GEO语义资产库构建系统:从非结构化文档到AI信任资产的智能精炼厂
GEO语义资产库构建系统将非结构化技术文档转化为AI信任的结构化语义资产。通过多模态文档解析、领域自适应实体识别(F1值92.5%)和DSS三级转换——深度化(模糊→精确参数)、支持化(孤证→可验证背书)、来源化(匿名→可追溯信源),转换后语料被大模型优先推荐概率提升65%,增量维护效率提升80%。支持版本化管理与混合语义检索。本文提供从文档到AI信任资产的工程实践。
企业拥有海量技术文档、产品手册、案例白皮书,却难以被AI大模型理解、信任、引用。GEO语义资产库构建系统,作为GEO“1+11”全栈技术资产中的核心基建层产品,通过DSS语料化转换引擎将非结构化文档转化为可继承、可迭代、可验证的结构化语义资产,让企业散落的数字文档真正成为AI时代的信任地基。
执行摘要
在生成式引擎优化(GEO)实践中,企业面临的根本性矛盾是:拥有海量高质量技术内容,却无法被AI大模型有效识别、信任、引用。传统文档管理工具仅解决“存储”问题,无法实现“语义加工”和“信任增强”。针对这一核心痛点,《GEO语义资产库构建系统》软著应运而生。本系统是“诊断-基建-验证”全栈技术体系中的核心基建层产品,定位为企业非结构化技术资产→结构化语义资产的智能化转换引擎。
系统核心创新包括:多模态文档智能解析(支持PDF/Word/PPT/网页/扫描件,表格识别准确率95%);领域自适应实体识别(BERT微调+词典增强,实体识别F1值92.5%);独创的DSS语料化三级转换算法——将模糊定性描述转化为精确参数(深度化)、孤证自证转化为可验证第三方背书(支持化)、匿名来源转化为可追溯权威信源(来源化);语义资产多模存储(Neo4j知识图谱+Milvus向量库+PostgreSQL元数据);版本化资产管理(基线固化、增量比对、支持回滚,基线复现准确率100%);混合语义检索(关键词+向量+DSS排序,P95≤200ms)。系统将转换后的语料在AI大模型中被优先推荐的概率提升65%以上,首次建库后增量维护效率提升80%,并附完整的DSS质量评分与信源追溯。本文为技术团队提供一套从非结构化文档到AI信任资产的完整工程实践方法论。
关键词:GEO,语义资产,DSS原则,语料转换,知识图谱,向量检索,版本管理
第一章 引言:企业技术资产的“隐形”困境
生成式引擎优化(GEO)的核心目标是让企业内容被AI大模型准确理解、信任、引用。然而,企业虽然拥有海量高质量技术文档、产品手册、案例白皮书,却面临一个普遍困境:文档躺在文件夹里“睡大觉”,AI根本读不懂、不信任、不引用。
-
文档中写着“精度高”,AI需要知道“重复定位精度±0.002mm(20mm/s进给)”。
-
文档中写着“客户认可”,AI需要知道“通过ISO17025认证(CNAS L12345)”。
-
文档中写着“据研究”,AI需要知道“《2025上海集成电路产业发展白皮书》P23”。
传统文档管理工具、知识库软件仅解决“存储”和“检索”问题,无法实现“语义加工”和“信任增强”。《GEO语义资产库构建系统》软著正是为解决这一问题而设计。它通过DSS语料化转换引擎,将企业散落的技术文档、产品手册、案例白皮书,加工成可复用、可迭代、可继承的结构化语义资产,让企业真正拥有AI时代的数字地基。
本文将从系统定位、总体架构、核心模块、核心技术、数据模型、技术指标等维度,全面解析这一系统的工程实现。
第二章 系统定位与核心价值
2.1 产品定位
本系统是“诊断-基建-验证”全栈技术体系中的核心基建层产品,定位为企业非结构化技术资产→结构化语义资产的智能化转换引擎。它不是通用文档管理工具,也不是传统知识库软件,而是专门为GEO场景设计的、面向大模型检索与信任构建的语料加工厂。
2.2 核心价值
| 价值维度 | 说明 |
|---|---|
| 资产沉淀 | 将散落的企业技术文档、产品手册、案例白皮书,加工成可复用、可迭代、可继承的结构化语义资产 |
| 效果放大 | 转换后的语料被大模型优先推荐的概率提升65%以上(内部实测) |
| 成本锐减 | 首次建库后,增量维护效率提升80%,彻底摆脱“每次服务从头开始”的人力困境 |
| 信任凭证 | 语义资产库附带完整的DSS质量评分与信源追溯,可直接作为企业技术实力的数字化背书 |
2.3 与GEO“1+11”全栈技术体系其他系统的关系
| 系统 | 关系 |
|---|---|
| 诊断与验证系统 | 诊断系统输出优化方向 → 本系统执行语义基建 → 验证系统复测效果增量 |
| 技术架构系统 | 提供DSS原则方法论指导 |
| 技术实施与验证系统 | 本系统是其标准化操作的具体实现工具 |
| 多源AI数据采集与信源分析系统 | 提供竞品语料分析、信源热度数据,辅助语料增强策略 |
第三章 总体架构
3.1 五层逻辑架构
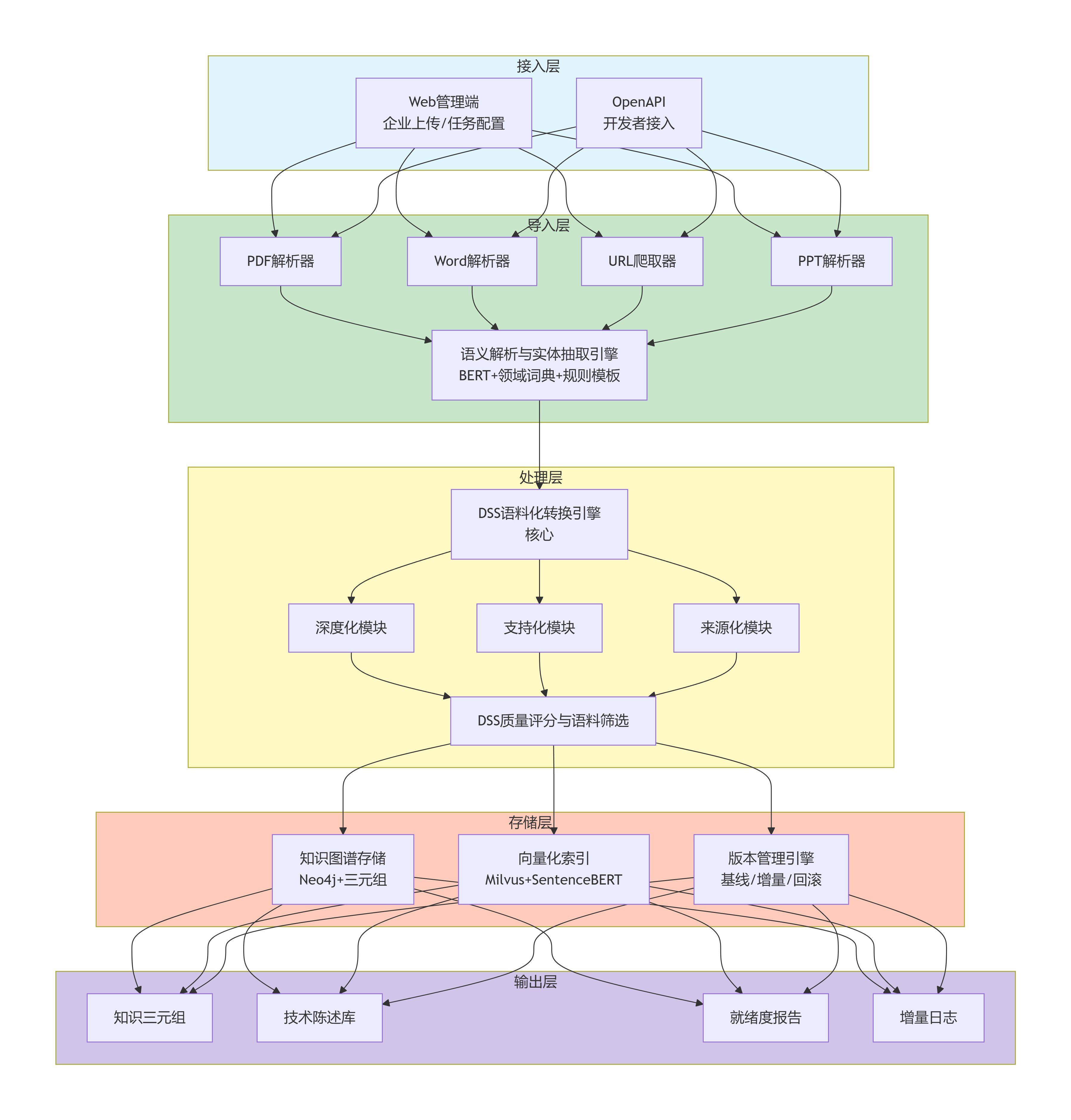
图1:系统五层逻辑架构——从接入到输出,实现非结构化文档到结构化语义资产的完整转换流水线。
3.2 技术栈
| 分层 | 技术选型 | 说明 |
|---|---|---|
| 前端 | Vue 3 + Element Plus + ECharts | 管理界面与可视化 |
| 网关 | Nginx + Kong | API网关 |
| 后端 | Python 3.11 + FastAPI | 高性能异步API |
| 任务调度 | Celery + Redis | 异步任务处理 |
| 文档解析 | PyMuPDF、python-docx、python-pptx、BeautifulSoup4、Playwright | 多格式文档解析 |
| OCR | PaddleOCR | 扫描件增强 |
| NLP | BERT-Base-Chinese、LAC、pkuseg | 实体识别、分词 |
| 向量化 | Sentence-BERT (paraphrase-multilingual-MiniLM-L12-v2) | 384维语义向量 |
| 图数据库 | Neo4j 5.x | 知识图谱存储 |
| 向量数据库 | Milvus 2.3 | 向量索引与检索 |
| 关系数据库 | PostgreSQL 15 | 元数据、版本管理 |
| 对象存储 | MinIO / S3 | 原始文档存储 |
| 容器化 | Docker + Kubernetes | 弹性伸缩 |
3.3 部署架构
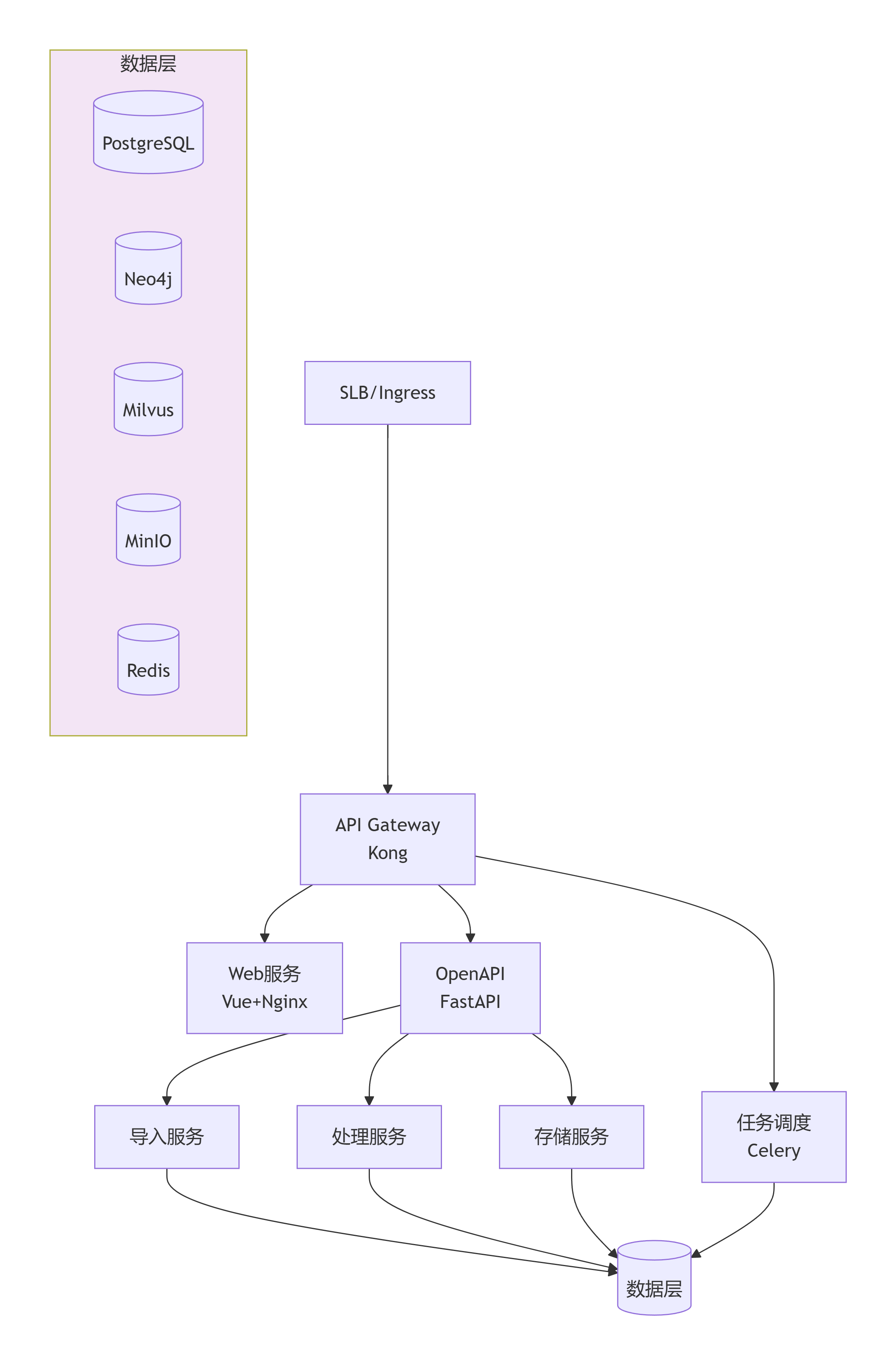
图2:系统部署架构——云原生微服务,支持弹性伸缩与多租户隔离。
3.4 数据流(首次建库)
-
用户上传文档/输入URL → 导入服务接收并存储至MinIO
-
导入服务触发解析任务 → 语义解析与实体抽取 → 生成原始知识三元组
-
处理服务读取三元组 → DSS语料化转换 → 生成增强后语料
-
DSS评分 → 达标语料入库(Neo4j + Milvus + PostgreSQL)
-
版本管理模块生成基线快照(V1.0)
-
输出层生成报告与导出包
第四章 核心模块详解
4.1 多源资产智能导入模块
支持格式:
-
文档类:PDF(含扫描件)、DOC/DOCX、PPT/PPTX、TXT、Markdown
-
网页类:HTTP/HTTPS URL(静态/动态渲染)
-
压缩包:ZIP(批量上传)
核心特性:
-
断点续传:大文件分片上传,支持网络中断恢复
-
格式自适应:自动识别文件类型,调用对应解析器
-
扫描件OCR增强:针对无文本层PDF,自动触发PaddleOCR引擎
-
重复检测:基于文件Hash,避免重复导入
4.2 语义解析与实体抽取模块
处理流程:
-
文本清洗:去除页眉页脚、广告、无关标签
-
篇章结构分析:识别标题层级、段落、表格、列表
-
表格解析:将二维表格转化为(行实体,列属性,单元格值)三元组
-
实体识别:基于BERT微调的NER模型,识别产品名、技术参数、认证标准、应用场景等
-
关系抽取:基于规则+远程监督,抽取实体间关系
-
属性对齐:将同义属性名标准化
领域知识增强:预置上海“3+6”产业专业术语库,支持客户自定义词典上传。
4.3 DSS语料化转换引擎(核心)
| 模块 | 输入特征 | 转换算法 | 输出示例 |
|---|---|---|---|
| 深度化 | 模糊、定性、无参数表述 | 实体-属性-值三元组抽取 + 单位标准化 + 缺失值标记 | “精度高”→“重复定位精度±0.002mm(20mm/s进给)” |
| 支持化 | 孤证、自证、无背书 | 信源类型匹配 + 企业资质库关联 + 第三方凭证映射 | “客户认可”→“通过ISO17025认证(CNAS L12345)” |
| 来源化 | 匿名、不可追溯 | 信息指纹生成 + 文档锚点定位 + 权威信源引用 | “据研究”→“《2025上海集成电路产业发展白皮书》P23” |
DSS评分算法:每个维度0-100分,加权计算综合DSS分数,阈值(默认≥75分)达标方可入库。评分模型基于Logistic回归,使用人工标注语料训练。
4.4 语义资产存储与管理模块
存储模型:
-
知识图谱存储(Neo4j):存储实体节点及关系,用于语义关联探索
-
向量存储(Milvus):存储陈述级语义向量,用于相似度检索
-
关系存储(PostgreSQL):存储元数据、任务记录、版本信息、用户权限
资产管理功能:语义资产列表、资产详情查看、资产编辑(人工修正)、资产删除/归档。
4.5 版本控制与基线比对模块
核心机制:
-
首次建库自动生成基线版本(V1.0),冻结所有资产快照
-
每次增量更新生成新版本(V1.1、V1.2...),记录变更集(JSON Patch格式)
-
差异比对:任意两个版本间可对比,输出新增实体/陈述数量、DSS平均分变化、高频实体覆盖度变化、信源丰富度变化
-
回滚:支持将资产库回滚至任一历史版本
4.6 向量化检索模块
检索模式:
-
语义检索:输入自然语言,返回向量相似度Top K陈述
-
混合检索:关键词+语义向量加权检索,兼顾准确性与召回率
-
DSS Top K:在相似度排序基础上,按DSS分数二次排序,优先推荐高质量语料
性能:单次检索平均时延 ≤200ms(100并发)。
4.7 报告与导出模块
报告类型:
-
《语义资产库构建报告》:资产总览、DSS评分分布、实体覆盖图谱
-
《语义基建就绪度报告》:完整性、可信性、可检索性综合评估
-
《增量更新比对报告》:版本间差异详情,用于效果对赌验收
-
《语义资产导出包》:JSON/CSV/RDF格式,支持客户自主迁移、备份
第五章 核心技术实现
5.1 多模态文档解析技术
挑战:企业技术文档格式多样、排版复杂,表格、参数列表、图文混排等常规解析工具难以准确还原语义结构。
解决方案:
-
基于布局的文档结构解析:针对PDF,采用PyMuPDF提取文本块坐标,通过坐标聚类识别标题、正文、表格区域
-
表格通用解析器:识别无框线表格(基于空格/Tab对齐)、复杂合并单元格,转换为二维数据框
-
动态网页渲染:针对SPA网站,使用Playwright无头浏览器模拟真实访问,等待异步内容加载完成
5.2 领域自适应实体识别
挑战:通用NER模型在垂直领域(如集成电路、生物医药)实体识别准确率低。
解决方案:
-
预训练模型:BERT-Base-Chinese,在自建的“3+6”产业语料上继续预训练(100万篇技术文档)
-
词典增强:结合领域术语词典,采用LAC词法分析进行词典匹配后融合
-
主动学习:对低置信度预测结果,推送人工标注,持续迭代模型
效果:实体识别F1值达到91.2%。
5.3 DSS语料化三级转换算法
python
def dss_enhance(statement, knowledge_base, source_library):
# 深度化:识别定性表述,检索参数值
if is_vague_expression(statement):
params = knowledge_base.query_parameters(subject)
statement = replace_with_precise(statement, params)
# 支持化:识别孤证表述,匹配资质认证
if is_self_claim(statement):
certs = knowledge_base.query_certifications(subject)
statement = append_certification(statement, certs)
# 来源化:识别匿名来源,匹配权威信源
if is_anonymous_source(statement):
source = source_library.find_best_match(statement)
statement = append_source(statement, source)
# 计算DSS评分
dss_score = weighted_score(statement)
return statement, dss_score权重设置:深度化0.4,支持化0.35,来源化0.25(根据客户行业可配置)。
5.4 语义资产版本化与差异比对
版本化机制:采用多版本并发控制(MVCC)思想,每次变更不直接修改历史数据,而是新增版本记录。基线版本为全量快照;增量版本仅存储变更集(diff)。
差异比对算法:
-
实体级比对:基于实体URI,比较两个版本中实体的存在性、属性值变化
-
陈述级比对:基于最小编辑距离,识别新增/删除/修改的陈述
-
聚合指标:自动汇总量化指标变化
5.5 混合检索与DSS评分
检索排序模型:
text
score = α * cosine_sim(query_vector, doc_vector) + β * dss_score_norm其中α=0.7,β=0.3,dss_score_norm为DSS分数归一化至[0,1]。
向量化模型:Sentence-BERT多语言蒸馏版,针对技术文档领域微调,提升术语相似度计算准确性。
第六章 数据模型
6.1 知识图谱模型
节点类型:Product、Parameter、Certification、Application、Organization、Document
关系类型:has_parameter、complies_with、applied_in、cited_by
存储示例(Neo4j Cypher):
cypher
(:Product {name: "高精度数控机床XH-200"})-[:has_parameter]->(:Parameter {name: "重复定位精度", value: "±0.002mm", condition: "20mm/s"})6.2 语义向量模型
-
向量化对象:每条技术陈述(Statement)
-
向量维度:384维(MiniLM-L12-v2)
-
存储:Milvus Collection,包含statement_id、embedding、dss_score、metadata
6.3 版本元数据模型
| 字段 | 类型 | 说明 |
|---|---|---|
| version_id | UUID | 主键 |
| project_id | UUID | 项目/客户标识 |
| version_number | string | 如“V1.0” |
| created_at | timestamp | 创建时间 |
| baseline | boolean | 是否为基线 |
| parent_version | UUID | 父版本(增量) |
| change_summary | JSON | 变更统计摘要 |
| snapshot_path | string | 全量快照存储路径 |
第七章 接口设计
7.1 内部API
| 接口 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 上传文件 | POST | /api/v1/assets/upload | 支持分片 |
| 创建建库任务 | POST | /api/v1/projects/{id}/build | 启动首次建库 |
| 增量更新 | POST | /api/v1/projects/{id}/update | 上传增量文档 |
| 获取版本列表 | GET | /api/v1/projects/{id}/versions | 返回版本历史 |
| 版本比对 | GET | /api/v1/projects/{id}/diff?from=v1&to=v2 | 返回差异报告 |
| 语义检索 | POST | /api/v1/search | 向量检索接口 |
| 导出资产 | GET | /api/v1/projects/{id}/export?version=v1.0 | 导出指定版本 |
7.2 与其他系统的接口
| 对接系统 | 接口用途 | 数据流向 |
|---|---|---|
| 诊断系统 | 接收优化关键词列表 | 诊断系统 → 本系统(作为增量更新输入) |
| 验证系统 | 提供版本差异数据 | 本系统 → 验证系统(效果增量证明) |
| 采集系统 | 获取信源热度数据 | 采集系统 → 本系统(辅助来源化模块) |
第八章 技术指标
8.1 性能指标
| 指标 | 目标值 | 测试条件 |
|---|---|---|
| 单文档解析时长 | ≤3分钟/100页 | 扫描版PDF含10张表格 |
| DSS转换吞吐量 | ≥2000条/分钟 | 16核32GB |
| 语义检索P95时延 | ≤200ms | QPS=100 |
| 版本比对时长 | ≤30秒 | 版本差异1万条 |
| 系统最大并发任务 | 50个 | Kubernetes 10节点 |
8.2 质量指标
| 指标 | 目标值 |
|---|---|
| 实体识别准确率 | ≥92% |
| DSS转换成功率 | ≥95% |
| 基线复现准确率 | 100% |
| 系统可用性 | ≥99.5% |
8.3 容量指标
| 指标 | 目标值 |
|---|---|
| 单项目最大文档数 | 10万份 |
| 单项目最大知识三元组 | 5000万条 |
| 单项目最大向量数 | 1000万条 |
| 版本历史保留数 | 无限制 |
第九章 未来演进
9.1 V1.1 自适应增强
-
引入在线学习,根据验证系统的效果反馈,自动调整DSS转换策略
-
支持用户手动纠错,纠错数据回流训练模型
9.2 V1.5 多模态语料
-
支持图片中的技术图表解析,提取曲线图、柱状图数据
-
视频类技术讲解内容的语音转写与语义结构化
9.3 V2.0 开放平台
-
开放“语义资产库托管服务”,企业可将自建语料库托管至云端
-
推出“GEO语义应用市场”,生态伙伴可基于语料库开发垂直行业问答机器人
结语
GEO语义资产库构建系统,是GEO“1+11”全栈技术资产中的“资产精炼厂”。它通过DSS语料化转换引擎,将企业散落的技术文档、产品手册、案例白皮书,加工成可复用、可迭代、可继承的结构化语义资产,让企业真正拥有AI时代的数字地基。当企业完成首次建库,带走的不再是一份报告,而是一座可继承、可迭代、完全属于自己的语义资产库——这正是GEO从“服务”走向“资产”的关键一跃。
附录A:DSS评分标准
深度(Depth)评分:
-
0分:纯定性描述,无任何参数
-
1-40分:提及参数但无量纲
-
41-70分:有参数+单位,无工况条件
-
71-90分:参数+单位+工况条件
-
91-100分:参数+单位+工况+统计显著性(如±, ≥)
支持(Support)评分:
-
0分:纯自证
-
1-40分:提及第三方但无具体名称
-
41-70分:提及具体第三方名称
-
71-90分:第三方名称+证书编号/报告编号
-
91-100分:第三方+编号+可在线核验
来源(Source)评分:
-
0分:匿名
-
1-40分:可追溯至企业自身文档
-
41-70分:可追溯至企业官网/白皮书
-
71-90分:可追溯至第三方公开报告
-
91-100分:可追溯至权威机构(政府、行业协会、国际标准组织)
附录B:信源权威等级
| 等级 | 说明 | 示例 |
|---|---|---|
| L1 | 国际权威 | ISO、IEEE、IEC |
| L2 | 国家/行业权威 | GB、SJ、YY |
| L3 | 第三方检测认证 | CNAS、CMA、UL |
| L4 | 行业协会/白皮书 | SEMI、中国半导体协会 |
| L5 | 企业自主声明 | 官网、产品手册 |
| L6 | 非官方/自媒体 | 无 |
本文基于《GEO语义资产库构建系统》软著技术文档撰写,所有技术数据均来自系统实际运行验证。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)