【机器学习】决策树三兄弟:ID3、C4.5、CART 一篇搞懂
学决策树最容易卡在三个地方:熵(Entropy)到底在算什么?为什么“越乱越大”?信息增益(Information Gain)怎么就能选出“更好的特征”?基尼指数(Gini)为什么越小越好?和熵有什么区别?光看公式会头大,但一旦带着数字手算一遍就通了。ID3(信息增益)C4.5(增益率)CART(基尼指数)并且用“带数字的例子”把指标讲透。第二部分我会再写:Titanic 实战、CART 回归树、
0.引言
学决策树最容易卡在三个地方:
-
熵(Entropy)到底在算什么?为什么“越乱越大”?
-
信息增益(Information Gain)怎么就能选出“更好的特征”?
-
基尼指数(Gini)为什么越小越好?和熵有什么区别?
我的经验是:光看公式会头大,但一旦带着数字手算一遍就通了。
这篇文章我只聚焦三种经典决策树:
-
ID3(信息增益)
-
C4.5(增益率)
-
CART(基尼指数)
并且用“带数字的例子”把指标讲透。
(第二部分我会再写:Titanic 实战、CART 回归树、剪枝与防过拟合等。)
1. 决策树是什么?
决策树是一种树形结构模型:
-
内部节点:在某个特征上做判断(例如“是否有房?”)
-
分支:判断结果(有/无)
-
叶子节点:最终输出(分类标签或回归值)
决策树的建模流程通常是:
-
特征选择:选一个“最能让数据变纯”的特征做划分
-
树的生成:递归地继续划分子节点
-
剪枝:防止树太复杂导致过拟合
生活中的类比也很好理解:
比如“相亲决策树”,可能会按“年龄→长相→收入→是否公务员…”一步步筛选,本质也是在不断“缩小不确定性”。
训练一棵树的关键问题只有一个:
当前节点到底选哪个特征来划分,才能让数据变得更“纯”?
于是就出现了三套“衡量纯度/划分好坏”的标准:
-
ID3:信息增益(Entropy → Information Gain)
-
C4.5:增益率(Gain Ratio)
-
CART:基尼指数(Gini)
下面逐个讲清楚。
2. ID3 决策树:信息熵 & 信息增益
2.1 信息熵:为什么“越乱越大”?
信息熵衡量不确定性/混乱程度:
-
类别分布越平均 → 越不确定 → 熵越大
-
类别越集中(几乎都是同一类)→ 越确定 → 熵越小
公式(了解含义即可):
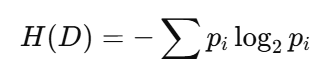
说明:log 的底数取 2(bit)或 e(nat)都可以,只是数值尺度不同,比较大小、选特征的结论不变。
例子1:α 与 β 谁更“乱”?
-
数据 α:
ABCDEFGH(8 种符号,每个概率 1/8)
![]()
-
数据 β:
AAAABBCD
A=1/2,B=1/4,C=1/8,D=1/8
![]()
✅ 结论:α 更乱(熵更大),β 更集中(熵更小)。
例子2:三分类分布的“纯度直觉”
-
例子2-1:假如数据集有三个类别,分别占比为:{⅓, ⅓, ⅓},
-
信息熵:很均匀 → 熵大
-
用 ln:1.0986
-
用 log2:1.585 bit
-
-
栗子2-2:假如数据集有三个类别,分别占比为:{1/10, 2/10, 7/10},
-
信息熵:更集中 → 熵更小
-
用 ln:0.8018
-
用 log2:1.1568 bit
-
-
栗子2-3:假如数据集有三个类别,分别占比为:{1, 0, 0},
-
信息熵::完全纯 → 熵=0
2.2 信息增益:ID3 怎么选“最优特征”?
信息增益的定义:
划分前的熵 − 划分后的条件熵(加权平均)
![]()
其中条件熵:
![]()
例子:6 条样本手算信息增益(强烈建议看懂这一段)
有 6 个样本,目标值只有 A/B 两类:
| 样本 | 特征 a | 目标值 |
|---|---|---|
| 1 | α | A |
| 2 | α | A |
| 3 | β | B |
| 4 | α | A |
| 5 | β | B |
| 6 | α | B |
(1) 先算整体熵 H(D)
整体:3A、3B
![]()
(2) 按特征 a 划分后:算各子集熵
-
a=α:4 条样本目标值是
AAAB(3A,1B)
![]()
-
a=β:2 条样本目标值是
BB(纯)
![]()
(3) 条件熵 H(D|a):加权平均
![]()
(4) 信息增益
Gain(D,a)=1−0.54=0.46Gain(D,a)=1-0.54=0.46Gain(D,a)=1−0.54=0.46
✅ 结论:特征 a 的信息增益是 0.46,说明它让数据“不确定性减少很多”,值得优先用来分裂。
2.3 ID3 的建树流程
-
计算当前节点所有特征的信息增益
-
选择信息增益最大的特征作为划分特征
-
按该特征取值生成子节点
-
在子节点上重复 1~3,直到满足停止条件
2.4 ID3 的缺点(也是 C4.5 出现的原因)
ID3 有一个非常典型的问题:
偏爱“取值很多”的特征(比如用户ID、订单号这类几乎每条都不同的字段)
因为取值多容易把数据切得很碎,看起来很“纯”,但实际上容易过拟合。
3. C4.5 决策树:增益率(专治 ID3 多值偏好)
C4.5 的核心思想:
用 增益率 替代信息增益:对“取值多”的特征加惩罚。
3.1 增益率公式(记住“除以惩罚项”即可)
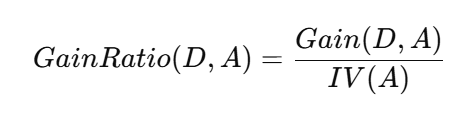
其中 IV(A)IV(A)IV(A)(固有值/特征熵):
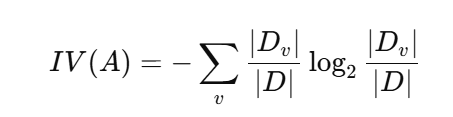
直觉理解:
-
如果一个特征把数据切得很碎(分支很多)→ IV 大 → 除完后增益率会被压下去
-
分支少、但切得有效 → 增益率更容易高
3.2 例子:特征 a 只有 2 个取值,特征 b 有 6 个取值,该选谁?
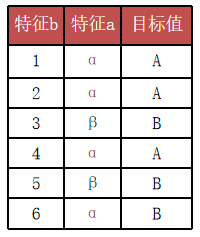
还是同样 6 条样本:
-
特征 a:2 个取值(α/β)
-
特征 b:6 个取值(1~6,每条样本一个值)
特征 a:
-
信息增益:0.46(上一节已经算过)
-
固有值:
![]()
-
增益率:
![]()
特征 b:
-
信息增益:≈1(因为每条都被单独分开,子节点几乎全纯)
-
固有值:
![]()
-
增益率:
![]()
✅ 结论:C4.5 选择 a(0.50 > 0.39),从而避免了 ID3 盲目选择“取值多”的 b。
决策树
4. CART 决策树:基尼指数(分类常用)
CART(Classification And Regression Tree)非常常见。
这里第一部分只讲它在分类场景下的核心:基尼指数最小化。(回归树我放到第二部分详细讲。)
4.1 基尼指数:怎么理解“越小越纯”?
基尼指数:
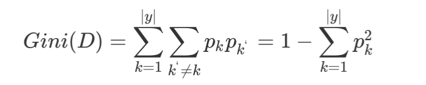
直觉理解:
从节点中随机抽 2 个样本,它们类别不同的概率。
越小表示越不容易抽到不同类别 → 越纯。
CART 的特征选择标准:
选择使“划分后加权 Gini 最小”的特征/切分点
4.2 例子:是否有房(手算 Gini)
假设“是否拖欠贷款”是目标(yes/no),现在计算特征“是否有房”划分的效果:
-
有房:3 个样本,全是 no(3no, 0yes)
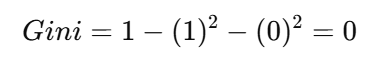
-
无房:7 个样本,4no, 3yes
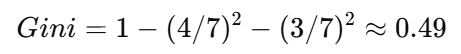
加权后的划分基尼:
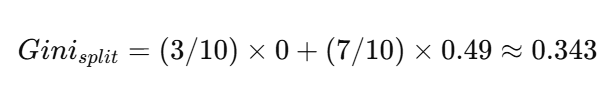
✅ 结论:这个划分的 Gini ≈ 0.343。
4.3 例子:婚姻状况的二叉切分(CART 的经典特点)
CART 对多值特征通常做二叉切分(把类别分成两组),比如:
-
{married} vs {single, divorced}
假设:
-
married:4 个样本,全是 no → Gini=0
-
非 married:6 个样本,3no 3yes →
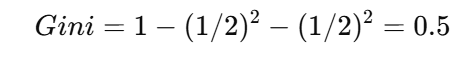
加权:
![]()
✅ 结论:0.3 < 0.343,说明“婚姻状况这样二分”比“是否有房”更好。
决策树
4.4 连续特征怎么切?(年收入)
连续变量(年收入)在 CART 的处理方式很固定:
-
对收入排序
-
取相邻值的中点当候选阈值(如:65、72.5、80、…、97.5…)
-
对每个候选阈值都算一遍划分后的 Gini
-
选 Gini 最小 的阈值作为最优切分点
课件示例中,年收入候选点中能得到最小 Gini(如 0.3),对应阈值例如 97.5 等。
决策树
5. ID3 / C4.5 / CART 总结对比
| 算法 | 核心指标 | 选择规则 | 分支方式 | 典型特点 |
|---|---|---|---|---|
| ID3 | 信息增益 | 越大越好 | 多叉 | 简单直观,但偏爱取值多特征 |
| C4.5 | 增益率 | 越大越好 | 多叉 | 用惩罚项修正 ID3 的多值偏好 |
| CART | 基尼指数 | 越小越好 | 二叉 | 工程常见;对类别特征常二分组合,对连续特征找阈值 |
6. 小结(以及第二部分预告)
这一部分我把三兄弟的“核心指标”用例子讲清楚了:
-
熵:衡量乱不乱
-
信息增益:划分后减少了多少不确定性(ID3)
-
增益率:信息增益 ÷ 惩罚项(C4.5)
-
基尼指数:不纯度,越小越纯(CART)
第二部分我会继续写:
Titanic 生存预测实战、CART 回归树(平方误差)、剪枝(预剪枝/后剪枝)与过拟合(这些我就不在本文展开了)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)