML 转换为 Markdown、过滤低质量样本,以及分割长对话以适应模型上下文长度,从而确保了用于真实交互建模的高质量 SFT 数据。
• WildChat。WildChat [479] 包含 100 万条跨多种语言和提示类型的真实用户-ChatGPT 交互记录,其特色是包含模棱两可的请求、语码转换等独特对话,既可作为 SFT 资源,也可作为分析用户行为的工具。
• GenQA。GenQA [480] 提供了一个庞大的 SFT 数据集,包含超过 1000 万条经过清洗和过滤的指令样本,这些样本完全由 LLM 生成,无需人工输入或复杂流程,通过快速生成合成数据以弥补覆盖范围缺口,从而对现有语料库形成补充。
与人工标注数据相比,合成数据在成本、可扩展性和隐私方面的优势,可能被其深度与真实性的潜在不足所抵消,并存在传播偏见和过度简化的风险。对 AI 生成内容的依赖可能延续模型固有的错误,这凸显了整合合成数据与人类生成数据的必要性,以增强 LLM 在不同情境下的鲁棒性和适用性。
9 应用
尽管预训练赋予了大型语言模型(LLM)强大的基础能力,但在部署于专业领域时,它们仍频繁面临一些持续存在的局限,包括有限的上下文长度、幻觉生成倾向、次优的推理能力以及固有的偏见。在现实应用中,精确性、可靠性与伦理一致性至关重要,这些缺陷因此具有关键性影响。此类挑战引发出若干根本性问题:(1) 如何系统性地提升LLM性能以满足特定领域的需求?(2) 何种策略能有效缓解应用场景中固有的实际障碍?后训练作为一种关键解决方案应运而生,它通过精炼模型对领域特定术语和推理模式的认识,同时保留其广谱能力,从而增强了LLM的适应性。本章阐述了经过后训练的LLM在专业、技术和交互领域的变革性应用,阐明了定制化的后训练方法如何应对这些挑战,并在多样化的应用场景中提升模型的实用性。
9.1 专业领域
法律助手。法律领域是运用后训练技术为大型语言模型(LLM)注入专业知识的绝佳场景,使其能够驾驭复杂的法律知识体系,并应对法学中固有的多层面挑战。大量研究[485, 486, 487]已探讨了LLM在该领域的应用,涵盖法律问答[488, 489]、判决预测[490, 491]、文档摘要[492, 493]以及检索增强和司法推理等更广泛的任务[494, 495, 496]。经过后训练的法律助手,例如LawGPT[497]和Lawyer-LLaMA[498],展现出卓越的能力。它们不仅能就各类法律事务提供可靠指导,更在专业资格考试中取得成功,这证明了其先进的解释与分析能力。诸如LexiLaw[499]和SAUL[500]等模型提供的多语言支持(包括英语和中文)进一步扩展了其应用范围,提升了可及性。这些进步的核心在于对精心构建的法律语料库进行后训练,例如ChatLaw[501]将大量法律文本整合为对话数据集,使模型能够精炼其推理和术语识别能力。
医疗健康。后训练显著提升了大型语言模型(LLM)在各类医疗健康应用中的表现,其通过利用领域特定数据,精准应对临床与学术需求。在临床场景中,LLM辅助完成药物发现[502]、药物协同效应预测[503]与催化剂设计[504]、诊断支持、病历生成和患者互动等任务;而在学术界,得益于针对性后训练带来的性能提升,LLM在医疗报告合成[505]和问答[506]方面表现出色。例如,基于50万条医疗咨询记录精炼的ChatMed[507],其诊断和咨询准确性得到增强;而利用涵盖中文医学及通用领域的400万条指令进行微调的PULSE[508],则展现了卓越的多任务处理能力。这些模型通过后训练适配嵌入了精细的医学知识,从而超越了通用模型,凸显了定制化数据集在实现实际效用方面的不可或缺性。此类进步不仅提升了任务特定成果,也为将LLM整合到医疗工作流程铺平了道路——在这些流程中,精确性和语境相关性不容妥协,从而突显了后训练对现实世界医疗应用所产生的变革性影响。
金融经济。在金融和经济领域,大型语言模型(LLM)在情感分析[509]、信息抽取[510]和问答[511]等任务中展现出巨大潜力,而后训练通过领域特定精炼进一步放大了其效能。虽然通用LLM提供了坚实基础,但诸如FinGPT[512]和DISC-FinLLM[513]等专门模型在金融语料库上进行后训练后,表现出显著改进,在需要细致理解市场动态和术语的任务中表现优异。同样地,XuanYuan[514]利用大量金融数据集和先进的后训练技术来提升经济建模与预测的准确性,其表现优于未经调优的基准模型。这些进展说明了后训练在使LLM适应金融应用复杂需求方面的关键作用。在这些应用中,精确解读定量数据和定性见解至关重要,从而确保模型能输出符合行业标准与期望的、可靠的、具备领域知识的成果。
移动智能体。大型多模态模型(LMM)的发展催生了一个新兴的、专注于基于LMM的图形用户界面(GUI)智能体[515]的研究领域。该领域旨在开发能够在多样化GUI环境中执行任务的人工智能助手,涵盖网页界面[516, 517, 518, 519, 520]、个人计算平台[521, 522, 523, 524, 525]以及移动设备[526, 527, 528, 529, 530]。在移动环境中,一个研究方向通过工具集成[526]和额外的探索阶段[527, 528]来增强单个智能体的感知与推理能力。最近的进展通过采用多智能体系统进行决策与反思[531, 529],展现出巨大潜力,从而提升了任务效能。值得注意的是,MobileAgent-E[532]引入了智能体间的分层结构,促进了稳健的长时程规划,并提升了低级动作的精确性。这些发展突显了多模态后训练策略在培育适用于复杂移动环境的自适应、高效智能体方面的变革性作用。
9.2 技术与逻辑推理
数学推理。大语言模型在数学推理方面展现出显著潜力,涵盖代数运算、微积分和统计分析,而后训练对于弥合计算能力与类人熟练度之间的差距至关重要。GPT-4 [9] 在标准化数学评估中取得高分,这一成就归功于其多样化的预训练语料库,而后训练则进一步提升了此项能力。以DeepSeekMath [64] 为例,它利用专门的数学数据集以及诸如监督微调和群体相对策略优化 [64] 等技术,通过结构化的思维链来处理复杂问题,从而提升了推理精度。OpenAI的o1 [41] 通过强化学习推进了这一前沿,迭代优化推理策略,在多步推导和证明中实现卓越性能。这种通过后训练进行的持续优化不仅提升了准确性,也使大语言模型的输出与严谨的数学逻辑保持一致,使其成为教育和研究领域中高级推理场景下的宝贵工具。
代码生成。后训练彻底改变了代码生成领域,使大语言模型在自动编码、调试和文档编写方面表现卓越,从而改变了软件开发工作流程。基于海量多样化代码库训练的Codex [533] 支撑了GitHub Copilot *,以出色的准确性提供实时编码辅助。像Code Llama [384] 这样的专用模型进一步精炼了此能力,利用针对编程的数据集进行后训练,以协助开发者跨语言和框架工作。OpenAI的o1 [41] 将其数学推理能力扩展至代码生成,产出可与人类输出媲美的高质量、上下文感知的代码片段。当前研究侧重于增强个性化、深化上下文理解以及嵌入伦理防护措施,以降低代码滥用等风险,确保大语言模型在技术领域最大化生产力的同时,遵循负责任的开发原则。
9.3 理解与交互
推荐系统。大语言模型已成为推荐系统的变革性推动者,其通过分析用户交互、产品描述和评论,以前所未有的细粒度提供个性化建议[534, 535, 536]。训练后增强技术提升了它们整合情感分析的能力,使其能够细致入微地理解内容与情感基调,这在GPT-4[9]等模型以及LLaRA[537]、AgentRec[538]等专门系统中得到印证。亚马逊、淘宝等电商巨头利用这些能力处理评论情感、搜索查询和购买历史,以高保真度优化客户偏好模型并预测兴趣[535]。超越物品排序,经训练后增强的大语言模型还参与对话式推荐、规划与内容生成,通过提供适应动态变化偏好的、情境敏感的交互来提升用户体验,这证明了训练后增强在连接数据分析与实际效用方面的作用。
语音对话。经训练后增强的大语言模型重新定义了语音处理,将识别、合成与翻译推进到前所未有的自然与准确水平[539]。这些模型处理文本转语音[540]、文本转音频生成[541]及语音识别[542]等任务,为亚马逊Alexa、苹果Siri、阿里巴巴天猫精灵等无处不在的工具提供支持。Whisper[543]以其高保真转录体现了这一进展,而GPT-4o[78]则引入了实时语音交互,无缝融合多模态输入。未来方向包括多语言翻译和个性化语音合成,训练后增强技术将精炼大语言模型以打破语言障碍,并根据个体用户特征定制响应,从而提升全球语境下人机交互的可访问性与参与度。
视频理解。大语言模型向视频理解领域的延伸标志着一个重要的前沿,训练后增强技术使得Video-LLaMA[341]等模型能够执行字幕生成、内容摘要与分析,从而简化多媒体内容创作与理解。Sora[544]通过从文本提示生成复杂视频,进一步革新了该领域,它降低了技术门槛并促进了创新性叙事,实现了内容创作的民主化。这些进步利用训练后增强技术使大语言模型适应视觉-时序数据,提升了其在从教育到娱乐等应用中的解释深度与实用性。然而,它们也带来了计算可扩展性、隐私保护和伦理治理方面的挑战,特别是在生成内容滥用方面。随着训练后增强方法的演进,解决这些问题对于确保视频相关应用可持续、负责任的部署至关重要,需要在创新与社会考量之间取得平衡。
10 开放问题与未来方向
本节旨在批判性评估大型语言模型后训练方法中尚未解决的挑战与未来发展方向,并将分析置于OpenAI的o1[41]和深度求索的DeepSeek-R1[28]发布所带来的变革性进展背景下。这些模型通过大规模强化学习重新定义了推理基准,但它们的出现也凸显出解决后训练技术中持续存在的局限性的紧迫性。后续小节将阐述七个关键性开放问题,每个问题均因其对领域发展的关键重要性及亟需解决的必要性而被着重强调,同时提出推动未来研究的可行策略,以确保大型语言模型在不同应用场景中实现负责任的演进。
超越大规模强化学习的推理能力增强
o1与DeepSeek-R1的推出标志着大语言模型推理能力的范式转变,它们利用RLHF和群体相对策略优化(GRPO)等大规模强化学习框架,在数学证明与逻辑推导等多步骤问题上实现了前所未有的准确性。然而,对二元奖励信号和大量人类反馈的依赖暴露了其关键局限:难以有效泛化至复杂开放任务(如科学假设生成或动态环境中的战略决策)。这一空白亟待填补——随着现实场景中对类人推理能力的需求增长,其重要性在于释放大语言模型作为自主智能体的潜力,突破现有基准。当前强化学习方法受限于奖励稀疏性与任务复杂性适应不足,亟需创新框架。可行的解决方案包括开发多目标强化学习系统,整合自监督一致性检验(如验证推理步骤间的逻辑连贯性)和领域先验知识(如数学公理或科学原理),以在无需海量人工标注的情况下引导推理[545,546]。此类进步可减少对高成本反馈循环的依赖,提升可扩展性,并使大语言模型能够处理未知推理领域——DeepSeek-R1的冷启动强化学习创新已使这一前景初现曙光。
下一代大语言模型的后训练可扩展性
随着大语言模型规模与复杂性攀升(以下一代模型的巨量参数架构为典型),后训练的可扩展性已成为严峻而紧迫的挑战。基于强化学习的方法(如DeepSeek-R1需庞大计算基础设施的冷启动方法)具有资源密集型特性,限制了其仅能被资金充裕的机构所及,并引发显著的可持续性担忧,尤其在多模态应用(如视频分析)和实时系统(如对话代理)领域。此问题至关重要,因其可能加剧资源充足与资源受限研究群体间的差距,阻碍大语言模型发展的公平进程。虽然参数高效微调(PEFT)[92]缓解了部分开销,但其在大规模数据集上性能常出现退化,突显了对可扩展替代方案的迫切需求。可行的未来方向[547,548,549]包括:设计轻量级强化学习算法(如适配GRPO以降低内存占用)、分布式后训练框架(将计算负载分散至去中心化网络),以及先进蒸馏技术(在最小化资源需求的同时保持推理与适应能力)。这些方案若能实现,将推动后训练民主化,顺应领域对可持续与包容性创新的迫切需求。
强化学习驱动模型中的伦理对齐与偏见缓解
通过强化学习进行的后训练(如o1的谨慎对齐策略所示)可能强化训练数据(如HH-RLHF[104]或合成语料库)中嵌入的偏见,从而放大伦理风险——鉴于大语言模型在医疗诊断、司法决策等敏感领域的部署,此挑战极为紧迫。伦理对齐的动态可变性(即一种文化背景下的公平在另一背景下可能构成偏见)对实现普适可信的大语言模型构成重大障碍,使得该问题对保障公平安全的人工智能系统至关重要。现有方法可能过度审查(损害模型效用,如抑制创造性输出)或修正不足(延续有害偏见,如种族或性别差异)。解决此问题需开发公平感知的强化学习目标,整合多利益相关者偏好模型(如聚合多样化人类判断)与对抗去偏技术,以在训练中消除数据集偏见。这些方法的可行性[550]得益于可解释性工具与多目标优化的最新进展,使得在伦理鲁棒性与实用功能间取得平衡成为可能——o1的实际部署挑战正凸显了这一必要性。
实现整体推理的无缝多模态融合
通向多模态大语言模型的发展轨迹(由o1的推理增强与GPT-4o的融合能力[78]预示)凸显了对后训练方法的迫切需求:这些方法需无缝整合文本、图像、音频等多类数据以实现整体推理——此能力对实时视频分析、增强现实及跨模态科学探索等应用至关重要。当前方法因数据异质性与全面多模态训练语料稀缺,难以实现稳健的跨模态对齐,限制了大语言模型对多样化输入进行连贯推理的能力。此挑战的重要性在于其释放变革性应用的潜力,但若缺乏可扩展框架则难以解决。DeepSeek-R1的冷启动强化学习提供了一个有希望的起点,表明统一模态编码器(如能将异构数据编码至共享隐空间)与动态强化学习策略(自适应权衡模态贡献)或可弥合这一鸿沟。未来研究应优先创建多模态基准与合成数据集(基于Magpie[481]等已有成果),以推动进展——鉴于多模态预训练与强化学习优化的最新进展,此目标切实可行。
情境自适应的可信度框架
后训练大语言模型的可信度日益被视为动态、情境依赖的属性而非静态品质(如o1在教育等敏感领域输出谨慎,在创造性任务中则更自由)。这种可变性——其中安全性要求(如避免教育场景中的错误信息)可能与效用需求(如激发写作创造力)冲突——构成了紧迫挑战,因其对用户信任及大语言模型在多样现实场景中的适用性至关重要。当前后训练方法常过度优先安全,导致效用折损;或未能适应情境特定需求,削弱可靠性。解决此问题需情境敏感的强化学习模型,能动态调整安全-效用权衡,利用实时用户反馈与可解释安全指标(如生成内容的透明度评分)确保适应性。此方法的可行性[551]得益于自适应学习系统与实时监控技术的进步,为平衡可信度与功能性提供了路径——随着o1等模型向高风险应用扩展,此需求尤为迫切。
后训练创新的可及性与民主化
先进后训练方法(以DeepSeek-R1的强化学习驱动方法为典型)的计算强度将其应用局限于资源充裕的实体,形成了紧迫的可及性壁垒,压制了小型研究社区与产业部门的创新(即对促进人工智能公平发展至关重要的问题)。这种排他性不仅限制了贡献的多样性,也阻碍了领域协同应对全球挑战的能力。民主化这些创新需要开发高效、开源的工具与框架,在不牺牲质量的前提下降低入门门槛——此目标可通过强化学习的可扩展PEFT适配[92]、共享后训练模型的协作平台(如Hugging Face枢纽)及类似Magpie[481]的流线型合成数据生成管道来实现。未来努力应聚焦于优化这些方案以促进广泛采用,确保后训练的变革潜力(以o1与DeepSeek-R1为例)超越精英机构,惠及更广泛的人工智能生态。
创造性智能与系统2思维
将创造性智能融入系统2推理,代表着大语言模型演进的新兴前沿[552]。尽管如OpenAI的o1与DeepSeek的R1等推理模型擅长模仿系统2思维进行审慎的逐步逻辑分析,但其创造性智能(涉及生成新思想、融合不同概念及灵活适应非结构化问题)仍有待深入探索。这一空白至关重要,因为创造性智能支撑着艺术创作、科学发现与战略创新等领域的类人问题解决,仅靠僵化的逻辑框架远远不够。此挑战的紧迫性在于其潜力——将大语言模型从分析工具提升为自主创造主体,是实现通用人工智能(AGI)的变革性跨越。下文将结合本综述的见解,概述这一开放问题并提出未来方向。
11 总结
本文首次对后训练语言模型(PoLMs)进行了全面综述,系统追溯了其自2018年ChatGPT对齐技术起源至2025年DeepSeek-R1推理里程碑的发展轨迹,并确认了其在推理精度、领域适应性及伦理完整性方面的变革性影响。我们评估了广泛的技术谱系(包括微调、对齐、推理、效率、集成与适应),综合了它们在从法律分析到多模态理解等专业、技术和交互领域的贡献。我们的分析强调,后训练语言模型已显著推进了大语言模型的能力,从最初的对齐创新演变为复杂的推理框架;然而,研究也揭示了持续存在的挑战,包括偏见存续、计算可扩展性以及情境化的伦理对齐需求。这些发现被整合在一个新颖的分类体系内,强调了一种整合性方法的必要性,即将推理进展与效率及伦理要求相协调。我们得出结论:持续的跨学科合作、严谨的方法论评估,以及开发自适应、可扩展的框架,对于实现大语言模型成为跨领域应用中可靠、负责任工具至关重要。作为该领域的开创性综述,本研究整合了近年来后训练语言模型的进展,奠定了坚实的学术基础,以启发未来研究培育能够巧妙融合精度、伦理稳健性与多功能性的大语言模型,从而满足科学与社会语境不断演进的需求。
引用文献
- [1] Alec Radford. Improving language understanding by generative pre-training. 2018.
- [2] Jacob Devlin. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [3] Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel P. Kuksa. Natural language processing (almost) from scratch. ArXiv, abs/1103.0398, 2011.
- [4] Swapan Ghosh. Developing artificial intelligence (ai) capabilities for data-driven business model innovation: Roles of organizational adaptability and leadership. Journal of Engineering and Technology Management, 75:101851, 2025.
- [5] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3):1–45, 2024.
- [6] Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
- [7] Tom B Brown. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- [8] Boyu Zhang, Hongyang Yang, and Xiao-Yang Liu. Instruct-fingpt: Financial sentiment analysis by instruction tuning of general-purpose large language models, 2023.
- [9] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [10] Ce Zhou, Qian Li, Chen Li, Jun Yu, Yixin Liu, Guangjing Wang, Kai Zhang, Cheng Ji, Qiben Yan, Lifang He, et al. A comprehensive survey on pretrained foundation models: A history from bert to chatgpt. arXiv preprint arXiv:2302.09419, 2023.
- [11] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. Advances in neural information processing systems, 13, 2000.
- [12] Tomas Mikolov. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- [13] Zhilin Yang. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237, 2019.
- [14] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [15] M Lewis. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
- [16] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences, 2020.
- [17] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- [18] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- [19] Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355, 2023.
- [20] Zhiyuan Zeng, Jiatong Yu, Tianyu Gao, Yu Meng, Tanya Goyal, and Danqi Chen. Evaluating large language models at evaluating instruction following. arXiv preprint arXiv:2310.07641, 2023.
- [21] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. A survey on in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- [22] Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learning to retrieve prompts for in-context learning. arXiv preprint arXiv:2112.08633, 2021.
- [23] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- [24] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690, 2024.
- [25] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
- [26] Google. Gemini-2.0-flash. 2025.
- [27] Claude 3. The claude 3 model family: Opus, sonnet, haiku.
- [28] DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. 2025.
- [29] Yefei He, Luping Liu, Jing Liu, Weijia Wu, Hong Zhou, and Bohan Zhuang. Ptqd: Accurate posttraining quantization for diffusion models. Advances in Neural Information Processing Systems, 36, 2024.
- [30] Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. arXiv preprint arXiv:2311.17043, 2023.
- [31] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- [32] Bo Adler, Niket Agarwal, Ashwath Aithal, Dong H Anh, Pallab Bhattacharya, Annika Brundyn, Jared Casper, Bryan Catanzaro, Sharon Clay, Jonathan Cohen, et al. Nemotron-4 340b technical report. arXiv preprint arXiv:2406.11704, 2024.
- [33] Stephen H Bach, Victor Sanh, Zheng-Xin Yong, Albert Webson, Colin Raffel, Nihal V Nayak, Abheesht Sharma, Taewoon Kim, M Saiful Bari, Thibault Fevry, et al. Promptsource: An integrated development environment and repository for natural language prompts. arXiv preprint arXiv:2202.01279, 2022.
- [34] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688, 2023.
- [35] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023.
- [36] Xu Han, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, Yuan Yao, Ao Zhang, Liang Zhang, et al. Pre-trained models: Past, present and future. AI Open, 2:225–250, 2021.
- [37] Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. Pre-trained models for natural language processing: A survey. Science China technological sciences, 63(10):18721897, 2020.
- [38] Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ramnath, Sougata Chaudhuri, Shubham Mehrotra, Xiang-Bo Mao, Sitaram Asur, et al. A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more. arXiv preprint arXiv:2407.16216, 2024.
- [39] Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine-tuning for large models: A comprehensive survey. ArXiv, abs/2403.14608, 2024.
- [40] Tong Xiao and Jingbo Zhu. Foundations of large language models. ArXiv, abs/2501.09223, 2025.
- [41] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
- [42] Colin Raffel, Noam M. Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-totext transformer. J. Mach. Learn. Res., 21:140:1–140:67, 2019.
- [43] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021.
- [44] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- [45] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. Training language models to follow instructions with human feedback. ArXiv, abs/2203.02155, 2022.
- [46] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. ArXiv, abs/1707.06347, 2017.
- [47] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Huai hsin Chi, F. Xia, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. ArXiv, abs/2201.11903, 2022.
- [48] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:94599474, 2020.
- [49] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model, 2024.
- [50] Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378, 2023.
- [51] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems, 35:23716–23736, 2022.
- [52] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pretraining with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023.
- [53] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. ArXiv, abs/2304.08485, 2023.
- [54] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1–39, 2022.
- [55] Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024.
- [56] Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-play preference optimization for language model alignment. arXiv preprint arXiv:2405.00675, 2024.
- [57] Maciej S ́ wiechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Ma’ndziuk. Monte carlo tree search: a review of recent modifications and applications. Artificial Intelligence Review, 56:24972562, 2021.
- [58] Zhihong Shao, Damai Dai, Daya Guo, Bo Liu (Benjamin Liu), Zihan Wang, and Huajian Xin. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. ArXiv, abs/2405.04434, 2024.
- [59] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. Advances in neural information processing systems, 28, 2015.
- [60] Michael Völske, Martin Potthast, Shahbaz Syed, and Benno Stein. Tl; dr: Mining reddit to learn automatic summarization. In Proceedings of the Workshop on New Frontiers in Summarization, pages 59–63, 2017.
- [61] Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning, 2019.
- [62] Dongyoung Go, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, and Marc Dymetman. Aligning language models with preferences through f-divergence minimization, 2023.
- [63] Natasha Jaques, Judy Hanwen Shen, Asma Ghandeharioun, Craig Ferguson, Agata Lapedriza, Noah Jones, Shixiang Shane Gu, and Rosalind Picard. Human-centric dialog training via offline reinforcement learning, 2020.
- [64] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024.
- [65] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023.
- [66] Hugo Touvron, Louis Martin, Kevin R. Stone, et al. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023.
- [67] DeepSeek-AI Xiao Bi, Deli Chen, Guanting Chen, et al. Deepseek llm: Scaling open-source language models with longtermism. ArXiv, abs/2401.02954, 2024.
- [68] DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, et al. Deepseek-v3 technical report. ArXiv, abs/2412.19437, 2024. [69] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, et al. Qwen technical report. ArXiv, abs/2309.16609, 2023.
- [70] An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, et al. Qwen2 technical report. ArXiv, abs/2407.10671, 2024.
- [71] Qwen An Yang, Baosong Yang, Beichen Zhang, et al. Qwen2.5 technical report. ArXiv, abs/2412.15115, 2024.
- [72] Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- [73] Mistral. Mistral-large2. 2024.
- [74] Anthropic. claude2. 2023.
- [75] Claude Ahtropic. Claude. [Online]. Available: https://www.anthropic.com/claude, 2024.
- [76] Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- [77] Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- [78] OpenAI. GPT-4o System Card, 2024.
- [79] OpenAI. Openai-o3. 2025.
- [80] Team Glm Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Ming yue Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, Shuxun Yang, Weng Lam Tam, Wenyi Zhao, Xiao Liu, Xiaoyu Xia, Xiaohan Zhang, Xiaotao Gu, Xin Lv, Xinghan Liu, Xinyi Liu, Xinyue Yang, Xixuan Song, Xunkai Zhang, Yi An, Yifan Xu, Yilin Niu, Yuantao Yang, Yueyan Li, Yushi Bai, Yuxiao Dong, Zehan Qi, Zhaoyu Wang, Zhenyi Yang, Zhengxiao Du, Zhen-Ping Hou, and Zihan Wang. Chatglm: A family of large language models from glm-130b to glm-4 all tools. ArXiv, abs/2406.12793, 2024.
- [81] Databricks. Databricks/dbrx. 2024.
- [82] Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652, 2024.
- [83] Jamba Team Barak Lenz, Alan Arazi, Amir Bergman, Avshalom Manevich, Barak Peleg, Ben Aviram, Chen Almagor, Clara Fridman, Dan Padnos, Daniel Gissin, Daniel Jannai, Dor Muhlgay, Dor Zimberg, Edden M. Gerber, Elad Dolev, Eran Krakovsky, Erez Safahi, Erez Schwartz, Gal Cohen, Gal Shachaf, Haim Rozenblum, Hofit Bata, Ido Blass, Inbal Magar, Itay Dalmedigos, Jhonathan Osin, Julie Fadlon, Maria Rozman, Matan Danos, Michael Gokhman, Mor Zusman, Naama Gidron, Nir Ratner, Noam Gat, Noam Rozen, Oded Fried, Ohad Leshno, Omer Antverg, Omri Abend, Opher Lieber, Or Dagan, Orit Cohavi, Raz Alon, Ro’i Belson, Roi Cohen, Rom Gilad, Roman Glozman, Shahar Lev, Shaked Haim Meirom, Tal Delbari, Tal Ness, Tomer Asida, Tom Ben Gal, Tom Braude, Uriya Pumerantz, Yehoshua Cohen, Yonatan Belinkov, Yuval Globerson, Yuval Peleg Levy, and Yoav Shoham. Jamba-1.5: Hybrid transformer-mamba models at scale. ArXiv, abs/2408.12570, 2024.
- [84] Amazon Artificial General Intelligence. The amazon nova family of models: Technical report and model card. Amazon Technical Reports, 2024.
- [85] Kimi Team, Angang Du, Bofei Gao, Bowei Xing, et al. Kimi k1.5: Scaling reinforcement learning with llms. 2025. [86] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. In Annual Meeting of the Association for Computational Linguistics, 2022.
- [87] Kavita A. Ganesan. Rouge 2.0: Updated and improved measures for evaluation of summarization tasks. ArXiv, abs/1803.01937, 2015.
- [88] Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, and Jing Xiao. From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning. ArXiv, abs/2308.12032, 2023.
- [89] Qianlong Du, Chengqing Zong, and Jiajun Zhang. Mods: Model-oriented data selection for instruction tuning. ArXiv, abs/2311.15653, 2023.
- [90] Yihan Cao, Yanbin Kang, Chi Wang, and Lichao Sun. Instruction mining: Instruction data selection for tuning large language models. 2023.
- [91] Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Dekang Lin, Yuji Matsumoto, and Rada Mihalcea, editors, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics.
- [92] J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. ArXiv, abs/2106.09685, 2021.
- [93] Kai Lv, Yuqing Yang, Tengxiao Liu, Qi jie Gao, Qipeng Guo, and Xipeng Qiu. Full parameter finetuning for large language models with limited resources. ArXiv, abs/2306.09782, 2023.
- [94] Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Frederick Diamos, Erich Elsen, David García, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. ArXiv, abs/1710.03740, 2017.
- [95] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. ArXiv, abs/1604.06174, 2016.
- [96] Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, and Guoyin Wang. Instruction tuning for large language models: A survey. ArXiv, abs/2308.10792, 2023.
- [97] Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language models with (almost) no human labor. ArXiv, abs/2212.09689, 2022.
- [98] Zhen-Ru Zhang, Chuanqi Tan, Haiyang Xu, Chengyu Wang, Jun Huang, and Songfang Huang. Towards adaptive prefix tuning for parameter-efficient language model fine-tuning. arXiv preprint arXiv:2305.15212, 2023.
- [99] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602, 2021.
- [100] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. AI Open, 5:208–215, 2024.
- [101] Zhengbao Jiang, Frank F Xu, Jun Araki, and Graham Neubig. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438, 2020.
- [102] Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980, 2020.
- [103] Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. Reft: Reasoning with reinforced fine-tuning. ArXiv, abs/2401.08967, 2024.
- [104] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- [105] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022.
- [106] Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302, 2023.
- [107] Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. Preference ranking optimization for human alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18990–18998, 2024.
- [108] Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, Victor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. 2023.
- [109] Jing Xu, Andrew Lee, Sainbayar Sukhbaatar, and Jason Weston. Some things are more cringe than others: Iterative preference optimization with the pairwise cringe loss, 2024.
- [110] Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. arXiv preprint arXiv:2401.08417, 2024.
- [111] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. arXiv preprint arXiv:2401.10020, 2024.
- [112] Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms. arXiv preprint arXiv:2402.14740, 2024.
- [113] Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mohammad Saleh, Simon Baumgartner, Jialu Liu, et al. Lipo: Listwise preference optimization through learningto-rank. arXiv preprint arXiv:2402.01878, 2024.
- [114] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024.
- [115] Shitong Duan, Xiaoyuan Yi, Peng Zhang, Tun Lu, Xing Xie, and Ning Gu. Negating negatives: Alignment without human positive samples via distributional dispreference optimization. arXiv preprint arXiv:2403.03419, 2024.
- [116] Ryan Park, Rafael Rafailov, Stefano Ermon, and Chelsea Finn. Disentangling length from quality in direct preference optimization. arXiv preprint arXiv:2403.19159, 2024.
- [117] Corby Rosset, Ching-An Cheng, Arindam Mitra, Michael Santacroce, Ahmed Awadallah, and Tengyang Xie. Direct nash optimization: Teaching language models to self-improve with general preferences, 2024.
- [118] Rafael Rafailov, Joey Hejna, Ryan Park, and Chelsea Finn. From r to q*: Your language model is secretly a q-function. arXiv preprint arXiv:2404.12358, 2024.
- [119] Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Token-level direct preference optimization. arXiv preprint arXiv:2404.11999, 2024.
- [120] Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. arXiv preprint arXiv:2404.05868, 2024.
- [121] Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a referencefree reward. arXiv preprint arXiv:2405.14734, 2024.
- [122] Zhichao Wang, Bin Bi, Can Huang, Shiva Kumar Pentyala, Zixu James Zhu, Sitaram Asur, and Na Claire Cheng. Una: Unifying alignments of rlhf/ppo, dpo and kto by a generalized implicit reward function, 2024.
- [123] Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Tianyi Qiu, and Yaodong Yang. Aligner: Efficient alignment by learning to correct, 2024.
- [124] Timo Kaufmann, Paul Weng, Viktor Bengs, and Eyke Hüllermeier. A survey of reinforcement learning from human feedback. arXiv preprint arXiv:2312.14925, 2023.
- [125] Baicen Xiao, Qifan Lu, Bhaskar Ramasubramanian, Andrew Clark, Linda Bushnell, and Radha Poovendran. Fresh: Interactive reward shaping in high-dimensional state spaces using human feedback. arXiv preprint arXiv:2001.06781, 2020.
- [126] Riad Akrour, Marc Schoenauer, and Michele Sebag. Preference-based policy learning. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2011, Athens, Greece, September 5-9, 2011. Proceedings, Part I 11, pages 12–27. Springer, 2011.
- [127] Serkan Cabi, Sergio Gómez Colmenarejo, Alexander Novikov, Ksenia Konyushkova, Scott Reed, Rae Jeong, Konrad Zolna, Yusuf Aytar, David Budden, Mel Vecerik, et al. Scaling data-driven robotics with reward sketching and batch reinforcement learning. arXiv preprint arXiv:1909.12200, 2019.
- [128] Jerry Zhi-Yang He and Anca D Dragan. Assisted robust reward design. arXiv preprint arXiv:2111.09884, 2021. [129] Yuchen Cui, Qiping Zhang, Brad Knox, Alessandro Allievi, Peter Stone, and Scott Niekum. The empathic framework for task learning from implicit human feedback. In Conference on Robot Learning, pages 604–626. PMLR, 2021.
- [130] Jianlan Luo, Perry Dong, Yuexiang Zhai, Yi Ma, and Sergey Levine. Rlif: Interactive imitation learning as reinforcement learning. arXiv preprint arXiv:2311.12996, 2023.
- [131] Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Eureka: Human-level reward design via coding large language models. arXiv preprint arXiv:2310.12931, 2023.
- [132] Gaurav R Ghosal, Matthew Zurek, Daniel S Brown, and Anca D Dragan. The effect of modeling human rationality level on learning rewards from multiple feedback types. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5983–5992, 2023.
- [133] Lin Guan, Mudit Verma, Suna Sihang Guo, Ruohan Zhang, and Subbarao Kambhampati. Widening the pipeline in human-guided reinforcement learning with explanation and context-aware data augmentation. Advances in Neural Information Processing Systems, 34:21885–21897, 2021.
- [134] Andreea Bobu, Marius Wiggert, Claire Tomlin, and Anca D Dragan. Inducing structure in reward learning by learning features. The International Journal of Robotics Research, 41(5):497–518, 2022.
- [135] Andreea Bobu, Yi Liu, Rohin Shah, Daniel S Brown, and Anca D Dragan. Sirl: similarity-based implicit representation learning. In Proceedings of the 2023 ACM/IEEE International Conference on Human-Robot Interaction, pages 565–574, 2023.
- [136] Justin Fu, Katie Luo, and Sergey Levine. Learning robust rewards with adversarial inverse reinforcement learning. arXiv preprint arXiv:1710.11248, 2017.
- [137] Daniel Brown, Wonjoon Goo, Prabhat Nagarajan, and Scott Niekum. Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations. In International conference on machine learning, pages 783–792. PMLR, 2019.
- [138] Hoang Le, Cameron Voloshin, and Yisong Yue. Batch policy learning under constraints. In International Conference on Machine Learning, pages 3703–3712. PMLR, 2019.
- [139] Alexander Irpan, Kanishka Rao, Konstantinos Bousmalis, Chris Harris, Julian Ibarz, and Sergey Levine. Off-policy evaluation via off-policy classification. Advances in Neural Information Processing Systems, 32, 2019.
- [140] Adam Gleave, Michael Dennis, Shane Legg, Stuart Russell, and Jan Leike. Quantifying differences in reward functions. arXiv preprint arXiv:2006.13900, 2020.
- [141] Blake Wulfe, Ashwin Balakrishna, Logan Ellis, Jean Mercat, Rowan McAllister, and Adrien Gaidon. Dynamics-aware comparison of learned reward functions. arXiv preprint arXiv:2201.10081, 2022.
- [142] Erik Jenner, Joar Max Viktor Skalse, and Adam Gleave. A general framework for reward function distances. In NeurIPS ML Safety Workshop, 2022.
- [143] Joar Skalse, Lucy Farnik, Sumeet Ramesh Motwani, Erik Jenner, Adam Gleave, and Alessandro Abate. Starc: A general framework for quantifying differences between reward functions. arXiv preprint arXiv:2309.15257, 2023.
- [144] Erik Jenner and Adam Gleave. Preprocessing reward functions for interpretability. arXiv preprint arXiv:2203.13553, 2022.
- [145] Lingfeng Shen, Sihao Chen, Linfeng Song, Lifeng Jin, Baolin Peng, Haitao Mi, Daniel Khashabi, and Dong Yu. The trickle-down impact of reward (in-) consistency on rlhf. arXiv preprint arXiv:2309.16155, 2023.
- [146] Ellen Novoseller, Yibing Wei, Yanan Sui, Yisong Yue, and Joel Burdick. Dueling posterior sampling for preference-based reinforcement learning. In Conference on Uncertainty in Artificial Intelligence, pages 1029–1038. PMLR, 2020.
- [147] Yichong Xu, Ruosong Wang, Lin Yang, Aarti Singh, and Artur Dubrawski. Preference-based reinforcement learning with finite-time guarantees. Advances in Neural Information Processing Systems, 33:18784–18794, 2020.
- [148] Aadirupa Saha, Aldo Pacchiano, and Jonathan Lee. Dueling rl: Reinforcement learning with trajectory preferences. In International Conference on Artificial Intelligence and Statistics, pages 6263–6289. PMLR, 2023.
- [149] Xiaoyu Chen, Han Zhong, Zhuoran Yang, Zhaoran Wang, and Liwei Wang. Human-in-the-loop: Provably efficient preference-based reinforcement learning with general function approximation. In International Conference on Machine Learning, pages 3773–3793. PMLR, 2022.
- [150] Souradip Chakraborty, Amrit Singh Bedi, Alec Koppel, Dinesh Manocha, Huazheng Wang, Mengdi Wang, and Furong Huang. Parl: A unified framework for policy alignment in reinforcement learning. arXiv preprint arXiv:2308.02585, page 3, 2023.
- [151] Banghua Zhu, Michael Jordan, and Jiantao Jiao. Principled reinforcement learning with human feedback from pairwise or k-wise comparisons. In International Conference on Machine Learning, pages 43037–43067. PMLR, 2023.
- [152] Wenhao Zhan, Masatoshi Uehara, Nathan Kallus, Jason D Lee, and Wen Sun. Provable offline preference-based reinforcement learning. arXiv preprint arXiv:2305.14816, 2023.
- [153] Zihao Li, Zhuoran Yang, and Mengdi Wang. Reinforcement learning with human feedback: Learning dynamic choices via pessimism. arXiv preprint arXiv:2305.18438, 2023.
- [154] Banghua Zhu, Michael I Jordan, and Jiantao Jiao. Iterative data smoothing: Mitigating reward overfitting and overoptimization in rlhf. arXiv preprint arXiv:2401.16335, 2024.
- [155] Dingwen Kong and Lin Yang. Provably feedback-efficient reinforcement learning via active reward learning. Advances in Neural Information Processing Systems, 35:11063–11078, 2022.
- [156] Chi Jin, Zhuoran Yang, Zhaoran Wang, and Michael I Jordan. Provably efficient reinforcement learning with linear function approximation. In Conference on learning theory, pages 2137–2143. PMLR, 2020.
- [157] Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, et al. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback. In Forty-first International Conference on Machine Learning.
- [158] Ralph Allan Bradley and Milton E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- [159] Heejong Bong and Alessandro Rinaldo. Generalized results for the existence and consistency of the mle in the bradley-terry-luce model, 2022.
- [160] Dahyun Kim, Yungi Kim, Wonho Song, Hyeonwoo Kim, Yunsu Kim, Sanghoon Kim, and Chanjun Park. sdpo: Don’t use your data all at once, 2024.
- [161] William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802, 2022.
- [162] Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. Advances in Neural Information Processing Systems, 35:21314–21328, 2022.
- [163] Emily First, Markus N Rabe, Talia Ringer, and Yuriy Brun. Baldur: Whole-proof generation and repair with large language models. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1229–1241, 2023.
- [164] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with selffeedback. Advances in Neural Information Processing Systems, 36, 2024.
- [165] Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Y Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, et al. Rarr: Researching and revising what language models say, using language models. arXiv preprint arXiv:2210.08726, 2022.
- [166] Shuyang Jiang, Yuhao Wang, and Yu Wang. Selfevolve: A code evolution framework via large language models. arXiv preprint arXiv:2306.02907, 2023.
- [167] Afra Feyza Akyürek, Ekin Akyürek, Aman Madaan, Ashwin Kalyan, Peter Clark, Derry Wijaya, and Niket Tandon. Rl4f: Generating natural language feedback with reinforcement learning for repairing model outputs. arXiv preprint arXiv:2305.08844, 2023.
- [168] Kechi Zhang, Zhuo Li, Jia Li, Ge Li, and Zhi Jin. Self-edit: Fault-aware code editor for code generation. arXiv preprint arXiv:2305.04087, 2023.
- [169] Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models. arXiv preprint arXiv:2309.11495, 2023.
- [170] Shrisha Bharadwaj, Yufeng Zheng, Otmar Hilliges, Michael J. Black, and Victoria FernandezAbrevaya. Flare: Fast learning of animatable and relightable mesh avatars. ACM Transactions on Graphics (TOG), 42:1 – 15, 2023.
- [171] Liangming Pan, Alon Albalak, Xinyi Wang, and William Yang Wang. Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. arXiv preprint arXiv:2305.12295, 2023.
- [172] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024.
- [173] Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128, 2023.
- [174] Seonghyeon Ye, Yongrae Jo, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, and Minjoon Seo. Selfee: Iterative self-revising llm empowered by self-feedback generation. Blog post, 2023.
- [175] Qiang Yang, Gong-Wei Song, Wei neng Chen, Ya-Hui Jia, Xudong Gao, Zhen Lu, Sang-Woon Jeon, and Jun Zhang. Random contrastive interaction for particle swarm optimization in high-dimensional environment. IEEE Transactions on Evolutionary Computation, 28:933–949, 2024.
- [176] Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904, 2023.
- [177] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023.
- [178] Keshav Ramji, Young-Suk Lee, Ram’on Fernandez Astudillo, Md Arafat Sultan, Tahira Naseem, Asim Munawar, Radu Florian, and Salim Roukos. Self-refinement of language models from external proxy metrics feedback. arXiv preprint arXiv:2403.00827, 2024.
- [179] Chenrui Zhang, Lin Liu, Chuyuan Wang, Xiao Sun, Hongyu Wang, Jinpeng Wang, and Mingchen Cai. Prefer: Prompt ensemble learning via feedback-reflect-refine. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19525–19532, 2024.
- [180] Seongyun Lee, Sue Hyun Park, Yongrae Jo, and Minjoon Seo. Volcano: mitigating multimodal hallucination through self-feedback guided revision. arXiv preprint arXiv:2311.07362, 2023.
- [181] Yangruibo Ding, Marcus J Min, Gail Kaiser, and Baishakhi Ray. Cycle: Learning to self-refine the code generation. Proceedings of the ACM on Programming Languages, 8(OOPSLA1):392–418, 2024.
- [182] Leonardo Ranaldi, Freitas, et al. Self-refine instruction-tuning for aligning reasoning in language models. arXiv preprint arXiv:2405.00402, 2024.
- [183] Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b. arXiv preprint arXiv:2406.07394, 2024.
- [184] Wenqi Zhang, Yongliang Shen, Linjuan Wu, Qiuying Peng, Jun Wang, Yueting Zhuang, and Weiming Lu. Self-contrast: Better reflection through inconsistent solving perspectives. arXiv preprint arXiv:2401.02009, 2024.
- [185] Zhaopeng Feng, Yan Zhang, Hao Li, Wenqiang Liu, Jun Lang, Yang Feng, Jian Wu, and Zuozhu Liu. Improving llm-based machine translation with systematic self-correction. arXiv preprint arXiv:2402.16379, 2024.
- [186] Wenda Xu, Daniel Deutsch, Mara Finkelstein, Juraj Juraska, Biao Zhang, Zhongtao Liu, William Yang Wang, Lei Li, and Markus Freitag. Llmrefine: Pinpointing and refining large language models via finegrained actionable feedback. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 1429–1445, 2024.
- [187] Wenda Xu, Guanglei Zhu, Xuandong Zhao, Liangming Pan, Lei Li, and William Wang. Pride and prejudice: Llm amplifies self-bias in self-refinement. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15474–15492, 2024.
- [188] Xin Quan, Marco Valentino, Louise A Dennis, and André Freitas. Verification and refinement of natural language explanations through llm-symbolic theorem proving. arXiv preprint arXiv:2405.01379, 2024.
- [189] Mohamed Abdelaal, Samuel Lokadjaja, and Gilbert Engert. Gllm: Self-corrective g-code generation using large language models with user feedback. 2025.
- [190] Geunwoo Kim, Pierre Baldi, and Stephen McAleer. Language models can solve computer tasks. Advances in Neural Information Processing Systems, 36, 2024.
- [191] Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, et al. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390, 2023.
- [192] Jitao Sang, Yuhang Wang, Jing Zhang, Yanxu Zhu, Chao Kong, Junhong Ye, Shuyu Wei, and Jinlin Xiao. Improving weak-to-strong generalization with scalable oversight and ensemble learning. arXiv preprint arXiv:2402.00667, 2024.
- [193] Chujie Zheng, Ziqi Wang, Heng Ji, Minlie Huang, and Nanyun Peng. Weak-to-strong extrapolation expedites alignment. arXiv preprint arXiv:2404.16792, 2024.
- [194] Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, and Tong Zhang. Iterative preference learning from human feedback: Bridging theory and practice for rlhf under klconstraint. In Proc. the 41st International Conference on Machine Learning (ICML2024), 2024.
- [195] Ziqi Wang, Le Hou, Tianjian Lu, Yuexin Wu, Yunxuan Li, Hongkun Yu, and Heng Ji. Enable lanuguage models to implicitly learn self-improvement from data. In Proc. The Twelfth International Conference on Learning Representations (ICLR2024), 2024.
- [196] Peter Hase, Mohit Bansal, Peter Clark, and Sarah Wiegreffe. The unreasonable effectiveness of easy training data for hard tasks. arXiv preprint arXiv:2401.06751, 2024.
- [197] Zhiqing Sun, Longhui Yu, Yikang Shen, Weiyang Liu, Yiming Yang, Sean Welleck, and Chuang Gan. Easy-to-hard generalization: Scalable alignment beyond human supervision. arXiv preprint arXiv:2403.09472, 2024.
- [198] Jianyuan Guo, Hanting Chen, Chengcheng Wang, Kai Han, Chang Xu, and Yunhe Wang. Vision superalignment: Weak-to-strong generalization for vision foundation models. arXiv preprint arXiv:2402.03749, 2024.
- [199] QWen. Qwq: Reflect deeply on the boundaries of the unknown. 2023.
- [200] Volodymyr Mnih. Asynchronous methods for deep reinforcement learning. arXiv preprint arXiv:1602.01783, 2016.
- [201] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- [202] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [203] Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems, 36, 2024.
- [204] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of Machine Learning and Systems, 6:87–100, 2024.
- [205] Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, and Eunhyeok Park. Owq: Outlier-aware weight quantization for efficient fine-tuning and inference of large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 13355–13364, 2024.
- [206] Hanlin Tang, Yifu Sun, Decheng Wu, Kai Liu, Jianchen Zhu, and Zhanhui Kang. Easyquant: An efficient data-free quantization algorithm for llms. arXiv preprint arXiv:2403.02775, 2024.
- [207] Gunho Park, Baeseong Park, Minsub Kim, Sungjae Lee, Jeonghoon Kim, Beomseok Kwon, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, and Dongsoo Lee. Lut-gemm: Quantized matrix multiplication based on luts for efficient inference in large-scale generative language models. arXiv preprint arXiv:2206.09557, 2022.
- [208] Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization. arXiv preprint arXiv:2306.07629, 2023.
- [209] Yingsong Luo and Ling Chen. Daq: Density-aware post-training weight-only quantization for llms. arXiv preprint arXiv:2410.12187, 2024.
- [210] Fuwen Tan, Royson Lee, Łukasz Dudziak, Shell Xu Hu, Sourav Bhattacharya, Timothy Hospedales, Georgios Tzimiropoulos, and Brais Martinez. Mobilequant: Mobile-friendly quantization for ondevice language models. arXiv preprint arXiv:2408.13933, 2024.
- [211] Yihua Shao, Siyu Liang, Zijian Ling, Minxi Yan, Haiyang Liu, Siyu Chen, Ziyang Yan, Chenyu Zhang, Haotong Qin, Michele Magno, et al. Gwq: Gradient-aware weight quantization for large language models. arXiv preprint arXiv:2411.00850, 2024.
- [212] Stefanos Angelidis, Reinald Kim Amplayo, Yoshihiko Suhara, Xiaolan Wang, and Mirella Lapata. Extractive opinion summarization in quantized transformer spaces. Transactions of the Association for Computational Linguistics, 9:277–293, 2021.
- [213] Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. Zeroquant: Efficient and affordable post-training quantization for large-scale transformers. Advances in Neural Information Processing Systems, 35:27168–27183, 2022.
- [214] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35:3031830332, 2022.
- [215] Zhihang Yuan, Lin Niu, Jiawei Liu, Wenyu Liu, Xinggang Wang, Yuzhang Shang, Guangyu Sun, Qiang Wu, Jiaxiang Wu, and Bingzhe Wu. Rptq: Reorder-based post-training quantization for large language models. arXiv preprint arXiv:2304.01089, 2023.
- [216] Cong Guo, Jiaming Tang, Weiming Hu, Jingwen Leng, Chen Zhang, Fan Yang, Yunxin Liu, Minyi Guo, and Yuhao Zhu. Olive: Accelerating large language models via hardware-friendly outlier-victim pair quantization. In Proceedings of the 50th Annual International Symposium on Computer Architecture, pages 1–15, 2023.
- [217] Xiaoxia Wu, Zhewei Yao, and Yuxiong He. Zeroquant-fp: A leap forward in llms post-training w4a8 quantization using floating-point formats. arXiv preprint arXiv:2307.09782, 2023.
- [218] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- [219] Xiuying Wei, Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, and Xianglong Liu. Outlier suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling. arXiv preprint arXiv:2304.09145, 2023.
- [220] Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models. arXiv preprint arXiv:2308.13137, 2023.
- [221] Xijie Huang, Zechun Liu, Shih-Yang Liu, and Kwang-Ting Cheng. Rolora: Fine-tuning rotated outlierfree llms for effective weight-activation quantization. arXiv preprint arXiv:2407.08044, 2024.
- [222] Xuan Shen, Zhaoyang Han, Lei Lu, Zhenglun Kong, Peiyan Dong, Zhengang Li, Yanyue Xie, Chao Wu, Miriam Leeser, Pu Zhao, et al. Hotaq: Hardware oriented token adaptive quantization for large language models. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024.
- [223] Lei Chen, Yuan Meng, Chen Tang, Xinzhu Ma, Jingyan Jiang, Xin Wang, Zhi Wang, and Wenwu Zhu. Q-dit: Accurate post-training quantization for diffusion transformers. arXiv preprint arXiv:2406.17343, 2024.
- [224] Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization. arXiv preprint arXiv:2401.18079, 2024.
- [225] Yuxuan Yue, Zhihang Yuan, Haojie Duanmu, Sifan Zhou, Jianlong Wu, and Liqiang Nie. Wkvquant: Quantizing weight and key/value cache for large language models gains more. arXiv preprint arXiv:2402.12065, 2024.
- [226] Shichen Dong, Wen Cheng, Jiayu Qin, and Wei Wang. Qaq: Quality adaptive quantization for llm kv cache. arXiv preprint arXiv:2403.04643, 2024.
- [227] Yefei He, Luoming Zhang, Weijia Wu, Jing Liu, Hong Zhou, and Bohan Zhuang. Zipcache: Accurate and efficient kv cache quantization with salient token identification. arXiv preprint arXiv:2405.14256, 2024.
- [228] Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. arXiv preprint arXiv:2402.02750, 2024.
- [229] Wenjing Ke, Zhe Li, Dong Li, Lu Tian, and Emad Barsoum. Dl-qat: Weight-decomposed low-rank quantization-aware training for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 113–119, 2024.
- [230] Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. In International Conference on Machine Learning, pages 10323–10337. PMLR, 2023.
- [231] Yiwei Li, Peiwen Yuan, Shaoxiong Feng, Boyuan Pan, Bin Sun, Xinglin Wang, Heda Wang, and Kan Li. Turning dust into gold: Distilling complex reasoning capabilities from llms by leveraging negative data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18591–18599, 2024.
- [232] Yann LeCun, John Denker, and Sara Solla. Optimal brain damage. Advances in neural information processing systems, 2, 1989.
- [233] Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695, 2023.
- [234] Hang Shao, Bei Liu, and Yanmin Qian. One-shot sensitivity-aware mixed sparsity pruning for large language models. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 11296–11300. IEEE, 2024.
- [235] Dayou Du, Yijia Zhang, Shijie Cao, Jiaqi Guo, Ting Cao, Xiaowen Chu, and Ningyi Xu. Bitdistiller: Unleashing the potential of sub-4-bit llms via self-distillation. arXiv preprint arXiv:2402.10631, 2024.
- [236] Haojun Xia, Zhen Zheng, Yuchao Li, Donglin Zhuang, Zhongzhu Zhou, Xiafei Qiu, Yong Li, Wei Lin, and Shuaiwen Leon Song. Flash-llm: Enabling cost-effective and highly-efficient large generative model inference with unstructured sparsity. arXiv preprint arXiv:2309.10285, 2023.
- [237] Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models. arXiv preprint arXiv:2305.11627, 2023.
- [238] Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Fluctuation-based adaptive structured pruning for large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 10865–10873, 2024.
- [239] Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024, 2024.
- [240] Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. Sheared llama: Accelerating language model pre-training via structured pruning. arXiv preprint arXiv:2310.06694, 2023.
- [241] Mingyang Zhang, Hao Chen, Chunhua Shen, Zhen Yang, Linlin Ou, Xinyi Yu, and Bohan Zhuang. Loraprune: Structured pruning meets low-rank parameter-efficient fine-tuning. In Findings of the Association for Computational Linguistics ACL 2024, pages 3013–3026, 2024.
- [242] Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pages 22137–22176. PMLR, 2023.
- [243] Mingxue Xu, Yao Lei Xu, and Danilo P Mandic. Tensorgpt: Efficient compression of the embedding layer in llms based on the tensor-train decomposition. arXiv preprint arXiv:2307.00526, 2023.
- [244] Yixiao Li, Yifan Yu, Qingru Zhang, Chen Liang, Pengcheng He, Weizhu Chen, and Tuo Zhao. Losparse: Structured compression of large language models based on low-rank and sparse approximation. In International Conference on Machine Learning, pages 20336–20350. PMLR, 2023.
- [245] Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization. arXiv preprint arXiv:2207.00112, 2022.
- [246] Zhihang Yuan, Yuzhang Shang, Yue Song, Qiang Wu, Yan Yan, and Guangyu Sun. Asvd: Activation-aware singular value decomposition for compressing large language models. arXiv preprint arXiv:2312.05821, 2023.
- [247] Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. Svd-llm: Truncation-aware singular value decomposition for large language model compression. arXiv preprint arXiv:2403.07378, 2024.
- [248] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR, 2019.
- [249] Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247, 2020.
- [250] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. arXiv preprint arXiv:2110.04366, 2021.
- [251] Tao Lei, Junwen Bai, Siddhartha Brahma, Joshua Ainslie, Kenton Lee, Yanqi Zhou, Nan Du, Vincent Zhao, Yuexin Wu, Bo Li, et al. Conditional adapters: Parameter-efficient transfer learning with fast inference. Advances in Neural Information Processing Systems, 36:8152–8172, 2023.
- [252] Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao. Mera: Merging pretrained adapters for few-shot learning. arXiv preprint arXiv:2308.15982, 2023.
- [253] Aleksandar Petrov, Philip HS Torr, and Adel Bibi. When do prompting and prefix-tuning work? a theory of capabilities and limitations. arXiv preprint arXiv:2310.19698, 2023.
- [254] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208, 2021.
- [255] Chen Zhang, Dawei Song, Zheyu Ye, and Yan Gao. Towards the law of capacity gap in distilling language models. arXiv preprint arXiv:2311.07052, 2023.
- [256] Fang Ma, Chen Zhang, Lei Ren, Jingang Wang, Qifan Wang, Wei Wu, Xiaojun Quan, and Dawei Song. Xprompt: Exploring the extreme of prompt tuning. arXiv preprint arXiv:2210.04457, 2022.
- [257] Zhuofeng Wu, Sinong Wang, Jiatao Gu, Rui Hou, Yuxiao Dong, VG Vydiswaran, and Hao Ma. Idpg: An instance-dependent prompt generation method. arXiv preprint arXiv:2204.04497, 2022.
- [258] Tu Vu, Brian Lester, Noah Constant, Rami Al-Rfou, and Daniel Cer. Spot: Better frozen model adaptation through soft prompt transfer. arXiv preprint arXiv:2110.07904, 2021.
- [259] Lichang Chen, Heng Huang, and Minhao Cheng. Ptp: Boosting stability and performance of prompt tuning with perturbation-based regularizer. arXiv preprint arXiv:2305.02423, 2023.
- [260] Zhengxiang Shi and Aldo Lipani. Dept: Decomposed prompt tuning for parameter-efficient finetuning. arXiv preprint arXiv:2309.05173, 2023.
- [261] Joon-Young Choi, Junho Kim, Jun-Hyung Park, Wing-Lam Mok, and SangKeun Lee. Smop: Towards efficient and effective prompt tuning with sparse mixture-of-prompts. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14306–14316, 2023.
- [262] Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 35:1950–1965, 2022.
- [263] Dongze Lian, Daquan Zhou, Jiashi Feng, and Xinchao Wang. Scaling & shifting your features: A new baseline for efficient model tuning. Advances in Neural Information Processing Systems, 35:109–123, 2022.
- [264] Ximing Lu, Faeze Brahman, Peter West, Jaehun Jung, Khyathi Chandu, Abhilasha Ravichander, Prithviraj Ammanabrolu, Liwei Jiang, Sahana Ramnath, Nouha Dziri, et al. Inference-time policy adapters (ipa): Tailoring extreme-scale lms without fine-tuning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6863–6883, 2023.
- [265] Demi Guo, Alexander M Rush, and Yoon Kim. Parameter-efficient transfer learning with diff pruning. arXiv preprint arXiv:2012.07463, 2020.
- [266] Yi-Lin Sung, Varun Nair, and Colin A Raffel. Training neural networks with fixed sparse masks. Advances in Neural Information Processing Systems, 34:24193–24205, 2021.
- [267] Alan Ansell, Edoardo Maria Ponti, Anna Korhonen, and Ivan Vulic ́. Composable sparse fine-tuning for cross-lingual transfer. arXiv preprint arXiv:2110.07560, 2021.
- [268] Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 12799–12807, 2023.
- [269] Runxin Xu, Fuli Luo, Zhiyuan Zhang, Chuanqi Tan, Baobao Chang, Songfang Huang, and Fei Huang. Raise a child in large language model: Towards effective and generalizable fine-tuning. arXiv preprint arXiv:2109.05687, 2021.
- [270] Danilo Vucetic, Mohammadreza Tayaranian, Maryam Ziaeefard, James J Clark, Brett H Meyer, and Warren J Gross. Efficient fine-tuning of bert models on the edge. In 2022 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1838–1842. IEEE, 2022.
- [271] Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199, 2021.
- [272] Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. arXiv preprint arXiv:2012.13255, 2020.
- [273] Mojtaba Valipour, Mehdi Rezagholizadeh, Ivan Kobyzev, and Ali Ghodsi. Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. arXiv preprint arXiv:2210.07558, 2022.
- [274] Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning. arXiv preprint arXiv:2303.10512, 2023.
- [275] Ning Ding, Xingtai Lv, Qiaosen Wang, Yulin Chen, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. Sparse low-rank adaptation of pre-trained language models. arXiv preprint arXiv:2311.11696, 2023.
- [276] Adam X Yang, Maxime Robeyns, Xi Wang, and Laurence Aitchison. Bayesian low-rank adaptation for large language models. arXiv preprint arXiv:2308.13111, 2023.
- [277] Rabeeh Karimi Mahabadi, James Henderson, and Sebastian Ruder. Compacter: Efficient low-rank hypercomplex adapter layers. Advances in Neural Information Processing Systems, 34:1022–1035, 2021.
- [278] Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki Markus Asano. Vera: Vector-based random matrix adaptation. arXiv preprint arXiv:2310.11454, 2023.
- [279] Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, KwangTing Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024.
- [280] Qiushi Huang, Tom Ko, Zhan Zhuang, Lilian Tang, and Yu Zhang. HiRA: Parameter-efficient hadamard high-rank adaptation for large language models. In The Thirteenth International Conference on Learning Representations, 2025.
- [281] Zhan Zhuang, Yulong Zhang, Xuehao Wang, Jiangang Lu, Ying Wei, and Yu Zhang. Time-varying lora: Towards effective cross-domain fine-tuning of diffusion models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024.
- [282] Xuehao Wang, Zhan Zhuang, Feiyang Ye, and Yu Zhang. MTSAM: Multi-task fine-tuning for segment anything model. In The Thirteenth International Conference on Learning Representations, 2025.
- [283] Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models. Advances in Neural Information Processing Systems, 37:121038121072, 2025.
- [284] Shaowen Wang, Linxi Yu, and Jian Li. Lora-ga: Low-rank adaptation with gradient approximation. Advances in Neural Information Processing Systems, 37:54905–54931, 2025.
- [285] Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models. arXiv preprint arXiv:2402.12354, 2024.
- [286] Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, and Tieniu Tan. Lora-pro: Are low-rank adapters properly optimized? arXiv preprint arXiv:2407.18242, 2024.
- [287] Zhan Zhuang, Xiequn Wang, Yulong Zhang, Wei Li, Yu Zhang, and Ying Wei. Copra: A progressive lora training strategy. arXiv preprint arXiv:2410.22911, 2024.
- [288] Qiushi Huang, Tom Ko, Lilian Tang, and Yu Zhang. ColoRA: A competitive learning approach for enhancing loRA. In The Thirteenth International Conference on Learning Representations, 2025.
- [289] Yuning Mao, Lambert Mathias, Rui Hou, Amjad Almahairi, Hao Ma, Jiawei Han, Wen-tau Yih, and Madian Khabsa. Unipelt: A unified framework for parameter-efficient language model tuning. arXiv preprint arXiv:2110.07577, 2021.
- [290] Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. Neural prompt search. arXiv preprint arXiv:2206.04673, 2022.
- [291] Han Zhou, Xingchen Wan, Ivan Vulic ́, and Anna Korhonen. Autopeft: Automatic configuration search for parameter-efficient fine-tuning. Transactions of the Association for Computational Linguistics, 12:525–542, 2024.
- [292] Xuehao Wang, Liyuan Wang, Binghuai Lin, and Yu Zhang. Headmap: Locating and enhancing knowledge circuits in LLMs. In The Thirteenth International Conference on Learning Representations, 2025.
- [293] Zhiqiang Hu, Lei Wang, Yihuai Lan, Wanyu Xu, Ee-Peng Lim, Lidong Bing, Xing Xu, Soujanya Poria, and Roy Ka-Wei Lee. Llm-adapters: An adapter family for parameter-efficient fine-tuning of large language models. arXiv preprint arXiv:2304.01933, 2023.
- [294] Solomon Kullback and Richard A Leibler. On information and sufficiency. The annals of mathematical statistics, 22(1):79–86, 1951.
- [295] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- [296] Shiyang Li, Jianshu Chen, Yelong Shen, Zhiyu Chen, Xinlu Zhang, Zekun Li, Hong Wang, Jing Qian, Baolin Peng, Yi Mao, et al. Explanations from large language models make small reasoners better. arXiv preprint arXiv:2210.06726, 2022.
- [297] Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. Teaching small language models to reason. arXiv preprint arXiv:2212.08410, 2022.
- [298] Namgyu Ho, Laura Schmid, and Se-Young Yun. Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071, 2022.
- [299] Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. Distilling reasoning capabilities into smaller language models. Findings of the Association for Computational Linguistics: ACL 2023, pages 7059–7073, 2023.
- [300] Yukun Huang, Yanda Chen, Zhou Yu, and Kathleen McKeown. In-context learning distillation: Transferring few-shot learning ability of pre-trained language models. arXiv preprint arXiv:2212.10670, 2022.
- [301] Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. Specializing smaller language models towards multi-step reasoning. In International Conference on Machine Learning, pages 10421–10430. PMLR, 2023.
- [302] Minghao Wu, Abdul Waheed, Chiyu Zhang, Muhammad Abdul-Mageed, and Alham Fikri Aji. Laminilm: A diverse herd of distilled models from large-scale instructions. arXiv preprint arXiv:2304.14402, 2023.
- [303] Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, and Xiang Ren. Scott: Selfconsistent chain-of-thought distillation. arXiv preprint arXiv:2305.01879, 2023.
- [304] Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301, 2023.
- [305] Yuxin Jiang, Chunkit Chan, Mingyang Chen, and Wei Wang. Lion: Adversarial distillation of proprietary large language models. arXiv preprint arXiv:2305.12870, 2023.
- [306] Xuekai Zhu, Biqing Qi, Kaiyan Zhang, Xinwei Long, Zhouhan Lin, and Bowen Zhou. Pad: Programaided distillation can teach small models reasoning better than chain-of-thought fine-tuning. arXiv preprint arXiv:2305.13888, 2023.
- [307] Yuxuan Liu. Learning to reason with autoregressive in-context distillation. In The Second Tiny Papers Track at ICLR 2024, 2024.
- [308] Shankar Padmanabhan, Yasumasa Onoe, Michael Zhang, Greg Durrett, and Eunsol Choi. Propagating knowledge updates to lms through distillation. Advances in Neural Information Processing Systems, 36:47124–47142, 2023.
- [309] Zhaoyang Wang, Shaohan Huang, Yuxuan Liu, Jiahai Wang, Minghui Song, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, et al. Democratizing reasoning ability: Tailored learning from large language model. arXiv preprint arXiv:2310.13332, 2023.
- [310] Ming Li, Lichang Chen, Jiuhai Chen, Shwai He, Jiuxiang Gu, and Tianyi Zhou. Selective reflectiontuning: Student-selected data recycling for llm instruction-tuning. In Findings of the Association for Computational Linguistics ACL 2024, pages 16189–16211, 2024.
- [311] Ming Li, Jiuhai Chen, Lichang Chen, and Tianyi Zhou. Can llms speak for diverse people? tuning llms via debate to generate controllable controversial statements, 2024.
- [312] Lu Hou, Zhiqi Huang, Lifeng Shang, Xin Jiang, Xiao Chen, and Qun Liu. Dynabert: Dynamic bert with adaptive width and depth. Advances in Neural Information Processing Systems, 33:9782–9793, 2020.
- [313] Chen Liang, Simiao Zuo, Qingru Zhang, Pengcheng He, Weizhu Chen, and Tuo Zhao. Less is more: Task-aware layer-wise distillation for language model compression. In International Conference on Machine Learning, pages 20852–20867. PMLR, 2023.
- [314] Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In The Twelfth International Conference on Learning Representations, 2024.
- [315] Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543, 2023.
- [316] Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, and Yuandong Tian. Rlcd: Reinforcement learning from contrastive distillation for language model alignment, 2024.
- [317] Inar Timiryasov and Jean-Loup Tastet. Baby llama: knowledge distillation from an ensemble of teachers trained on a small dataset with no performance penalty. arXiv preprint arXiv:2308.02019, 2023.
- [318] Asaf Yehudai, Boaz Carmeli, Yosi Mass, Ofir Arviv, Nathaniel Mills, Assaf Toledo, Eyal Shnarch, and Leshem Choshen. Genie: Achieving human parity in content-grounded datasets generation. arXiv preprint arXiv:2401.14367, 2024.
- [319] Enneng Yang, Li Shen, Zhenyi Wang, Guibing Guo, Xiaojun Chen, Xingwei Wang, and Dacheng Tao. Representation surgery for multi-task model merging. ArXiv, abs/2402.02705, 2024.
- [320] Chen Jia. Adversarial moment-matching distillation of large language models, 2024.
- [321] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network, 2015.
- [322] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023.
- [323] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. Scaling instruction-finetuned language models, 2022.
- [324] Yue Wang, Weishi Wang, Shafiq Joty, and Steven C. H. Hoi. Codet5: Identifier-aware unified pretrained encoder-decoder models for code understanding and generation, 2021.
- [325] Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born again neural networks, 2018.
- [326] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- [327] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023.
- [328] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- [329] Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- [330] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- [331] Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding language models to images for multimodal inputs and outputs. In International Conference on Machine Learning, pages 1728317300. PMLR, 2023.
- [332] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024.
- [333] K Chen, Z Zhang, W Zeng, R Zhang, F Zhu, and R Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arxiv 2023. arXiv preprint arXiv:2306.15195.
- [334] Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pretraining for visual language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26689–26699, 2024.
- [335] Renjie Pi, Jiahui Gao, Shizhe Diao, Rui Pan, Hanze Dong, Jipeng Zhang, Lewei Yao, Jianhua Han, Hang Xu, Lingpeng Kong, et al. Detgpt: Detect what you need via reasoning. arXiv preprint arXiv:2305.14167, 2023.
- [336] Yangyi Chen, Xingyao Wang, Hao Peng, and Heng Ji. Solo: A single transformer for scalable visionlanguage modeling. In Transactions on Machine Learning Research, 2024.
- [337] Hugo Laurençon, Léo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building visionlanguage models? Advances in Neural Information Processing Systems, 37:87874–87907, 2025.
- [338] Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Yadong Mu, et al. Unified languagevision pretraining in llm with dynamic discrete visual tokenization. In International Conference on Learning Representations, 2024. [339] Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302, 2024.
- [340] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025.
- [341] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
- [342] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- [343] Feilong Chen, Minglun Han, Haozhi Zhao, Qingyang Zhang, Jing Shi, Shuang Xu, and Bo Xu. Xllm: Bootstrapping advanced large language models by treating multi-modalities as foreign languages. arXiv preprint arXiv:2305.04160, 2023.
- [344] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- [345] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 1(2):3, 2023.
- [346] Gongwei Chen, Leyang Shen, Rui Shao, Xiang Deng, and Liqiang Nie. Lion: Empowering multimodal large language model with dual-level visual knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26540–26550, 2024.
- [347] Junyu Lu, Dixiang Zhang, Songxin Zhang, Zejian Xie, Zhuoyang Song, Cong Lin, Jiaxing Zhang, Bingyi Jing, and Pingjian Zhang. Lyrics: Boosting fine-grained language-vision alignment and comprehension via semantic-aware visual objects. arXiv preprint arXiv:2312.05278, 2023.
- [348] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390, 2023.
- [349] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: a multimodal model with in-context instruction tuning. corr abs/2305.03726 (2023), 2023.
- [350] Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023.
- [351] Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open webscale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems, 36, 2024.
- [352] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. arXiv prepring arXiv:2312.14238, 2023.
- [353] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023.
- [354] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv preprint arXiv:2306.05424, 2023.
- [355] Ruyang Liu, Chen Li, Yixiao Ge, Ying Shan, Thomas H Li, and Ge Li. One for all: Video conversation is feasible without video instruction tuning. arXiv preprint arXiv:2309.15785, 2023.
- [356] Peng Gao, Renrui Zhang, Chris Liu, Longtian Qiu, Siyuan Huang, Weifeng Lin, Shitian Zhao, Shijie Geng, Ziyi Lin, Peng Jin, et al. Sphinx-x: Scaling data and parameters for a family of multi-modal large language models. arXiv preprint arXiv:2402.05935, 2024.
- [357] Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, and Jing Liu. Vl-mamba: Exploring state space models for multimodal learning. arXiv preprint arXiv:2403.13600, 2024.
- [358] Minjie Zhu, Yichen Zhu, Xin Liu, Ning Liu, Zhiyuan Xu, Chaomin Shen, Yaxin Peng, Zhicai Ou, Feifei Feng, and Jian Tang. A comprehensive overhaul of multimodal assistant with small language models. arXiv preprint arXiv:2403.06199, 2024.
- [359] Han Zhao, Min Zhang, Wei Zhao, Pengxiang Ding, Siteng Huang, and Donglin Wang. Cobra: Extending mamba to multi-modal large language model for efficient inference. arXiv preprint arXiv:2403.14520, 2024.
- [360] QWen. Qvq: To see the world with wisdom. 2024.
- [361] Anthropic. Claude 3.7 Sonnet, 2025.
- [362] OpenAI. OpenAI GPT-4.5 System Card, 2025.
- [363] Paul K Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, et al. Audiopalm: A large language model that can speak and listen. arXiv preprint arXiv:2306.12925, 2023.
- [364] Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv preprint arXiv:2305.11000, 2023.
- [365] Puyuan Peng, Po-Yao Huang, Shang-Wen Li, Abdelrahman Mohamed, and David Harwath. Voicecraft: Zero-shot speech editing and text-to-speech in the wild. arXiv preprint arXiv:2403.16973, 2024.
- [366] Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, et al. Imagebind-llm: Multi-modality instruction tuning. arXiv preprint arXiv:2309.03905, 2023.
- [367] Seungwhan Moon, Andrea Madotto, Zhaojiang Lin, Tushar Nagarajan, Matt Smith, Shashank Jain, Chun-Fu Yeh, Prakash Murugesan, Peyman Heidari, Yue Liu, et al. Anymal: An efficient and scalable any-modality augmented language model. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1314–1332, 2024.
- [368] Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. arXiv preprint arXiv:2309.05519, 2023.
- [369] Zineng Tang, Ziyi Yang, Mahmoud Khademi, Yang Liu, Chenguang Zhu, and Mohit Bansal. Codi2: In-context interleaved and interactive any-to-any generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27425–27434, 2024.
- [370] Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understanding reasoning and planning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26428–26438, 2024.
- [371] Artemis Panagopoulou, Le Xue, Ning Yu, Junnan Li, Dongxu Li, Shafiq Joty, Ran Xu, Silvio Savarese, Caiming Xiong, and Juan Carlos Niebles. X-instructblip: A framework for aligning xmodal instruction-aware representations to llms and emergent cross-modal reasoning. arXiv preprint arXiv:2311.18799, 2023.
- [372] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- [373] Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1935819369, 2023.
- [374] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15180–15190, June 2023.
- [375] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11975–11986, 2023. [376] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- [377] Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [378] Yu Zhang, Wei Han, James Qin, Yongqiang Wang, Ankur Bapna, Zhehuai Chen, Nanxin Chen, Bo Li, Vera Axelrod, Gary Wang, et al. Google usm: Scaling automatic speech recognition beyond 100 languages. arXiv preprint arXiv:2303.01037, 2023.
- [379] Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D. Plumbley, Yuexian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:3339–3354, 2024. [380] Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, and Mark D Plumbley. Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:2880–2894, 2020.
- [381] Ke Chen, Xingjian Du, Bilei Zhu, Zejun Ma, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection. In ICASSP 20222022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 646–650. IEEE, 2022.
- [382] Wouter M Kouw and Marco Loog. An introduction to domain adaptation and transfer learning. arXiv preprint arXiv:1812.11806, 2018.
- [383] Jingjing Li, Zhiqi Yu, Zhekai Du, Lei Zhu, and Heng Tao Shen. A comprehensive survey on source-free domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell., 46(8):5743–5762, 2024.
- [384] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2023.
- [385] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474, 2022.
- [386] Shima Imani, Liang Du, and Harsh Shrivastava. Mathprompter: Mathematical reasoning using large language models. arXiv preprint arXiv:2303.05398, 2023.
- [387] Tongtong Wu, Linhao Luo, Yuan-Fang Li, Shirui Pan, Thuy-Trang Vu, and Gholamreza Haffari. Continual learning for large language models: A survey. arXiv preprint arXiv:2402.01364, 2024.
- [388] Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, et al. A comprehensive study of knowledge editing for large language models. arXiv preprint arXiv:2401.01286, 2024.
- [389] Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memorybased model editing at scale. In International Conference on Machine Learning, pages 15817–15831. PMLR, 2022.
- [390] Hengrui Gu, Kaixiong Zhou, Xiaotian Han, Ninghao Liu, Ruobing Wang, and Xin Wang. Pokemqa: Programmable knowledge editing for multi-hop question answering. arXiv preprint arXiv:2312.15194, 2023.
- [391] Qingxiu Dong, Damai Dai, Yifan Song, Jingjing Xu, Zhifang Sui, and Lei Li. Calibrating factual knowledge in pretrained language models. arXiv preprint arXiv:2210.03329, 2022.
- [392] Zeyu Huang, Yikang Shen, Xiaofeng Zhang, Jie Zhou, Wenge Rong, and Zhang Xiong. Transformerpatcher: One mistake worth one neuron. arXiv preprint arXiv:2301.09785, 2023.
- [393] Evan Hernandez, Belinda Z Li, and Jacob Andreas. Inspecting and editing knowledge representations in language models. arXiv preprint arXiv:2304.00740, 2023.
- [394] Tom Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, and Marzyeh Ghassemi. Aging with grace: Lifelong model editing with discrete key-value adaptors. Advances in Neural Information Processing Systems, 36, 2024.
- [395] Suhang Wu, Minlong Peng, Yue Chen, Jinsong Su, and Mingming Sun. Eva-kellm: A new benchmark for evaluating knowledge editing of llms. arXiv preprint arXiv:2308.09954, 2023.
- [396] Lang Yu, Qin Chen, Jie Zhou, and Liang He. Melo: Enhancing model editing with neuron-indexed dynamic lora. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19449–19457, 2024.
- [397] Chen Zhu, Ankit Singh Rawat, Manzil Zaheer, Srinadh Bhojanapalli, Daliang Li, Felix Yu, and Sanjiv Kumar. Modifying memories in transformer models. arXiv preprint arXiv:2012.00363, 2020.
- [398] Anton Sinitsin, Vsevolod Plokhotnyuk, Dmitriy Pyrkin, Sergei Popov, and Artem Babenko. Editable neural networks. arXiv preprint arXiv:2004.00345, 2020.
- [399] Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. arXiv preprint arXiv:2104.08164, 2021.
- [400] Peter Hase, Mona Diab, Asli Celikyilmaz, Xian Li, Zornitsa Kozareva, Veselin Stoyanov, Mohit Bansal, and Srinivasan Iyer. Methods for measuring, updating, and visualizing factual beliefs in language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2714–2731, 2023.
- [401] Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale. arXiv preprint arXiv:2110.11309, 2021.
- [402] Chenmien Tan, Ge Zhang, and Jie Fu. Massive editing for large language models via meta learning. arXiv preprint arXiv:2311.04661, 2023.
- [403] Akshaj Kumar Veldanda, Shi-Xiong Zhang, Anirban Das, Supriyo Chakraborty, Stephen Rawls, Sambit Sahu, and Milind Naphade. Llm surgery: Efficient knowledge unlearning and editing in large language models. arXiv preprint arXiv:2409.13054, 2024.
- [404] Yongchang Li, Yujin Zhu, Tao Yan, Shijian Fan, Gang Wu, and Liang Xu. Knowledge editing for large language model with knowledge neuronal ensemble. arXiv preprint arXiv:2412.20637, 2024.
- [405] Tianci Liu, Zihan Dong, Linjun Zhang, Haoyu Wang, and Jing Gao. Mitigating heterogeneous token overfitting in llm knowledge editing. arXiv preprint arXiv:2502.00602, 2025.
- [406] Jiaxin Qin, Zixuan Zhang, Chi Han, Manling Li, Pengfei Yu, and Heng Ji. Why does new knowledge create messy ripple effects in llms? In Proc. The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP2024), 2024.
- [407] Jiateng Liu, Pengfei Yu, Yuji Zhang, Sha Li, Zixuan Zhang, and Heng Ji. Evedit: Event-based knowledge editing with deductive editing boundaries. In Proc. The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP2024), 2024.
- [408] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.
- [409] Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey. arXiv preprint arXiv:2402.19473, 2024.
- [410] Ye Zhang, Mengran Zhu, Yulu Gong, and Rui Ding. Optimizing science question ranking through model and retrieval-augmented generation. International Journal of Computer Science and Information Technology, 1(1):124–130, 2023.
- [411] Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. Benchmarking retrieval-augmented generation for medicine. arXiv preprint arXiv:2402.13178, 2024.
- [412] Boyu Zhang, Hongyang Yang, Tianyu Zhou, Muhammad Ali Babar, and Xiao-Yang Liu. Enhancing financial sentiment analysis via retrieval augmented large language models. In Proceedings of the fourth ACM international conference on AI in finance, pages 349–356, 2023.
- [413] Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6491–6501, 2024.
- [414] Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. arXiv preprint arXiv:2007.01282, 2020.
- [415] Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983, 2023.
- [416] Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024.
- [417] Vladimir Karpukhin, Barlas Og ̆uz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020.
- [418] Thang Nguyen, Peter Chin, and Yu-Wing Tai. Reward-rag: Enhancing rag with reward driven supervision. arXiv preprint arXiv:2410.03780, 2024.
- [419] Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023.
- [420] Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Retrieval-augmented transformer for image captioning. In Proceedings of the 19th international conference on content-based multimedia indexing, pages 1–7, 2022.
- [421] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
- [422] Boxin Wang, Wei Ping, Peng Xu, Lawrence McAfee, Zihan Liu, Mohammad Shoeybi, Yi Dong, Oleksii Kuchaiev, Bo Li, Chaowei Xiao, et al. Shall we pretrain autoregressive language models with retrieval? a comprehensive study. arXiv preprint arXiv:2304.06762, 2023.
- [423] Yinghao Zhu, Changyu Ren, Shiyun Xie, Shukai Liu, Hangyuan Ji, Zixiang Wang, Tao Sun, Long He, Zhoujun Li, Xi Zhu, et al. Realm: Rag-driven enhancement of multimodal electronic health records analysis via large language models. arXiv preprint arXiv:2402.07016, 2024.
- [424] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022.
- [425] Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy. arXiv preprint arXiv:2305.15294, 2023.
- [426] Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652, 2023.
- [427] Liang Wang, Nan Yang, and Furu Wei. Learning to retrieve in-context examples for large language models. arXiv preprint arXiv:2307.07164, 2023.
- [428] Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, et al. Ra-dit: Retrieval-augmented dual instruction tuning. arXiv preprint arXiv:2310.01352, 2023.
- [429] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR, 2020.
- [430] Fumin Shen, Wei Liu, Shaoting Zhang, Yang Yang, and Heng Tao Shen. Learning binary codes for maximum inner product search. In Proceedings of the IEEE International Conference on Computer Vision, pages 4148–4156, 2015.
- [431] Enneng Yang, Li Shen, Guibing Guo, Xingwei Wang, Xiaochun Cao, Jie Zhang, and Dacheng Tao. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities. arXiv preprint arXiv:2408.07666, 2024.
- [432] Charles Goddard, Shamane Siriwardhana, Malikeh Ehghaghi, Luke Meyers, Vlad Karpukhin, Brian Benedict, Mark McQuade, and Jacob Solawetz. Arcee’s mergekit: A toolkit for merging large language models. arXiv preprint arXiv:2403.13257, 2024.
- [433] Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pages 23965–23998. PMLR, 2022.
- [434] Negin Entezari, Saba A Al-Sayouri, Amirali Darvishzadeh, and Evangelos E Papalexakis. All you need is low (rank) defending against adversarial attacks on graphs. In WSDM, 2020.
- [435] Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. arXiv preprint arXiv:2212.04089, 2022.
- [436] Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models. Advances in Neural Information Processing Systems, 36, 2024.
- [437] Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. In Forty-first International Conference on Machine Learning, 2024.
- [438] Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm-blender: Ensembling large language models with pairwise ranking and generative fusion. arXiv preprint arXiv:2306.02561, 2023.
- [439] Fanqi Wan, Xinting Huang, Deng Cai, Xiaojun Quan, Wei Bi, and Shuming Shi. Knowledge fusion of large language models. arXiv preprint arXiv:2401.10491, 2024.
- [440] Fanqi Wan, Longguang Zhong, Ziyi Yang, Ruijun Chen, and Xiaojun Quan. Fusechat: Knowledge fusion of chat models. arXiv preprint arXiv:2408.07990, 2024.
- [441] Joan Puigcerver, Carlos Riquelme, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts. arXiv preprint arXiv:2308.00951, 2023.
- [442] Mohammed Muqeeth, Haokun Liu, and Colin Raffel. Soft merging of experts with adaptive routing. arXiv preprint arXiv:2306.03745, 2023.
- [443] Tian-Yu Liu, Aditya Golatkar, and Stefan 0 Soatto. Tangent transformers for composition, privacy and removal. ArXiv, abs/2307.08122, 2023.
- [444] Ruochen Jin, Bojian Hou, Jiancong Xiao, Weijie J. Su, and Li Shen. Fine-tuning linear layers only is a simple yet effective way for task arithmetic. CoRR, abs/2407.07089, 2024.
- [445] Guillermo Ortiz-Jiménez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models. ArXiv, abs/2305.12827, 2023.
- [446] Dang Nguyen, Trang Thi Thu Nguyen, Khai Nguyen, D.Q. Phung, Hung Bui, and Nhat Ho. On cross-layer alignment for model fusion of heterogeneous neural networks. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5, 2021.
- [447] Omri Avrahami, Dani Lischinski, and Ohad Fried. Gan cocktail: mixing gans without dataset access. ArXiv, abs/2106.03847, 2021.
- [448] Sidak Pal Singh and Martin Jaggi. Model fusion via optimal transport. ArXiv, abs/1910.05653, 2019.
- [449] Samuel K. Ainsworth, Jonathan Hayase, and Siddhartha S. Srinivasa. Git re-basin: Merging models modulo permutation symmetries. ArXiv, abs/2209.04836, 2022.
- [450] Aviv Shamsian, Aviv Navon, Ethan Fetaya, and Gal Chechik. Personalized federated learning using hypernetworks. In International Conference on Machine Learning, 2021.
- [451] Keller Jordan, Hanie Sedghi, Olga Saukh, Rahim Entezari, and Behnam Neyshabur. Repair: Renormalizing permuted activations for interpolation repair. ArXiv, abs/2211.08403, 2022.nedict, Mark McQuade, and Jacob Solawetz. Arcee’s mergekit: A toolkit for merging large language models. arXiv preprint arXiv:2403.13257, 2024.
- [452] Yuyan Zhou, Liang Song, Bingning Wang, and Weipeng Chen. Metagpt: Merging large language models using model exclusive task arithmetic. In Conference on Empirical Methods in Natural Language Processing, 2024.
- [453] Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao. Adamerging: Adaptive model merging for multi-task learning. In The Twelfth International Conference on Learning Representations, 2024.
- [454] An Quang Tang, Li Shen, Yong Luo, Liang Ding, Han Hu, Bo Du, and Dacheng Tao. Concrete subspace learning based interference elimination for multi-task model fusion. ArXiv, abs/2312.06173, 2023.
- [455] Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, and Dacheng Tao. Merging multi-task models via weight-ensembling mixture of experts. CoRR, abs/2402.00433, 2024.
- [456] Zhenyi Lu, Chenghao Fan, Wei Wei, Xiaoye Qu, Dangyang Chen, and Yu Cheng. Twin-merging: Dynamic integration of modular expertise in model merging. ArXiv, abs/2406.15479, 2024.
- [457] Tom Gunter, Zirui Wang, Chong Wang, Ruoming Pang, Andy Narayanan, Aonan Zhang, Bowen Zhang, Chen Chen, Chung-Cheng Chiu, David Qiu, et al. Apple intelligence foundation language models. arXiv preprint arXiv:2407.21075, 2024.
- [458] Shu Hu, Yiming Ying, Xin Wang, and Siwei Lyu. Sum of ranked range loss for supervised learning. Journal of Machine Learning Research, 23(112):1–44, 2022.
- [459] Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. Multitask prompted training enables zeroshot task generalization. arXiv preprint arXiv:2110.08207, 2021.
- [460] Kawin Ethayarajh, Yejin Choi, and Swabha Swayamdipta. Understanding dataset difficulty with vusable information. In International Conference on Machine Learning, 2021.
- [461] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted questionanswering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- [462] Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. Supernaturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705, 2022.
- [463] Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, et al. Crosslingual generalization through multitask finetuning. arXiv preprint arXiv:2211.01786, 2022.
- [464] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023.
- [465] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- [466] Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversationsdemocratizing large language model alignment. Advances in Neural Information Processing Systems, 36, 2024.
- [467] Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv preprint arxiv:2301.07597, 2023.
- [468] Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instructiontuned llm. Company Blog of Databricks, 2023.
- [469] RyokoAI. Sharegpt52k. https://huggingface.co/datasets/RyokoAI/ShareGPT52K, 2023. Accessed: 2024-04-27.
- [470] Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evolinstruct. arXiv preprint arXiv:2306.08568, 2023.
- [471] Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Baochang Ma, and Xiangang Li. Belle: Be everyone’s large language model engine, 2023.
- [472] W Lian, B Goodson, E Pentland, et al. Openorca: An open dataset of gpt augmented flan reasoning traces, 2023.
- [473] Nathan Lambert, Lewis Tunstall, Nazneen Rajani, and Tristan Thrush. Huggingface h4 stack exchange preference dataset, 2023.
- [474] Teknium. Openhermes dataset, 2023a.
- [475] Teknium. Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants, 2023b.
- [476] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233, 2023.
- [477] Jinjie Ni, Fuzhao Xue, Kabir Jain, Mahir Hitesh Shah, Zangwei Zheng, and Yang You. Instruction in the wild: A user-based instruction dataset. https://github.com/XueFuzhao/ InstructionWild, 2023.
- [478] Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. arXiv preprint arXiv:2304.01196, 2023.
- [479] Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatGPT interaction logs in the wild. In The Twelfth International Conference on Learning Representations, 2024.
- [480] Jiuhai Chen, Rifaa Qadri, Yuxin Wen, Neel Jain, John Kirchenbauer, Tianyi Zhou, and Tom Goldstein. Genqa: Generating millions of instructions from a handful of prompts. arXiv preprint arXiv:2406.10323, 2024.
- [481] Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing. arXiv preprint arXiv:2406.08464, 2024.
- [482] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- [483] Bill Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In Third international workshop on paraphrasing (IWP2005), 2005.
- [484] Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial nli: A new benchmark for natural language understanding. arXiv preprint arXiv:1910.14599, 2019.
- [485] Jaromir Savelka, Kevin D. Ashley, Morgan A. Gray, Hannes Westermann, and Huihui Xu. Explaining legal concepts with augmented large language models (gpt-4), 2023.
- [486] Hannes Westermann, Jaromir Savelka, and Karim Benyekhlef. Llmediator: Gpt-4 assisted online dispute resolution, 2023.
- [487] Chengyuan Liu, Shihang Wang, Yangyang Kang, Lizhi Qing, Fubang Zhao, Changlong Sun, Kun Kuang, and Fei Wu. More than catastrophic forgetting: Integrating general capabilities for domainspecific llms, 2024.
- [488] Behrooz Mansouri and Ricardo Campos. Falqu: Finding answers to legal questions, 2023.
- [489] Antoine Louis, Gijs van Dijck, and Gerasimos Spanakis. Interpretable long-form legal question answering with retrieval-augmented large language models, 2023.
- [490] Ilias Chalkidis, Manos Fergadiotis, Dimitrios Tsarapatsanis, Nikolaos Aletras, Ion Androutsopoulos, and Prodromos Malakasiotis. Paragraph-level rationale extraction through regularization: A case study on European court of human rights cases. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021.
- [491] Dietrich Trautmann, Alina Petrova, and Frank Schilder. Legal prompt engineering for multilingual legal judgement prediction, 2022.
- [492] Xue Zongyue, Liu Huanghai, Hu Yiran, Kong Kangle, Wang Chenlu, Liu Yun, and Shen Weixing. Leec: A legal element extraction dataset with an extensive domain-specific label system, 2023.
- [493] Hang Jiang, Xiajie Zhang, Robert Mahari, Daniel Kessler, Eric Ma, Tal August, Irene Li, Alex Pentland, Yoon Kim, Deb Roy, and Jad Kabbara. Leveraging large language models for learning complex legal concepts through storytelling. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024.
- [494] Hai-Long Nguyen, Duc-Minh Nguyen, Tan-Minh Nguyen, Ha-Thanh Nguyen, Thi-Hai-Yen Vuong, and Ken Satoh. Enhancing legal document retrieval: A multi-phase approach with large language models, 2024.
- [495] Atin Sakkeer Hussain and Anu Thomas. Large language models for judicial entity extraction: A comparative study, 2024.
- [496] Aniket Deroy, Kripabandhu Ghosh, and Saptarshi Ghosh. Applicability of large language models and generative models for legal case judgement summarization, 2024.
- [497] Zhi Zhou, Jiang-Xin Shi, Peng-Xiao Song, Xiao-Wen Yang, Yi-Xuan Jin, Lan-Zhe Guo, and Yu-Feng Li. Lawgpt: A chinese legal knowledge-enhanced large language model, 2024.
- [498] Quzhe Huang, Mingxu Tao, Chen Zhang, Zhenwei An, Cong Jiang, Zhibin Chen, Zirui Wu, and Yansong Feng. Lawyer llama. https://github.com/AndrewZhe/lawyer-llama, 2023.
- [499] Haitao Li. Lexilaw. https://github.com/CSHaitao/LexiLaw, 2023.
- [500] Pierre Colombo, Telmo Pires, Malik Boudiaf, Rui Melo, Dominic Culver, Sofia Morgado, Etienne Malaboeuf, Gabriel Hautreux, Johanne Charpentier, and Michael Desa. Saullm-54b & saullm-141b: Scaling up domain adaptation for the legal domain, 2024.
- [501] Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. Chatlaw. https://github.com/ PKU-YuanGroup/ChatLaw, 2023.
- [502] Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. Translation between molecules and natural language. In Proc. The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP2022), 2022.
- [503] Carl Edwards, Aakanksha Naik, Tushar Khot, Martin Burke, Heng Ji, and Tom Hope. Synergpt: Incontext learning for personalized drug synergy prediction and drug design. In Proc. 1st Conference on Language Modeling (COLM2024), 2024.
- [504] Henry William Sprueill, Carl Edwards, Mariefel V Olarte, Udishnu Sanyal, Heng Ji, and Sutanay Choudhury. Monte carlo thought search: Large language model querying for complex scientific reasoning in catalyst design. In Proc. The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP2023) Findings, 2023.
- [505] Wenjun Hou, Kaishuai Xu, Yi Cheng, Wenjie Li, and Jiang Liu. Organ: Observation-guided radiology report generation via tree reasoning, 2023.
- [506] Yunsoo Kim, Jinge Wu, Yusuf Abdulle, and Honghan Wu. Medexqa: Medical question answering benchmark with multiple explanations, 2024.
- [507] Wei Zhu and Xiaoling Wang. Chatmed: A chinese medical large language model. https: //github.com/michael-wzhu/ChatMed, 2023.
- [508] Shaoting Zhang Xiaofan Zhang, Kui Xue. Pulse: Pretrained and unified language service engine. 2023.
- [509] Wei Luo and Dihong Gong. Pre-trained large language models for financial sentiment analysis, 2024.
- [510] Simerjot Kaur, Charese Smiley, Akshat Gupta, Joy Sain, Dongsheng Wang, Suchetha Siddagangappa, Toyin Aguda, and Sameena Shah. Refind: Relation extraction financial dataset. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23. ACM, 2023.
- [511] Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. Financebench: A new benchmark for financial question answering, 2023.
- [512] Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. Fingpt: Open-source financial large language models. arXiv preprint arXiv:2306.06031, 2023.
- [513] Wei Chen, Qiushi Wang, Zefei Long, Xianyin Zhang, Zhongtian Lu, Bingxuan Li, Siyuan Wang, Jiarong Xu, Xiang Bai, Xuanjing Huang, and Zhongyu Wei. Disc-finllm: A chinese financial large language model based on multiple experts fine-tuning. arXiv preprint arXiv:2310.15205, 2023.
- [514] Xuanyu Zhang and Qing Yang. Xuanyuan 2.0: A large chinese financial chat model with hundreds of billions parameters. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 4435–4439, 2023.
- [515] Shuai Wang, Weiwen Liu, Jingxuan Chen, Weinan Gan, Xingshan Zeng, Shuai Yu, Xinlong Hao, Kun Shao, Yasheng Wang, and Ruiming Tang. Gui agents with foundation models: A comprehensive survey. arXiv preprint arXiv:2411.04890, 2024.
- [516] Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [517] Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v(ision) is a generalist web agent, if grounded. In Forty-first International Conference on Machine Learning, 2024.
- [518] Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. arXiv preprint arXiv:2401.13919, 2024.
- [519] Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks?, 2024.
- [520] Revanth Gangi Reddy, Sagnik Mukherjee, Jeonghwan Kim, Zhenhailong Wang, Dilek Hakkani-Tur, and Heng Ji. Infogent: An agent-based framework for web information aggregation. arXiv preprint arXiv:2410.19054, 2024.
- [521] Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. Cogagent: A visual language model for gui agents, 2023.
- [522] Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Qi Zhang. UFO: A UI-Focused Agent for Windows OS Interaction. arXiv preprint arXiv:2402.07939, 2024.
- [523] Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Yifan Xu, Xixuan Song, Shudan Zhang, Hanyu Lai, Xinyi Liu, Hanlin Zhao, et al. Visualagentbench: Towards large multimodal models as visual foundation agents. arXiv preprint arXiv:2408.06327, 2024.
- [524] Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2404.07972, 2024.
- [525] Weihao Tan, Ziluo Ding, Wentao Zhang, Boyu Li, Bohan Zhou, Junpeng Yue, Haochong Xia, Jiechuan Jiang, Longtao Zheng, Xinrun Xu, et al. Towards general computer control: A multimodal agent for red dead redemption ii as a case study. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024.
- [526] Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024. [527] Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users, 2023.
- [528] Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, and Yunchao Wei. Appagent v2: Advanced agent for flexible mobile interactions. arXiv preprint arXiv:2408.11824, 2024.
- [529] Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent-v2: Mobile device operation assistant with effective navigation via multiagent collaboration. arXiv preprint arXiv:2406.01014, 2024.
- [530] Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, et al. Autoglm: Autonomous foundation agents for guis. arXiv preprint arXiv:2411.00820, 2024. [531] Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573, 2024.
- [532] Zhenhailong Wang, Haiyang Xu, Junyang Wang, Xi Zhang, Ming Yang, Ji Zhang, Fei Huang, and Heng Ji. Mobile-agent-e: Self-evolving mobile assistant for complex real-world tasks. In arxiv, 2025.
- [533] OpenAI. OpenAI Codex, 2021.
- [534] Jizhi Zhang, Keqin Bao, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. Is chatgpt fair for recommendation? evaluating fairness in large language model recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems, volume 2012 of RecSys ’23. ACM, 2023.
- [535] Luke Friedman, Sameer Ahuja, David Allen, Zhenning Tan, Hakim Sidahmed, Changbo Long, Jun Xie, Gabriel Schubiner, Ajay Patel, Harsh Lara, Brian Chu, Zexi Chen, and Manoj Tiwari. Leveraging large language models in conversational recommender systems, 2023.
- [536] Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. Llmrec: Large language models with graph augmentation for recommendation, 2024.
- [537] Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. Llara: Large language-recommendation assistant, 2024.
- [538] An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. On generative agents in recommendation, 2024.
- [539] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, and Rif A. Saurous. Tacotron: Towards end-to-end speech synthesis, 2017.
- [540] Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, and Nima Mesgarani. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models, 2023.
- [541] Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models, 2023.
- [542] Pete Warden. Speech commands: A dataset for limited-vocabulary speech recognition, 2018.
- [543] OpenAI. Whisper. https://github.com/openai/whisper, 2023.
- [544] OpenAI. Sora, 2024.
- [545] Wesley H Holliday, Matthew Mandelkern, and Cedegao E Zhang. Conditional and modal reasoning in large language models. arXiv preprint arXiv:2401.17169, 2024.
- [546] Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, Xiaolong Li, et al. Selfplaying adversarial language game enhances llm reasoning. Advances in Neural Information Processing Systems, 37:126515–126543, 2025.
- [547] Zifei Xu, Alexander Lan, Tristan Webb, Sayeh Sharify, Xin Wang, et al. Scaling laws for post-training quantized large language models. arXiv preprint arXiv:2410.12119, 2024.
- [548] Adam Ibrahim, Benjamin Thérien, Kshitij Gupta, Mats L Richter, Quentin Anthony, Timothée Lesort, Eugene Belilovsky, and Irina Rish. Simple and scalable strategies to continually pre-train large language models. arXiv preprint arXiv:2403.08763, 2024.
- [549] Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, et al. {MegaScale}: Scaling large language model training to more than 10,000 {GPUs}. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24), pages 745–760, 2024.
- [550] Adam Dahlgren Lindström, Leila Methnani, Lea Krause, Petter Ericson, Íñigo Martínez de Rituerto de Troya, Dimitri Coelho Mollo, and Roel Dobbe. Ai alignment through reinforcement learning from human feedback? contradictions and limitations. arXiv preprint arXiv:2406.18346, 2024.
- [551] Lichao Sun, Yue Huang, Haoran Wang, Siyuan Wu, Qihui Zhang, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, et al. Trustllm: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561, 3, 2024.
- [552] Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, et al. From system 1 to system 2: A survey of reasoning large language models. arXiv preprint arXiv:2502.17419, 2025.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)