生产级智能体RAG入门指南(6种RAG模式详解含示例)
智能体RAG:优化检索增强生成的新范式 传统RAG对所有查询采用固定流程,导致无关检索、高成本和延迟问题。智能体RAG通过动态决策优化流程,系统自主判断何时检索、检索什么及何时停止。本文解析六种智能体RAG模式: 条件式:单步判断是否需检索 迭代式:多轮优化检索查询 工具路由:智能选择数据源 基于规划:预先制定执行步骤 自评估:生成后验证答案质量 多智能体:并行处理复杂子任务 实际应用中,简单模式
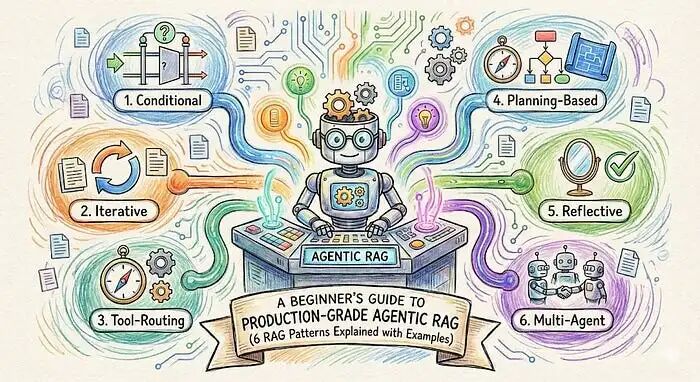
六种智能体RAG模式及其实际生产权衡解析
大多数RAG演示在真实用户出现之前都能正常工作。然而,一旦投入实际使用,它们就会检索到无关的上下文,浪费token,仍然产生幻觉。问题不在于模型或检索本身。
问题在于传统RAG对所有查询都采用相同的处理方式。
智能体RAG改变了这一点。系统不再总是进行检索,而是决定何时检索、检索什么、以及何时停止。
本指南将解释什么是智能体RAG、为什么传统RAG在生产环境中失效,以及如何为实际系统选择正确的智能体RAG模式。
传统RAG的工作原理(从第一性原理出发)
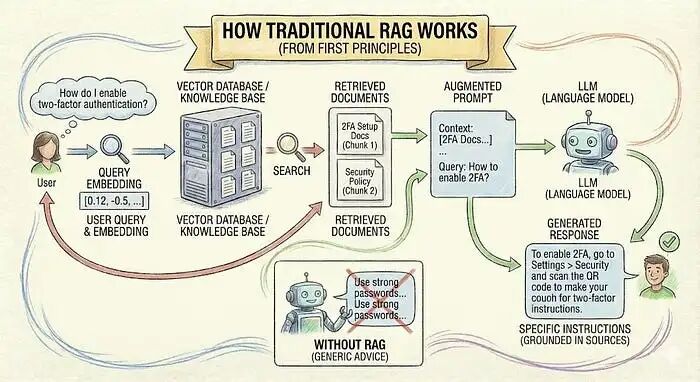
让我们先了解一下传统RAG的工作原理。检索增强生成(RAG)结合了多个步骤:
- • 检索相关信息并基于检索结果生成响应。不再仅依赖模型在训练期间学到的知识,
- • 在查询时引入外部数据。这很重要,因为语言模型有知识截止日期。它们不知道你的内部流程或最近的变更。如果信息不在提示中,模型就无法使用它。
- • RAG通过搜索知识库、将相关文档添加到提示中,并基于这些来源生成有依据的答案来解决这个问题。
示例: 你正在为一款SaaS产品构建支持机器人。用户问"如何启用双因素认证?"没有RAG,模型可能会给出通用的安全建议。有了RAG,系统会检索你实际的设置文档,并生成针对你产品的具体说明。
基本流程很简单: - • 将用户查询转换为数值表示(嵌入)
- • 在向量数据库中搜索具有相似嵌入的文档
- • 取排名最高的结果并将它们添加到提示中
- • 生成响应
这很有效。但它存在问题。
为什么传统RAG在生产环境中失效
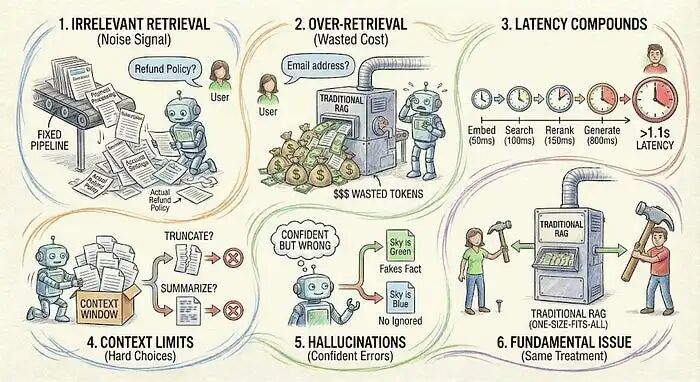
固定管道方法以可预测的方式失败。
- • 无关检索持续发生。用户问"你们的退款政策是什么?"系统检索关于支付处理、订阅管理和账户设置的文档,因为它们都提到了钱。实际的退款政策可能埋在第五个结果中。模型现在必须从噪音中筛选出信号。
- • 过度检索浪费token和金钱。简单问题与复杂问题受到相同对待。用户问"你们的电子邮件地址是什么?"系统仍然检索五个文档并传递给模型。你刚刚为一个模型可以直接回答的问题花费了10倍的token。
- • 延迟在管道中累积。嵌入查询(50毫秒)。搜索数据库(100毫秒)。重排结果(150毫秒)。生成响应(800毫秒)。一个简单问题你需要1.1秒。用户能察觉到。
- • 上下文限制迫使你做出艰难选择。你可以检索10个文档,但它们不能全部放入上下文窗口。你是截断它们?还是先总结它们?每种选择都会引入新的失败模式。
- • 幻觉持续存在,即使检索效果很好。模型可能会抓住检索上下文中的一个句子,然后围绕它构建整个响应,忽略其他文档中的矛盾信息。或者它可能会将检索到的信息与其训练数据混合,产生自信但错误的答案。
根本问题在于传统RAG对所有查询采用相同的方式处理。它检索相同数量的文档,使用相同的搜索策略,遵循相同的生成模式,而不管用户实际需要什么。
"智能体RAG"的实际含义
智能体RAG赋予系统决策能力。它不是遵循固定管道,而是在每个步骤推理应该做什么。
可以这样想:如果传统RAG是管道,那么智能体RAG就是决策树。
- • 在传统RAG中,每个查询遵循相同的路径: 检索,然后生成。
- • 在智能体RAG中,系统根据观察到的情况进行分支: 我应该检索吗?我应该搜索哪些来源?检索的信息是否足够?我需要更多信息吗?
这不意味着系统变得自主或不可预测。这意味着你使用语言模型的推理能力来引导检索过程,而不仅仅是生成步骤。
一个简单的例子可以澄清这一点。
用户问"240的15%是多少?"传统RAG可能会检索关于百分比的文档。智能体RAG认识到这是一个数学问题,模型可以直接解决,完全跳过检索。
另一个用户问"过去两年我们的定价是如何变化的?"传统RAG检索当前的定价页面。智能体RAG认识到它需要历史数据,搜索归档文档,比较版本,并综合这些变化。
"智能体"部分指的是这个决策循环。
系统观察查询,决定一个动作(检索、计算、生成),评估结果,并决定是继续还是返回答案。
核心智能体RAG工作流
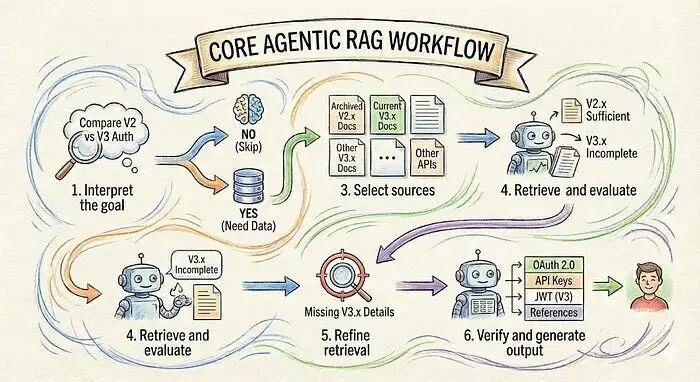
让我们看看智能体RAG系统如何使用文档助手处理真实查询。
查询:“比较2.x和3.x版本中的认证方法”
系统通过一系列决策:
1. 解读目标
模型认识到这是一个比较任务,而不是简单的查找。它需要来自两个不同版本的信息,并必须提取和对比功能。
2. 决定是否检索
模型检查这是否能仅从训练数据中回答。不能,所以需要检索。
3. 选择来源
系统不是搜索所有内容,而是选择:
- • 2.x版本的归档文档
- • 3.x版本的当前文档
传统RAG系统会跨所有来源发出一次广泛的搜索。
4. 检索并评估
系统检索两个版本的文档并评估完整性: - • 2.x版本的内容足够
- • 3.x版本的内容不完整,引用了另一个指南
系统决定再次检索。
5. 优化检索
它发出针对性搜索,检索缺失的v3.x认证详情,并获取所需信息。
6. 验证并生成
从两个版本获得足够信息后,系统生成结构化比较: - • OAuth 2.0和API密钥(两个版本)
- • JWT(仅v3.x)
- • 引用具体文档章节
这就是使工作流具有智能体特性的地方。
系统选择何时检索、使用哪些来源,以及是否需要另一次检索。传统RAG管道会检索一次并希望初始结果足够。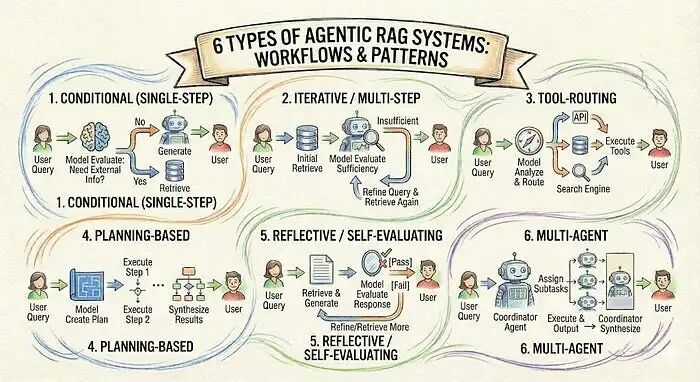
六种智能体RAG系统类型
智能体RAG不是单一架构。它是一系列模式,在检索过程的不同点添加决策能力。
条件式(单步)智能体RAG
最简单的智能体行为形式是决定是否进行检索。在任何检索发生之前,模型会评估查询。
这能从模型的训练数据中回答吗?它需要当前信息吗?它是不需要检索的计算或推理任务吗?
基于这种评估,系统要么跳过检索直接生成,要么检索一次然后生成。
工作原理:
- • 用户查询到达
- • 模型评估:这需要外部信息吗?
- • 如果不需要:从模型知识直接生成响应
- • 如果需要:检索相关文档,然后生成
- • 返回响应
当你的查询混合时,这种模式表现出色。有些需要当前数据(产品规格、文档)。其他的不需要(一般知识、数学、推理)。你想避免不必要的检索成本。
优点: - • 在混合使用应用中减少30-40%查询的检索成本
- • 对不需要检索的查询更快
- • 简单实现和调试
- • 通常总体成本更低,延迟相似
缺点: - • 在检索前添加一次LLM调用(200-300毫秒)
- • 模型可能错误决定跳过检索
- • 需要为你的用例调整决策提示
迭代/多步智能体RAG
有时第一次检索不够。系统检索、评估结果,并决定是否用优化后的查询再次检索。
工作原理:
- • 基于用户查询执行初始检索
- • 模型评估检索内容的充分性和相关性
- • 如果不够:制定优化查询,再次检索
- • 重复最多达最大迭代次数(通常2-3次)
- • 从累积的上下文生成最终响应
当查询经常模糊,或你的知识库大且多样时使用这个。初始检索经常偏离目标,基于发现的内容进行渐进优化可以改善结果。
优点: - • 显著提高复杂查询的答案质量
- • 处理需要澄清的模糊问题
- • 可以从糟糕的初始检索中恢复
缺点: - • 每次迭代增加延迟(检索+评估周期)
- • 多步骤导致更高的token使用
- • 需要仔细设置停止条件以避免无限循环
工具路由智能体RAG
许多应用有多个检索来源:文档数据库、API、搜索引擎和用户数据库。工具路由系统分析查询并决定使用哪些来源。
工作原理:
- • 分析用户查询以了解信息需求
- • 模型决定哪些数据来源相关
- • 路由到适当的工具:API、数据库、搜索引擎等
- • 根据需要顺序或并行执行工具
- • 基于工具输出生成响应
当你有异构数据来源且不同查询类型需要不同后端时,这种模式有意义。你想避免为每个查询搜索所有内容。
优点: - • 通过使用正确的数据来源显著提高相关性
- • 减少跨无关来源的不必要搜索
- • 可以结合实时API数据和静态文档
- • 仅访问需要的来源以优化成本
缺点: - • 需要仔细的工具定义和清晰描述
- • 路由决策添加一次LLM调用
- • 错误路由将查询发送到错误来源
- • 更复杂的工具管理和错误处理
基于规划的智能体RAG
对于需要特定顺序的多个步骤的复杂查询,基于规划的系统在采取行动之前创建计划。系统将查询分解为步骤,确定每步需要什么信息,然后执行计划。
工作原理:
- • 模型分析查询并创建多步计划
- • 计划指定要检索什么、计算什么以及按什么顺序
- • 系统逐步执行计划
- • 每步的结果为后续步骤提供信息
- • 最后一步将所有结果综合成响应
当查询始终复杂且多方面、操作顺序重要,且你需要将检索与计算或API调用结合时,使用这个。
优点: - • 处理需要顺序操作的复杂查询
- • 计划提供推理过程的透明度
- • 可以在执行前验证计划
缺点: - • 规划步骤预先增加延迟
- • 计划可能不正确,导致走向错误路径
- • 如果早期步骤失败则难以恢复
反思/自评估智能体RAG
在生成响应后,某些系统会在返回给用户之前评估自己的输出的准确性和完整性。
工作原理:
- • 从检索信息生成初始响应
- • 评估步骤根据质量标准评估响应
- • 如果评估通过:返回响应
- • 如果评估失败:检索更多信息或根据反馈重新生成
当答案质量至关重要、幻觉代价高,且你有明确的标准判断什么是好答案时,这种模式很合适。
优点: - • 在幻觉到达用户之前捕获它们
- • 提高答案的完整性和准确性
- • 提供质量保证层
缺点: - • 使生成成本翻倍(初始+评估)
- • 增加500-1000毫秒延迟
- • 需要清晰、可衡量的评估标准
多智能体RAG
多个专业智能体处理查询的不同方面。协调器将查询分解为子任务并分配给专业智能体。每个智能体有自己的上下文、工具和指令。
工作原理:
- • 协调器分析查询并识别子任务
- • 将每个子任务分配给专业智能体
- • 智能体使用自己的工具并行执行
- • 协调器从智能体输出综合最终响应
现实是:你很少需要这个。只有当你有真正可以并行运行的独立子任务,且更简单的模式已被证明不够时,才使用这种模式。
优点: - • 允许独立子任务并行执行
- • 每个智能体针对特定任务类型优化
- • 如果并行做得好可以减少延迟
缺点: - • 实现复杂度高
- • 调试困难
- • 智能体之间的上下文管理很棘手
- • 大多数生产系统从更简单的模式中获得更好的结果
暂停:到目前为止我们涵盖的内容
此时,你理解了核心区别:传统RAG是固定管道,智能体RAG是决策系统。你已经看到了六种模式,每种都逐渐增加更多的智能体性。大多数生产系统使用其中一两种,而不是全部六种。
我们涵盖的模式处理智能体RAG的"什么"和"如何"。现在我们将解决实际问题:控制延迟和成本,以及选择真正适合你用例的模式。
管理延迟和成本的生产模式
智能体行为增加了灵活性,但也会增加成本和延迟。以下是如何控制两者。
基于置信度的条件检索
在检索之前,问模型:"以1-10分计,你对这个查询需要外部信息的置信度是多少?"如果置信度低于7,就检索。如果高于7,直接生成。这个简单的启发式方法在混合使用应用中减少了30-40%的不必要检索。
迭代系统中的早期停止
设置质量阈值。每次检索后,评估信息是否足够。如果超过阈值,就停止。不要迭代到固定次数。这在第一次或第二次尝试成功时防止不必要的检索周期。
多级缓存
- • 对常见查询缓存嵌入
- • 缓存检索结果1-24小时(取决于数据新鲜度要求)
- • 对真正相同的查询缓存完整响应
- • 使用语义缓存来识别"如何重置密码?"和"我忘了密码,该怎么做?"是同一个问题
- • 对于FAQ风格的应用可以将API调用减少50-70%
先浅后深的检索
从快速、近似检索开始。快速返回20个候选。如果模型确定需要更多上下文或更高精度,执行更慢但更彻底的搜索。这保持常见情况快速,同时在需要时允许深度。
并行流式评估
不要等到完整检索完成才开始评估。当块从数据库返回时,立即开始评估相关性。当所有块到达时,你已经评估了第一批,可以更快地做出检索决策。
预算感知的迭代限制
为每个查询设置token预算。跟踪检索和生成步骤中的使用情况。当你接近预算时,强制系统用已有信息生成。这防止复杂查询的成本失控,同时仍允许大多数情况进行迭代。
非关键路径的异步优化
快速返回初始答案。继续在后台使用反思模式优化。如果优化后的答案明显更好,通知用户。大多数用户更喜欢快速、足够的答案,而不是等待完美的答案。
关键是度量。检测每个步骤。跟踪每个代码路径处理的查询百分比。测量每种模式的延迟和token使用。优化处理最多流量的慢路径。
如何选择正确的智能体RAG模式
首先回答这些问题。每个问题都会缩小哪种模式适合你的用例。
模型能否仅从训练数据回答大多数查询?
如果是:从条件单步智能体RAG开始。让系统在可能时跳过检索。这是最简单的智能体模式,通常就足够了。
如果不是:继续下一个问题。
你是否 有需要不同访问方法的多个不同数据来源?
如果是:使用工具路由智能体RAG。让系统选择要查询哪个后端。这防止搜索无关来源并提高精度。
如果不是:继续下一个问题。
查询是否经常模糊或不明确?
如果是:考虑迭代智能体RAG。允许系统基于发现的内容优化搜索。将迭代限制在2-3次以控制延迟。
如果不是:继续下一个问题。
查询是否需要特定顺序的多个步骤?
如果是:使用基于规划的智能体RAG。让系统创建并执行计划。当顺序重要时这很有效(比如在检查资格之前查找先决条件)。
如果不是:继续下一个问题。
错误答案的代价是否很高?
如果是:在所选模式之上添加反思/自评估行为。这在错误到达用户之前捕获它们。接受延迟成本。
如果不是:你选择的基础模式可能就足够了。
其他考虑因素:
你的应用对延迟有多敏感?实时聊天需要条件单步。批处理可以使用带反思的基于规划。
你的错误容忍度是多少?高风险应用(医疗、法律、金融)受益于自评估。低风险应用可以跳过它。
你的数据有多复杂?简单、结构良好的文档用条件检索效果很好。混乱、异构数据受益于工具路由或迭代方法。
你的预算是多少?更多智能体行为意味着更多LLM调用。如果你受成本约束,从简单的开始,只有在度量证明需要时才增加智能体性。
大多数应用最终是混合体:条件检索跳过不必要的搜索,工具路由选择正确的数据来源,以及对标记为高风险的查询可选的自评估。
结论
智能体RAG是一个频谱,而不是二元选择。
一端是固定管道的传统RAG。另一端是完全自主的系统,它们规划、执行、评估和迭代。大多数生产系统处于两者之间。
从解决你 immediate问题的最简单模式开始。彻底检测它。测量它在哪里失败。只有在解决那些特定失败时才增加智能体性。
如果90%的查询用传统RAG能正常工作,不要到处添加智能体性。把它加到那10%有困难的查询上。
如果检索快速且便宜,你可能不需要条件逻辑。如果你的数据是同质的,你不需要工具路由。
目标不是构建最复杂的系统,而是构建在延迟和成本约束内可靠地为用户服务的系统。
智能体RAG给你工具来处理简单检索不足的情况。明智地使用它们。生产中效果最好的系统是那些只在合理的地方增加复杂性、测量一切、并将用户体验置于首位的系统。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇
g_convert/212274dbce537968b9e70bf62341ad85.png)
配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献706条内容
已为社区贡献706条内容

所有评论(0)