训练数据选择又有新方法了?——两篇文章的阅读笔记 Less is Enough和 OPUS
本文是对近期两篇大模型 训练数据选择 方向论文的阅读笔记,第一篇文章是 Less is Enough: SynthesizingDiverse Data in Feature Space of LLMs 第二篇是 OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in
Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs
一句话总结
作者介绍了一种在 Post-training 阶段,利用 SAE 对训练集进行“查漏补缺”的数据合成方案,旨在通过增加少量合成样本,达到更好的任务效果。
要实现“查漏补缺”,至少要满足两点:
第一、 我们要有一个“潜在的全集”
第二、我们要能把全集“拆解并分类”:这样才知道什么东西少了。
针对“潜在的全集”,作者使用了一个【与任务相关+没有标签的数据集】作为全集的化身;
为了“拆解并分类”,作者利用 SAE 对全集进行分解,但这其中,我们真正要利用的是【与任务相关】的特征。
而要确定【任务相关】,就需要人先构造一个“任务描述”——这样 LLM 才能基于特征的激活样本,自动化地筛选出目标特征。
综合下来,作者的实际操作步骤如下:
具体步骤
如果给定:
※ 任务相关语料集 A:就是语料,无标注
※ 任务的详细描述 B(比如训练模型识别【不良价值】的回复)
※ 现有训练样本集 C:针对当前任务标注过,可以是 任务相关语料集 A的一部分,也可以完全没关系。
我们可以:
※ Step1:用语料A训练一个 SAE;
※ Step2:基于描述B,让LLM 在SAE中筛选出相关特征。
※ Step3:找到那些“在语料A中激活,但在样本集C中未激活”的相关特征。
※ Step4:利用这些特征,让LLM生成 C 中缺失的样本,作为符合描述B的正样本。
※ Step5:用这样生成的少量合成样本 + 原训练集训练。
关键细节
一,怎么具体的筛选特征(我会增加这样做的隐患) 其二、怎么生成缺失的样本,这里主要是对比样本的部分很重要(把相关实验结果也放进来;其三、效果,这里要讲的是跟实际应用的效果相关的(作者自己突出的很多样本对很少样本的东西倒是不重要),比如我们谈到的覆盖多少遗漏特征的。你再想想还有什么应该要谈的。你不用写细节出来,我在捋后面的大纲
怎么从SAE特征池中筛选出相关特征?合成什么样的数据?
首先,作者基于日常对话训练了一个SAE,这个SAE有6.5万个特征。
然后,作者针对每个特征挑选了【使该特征激活值最大】的Top-10个文本(见下图),然后让LLM定义这个特征是干什么的(下图Summary of text Spans)。
接着,(针对)作者拿着下面这个特征的定义,让LLM生成下图中Synthesized的这样的例句,然后,观察对应的SAE特征是否被激活,如果生成了能激活对应的样本,就算成功。
效果怎么样
作者测试了若干场景,Instruction Following,[不良价值回复]检测,控制模型[谄媚],建立奖励模型。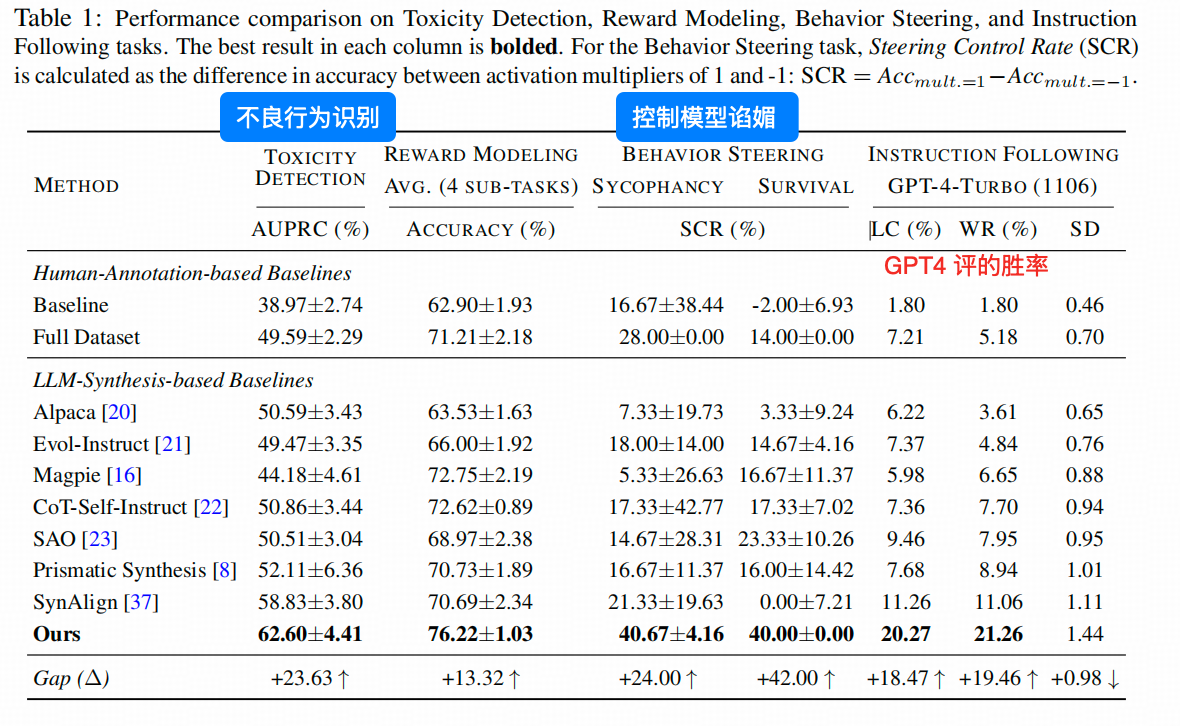
为了比较方法的效果,作者从任务的开源数据集中,抠出了一小部分,作为 训练样本集 C ,这样就可以比较,仅使用这个可能有偏,可能数据量小的数据集(上图的Baseline)带来的效果,和 开源数据集这个数据量较大,一般认为对任务空间cover较好的样本(上图的Full Dataset),以及作者构建的:能覆盖SAE特征的样本。这之间的效果差异。
但从几个任务的角度而言,作者的方法无疑是很有竞争力的。
重点看表上,Full Dataset组的实验结果,也没有作者的Ours这一行的水平,这确实能说明,通过特征方向补充数据存在优势,上表左右侧的Instruction Following任务上,作者方法的Win Rate显著的超过了几个市面上常用的IF 数据集,也能够说明问题。
这个效果是【定向补充样本】带来的,还是【生成的样本质量更好】带来的?
当然是【定向补充样本】带来的😁,关键看作者是怎么证明这点的。
一个非常 Naive 的问题是:如果在【查漏补缺】的过程中,故意漏掉一部分特征不补,效果会变差吗?
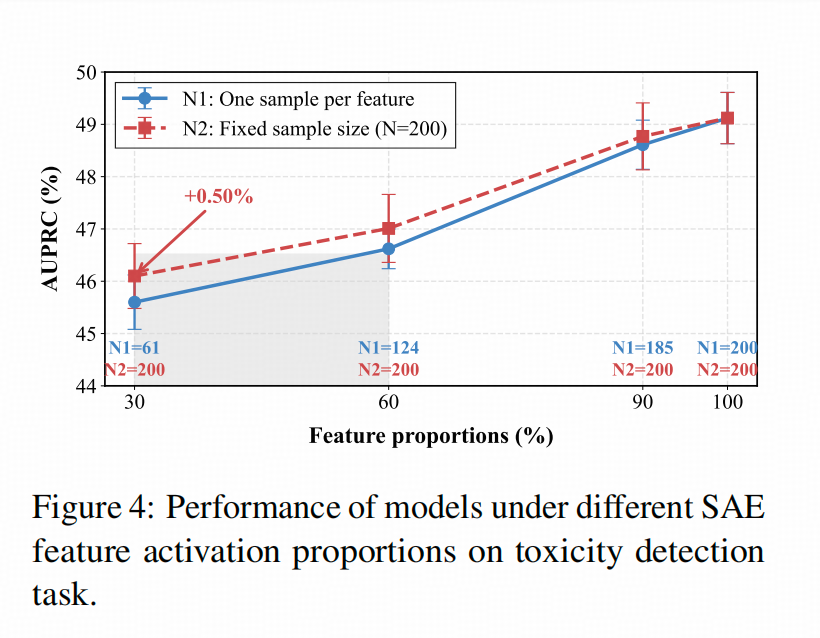
当然,为了验证这一点,得排除“样本总量变少”带来的干扰。
所以,在总补充样本量固定为 200 的情况下(下图红线),如果只覆盖 SAE 提示的【未覆盖特征】的 30%(下图最左两个点),相比于全覆盖(下图最右侧点),识别 AUC 降了 4 个点。
A模型训的SAE,能给B模型用吗?
答案是【可以】。
作者测试了三种实验变量:
※ 用哪个模型来 训练嫁接的SAE
※ 用哪个模型来 生成补充样本
※ 用哪个模型来做【被训练】的任务模型。
首先,在作者测试的三个模型当中,作为【被训练】的任务模型里,最强的仍然是Qwen。
剩下两个变量怎么选?看下图:
蓝柱 / 红柱:分别代表用 Qwen / LLama 训 SAE。
横轴:代表用谁(Qwen / Mistral / LLama)来生成样本。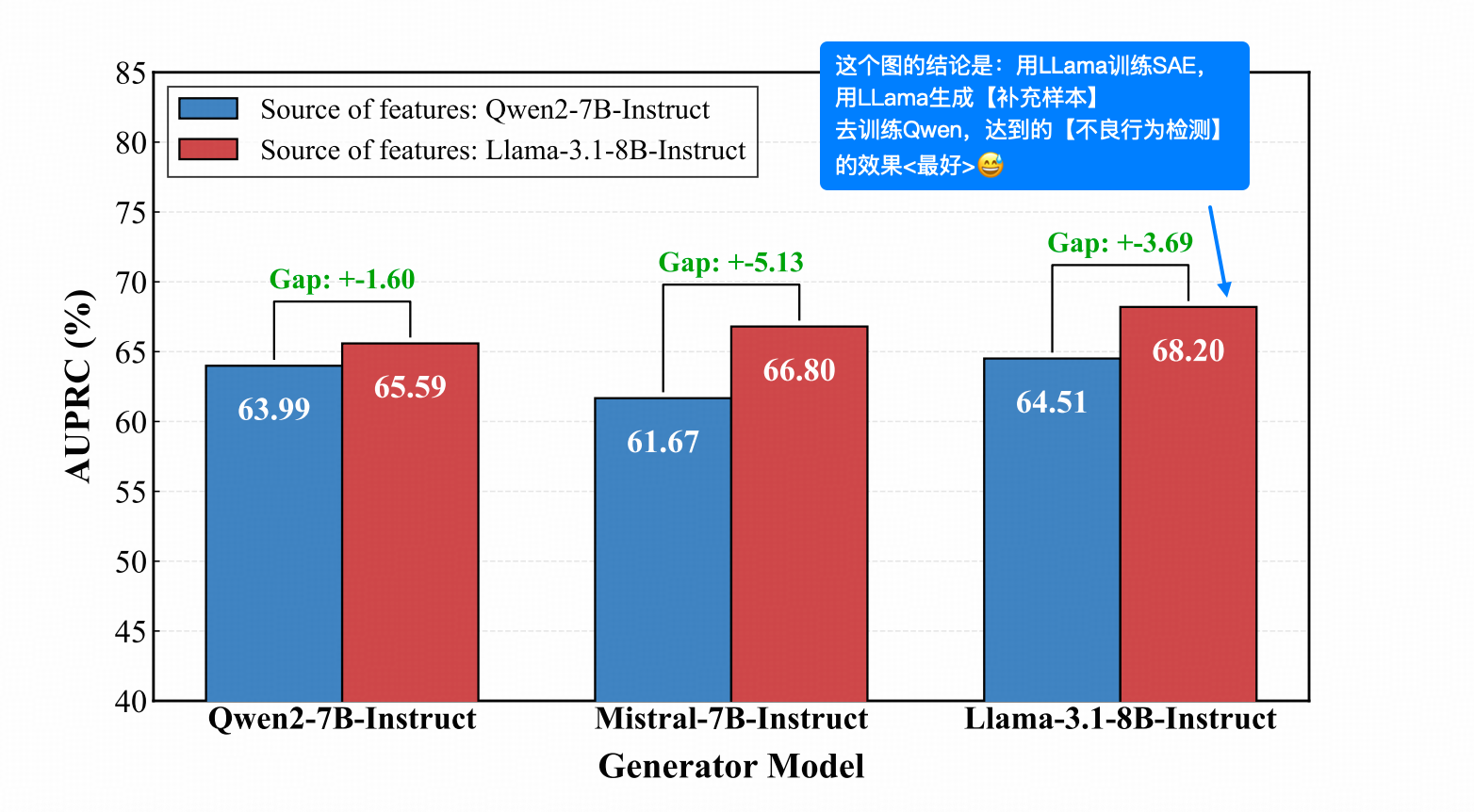
上图结论是:LLama 同时作为【SAE嫁接模型】和【样本生成模型】时,效果最好。
老实说,能有3个点的优势,我是非常惊讶的。这说明【样本生成模型】产出的数据,即便过了SAE特征激活的过滤,也仍然存在质量差异。如果能找到影响这种差异的因子,就能进一步提升数据质量。
但比较可惜的是,作者没有对此做更深入的针对性分析,也没有给出对应的样本比较。
OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
一句话总结
这篇文章中,作者用一个数据集当【导游】,来引导每个Step采样训练样本的方向:训练样本跟【导游】的梯度越接近,就越容易被抽中参与训练。作者认为,这样训练出的模型,在【导游】数据对应的任务上表现更好。
用“梯度对齐”做数据筛选不稀奇,但要用在预训练上(虽然我认为这个方法更适合mid-training),就要处理算【导游】梯度的超高开销。
但是呢,作者实际实验中,导游“数据集”是随机抽的8个样本,而不是我想象的几百个(我天真了),训练样本筛选是一个32选16的半淘汰制。(其实都合理,主要是我预期管理失败了😂)。
但这篇文章还是有一些看点:
- 用了常规的以观察数据集(导游)锚定训练方向的方案,但针对AdamW和MUON这两个流行的optimizer做了适配。
- 把梯度内积转化成向量外积来降低存储压力;
- 用CountSketch这个类似随机初始稀疏MLP的方法,来近似内积预算。
关键细节
1. 怎么找和【导游】数据集方向一致的样本?
这里就要请出【数据影响力】方向中的一段常见推导↓:
为了衡量模型训练一个 step 带来的影响,通常需要引入一个“观测数据集”作为参照。(在同类工作中,这通常是测试集,用来评估训练一步对准确率的提升;而在本文中,它就是用来引导采样的【导游】数据集)。
通过泰勒展开,我们可以把模型训练前后 f(θt)f(\theta_t)f(θt)和f(θt+1)f(\theta_{t+1})f(θt+1)在观测集上的表现变化,近似转化为两个梯度的内积:即“观测集梯度”与“训练数据梯度”的内积。内积越大(即角度越一致),代表当前步的训练数据对观测集的增益越明显。
即:
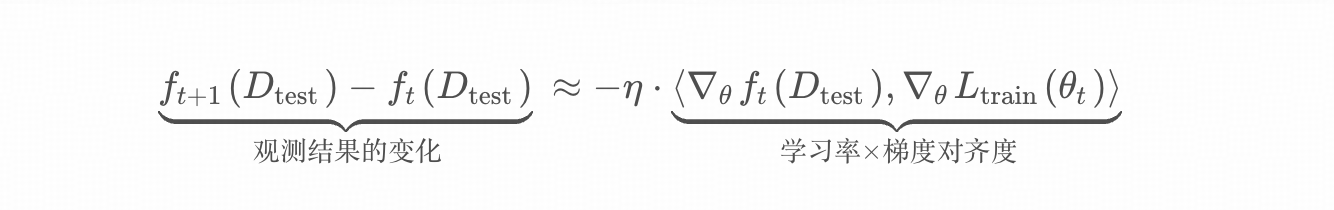
这就引入另一个常用变换 Ghost
上面这个内积需要对整个参数向量 θ∈Rd\theta \in \mathbb{R}^dθ∈Rd 求和,ddd 是模型总参数量。直接计算需要显式获得两个ddd 维梯度向量,存储和计算开销都不可接受。
以 Transformer 中的任意一个线性层为例,设其权重为 W∈Rdin×doutW \in \mathbb{R}^{d_{\text{in}} \times d_{\text{out}}}W∈Rdin×dout。对于这一层,训练样本的梯度可以写成外积形式:
∇WLtrain=xtrain⊗δtrain \nabla_W L_{\text{train}} = \mathbf{x}_{\text{train}} \otimes \boldsymbol{\delta}_{\text{train}} ∇WLtrain=xtrain⊗δtrain
其中 xtrain∈Rdin\mathbf{x}_{\text{train}} \in \mathbb{R}^{d_{\text{in}}}xtrain∈Rdin 是该层的前向输入向量,δtrain∈Rdout\boldsymbol{\delta}_{\text{train}} \in \mathbb{R}^{d_{\text{out}}}δtrain∈Rdout 是反向传播来的误差信号。
同样,观测集对该层权重的梯度也满足:
∇Wft(Dtest)=xtest⊗δtest \nabla_W f_t(D_{\text{test}}) = \mathbf{x}_{\text{test}} \otimes \boldsymbol{\delta}_{\text{test}} ∇Wft(Dtest)=xtest⊗δtest
现在来看这一层对内积的贡献 ⟨∇Wf,∇WL⟩F\langle \nabla_W f, \nabla_W L \rangle_F⟨∇Wf,∇WL⟩F,展开:
⟨∇Wf,∇WL⟩F=∑i=1din∑j=1dout(∇Wf)ij(∇WL)ij \langle \nabla_W f, \nabla_W L \rangle_F = \sum_{i=1}^{d_{\text{in}}} \sum_{j=1}^{d_{\text{out}}} (\nabla_W f)_{ij} (\nabla_W L)_{ij} ⟨∇Wf,∇WL⟩F=i=1∑dinj=1∑dout(∇Wf)ij(∇WL)ij
代入外积表达式 (∇Wf)ij=(xtest)i(δtest)j(\nabla_W f)_{ij} = (\mathbf{x}_{\text{test}})_i (\boldsymbol{\delta}_{\text{test}})_j(∇Wf)ij=(xtest)i(δtest)j,(∇WL)ij=(xtrain)i(δtrain)j(\nabla_W L)_{ij} = (\mathbf{x}_{\text{train}})_i (\boldsymbol{\delta}_{\text{train}})_j(∇WL)ij=(xtrain)i(δtrain)j:
=∑i=1din∑j=1dout[(xtest)i(δtest)j]⋅[(xtrain)i(δtrain)j] = \sum_{i=1}^{d_{\text{in}}} \sum_{j=1}^{d_{\text{out}}} \left[ (\mathbf{x}_{\text{test}})_i (\boldsymbol{\delta}_{\text{test}})_j \right] \cdot \left[ (\mathbf{x}_{\text{train}})_i (\boldsymbol{\delta}_{\text{train}})_j \right] =i=1∑dinj=1∑dout[(xtest)i(δtest)j]⋅[(xtrain)i(δtrain)j]
因为所有因子都是标量,可以重新排列:
=∑i=1din∑j=1dout(xtest)i(xtrain)i⋅(δtest)j(δtrain)j = \sum_{i=1}^{d_{\text{in}}} \sum_{j=1}^{d_{\text{out}}} (\mathbf{x}_{\text{test}})_i (\mathbf{x}_{\text{train}})_i \cdot (\boldsymbol{\delta}_{\text{test}})_j (\boldsymbol{\delta}_{\text{train}})_j =i=1∑dinj=1∑dout(xtest)i(xtrain)i⋅(δtest)j(δtrain)j
注意到 (xtest)i(xtrain)i(\mathbf{x}_{\text{test}})_i (\mathbf{x}_{\text{train}})_i(xtest)i(xtrain)i 只依赖于 iii,(δtest)j(δtrain)j(\boldsymbol{\delta}_{\text{test}})_j (\boldsymbol{\delta}_{\text{train}})_j(δtest)j(δtrain)j 只依 赖于 jjj,因此双重求和可以分解为两个独立求和之积:
=(∑i=1din(xtest)i(xtrain)i)⋅(∑j=1dout(δtest)j(δtrain)j) = \left( \sum_{i=1}^{d_{\text{in}}} (\mathbf{x}_{\text{test}})_i (\mathbf{x}_{\text{train}})_i \right) \cdot \left( \sum_{j=1}^{d_{\text{out}}} (\boldsymbol{\delta}_{\text{test}})_j (\boldsymbol{\delta}_{\text{train}})_j \right) =(i=1∑din(xtest)i(xtrain)i)⋅(j=1∑dout(δtest)j(δtrain)j)
这正是两个向量内积的乘积:
=(xtest⊤xtrain) (δtest⊤δtrain) = (\mathbf{x}_{\text{test}}^\top \mathbf{x}_{\text{train}}) \; (\boldsymbol{\delta}_{\text{test}}^\top \boldsymbol{\delta}_{\text{train}}) =(xtest⊤xtrain)(δtest⊤δtrain)
至此,原本需要 O(dindout)O(d_{\text{in}} d_{\text{out}})O(dindout) 次乘加的大矩阵内积,被简化为两个小向量的内积(各需 O(din)O(d_{\text{in}})O(din) 和 O(dout)O(d_{\text{out}})O(dout) 次乘加),计算量大幅降低。
同时,存储梯度时只需保存输入向量 x\mathbf{x}x 和误差向量 δ\boldsymbol{\delta}δ,内存占用也从矩阵规模降为向量规模。
这样每一步迭代的运算量也仍然很大,这里作者用了另外一个技巧↓
CountSketch
作者的目的是利用一个快速的维度压缩,将d×dd \times dd×d的运算,映射成 m×mm\times mm×m的运算,当然 m≪dm\ll dm≪d
CountSketch 从形式上,比较像一个随机初始的稀疏线性映射。即,初始化一个 d×md \times md×m 的稀疏矩阵,保证这个矩阵的每一行都只有一个位置有值,且这个值只可能是 +1 或 -1。这样就可以变成一个哈希运算。映射后的 m×mm \times mm×m 内积,在理论上保障,与 d×dd \times dd×d 的相对距离保持一致。
效果怎么样
我先绕开作者的主实验(我认为作者的主实验反而有点说不清楚),看看这个方法在Continue Pretrain的效果。这个实验的Setup是这样的。
被训练模型:Qwen3-8B-Base(已预训练的通用模型)
训练语料:SciencePedia(科学领域数据集,共3B token)
测试数据集:OlympicArena(多学科科学推理)和SciAssess(科学文献分析),各含多个子领域(如物理、化学、生物、材料、医学等)。
导游数据集:从SciencePedia中检索出的与下游科学任务(OlympicArena和SciAssess验证集)语义相似的文档构成代理池,约30M token,但还是每个step随机从中抽8个当【导游】。导游数据集与测试集任务领域一致,但与测试集无重叠。
下面这个图,比较了模型在测试集上的表现↓: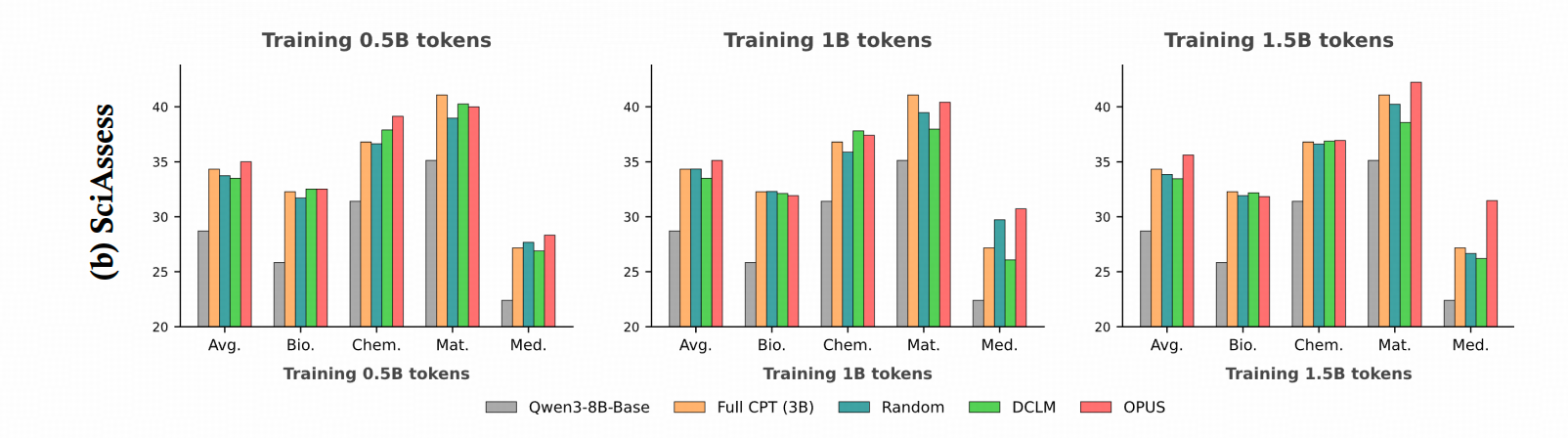
上图将作者的OPUS方法与其他几种设置进行了对比:
没有训练的基座 - 灰色
用了所有语料SciencePedia训练 - 橙色
用随机挑选的样本训练,比例为32选16 - 蓝色
用模型筛选高质量样本训练,仅区分质量而不分方向 - 绿色
作者的方法,同样是32选16 - 红色
上图展示的现象是:
第一,在生物、化学、数学、医疗这几个测试领域中,当训练数据量达到1.5B,也就是可用训练集的一半时,作者的方案在数学和医疗上展现出了显著优势。
第二,整体来看,并不能说作者的方法全面领先。实际上,作者的主实验也存在这个问题,带来的Margin提升确实比较有限。
在原文的Table7 ,Table8 中,作者还展示了:
Table7 :如果将【用导游数据指导采样】变成【直接选跟导游数据集夹角最小的Top-K个样本】
Table 8: 扩大采样候选集或调整采样概率
这些情况下,OPUS相较于Random的优势,但结果都是Margin并不大.
效果😓,但是效率应该还不错吧?
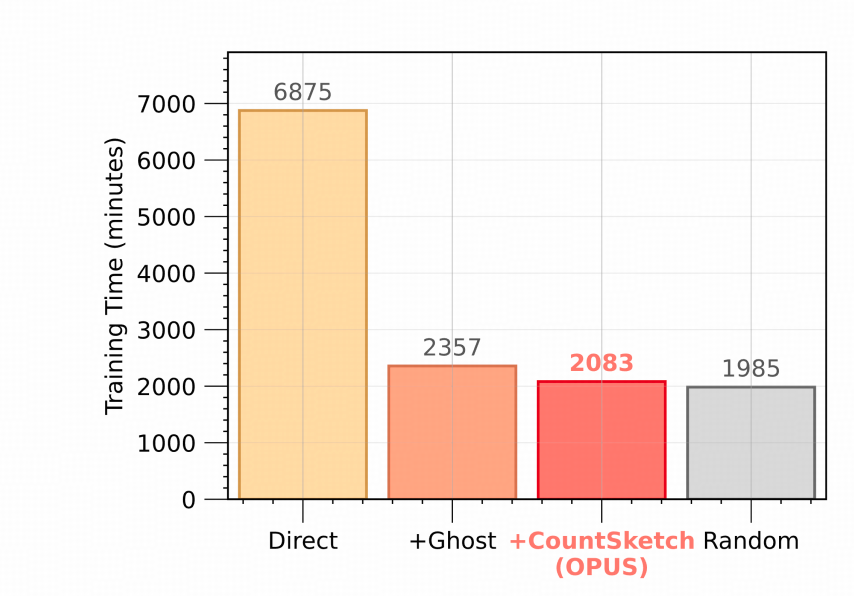
是的,作者在Figure7展示了,Ghost+CountSketch带来的训练时间优化效果。
上图中展示了不同设置下的训练时间对比:
黄色 - 直接使用泰勒展开式进行内积运算的训练时间;
橙色 - 把内积形式转化成外积形式,即Ghost方法对应的训练时间;
红色 - 在此基础上,再加上CountSketch的对应训练时间。
对比灰色的“随机选择样本”训练时间来看,这套方法的效率确实不错。
不过,这部分本来可以多深入分析一下。比如Ghost方法带来的时间优化,到底是不是因为显存管理开销减少才实现的?作者没有展开,只是汇报了结果。我能理解作者是希望把核心优势押在“模型效果好”这一点上,但是吧,这效果其实…… ̄□ ̄|| 仔细想想也是,在模型效果没有给人留下明确的深刻印象时,单去强调只增加了多少训练成本,其实有点无力。
评价
-
相比于梯度内积这个常规尺度,SAE激活是个比较新的思路。当然,这里面也埋着💣:
Less is Enough 的作者展示这样一件事:用A模型训练的SAE也能指导B模型生成样本和训练,这样,拿一个训练好的SAE直接用也可以,这就简化了操作。
但SAE的训练并不能保证特征维度能cover某个业务方向的全部或者大部分特征,这个点要怎么保证? -
OPUS虽然没有展示比较高的Margin,主实验设计好像也展现不出来自己方法的优势(主实验中,导游数据集还是MMLU抽的,这你说……我确实期待更极端的实验),但是把几套常规打法揉完了之后,还做了对应优化器上的理论转换与处理,这也是值得一读的(作者在AdamW和Muon上的变化我没写,写不动了……)
-
OPUS在附录里展示了用几种不同筛选方法给样本打分的结果,及其对应的样本原文,有兴趣的朋友可以自己翻一下。我其实非常希望这类研究数据筛选的工作,在实验后,能展示并分析一部分构造或筛选的数据,或进行对比。纵然很多分析难以一锤定音的指出有效的,好的数据,到底应该符合一个什么样的描述,但也有可能得到一个有启发性的观点。
-
数据选择这个方向,在前年算是比较火热,也涌现了很多方法,到现在的话,确实也不是第一梯度的热点方向了。而且,现在还scaling得动吗?轮子该往哪儿滚呢?——其实,能指导工业生产的方法还是可以再多的。如果能在降低知识冲突带来的训练问题上,有更优效率的数据合成或筛选方法,那就更好了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)