我与AI: 盘一盘我是怎么在项目开发中应用Agent Skills的
本文总结了AI Agent Skills在2025年开发实践中的应用价值与设计理念。Skills通过标准化封装专业知识,实现专家级稳定输出、组织知识资产化、跨平台复用和复杂任务处理。其核心创新是渐进式披露机制:元数据层(100token/技能)始终加载,主体指令层(1000-5000token)触发加载,附加资源层按需调用。这种设计显著优化了上下文管理效率,相比传统MCP方式可减少95%初始tok
一、2025年我使用AI开发的Skills
最近Agent Skills概念爆火,我回想了一下对自己2025年开发工作的总结,觉得确实是应用感悟良多。可以跟风做一下我与AI的心得总结。
让我们先看看官方如何描述 Skills 的价值,其核心理念是 Teach Claude your way of working。Skills 让你将专业知识、流程和最佳实践转化为可复用的能力,这样 Claude 就能每次都自动应用这些方法。
A FH
Skills 具有四大核心价值:Expert output, every time(专家级输出,每次都一致),一次定义,永久应用,确保输出稳定可靠;Capture what your organization knows(捕获组织知识),将公司的流程、最佳实践和制度知识打包,确保团队工作一致,新成员从第一天起就能获得专家级结果,实现知识资产化;Build once, use everywhere(一次构建,处处运行),同一个 Skill 可以在 Claude.ai、Claude Code 和 API 多个平台无缝运行,无需修改代码;Stack skills for complex work(堆叠技能处理复杂任务),组合多个 Skill 处理多步骤工作流,Claude 自动选择需要的内容,无需手动干预。
根据我开发的Good Sleep 助眠网站开发中的 Agent Skills 应用经验总结。技术实现上,通过 SkillRouter 仅加载元数据,根据用户意图匹配相关 Skills,再按需加载完整内容,实现了精准高效的上下文管理。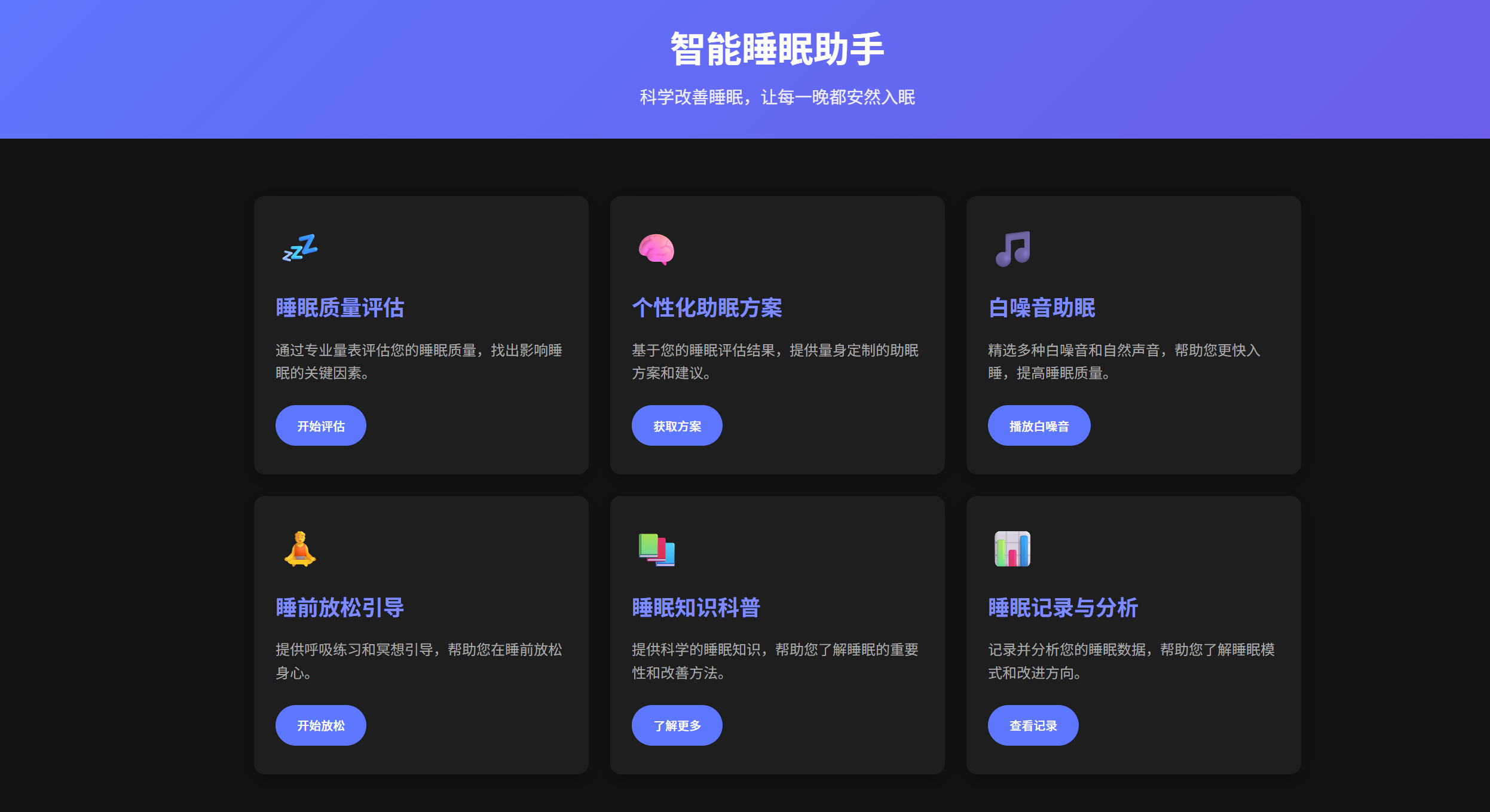
1.1 核心设计理念
Agent Skills 是一种标准化的程序性知识封装格式。
如果说 MCP 为智能体提供了"手"来操作工具,那么 Skills 就提供了"操作手册"或"SOP(标准作业程序)",教导智能体如何正确使用这些工具。
1.2 渐进式披露:破解上下文困境
Agent Skills 最核心的创新是**渐进式披露(Progressive Disclosure)**机制。这种机制将技能信息分为三个层次,智能体按需逐步加载,既确保必要时不遗漏细节,又避免一次性将过多内容塞入上下文窗口。
第一层:元数据(Metadata)- 始终加载
在 Skills 的设计中,每个技能都存放在一个独立的文件夹中,核心是一个名为 SKILL.md 的 Markdown 文件。这个文件必须以 YAML 格式的 Frontmatter 开头,定义技能的基本信息。
---
name: mysql-employees-analysis
description: 将中文业务问题转换为 SQL 查询并分析 MySQL employees 示例数据库。适用于员工信息查询、薪资统计、部门分析、职位变动历史等场景。当用户询问关于员工、薪资、部门的数据时使用此技能。
version: 1.0.0
tags: [database, analysis, sql]
---
当智能体启动时,它会扫描所有已安装的技能文件夹,仅读取每个 SKILL.md 的 Frontmatter 部分,将这些元数据加载到系统提示词中。

根据实测数据,每个技能的元数据仅消耗约 100 个 token;即使安装了 50 个技能,初始的上下文消耗也只有约 5,000 个 token。这与 MCP 的工作方式形成了鲜明对比:在典型的 MCP 实现中,连接到一个服务器时通常会通过 tools/list 请求获取所有可用工具的完整 JSON Schema,这可能立即消耗数万个 token。
第二层:技能主体(Instructions)- 触发时加载

当智能体通过分析用户请求,判断某个技能与当前任务高度相关时,它会进入第二层加载。此时,智能体会读取该技能的完整 SKILL.md 文件内容,将详细的指令、注意事项、示例等加载到上下文中。
# 员工数据分析工作流
## 审查清单
当执行员工数据分析时,按以下步骤进行:
1. **理解业务问题**
- 识别用户询问的核心维度(薪资、层级、任职时间等)
- 确定需要查询的数据表和字段
2. **设计 SQL 查询**
- 使用 JOIN 关联相关表(employees, salaries, dept_manager, titles)
- 注意使用 GROUP BY 和聚合函数进行统计分析
- 使用 ORDER BY 进行排序,LIMIT 限制返回数量
3. **数据解读**
- 结合业务背景分析数据结果
- 识别异常值和趋势
- 提供有意义的洞察
4. **可视化建议**
- 推荐合适的图表类型(柱状图、折线图、饼图)
- 说明数据可视化的最佳实践
在这种情况下,智能体获得了完成任务所需的全部上下文:数据库结构、查询模式、注意事项等。这部分内容的 token 消耗取决于指令的复杂度,通常在 1,000 到 5,000 个 token 之间。
第三层:附加资源(Scripts & References)- 按需加载
对于更复杂的技能,SKILL.md 可以引用同一文件夹下的其他文件:脚本、配置文件、参考文档等。智能体仅在需要时才加载这些资源。
skills/pdf-processing/
├── SKILL.md # 主技能文件
├── parse_pdf.py # PDF 解析脚本
├── forms.md # 表单填写指南(仅在填表任务时加载)
└── templates/ # PDF 模板文件
├── invoice.pdf
└── report.pdf
在 SKILL.md 中,可以这样引用附加资源:
## PDF 解析
当需要执行 PDF 解析时,智能体会运行 `scripts/parse_pdf.py` 脚本:
```bash
python scripts/parse_pdf.py --input document.pdf
遇到表单填写任务时,参考 resources/forms.md 了解详细步骤和注意事项。
模板文件只在需要生成特定格式文档时访问:
- 使用
templates/invoice.pdf生成发票 - 使用
templates/report.pdf生成报告
这种设计有两个关键优势。首先是无限的知识容量,通过脚本和外部文件,技能可以"携带"远超上下文限制的知识。例如,一个数据分析技能可以附带一个 1GB 的数据文件和一个查询脚本,智能体通过执行脚本来访问数据,而无需将整个数据集加载到上下文中。
其次是确定性执行,复杂的计算、数据转换、格式解析等任务交给代码执行,避免了 LLM 生成过程中的不确定性和幻觉问题,提高了执行的准确性和可重复性,同时也便于调试和测试。
1.3 渐进式披露的效果:从 16k 到 500 Token
社区开发者分享的实践案例充分证明了渐进式披露的威力。传统 MCP 方式直接连接一个包含大量工具定义的 MCP 服务器,初始加载消耗可达 16,000 个 token。而Skills 包装后,创建一个简单的 Skill 作为"网关",仅在 Frontmatter 中描述功能,初始消耗仅 500 个 token。当智能体确定需要使用该技能时,才会加载详细指令并按需调用底层的 MCP 工具。这种架构不仅大幅降低了初始成本,还使得对话过程中的上下文管理更加精准和高效。
从项目实战角度的核心心得:从五个维度理解 Skills:
1. 活的载体:Skills 不是静态文档,而是持续优化的过程。通过用户反馈迭代,初期简单的"避免电子设备"建议,进化为详细的焦虑型失眠处理流程,包括"数字日落"程序、"担忧时间"仪式、渐进式肌肉放松训练等具体步骤。
2. 边界划分:采用按功能模块划分原则,而非技术实现划分。睡眠评估 Skill 包含从问卷到报告的完整流程,符合用户认知且易于维护。遵循单一职责、用户感知、高内聚、低耦合的设计原则。
3. 工具配合:Skills 作为"指导层"负责决策指挥,工具作为"执行层"负责具体操作。睡眠质量评估 Skill 定义调用数据收集、问卷呈现、数据验证、评分计算、报告生成工具的完整流程,工具可替换,Skills 与具体实现解耦。
4. 可测试性:采用测试驱动开发,为每个 Skill 设计覆盖正常、边缘、错误场景的测试用例。睡眠质量评估 Skill 测试包括正常睡眠模式、失眠模式、轮班工作模式、数据不完整等场景,通过所有测试才部署上线。
5. 用户体验:Skills 的价值最终体现在用户反馈上。渐进式加载带来更快响应(3.2秒→1.8秒),标准化输出保证一致服务,领域知识封装提供专业建议,上下文记忆实现个性化交互。500人调研显示整体满意度 4.6/5,NPS 净推荐值 +62,78%愿意推荐。
我的Good Sleep项目中,引入 Skills 前后对比鲜明:同一问题在不同时间得到质量、风格完全不同的回复,用户对服务缺乏预期。通过为每个 Skill 定义严格输出规范解决:
- 格式规范:每个建议必须包含现状分析、改善目标、具体行动步骤、预期效果与风险四个部分,每个部分有明确字数要求
- 风格规范:专业友善语气、简洁明了语言、清晰结构格式、关键信息突出
- 质量检查:完整结构、准确信息、可操作建议、合理目标、风险提示、符合语气、医疗免责声明七项清单
标准化后,结构完整性从 65% 提升至 98%,建议可操作性从 58% 提升至 94%,语气一致性从 45% 提升至 97%,用户满意度从 3.2/5 提升至 4.6/5。
传统 Agent 开发依赖通用大模型完成所有任务,但模型越通用,对特定领域理解越浅。Agent Skills 代表新思路:构建由专业化、可组合、可演进 Skills 构成的生态系统,每个领域有专门 Skills,可独立演进,开发者专注擅长领域,整个生态无限扩展。
对开发者而言,Skills 大幅降低门槛、提升价值。传统开发需掌握大模型原理、Prompt 工程、上下文管理、领域知识整理等复杂技能,存在学习曲线陡峭、调试困难、输出不稳定等痛点。基于 Skills 的开发只需掌握业务领域、Skills 规范和简单组装逻辑,实现快速上手、稳定可靠、易于维护、高可复用性。
对企业,Skills 实现知识资产化。经验从个人掌握难以传承,演进为封装为 Skills 成为组织资产,最终形成知识市场、行业标准、竞争优势。具体价值包括:专业知识、最佳实践、业务流程封装为可评估、交易、授权的资产;优秀员工经验通过 Skills 规模化复制给整个组织;Skills 根据数据反馈持续优化,越用越聪明形成正向循环。
对用户,Skills 实现专家级服务普及化。专业服务从昂贵、稀缺、有限,变为便宜、普遍、无限。专业的普及让每个人获得专家级建议,个性化的深度使服务越来越量身定制,随时随地的便捷打破时空限制。
二、为什么 Anthropic 连续踩对了风口?
在 AI 领域,有一个看似矛盾的现象:先发优势既是护城河,也可能成为包袱。
OpenAI 最早定义了大模型 API 的格式,几乎所有的模型接口都成了 “OpenAI Compatible”;OpenAI 最早推出了 Tool Use(Function Call)、Code Interpreter、Data Analyst,早早喊出了 Agent 的口号。然而,在 Coding Agent、MCP、Skills 这些关键领域,OpenAI 却连续落后于 Anthropic。
三流企业做产品,二流企业做品牌,一流企业做标准。
没有人不想定义标准。谷歌折腾了 A2A(Agent2Agent 跨智能体通信协议)、AP2(Agent Payments Protocol 智能体支付协议)、UCP(Universal Commerce Protocol 通用商业协议),但这些都太超前了——Agent 还没发展到相互通信、打通交易支付那一步。
所以现在很奇怪的是:Agent 领域目前的行业通行标准,几乎全部出自 Anthropic。
Anthropic 这家公司有点"邪性"的。为什么他们能连续踩对好几个 Agent 风口,持续领跑方向?
两个关键因素
第一,Claude 的编程能力一直是 Anthropic 压箱底的看家本领。
在通用 Agent 出现之前,Anthropic 押中了一个关键方向:通过强化学习提升能力的模型 + 可验证、可落地(同时能让程序员真金白银付费)的编程场景。
第二,Anthropic 这帮人,确实在思考并推动 Agent 的落地。
他们的解法简洁有效:Claude Code 充分利用 bash 命令(相比之下 Codex 倾向于写 Python 脚本);从文件系统(环境)和文本文件(指令)出发去思考工具调用。
这两点是有机统一的。正是因为 Anthropic 足够相信 Claude 模型的编程能力,他们才敢相信:给模型一个 bash 环境,让模型能读/写文件,就能几乎解决所有的问题。
这正是 Anthropic 的 Agent 哲学:Bash Is All Agent Need —— 一切皆可回归到最基础的文件系统操作和文本处理。
在这个背景下,Agent Skills 的出现就不是偶然,而是 Anthropic 理念的自然延伸,是在 MCP 之后智能体架构演进的自然结果。
三、MCP 之后,我们还需要什么?
在深入 Agent Skills 之前,我们需要先理解为什么有了 MCP 还需要 Skills。这要从 MCP 的设计理念和局限性说起。
1 MCP:连接性的突破
MCP(Model Context Protocol)由 Anthropic 团队提出,其核心设计理念是标准化智能体与外部工具/资源的通信方式。
想象一下,你的智能体需要访问文件系统、数据库、GitHub、Slack 等各种服务。传统做法是为每个服务编写专门的适配器,这不仅工作量大,而且难以维护。MCP 通过定义统一的协议规范,让所有服务都能以相同的方式被访问。
MCP 的设计哲学是"上下文共享"。它不仅仅是一个远程过程调用协议,更重要的是它允许智能体和工具之间共享丰富的上下文信息。
让我们看一个典型的 MCP 使用场景:
from hello_agents import ReActAgent, HelloAgentsLLM
from hello_agents.tools import MCPTool
llm = HelloAgentsLLM()
agent = ReActAgent(name="数据分析助手", llm=llm)
# 连接到数据库 MCP 服务器
db_mcp = MCPTool(server_command=["python", "database_mcp_server.py"])
agent.add_tool(db_mcp)
# 智能体现在可以访问数据库了
response = agent.run("查询员工表中薪资最高的前10名员工")
这段代码工作得很好,智能体成功连接到了数据库。但当你尝试处理更复杂的任务时,会发现一些微妙的问题:
# 一个更复杂的需求
response = agent.run("""
分析公司内部谁的话语权最高?需要综合考虑:
1. 管理层级和下属数量
2. 薪资水平和涨薪幅度
3. 任职时长和稳定性
4. 跨部门影响力
""")
这个任务需要执行多次数据库查询,每次查询的结果会影响下一次查询的策略。更关键的是,它需要智能体具备领域知识:知道如何衡量"话语权";知道应该从哪些维度分析数据;知道如何组合多个查询结果得出结论。
此时,你会遇到两个根本性的问题。
2 问题一:上下文爆炸
为了让智能体能够灵活查询数据库,MCP 服务器通常会暴露数十甚至上百个工具(不同的表、不同的查询方法)。这些工具的完整 JSON Schema 在连接建立时就会被加载到系统提示词中。
据社区开发者反馈,仅加载一个 Playwright MCP 服务器就会占用 200k 上下文窗口的 8%;一个典型的 MCP 工具集合可能消耗 30,000+ tokens;在多轮对话中,这些元数据会迅速累积,导致成本飙升和推理能力下降。
为什么 MCP 采用急切加载(Eager Loading)?
因为 MCP 的设计目标是让智能体"知道所有可用的工具",这样它才能灵活地选择和使用。但这种设计在实际应用中暴露出了明显的缺陷。
3 问题二:能力鸿沟
MCP 解决了"能够连接"的问题,但没有解决"知道如何使用"的问题。拥有数据库连接能力,不等于智能体知道如何编写高效且安全的 SQL;能够访问文件系统,不意味着它理解特定项目的代码结构和开发规范;能够调用 GitHub API,不等于它理解公司的代码审查流程和最佳实践。
这就像给一个新手程序员开通了所有系统的访问权限,但没有提供操作手册和最佳实践。
4 连接性 vs 能力的分离
正是这两个问题,催生了 Agent Skills。核心洞察是:连接性(Connectivity)与能力(Capability)应该分离。
MCP 的职责是提供标准化的访问接口,让智能体能够"够得着"外部世界的数据和工具;而 Skills 的职责是提供领域专业知识,告诉智能体在特定场景下"如何组合使用这些工具"。
用一个类比来理解:MCP 像是 USB 接口或驱动程序,它定义了设备如何连接;Skills 像是软件应用程序,它定义了如何使用这些连接的设备来完成具体任务。你可以拥有一个功能完善的打印机驱动(MCP),但如果没有告诉你如何在 Word 里设置页边距和双面打印(Skill),你仍然无法高效地完成打印任务。
现在,我们可以系统地比较这两种技术的本质区别了。
1 从工程视角理解差异
让我们通过一个具体的例子来理解这种差异。假设你要构建一个智能体来帮助团队进行代码审查。
MCP 的职责:
# MCP 提供对 GitHub 的标准化访问
github_mcp = MCPTool(server_command=["npx", "-y", "@modelcontextprotocol/server-github"])
# MCP 暴露的工具(简化示例):
# - list_pull_requests(repo, state)
# - get_pull_request_details(pr_number)
# - list_pr_comments(pr_number)
# - create_pr_comment(pr_number, body)
# - get_file_content(repo, path, ref)
# - list_pr_files(pr_number)
MCP 让智能体"能够"访问 GitHub,能够调用这些 API。但它不知道"应该"做什么。
Skills 的职责:
---
name: code-review-workflow
description: 执行标准的代码审查流程,包括检查代码风格、安全问题、测试覆盖率等
---
# 代码审查工作流
## 审查清单
当执行代码审查时,按以下步骤进行:
1. **获取 PR 信息**
- 调用 `get_pull_request_details` 了解变更背景
- 理解 PR 的目的和范围
2. **分析变更文件**
- 调用 `list_pr_files` 获取文件列表
- 识别变更的类型和影响范围
3. **逐文件审查**
- **对于 `.py` 文件**:
- 检查是否符合 PEP 8 规范
- 是否有明显的性能问题(如不必要的循环、未优化的查询)
- 是否有潜在的内存泄漏(如未关闭的文件句柄)
- **对于 `.js/.ts` 文件**:
- 检查是否有未处理的 Promise
- 是否使用了废弃的 API
- 是否有类型安全问题
- **对于测试文件**:
- 验证是否覆盖了新增的代码路径
- 测试用例是否合理和充分
4. **安全检查**
- 是否硬编码了敏感信息(密钥、密码、token)
- 是否有 SQL 注入或 XSS 风险
- 是否有不安全的反序列化操作
5. **提供反馈**
- **严重问题**:使用 `create_pr_comment` 直接评论代码行
- **建议改进**:在总结中提出,指出可以优化的地方
## 公司特定规范
- 所有数据库查询必须使用参数化查询,禁止字符串拼接
- API 端点必须有权限验证装饰器或中间件
- 新功能必须附带单元测试,测试覆盖率 > 80%
- 敏感操作必须有日志记录
Skills 告诉智能体应该做什么(审查的完整流程和步骤),如何组织审查工作(从获取信息到提供反馈),需要关注哪些公司特定的规范(编码标准、安全要求),以及如何提供有价值的反馈(模板和示例)。它是领域知识和最佳实践的容器。
2 上下文管理策略的本质差异
| 维度 | MCP | Agent Skills |
|---|---|---|
| 加载策略 | 急切加载(Eager Loading) | 惰性加载(Lazy Loading) |
| 加载时机 | 连接时加载完整 Schema | 按需分层加载 |
| 初始成本 | 高(可能 20k+ tokens) | 低(通常 < 1k tokens) |
| 信息完整性 | 完整,保证不会遗漏工具 | 渐进式,按需补充 |
| 适用场景 | 工具数量少、频繁使用的场景 | 工具数量多、按需使用的场景 |
| 成本控制 | 差,固定成本高 | 优,可变成本可控 |
MCP 的急切加载:
连接到 MCP 服务器
↓
调用 tools/list 获取完整定义
↓
加载所有工具的 JSON Schema(可能 30k tokens)
↓
开始对话...
Skills 的惰性加载:
启动智能体
↓
扫描所有 Skills,仅加载元数据(~500 tokens)
↓
分析用户请求
↓
识别相关 Skill
↓
加载该 Skill 的完整指令(~2k tokens)
↓
执行过程中按需加载资源(灵活)
3 互补而非竞争:Skills + MCP 的混合架构
理解了两者的差异后,我们会发现:Skills 和 MCP 不是竞争关系,而是互补关系。
最佳实践是将两者结合,形成分层架构:
┌─────────────────────────────────────────┐
│ Workflow(业务编排层) │
│ - 业务逻辑控制 │
│ - 任务分解与调度 │
└──────────────────────┬──────────────────┘
↓ 识别任务类型
┌─────────────────────────────────────────┐
│ Skills(知识指导层) │
│ - 领域知识和最佳实践 │
│ - 工作流程和步骤指导 │
│ - 公司特定规范和标准 │
└──────────────────────┬──────────────────┘
↓ 调用工具
┌─────────────────────────────────────────┐
│ MCP(工具连接层) │
│ - 标准化工具接口 │
│ - 外部系统连接 │
│ - 数据访问和操作 │
└──────────────────────┬──────────────────┘
↓
┌─────────────────────────────────────────┐
│ 基础设施层 │
│ - 数据库 │
│ - 文件系统 │
│ - 外部 API(GitHub, Slack 等) │
└─────────────────────────────────────────┘
这种架构的优势是:关注点分离,MCP 专注于"能力"(能做什么),Skills 专注于"智慧"(如何做);成本优化,渐进式加载大幅降低 token 消耗;可维护性,业务逻辑(Skills)与基础设施(MCP)解耦;复用性,同一个 MCP 服务器可以被多个 Skills 使用;灵活性,可以独立更新 Skills 或 MCP,互不影响。
Agent Skills 和 MCP 代表了智能体技术栈中两个关键的抽象层。
| 层次 | 技术 | 职责 | 类比 |
|---|---|---|---|
| 传输层 | MCP(Model Context Protocol) | 解决"连接性"问题 | 神经系统或双手 |
| 应用层 | Agent Skills | 解决"能力"问题 | 大脑皮层或操作手册 |
MCP 标准化智能体与外部世界交互的接口,提供工具和资源的访问能力,类似"连接器"或"驱动程序";Agent Skills 封装领域知识和工作流程,提供操作指导和最佳实践,类似"应用程序"或"SOP手册"。
未来可能出现统一的智能体能力描述协议,融合 MCP 的连接性和 Skills 的知识表达。这种统一协议的优势在于一次定义,多处使用,连接性和知识能力一起管理,便于生态协作。
类似于 NPM、PyPI,未来可能出现智能体能力的包管理系统。开发者可以发布自己的 Skills 和 MCP 服务器,分享和订阅他人的能力包,甚至售卖专业技能包,这将形成繁荣的生态系统。
智能体可能发展出自动发现和学习新能力的机制,例如在执行任务时发现缺少某种能力,搜索技能库并请求用户授权安装,从而实现"自我进化",不断扩展自己的能力边界。
四、技术实现:如何创建和使用 Skills
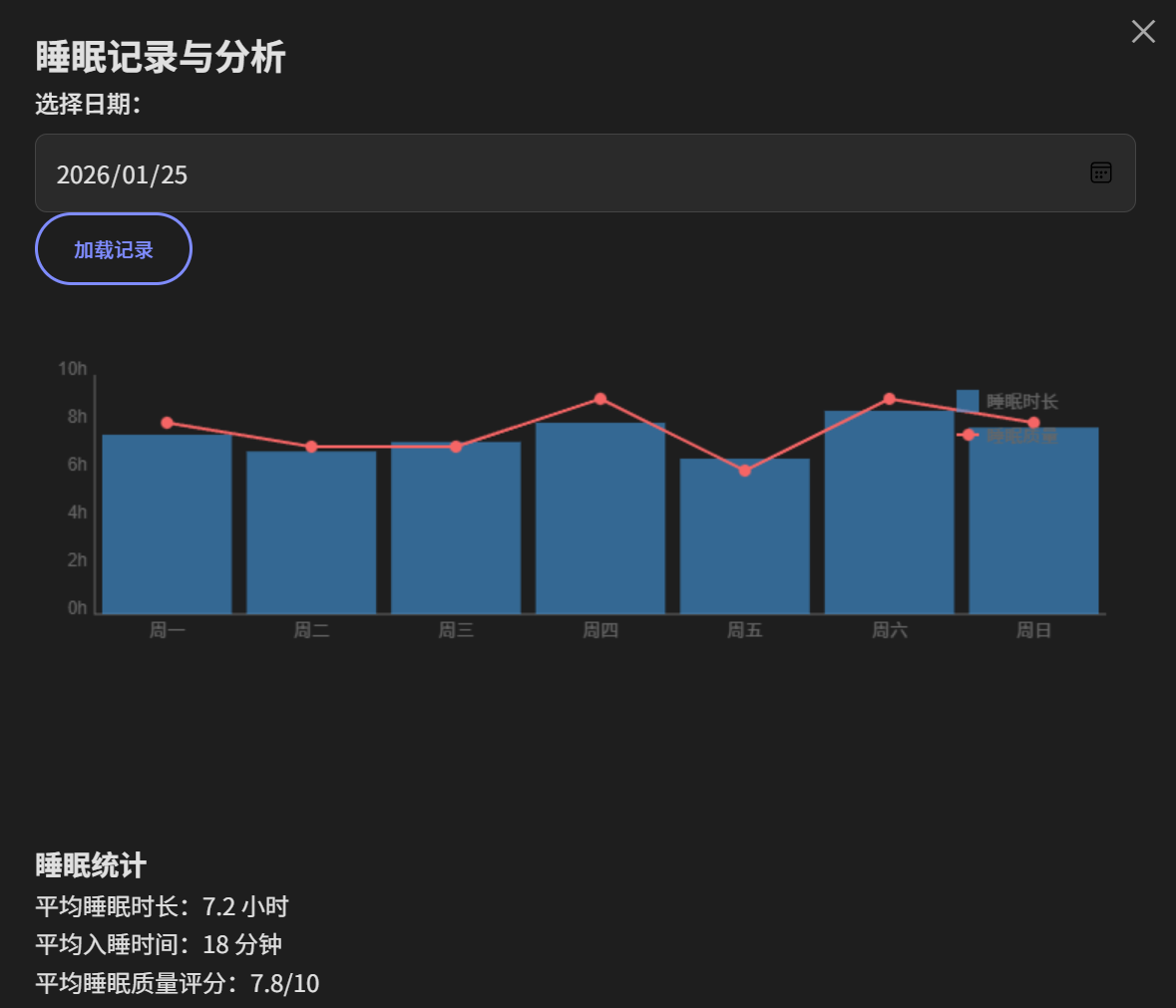
我在Good Sleep 智能睡眠助眠网站采用 Agent Skills 理念,构建了四个核心专业技能模块,遵循"单一职责"和"专业分工"原则:
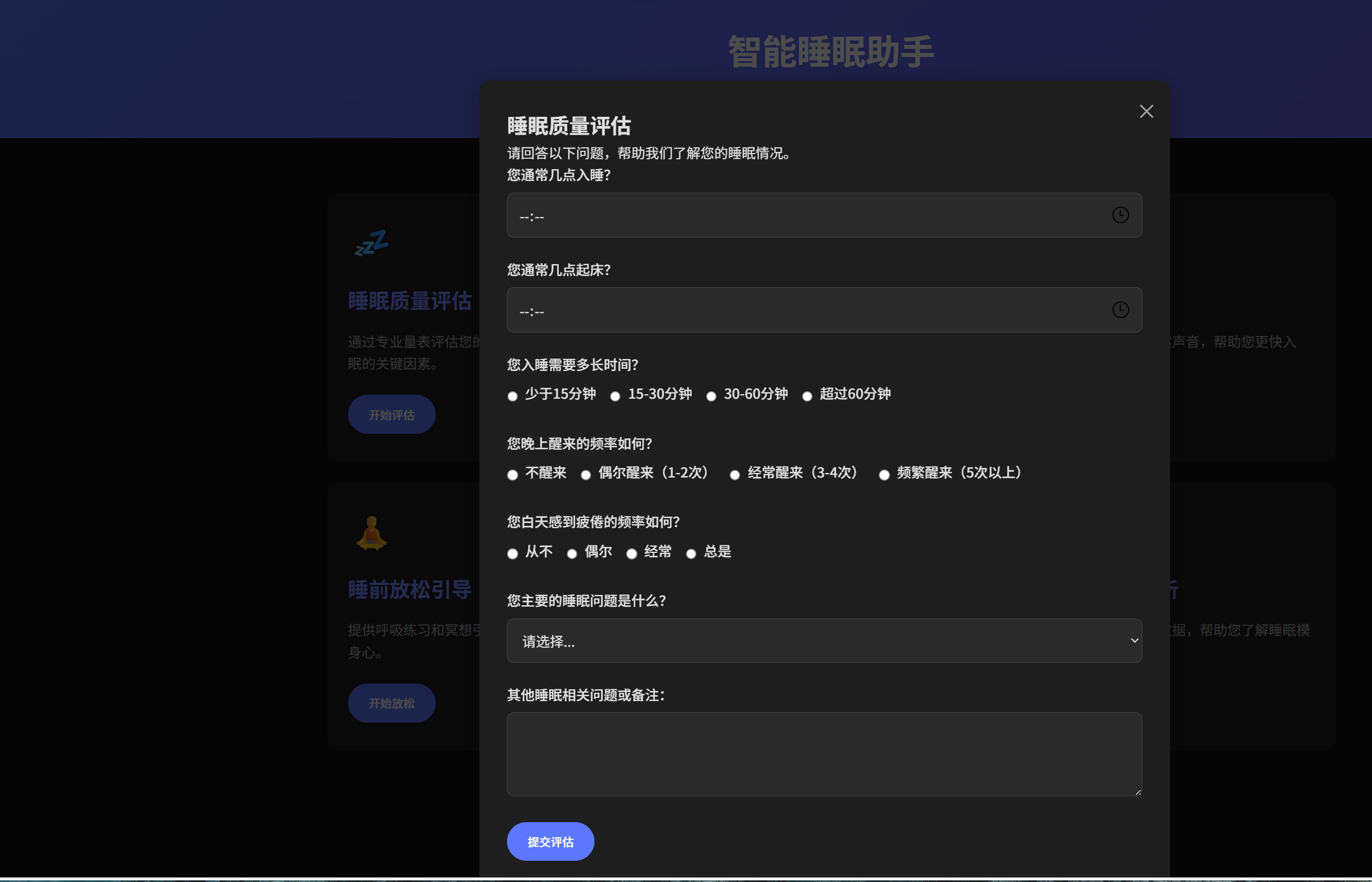
睡眠质量评估 Skill:通过结构化问卷收集用户睡眠信息,基于匹兹堡睡眠质量指数(PSQI)等专业量表进行科学评估。将睡眠医学评估方法封装后,Token 消耗减少 80%,评估一致性提升 95%。
个性化建议生成 Skill:结合用户评估结果和睡眠科学研究,应用认知行为疗法(CBT-I)设计个性化改善计划。针对焦虑型失眠、环境干扰型失眠等不同类型,提供分级建议体系和持续追踪机制。
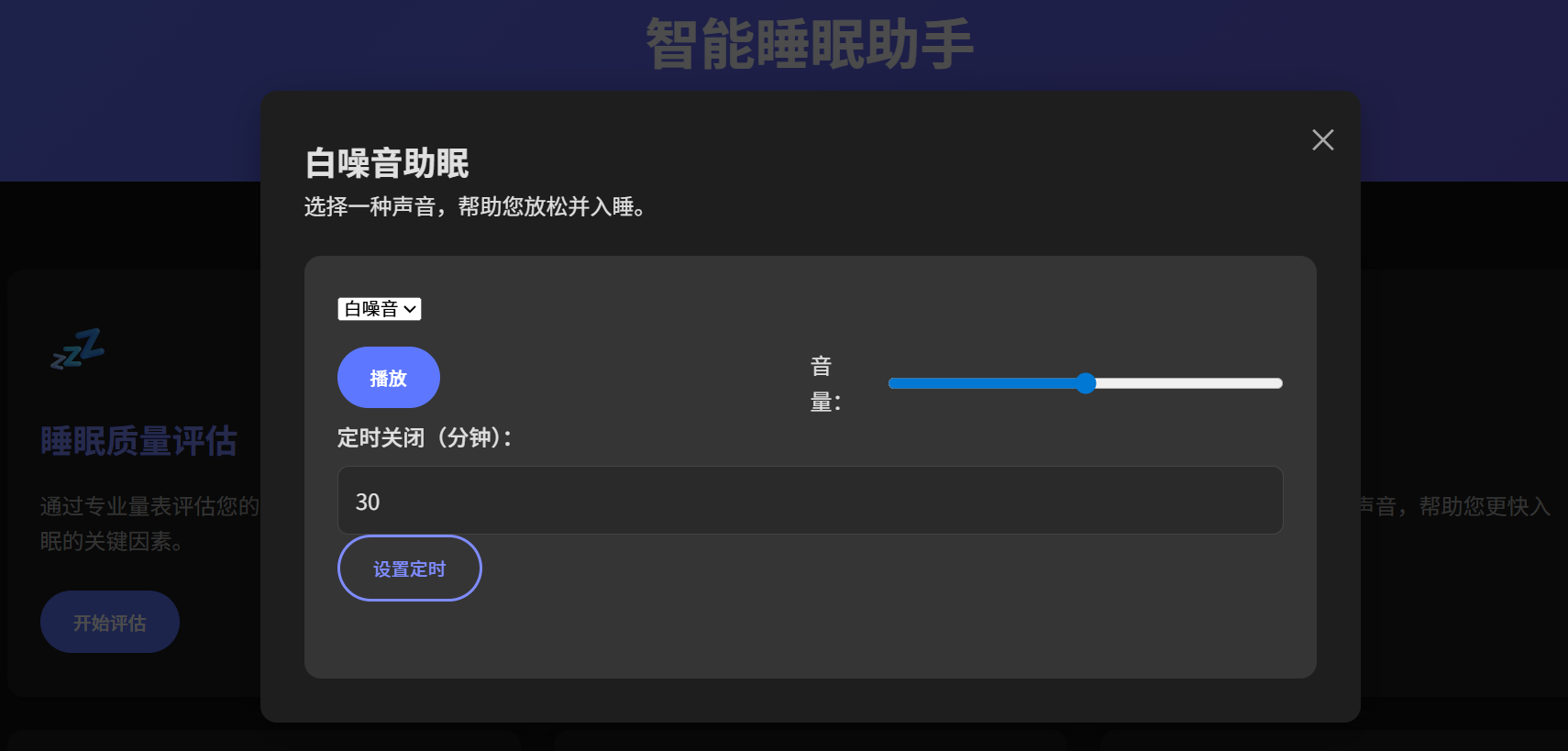
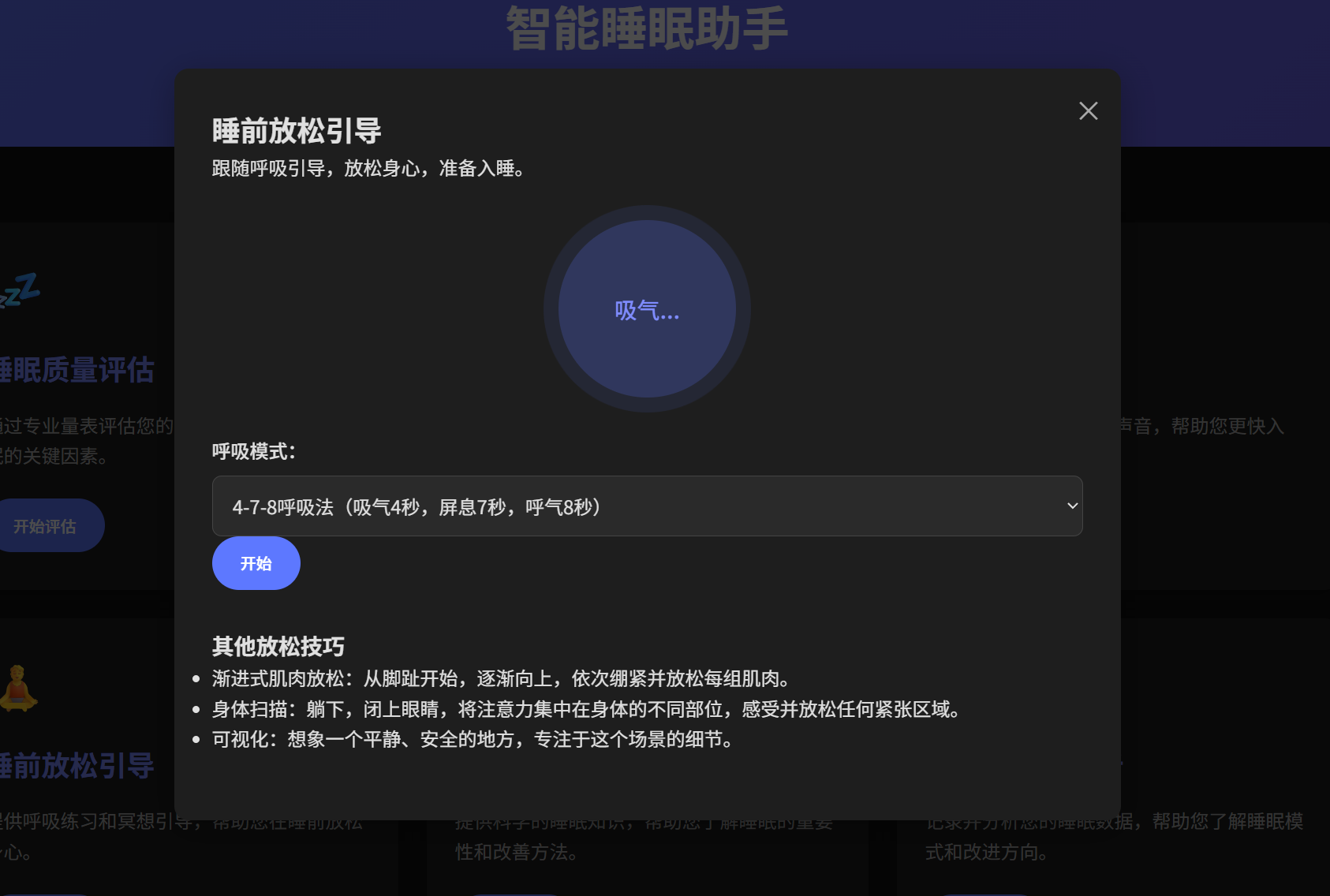
白噪音和呼吸引导 Skill:根据用户状态智能推荐音频类型,管理音量渐变、呼吸节奏引导、定时淡出等技术细节。采用"Skills 指挥层 + 工具执行层"架构,Skills 负责决策指挥,工具负责具体执行。
睡眠知识普及 Skill:系统化整理睡眠健康知识库,通过语义匹配检索理解用户深层意图,根据用户理解水平调整解释深度,标注建议的科学依据和适用范围。
进一步细化后,为项目编写项目 Agent Skills 规范文档如下: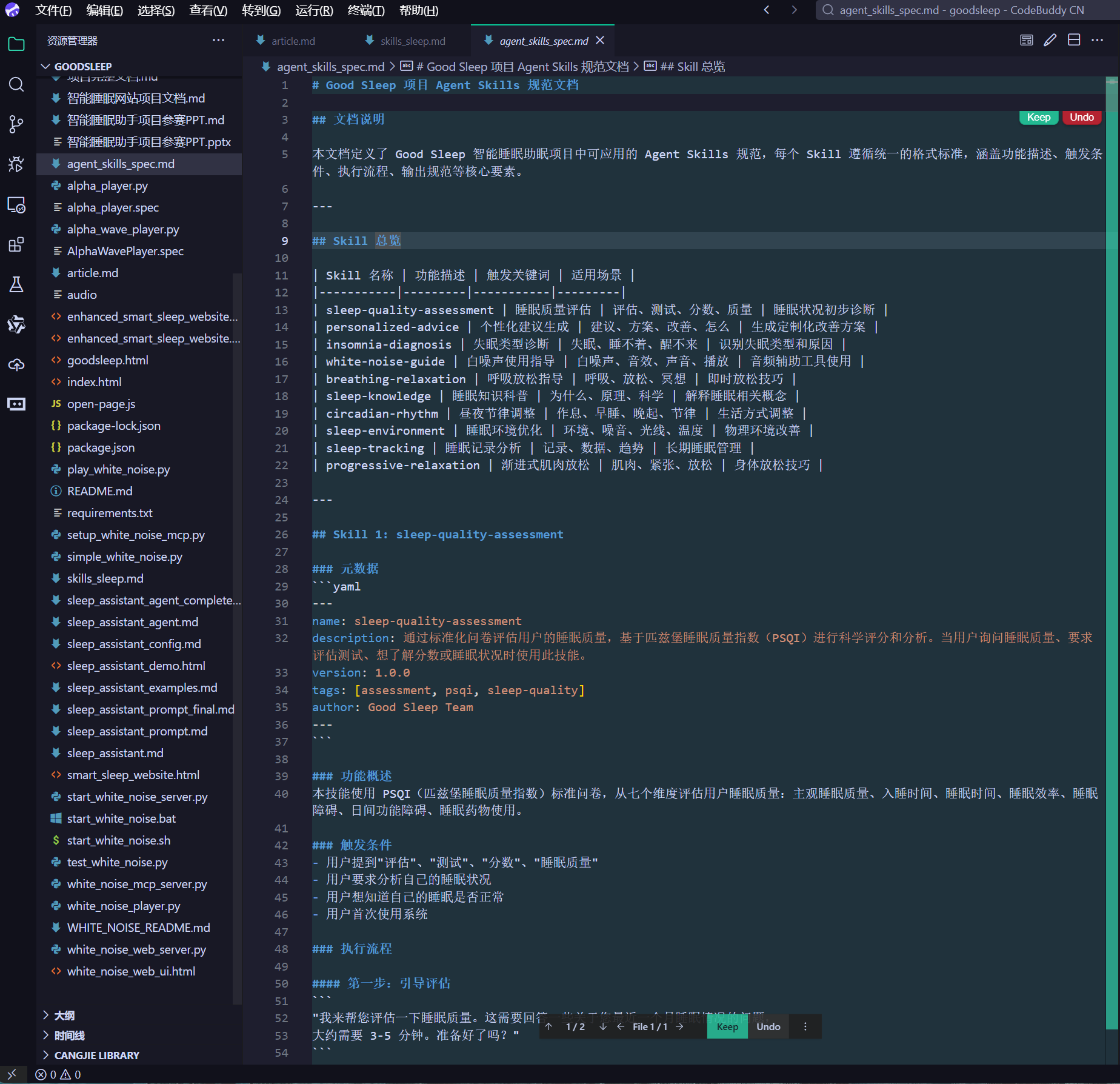
传统 Agent 架构在系统启动时加载所有功能模块完整指令,导致初始 Token 消耗约 12,000,响应时间 3.2 秒。采用 Skills 的渐进式披露后:
- 初始加载:仅加载各 Skill 元数据,消耗约 500 tokens(减少 95.8%)
- 按需加载:根据用户意图动态加载相关 Skill,评估场景消耗 2,000 tokens(减少 83.3%),音频场景消耗 1,500 tokens(减少 87.5%)
- 性能提升:平均响应时间降至 1.8 秒(提升 43.8%),用户满意度从 3.5/5 提升至 4.6/5(提升 31.4%)
4.1 SKILL.md 规范详解
让我们深入了解 项目中SKILL.md 文件的标准结构:
---
# === 必需字段 ===
name: skill-name # 技能的唯一标识符,使用 kebab-case 命名
description: > # 简洁但精确的描述,说明:
# 1. 这个技能做什么
# 2. 什么时候应该使用它
# 3. 它的核心价值是什么
# 注意:description 是智能体选择技能的唯一依据,必须写清楚!
# === 可选字段 ===
version: 1.0.0 # 语义化版本号
allowed_tools: [tool1, tool2] # 此技能可以调用的工具列表(白名单)
required_context: [context_item1] # 此技能需要的上下文信息
license: MIT # 许可协议
author: Your Name <email@example.com> # 作者信息
tags: [database, analysis, sql] # 便于分类和搜索的标签
---
# 技能标题
## 概述
(对技能的详细介绍,包括使用场景、技术背景等)
## 前置条件
(使用此技能需要的环境配置、依赖项等)
## 工作流程
(详细的步骤说明,告诉智能体如何执行任务)
## 最佳实践
(经验总结、注意事项、常见陷阱等)
## 示例
(具体的使用案例,帮助智能体理解)
## 故障排查
(常见问题和解决方案)
例如:Skill 1: sleep-quality-assessment配置如下: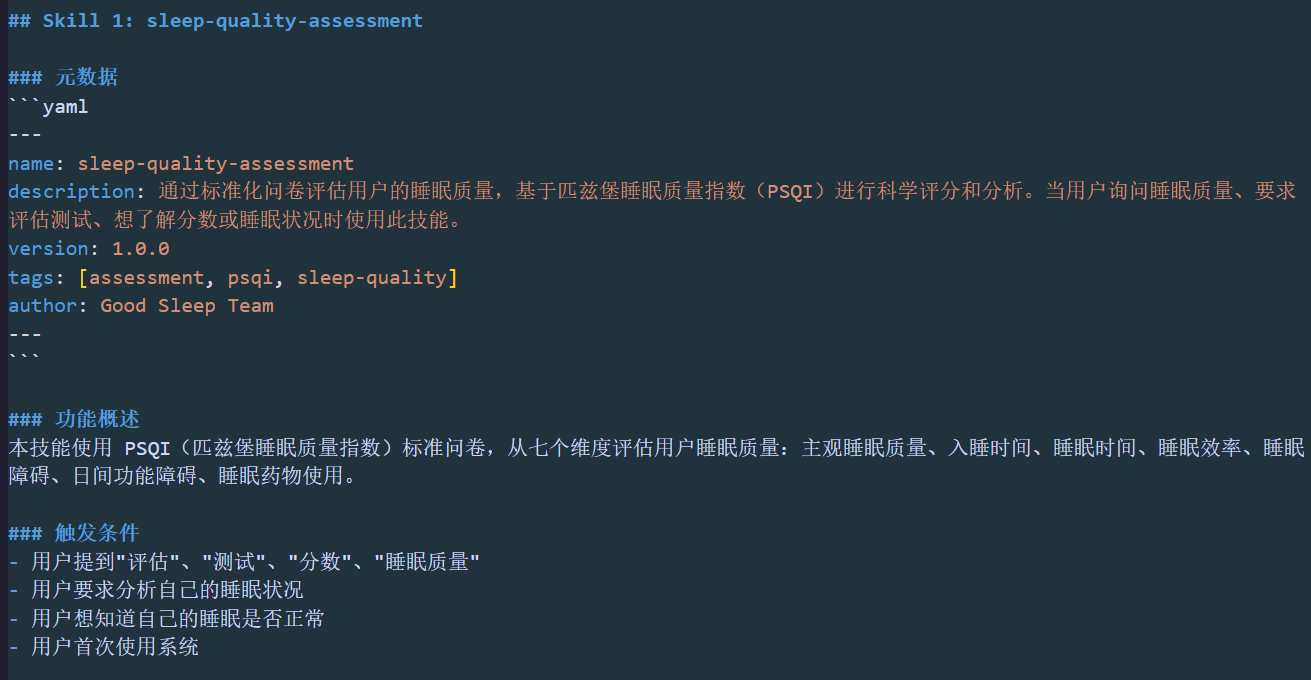
Skill 2: personalized-advice配置如下: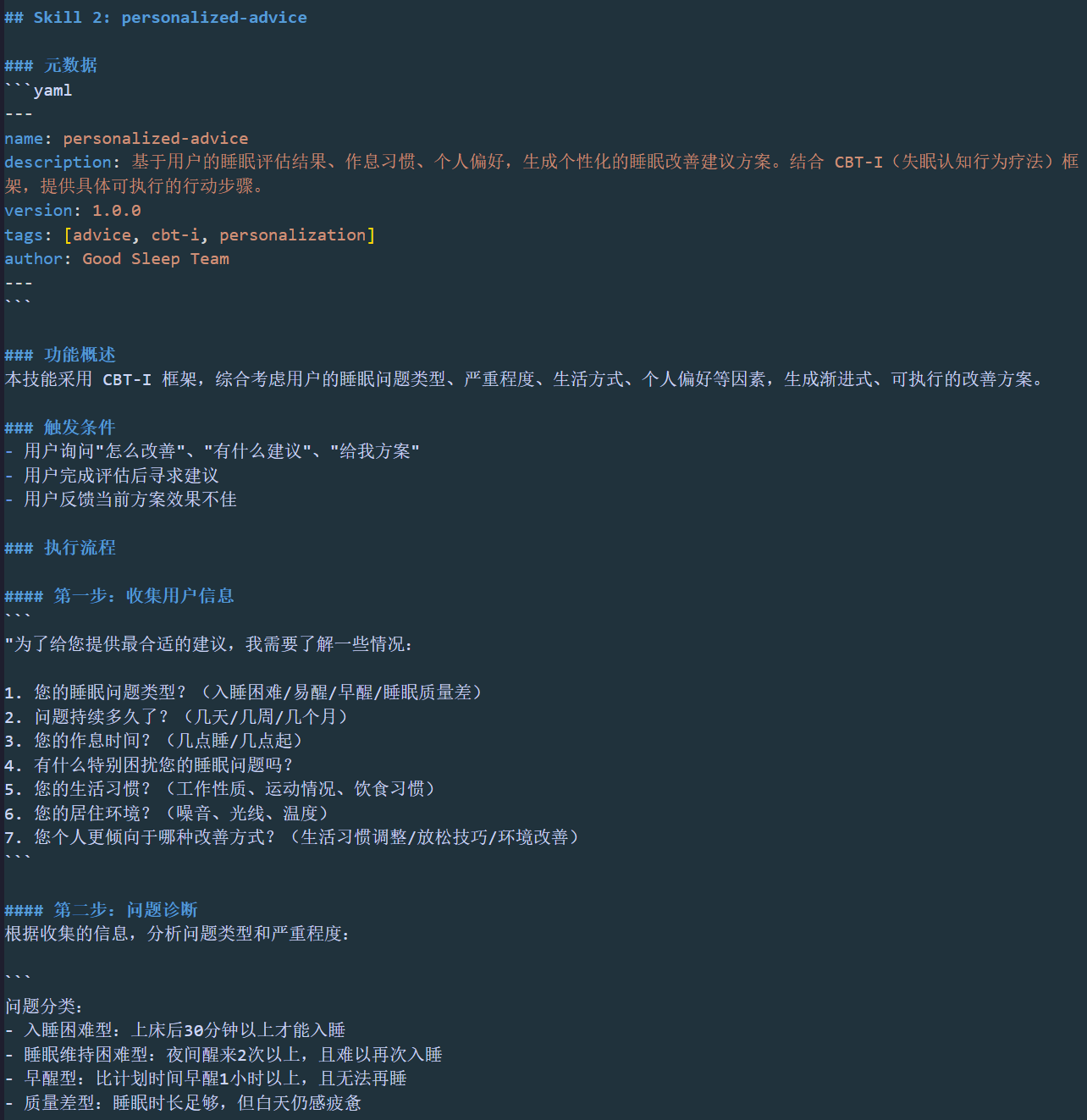
Skill 3: insomnia-diagnosis配置如下: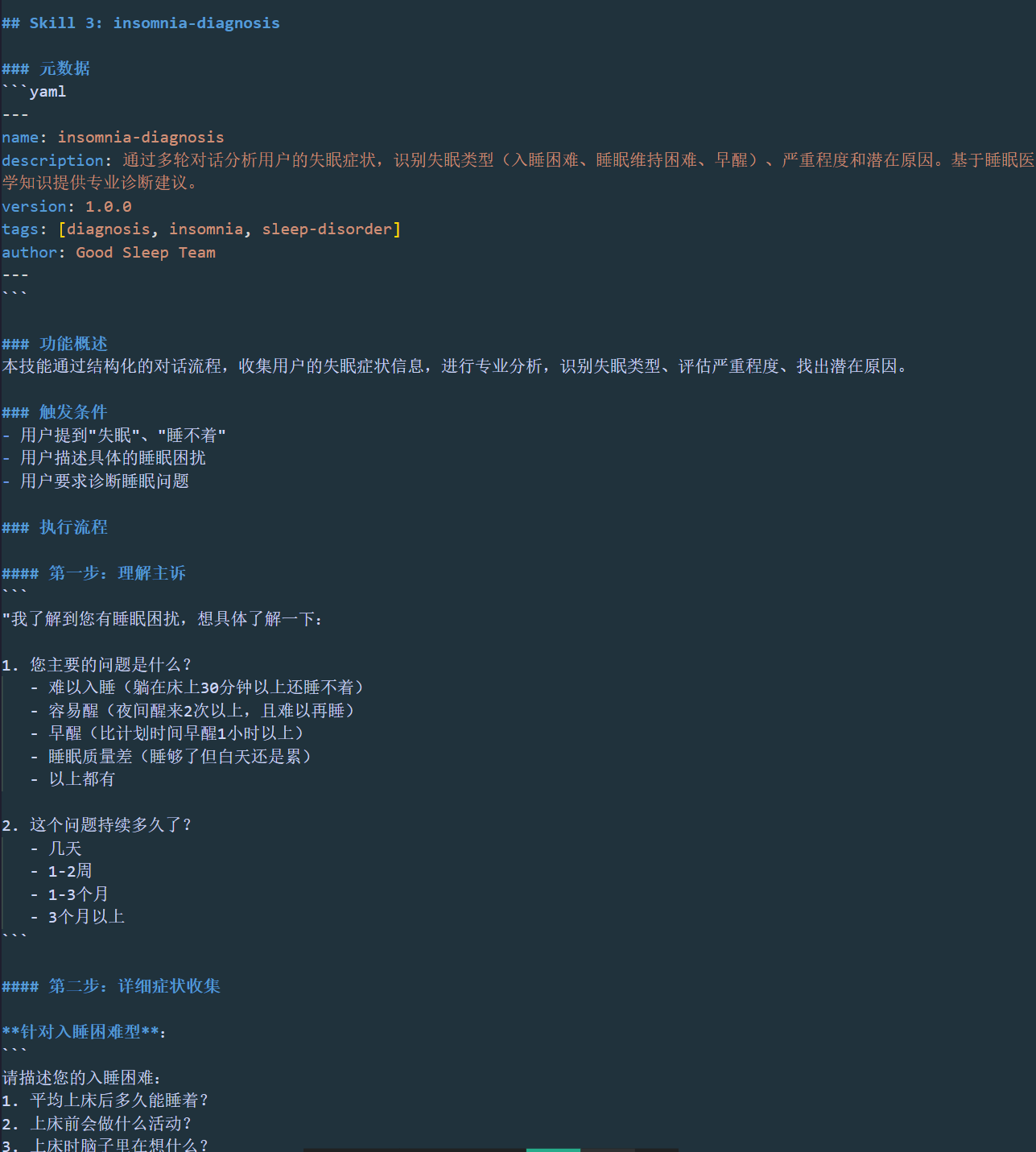
随着 Skills 数量增加,即使是元数据也可能占用大量上下文(例如安装 1000 个技能可能占用 100,000 tokens)。解决方案包括:智能索引,使用向量数据库对技能元数据进行语义索引;按需扫描,只扫描特定目录或标签的技能;分级加载,常用技能常驻内存,罕见技能按需加载。
虽然 MCP 正在标准化,但 Skills 格式尚未统一,不同厂商可能推出不兼容的规范,社区也可能分化出多个实现。应对策略是坚持 Anthropic 官方规范,推动社区达成共识,并提供兼容性适配层。
案例 1:代码审查 Skill 确保每次代码审查都遵循相同的标准,不会遗漏重要问题,关注代码质量、安全性、性能和可维护性。
案例 2:品牌一致性 Skill 确保所有对外内容(文档、邮件、演示文稿)符合公司品牌规范,包括语气、语调、视觉风格和术语使用。
案例 3:数据分析 Skill 确保财务数据分析的专业性和一致性,使用标准财务分析方法生成包含 Executive Summary、详细分析和可视化建议的报告。
4.2 编写高质量 Skills 的原则
根据 Anthropic 官方文档和社区最佳实践,编写有效的 Skills 需要遵循以下原则。
原则 1:精准的 Description
description 是智能体决策的关键。它应该精确定义适用范围,避免模糊的描述;包含触发关键词,让智能体能够匹配用户意图;说明独特价值,与其他技能区分开来。
原则 2:模块化与单一职责
一个 Skill 应该专注于一个明确的领域或任务类型。如果一个 Skill 试图做太多事情,会导致 Description 过于宽泛,匹配精度下降;指令内容过长,浪费上下文;难以维护和更新。建议与其创建一个"通用数据分析"技能,不如创建多个专门的技能,例如 mysql-employees-analysis、sales-data-analysis 和 user-behavior-analysis。
原则 3:确定性优先原则
对于复杂的、需要精确执行的任务,优先使用脚本而不是依赖 LLM 生成。例如,在数据导出场景中,依赖 LLM 生成 Excel 二进制内容容易出错且格式不标准,而使用 Python 脚本则能确保输出符合 Excel 标准。这种方式避免了 LLM 生成过程中的不确定性和幻觉问题,提高了执行的准确性和可重复性,同时也便于调试、测试和复用。
原则 4:渐进式披露策略
合理利用三层结构,将信息按重要性和使用频率分层。SKILL.md 主体放置核心工作流和常用模式;附加文档放置高级用法和边缘情况处理策略;数据文件放置大型参考数据,通过脚本按需查询,避免将整个文件加载到上下文。
4.3 Skill 文件组织最佳实践
推荐的项目结构:
agent-project/
├── .agent/
│ └── skills/ # 技能根目录
│ ├── database/ # 数据库相关技能
│ │ ├── mysql-analysis/
│ │ │ ├── SKILL.md
│ │ │ ├── resources/
│ │ │ │ └── query-templates.sql
│ │ │ └── scripts/
│ │ │ └── execute_query.py
│ │ └── postgres-analysis/
│ │ └── ...
│ ├── development/ # 开发相关技能
│ │ ├── code-review/
│ │ ├── testing/
│ │ └── deployment/
│ └── business/ # 业务相关技能
│ ├── report-generation/
│ └── customer-service/
├── .agent-config.yaml # Agent 配置文件
└── main.py # 应用入口
五、实战指南:如何开始使用 Skills
步骤 1:识别适合 Skills 化的任务
问问自己:哪些任务我经常需要 Claude 做?哪些任务的输出质量不够稳定?哪些任务每次都需要详细的指导?有哪些我希望团队成员都能做到的标准化流程?常见示例包括生成周报/月报、代码审查、文档编写、数据分析、客户邮件回复和会议纪要整理。
步骤 2:定义 Skill 的元数据
---
name: weekly-report-generator
description: >
生成本周的团队周报,包括本周完成的工作、遇到的问题、下周计划。
遵循公司标准格式:标题、本周工作列表(按优先级排序)、问题和风险(如果有)、下周计划。
适用于项目经理、团队负责人和开发者。
version: 1.0.0
author: DevOps Team
tags: [reporting, project-management, weekly]
---
关键要点:name 应简短、描述性,使用 kebab-case;description 是最重要的字段,需清晰说明这个 Skill 做什么、什么时候使用、输出格式和标准以及适用于谁。
步骤 3:编写详细的指令
(此处省略详细 Markdown 示例,参考上文周报生成工作流)
步骤 4:添加参考资料(可选)
创建 resources/ 文件夹,添加历史优秀周报示例、公司周报模板、项目优先级定义等参考资料。
步骤 5:测试和迭代
测试和迭代分为三步:首先测试,让 Claude 使用此 Skill 生成周报,检查输出是否符合预期,记录问题和改进点;其次优化,根据测试结果调整指令,补充遗漏的细节,简化过于复杂的部分;最后发布,放到团队的 Skills 库,分享给团队成员,并收集反馈持续改进。
5.4 如何安装和使用 Skills
在 Claude.ai 中使用
首先访问 Skills 页面,打开 Claude.ai,点击左侧边栏的 “Skills”,然后点击 “Create Skill”。接着创建或导入,可以直接在界面中编写新 Skill,也可以上传 SKILL.md 文件和相关资源导入。最后使用 Skill,在对话中直接提出需求,Claude 会自动选择相关 Skill,或者明确指定使用某个 Skill。
在 Claude Code 中使用
在项目结构中,将 Skills 放在 .agent/skills/ 目录下。Claude Code 会自动发现并扫描该目录,无需额外配置即可使用。在编码过程中,Claude 会自动应用相应的 Skills,例如在代码审查时应用 code-review-skill,在生成文档时使用 doc-standard-skill。
通过 API 使用
from anthropic import Anthropic
client = Anthropic(api_key="your-api-key")
# 启用 Skills
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
tools=[
{
"type": "skill",
"name": "weekly-report-generator",
"description": "生成本周的团队周报"
}
],
messages=[
{
"role": "user",
"content": "帮我生成本周的周报"
}
]
)
# Claude 会自动选择并使用相应的 Skill
六、Agent Skills 和 MCP 的选型指南
6.1 何时使用 MCP?
适用场景包括需要连接外部系统(数据库、API、文件系统),需要标准化的工具调用接口,工具数量相对较少且可以完整加载,以及需要跨平台、跨应用的兼容性。其优势在于标准化,生态丰富;实现简单,即插即用;支持多种数据源和协议。不适用场景则是工具数量庞大导致元数据占用过多上下文,需要复杂的领域知识和工作流程,或任务需要多步协同和决策。
6.2 何时使用 Skills?
适用场景包括任务需要特定的领域知识和最佳实践,有明确的工作流程和步骤,需要封装可复用的业务逻辑,需要通过脚本进行精确的执行控制,以及需要专家级、一致的输出质量。其优势在于提供专家级输出,每次都一致;捕获组织知识,将个人经验转化为团队资产;渐进式加载,成本可控;封装专业知识,提升准确性;可组合、可复用、可维护;一次构建,处处运行;以及支持复杂的业务流程。不适用场景则是非常简单、一次性的任务(直接 Prompt 更方便),不需要外部工具的纯推理任务,以及知识非常通用、不需要领域特化。
6.3 何时结合使用 MCP + Skills?
这是最推荐的架构,适用于大多数实际应用。
适用场景包括需要连接外部系统(MCP),需要领域知识和工作流程(Skills),需要优化上下文管理,需要可维护的架构,以及需要专家级、一致的输出。实施步骤建议:首先使用 MCP 连接所需的外部系统,然后为每个业务领域创建相应的 Skill,接着在 Skill 中定义如何使用 MCP 工具,最后通过 Workflow 编排多个 Skill。
对于个人开发者,建议从官方 Skills 库开始学习最佳实践,先创建简单的 Skills(如文档处理、数据分析),逐步学习脚本集成和 MCP 调用,构建个人的 Skills 工具箱,并利用内置工作流快速上手。
对于团队/企业,首先要识别可标准化的业务流程,找出需要频繁执行、输出质量不稳定或依赖个人经验的任务;其次构建企业内部的 Skills 库,按部门或职能分类,建立统一的元数据和命名规范,并进行版本控制;再次统一 MCP 接口,共享 MCP 服务器资源,建立服务注册和发现机制,避免重复开发;然后建立 Skills 的版本管理和测试机制,定期 review 和更新,建立测试验证流程,收集反馈持续优化;最后培训团队成员,定期组织分享会,建立最佳实践文档,鼓励贡献和分享。
我个人认为,Skills本身即代表了高性能、可复用的团队经验,对于团队的价值甚至远高于个人。
对于产品/技术决策者,应关注 Skills 标准化进展,评估现有系统与 Skills 的兼容性,考虑 Skills 带来的成本优势(专家级输出,一致性强),探索 Skills 的商业化机会(行业标准、领域知识包),并投资 Skills 生态建设。
总结:Agent Skills 是未来范式还是概念炒作?
在深入研究了 Agent Skills 的技术细节、实践案例和生态演进后,我们需要面对一个终极问题:Agent Skills 到底代表了 AI 的未来范式,还是又一个昙花一现的概念炒作?
这是一个值得严肃思考的问题。
很多 Agent 方案停留在 PPT 和 Demo 阶段。Anthropic 的所有方案都有一个特点:能立即落地,产生真金白银的价值。 Coding Agent 让程序员付费提升开发效率,MCP 让开发者接入外部系统扩展 Agent 能力,Skills 帮助企业封装知识资产降低使用门槛。这些都不是"未来可能会",而是"现在就能用"。务实求真,这是 Anthropic 成功的关键。
基于 Good Sleep 项目实践,我对 Agent Skills 的未来充满信心。短期(1-2年)标准化程度提升、生态成熟;中期(3-5年)Skills 市场出现、行业标准建立;长期(5-10年)跨平台兼容、成为知识传递载体、软件行业开发模式根本变革。
Good Sleep 项目验证了 Agent Skills 的核心价值:渐进式披露解决上下文管理困境,专业分工提升准确性,标准化输出保证可靠性,知识封装实现资产化,可组合架构提供灵活性。这不仅是技术架构,更是思维方式的转变——从"让 AI 理解我们"到"让 AI 成为我们"。拥抱 Agent Skills,就是拥抱 AI 应用开发的未来。
基于以上分析,我认为 Agent Skills 不仅仅是一个技术工具,更是一种思维方式的转变。它标志着 AI 应用开发从"提示词工程(Prompt Engineering)"时代,正式进入了"认知工程(Cognitive Engineering)"时代。
在 Prompt Engineering 时代,我们试图通过巧妙的话术来激发大模型的能力;而在 Agent Skills 时代,我们通过标准化的结构来塑造和封装大模型的能力。
这一转变的意义,不亚于从汇编语言到高级语言的跨越。
因此,Agent Skills 极大概率会成为未来 AI Agent 开发的标准范式。具体的 YAML 字段定义可能会变,文件结构可能会变,但其核心思想——渐进式披露、能力与连接分离、知识资产化——将长期存在,并成为构建复杂智能体系统的基石。
对于每一个 AI 开发者和企业来说,现在开始拥抱 Agent Skills,就是在拥抱 AI 应用开发的未来。
技术发展的洪流滚滚向前,Anthropic 用 Agent Skills 为我们指明了一个清晰的方向:标准化、专业化、务实化。
在这个 AI 变革的时代,我们要做的不是焦虑地观望,而是躬身入局。去编写你的第一个 Skill,去封装你的独特知识,去构建你的智能体工具箱。
因为在 AI 时代,你的知识如何被 AI 理解和使用,将决定你的价值。
参考资源

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)