AI Agent学习日记 Day4
上周Claude code的源码泄露了,大家都在学习和分析,我也打算借鉴其中的一些实现方法和优秀思想。首先我把Claude code的双重熔断机制加进了我的Agent。
上周Claude code的源码泄露了,大家都在学习和分析,我也打算借鉴其中的一些实现方法和优秀思想。首先我把Claude code的双重熔断机制加进了我的Agent。
Claude code整体流程图(抄的)
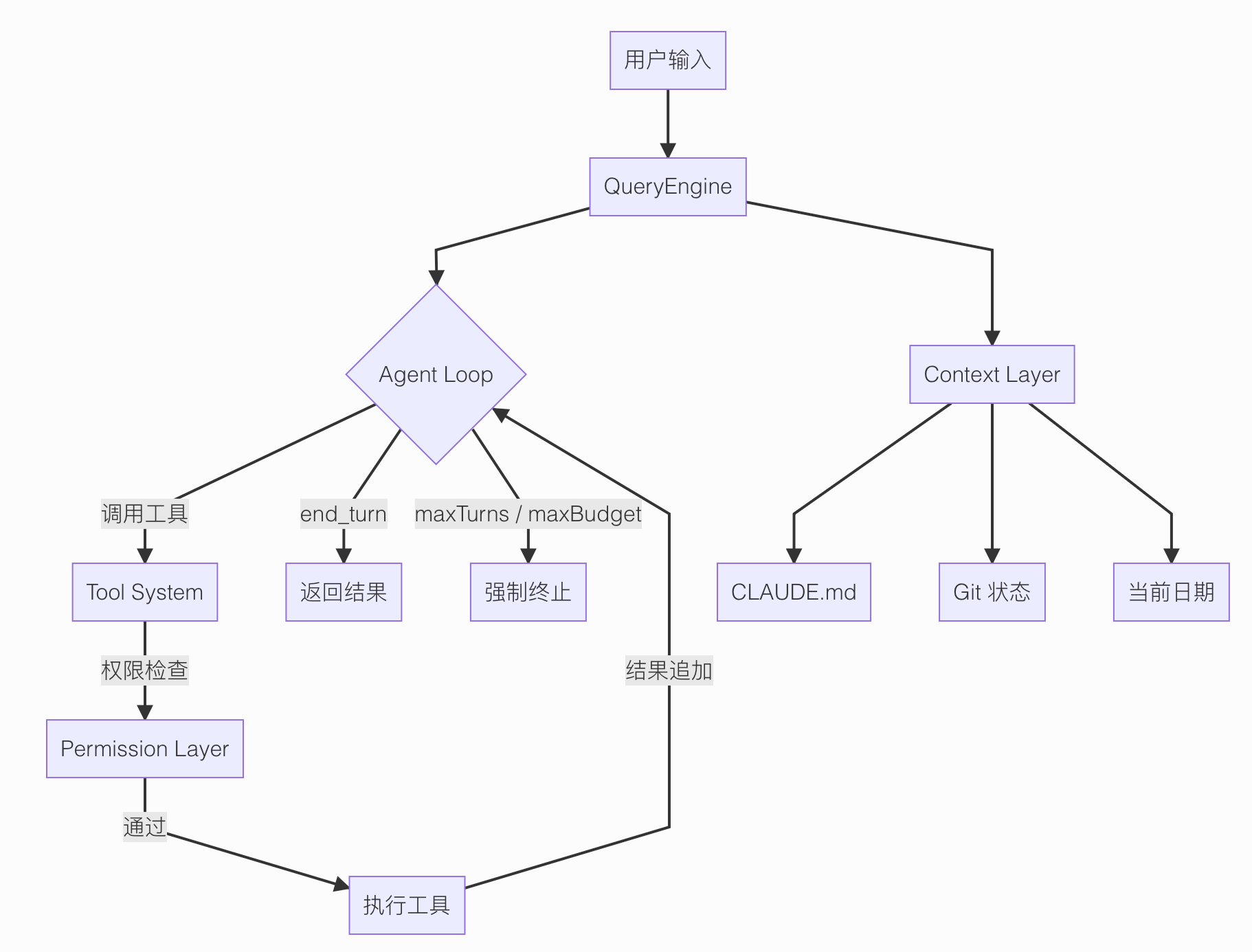
双重熔断机制实现分析
Claude Code 的实时 Token 计数机制
Claude code的最大token数是Token 实时累计,它不是等一次完整对话结束才算用了多少 token,而是每收到一段流式响应,就立刻把这段的 token 用量累加进去。Claude API 的流式响应中,token 使用量并不在 content_block 或 text 事件中,而是在单独的 message_delta 事件中发送。Claude Code 在收到 message_delta 时立即累加 usage.output_tokens,同时 message_start 中也有 usage.input_tokens。
QueryEngine.ts 第 789 行
if (message.event.type === 'message_start') {
// 新消息开始,重置本条消息的计数
currentMessageUsage = EMPTY_USAGE
currentMessageUsage = updateUsage(
currentMessageUsage,
message.event.message.usage,
)
}
if (message.event.type === 'message_delta') {
// 流式增量,立刻累加
currentMessageUsage = updateUsage(
currentMessageUsage,
message.event.usage,
)
}
if (message.event.type === 'message_stop') {
// 一条消息结束,追加到全局总量
this.totalUsage = accumulateUsage(
this.totalUsage,
currentMessageUsage,
)
}LangChain 的 Token 计数限制
Langchain的on_chat_model_stream 事件中的 chunk 通常是一个 AIMessageChunk,它的 usage_metadata 字段在流式过程中为 None,只有最后一块(或者调用结束时)才会有值。正包含完整 usage_metadata 的是 on_chat_model_end 事件中的 output(一个完整的 AIMessage)。所以我的实现是在每次on_chat_model_end的时候统计消耗的token数。
代码实现
elif kind == "on_chat_model_end":
# 获取完整的 AIMessage(不是 Chunk)
output_msg = event["data"]["output"]
# 提取 token 用量
input_toks = 0
output_toks = 0
try:
if hasattr(output_msg, "usage_metadata") and output_msg.usage_metadata:
input_toks = output_msg.usage_metadata.get("input_tokens", 0)
output_toks = output_msg.usage_metadata.get("output_tokens", 0)
except Exception as e:
print(f"提取 token 失败: {e}")
total_input_tokens += input_toks
total_output_tokens += output_toks
total_all_tokens = total_input_tokens + total_output_tokens循环控制机制实现
在 LangGraph(包括 create_agent 底层使用的图)中,recursion_limit 限制的是图中节点被执行的次数,而不是“LLM 调用次数”或“用户感知的回合数”。
一个典型的 ReAct Agent 图结构大致如下:
agent_node (调用 LLM) -> should_continue (条件边) -> tools_node (执行工具) -> 回到 agent_node
每执行一次 agent_node 或 tools_node 都算一个“step”。这虽然和Claude code的Agent循环次数不太一样,但是换汤不换药,都可以用来表示Agent执行的次数。
实现代码
在config里写上"recursion_limit": MAX_TURNS,然后再在调用astream_events的时候加上config参数就行了
config = {
"configurable": {"thread_id": "1"},
"recursion_limit": MAX_TURNS
}
event_stream = st.session_state.agent.astream_events(
{"messages": [HumanMessage(content=user_input)]},
config=config,
version="v2"
)遇到的问题
需要在创建大模型的时候加上stream_options={"include_usage": True},否则在返回的AIMessage里不会包含usage_metadata,也就无法获取到token信息。
LLM = ChatOpenAI(
model="qwen3.5-plus",
temperature=0.1,
api_key=DASHSCOPE_API_KEY,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
timeout=300,
extra_body={"enable_search": True},
stream_options={"include_usage": True},
)astream_events是异步的,当触发熔断的时候需要显示关掉异步生成器。否则它仍在后台运行,会持续向 LangSmith 发送追踪事件,LangSmith上面Agent执行就会显示pending。
if total_all_tokens >= MAX_BUDGET_TOKENS:
should_stop = True
token_placeholder.markdown(f"🚨 **预算超限!累计 {total_all_tokens} token 已达到上限 {MAX_BUDGET_TOKENS},任务终止。**")
await event_stream.aclose()
break
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)