OpenClaw跟Skills、MCP、RAG和Agent有什么关系?
昨天,一个刚入行的小伙伴在群里问我:苏三哥,我看了两天OpenClaw的资料,什么Skills、MCP、RAG、Agent,这些词看得我头都大了。它们到底啥关系?OpenClaw又是干啥的?我回了他一句:“你见过小龙虾吗?OpenClaw就是那只‘龙虾’,其他都是它的‘钳子’、‘脑子’和‘食谱’。最近OpenClaw在GitHub上狂揽近30万星标,成为2026年开年最火的开源项目。但很多小伙伴和
前言
昨天,一个刚入行的小伙伴在群里问我:苏三哥,我看了两天OpenClaw的资料,什么Skills、MCP、RAG、Agent,这些词看得我头都大了。
它们到底啥关系?
OpenClaw又是干啥的?”
我回了他一句:“你见过小龙虾吗?OpenClaw就是那只‘龙虾’,其他都是它的‘钳子’、‘脑子’和‘食谱’。”
最近OpenClaw在GitHub上狂揽近30万星标,成为2026年开年最火的开源项目。但很多小伙伴和我那位同事一样,被一堆新概念绕晕了。
今天,我准备用一张图、一个故事,把这几个概念彻底讲清楚。
希望对你会有所帮助。
01 一个故事讲清所有概念
在讲技术之前,我先讲个故事。
假设你是一个古代的皇帝(用户),你有一个军师(AI模型),军师很聪明,但他不能离开军师府(云端),也不知道外面发生了什么。
你想知道边疆的战况(实时信息),军师说:“我不知道,我没去过边疆。”——这就是知识截止问题。
你让人把边疆的地图、情报都搬进军师府,军师看了之后告诉你战况。——这就是RAG(检索增强生成)。
你觉得不够,想让军师直接指挥边疆的士兵。你说:“让张三将军出兵!”军师说:“我不认识张三,也不知道怎么调兵。”——这就是行动能力缺失问题。
你告诉军师:“你要调兵,就写一道圣旨,格式是:‘调兵:将军=张三,数量=1000’。”然后你安排一个传令官,拿着圣旨去调兵。——这就是Function Calling(函数调用)。
后来,你需要调兵、调粮草、调民夫,每个都有自己的格式和流程。你给每个将军都配了一个传令官,还定了一套规矩:传令官用什么格式,在哪等命令。——这就是MCP(模型上下文协议)。
但你发现,军师虽然会调兵,但不知道什么时候该调、调多少、和谁配合。于是你给军师配了一本《用兵手册》,里面写着:遇到敌军攻城,先调兵,再调粮草,最后调民夫。——这就是Skills(技能)。
最后,这个军师既能思考(模型),又有记忆(Memory),还能查资料(RAG),还能动手做事(MCP),还能按流程办事(Skills)。他就是一个完整的Agent(智能体)。
而OpenClaw,就是一个把所有这些能力打包、开源、能跑在你电脑上的“皇帝身边的传令中枢”——你只需要在微信上给它发句话,它就能调兵遣将、管理文件、操作电脑。
02 概念全景图:一张图看懂所有关系
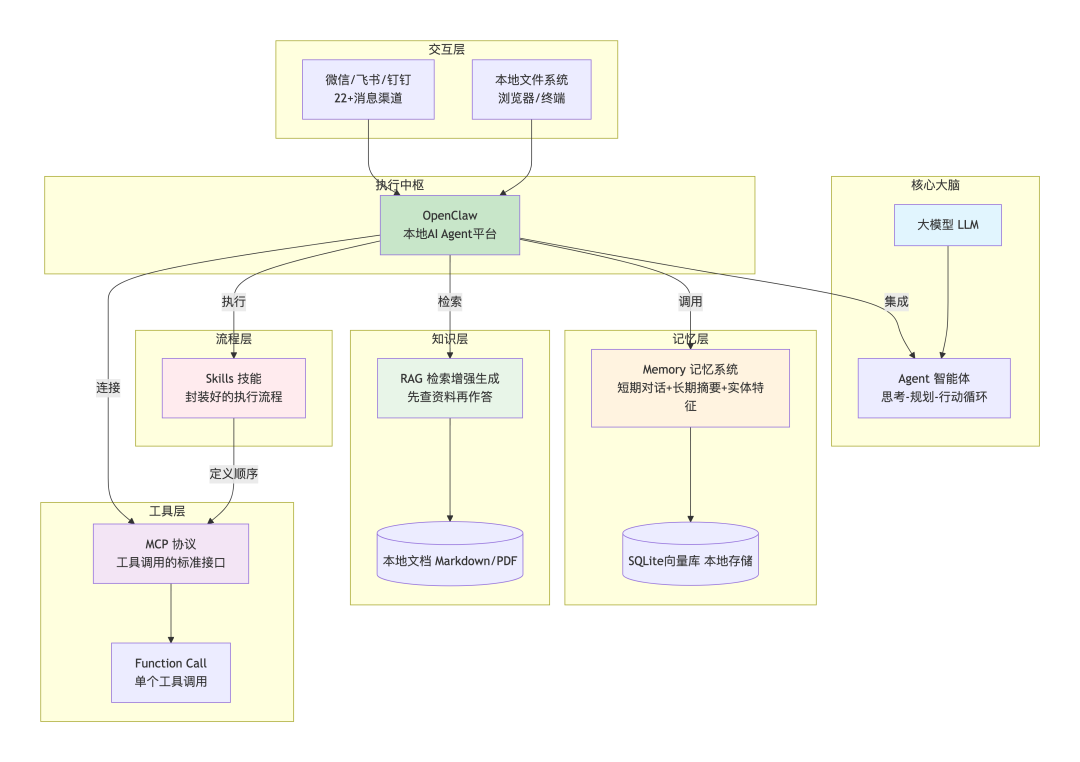
这张图清晰地展示了各层之间的关系。
下面我们一层一层拆解。
03 第一层:核心大脑——Agent
Agent(智能体) 是一个能够感知环境、做出决策并执行动作的自主系统。
OpenClaw的核心架构中,Agent采用经典的“观察-计划-行动”(Observe-Plan-Act)循环范式。当用户发来消息:
-
观察:理解用户意图,查看当前状态
-
计划:拆解任务,决定需要调用哪些工具
-
行动:执行具体操作,获取结果
-
循环:直到任务完成
在OpenClaw中,每个Agent都有自己的工作区(workspace),包含一系列配置文件:
AGENTS.md # Agent职责声明,决定工具权限
SOUL.md # 个性化提示词,注入system prompt
TOOLS.md # 工具白名单/黑名单,安全边界
IDENTITY.md # 身份标识,用于不同聊天渠道展示
USER.md # 用户偏好,上下文先验
MEMORY.md # 用户记忆文档(RAG源)
这种设计让Agent不再是黑盒,而是完全可配置、可审计的。
04 第二层:记忆层——Memory系统
Memory(记忆) 是让AI具备持久化记忆能力的机制。
大模型的推理服务本身是无状态的HTTP服务,每次请求处理完成后不会保留任何数据。OpenClaw通过分层记忆机制解决这个问题:
-
短期记忆:原封不动地保留最近几轮的对话原文
-
长期记忆:后台触发小模型压缩历史对话成摘要,提取“实体特征”(如“用户是上海的程序员”)存入数据库
OpenClaw的记忆系统非常独特——它完全基于SQLite构建。源码分析显示,它采用“向量+关键词”混合检索策略:
// OpenClaw记忆检索的核心逻辑(伪代码)
asyncfunctionsearchMemory(queryVector, limit = 5) {
try {
// 1. 快速路径:使用sqlite-vec扩展进行原生向量检索
returnawait db.all(`
SELECT c.text, vec_distance_cosine(v.embedding, ?) AS dist
FROM chunks_vec v
JOIN chunks c ON c.id = v.id
ORDER BY dist ASC LIMIT ?
`, [queryVector, limit]);
} catch (err) {
// 2. 安全路径:扩展不可用,退回到JS计算
const allChunks = await db.all("SELECT text, embedding FROM chunks");
return allChunks
.map(chunk => ({
...chunk,
dist: cosineSimilarity(queryVector, JSON.parse(chunk.embedding))
}))
.sort((a, b) => a.dist - b.dist)
.slice(0, limit);
}
}
这种设计的精妙之处在于:优先使用原生扩展追求性能,扩展不可用时优雅降级,保证功能始终可用。
05 第三层:知识层——RAG是什么?
RAG(检索增强生成) 解决的是大模型知识“冻结”的问题——模型训练完成后就无法更新,不知道实时新闻和企业内部文档。
RAG的核心流程是“先查资料,再作答”:
-
用户提问
-
系统在知识库中检索相关内容
-
将检索结果和原始问题一起发给模型
-
模型基于这些资料生成答案
在OpenClaw中,RAG的实现同样基于SQLite。它可以将你的本地Markdown文件、文档库向量化后存入本地向量库,每次提问时先检索相关片段,再让模型回答。
06 第四层:工具层——Function Call和MCP
Function Call:让AI能“动手”
Function Call(函数调用) 是大模型的一项核心能力。开发者告诉模型“你有这些工具可以用”,模型在需要时输出结构化的调用请求,由开发者执行真实的函数。
// Function Call的典型流程
// 用户问:“北京天气怎么样?”
// 模型输出:
{
"function": "get_weather",
"parameters": {"city": "北京"}
}
// 开发者调用真实API,获取天气数据
// 模型基于数据生成最终回答:“北京当前25℃,晴”
MCP:标准化的工具调用协议
MCP(Model Context Protocol) 是Anthropic提出的标准化协议,统一了工具调用的接口规范。它让开发者按照统一标准写工具,让模型按照统一格式调用,实现工具复用。
但OpenClaw有个有趣的设计选择:它故意不支持MCP。为什么?
根据官方解释,主要原因有三:
-
安全与隐私:MCP涉及多模型协作,数据共享可能带来泄露风险
-
技术灵活性:不想被固定协议束缚,保持快速迭代能力
-
资源优化:减少依赖,降低系统复杂度,提供更快的响应时间
OpenClaw采用更轻量的Skills机制替代MCP,后面会详细讲。
07 第五层:流程层——Skills是什么?
Skills(技能) 是OpenClaw最核心的创新。如果说MCP是“单个工具”,Skills就是“封装好的完整流程”。
Skills要解决的是这个问题:有了工具,模型不知道“何时用、按什么顺序用、如何组合工具”。就像一个人有了锤子、锯子、钉子,但不知道怎么做一把椅子——他需要的是《木工手册》。
在OpenClaw中,Skills就是这套“操作手册”:
-
memory:记忆能力,保存用户偏好和历史信息
-
web_search:互联网搜索,获取实时信息
-
browser:网页浏览,打开网页提取内容
-
file:文件操作,创建、读取、修改文件
安装Skills非常简单:
clawhub install memory # 安装记忆技能
clawhub install browser # 安装浏览器控制技能
OpenClaw官方ClawHub技能注册中心拥有超千款技能插件,覆盖办公自动化、代码管理、数据处理等多个领域。
08 OpenClaw:集大成者的智能体平台
现在,我们把所有概念串起来,看看OpenClaw到底是怎么运作的。
OpenClaw是什么?
OpenClaw(原名Clawdbot/Moltbot)是由奥地利开发者Peter Steinberger(PSPDFKit创始人)于2025年11月发布的开源AI Agent框架,2026年初完成更名,采用MIT开源协议。目前GitHub星标已超29万,社区贡献者超过1000人。
一句话概括:一个坐在你消息应用和工具链之间的Agent运行时+网关,24/7永远在线。
OpenClaw的四层架构:
|
层级 |
组件 |
作用 |
|---|---|---|
|
控制网关层 |
Gateway |
管理所有入站出站通讯,统一处理Telegram、飞书、钉钉等22+平台消息 |
|
推理与认知层 |
Reasoning Layer |
接入大模型,执行“观察-计划-行动”循环 |
|
记忆与状态层 |
Memory System |
SQLite存储的持久化记忆系统 |
|
技能与执行层 |
Skills & Execution |
调用Skills执行具体操作 |
一个完整的执行流程:
-
用户在微信发消息:“帮我整理桌面文件”
-
网关层收到消息,转给Agent
-
Agent分析任务,调用
file技能 -
技能执行文件操作,返回结果
-
记忆层记录这次操作,供后续参考
-
Agent生成回复:“已整理,将图片移至Pictures文件夹”
09 选择OpenClaw,还是Dify?
理解了这些概念后,最后一个问题:企业在什么场景下选择OpenClaw?
根据行业实践,核心区别在于:
|
维度 |
OpenClaw |
Dify/Workflow |
|---|---|---|
| 设计理念 |
Agent分支:相信LLM能自主编排 |
ChatBot分支:严格控制上下文 |
| 流程控制 |
自主规划,动态决策 |
固定画布,静态编排 |
| 适用场景 |
高自由度、无法预定义流程的任务 |
标准流程、需要严格审阅的任务 |
| 典型应用 |
系统运维、文件管理、浏览器自动化 |
客服流程、审批流程、合规要求 |
简单说:需要AI自己想办法的,用OpenClaw;需要AI按标准流程走的,用Dify。
两者也可结合:把编排好的Workflow封装成Skills,让OpenClaw按编排好的流程作业。
10 安全提醒:别让你的龙虾失控
最后,一个重要的提醒。
OpenClaw拥有执行shell命令、操作文件系统的能力,这意味着它拥有和你一样的电脑权限。
几个必须遵守的安全准则:
-
不要在主用电脑上“裸奔”运行:建议用旧电脑、虚拟机或新建系统账号测试
-
API Key不要泄露:不要提交到git,不要截图
-
长期运行建议用Docker/VPS:实现权限隔离
-
永远不要把它当“文件传输助手”:时刻假设数据可能泄露
总结
回到最初的问题:OpenClaw跟Skills、MCP、RAG和Agent有什么关系?
-
Agent是整体概念,OpenClaw是Agent的具体实现
-
RAG是给Agent提供外部知识的方法
-
Memory是让Agent记住历史的方法
-
MCP是标准化工具调用的协议(OpenClaw选择不用)
-
Skills是OpenClaw独创的、封装了执行流程的能力模块
-
OpenClaw是一个把以上所有能力整合在一起、开源免费、能跑在你电脑上的智能体平台
有些小伙伴可能会问:“我该从哪开始学?”我的建议是:先理解Agent是什么,然后动手部署一次OpenClaw。跟着阿里云的教程,15分钟就能跑起来。
开源地址:
-
OpenClaw:https://github.com/openclaw(原名clawdbot/moltbot)
-
阿里云一键部署专题:https://www.aliyun.com/activity/ecs/clawdbot

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)