Gemini 3 全面解析:特性、实操与代码示例
2026年初,Google正式推出Gemini 3系列模型,作为其迄今为止最智能的AI模型家族,它在高级推理、自主编码、多模态处理等领域实现了全方位突破,旨在通过强大的技术能力,将开发者的任何想法快速转化为现实。不同于前序版本,Gemini 3不仅优化了模型性能,更引入了可灵活调控的推理机制、生成式UI等全新功能,同时提供了简洁易用的API接口,让开发者无需深入底层开发,即可快速集成其核心能力。本文将从Gemini 3的核心特性出发,搭配可直接运行的代码示例,帮助开发者快速上手这款新一代AI模型。

一、Gemini 3 核心特性概览
Gemini 3系列包含三款核心模型,分别适配不同场景需求,整体具备以下四大核心优势,为开发提供更灵活、高效的支撑:
-
强大的多模型适配:Gemini 3 Pro主打复杂任务处理,Gemini 3 Flash兼顾速度与性价比,Gemini 3 Pro Image(Nano Banana Pro)专注高质量图片生成,均处于预览阶段,可根据需求灵活选择。
-
可控的推理能力:引入
thinking_level参数,支持低、中、高、极简四个推理级别,可根据任务复杂度调控推理深度,平衡延迟与效果。 -
全场景多模态融合:无缝整合文本、图像、视频、音频和代码,在视觉推理、跨模态交互等领域实现突破,甚至能识别模糊字符、解析复杂图表。
-
高效的编码与开发支持:支持Vibe Coding编程范式,可通过自然语言生成完整应用,代码生成速度与质量显著提升,同时兼容多种编程语言与开发场景。
此外,Gemini 3系列均支持100万token的超大上下文窗口(部分模型除外),知识截点更新至2025年1月,可轻松处理300页文档或1小时视频等大规模数据,大幅降低长文本、复杂任务的开发难度。
二、Gemini 3 实操准备:环境搭建与API配置
在使用Gemini 3进行开发前,需完成基础环境搭建与API密钥配置,步骤如下:
-
获取Gemini API密钥:访问Google AI开发者平台,注册并创建项目,在项目中申请Gemini API密钥(需注意保护密钥安全,避免公开泄露)。
-
安装依赖库:Gemini 3提供Python、JavaScript等多种语言的SDK,本文以Python为例,通过pip安装官方依赖库。
基础环境安装(Python)
# 安装Google Gemini官方Python SDK pip install google-generativeai安装完成后,即可通过SDK初始化客户端,关联API密钥,开始调用Gemini 3模型的各项能力。
三、Gemini 3 核心功能代码示例
以下代码示例涵盖Gemini 3最常用的三大场景:基础文本生成、推理级别调控、多模态(文本+图像)交互,所有代码均可直接替换API密钥后运行,适配Gemini 3 Pro预览版。
示例1:基础文本生成(代码调试场景)
Gemini 3 Pro具备强大的自主编码能力,可快速识别代码中的问题(如竞态条件)并给出解决方案,适用于日常开发中的代码调试场景,代码如下:
# 导入Gemini SDK
from google import genai
# 1. 初始化客户端(替换为你的API密钥)
genai.configure(api_key="YOUR_GEMINI_API_KEY")
# 2. 选择Gemini 3 Pro预览版模型
model = genai.GenerativeModel("gemini-3-pro-preview")
# 3. 定义待调试的多线程C++代码片段
cpp_code = """
#include <iostream>
#include <thread>
using namespace std;
int count = 0;
void increment() {
for (int i = 0; i < 10000; ++i) {
count++; // 存在竞态条件的代码
}
}
int main() {
thread t1(increment);
thread t2(increment);
t1.join();
t2.join();
cout << "最终计数: " << count << endl;
return 0;
}
"""
# 4. 调用模型识别代码中的竞态条件并给出修复方案
prompt = f"请找出以下多线程C++代码中的竞态条件,并给出修复后的完整代码和详细说明:\n{cpp_code}"
response = model.generate_content(prompt)
# 5. 输出结果
print("Gemini 3 代码调试结果:")
print("="*50)
print(response.text)
运行结果说明:模型会精准识别出count++语句中的竞态条件(多线程同时操作共享变量),并给出两种修复方案——使用互斥锁(mutex)或原子变量(atomic),同时附带修复后的完整代码和原理说明,大幅提升调试效率。

示例2:推理级别调控(平衡延迟与效果)
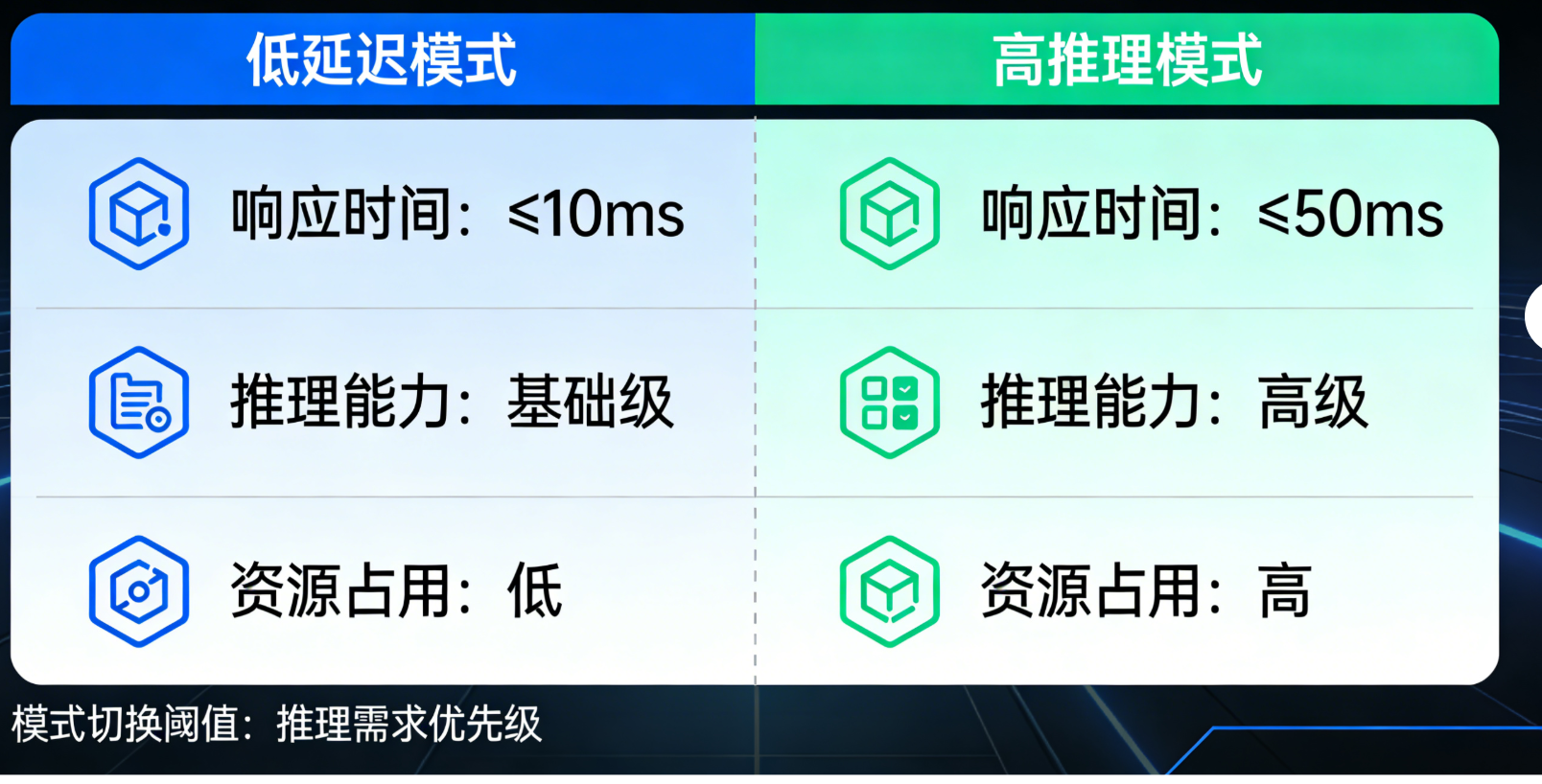
Gemini 3引入的thinking_level参数,可灵活调控模型的推理深度,适用于不同延迟需求的场景(如简单聊天需低延迟,复杂推理需高深度)。以下代码演示如何设置推理级别:
from google import genai
from google.genai import types
# 初始化客户端(替换为你的API密钥)
genai.configure(api_key="YOUR_GEMINI_API_KEY")
# 选择Gemini 3 Pro预览版模型
model = genai.GenerativeModel("gemini-3-pro-preview")
# 定义两个不同复杂度的任务
simple_task = "解释什么是AI,用一句话概括" # 简单任务,适合低延迟
complex_task = "详细阐述Gemini 3的Deep Think模式与传统推理模式的区别,结合具体应用场景说明" # 复杂任务,适合高推理深度
# 1. 低推理级别(low):适用于简单任务,低延迟优先
print("【低推理级别 - 简单任务】")
print("任务:", simple_task)
response_low = model.generate_content(
contents=simple_task,
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="low")
)
)
print("结果:", response_low.text)
print("\n" + "="*60 + "\n")
# 2. 高推理级别(high):适用于复杂任务,推理深度优先(默认级别)
print("【高推理级别 - 复杂任务】")
print("任务:", complex_task)
response_high = model.generate_content(
contents=complex_task,
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(thinking_level="high")
)
)
print("结果:", response_high.text)
关键说明:Gemini 3 Pro支持low和high两个推理级别,Gemini 3 Flash额外支持minimal(极简,最低延迟)和medium(平衡)级别,可根据实际场景灵活配置,兼顾效果与性能。
示例3:多模态交互(文本+图像识别)
Gemini 3 Pro Image(gemini-3-pro-image-preview)具备强大的图像识别能力,可结合文本提示,解析图像内容、识别元素并生成相关结果。以下代码演示如何实现文本+图像的多模态交互:
from google import genai
import base64
# 初始化客户端(替换为你的API密钥)
genai.configure(api_key="YOUR_GEMINI_API_KEY")
# 选择Gemini 3 Pro Image预览版模型(专注图像处理)
model = genai.GenerativeModel("gemini-3-pro-image-preview")
# 工具函数:将本地图像转为base64格式(适配API输入要求)
def image_to_base64(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 1. 准备图像(替换为你的本地图像路径,如电路图、图表等)
image_path = "test_image.png"
image_base64 = image_to_base64(image_path)
# 2. 定义文本提示(结合图像需求,明确任务)
prompt = {
"contents": [
{
"parts": [
{
"text": "请详细分析这张图像的内容,识别图像中的所有关键元素,若为图表请解读数据,若为电路图请识别电阻、电容位置,给出详细的分析报告"
},
{
"inlineData": {
"mimeType": "image/png", # 图像格式,根据实际调整(jpg/png等)
"data": image_base64
}
}
]
}
]
}
# 3. 调用模型进行多模态识别
response = model.generate_content(prompt)
# 4. 输出识别结果
print("Gemini 3 多模态图像识别结果:")
print("="*50)
print(response.text)
运行说明:需将image_path替换为本地图像路径(支持png、jpg等格式),模型可精准识别图像内容,包括模糊字符、复杂图表、电路图等,甚至能模拟物理现象(如柠檬落水的水花、光影效果),多模态融合能力远超前序版本。
四、Gemini 3 开发注意事项与进阶方向
1. 开发注意事项
-
模型兼容性:目前Gemini 3系列均为预览版,部分高级功能(如Deep Think、Gemini Agent)仅限Google AI Ultra订阅用户使用。
-
密钥安全:API密钥是调用模型的核心凭证,需妥善保管,避免嵌入公开代码、前端页面中,建议通过环境变量管理密钥。
-
定价说明:不同模型的定价差异较大,Gemini 3 Flash性价比最高,Gemini 3 Pro Image的定价与图像分辨率相关,需注意控制token使用量以降低成本。
2. 进阶开发方向
基于Gemini 3的核心能力,开发者可探索以下进阶场景,实现更具创新性的应用:
-
生成式UI开发:结合Gemini 3的生成式UI能力,通过提示词生成沉浸式界面、动态Web应用,甚至一键生成Web操作系统。
-
智能体开发:利用Gemini Agent的自主任务执行能力,开发邮件管理、旅行规划等多步骤任务应用,自主调用搜索、日历等工具。
-
全息交互开发:结合Three.js等前端技术,实现手势控制、全息展示等交互效果,如全息便签墙、3D模型交互等。
五、总结
Gemini 3系列模型的推出,标志着AI从“回答问题”向“完成工作”的范式转变,其强大的推理能力、多模态融合能力、编码支持能力,为开发者提供了更广阔的创作空间。本文通过核心特性解析+可运行代码示例,帮助开发者快速上手Gemini 3的基础开发,无论是简单的文本生成、代码调试,还是复杂的多模态交互、智能体开发,Gemini 3都能凭借简洁的API接口和强大的底层能力,大幅提升开发效率。
随着预览版的不断优化,Gemini 3未来将开放更多高级功能,适配更多行业场景。对于开发者而言,尽早熟悉其API使用与核心特性,将能在AI开发浪潮中抢占先机,打造更具创新性的应用产品。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)