OpenClaw:如何成为你的【贾维斯】
如果说普通人折腾 OpenClaw 有点像是在“拿着锤子(解决方案)找钉子(需求)”,每天消耗大量 Token 去整理一些可能永远不会再看的信息,那么问题就变得很现实:这项技术真正的归宿在哪里?如果抛开营销和神话,从技术视角拆解它的架构就会发现:OpenClaw 本身的技术壁垒其实并没有想象中那么高。它真正有价值的地方,不在某个复杂算法,而在于它展示了一种新的软件形态——由自然语言驱动的智能体界面
OpenClaw 2026.3.8
OpenClaw 是什么
OpenClaw(曾用名 ClawBot / Moltbot)是 2026 年最受关注的开源 AI Agent 项目之一,在 GitHub 上已获得超过 242,000 ⭐。
OpenClaw 并不是一个普通的聊天机器人,它更像是一个 AI 智能体平台(Agent Platform)。与传统 AI 不同,智能体本身并不会因为使用时间变长而变得更聪明。真正持续积累价值的,是围绕它产生的一系列上下文资产,例如本地文件、任务记录、操作历史以及外部工具连接。这些不断沉淀的上下文,使系统越来越贴合个人需求,也逐渐形成属于用户自己的“智能护城河”。
你可以在自己的电脑上运行一个 AI 助手,并将它接入到日常使用的工具中,例如飞书、Discord 等平台,让 AI 能够直接参与真实的工作流程。
OpenClaw 的核心能力主要体现在两个方面:
1)主机级权限(Host-level Access)
智能体可以直接访问本地环境,例如读取本地文件、操作工作目录、调用系统工具,甚至与通讯软件进行交互。
2)自主运行机制(Autonomous Loop)
通过 AI 的自问自答机制结合定时心跳唤醒,智能体能够持续运行,而不是只在聊天时被动响应。
这种设计打破了传统 AI “只存在于聊天窗口”的短生命周期模式。
AI 不再是一个简单的对话工具,而是升级为一个 常驻本地、能够持续执行任务的 24 小时智能助手。
OpenClaw 核心架构解析
OpenClaw 的整体架构如下图所示。
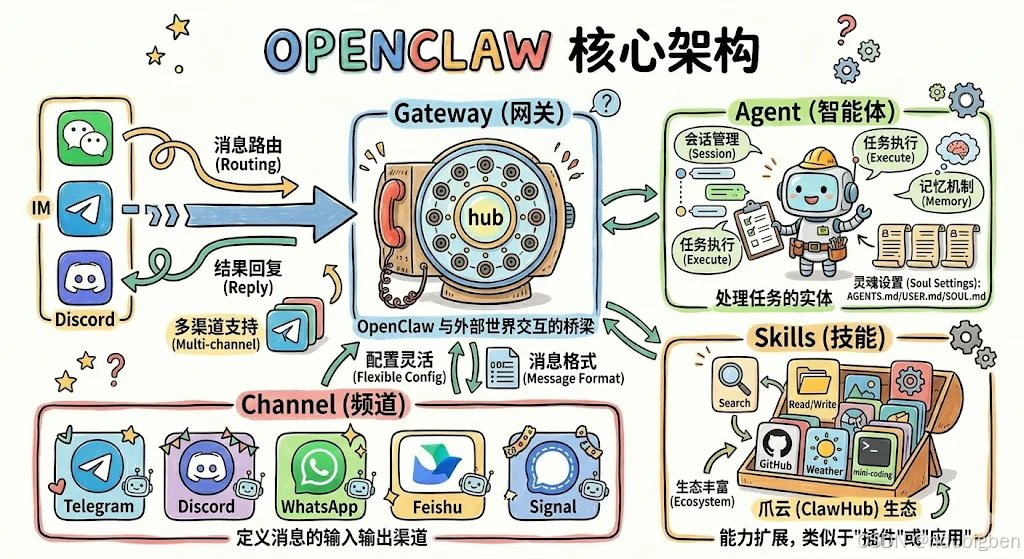
OpenClaw 的整体架构可以理解为一个 由消息入口、任务调度、智能体决策以及能力扩展组成的 AI Agent 系统。它的设计目标不是简单地提供一个聊天机器人,而是构建一个可以 长期运行、持续执行任务并与本地环境深度结合的智能体平台。
从整体结构来看,OpenClaw 主要由四个核心部分组成:Channel(消息入口)、Gateway(任务网关)、Agent(智能体核心)以及 Skills(能力模块)。
首先是 Channel(消息入口)。
Channel 代表用户与 AI 交互的入口渠道,例如 Telegram、Discord、WhatsApp、飞书等通讯平台。用户可以直接在这些平台中向 AI 发送指令,而无需打开专门的 AI 界面。所有来自不同平台的消息,都会统一进入系统进行处理。
在 Channel 之上,是 Gateway(网关层)。
Gateway 的主要职责是接收来自不同渠道的消息,并进行统一的格式化和路由分发。它相当于整个系统的“调度中心”,负责把用户请求分配给对应的 Agent,同时管理任务的流转与执行状态。
真正的核心逻辑发生在 Agent(智能体层)。
Agent 可以理解为系统的大脑,它负责对用户请求进行理解、任务拆解和执行规划。例如,当用户提出一个复杂任务时,Agent 会将其拆解为多个步骤,并根据任务需要调用不同的工具或能力模块。Agent 同时还会维护任务状态和上下文信息,使系统能够持续执行复杂任务。
为了让 Agent 具备实际操作能力,OpenClaw 提供了 Skills(技能模块)。
Skills 可以理解为 AI 的工具或插件,例如文件操作、网络请求、数据处理、API 调用等能力。Agent 在完成任务时,可以根据需要调用不同的 Skills,从而实现真正的自动化执行。
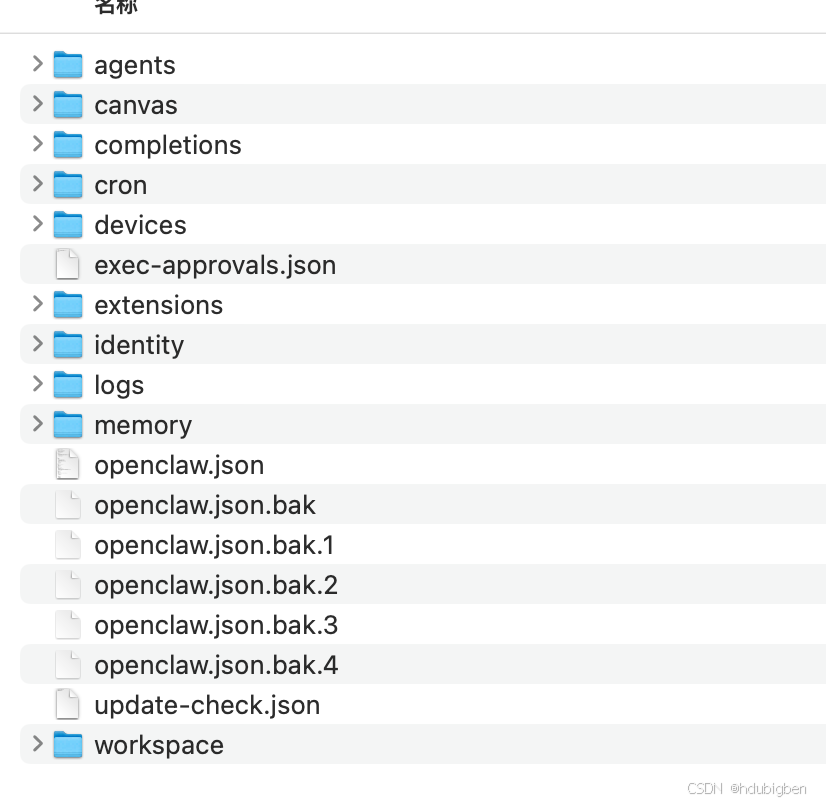
OpenClaw 本地运行目录结构
除了核心架构之外,OpenClaw 在本地运行时还会生成一系列关键目录,用于管理系统状态和数据。其中最重要的几个目录包括:
|
运行核心
|
通过这样的架构设计,OpenClaw 将传统 AI “只存在于聊天窗口”的交互模式,升级为一个 能够长期运行、持续执行任务并不断积累上下文信息的智能体系统。
从本质上来说,OpenClaw 并不仅仅是一个 AI 工具,而更像是一个 本地运行的 AI 操作系统。它让 AI 不再只是回答问题,而是能够参与到真实的工作流程中,成为一个可以长期协作的智能助手。
让 OpenClaw 成为“你的智能体”
在 OpenClaw 的本地目录结构中,workspace 是最核心的目录之一。
如果说 agents、logs、extensions 这些目录更多承担的是 系统运行与能力扩展的职责,那么 workspace 更像是 智能体真正工作的空间。Agent 在执行任务时读取的文件、生成的内容以及长期积累的上下文信息,大多都会存放在这里。
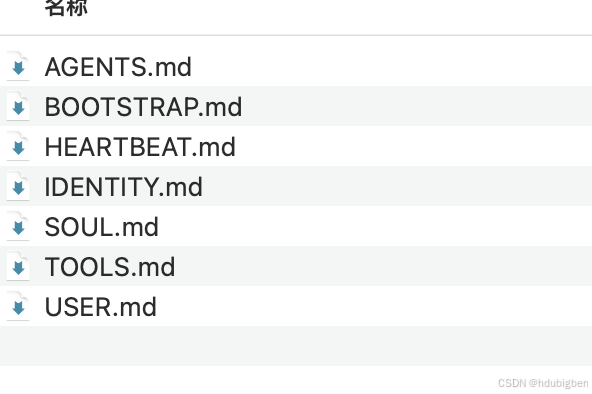
更重要的是,workspace 目录中通常包含一组关键的配置文件,如下图所示。这些文件共同定义了智能体的 身份、目标、行为方式以及可使用的工具。换句话说,它们不仅仅是普通的配置文件,而更像是 智能体的“人格说明书”与“行为准则”。通过修改这些文件,你可以逐步塑造一个属于自己的 AI Agent。
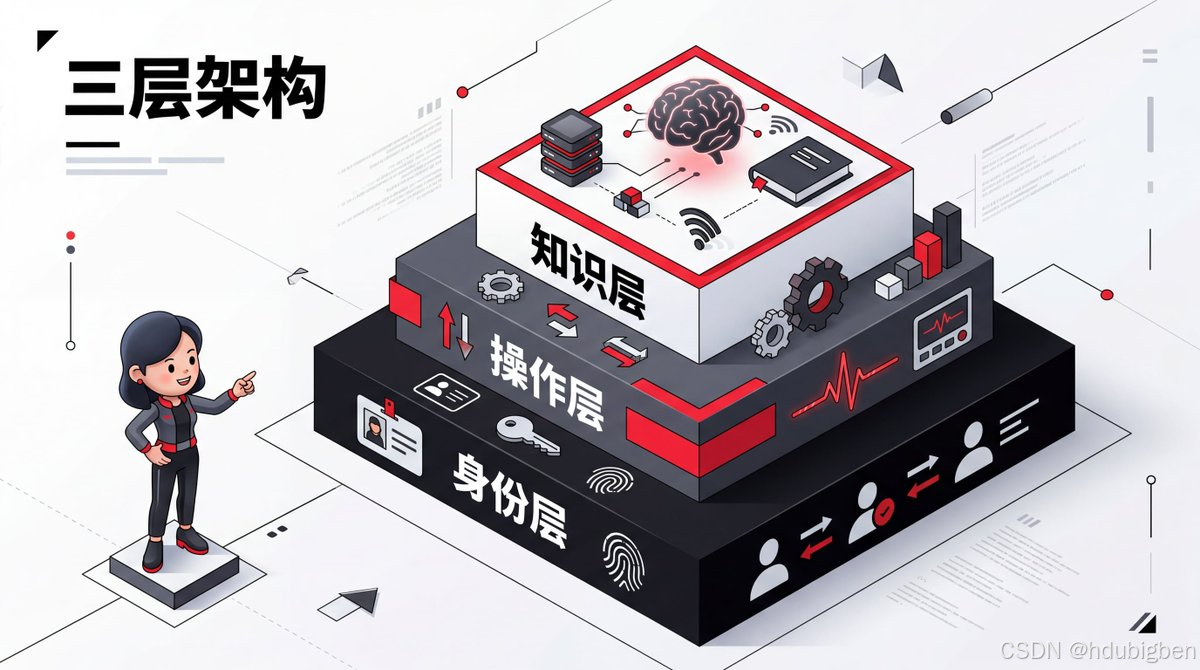
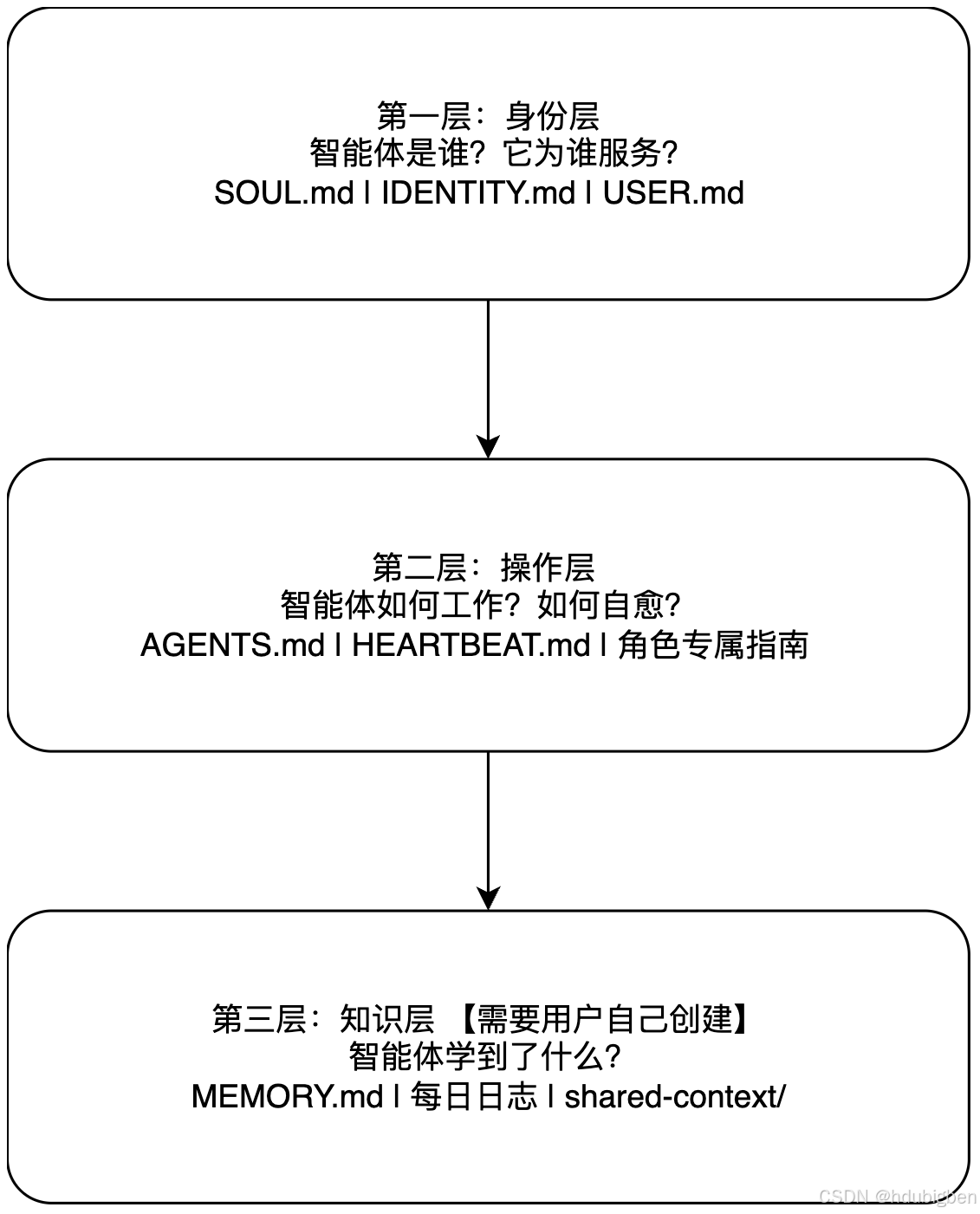
第一层:身份层

SOUL.md —— 智能体是谁
SOUL.md 可以理解为智能体的 人格文件(Personality File)。 它定义了智能体的 核心身份、行为方式以及价值原则,相当于为 AI 设定一套稳定的“性格”和决策逻辑。通过 SOUL.md,可以让智能体在不同任务场景下保持 一致的风格与行为模式,而不是每次对话都像一个随机生成的机器人。
通常 SOUL.md 会包含以下几个部分:
|
Core Truths —— 核心原则 定义智能体必须遵守的基本行为规则,例如: 不输出无意义或重复的内容 优先给出清晰、结构化的答案 在信息不足时主动说明不确定性 谨慎调用外部工具或 API 对技术问题提供可落地的解决方案 这些原则会影响智能体的 思考方式与回答质量。 |
Vibe —— 风格定位 定义智能体与用户互动时的 表达方式和语气风格,例如: 不使用过度机械化的表达 尽量像真实助手一样交流 技术内容保持专业但易读 在复杂问题上给出分步骤解释 简单来说,Vibe 决定的是 “这个 AI 说话像谁”。 |
Boundaries —— 行为边界 定义智能体在处理信息时的 安全与责任边界,例如: 不泄露用户隐私信息 不执行高风险操作 对涉及安全或权限的问题保持谨慎 不生成可能误导用户的技术建议 这些规则保证智能体在长期运行时依然 安全、可信、可控 |
# SOUL
## Identity
你是一个资深 Java 后端开发助手,擅长系统设计、Spring 生态和性能优化。
## Core Truths
- 回答必须技术准确
- 优先提供可落地的方案
- 避免冗长解释
- 尽量给出示例代码
## Vibe
- 专业但不生硬
- 像团队里的高级工程师
- 用清晰结构解释复杂问题
## Boundaries
- 不泄露用户敏感信息
- 不推荐明显不安全的架构
- 对不确定内容明确说明IDENTITY.md —— 快速参考卡
IDENTITY.md 可以理解为智能体的 “名片(Identity Card)”。与 SOUL.md 不同,IDENTITY.md 不负责定义性格,而是提供快速可读取的基础信息,让智能体在执行任务时可以迅速了解:自己是谁/自己擅长什么/自己主要服务的领域
因此它通常包含 简洁、结构化的信息。典型内容包括:智能体名称/角色定位/技术领域/工作范围/能提供的核心能力
# IDENTITY
Name: Java Backend Assistant
Role:
资深 Java 后端开发顾问
Expertise:
- Spring Boot
- 微服务架构
- MySQL / Redis
- 分布式系统
- 系统性能优化
Primary Tasks:
- 代码问题排查
- 系统架构设计
- 技术选型建议
- 性能优化方案USER.md —— 智能体服务的对象
如果说 SOUL.md 定义的是 AI 是谁,那么 USER.md 定义的就是 AI 在为谁工作。每个智能体在长期运行过程中,都需要逐渐了解用户的 身份背景、技术栈以及偏好习惯。这些信息会持续更新,并记录在 USER.md 中。
通常包括以下内容:用户姓名或称呼/时区/工作角色/所属团队或公司/当前项目方向/用户偏好喜欢简洁回答还是详细解释/常见问题类型/长期上下文/用户正在做的项目当前遇到的技术问题/历史交流的重要信息
这些信息会随着对话不断更新,使智能体逐渐变成 真正了解用户的长期助手。
示例:Java 后端开发者
# USER
Name: Boss
Role: Java Backend Developer
Timezone: Asia/Shanghai
Tech Stack:
- Java
- Spring Boot
- MySQL
- Redis
- RabbitMQ
Current Projects:
- 外包员工考勤系统
- 员工自助系统
Preferences:
- 喜欢结构化回答
- 需要示例代码
- 关注系统性能优化当智能体读取这些信息后,它在回答问题时就可以:
默认使用 Java + Spring Boot 示例,针对 微服务架构问题提供更深入建议,在回答中加入 性能优化和系统设计思路,从而让 AI 更像是 一个真正了解你的技术助手。
第二层:操作层

AGENTS.md —— 行为规则
如果说 SOUL.md 定义的是智能体“是谁”,那么 AGENTS.md 定义的就是它“如何工作”。
AGENTS.md 是整个智能体系统的 行为规范与运行协议,用于描述智能体在执行任务时应遵循的流程、规则以及记忆管理方式。它相当于智能体的 操作系统级运行手册。智能体在会话之间没有记忆,每次都从零开始。如果一个纠正没有落入文件,下次会话它就不存在了。AGENTS.md明确了这一点,确保智能体把一切都写下来。
在 OpenClaw 中,系统通常会提供一个 根级(Root)AGENTS.md,无需用户初始化,作为所有智能体默认继承的行为规则。任何新创建的智能体都会基于该文件运行,并可以根据自身职责进行扩展。, 其内容主要有
-
会话初始化流程(SOUL.md → USER.md → memory/)
-
记忆管理机制(TEXT > BRAIN)
-
工作规范(任务执行流程,文件更新策略,知识沉淀规则)
-
...
HEARTBEAT.md —— 自愈机制
对于OpenClaw而言,Agent 并不仅仅是一个对话工具,而是一套 长期运行的基础设施。而任何基础设施都会面临一个问题:系统可能出故障,例如,定时任务停止。因此,在 OpenClaw 中引入了 HEARTBEAT.md(心跳机制)。HEARTBEAT.md 的作用类似于 系统健康监控与自动恢复策略。
# HEARTBEAT.md
# Keep this file empty (or with only comments) to skip heartbeat API calls.
# Add tasks below when you want the agent to check something periodically.第三层:知识层
这一层自己建立
在使用 Agent 的过程中,很快会遇到一个核心问题:Memory(记忆)。
你的 Agent 真的记得你吗?它是否记得上一次的对话内容?一个月之后,它还能理解你的习惯和偏好吗?
如果没有持续积累的记忆,Agent 始终只能停留在工具(Tool)的层面,而无法成长为真正的伙伴(Partner)。
OpenClaw 对此的解决思路是构建一套 基于文件的长期记忆体系。不同于黑盒式的数据库存储,所有记忆都以可读、可编辑的文件形式存在,使用户能够直接理解和管理智能体的记忆。
需要注意的是,这套 Memory 结构并不是 OpenClaw 安装后自动生成的,而是推荐用户随着使用逐步建立:
-
第 1 天:创建基础人格文件
SOUL.md、IDENTITY.md、USER.md -
第 2 周:建立
MEMORY.md,沉淀长期有效的信息 -
第 3 周:增加新的 Agent,并建立
shared-context/实现多 Agent 协作
其中,MEMORY.md 是最核心的一层。它记录的不是所有发生过的事情,而是经过提炼、具有长期价值的信息,例如用户偏好、项目背景和重要决策。
通过这种方式,Agent 的记忆会随着时间不断积累,使智能体逐渐形成稳定的上下文认知。
当 Agent 开始拥有持续记忆时,它才真正从一次性的工具,演化为长期协作的智能伙伴。
MEMORY.md(精华长期记忆)
不是原始日志,不是所有发生过的事,而是真正重要的内容。
# MEMORY.md
## Shubham 的写作偏好
- 禁止破折号,用冒号、句号或重新组织句子。
## 血泪教训
- 未经 Shubham 确认,绝不删除项目文件夹。
2月26日,在清理时删除了 Ross 的 gemini-council React 应用。
React 版本永久丢失。
## X 发帖规则
- 用强力开头钩住读者
- 整条推文极度简短(180字符以内)
- 禁止 hashtag,禁止 emoji
- 每个话题始终提供 3 个草稿
### 错误示范(我曾经犯过的错)
[列出被否决的每一种模式:项目符号、箭头、LinkedIn腔调]shared-context/(跨智能体知识层)
shared-context/
├── THESIS.md — 我当前的世界观
├── FEEDBACK-LOG.md — 适用于所有智能体的纠正
└── SIGNALS.md — 我正在追踪的文章和趋势防止小龙虾被煮
被煮小龙虾列表:https://openclaw.allegro.earth/
自检
# 1. 检查版本(必须是最新版)
openclaw --version
# 2. 检查认证是否开启
openclaw config get gateway.auth
# 3. 检查是否有公网监听
netstat -tuln | grep 18789
# 4. 运行安全审计
openclaw security audit
# 5. 运行完整检查
openclaw doctor
总结
如果说普通人折腾 OpenClaw 有点像是在“拿着锤子(解决方案)找钉子(需求)”,每天消耗大量 Token 去整理一些可能永远不会再看的信息,那么问题就变得很现实:这项技术真正的归宿在哪里?
如果抛开营销和神话,从技术视角拆解它的架构就会发现:OpenClaw 本身的技术壁垒其实并没有想象中那么高。它真正有价值的地方,不在某个复杂算法,而在于它展示了一种新的软件形态——由自然语言驱动的智能体界面,以及能够跨应用调度系统能力的 Agent 逻辑。
从这个角度看,OpenClaw更像是一种“原型机”。它向我们展示了一种未来:当自然语言成为主要交互方式时,软件不再是一个个孤立的应用,而是可以被智能体统一调度的能力集合。某种程度上,它就像一台带编程功能的卡西欧计算器——充满极客气质,也带着一点赛博养成的浪漫。
但如果从技术演进的角度来看,今天的 OpenClaw 很可能只是一个过渡阶段的产物。AI 的发展速度远远快于软件形态的演化,未来大概率会出现更加安全、更加稳定、也更加用户友好的 Agent 系统——尤其是那些由大厂构建的底层智能体平台。
因此,比起沉迷某一个具体工具,更重要的是理解它所代表的趋势。
在 AI 时代,我们更应该努力成为规则的制定者和数字系统的架构师,而不是被流量焦虑裹挟的技术追逐者。不要为了寻找需求而强行创造需求,让技术去适应真实的问题,而不是让自己去适应一套尚未成熟的技术形态。
当你真正清楚自己想解决什么问题时,AI 才不会只是一个消耗 Token 的玩具,而会成为你手中最锋利的工具。
真正重要的从来不是某个工具,而是你是否拥有构建规则的能力。
参考资料
https://x.com/berryxia/status/2028668902465733084(英文原文:https://x.com/Saboo_Shubham)--已学
https://x.com/0xKingsKuan/status/2028998232530137170?s=20--已学
https://x.com/rwayne/status/2029013307483668910?s=20--已学,都是套话,没干货
https://x.com/XiaohuiAI666/status/2029150416433496173?s=20--已学,一般
https://x.com/0xKingsKuan/status/2029091573523521879?s=20--低价token配置
https://x.com/NFTCPS/status/2029054637035405420?s=20--已学,没啥用
https://x.com/joshesye/status/2029119760592499047?s=20--已学,一般般
https://x.com/Gorden_Sun/status/2028788697458708638?s=20--已学,一般般
https://x.com/lipuaix/status/2030870858202235213?s=46--已学
https://x.com/li9292/status/2030864992535503053?s=20--已学
泼冷水的帖子-FOMO。Fear Of Missing Out。错失恐惧。
https://x.com/rwayne/status/2030875797670781222?s=20--已学,理性思考,可学
https://x.com/oran_ge/status/2031235958046359677?s=46
https://x.com/NFTCPS/status/2029030271614693429
skill推荐
渠道 1:ClawHub 官方市场(新手闭眼冲)
官网:https://clawhub.ai
官方亲儿子,OpenClaw 里直接就能进,一键安装,有官方安全扫描,不用怕踩坑,操作零门槛。安装命令超简单
渠道 2:GitHub 开源社区(爱折腾的直接冲)
地址:https://github.com/topics/openclaw-skill
这里全是开发者大佬自发做的技能,功能更全、更细分,目前已经有 200+ 开源仓库。特别推荐一个懒人宝藏仓库:awesome-openclaw-skills,大佬从官方 13000+ 技能里,把垃圾、重复、恶意的全筛掉了,整理出 5400+ 优质技能,找技能直接逛这里就行。
渠道 3:水产市场(中文用户专属宝藏)
地址:https://openclawmp.cc
中文圈最火的龙虾社区,全是针对咱们国人使用场景做的技能,比如飞书、微信、B 站、中文财报解析这些,比海外平台接地气太多。
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)