World Knowledge:让智能体在任务到来前先理解世界
当前自进化智能体仍依赖人工预设任务和奖励机制,缺乏真正的自主探索能力。本研究提出元学习驱动的智能体进化范式,让智能体在没有明确任务时主动构建结构化环境知识(World Knowledge)。通过URL爬取聚类、知识生成、任务执行和效果评估的完整流程,智能体能预先建立环境认知地图,显著提升后续任务效率。实验表明,这种自主探索生成的知识能有效减少任务执行步数,提高成功率,为实现真正的自进化智能体提供了
1. 问题背景:当前“自进化智能体”为什么还不够自进化
大语言模型智能体通常被描述为能够自主规划、调用工具、执行任务的系统,但在多数研究和产品实现中,所谓“自进化”仍然依赖人类预先给定的任务、流程与奖励。智能体先接收一个目标,再按照人类设计好的浏览、搜索、反思、打分、更新链路执行;如果没有任务,没有奖励函数,也没有外部评判器,它往往不会主动探索环境,更谈不上在任务到来之前形成可复用的认知结构。这篇论文试图回答一个更底层的问题:智能体能否像人进入新城市、打开新软件一样,在没有明确任务时也主动建立一张“环境地图”,并在后续任务中利用这张地图提高效率与成功率。论文地址:https://arxiv.org/abs/2604.18131
代码地址:https://github.com/Bklight999/world-knowledge
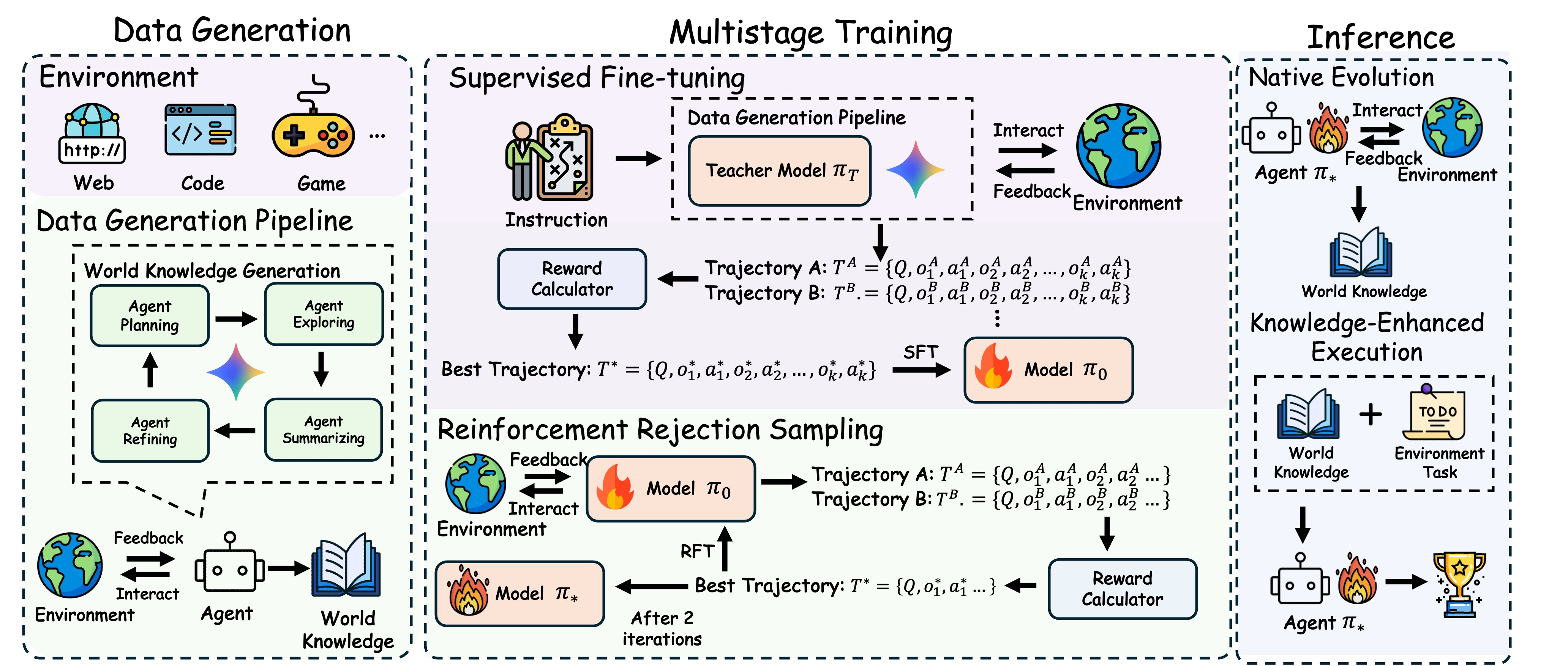
论文把现有自进化范式分成三类。第一类是经验驱动进化,智能体通过人工构造的任务和奖励积累轨迹,再把这些经验写入提示词、记忆库、工具库或模型参数;第二类是对抗式进化,由挑战者生成更难任务,由求解器在对抗中变强;第三类则是作者提出的元学习驱动进化,也就是让智能体学习一种“如何探索环境并压缩知识”的能力。前两类虽然能提升表现,但都没有摆脱外部任务与流程设计,智能体仍然是在做练习题;第三类的目标更接近原生自进化:在推理阶段不需要人工任务、不需要外部奖励,也不需要固定工作流,而是主动探索未知环境并生成 World Knowledge。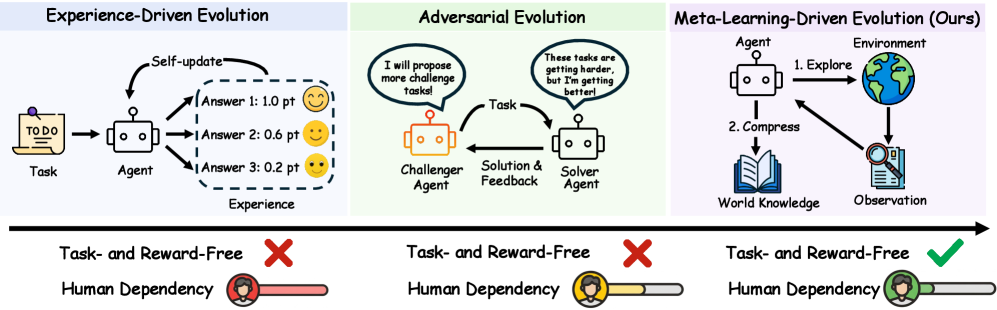
2. 概念与项目对象
2.1 World Knowledge 的含义
项目 README 对 World Knowledge 的定义很直接:它是某个具体环境实例的紧凑结构化表示。在这个仓库里,它通常保存为 Markdown 文件,历史脚本中也会叫 notebook 或 guidebook,这些名字指的是同一类对象。
World Knowledge (K): a compact, structured representation of a specific environment instance.
它不是通用百科,也不是模型参数中的隐式知识。它更像某个网站的环境地图:记录页面类别、URL 前缀、关键事实、导航入口,以及后续任务可能优先访问的位置。
2.2 代码中的术语对应
阅读仓库时,可以先把论文术语和代码术语统一起来。这样再看 questions/、output_note/、problem_generation_with_notebook.py、test_accuracy.py 时,文件之间的关系会清楚很多。
| 论文术语 | 仓库里的常见名字 | 含义 |
|---|---|---|
| World Knowledge | notebook / guidebook | 针对某个环境生成的结构化 Markdown 知识 |
| Native Evolution Phase | Notebook Generation | 先探索网站并生成 World Knowledge |
| Knowledge-Enhanced Execution Phase | CK-pro Test | 带着 World Knowledge 做下游网页任务 |
| Reward / Success | Judge / Accuracy | 用下游任务成功率评价知识是否有用 |
World Knowledge 的价值不在于文档写得多完整,而在于能否帮助 Agent 更快、更准地完成后续任务。比如“ACL 2024 官网包含会议信息”价值有限;写清注册、日程、打印服务、签证页面分别负责什么,才真正能降低探索成本。
2.3 真实输入样例
仓库已经带了会议网站的聚类文件,例如 world-knowledge/data/conference/2024_aclweb_org_clusters.txt。这个文件不是原始 URL 清单,而是经过预处理的网站骨架。
Total: 2 clusters, 31 URLs [SHOW_ALL (< 250 URLs)] | per-cluster sizes: [17, 14]
============================================================
[Prefix] https://2024.aclweb.org (17/17 URLs)
https://2024.aclweb.org [in:31 out:19 score:37]
https://2024.aclweb.org/participants [in:31 out:15 score:36]
https://2024.aclweb.org/calls/main_conference_papers [in:31 out:14 score:35]
https://2024.aclweb.org/faq [in:31 out:12 score:35]
https://2024.aclweb.org/sponsors [in:31 out:10 score:34]
https://2024.aclweb.org/organization [in:31 out:10 score:34]
https://2024.aclweb.org/registration [in:31 out:9 score:34]
其中 in 表示站内入链数,out 表示站内出链数,score 是页面重要性分数。模型不是从首页盲目点击,而是先拿到按 URL 前缀组织、带结构分数的页面列表。
3. 工程链路与关键实现
3.1 总体流程
README 给出的流程可以压缩为四个阶段:先抓取和聚类网站 URL,再生成 World Knowledge;随后把它拼进下游任务;最后运行 CK-pro Agent,并用 LLM judge 和步数统计评估效果。
Target website URLs
-> URL crawl / clustering
-> World Knowledge prompt generation
-> World Knowledge generation
-> Test set construction
-> CK-pro inference
-> LLM-based judging
-> Accuracy / efficiency analysis
对应到仓库文件,可以按下面这张表阅读。这里的 test_efficency.py 是项目原文件名,虽然拼写不是常见的 efficiency,但文章中保留项目实际名称,避免读者找不到文件。
| 阶段 | 关键文件 | 作用 |
|---|---|---|
| URL 爬取 | preprocess/crawl_urls.py |
从种子站点抓同域页面 |
| URL 聚类 | preprocess/cluster_urls.py |
按路径前缀聚类并计算 in/out/score |
| Prompt 生成 | notebook_prompt.py / notebook_prompt_short.py |
把 cluster 文件转成 Guidebook 构建任务 |
| 知识生成 | System.ckv3.ck_main.main |
调网页 Agent 读取真实页面并写 Markdown |
| 任务构造 | problem_generation_with_notebook.py |
把 WebWalker 问题和 notebook 拼成测试输入 |
| 评测统计 | test_accuracy.py、test_efficency.py、calculate_effectiveness.py |
计算准确率和平均步数 |
3.2 URL 爬取与聚类
preprocess/crawl_urls.py 从种子 URL 出发抓同域 HTML 页面。它采用 BFS 方式发现链接,目标是建立当前网站内部页面集合,而不是抓取互联网外部链接。
def crawl_urls(base_url, max_count=MAX_PAGES_PER_URL, max_workers=MAX_WORKERS):
"""BFS crawl to discover same-domain URLs."""
base_url = base_url.rstrip("/")
parsed_base = urlparse(base_url)
base_domain = parsed_base.netloc
脚本只把同域名 URL 放回队列。这样可以避免赞助商官网、社交媒体、地图服务等外部链接污染当前环境知识。
if urlparse(clean_url).netloc == base_domain:
with lock:
if clean_url not in seen_urls:
seen_urls.add(clean_url)
url_queue.put(clean_url)
preprocess/cluster_urls.py 会读取爬虫产出的 URL,过滤 PDF,抓取页面链接关系,再统计站内入链和出链。页面重要性分数来自项目真实代码:
def _importance_score(in_count, out_count):
return in_count + 0.3 * out_count
入链多的页面通常是重要入口,出链多的页面往往是导航页或聚合页。脚本会按这个分数对页面排序,并在大站点中过滤低价值 URL。
ranked = sorted(
members,
key=lambda u: _importance_score(*link_counts.get(u, (0, 0))),
reverse=True
)
小站点会展示全部 URL,大站点会过滤和截断。代码里的阈值是:
SMALL_SITE_THRESHOLD = 250
3.3 Guidebook Prompt 与生成
notebook_prompt_short.py 是理解 World Knowledge 生成约束的关键文件。它要求 Agent 先解析 cluster 文件,再制定 token 分配计划,逐个类别调用网页工具,最后检查总长度。
1. Call parse_cluster_stats() to read the file header and get the total number of URLs and categories.
2. Create a token allocation plan.
3. Process categories one by one.
4. After all categories are processed, check the total length with count_guidebook_tokens().
模板还明确要求每个页面摘要必须来自真实 web_agent() 调用,不能编造内容;每条页面记录必须包含完整 URL;只包含同域页面;用自己的话总结,不能复制网页原文。
Every page summary must come from a real web_agent() call.
Never fabricate or guess content.
Every scraped page entry must include its full URL.
Only include pages from the website's own domain.
每个类别的输出格式也在模板中规定。它要求包含类别名称、URL 前缀、类别摘要和已抓取页面列表,便于人检查,也便于后续 Agent 根据 URL 回到真实页面验证。
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)