用什么来搭建知识库(写给小白的LLM工具选型系列:第六篇)
本文介绍AI知识库(RAG)的基本原理与搭建方案。首先用图书馆索引类比解释向量化、向量数据库和检索增强生成的概念,说明AI知识库通过将文档转换为向量并存储,实现语义检索与智能回答。接着对比三类主流方案:一键式托管产品(如腾讯IMA)、半托管低代码工具(如PandaWiki)和完全自定义方案(如AnythingLLM),分析其优缺点、成本及隐私控制。最后提供30分钟实操教程,演示使用OpenAI嵌入
(本文为AI生成,未做人工验证,也未列出参考资料。以后可能会更新)
本文面向小白读者,介绍基于AI的大规模知识库(RAG)的基本原理和常见方案。我们首先用通俗类比说明向量化、向量数据库和检索增强生成(RAG)的概念;然后系统对比一键式托管产品、半托管/低代码方案和完全自定义方案(如 AnythingLLM 等)的优缺点、成本和隐私控制;接着给出一个可在30分钟内完成的实操教程,包含必要的命令、示例代码和示例数据;最后讨论部署维护、成本估算、隐私合规建议和后续拓展方向,并列出相关资源链接和练手项目建议。本文力求浅显易懂,让初学者快速入门 AI 知识库构建。
1. AI知识库基础原理
AI知识库的核心就是把大量文档(如PDF、Word、网页等)转换成计算机能处理的“向量”形式,并借助大语言模型(LLM)进行智能检索与生成。**向量化(Embedding)**可以简单理解为:将一句话或一个文档转换成一组数字,就像给文本打上一个独特的“坐标标签”。机器只能处理数字,因此需要把文字、图像或音频等数据映射到向量空间。这类似于把每本书在图书馆的索引卡上标记一个独特的编号,便于后续查找。Embedding 模型(如BERT、sentence-transformers或 OpenAI 的 text-embedding-ada-002)就是经过训练的神经网络,用来生成高质量的文本向量。
这些向量表示连同原始文档片段一起存入向量数据库(Vector DB),这是专门管理高维向量的新型数据库。与传统的表格化数据库不同,向量库把文档映射到多维空间中,用向量间的距离来衡量语义相似度。这使得系统能够理解不同文本之间的含义关联,在不依赖关键词完全匹配的情况下快速检索信息。
在用户查询阶段,系统把用户问题同样向量化(可以理解为把用户问题在同一坐标系中标记位置),然后在向量数据库中找到最相似的文档片段。这一过程就是检索(Retrieval)。最后,将检索到的相关文档片段与原始问题一起输入大语言模型,让模型生成包含这些知识的自然语言回答。这一将“先检索后生成”的混合模式称为检索增强生成(RAG):通过引用外部权威知识库的信息,让AI生成的答案更加准确可靠。
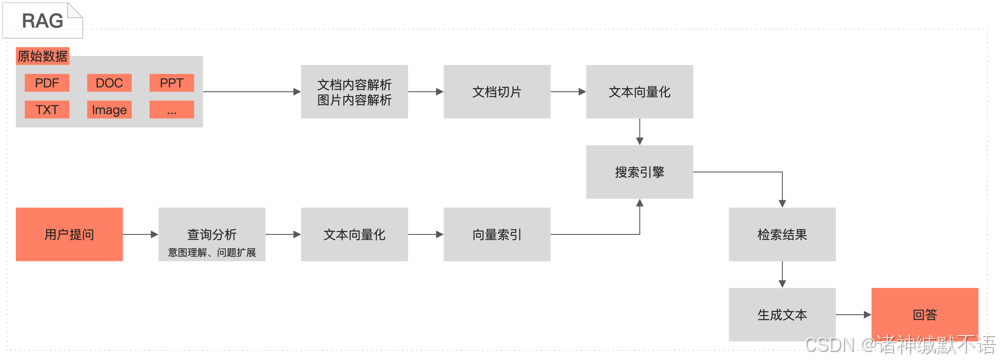
图示:RAG(检索增强生成)技术流程示意图。左侧展示数据处理和索引阶段:首先解析各种格式的原始文档(PDF、DOC、图片等),将文档切片并向量化存入数据库;右侧展示查询阶段:用户提问被向量化后进行语义检索,找到最相关的文档片段后送入语言模型生成最终答案(对话即回答)。
简而言之,AI知识库相当于给你的文件和知识内容建立了一个“语义索引”,就像图书馆在每本书上贴上智能标签。用户提问时,系统先“去书架”中找出最相关的书页(检索),再请“大脑”(语言模型)根据这些书页内容进行回答(生成)。这样的设计既保留了强大语言模型的表达能力,又能结合外部事实知识,既提高了回答的准确性,也方便随时更新知识库而不需重训模型。
2. 主流搭建方案对比
根据自动化程度和可定制性,AI知识库搭建方案大致可分为三类:一键式托管产品、半托管/低代码方案,以及完全自定义方案。下表比较了每种方案的代表工具、主要优缺点、成本投入、上手难度、可扩展性及隐私控制等方面。
| 方案类型 | 代表产品/工具 | 优点 | 缺点 | 成本 | 难度 | 可扩展性 | 隐私控制 |
|---|---|---|---|---|---|---|---|
| 一键式/托管产品 | 如腾讯 IMA 知识库、Youdao QAnything、ChatGPT(插件)等 | - 零编程,上手简单 - 云端自动维护,更新方便 - 方案成熟、用户界面友好 |
- 功能固定,灵活性低 - 依赖厂商服务,可能有配额或订阅费用 - 数据托管在第三方,隐私可控性差 |
一般免费起步,商业版本或扩容需付费 | 低 | ★★★☆☆(取决于服务商扩容能力) | ★☆☆☆☆(需信任供应商,数据托管在云端) |
| 半托管/低代码方案 | 如 PandaWiki(开源一行Docker部署)、ChatWiki、MaxKB、企业私有化产品等 | - 配置简单,部分开源,可定制性中等 - 多提供可视化界面、API 接口 - 支持多模型切换(如ChatWiki支持多达20+模型) |
- 通常需少量配置或部署;功能虽丰富但仍有局限 - 免费开源版功能可能简化,企业级版收费 |
一般开源免费,商业版或高级功能收费 | 中等 | ★★★★☆(大多支持自托管和云扩展) | ★★★☆☆(可私有化部署,数据留在企业;但视具体产品而定) |
| 完全自定义方案 | 如 AnythingLLM、基于 LangChain/LlamaIndex 自行集成(需选模型、向量化工具、向量库、检索器等) | - 灵活度最高,功能可按需扩展 - 完全开源可控,可接入任意模型和工具 - 隐私安全,数据可全程自行管理 |
- 需要专业技能和更多开发运维投入 - 初期搭建较复杂,需要选型并集成多个组件 - 维护成本高(自行升级、调试) |
开源免费,硬件/云资源和开发投入可能较高 | 高 | ★★★★★(几乎无限,视资源和架构而定) | ★★★★★(可100%自行部署,数据不出内网) |
- 一键式/托管产品:如腾讯 IMA 知识库是典型代表,依托大型云端模型和RAG技术为用户提供知识问答服务。它们优势在于无需部署、即开即用,但缺点是定制化能力弱,且使用时需联网并信任第三方保存知识数据。多数此类产品免费版功能有限,企业版可能需要按量付费。
- 半托管/低代码方案:以 PandaWiki、MaxKB、ChatWiki 等为例,这些工具一般提供图形化管理面板和API,开源版本可在私有服务器上部署。它们对用户更友好,部分功能一体化(如权限管理、单点登录、审计日志等),适合希望较快部署而又需一定可控性的企业用户。不过仍需一定的技术配置,且部分高级特性或企业版可能收费。
- 完全自定义方案:如使用 AnythingLLM 框架或者自行使用 LangChain、LlamaIndex 等搭建。这种方式要求自主选择和管理模型、嵌入器、向量数据库(如Chroma、Milvus等)和检索器。优点是高度自由,可精细化地优化各环节,且数据安全性最高,因为可以全程本地化部署。缺点是入门门槛高,需要较强的工程能力和部署维护经验。
综上,各方案的成本与难度趋于成正比:一键式产品成本低、易上手但灵活性和可控性有限;完全自定义灵活且私密性好,但投入更多。读者可根据实际需求(如是否有开发能力、数据是否敏感、预算等)选择合适方案。
3. 30分钟实操教程
以下我们演示一个30分钟内可完成的知识库搭建示例,假设读者使用Windows/Linux均可(操作系统未指定时,两者操作类似)。这里选择使用云端API的混合方案:OpenAI 嵌入 + Pinecone 向量库 + OpenAI 生成模型。若读者没有网络或API密钥,可将OpenAI 嵌入替换为Sentence-Transformers模型,本地搭配Chroma等开源向量库,过程类似,下文也会注明。
-
准备环境和数据
- 确保已安装 Python 3.8+。若未指定操作系统,可以先安装 Python 并配置环境变量。
- 准备示例文档,将几份文本资料(如
.txt或.pdf)放入同一文件夹。这里假设有doc1.txt、doc2.txt。内容示例:# doc1.txt 人工智能技术可以帮助我们快速检索和总结信息。知识库是组织化的信息集合... # doc2.txt 检索增强生成(RAG)结合了检索模型和生成模型的优势,用于提高大模型回答的准确性... - 打开终端(Windows 用 CMD/PowerShell,Linux 用 bash)。进入文档所在目录。
-
安装依赖
pip install openai pinecone-client这里我们使用 OpenAI 提供的
text-embedding-ada-002模型生成文本向量,并用 Pinecone (需注册,提供免费层)存储向量检索。无API密钥时,可改用本地替代方案:pip install sentence-transformers chromadb以后查询时,示例中用 OpenAI 的API,在无网络时可以使用SentenceTransformers生成嵌入、用 Chroma 存储向量。
-
初始化向量数据库
- 注册并登录 Pinecone(https://www.pinecone.io),获取 API 密钥和环境名称。
- 在 Python 中连接 Pinecone:
这里import pinecone pinecone.init(api_key="你的Pinecone_API密钥", environment="你的环境名") index_name = "my-knowledgebase" if index_name not in pinecone.list_indexes(): pinecone.create_index(index_name, dimension=1536) index = pinecone.Index(index_name)1536是text-embedding-ada-002的向量维度。若使用其他模型或本地Sentence-Transformer,需对应调整维度。
-
文档向量化与索引
- 将文档切片并生成向量,然后存入 Pinecone。简单起见,我们按全文做一个向量:
如果用本地Embedding替代,可使用:import openai openai.api_key = "你的OpenAI_API密钥" docs = {"doc1": "人工智能技术可以帮助我们快速检索...", "doc2": "检索增强生成(RAG)结合了检索模型和生成模型..."} embeddings = [] for doc_id, text in docs.items(): res = openai.Embedding.create(model="text-embedding-ada-002", input=text) vec = res['data'][0]['embedding'] embeddings.append((doc_id, vec)) # 向索引中插入向量 index.upsert(vectors=embeddings) print("向量已插入索引")
常见错误:如果提示维度不匹配,请确认创建索引时的from sentence_transformers import SentenceTransformer model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') for doc_id, text in docs.items(): vec = model.encode(text).tolist() index.upsert(vectors=[(doc_id, vec)])dimension与模型输出维度一致;网络错误时请检查API密钥和网络连接。
- 将文档切片并生成向量,然后存入 Pinecone。简单起见,我们按全文做一个向量:
-
执行检索问答
- 接下来模拟用户提问,例如:“什么是知识库?”
query = "知识库的作用是什么?" # 嵌入用户查询 qres = openai.Embedding.create(model="text-embedding-ada-002", input=query) qvec = qres['data'][0]['embedding'] # 从向量库检索最相似的文档(假设取前2条) result = index.query(vector=qvec, top_k=2, include_values=False) doc_ids = [match['id'] for match in result['matches']] print("检索到的相关文档片段:", doc_ids) context = "\n".join(docs[did] for did in doc_ids) # 使用GPT生成答案 prompt = f"根据以下资料回答:{context}\n\n提问:{query}\n回答:" resp = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}]) answer = resp['choices'][0]['message']['content'] print("AI回答:", answer)- 如果使用本地模型,最后一步可改为调用如 GPT4All 等开源模型;或者返回上下文片段供人工参考。
- 常见错误:询问后返回“未检索到结果”时,可检查向量库插入是否成功;生成回答时若出现“token过长”错误,可缩减提供给模型的上下文长度。
- 接下来模拟用户提问,例如:“什么是知识库?”
以上步骤完成后,一个简单的知识库问答系统就能运转起来:向量化的文档被索引,用户提问后系统会在知识库中检索相关内容并结合 LLM 生成回答。整个过程示意如下(可自行尝试更多文档与查询,验证效果)。
4. 部署、维护与后续扩展
部署与维护: 对于生产环境,可将上述流程容器化部署(如用 Docker 部署后端 API、向量库服务和调度脚本),并使用如 Kubernetes/1Panel 等工具保证服务高可用和日志监控。文档更新时应重新执行向量化并更新索引(可采用增量更新策略);性能优化可选用GPU加速或更快的嵌入模型,提高向量化速度。若知识内容持续增长,需评估向量库存储和检索开销。
成本估算: 若使用云API,以 OpenAI 为例,每条文本嵌入约 0.0004 美元(text-embedding-ada-002),生成回答按每千tokens计费;Pinecone等托管向量库也有免费额度,超出后按向量数或请求量收费。完全自建方案则主要考量硬件和维护成本(如购买服务器)。总体而言,小规模个人或中小企业级知识库搭建和使用成本可控(尤其可选本地化免费方案)。
隐私与合规: 对于包含敏感/个人信息的文档,强烈建议本地部署或使用私有云,确保数据不泄露到第三方。托管服务商的商业协议中注意数据使用条款(有些服务明确不将用户数据用于模型再训练)。确保合规性,例如对客户数据要符合《数据安全法》等相关规定;也应对访问进行权限控制和审计。
后续扩展: 一旦基础知识库运行稳定,可考虑引入以下功能:
- 接入自有模型:如引入国产大模型(DeepSeek R1、Qwen、MixedLM 等)或开源模型,满足特定语言/行业需求。
- 多模态知识库:将图片、音频等信息向量化并集成检索,例如使用 OCR 将图片内容提取文本,或使用 CLIP 等模型处理图像与文本混合检索。
- 自动化更新:结合消息队列或文件监测,实现新的文档自动入库;定期检查文档时效性,触发重索引或人工复核。
- 高级检索策略:例如混合检索(语义+关键词),以及结果去重、排序优化,提升检索准确度。
- 功能迭代:可增加问答监控和反馈机制,将用户纠错或不满意的回答用于系统优化,或者引入人机协同流程(如问答有歧义时自动寻求人类确认)。
5. 推荐资源
- 官方文档与标准:OpenAI 嵌入模型文档;阿里云 RAG 构建指南;Pinecone 快速开始;LangChain、LlamaIndex 项目主页和文档。
- 开源项目:AnythingLLM (全平台AI应用集成工具);PandaWiki(开源AI知识库系统);MaxKB(企业级RAG问答系统)。
- 技术博客:FastGPT 《知识库基础原理介绍》;人人都是产品经理《RAG企业实战》;CSDN 相关文章如“向量化入门”、“RAG原理解读”等。
- 工具平台:腾讯 IMA 平台文档和教程(如 Tencent IMA 使用心得);Youdao QAnything(网易有道本地知识库问答系统);DeepSeek RAG 案例(DeepSeek 社区教程)。
- 中文社区:CSDN、掘金、知乎等上关于“个人AI知识库搭建”、“RAG落地实践”的系列文章,以及开发者论坛常见问答。
6. 练手项目建议
- 个人文档问答助手:选取自己的学习笔记或工作文档(如项目手册、API文档等),搭建一个知识库,训练AI助手回答相关问题。可以使用开源模型和本地向量库,实践RAG全流程。
- FAQ智能机器人:收集一个主题的常见问题与答案(如大学课程常见问答、产品说明FAQ),构建知识库并开发问答机器人,将语义检索和LLM相结合,让聊天机器人可以应对这些问答。
- 混合检索搜索引擎:使用开源工具(如 Elasticsearch + SentenceTransformers)搭建一个小型搜索系统,实现既支持关键词检索又支持语义检索,比较两种检索方式的回答效果。可以选取新闻语料或百科条目进行试验,体验RAG检索前后效果的差异。
以上练手项目都可以帮助巩固对向量化、检索和生成技术的理解,同时培养对不同方案部署的实践能力。希望读者通过本文对AI知识库有全面了解,并能迅速动手实践,构建适合自己的智能知识库。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 0
0 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)