Langchain4j框架入门
本文介绍了使用Langchain4j框架开发AI代码生成平台的过程。通过声明式编程模式实现HTML和多文件代码生成功能,采用门面模式封装复杂逻辑,并引入流式输出提升用户体验。文章详细讲解了结构化输出优化、策略模式解析器设计、模板方法模式文件保存等关键技术点,最终实现了一个可扩展的AI代码生成系统,支持实时响应和文件保存功能。

目录
一. Langchain4j介绍
Langchain4j是目前主流的Java AI开发框架,有着三大优势:
声明式编程模式:用过简单的注释和接口定义,就可以实现复杂的AI交互逻辑,大大降低了开发门槛
丰富的模块支持:不仅支持Open AI 还兼容国内外主流的大模型服务
容易集成:它和Spring Boot 达到集成也做的不错,能快速整合到已有项目中
对比Spring AI来说,当Spring AI目前支持的功能更多,并且还有国内 Spring AI Alibaba巨头加持,生态更好,Langchain4j的优势在于可以独立于Spring 项目使用,灵活度更高,后续也会出一期Spring AI的使用
| 功能 / 概念 | LangChain4j | Spring AI |
|---|---|---|
| 聊天模型 | ChatModel |
ChatModel |
| 流式聊天 | StreamingChatModel |
ChatClient.stream() |
| AI 服务 | AiService |
ChatClient |
| 嵌入模型 | EmbeddingModel |
EmbeddingModel |
| 用户消息 | UserMessage |
UserMessage |
| AI 回复消息 | AiMessage |
AssistantMessage |
| 工具定义 | @Tool |
@Tool |
| 对话记忆 | ChatMemory |
ChatMemory |
| 文档加载 | DocumentLoader |
DocumentReader |
| 文档分割 | DocumentSplitter |
DocumentTransformer |
| 向量存储 | EmbeddingStore |
VectorStore |
| RAG 检索器 | ContentRetriever |
DocumentRetriever |
| 拦截器 | Guardrail |
Advisor |
| MCP | McpToolProvider |
ToolCallbackProvider |
接下来我们一起来通过一个案例来学习一下Langchain4j的使用吧
二. 实现AI应用生成
大模型接入
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
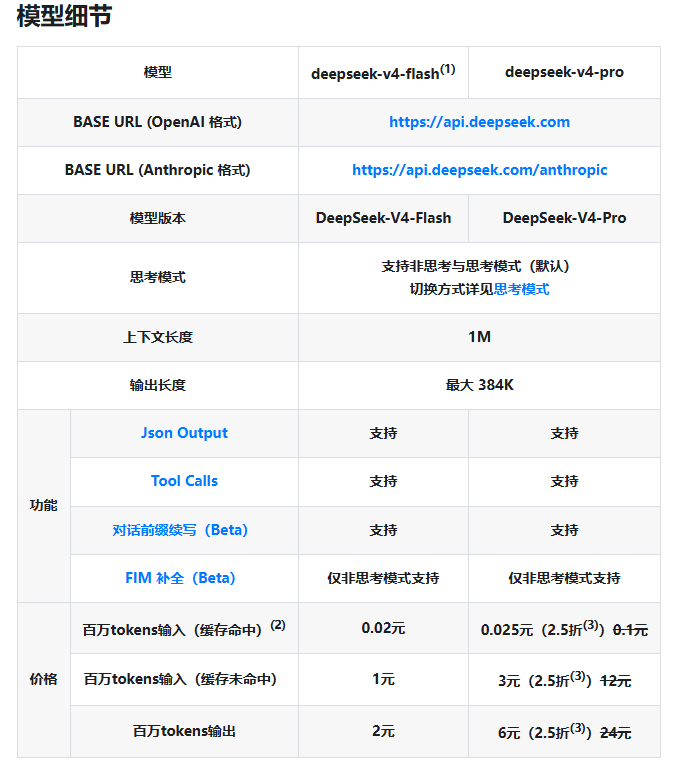
创建本地配置文件application.yml ,填写chat Model配置,这里我们就选择接入最新的deepseek v4模型:
# AI
langchain4j:
open-ai:
chat-model:
base-url: https://api.deepseek.com
api-key: <Your API Key> #请自行去官网获取
model-name: deepseek-chat
log-requests: true
log-responses: true
开发AI服务
public interface AiCodeGeneratorService {
String generateCode(String userMessage);
}
因为系统提示词通常情况下都比较长,我们单独维护在一个资源文件下,这里准备了两种生成模式对应的系统提示词
codegen-html-system-prompt.txt:原生 HTML 模式codegen-multi-file-system-prompt.txt:原生三件套模式

在服务接口中添加两个生成代码的方法,分别对应两种生成模式,使用Langchain4j的注解来指定系统提示词:
public interface AiCodeGeneratorService {
/**
* 生成 HTML 代码
*
* @param userMessage 用户消息
* @return 生成的代码结果
*/
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
String generateHtmlCode(String userMessage);
/**
* 生成多文件代码
*
* @param userMessage 用户消息
* @return 生成的代码结果
*/
@SystemMessage(fromResource = "prompt/codegen-multi-file-system-prompt.txt")
String generateMultiFileCode(String userMessage);
}
接下来我们来创建一个工厂类来初始化AI服务:
@Configuration
public class AiCodeGeneratorServiceFactory {
@Resource
private ChatModel chatModel;
@Bean
public AiCodeGeneratorService aiCodeGeneratorService() {
return AiServices.create(AiCodeGeneratorService.class, chatModel);
}
}
最后我们就可以编写一个单元测试来验证功能啦:
@SpringBootTest
class AiCodeGeneratorServiceTest {
@Resource
private AiCodeGeneratorService aiCodeGeneratorService;
@Test
void generateHtmlCode() {
String result = aiCodeGeneratorService.generateHtmlCode("爱编程的小新的个人主页介绍");
Assertions.assertNotNull(result);
}
@Test
void generateMultiFileCode() {
String multiFileCode = aiCodeGeneratorService.generateMultiFileCode("爱编程的小新的个人主页介绍");
Assertions.assertNotNull(multiFileCode);
}
}
测试结果应该就会发现AI返回的结果全部都放在一个String中啦
结构化输出
这时候已经能够调用AI生成代码了,但是直接返回字符串的方式不便于后续解析代码并保存为文件,因此我们需要将Ai的输出转换为结构化对象,这个时候我们就可以用Langchain4j的结构化输出就能够实现
基本实现
在model包下创建两个生成结果类,用于封装AI返回的内容:
@Data
public class HtmlCodeResult {
private String htmlCode;
private String description;
}
@Data
public class MultiFileCodeResult {
private String htmlCode;
private String cssCode;
private String jsCode;
private String description;
}
修改AI服务接口,让方法返回的是结构化对象:
/**
* 生成 HTML 代码
*
* @param userMessage 用户消息
* @return 生成的代码结果
*/
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
HtmlCodeResult generateHtmlCode(String userMessage);
/**
* 生成多文件代码
*
* @param userMessage 用户消息
* @return 生成的代码结果
*/
@SystemMessage(fromResource = "prompt/codegen-multi-file-system-prompt.txt")
MultiFileCodeResult generateMultiFileCode(String userMessage);
修改相应的单元测试调用方法的返回值类型即可重新测试
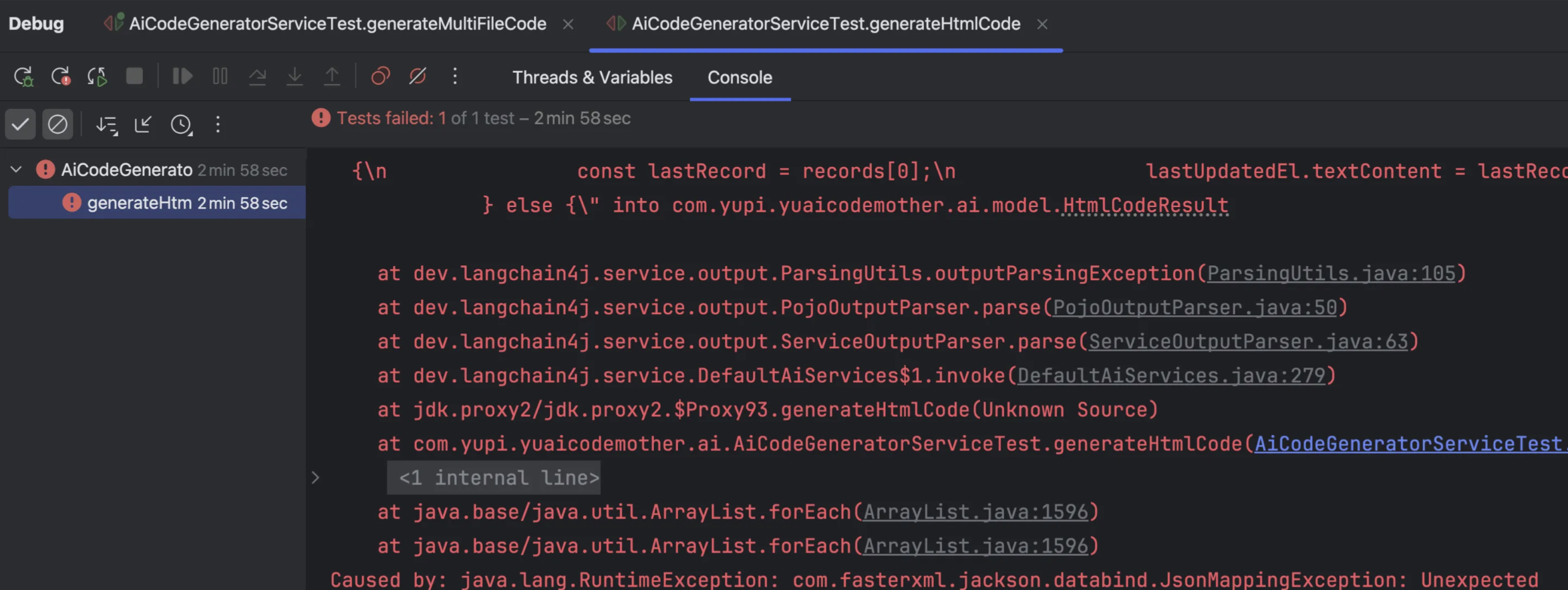
但是在实际测试中可能会出现报错,AI并没有乖乖的返回JSON格式,这个时候就需要通过一些技巧来优化提高结构化输出的准确度和稳定性
优化技巧
1. 设置 max_tokens
可以说设置一下输出长度,防止AI生成的JSON被半路截断,但是注意不要超出模型的限制:

langchain4j:
open-ai:
chat-model:
max-tokens: 8192
2. 添加字段描述
参考Langchain4j文档,为结果类和属性添加详细的描述信息,便于AI理解:
@Description("生成 HTML 代码文件的结果")
@Data
public class HtmlCodeResult {
@Description("HTML代码")
private String htmlCode;
@Description("生成代码的描述")
private String description;
}
@Description("生成多个代码文件的结果")
@Data
public class MultiFileCodeResult {
@Description("HTML代码")
private String htmlCode;
@Description("CSS代码")
private String cssCode;
@Description("JS代码")
private String jsCode;
@Description("生成代码的描述")
private String description;
}
这个时候再次测试,就可以看到提示词中自动补充了字段描述和配置信息,经过这些优化,结构化输出的准确度有了显著提升。
门面模式
现在我们已经能够生成代码并且能将生成的代码输出为相应的对象,现在我们就需要将生成的代码保存到本地文件系统中,那么什么是门面模式呢
门面模式通过提供一个统一的对外接口来隐藏子系统发复杂性,让客户端只需要于这个简化的接口交互,不用了解内部的复杂实现细节,说直白点就是再对外层进行一层封装
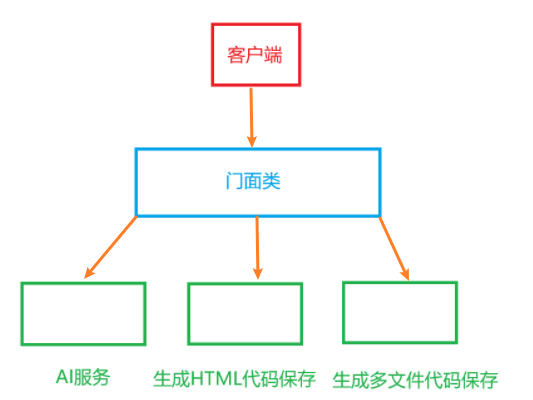
首先我们先定义生成类型枚举类:
@Getter
public enum CodeGenTypeEnum {
HTML("原生 HTML 模式", "html"),
MULTI_FILE("原生多文件模式", "multi_file");
private final String text;
private final String value;
CodeGenTypeEnum(String text, String value) {
this.text = text;
this.value = value;
}
/**
* 根据 value 获取枚举
*
* @param value 枚举值的value
* @return 枚举值
*/
public static CodeGenTypeEnum getEnumByValue(String value) {
if (ObjUtil.isEmpty(value)) {
return null;
}
for (CodeGenTypeEnum anEnum : CodeGenTypeEnum.values()) {
if (anEnum.value.equals(value)) {
return anEnum;
}
}
return null;
}
}
创建文件写入工具类CodeFIleSaver
public class CodeFileSaver {
// 文件保存根目录
private static final String FILE_SAVE_ROOT_DIR = System.getProperty("user.dir") + "/tmp/code_output";
/**
* 保存 HtmlCodeResult
*/
public static File saveHtmlCodeResult(HtmlCodeResult result) {
String baseDirPath = buildUniqueDir(CodeGenTypeEnum.HTML.getValue());
writeToFile(baseDirPath, "index.html", result.getHtmlCode());
return new File(baseDirPath);
}
/**
* 保存 MultiFileCodeResult
*/
public static File saveMultiFileCodeResult(MultiFileCodeResult result) {
String baseDirPath = buildUniqueDir(CodeGenTypeEnum.MULTI_FILE.getValue());
writeToFile(baseDirPath, "index.html", result.getHtmlCode());
writeToFile(baseDirPath, "style.css", result.getCssCode());
writeToFile(baseDirPath, "script.js", result.getJsCode());
return new File(baseDirPath);
}
/**
* 构建唯一目录路径:tmp/code_output/bizType_雪花ID
*/
private static String buildUniqueDir(String bizType) {
String uniqueDirName = StrUtil.format("{}_{}", bizType, IdUtil.getSnowflakeNextIdStr());
String dirPath = FILE_SAVE_ROOT_DIR + File.separator + uniqueDirName;
FileUtil.mkdir(dirPath);
return dirPath;
}
/**
* 写入单个文件
*/
private static void writeToFile(String dirPath, String filename, String content) {
String filePath = dirPath + File.separator + filename;
FileUtil.writeString(content, filePath, StandardCharsets.UTF_8);
}
}
这里使用临时目录tmp下保存文件,使用业务类型+雪花ID命名方法保证唯一性
定义AICodeGeneratorFacade类
/**
* AI 代码生成外观类,组合生成和保存功能
*/
@Service
public class AiCodeGeneratorFacade {
@Resource
private AiCodeGeneratorService aiCodeGeneratorService;
/**
* 统一入口:根据类型生成并保存代码
*
* @param userMessage 用户提示词
* @param codeGenTypeEnum 生成类型
* @return 保存的目录
*/
public File generateAndSaveCode(String userMessage, CodeGenTypeEnum codeGenTypeEnum) {
if (codeGenTypeEnum == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成类型为空");
}
return switch (codeGenTypeEnum) {
case HTML -> generateAndSaveHtmlCode(userMessage);
case MULTI_FILE -> generateAndSaveMultiFileCode(userMessage);
default -> {
String errorMessage = "不支持的生成类型:" + codeGenTypeEnum.getValue();
throw new BusinessException(ErrorCode.SYSTEM_ERROR, errorMessage);
}
};
}
/**
* 生成 HTML 模式的代码并保存
*
* @param userMessage 用户提示词
* @return 保存的目录
*/
private File generateAndSaveHtmlCode(String userMessage) {
HtmlCodeResult result = aiCodeGeneratorService.generateHtmlCode(userMessage);
return CodeFileSaver.saveHtmlCodeResult(result);
}
/**
* 生成多文件模式的代码并保存
*
* @param userMessage 用户提示词
* @return 保存的目录
*/
private File generateAndSaveMultiFileCode(String userMessage) {
MultiFileCodeResult result = aiCodeGeneratorService.generateMultiFileCode(userMessage);
return CodeFileSaver.saveMultiFileCodeResult(result);
}
}
经过测试可以看到生成文件的保存路径:
SSE流式输出
这时候代码生成功能已经可以正常工作了,但是结构化输出的速度比较慢,我们需要等待很长的时间才能看到结果,这样体验显然不好,这时候我们就需要引入SSE流式输出,像打字机一样,AI返回一个词,前端输出一个词
目前流式输出不支持结构化输出,但是我们可以在流式输出返回的过程中,手动拼接AI返回的结果,等全部输出完成后,再对结果进行解析和保存,既保证了实时性又不影响最终处理流程
LangChain4j+Reactor
Reactor是指响应式编程。LangChain4j提供了响应式编程依赖包,可以直接将AI返回的内容封装为更通用了Flux响应式对象,可以将Flux看成一个数据流,上游发来一个数据,下游就能处理一个数据
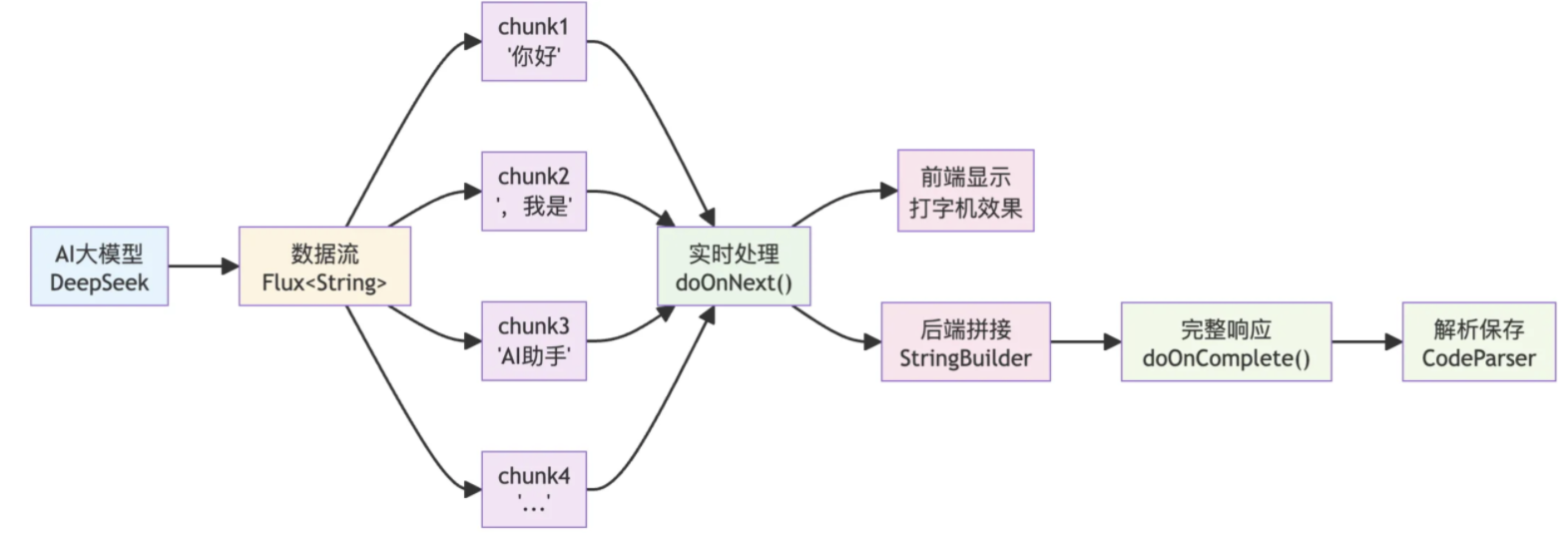
什么是响应式呢
以数据流为核心,数据来了自动触发处理,异步非阻塞、主动推送的编程思想,和传统主动拉取完全相反。
传统命令式编程(普通 Java)
你主动调用方法
阻塞等待结果返回
拿到数据再往下执行特点:我主动要,等待响应
响应式编程(WebFlux/Flux/Mono)
先定义好处理流程
数据自动推送过来
来了就自动执行逻辑,不阻塞特点:数据主动来,我被动处理
引入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
配置流式模型:
langchain4j:
open-ai:
streaming-chat-model:
base-url: https://api.deepseek.com
api-key: <Your API Key>
model-name: deepseek-chat
max-tokens: 8192
log-requests: true
log-responses: true
在AI Service工程类中注入流式模型
@Configuration
public class AiCodeGeneratorServiceFactory {
@Resource
private ChatModel chatModel;
@Resource
private StreamingChatModel streamingChatModel;
@Bean
public AiCodeGeneratorService aiCodeGeneratorService() {
return AiServices.builder(AiCodeGeneratorService.class)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel)
.build();
}
}
在AI Service中新增流式方法,跟之前的方法区别在于返回值改为了Flux对象
/**
* 生成 HTML 代码(流式)
*
* @param userMessage 用户消息
* @return 生成的代码结果
*/
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
Flux<String> generateHtmlCodeStream(String userMessage);
/**
* 生成多文件代码(流式)
*
* @param userMessage 用户消息
* @return 生成的代码结果
*/
@SystemMessage(fromResource = "prompt/codegen-multi-file-system-prompt.txt")
Flux<String> generateMultiFileCodeStream(String userMessage);
编写代码解析工具,因为流式输出返回的是字符串片段,我们需要等待AI全部返回完成后进行解析(这里可以让ai帮助我们生成这个工具的)
/**
* 代码解析器
* 提供静态方法解析不同类型的代码内容
*
*/
public class CodeParser {
private static final Pattern HTML_CODE_PATTERN = Pattern.compile("```html\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern CSS_CODE_PATTERN = Pattern.compile("```css\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern JS_CODE_PATTERN = Pattern.compile("```(?:js|javascript)\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
/**
* 解析 HTML 单文件代码
*/
public static HtmlCodeResult parseHtmlCode(String codeContent) {
HtmlCodeResult result = new HtmlCodeResult();
// 提取 HTML 代码
String htmlCode = extractHtmlCode(codeContent);
if (htmlCode != null && !htmlCode.trim().isEmpty()) {
result.setHtmlCode(htmlCode.trim());
} else {
// 如果没有找到代码块,将整个内容作为HTML
result.setHtmlCode(codeContent.trim());
}
return result;
}
/**
* 解析多文件代码(HTML + CSS + JS)
*/
public static MultiFileCodeResult parseMultiFileCode(String codeContent) {
MultiFileCodeResult result = new MultiFileCodeResult();
// 提取各类代码
String htmlCode = extractCodeByPattern(codeContent, HTML_CODE_PATTERN);
String cssCode = extractCodeByPattern(codeContent, CSS_CODE_PATTERN);
String jsCode = extractCodeByPattern(codeContent, JS_CODE_PATTERN);
// 设置HTML代码
if (htmlCode != null && !htmlCode.trim().isEmpty()) {
result.setHtmlCode(htmlCode.trim());
}
// 设置CSS代码
if (cssCode != null && !cssCode.trim().isEmpty()) {
result.setCssCode(cssCode.trim());
}
// 设置JS代码
if (jsCode != null && !jsCode.trim().isEmpty()) {
result.setJsCode(jsCode.trim());
}
return result;
}
/**
* 提取HTML代码内容
*
* @param content 原始内容
* @return HTML代码
*/
private static String extractHtmlCode(String content) {
Matcher matcher = HTML_CODE_PATTERN.matcher(content);
if (matcher.find()) {
return matcher.group(1);
}
return null;
}
/**
* 根据正则模式提取代码
*
* @param content 原始内容
* @param pattern 正则模式
* @return 提取的代码
*/
private static String extractCodeByPattern(String content, Pattern pattern) {
Matcher matcher = pattern.matcher(content);
if (matcher.find()) {
return matcher.group(1);
}
return null;
}
}
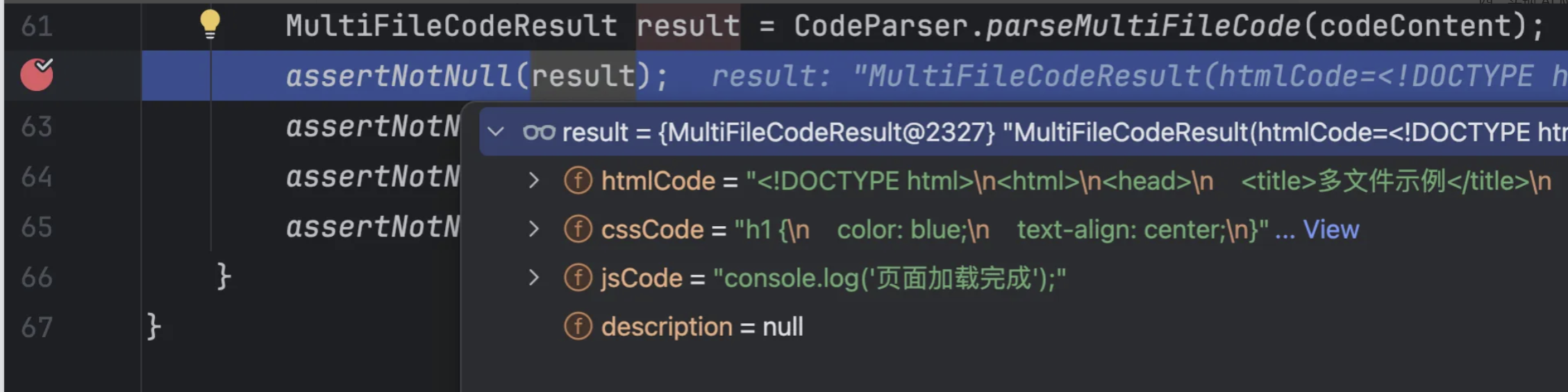
编写一个测试,验证解析器的功能:
class CodeParserTest {
@Test
void parseHtmlCode() {
String codeContent = """
随便写一段描述:
html 格式
<!DOCTYPE html>
<html>
<head>
<title>测试页面</title>
</head>
<body>
<h1>Hello World!</h1>
</body>
</html>
随便写一段描述
""";
HtmlCodeResult result = CodeParser.parseHtmlCode(codeContent);
assertNotNull(result);
assertNotNull(result.getHtmlCode());
}
@Test
void parseMultiFileCode() {
String codeContent = """
创建一个完整的网页:
html 格式
<!DOCTYPE html>
<html>
<head>
<title>多文件示例</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>欢迎使用</h1>
<script src="script.js"></script>
</body>
</html>
css 格式
h1 {
color: blue;
text-align: center;
}
```
```js
console.log('页面加载完成');
文件创建完成!
""";
MultiFileCodeResult result = CodeParser.parseMultiFileCode(codeContent);
assertNotNull(result);
assertNotNull(result.getHtmlCode());
assertNotNull(result.getCssCode());
assertNotNull(result.getJsCode());
}
}
在 AICodeGeneratorFacade中添加流式调用AI的方法:
/**
* 生成 HTML 模式的代码并保存(流式)
*
* @param userMessage 用户提示词
* @return 保存的目录
*/
private Flux<String> generateAndSaveHtmlCodeStream(String userMessage) {
Flux<String> result = aiCodeGeneratorService.generateHtmlCodeStream(userMessage);
// 当流式返回生成代码完成后,再保存代码
StringBuilder codeBuilder = new StringBuilder();
return result
.doOnNext(chunk -> {
// 实时收集代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
// 流式返回完成后保存代码
try {
String completeHtmlCode = codeBuilder.toString();
HtmlCodeResult htmlCodeResult = CodeParser.parseHtmlCode(completeHtmlCode);
// 保存代码到文件
File savedDir = CodeFileSaver.saveHtmlCodeResult(htmlCodeResult);
log.info("保存成功,路径为:" + savedDir.getAbsolutePath());
} catch (Exception e) {
log.error("保存失败: {}", e.getMessage());
}
});
}
/**
* 生成多文件模式的代码并保存(流式)
*
* @param userMessage 用户提示词
* @return 保存的目录
*/
private Flux<String> generateAndSaveMultiFileCodeStream(String userMessage) {
Flux<String> result = aiCodeGeneratorService.generateMultiFileCodeStream(userMessage);
// 当流式返回生成代码完成后,再保存代码
StringBuilder codeBuilder = new StringBuilder();
return result
.doOnNext(chunk -> {
// 实时收集代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
// 流式返回完成后保存代码
try {
String completeMultiFileCode = codeBuilder.toString();
MultiFileCodeResult multiFileResult = CodeParser.parseMultiFileCode(completeMultiFileCode);
// 保存代码到文件
File savedDir = CodeFileSaver.saveMultiFileCodeResult(multiFileResult);
log.info("保存成功,路径为:" + savedDir.getAbsolutePath());
} catch (Exception e) {
log.error("保存失败: {}", e.getMessage());
}
});
}
编写统一入口,根据生成类型枚举选择对应的流式方法:
/**
* 统一入口:根据类型生成并保存代码(流式)
*
* @param userMessage 用户提示词
* @param codeGenTypeEnum 生成类型
*/
public Flux<String> generateAndSaveCodeStream(String userMessage, CodeGenTypeEnum codeGenTypeEnum) {
if (codeGenTypeEnum == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成类型为空");
}
return switch (codeGenTypeEnum) {
case HTML -> generateAndSaveHtmlCodeStream(userMessage);
case MULTI_FILE -> generateAndSaveMultiFileCodeStream(userMessage);
default -> {
String errorMessage = "不支持的生成类型:" + codeGenTypeEnum.getValue();
throw new BusinessException(ErrorCode.SYSTEM_ERROR, errorMessage);
}
};
}
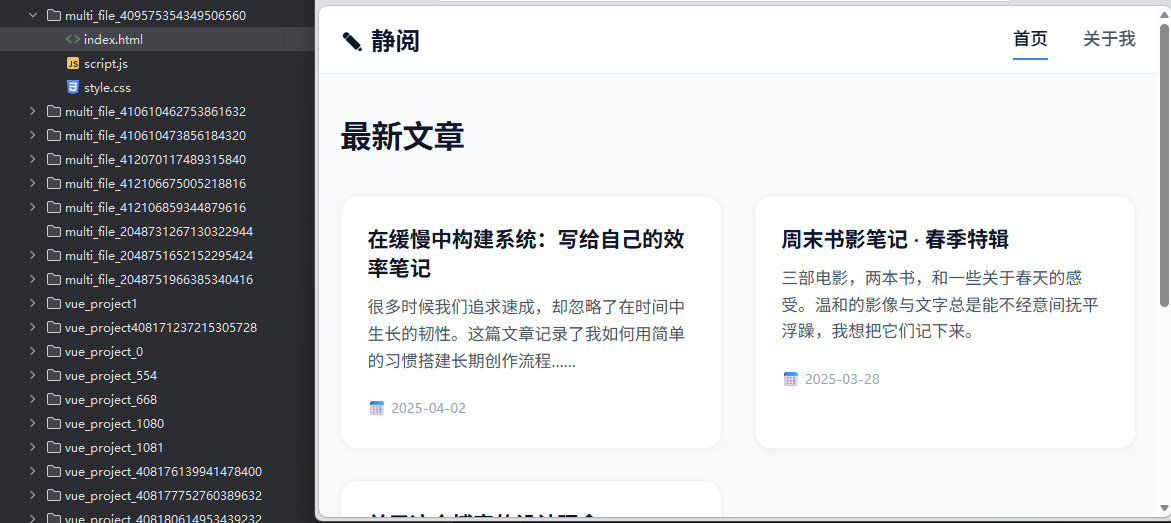
经过测试,查看网站生成效果:
代码优化
在上面的代码中我们可以发现有很多重复的代码,比如这里:
/**
* 生成 HTML 模式的代码并保存(流式)
*
* @param userMessage 用户提示词
* @return 保存的目录
*/
private Flux<String> generateAndSaveHtmlCodeStream(String userMessage) {
Flux<String> result = aiCodeGeneratorService.generateHtmlCodeStream(userMessage);
// 当流式返回生成代码完成后,再保存代码
StringBuilder codeBuilder = new StringBuilder();
return result
.doOnNext(chunk -> {
// 实时收集代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
// 流式返回完成后保存代码
try {
String completeHtmlCode = codeBuilder.toString();
HtmlCodeResult htmlCodeResult = CodeParser.parseHtmlCode(completeHtmlCode);
// 保存代码到文件
File savedDir = CodeFileSaver.saveHtmlCodeResult(htmlCodeResult);
log.info("保存成功,路径为:" + savedDir.getAbsolutePath());
} catch (Exception e) {
log.error("保存失败: {}", e.getMessage());
}
});
}
/**
* 生成多文件模式的代码并保存(流式)
*
* @param userMessage 用户提示词
* @return 保存的目录
*/
private Flux<String> generateAndSaveMultiFileCodeStream(String userMessage) {
Flux<String> result = aiCodeGeneratorService.generateMultiFileCodeStream(userMessage);
// 当流式返回生成代码完成后,再保存代码
StringBuilder codeBuilder = new StringBuilder();
return result
.doOnNext(chunk -> {
// 实时收集代码片段
codeBuilder.append(chunk);
})
.doOnComplete(() -> {
// 流式返回完成后保存代码
try {
String completeMultiFileCode = codeBuilder.toString();
MultiFileCodeResult multiFileResult = CodeParser.parseMultiFileCode(completeMultiFileCode);
// 保存代码到文件
File savedDir = CodeFileSaver.saveMultiFileCodeResult(multiFileResult);
log.info("保存成功,路径为:" + savedDir.getAbsolutePath());
} catch (Exception e) {
log.error("保存失败: {}", e.getMessage());
}
});
}
上面两个方法其实干的是同一件事,只是解析代码和保存文件的方法类型不同,那么这时候我们可以通过几种设计模式来优化代码结构
解析器部分使用策略模式:
策略模式定义:
同一个功能,有多种不同实现方案,随时自由切换使用,所有方案地位平等。
结构:
统一策略接口
多个不同实现类
上下文统一调用
特点:
算法互相替换
新增方案不用改旧代码
用组合,不用继承
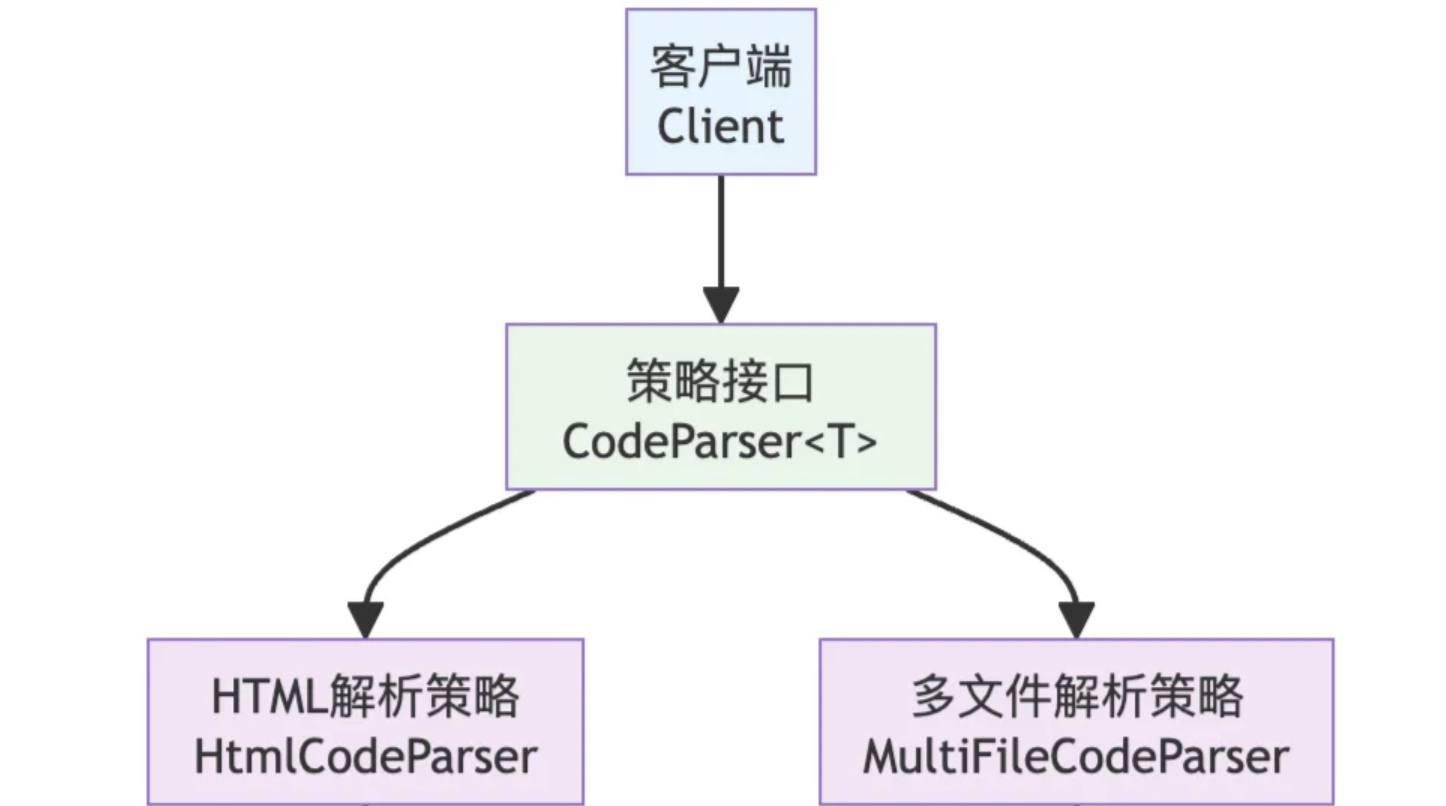
优化解析器:新建一个包
定义接口:通过泛型统一方法返回值
/**
* 代码解析器策略接口
*
*/
public interface CodeParser<T> {
/**
* 解析代码内容
*
* @param codeContent 原始代码内容
* @return 解析后的结果对象
*/
T parseCode(String codeContent);
}
编写HTML单文件代码解析器:
/**
* HTML 单文件代码解析器
*
*/
public class HtmlCodeParser implements CodeParser<HtmlCodeResult> {
private static final Pattern HTML_CODE_PATTERN = Pattern.compile("```html\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
@Override
public HtmlCodeResult parseCode(String codeContent) {
HtmlCodeResult result = new HtmlCodeResult();
// 提取 HTML 代码
String htmlCode = extractHtmlCode(codeContent);
if (htmlCode != null && !htmlCode.trim().isEmpty()) {
result.setHtmlCode(htmlCode.trim());
} else {
// 如果没有找到代码块,将整个内容作为HTML
result.setHtmlCode(codeContent.trim());
}
return result;
}
/**
* 提取HTML代码内容
*
* @param content 原始内容
* @return HTML代码
*/
private String extractHtmlCode(String content) {
Matcher matcher = HTML_CODE_PATTERN.matcher(content);
if (matcher.find()) {
return matcher.group(1);
}
return null;
}
}
编写多文件代码解析器:
package com.sunny.sunnyaicodebackend.core.parser;
import com.sunny.sunnyaicodebackend.ai.model.MultFileCodeResult;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 多文件代码解析器
*
*/
public class MultFileCodeParser implements CodeParser {
private static final Pattern HTML_CODE_PATTERN = Pattern.compile("```html\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern CSS_CODE_PATTERN = Pattern.compile("```css\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern JS_CODE_PATTERN = Pattern.compile("```(?:js|javascript)\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
@Override
public MultFileCodeResult parseCode(String codeContent) {
MultFileCodeResult result = new MultFileCodeResult();
String htmlcode = extractCodeByPattern(codeContent,HTML_CODE_PATTERN);
String csscode = extractCodeByPattern(codeContent,CSS_CODE_PATTERN);
String jscode = extractCodeByPattern(codeContent,JS_CODE_PATTERN);
//设置html代码
if(htmlcode != null && !htmlcode.trim().isEmpty()){
result.setHtmlCode(htmlcode);
}
if(csscode != null && !csscode.trim().isEmpty()){
result.setCssCode(csscode);
}
if(jscode != null && !jscode.trim().isEmpty()){
result.setJsCode(jscode);
}
return result;
}
private static String extractCodeByPattern(String codeContent, Pattern htmlCodePattern) {
//根据定义好的正则模板,扫描文本,生成一个匹配器
Matcher matcher = htmlCodePattern.matcher(codeContent);
if(matcher.find()){
return matcher.group(1);
}
return null;
}
}
编写代码解析执行器,根据代码类型执行相应的解析逻辑:
package com.sunny.sunnyaicodebackend.core.parser;
import com.sunny.sunnyaicodebackend.exception.BusinessException;
import com.sunny.sunnyaicodebackend.exception.ErrorCode;
import com.sunny.sunnyaicodebackend.model.enums.CodeGenTypeEnum;
/**
* 代码解析执行器
* 根据代码生成类型执行相应的解析逻辑
*/
public class CodeParserExecutor {
private static final HtmlCodeParser htmlCodeParser = new HtmlCodeParser();
private static final MultFileCodeParser multcodeParser = new MultFileCodeParser();
/**
* 执行代码解析器
* @param codeContent 生成内容
* @param codeGenTypeEnum 代码生成类型
* @return
*/
public static Object executeParser(String codeContent, CodeGenTypeEnum codeGenTypeEnum) {
return switch (codeGenTypeEnum){
case HTML -> htmlCodeParser.parseCode(codeContent);
case MULTI_FILE -> multcodeParser.parseCode(codeContent);
default -> {
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"不支持的代码生成器:"+codeGenTypeEnum);
}
};
}
}
接下来就是优化文件保存器,这里我们使用模板方法模式:
模板方法模式定义:
整体执行流程、步骤顺序固定不变,只把其中部分可变步骤交给子类重写。
特点
父类定死执行顺序
子类只能改细节,不能改流程
基于继承实现
常用
final锁住主流程不让重写
创建一个saver包:
创建文件保存模板抽象类:
package com.sunny.sunnyaicodebackend.core.saver;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.StrUtil;
import com.sunny.sunnyaicodebackend.constant.AppConstant;
import com.sunny.sunnyaicodebackend.exception.BusinessException;
import com.sunny.sunnyaicodebackend.exception.ErrorCode;
import com.sunny.sunnyaicodebackend.model.enums.CodeGenTypeEnum;
import java.io.File;
import java.nio.charset.StandardCharsets;
/**
* 抽象代码文件保存器--> 模板方法模式
* @param <T>
*/
public abstract class CodeFileSaverTemplate <T>{
//文件保存根目录
protected static final String FILE_SAVE_ROOT_DIR= AppConstant.CODE_OUTPUT_ROOT_DIR;
/**
* 模板方法:保存代码的标准流程
* @param result
* @return
*/
public final File saveCode(T result,Long appId){
// 1. 验证输入内容
validateInput(result);
// 2. 构架唯一目录
String baseDirPath=buildUniqueDir(appId);
// 3.保存文件(具体由子类实现)
saveFiles(result,baseDirPath);
// 4.返回目录文件对象
return new File(baseDirPath);
}
/**
* 构建文件的唯一路径(tmp/code_output/bizType(业务类型)+雪花ID)
*/
protected final String buildUniqueDir(Long appId){
if(appId==null){
throw new BusinessException(ErrorCode.PARAMS_ERROR,"应用ID不能为空");
}
String codeType= getCodeType().getValue();
String uniqueDirName= StrUtil.format("{}_{}",codeType, appId);
String dirPath=FILE_SAVE_ROOT_DIR + File.separator + uniqueDirName;
FileUtil.mkdir(dirPath);
return dirPath;
}
/**
* 验证输入参数(当前权限可由子类覆盖)
* @param result
*/
protected void validateInput(T result) {
if(result==null){
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"代码结果对象不能为空");
}
}
/**
* 写入单个文件的工具
* @param baseDirPath
* @param fileName
* @param content
*/
protected final void writeToFile(String baseDirPath,String fileName,String content){
if(StrUtil.isNotBlank(content)){
String filePath=baseDirPath+File.separator+fileName;
FileUtil.writeString(content,filePath, StandardCharsets.UTF_8);
}
}
/**
* 获得代码类型(由子类实现)
* @return
*/
protected abstract CodeGenTypeEnum getCodeType();
/**
* 保存文件的具体实现(由子类实现)
* @param result 代码结果对象
* @param baseDirPath 基础目录路径
*/
protected abstract void saveFiles(T result, String baseDirPath);
}
编写HTML代码文件保存器:
package com.sunny.sunnyaicodebackend.core.saver;
import cn.hutool.core.util.StrUtil;
import com.sunny.sunnyaicodebackend.ai.model.HtmlCodeResult;
import com.sunny.sunnyaicodebackend.exception.BusinessException;
import com.sunny.sunnyaicodebackend.exception.ErrorCode;
import com.sunny.sunnyaicodebackend.model.enums.CodeGenTypeEnum;
public class HtmlCodeFileSaverTemplate extends CodeFileSaverTemplate<HtmlCodeResult> {
@Override
protected CodeGenTypeEnum getCodeType() {
return CodeGenTypeEnum.HTML;
}
@Override
protected void saveFiles(HtmlCodeResult result, String baseDirPath) {
//保存Html文件
writeToFile(baseDirPath,"index.html",result.getHtmlCode());
}
@Override
protected void validateInput(HtmlCodeResult result) {
super.validateInput(result);
//HTMl代码不能为空
if(StrUtil.isBlank(result.getHtmlCode())){
throw new BusinessException(ErrorCode.SYSTEM_ERROR,"Html代码内容不能为空");
}
}
}
编写多文件代码保存器:
package com.sunny.sunnyaicodebackend.core.saver;
import cn.hutool.core.util.StrUtil;
import com.sunny.sunnyaicodebackend.ai.model.MultFileCodeResult;
import com.sunny.sunnyaicodebackend.exception.BusinessException;
import com.sunny.sunnyaicodebackend.exception.ErrorCode;
import com.sunny.sunnyaicodebackend.model.enums.CodeGenTypeEnum;
/**
* 多文件代码保存器
*
*
*/
public class MultFileCodeFileSaverTemplate extends CodeFileSaverTemplate<MultFileCodeResult> {
@Override
public CodeGenTypeEnum getCodeType() {
return CodeGenTypeEnum.MULTI_FILE;
}
@Override
protected void saveFiles(MultFileCodeResult result, String baseDirPath) {
// 保存 HTML 文件
writeToFile(baseDirPath, "index.html", result.getHtmlCode());
// 保存 CSS 文件
writeToFile(baseDirPath, "style.css", result.getCssCode());
// 保存 JavaScript 文件
writeToFile(baseDirPath, "script.js", result.getJsCode());
}
@Override
protected void validateInput(MultFileCodeResult result) {
super.validateInput(result);
// 至少要有 HTML 代码,CSS 和 JS 可以为空
if (StrUtil.isBlank(result.getHtmlCode())) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "HTML代码内容不能为空");
}
}
}
编写代码文件保存执行器:
package com.sunny.sunnyaicodebackend.core.saver;
import com.sunny.sunnyaicodebackend.ai.model.HtmlCodeResult;
import com.sunny.sunnyaicodebackend.ai.model.MultFileCodeResult;
import com.sunny.sunnyaicodebackend.exception.BusinessException;
import com.sunny.sunnyaicodebackend.exception.ErrorCode;
import com.sunny.sunnyaicodebackend.model.enums.CodeGenTypeEnum;
import java.io.File;
/**
* 代码文件保存执行器
* 根据代码生成类型执行相应的保存逻辑
*
*
*/
public class CodeFileSaverExecutor {
/**
* html文件保存器
*/
private static final HtmlCodeFileSaverTemplate htmlCodeFileSaver = new HtmlCodeFileSaverTemplate();
/**
* 多文件保存器
*/
private static final MultFileCodeFileSaverTemplate multiFileCodeFileSaver = new MultFileCodeFileSaverTemplate();
/**
* 执行代码保存
*
* @param codeResult 代码结果对象
* @param codeGenType 代码生成类型
* @return 保存的目录
*/
public static File executeSaver(Object codeResult, CodeGenTypeEnum codeGenType,Long appId) {
return switch (codeGenType) {
case HTML -> htmlCodeFileSaver.saveCode((HtmlCodeResult) codeResult,appId);
case MULTI_FILE -> multiFileCodeFileSaver.saveCode((MultFileCodeResult) codeResult,appId);
default -> throw new BusinessException(ErrorCode.SYSTEM_ERROR, "不支持的代码生成类型: " + codeGenType);
};
}
}
优化门面类,抽象出通用的流式代码处理方法:
/**
* 通用流式代码处理方法
*
* @param codeStream 代码流
* @param codeGenType 代码生成类型
* @return 流式响应
*/
private Flux<String> processCodeStream(Flux<String> codeStream, CodeGenTypeEnum codeGenType) {
StringBuilder codeBuilder = new StringBuilder();
return codeStream.doOnNext(chunk -> {
// 实时收集代码片段
codeBuilder.append(chunk);
}).doOnComplete(() -> {
// 流式返回完成后保存代码
try {
String completeCode = codeBuilder.toString();
// 使用执行器解析代码
Object parsedResult = CodeParserExecutor.executeParser(completeCode, codeGenType);
// 使用执行器保存代码
File savedDir = CodeFileSaverExecutor.executeSaver(parsedResult, codeGenType);
log.info("保存成功,路径为:" + savedDir.getAbsolutePath());
} catch (Exception e) {
log.error("保存失败: {}", e.getMessage());
}
});
}
通过这些优化,我们 AiCodeGeneratorFacade 类中的统一入口方法可以变得更加简洁和优雅:
/**
* 统一入口:根据类型生成并保存代码
*
* @param userMessage 用户提示词
* @param codeGenTypeEnum 生成类型
* @return 保存的目录
*/
public File generateAndSaveCode(String userMessage, CodeGenTypeEnum codeGenTypeEnum) {
if (codeGenTypeEnum == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成类型为空");
}
return switch (codeGenTypeEnum) {
case HTML -> {
HtmlCodeResult result = aiCodeGeneratorService.generateHtmlCode(userMessage);
yield CodeFileSaverExecutor.executeSaver(result, CodeGenTypeEnum.HTML);
}
case MULTI_FILE -> {
MultiFileCodeResult result = aiCodeGeneratorService.generateMultiFileCode(userMessage);
yield CodeFileSaverExecutor.executeSaver(result, CodeGenTypeEnum.MULTI_FILE);
}
default -> {
String errorMessage = "不支持的生成类型:" + codeGenTypeEnum.getValue();
throw new BusinessException(ErrorCode.SYSTEM_ERROR, errorMessage);
}
};
}
/**
* 统一入口:根据类型生成并保存代码(流式)
*
* @param userMessage 用户提示词
* @param codeGenTypeEnum 生成类型
*/
public Flux<String> generateAndSaveCodeStream(String userMessage, CodeGenTypeEnum codeGenTypeEnum) {
if (codeGenTypeEnum == null) {
throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成类型为空");
}
return switch (codeGenTypeEnum) {
case HTML -> {
Flux<String> codeStream = aiCodeGeneratorService.generateHtmlCodeStream(userMessage);
yield processCodeStream(codeStream, CodeGenTypeEnum.HTML);
}
case MULTI_FILE -> {
Flux<String> codeStream = aiCodeGeneratorService.generateMultiFileCodeStream(userMessage);
yield processCodeStream(codeStream, CodeGenTypeEnum.MULTI_FILE);
}
default -> {
String errorMessage = "不支持的生成类型:" + codeGenTypeEnum.getValue();
throw new BusinessException(ErrorCode.SYSTEM_ERROR, errorMessage);
}
};
}
通过上述种种优化,代码的可读性和可维护性都得到了显著提升。当我们需要支持新的生成类型时,只需要添加相应的枚举值和处理逻辑,而不需要修改主要的业务流程,这时候项目已经具备了基础的网站应用生成能力,但是现在AI是没有记忆的,下期介绍怎么让AI能够有记忆


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)