QDKT6-2AI 知识空间类产品拆解 & 功能实现反推 & 优化建议
企业协作、多团队共享知识库。高(可关闭企业知识)中等(有重复/漏检)个人学习、小型资料库。
·
二、基础概念铺垫
- 知识库问答应用:基于已有文档、消息等资料,通过AI技术实现“提问-检索-回答”的工具,比如腾讯文档AI、飞书问答等,核心是“让AI读懂你的资料并解答问题”。
- 检索逻辑:AI查找资料的方式,主要分为两种——
- 关键词检索:像传统搜索一样,通过提取问题中的关键词(如“AI面试”)匹配资料,速度快但不够智能;
- 语义检索(基于Embedding):把问题和资料都转换成计算机能理解的“语义向量”,即使表述不同(如“什么是agent”和“agent的定义”)也能匹配,更智能但技术要求高。
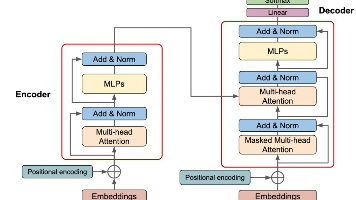
- RAG技术:全称“检索增强生成”,是知识库问答的核心技术,简单说就是“先检索相关资料,再让AI结合资料生成回答”,避免AI瞎编,确保答案有依据。
三、主流知识库产品实战体验
(一)腾讯文档AI
1. 核心功能
- 基于文档/空间的问答:可创建“空间”并导入文档,AI会检索空间内资料回答问题;
- 检索范围:默认检索全部文档,支持切换资料来源,但无法关闭“使用文档”权限(必须基于资料问答,不能单独用AI)。
2. 操作步骤(跟着做就行)
- 打开腾讯文档,创建新“空间”(比如命名“学习资料库”);
- 向空间导入文档(支持PDF、腾讯文档副本等,注意:导入后外部人员无法查看原文档);
- 点击空间内的“AI”按钮,输入问题(如“文档中有关于AI面试的内容吗?”);
- 等待AI检索,查看回答及引用的资料来源。
3. 优缺点
- 优点:导入文档后检索速度快,支持语义检索(比如用英文问“what's an agent”也能匹配中文资料);
- 缺点:产品成熟度低,检索结果有重复、漏检情况;权限设置不灵活,必须绑定文档,不能单独使用AI。
(二)飞书问答
1. 核心功能
- 多维度检索范围:可选择“仅用AI(豆包)”“使用企业知识”,支持筛选是否包含文档、消息、服务台内容等;
- 知识库管理:支持创建多个知识库,可设置分享权限(公开/兑换码),信息安全控制更完善。
2. 操作步骤
- 打开飞书,进入“知识库”模块(或通过飞书文档侧边栏找到“问答”入口);
- 选择检索范围:比如“不使用企业知识”(仅用AI)或“包含文档+消息”(基于企业资料);
- 输入问题(如“产品经理行动营的课件里有程序员笑话吗?”),查看AI回答及来源。
3. 优缺点
- 优点:权限设置灵活(可关闭企业知识),检索精度比腾讯文档略高,支持多类型资料(文档、消息、会议纪要);
- 缺点:网页端入口隐蔽,需通过飞书客户端或特定链接进入,操作稍复杂。
(三)两款产品核心对比(一目了然)
|
对比维度 |
腾讯文档AI |
飞书问答 |
|
权限灵活性 |
低(必须用文档) |
高(可关闭企业知识) |
|
检索精度 |
中等(有重复/漏检) |
中等偏上 |
|
操作难度 |
简单(入口直观) |
中等(入口隐蔽) |
|
适用场景 |
个人学习、小型资料库 |
企业协作、多团队共享知识库 |
四、核心技术逻辑拆解
1. 资料准备:让AI“读得到”资料
- 文档导入:支持PDF、Markdown、普通文档等格式(注意:部分工具不支持Markdown,需转PDF);
- 文档处理:AI会自动把长文档“分块”(比如每500字一块),再通过Embedding技术转换成语义向量,存储到“向量数据库”(相当于AI的“记忆库”)。
2. 提问处理:让AI“懂你的问题”
- 问题转换:你输入的自然语言问题(如“2024年国内AI政策导向是什么?”),会被转换成和资料一样的语义向量;
- 检索匹配:AI在向量数据库中查找和问题最相似的“文档块”(通常取Top5~10个最相关的),确保回答有依据。
3. 回答生成:让AI“说人话”
- 结合资料:AI把检索到的相关文档块,和你的问题、对话历史拼接成“提示词”(比如“根据以下资料回答问题:[文档内容],问题:[你的问题]”);
- 调用大模型:把提示词传给AI大模型(如豆包),大模型结合资料生成回答,避免瞎编。
4. 流式输出:让回答“实时显示”
- 什么是流式输出?不是等AI完全想好再一次性输出,而是“边想边说”,比如先输出“2024年国内AI政策核心是”,再慢慢补充后续内容,提升体验;
- 背后逻辑:AI每生成一个“词(Token)”就返回一次,前端页面实时拼接显示,直到回答完成。
五、开源项目拆解实战(从“用”到“懂”)
(一)Pandawiki核心定位
- 功能:开源的知识库问答工具,支持创建文档、导入资料、语义检索,可私有化部署(自己的服务器上运行);
- 适用场景:想搭建专属知识库,不想用腾讯/飞书的企业或个人。
(二)部署与配置步骤
- 准备工具:电脑需安装Git(代码下载工具)、Docker(环境配置工具,一键部署);
- 下载代码:打开终端,输入命令git clone https://github.com/pandawiki/pandawiki.git(复制粘贴即可),下载项目代码;
- 配置环境:
- 进入项目文件夹,找到docker-compose.yml文件,用记事本打开;
- 修改端口(如果80端口被占用,改成87或1324,避免冲突);
- 启动项目:终端输入docker-compose up -d,等待5分钟,打开浏览器输入http://localhost:87(端口号和你修改的一致),即可访问Pandawiki;
- 导入资料:创建知识库,上传PDF文档,等待AI完成Embedding(学习过程),之后就能提问了。
(三)用AI拆解项目逻辑(关键步骤)
如果想知道项目背后的代码逻辑,用Kimi、Claude等AI工具帮忙:
- 下载项目代码压缩包,上传到Kimi(需开通coding会员,按次数收费,性价比高);
- 给AI发指令:“分析这个Pandawiki项目的代码,用时序图展示核心流程(问答交互、文档创建),用Markdown文档输出结果”;
- 等待AI生成报告,重点看3部分:
- 问答交互流程:用户提问→前端验证→API服务→缓存对话历史→RAG检索→大模型生成回答→流式输出;
- 文档处理流程:创建文档→保存到数据库→分块→Embedding→存储到向量库;
- 权限控制:检索结果会过滤无权限的文档(比如别人的私有文档你看不到)。
(四)拆解后核心收获(零基础重点记)
- 所有知识库工具的核心逻辑都一样:“资料处理→检索→生成回答”;
- 开源项目的代码结构有规律:前端(页面交互)、后端(逻辑处理)、配置文件(环境设置)、存储(数据库/向量库);
- 遇到不懂的代码,不用死磕,让AI解释“这个函数是干嘛的”“这个流程是什么意思”,效率更高。
六、常见问题与避坑指南
- 导入文档后AI检索不到?
- 检查文档格式:部分工具不支持Markdown,转PDF再试;
- 确认文档已完成Embedding:开源项目可能需要等待几分钟,腾讯/飞书通常实时完成;
- 检查检索范围:是否选错了知识库或筛选条件(比如飞书选了“不包含文档”)。
- 部署开源项目时端口被占用?
- 换一个端口(比如87、1324、4437),修改配置文件后重启项目;
- 用终端命令查看占用端口(Windows:netstat -ano | findstr "80",Mac:lsof -i :80),关闭占用程序。
- 语义检索不如关键词检索快?
- 正常现象:语义检索需要转换向量,比关键词检索多一步,开源项目中可通过“缓存已生成的向量”提升速度;
- 腾讯/飞书之所以快,是因为优化了Embedding技术,支持“极速嵌入”。
七、学习路径建议(零基础进阶)
- 第一阶段(1-2周):体验产品
- 用腾讯文档AI、飞书问答导入自己的学习资料(比如笔记、课件),反复提问,感受两种检索逻辑的差异;
- 尝试创建空间、设置权限,熟悉产品功能。
- 第二阶段(2-3周):理解技术
- 重点看“核心技术逻辑”部分,不用深究代码,记住“资料分块→Embedding→检索→生成”的流程;
- 用AI工具(如豆包)解释“向量数据库是什么”“RAG和普通AI有什么区别”,直到听懂。
- 第三阶段(3-4周):实战拆解
- 按照步骤部署Pandawiki,导入资料并提问,验证技术流程;
- 用Kimi拆解项目,查看AI生成的时序图,对比实际产品和开源项目的差异。
- 第四阶段(可选):尝试改造
- 用AI工具修改Pandawiki的简单功能(比如修改页面标题、调整检索结果数量);
- 尝试导入不同类型的资料(图片PDF、长文档),测试工具的兼容性。
八、必备工具清单
- 产品体验:腾讯文档(网页版)、飞书(客户端);
- 项目部署:Git(代码下载)、Docker(环境配置)、浏览器(Chrome/Firefox);
- 代码拆解:Kimi(coding会员,按次数收费)、Claude(支持大文件上传);
- 文档编辑:妙言(支持Markdown,查看AI生成的报告)、记事本(修改配置文件)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)