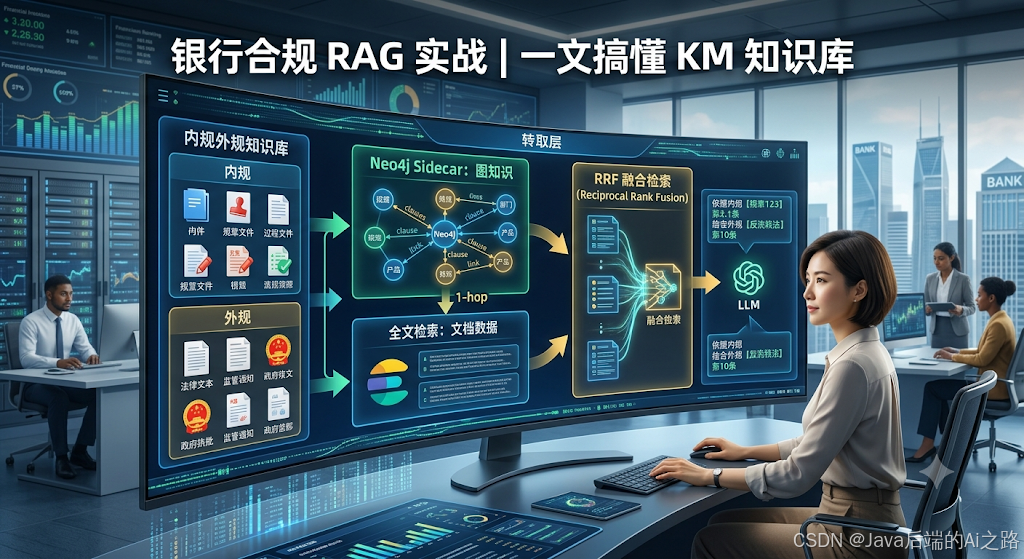
【银行合规 RAG 实战】一文搞懂 KM 知识库:内规外规、1-hop、Neo4j 侧车、RRF 融合检索
【银行合规 RAG 实战】一文搞懂 KM 知识库:内规外规、1-hop、Neo4j 侧车、RRF 融合检索
文章目录
前言:为什么你的合规知识库「能搜到,但说不清」?
做过银行合规 / 监管科技项目的同学,大概率踩过这个坑:
向量检索明明命中了《反洗钱管理办法》,却漏掉了外规里点名引用的《客户尽职调查实施细则》——
不是文档没入库,是**「谁引用谁、谁约束谁」这条链,系统里根本没有**。
我们团队在做 AI 合规审查平台 的 KM(Knowledge Management)模块演进时,从「能存能搜」走向「能连能溯」,中间一堆术语——内规外规、Phase 1、1-hop、Neo4j 侧车、RRF——把产品和开发都绕晕了。
这篇文章用一个真实项目的演进路径,把这些概念一次讲透。不讲空理论,直接对照代码和架构决策。
一、KM 是什么?——不是临时 RAG 文件夹
KM = Knowledge Management(知识管理模块),在本项目里是合规知识的正式资产层:
建库 → 上传 PDF/DOCX → 异步解析切块 → 向量化 → 混合检索
| 存储 | 职责 |
|---|---|
| PostgreSQL | 库 / 文档 / 知识 / 版本 / 元数据 |
| MinIO | 原文 PDF、DOCX |
| Milvus | 语义切块 + embedding(km_chunks) |
API 挂载在 /api/v1/km/*,和业务场景(002 监管对标、005 制度比对)通过 library_ids 绑定要查哪些库。
和 infrastructure.rag 的区别:
- KM:有 UI、有生命周期(
draft → published → offline)、长期沉淀 - RAG 基础设施:只管某个 Milvus collection 的 ingest + retrieve,适合临时文件
💡 一句话:需要「合规人员日常维护的知识库」→ 走 KM;场景里临时扔几份 docx 做一次性检索 → 走 infrastructure.rag。
二、为啥要分内规和外规?——不是爱折腾,是法律效力不同
KM 用 kb_scope 三分法:
KB_SCOPE_INTERNAL = "internal" # 内规
KB_SCOPE_EXTERNAL = "external" # 外规/监管
KB_SCOPE_BUSINESS = "business" # 业务知识/案例
| 外规 | 内规 | |
|---|---|---|
| 谁定 | 法律、监管规章 | 本行制度、细则 |
| 问什么 | 监管要求什么? | 我们行怎么做、怎么查? |
| 违反后果 | 行政处罚、刑事责任 | 内部问责 + 监管穿透 |
大白话:外规是交通法规,内规是公司《员工用车管理办法》——图书馆不会把宪法和公司手册塞同一格。
合规链条(图谱要连的那条「纲」):
外规(要求) → 内规(落实) → 检查点(可验证)
《吕氏春秋》讲 「纲举目张」——外规到内规的引用链是「纲」,Milvus 里散落的 chunk 是「目」。没有纲,目再多也是碎页。
三、三维度理解 KM:存 · 找 · 连
| 维度 | 关键词 | 现状 | 典故 |
|---|---|---|---|
| 怎么存 | PG + MinIO + Milvus | ✅ 已有 | 《永乐大典》分册典藏 |
| 怎么找 | 关键词 + 向量 | ✅ 已有 | 按图索骥 |
| 怎么连 | 引用/约束关系网 | ❌ Phase 1 待建 | 纲举目张 |
今天的缺口:解析管线已经抽出了 cross_references、条款 references,但关系散落在 JSON 里,没持久化。搜得到相似段落,答不了「这条内规依据哪条外规」。
四、Phase 1 是啥?——先拿 PG 验证,别急着上 Neo4j
分期演进,不推翻现有 KM:
| 阶段 | 做什么 | Neo4j |
|---|---|---|
| Phase 0 | 需求对齐、OpenSpec、画关系图 | 不部署 |
| Phase 1 | PG km_relation 边表 + 规则抽取 + 检索 1-hop |
不上 |
| Phase 2 | Neo4j 侧车 + 三通道检索 + RRF | 启用 |
| Phase 3 | 多跳、可视化、场景深度集成 | 增强 |
Phase 1 交付清单
- 存关系:PG 表
km_relation(CITES / SUPERSEDES / REQUIRES) - 抽关系:正则匹配「依据《××办法》」等,publish 后自动入库
- 扩检索:
expand_relations=true做 1-hop 扩展 - 验价值:002 监管对标 PoC,hit@5 目标提升 ≥ 15%
Phase 1 刻意不做
- ❌ 部署 Neo4j
- ❌ LLM 全量建图
- ❌ 前端图谱可视化
- ❌ 多跳 Cypher
设计哲学:先拿绳子把书串起来,别急着建整座地图馆。
五、1-hop 是啥?——关系网上只扩一圈
hop = 在关系图里走几步边
外规 A ──CITES──→ 内规 B ──CITES──→ 内规 C
| 深度 | 搜到 A 时能看到 |
|---|---|
| 0-hop(默认) | 只有 A 自己的 chunk |
| 1-hop | A + 直接引用的 B |
| 2-hop | A + B + C(B 引用的) |
Phase 1 的 expand_relations 就是 1-hop:
向量命中 knowledge A
→ 查 km_relation:A 有没有 CITES 边指向 B、C
→ 把 B、C 的 title + excerpt 拼进 A 的检索上下文
→ 前缀标记 [关联],下游 SKILL schema 不变
为啥只做 1-hop?
- PG 一条
WHERE source_knowledge_id = A就够,实现轻 - 避免关系爆炸(2-hop 可能从 10 条边炸到 100 条)
- 002 场景里「外规点名内规」往往是直接引用,1-hop 够用
大白话:搜到一本书,顺带把参考文献的封面摘要贴过来;参考文献的参考文献?那是 Phase 2 的事。
六、Neo4j 侧车是啥?——边斗模式,不是换引擎
侧车(Sidecar) = 在现有 KM 主链路旁边挂一个专门管关系的存储,不替换 PG / MinIO / Milvus。
KnowledgeService.publish()
├── KmIndexer → Milvus 向量索引 (主车)
└── GraphIngest → Neo4j 图谱写入 (侧车)
侧车三原则
-
并行写入,主流程不阻塞
Milvus 成功、Neo4j 失败 → 文档仍可发布,后台 Celery 重试 -
检索多一路,不替代原路
向量只在 Milvus;Neo4j 不双写 embedding,只管结构边 -
可开关
KM_GRAPH_NEO4J_ENABLED=false时 no-op,KM 照常跑
src/infrastructure/
├── rag/ # Milvus(已有)
└── neo4j/ # 图侧车(Phase 2)
├── client.py
├── ingest.py
└── retriever.py
30 秒版:Neo4j 是「关系地图馆」,KM 是「合规图书馆」——主馆找段落,侧馆追引用链。
七、RRF 是啥?——多路检索的「排名投票器」
RRF = Reciprocal Rank Fusion(倒数排名融合)
问题:两路分数没法直接比
| 通道 | 分数示例 | 量纲 |
|---|---|---|
| 向量语义 | 0.82 | 相似度 0~1 |
| BM25 关键词 | 12.5 | 另一套 |
不能直接加权平均。
RRF 思路:不看分数,看排名
对排名第 rank(从 0 开始)的结果:
RRF分 += 1 / (k + rank + 1) # 项目里 k = 60
同一条结果在语义榜第 2、关键词榜第 5 → 两边 RRF 分相加,越高越靠前。
手算例子
搜「客户尽职调查」:
| 排名 | 语义 | BM25 |
|---|---|---|
| 1 | 文档 A | 文档 B |
| 2 | 文档 B | 文档 A |
- 文档 A:语义第 1 + 关键词第 2 → 两路都靠前 → 综合第一
- 文档 C:只在语义榜 → 一路分 → 靠后
直觉:两路都认的结果,最靠谱。
RRF(RAG检索优化三要素:Recall召回 + Rank排序 + Filter过滤)三维度完整大纲
每一模块统一结构:专业定义 + 大白话解释 + 生活案例 + 古代典故诠释
维度一:Recall 召回(粗筛)
1.专业解释
向量库/全文索引中,基于用户问题做初步批量检索,从海量文档里快速捞出一批候选文本。目标是高召回率,宁可多捞,不能漏掉有用信息,属于大范围粗筛选。
2.大白话
先大面积撒网,把所有沾边的资料全部找出来,保证有用内容不会被漏掉,暂时不考虑垃圾内容。
3.生活案例
在图书馆查找历史资料,先把所有带“三国”关键词的书籍一次性全部借出来,先保证相关书籍一本不落,暂时不区分内容好坏。
4.典故诠释:广收博采(萧何收秦典籍)
刘邦攻入咸阳,众人争抢金银财宝,唯独萧何第一时间把秦朝天下律令、户籍、地理档案全部收藏。
思想内核:Recall不求精简,只求全覆盖。先把全部潜在有用素材尽数收拢,避免关键资料遗失,为后续筛选打下基础。
维度二:Rank 排序(精排)
1.专业解释
对召回得到的候选片段做相关性打分,依据语义相似度、上下文匹配度重新调整先后顺序,把最贴合用户提问的内容排在最前面,压低无关内容优先级。
2.大白话
渔网捞上来一堆鱼之后,按照个头大小、新鲜程度重新排队,最符合需求的放到首位。
3.生活案例
拿到几十本三国书籍后,逐一翻看内容,把专门讲赤壁之战的书本排到最前面,人物传记放到后面,无关杂书继续往后挪。
4.典故诠释:量材而授官(诸葛亮选贤排等)
诸葛亮治理西蜀,广揽人才之后,再依据才干高低划分等级,把懂军政的重臣置于决策前排,普通官吏位列其后。
思想内核:完成粗召回之后,再依据匹配度分出先后次序,让最匹配上下文的信息优先被大模型读取。
维度三:Filter 过滤(降噪)
1.专业解释
对排序后的结果做截断与清洗,剔除重复内容、冗余文本、低质量噪声片段,控制上下文长度,只保留高价值信息,防止无关内容干扰大模型输出。
2.大白话
排好队之后,把杂鱼、水草、重复的垃圾全部丢掉,只留下几条核心大鱼,精简素材总量。
3.生活案例
排好书籍顺序后,删掉内容重复的小册子,剔除野史谣言,只保留正史原文,精简到三五本核心资料再开始阅读。
4.典故诠释:删繁就简(孔子删诗书)
上古史料浩如烟海,孔子广泛收集文献之后,删减虚妄、重复、冗余篇章,最终整理出精简版《诗经》《尚书》。
思想内核:召回求全、排序求准、过滤求精,砍掉噪声冗余,避免上下文被无效信息污染。
整套RRF流程典故总结
- Recall(萧何收秦图籍):广搜集,不漏关键材料;
- Rank(孔明铨选官吏):排次序,优先匹配内容;
- Filter(孔子删定六经):去糟粕,精简上下文噪声。
整体思想:先撒网、再排队、最后除杂草,这就是RAG检索链路RRF三层核心逻辑。
需要我把这段整理成考试简答题精简版吗?
项目里的真实状态(踩坑预警 ⚠️)
基础设施层 HybridRetriever — 有真 RRF:
# src/infrastructure/rag/retrieval/retriever.py
_RRF_K = 60
class HybridRetriever:
"""Semantic + BM25 hybrid retrieval ...
Uses Reciprocal Rank Fusion (RRF) to merge semantic and keyword scores.
"""
KM 的 SearchService — 目前不是真 RRF:
PG hits + vector hits 拼接去重,PG 固定 0.5 分;PG 先命中还会压制向量分。
Phase 2 规划三路 RRF:
PG 关键词 ──┐
Milvus 向量 ──┼──→ RRF 融合 ──→ 最终结果
Neo4j 图检索 ──┘
大白话:两个评委打分体系不同,RRF 说——别管具体多少分,看各自排名第几,两边都靠前的赢。
八、全链路串起来:一次 002 监管对标检索
Phase 1 今天能做的事:
- 向量搜相似内规 ✅
- 沿 CITES 1-hop 拉回「被外规点名」的内规 ✅(新能力)
- 三路 RRF + Neo4j 多跳 ⏳ Phase 2
九、给架构师的决策备忘
| 问题 | 建议 |
|---|---|
| 第一期要不要上 Neo4j? | 不要,PG 边表先验证 |
| 关系怎么抽? | 规则优先(「依据/参照/按照《》」),LLM 辅助可选 |
| 检索怎么扩? | 1-hop CITES,默认关闭保兼容 |
| 向量还要不要? | 要,图谱是叠加层,不替代 Milvus |
| 业务场景怎么绑库? | library_ids 硬绑,别只靠 kb_scope |
十、总结:一张表带走
| 术语 | 人话 | 阶段 |
|---|---|---|
| KM | 合规知识库正式资产层 | 已有 |
| 内规/外规 | 监管定的 vs 本行落地的 | 已有 |
| Phase 1 | PG 存关系 + 规则抽取 + 1-hop | 首批交付 |
| 1-hop | 关系网只扩一圈邻居 | Phase 1 |
| Neo4j 侧车 | 图库伴跑,不替主存储 | Phase 2 |
| RRF | 多路检索按排名融合 | HybridRetriever 已有;KM 三路 Phase 2 |
口语收尾版:
咱们 KM 已经能把合规文档存好、切好、搜到相似片段——这是「永乐大典」加「按图索骥」。
缺的是「纲举目张」那条纲。Phase 1 用 PG 先把绳结打上;Phase 2 Neo4j 侧车 + RRF 三路融合,才是完整版图。
如果这篇文章对你有帮助,欢迎 👍 点赞 · ⭐ 收藏 · 💬 评论区交流
你在做 RAG / 知识图谱 / 合规场景时,遇到过「向量搜到了但引用链断了」的情况吗?评论区聊聊你的解法。
转载声明:本文为原创文章,如需转载,请联系作者获得授权,并注明出处。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)