艾体宝方案|告别运维数据孤岛:如何为 AIOps 构建统一的上下文 AI 数据底座?
现代 IT 运维团队正面临一个典型的尴尬处境。一方面,我们坐拥海量的运维数据:日志系统里躺着的非结构化文本、APM 工具产生的海量指标和链路追踪数据、CMDB 里存储的资产配置、事件管理系统中不断滚动的事故单。但另一方面,这些数据散落在不同的孤岛中,格式各异,彼此割裂。当系统真正出问题时,On-call 工程师往往需要手动在十多个工具间来回切换,试图在脑海中拼凑出故障的全貌。
现代 IT 运维团队正面临一个典型的尴尬处境。一方面,我们坐拥海量的运维数据:日志系统里躺着的非结构化文本、APM 工具产生的海量指标和链路追踪数据、CMDB 里存储的资产配置、事件管理系统中不断滚动的事故单。但另一方面,这些数据散落在不同的孤岛中,格式各异,彼此割裂。当系统真正出问题时,On-call 工程师往往需要手动在十多个工具间来回切换,试图在脑海中拼凑出故障的全貌。
这便是传统 AIOps 项目常常面临的第一个问题:数据没有做好打硬仗的准备。我们花费巨资引入机器学习模型或大语言模型(LLM),期望它能自动发现异常、定位根因,但它们面对的却是“脏”、孤立、且缺乏上下文的数据。
那么,一个真正能为 AI 助手提供强大动力的基础设施应该长什么样?它至少需要解决四个核心问题:打破数据孤岛的统一建模、对复杂关系的深度理解、持续为 AI 提供高质量业务上下文,以及支撑未来自动化 Agent 的高可信基础。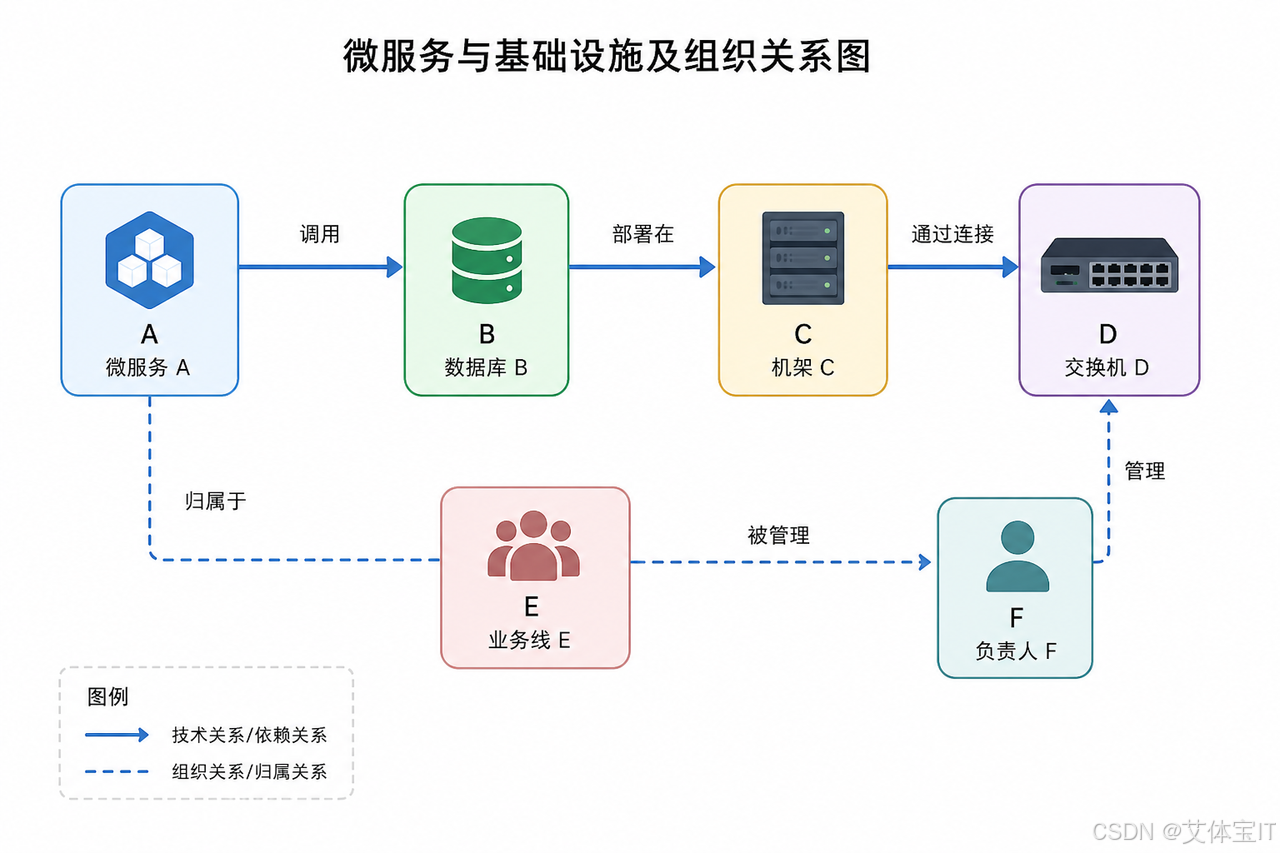
第一步:用“上下文平台”视角统一一切,重塑数据底座
运维世界的核心,其实不是一个个孤立的数字,而是“关系”。微服务 A 调用数据库 B,部署在机架 C 上,由交换机 D 连接,归属于业务线 E,被负责人 F 管理。这天然就是一张复杂的图。
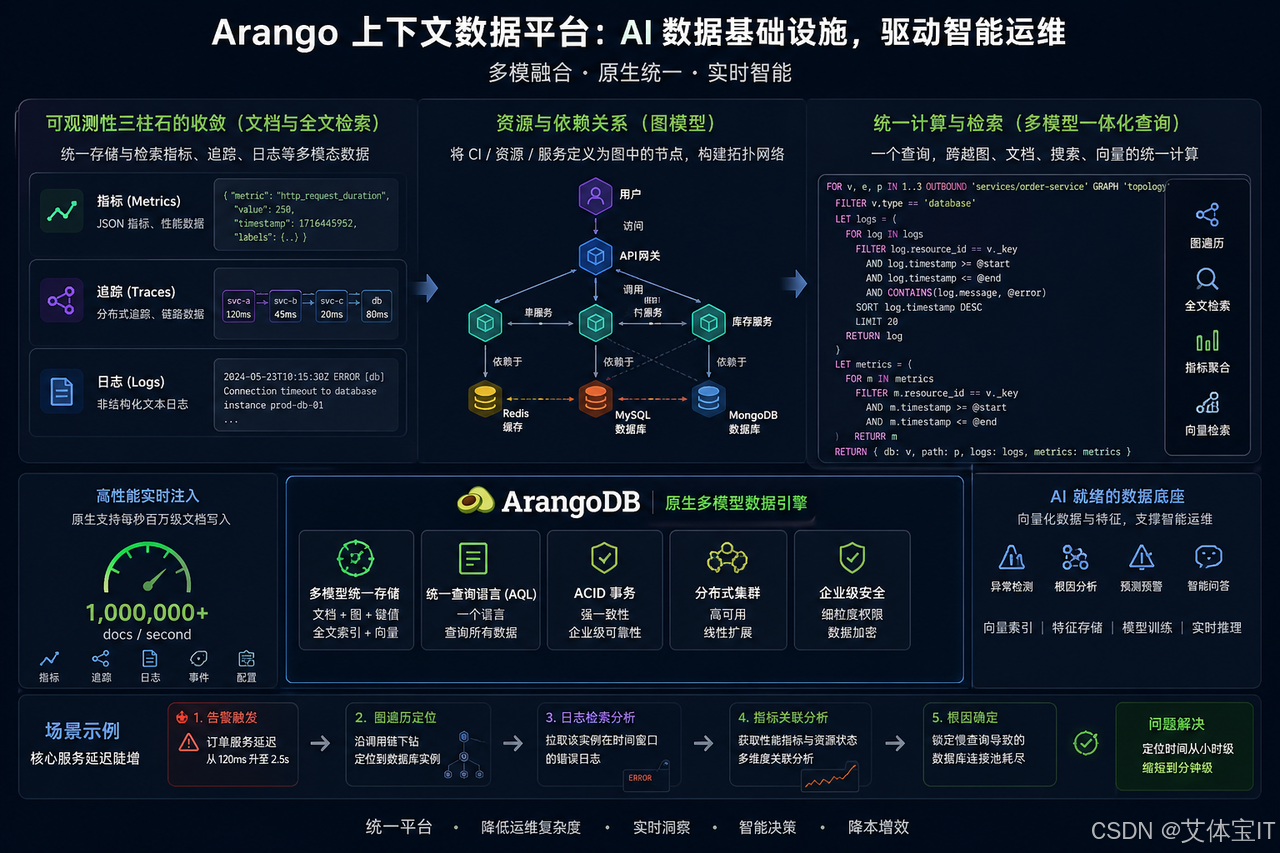
在过去,解决这个问题意味着拼凑多个专用的垂直数据库,并搭建脆弱的数据同步流水线。而 Arango 上下文数据平台(Contextual Data Platform)在这个场景下的核心价值,并非它仅仅是一个数据库工具,而是它提供了一套完整的 AI 数据基础设施。它以原生的多模型数据引擎为底座,将运维领域的多模态数据进行了统一融合:
- 可观测性三柱石的收敛(文档与全文检索):平台原生内置了搜索引擎和文档存储能力。复杂的 JSON 格式指标、分布式的 Trace 追踪链路,以及海量的非结构化文本日志,无需再分别存入 TSDB、ES 或 Hadoop,而是以统一的文档模型高效存储并支持分词检索。
- 资源与依赖关系(图模型):同时,它又能将主机、容器、微服务等 CI 项定义为图中的节点,原生构建出“部署于”、“调用”、“依赖”等拓扑网络。
- 统一计算与检索:想象一个场景,核心服务延迟陡增。在 Arango 的统一架构下,无需切换系统,一个查询就能从报警的微服务节点出发,沿着“调用”边迅速下钻到有问题的数据库实例,同时拉取该实例在特定时间窗口的错误日志与向量化数据。其平台底座可持续支撑每秒百万级文档的实时注入,完美契合海量运维数据的并发要求。
第二步:超越点状告警,赋能复杂的因果推理与告警收敛
单个数据点的异常往往噪音巨大,因关系导致的问题才需要警惕。真正的根因分析,其核心是理解故障如何在依赖图中传播。当“订单服务”报错时,根源可能是其依赖的“支付服务”所配置的“加密证书”过期。如果仅凭独立的告警,这条因果链极易被淹没,导致运维人员面临“告警风暴”。
Arango 平台不仅仅提供数据的存储,更提供了强大的图计算与 AI 推理能力。其统一查询语言 AQL 支持深度不定的图遍历,能高效追溯所有上游依赖路径。更重要的是,平台原生集成的 AI 套件,能对复杂的因果分析查询进行深度分析与自动重写。
借助这种图结构,企业可以轻松实现高维度的“告警收敛”。 你甚至可以在平台中预定义“反模式”子图(例如:“一个数据库节点同时被超过 5 个不健康的微服务连接”),直接作为高维度的故障判定规则。配合 SmartGraphs 等智能分片技术,即使关系图膨胀到数十亿节点规模,平台也能通过将强关联的业务数据“协同部署(Co-locate)”以降低网络开销,让大规模实时拓扑推理成为现实。

第三步:为 LLM 装上“关系大脑”,实现高准确率的 HybridRAG
大语言模型(LLM)能说会道,但在解决私有环境的运维问题时极易产生“幻觉”:它不知道你凌晨 3 点刚对 Ceph 集群做过扩容,也不懂内部诡异的错误码“XFS-442”意味着什么。
Arango 上下文数据平台为 AI 提供了高级别的 RAG 支持。这里不仅指单一的向量检索,而是平台原生集成的 HybridRAG(混合检索生成)能力。 在复杂的运维排障中,单一的向量检索往往不够精准(例如查询特定 IP 或错误码),而纯图谱查询又难以理解日志的自然语义。Arango 平台独特地将向量搜索(VectorRAG)、图遍历(GraphRAG)以及全文精确匹配(BM25)融为一体。
当运维工程师问:“凌晨的业务中断是什么原因导致的?” 平台的处理不仅是检索,而是构建立体的上下文:
- 图谱精确定位:首先在知识图谱中精准定位“凌晨”与“中断节点”,拉取周边的确切拓扑和历史变更记录。
- 多模态混合召回:结合向量搜索和全文检索,从海量非结构化日志、Runbook 和历史事故单中,找回语义最相关且关键字精确匹配的排障指南。
- 打包输送给大模型:平台将这一揽子“结构化关系 + 非结构化语义”的纯净上下文,连同原始问题一起喂给 LLM。
此时,LLM 拿到的不再是盲目的猜测,而是一份包含精确故障链的“小抄”。因为分析的源头和路径在底层平台中是完全可追溯的,这直接为 AI 的决策赋予了企业级的可解释性与信任度。
第四步:从 Copilot 到 AI Agent,支撑多智能体自动化运维
未来的 AIOps 将不再局限于人类问、AI 答的“副驾驶(Copilot)”模式,而是走向由 AI Agent(智能体)自主规划和执行修复动作的“自动驾驶”时代。 例如:Agent 在发现内存溢出后,自动触发日志分析、评估影响面并执行重启或扩容脚本。
要让 Agent 敢于在生产环境执行操作,它必须拥有一个高度可靠的“状态与记忆中枢”。Arango 上下文数据平台正是多智能体(Multi-Agent)并发工作负载的理想基座。它不仅为 Agent 提供决策所需的拓扑上下文,还凭借其 ACID 事务保证和高性能写入,实时记录各个 Agent 的思考过程、执行动作和状态变迁。多个运维 Agent(如网络排障 Agent、数据库优化 Agent)可以基于同一个统一的数据底座协同工作,避免因数据不同步导致的误操作。
实际工程收益的再思考:TCO、工作流与企业级治理的全面革新
最终,Arango 上下文数据平台给运维团队带来的,不仅仅是一个酷炫的 AI 工具,而是工作流重塑、基础设施收敛与企业级数据治理的全面升级。
- 内置的治理与信任机制:在企业级 IT 中,安全与权限是生命线。Arango 平台并非像外挂工具那样事后修补权限,而是原生内置了集中式访问控制策略、字段级的安全隔离、数据血缘追踪与完整的审计能力(Auditability)。这确保了 AI 只能看到它该看的运维数据,满足严格的合规要求。
- 显著降低总拥有成本(TCO):将图谱、向量、文档和全文检索收敛至单一平台,不仅消除了脆弱的数据同步流水线(Brittle pipelines),更大幅削减了维护多种专用数据库的软硬件和人力成本。
在真实案例中,电信运营商 Telenor 利用该方案对数万条机器日志进行上下文关联分析,大幅提升了事件检测能力。同时,其底层平台保证了关键运维数据的正确与合规——这是走向自动化响应场景的底线要求。某制造企业通过整合 ERP 与 IoT 孤岛数据,将库存持有成本降低了 30%,更印证了统一上下文在跨业务融合场景中的巨大商业价值。
在通往高阶智能运维的道路上,选择合适的 AI 数据基础设施,本质上是在选择一种对数据和上下文的组织哲学。Arango 上下文数据平台的哲学正是:承认业务关系的价值,在底层打通多模态数据,告别脆弱组件,为未来的 AI 与 Agent 持续输送最精准、最可信的业务上下文。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)