Apache Doris Python UDF:让 SQL 直接调用 Python 生态,支撑 Agent 时代复杂业务逻辑
随着 AI 应用和实时分析场景深入,进入数据平台的不再只是结构化业务表。日志、JSON、文本内容、行为事件、模型推理结果等半结构化和非结构化数据,正在成为实时分析的常见对象。
与此同时,分析链路中要完成的工作也在变化:它不再只是 COUNT、SUM、GROUP BY,还包括规则判断、字段解析、特征加工、标签抽取、模型打分等更复杂的业务逻辑。
这些逻辑往往更适合用 Python 实现。但如果把数据导出到外部脚本或服务中处理,就会带来链路拉长、时效下降、排查困难和治理复杂等问题。
Doris Python UDF 要解决的正是这个割裂:让开发者可以在 SQL 中创建并调用 Python 函数,将 Pandas、PyArrow 等 Python 生态能力引入 Doris 查询链路,在数据不离开分析链路的前提下完成更复杂的数据处理和业务计算。
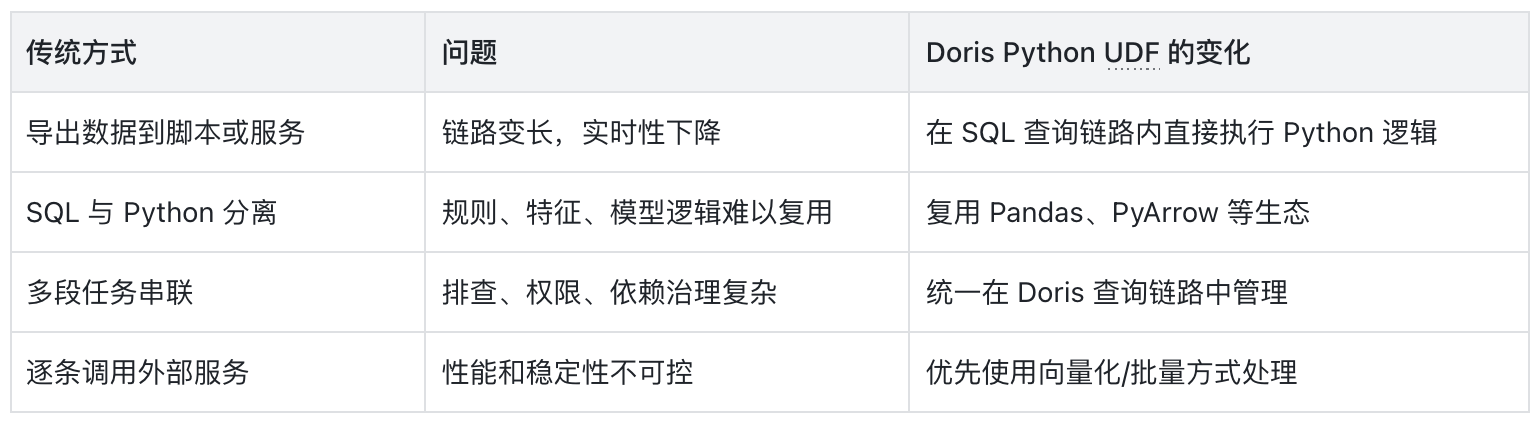
SelectDB 也已将这一能力纳入商业化产品体系,面向企业生产环境提供更完整的运维、稳定性、安全合规和技术支持能力。
像调用 SQL 函数一样调用 Python UDF
使用 Doris Python UDF 的心智模型非常简单:准备 Python 环境,声明函数,然后在 SQL 中直接调用。
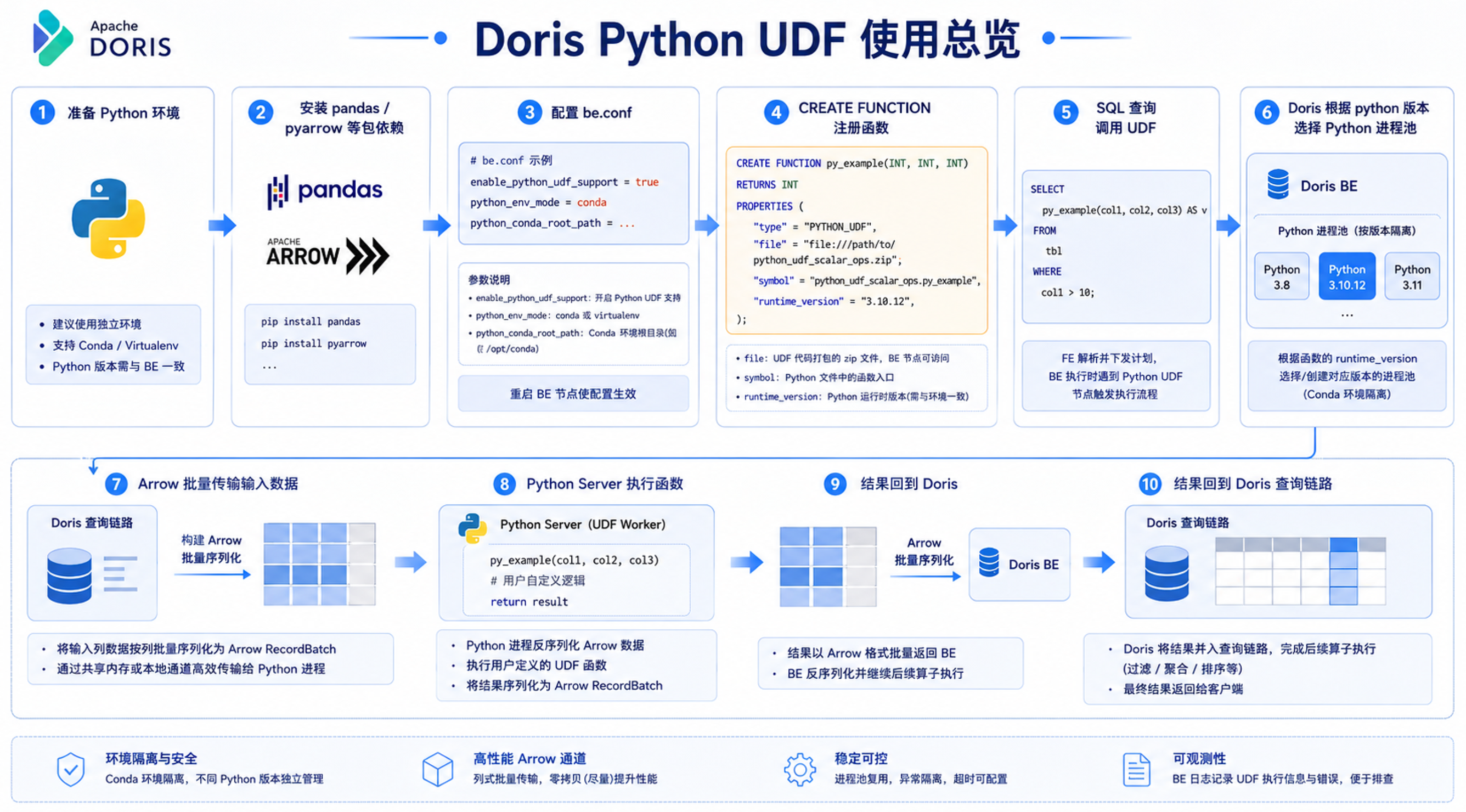
前置条件:在创建 Python UDF/UDAF/UDTF 前,需要在所有 BE 节点开启 Python UDF 相关配置,并在目标 Python 环境中安装 pandas 与 pyarrow。Python UDF Server 日志可在 output/be/log/python_udf_output.log 中查看。
下面以支付金额风险等级评估为例,创建一个 Python UDF:
DROP FUNCTION IF EXISTS py_risk_level(DOUBLE);
CREATE FUNCTION py_risk_level(DOUBLE)
RETURNS STRING
PROPERTIES (
"type" = "PYTHON_UDF",
"symbol" = "evaluate",
"runtime_version" = "3.12.11",
"always_nullable" = "true",
"volatility" = "immutable"
)
AS $$
def evaluate(amount):
if amount is None:
return None
if amount >= 10000:
return "high"
if amount >= 1000:
return "medium"
return "low"
$$;
创建完成后,该函数即可像 Doris 内置函数一样使用:
SELECT
user_id,
amount,
py_risk_level(amount) AS risk_level
FROM payment_events
WHERE dt = '2026-06-17'
ORDER BY user_id;
开发者可以把已有 Python 逻辑直接嵌入 SQL 查询链路,在 Doris 内完成数据处理、规则判断和特征加工。
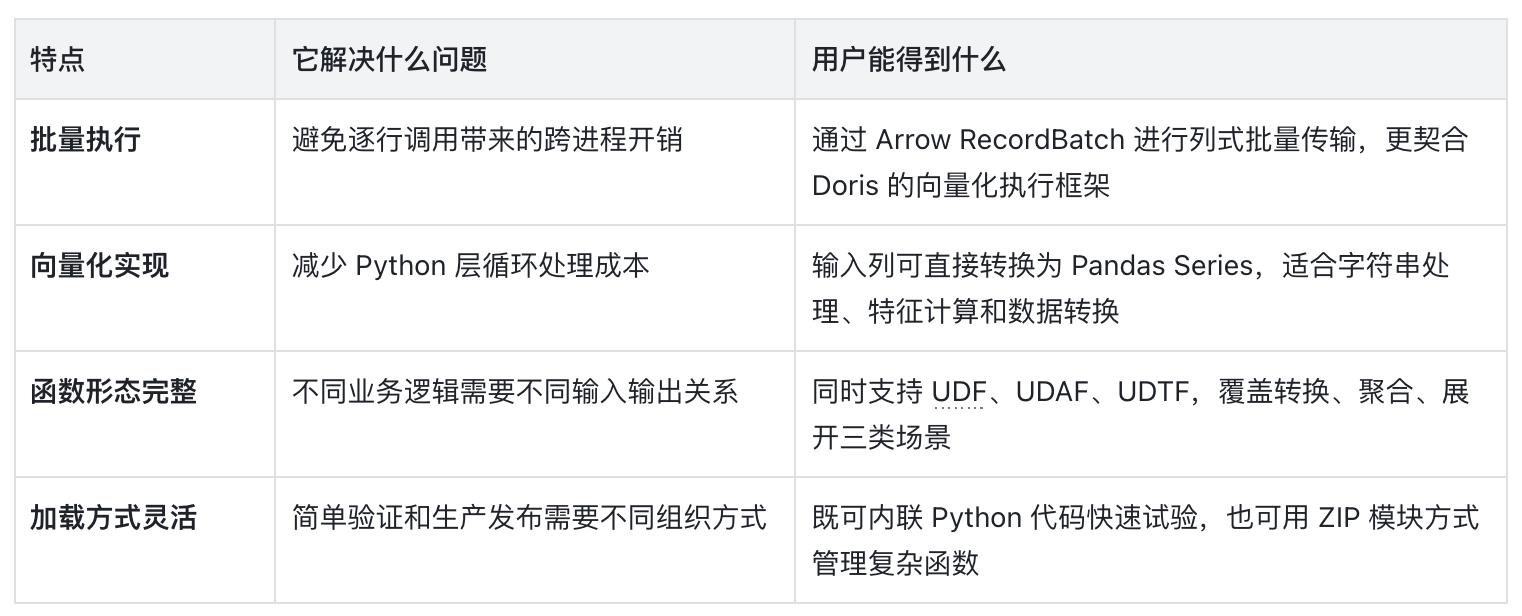
Python UDF 核心特点
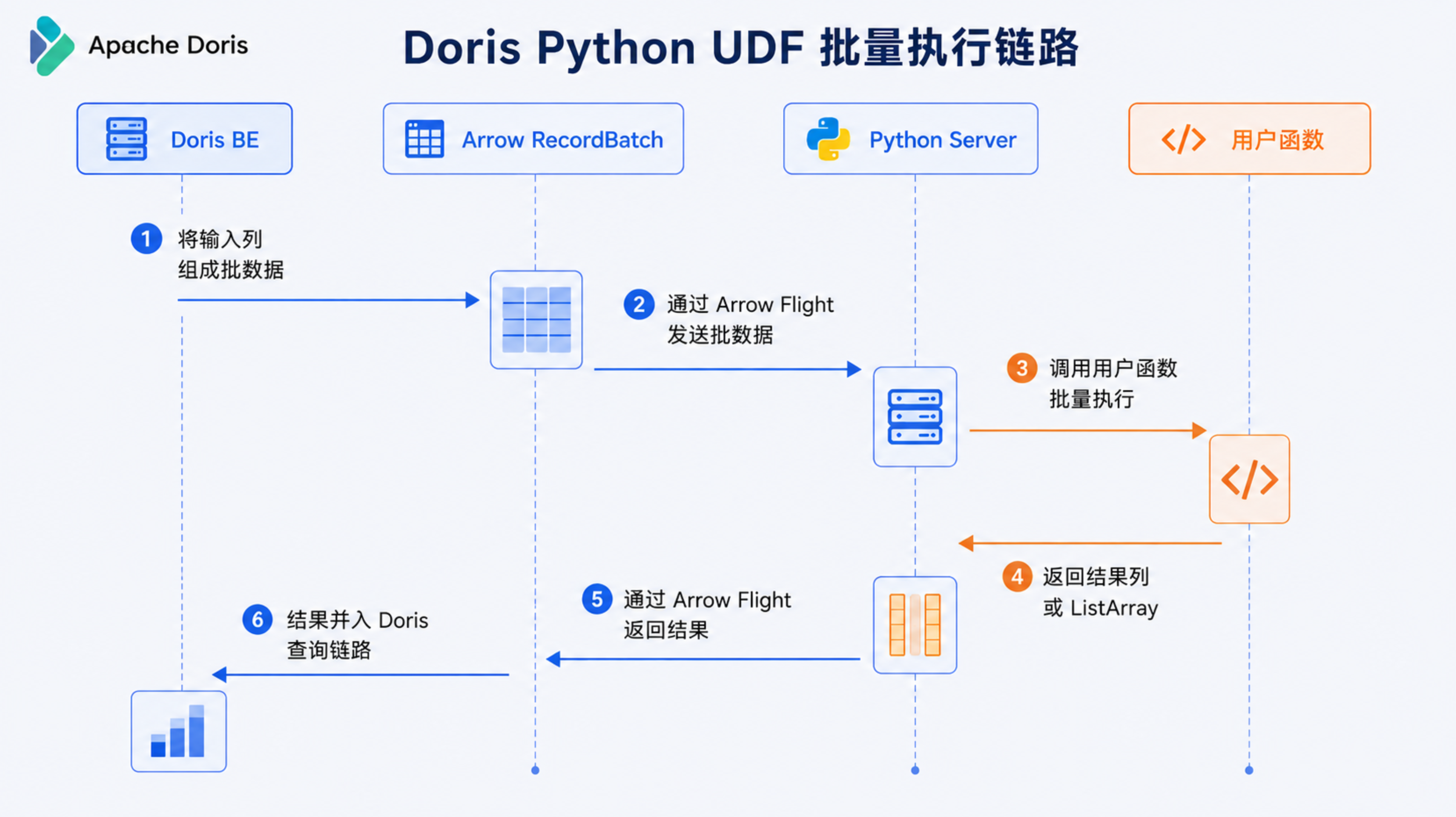
基于 Arrow RecordBatch 的批量执行
Python UDF 既要具备 Python 的灵活性,也需要尽可能降低跨语言、跨进程调用带来的额外开销。
Doris Python UDF 采用列式批量处理机制。执行过程中,Doris BE 会将输入数据组织为 Arrow RecordBatch,并通过 Arrow Flight 高效传输至独立的 Python Server。Python 函数完成批量计算后,结果再以列式数据形式返回 Doris 查询链路。
这种方式避免了传统逐行调用造成的频繁进程切换和序列化开销,使 Python 扩展能力能够与 Doris 的列式执行框架保持一致,在支持复杂业务逻辑的同时,尽可能保持查询执行效率。
支持 Pandas Series 向量化计算
对于字符串处理、特征计算、字段转换、分桶映射等列式处理场景,Python UDF 支持基于 Pandas Series 的向量化实现。
例如,可以使用 Pandas 对金额进行分桶:
CREATE FUNCTION py_amount_bucket(DOUBLE)
RETURNS INT
PROPERTIES (
"type" = "PYTHON_UDF",
"symbol" = "evaluate",
"runtime_version" = "3.10.12",
"always_nullable" = "true",
"volatility" = "immutable"
)
AS $$
import pandas as pd
# 显式声明pd.Series类型,使用向量化实现
def evaluate(amount: pd.Series) -> pd.Series:
return pd.cut(
amount,
bins=[-float("inf"), 100, 1000, 10000, float("inf")],
labels=[0, 1, 2, 3]
).astype("Int64")
$$;
相比在 Python 中逐行循环处理,向量化计算可以更好利用 Pandas 底层能力,减少解释器循环开销,适合大批量数据转换和特征加工场景。
完整支持 UDF、UDAF、UDTF
Doris Python 扩展能力覆盖三类函数形态:
同一套 Python 扩展框架能够覆盖标量计算、聚合计算和展开型处理,降低不同业务逻辑接入 Doris 的复杂度。
支持内联与模块化加载
Doris Python UDF 支持灵活的代码组织方式。
方式一:内联方式。对于简单函数,可以直接将 Python 代码写在 CREATE FUNCTION 语句中,适合快速验证和小规模试验:
CREATE FUNCTION py_add_one(INT)
RETURNS INT
PROPERTIES (
"type" = "PYTHON_UDF",
"symbol" = "evaluate",
"runtime_version" = "3.10.12",
"volatility" = "immutable"
)
AS $$
def evaluate(x):
return None if x is None else x + 1
$$;
方式二:模块方式。对于复杂函数,可以将 Python 代码打成 ZIP 包,并通过 file 与 symbol 指定模块入口:
CREATE FUNCTION py_add_one(INT)
RETURNS INT
PROPERTIES (
"type" = "PYTHON_UDF",
"file" = "file:///opt/doris/udf/math_ops.zip",
"symbol" = "math_ops.add_one",
"runtime_version" = "3.10.12",
"volatility" = "immutable"
);
这种方式更适合团队协作、代码评审、依赖管理和版本发布,也便于将生产级 Python 逻辑稳定接入 Doris。
面向生产环境的隔离、复用与自愈
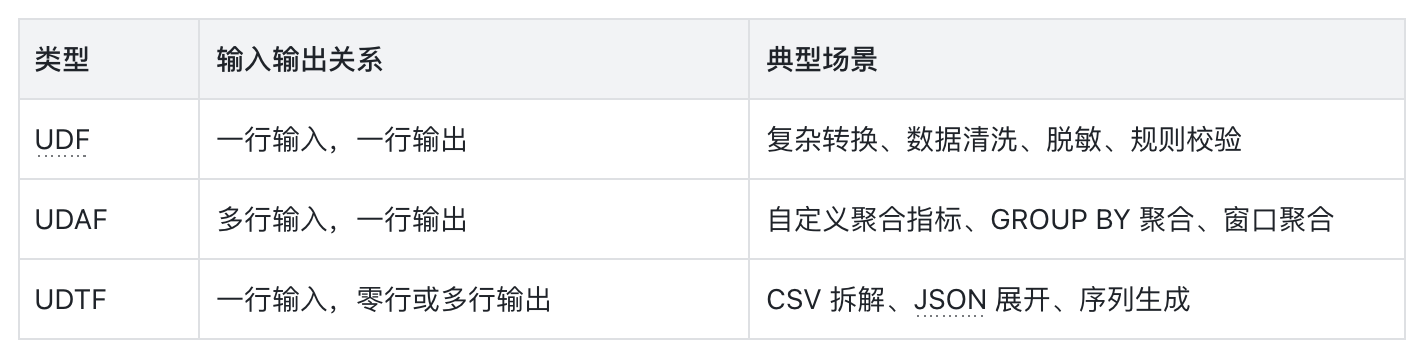
Python UDF 的重点不只是把 Python 跑起来,而是让它以可隔离、可复用、可恢复的方式进入生产查询链路。
关键机制设计及收益介绍:
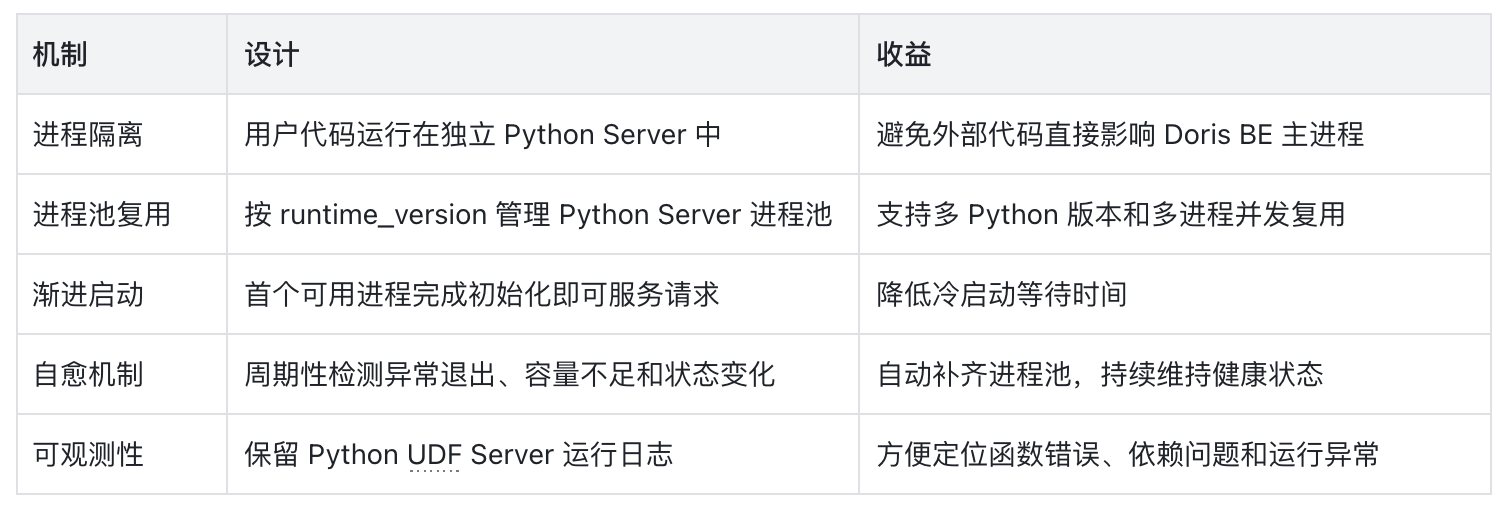
用户感知:对业务开发者来说,Python UDF 仍然只是一次普通 SQL 调用;进程管理、资源复用和故障恢复由 Doris 在底层自动完成。
适用场景:从复杂数据处理到 AI 分析
Doris Python UDF 可以应用于多类业务场景。具体如下。

这使得 Doris 不仅能够完成传统实时分析中的统计计算,也能够更自然地承接 AI 应用和复杂业务逻辑。
结束语
Doris Python UDF 提供的不只是一个函数扩展机制,而是一条连接 Doris 高性能分析能力与 Python 生态的通道。
当规则判断、文本处理、特征加工和模型打分可以直接嵌入 SQL 查询链路,开发者就不必为了复用 Python 生态而拆分实时分析流程。数据留在 Doris 内,复杂逻辑也能更自然地进入分析链路。
对于希望在生产环境中稳定使用这一能力的企业用户,SelectDB也已经提供对 Python、 UDF/UDAF/UDTF 的支持,并结合企业级运维、稳定版本、安全合规和技术支持能力,帮助用户更高效地将复杂 Python 逻辑接入实时分析与 AI 分析场景。
未来,随着更多 AI 能力进入数据分析链路,Python UDF 的意义在于:在保留 Doris 高性能 SQL 分析能力的同时,把 Python 生态的灵活性引入到生产查询中,让新的业务逻辑更快被验证、复用和上线。
特别鸣谢来自字节跳动的 @WencongLiu 和来自腾讯的 @sjyango 两位同学,感谢他们在社区 Python UDF 功能开发中的合作与贡献。也欢迎更多对 Doris 感兴趣的朋友积极参与社区建设,共同推动 Doris 生态持续发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)