计算机毕业设计:Python棉花产业数据可视化与预测系统 Django框架 ARIMA算法 数据分析 可视化 爬虫 大数据 大模型(建议收藏)✅
摘要 本文介绍了一个基于Django框架的棉花数据可视化分析与预测系统。系统采用Python开发,结合MySQL数据库和requests爬虫技术,从棉花产业经济信息网采集数据,运用ARIMA时间序列模型进行预测分析。主要功能包括:全球棉花产量/面积分布可视化(环形图、金字塔图)、中国各省份棉花数据热力图展示、棉花价格走势分析、基于ARIMA模型的产量/面积预测、数据采集管理以及用户登录系统。该系统
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
采用 Python 语言开发,基于 Django 框架搭建后端服务,使用 MySQL 数据库进行数据存储,通过 requests 爬虫技术从棉花产业经济信息网采集数据,运用时间序列 ARIMA 预测算法模型进行产量与价格预测,前端结合 Echarts 实现数据可视化。
功能模块
· 各国棉花面积产量分布分析
· 面积与产量分布分析
· 各国棉花数据分布分析
· 中国地图各省份产量分布分析
· 中国地图各省份种植面积分布分析
· 棉花价格分布分析
· 棉花产量预测与种植面积预测
· 数据采集
· 后台数据管理
· 注册登录
项目介绍
本系统基于 Django 框架构建棉花数据可视化分析与预测平台,通过 requests 爬虫从棉花产业经济信息网采集国内及国际棉花种植面积、产量、单产、价格等数据,存入 MySQL 数据库。系统提供全球及中国棉花数据的多维度可视化分析,包括各国产量面积环形图与金字塔图、中国各省份产量与种植面积地图热力图、棉花价格走势折线图等。基于 ARIMA 时间序列模型,对棉花产量、种植面积及价格进行未来趋势预测。系统还包含数据采集控制、后台数据管理及用户注册登录功能。
2、项目界面
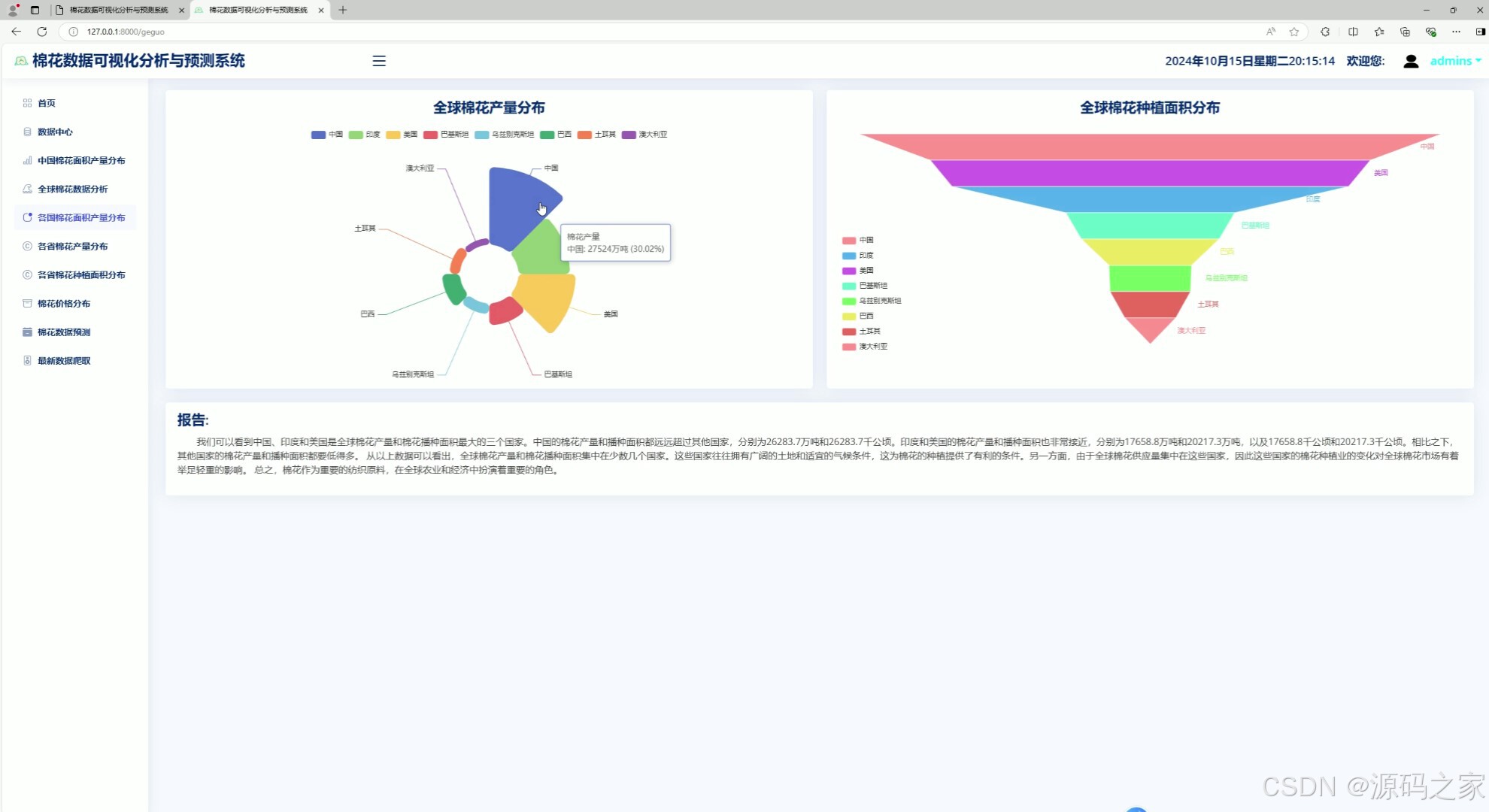
1、各国棉花面积产量分布分析
该页面为棉花数据可视化分析系统的全球棉花数据分布模块,通过环形图和金字塔图分别展示全球棉花产量与种植面积分布,并搭配分析报告,直观呈现各国棉花产业数据对比与分布情况。
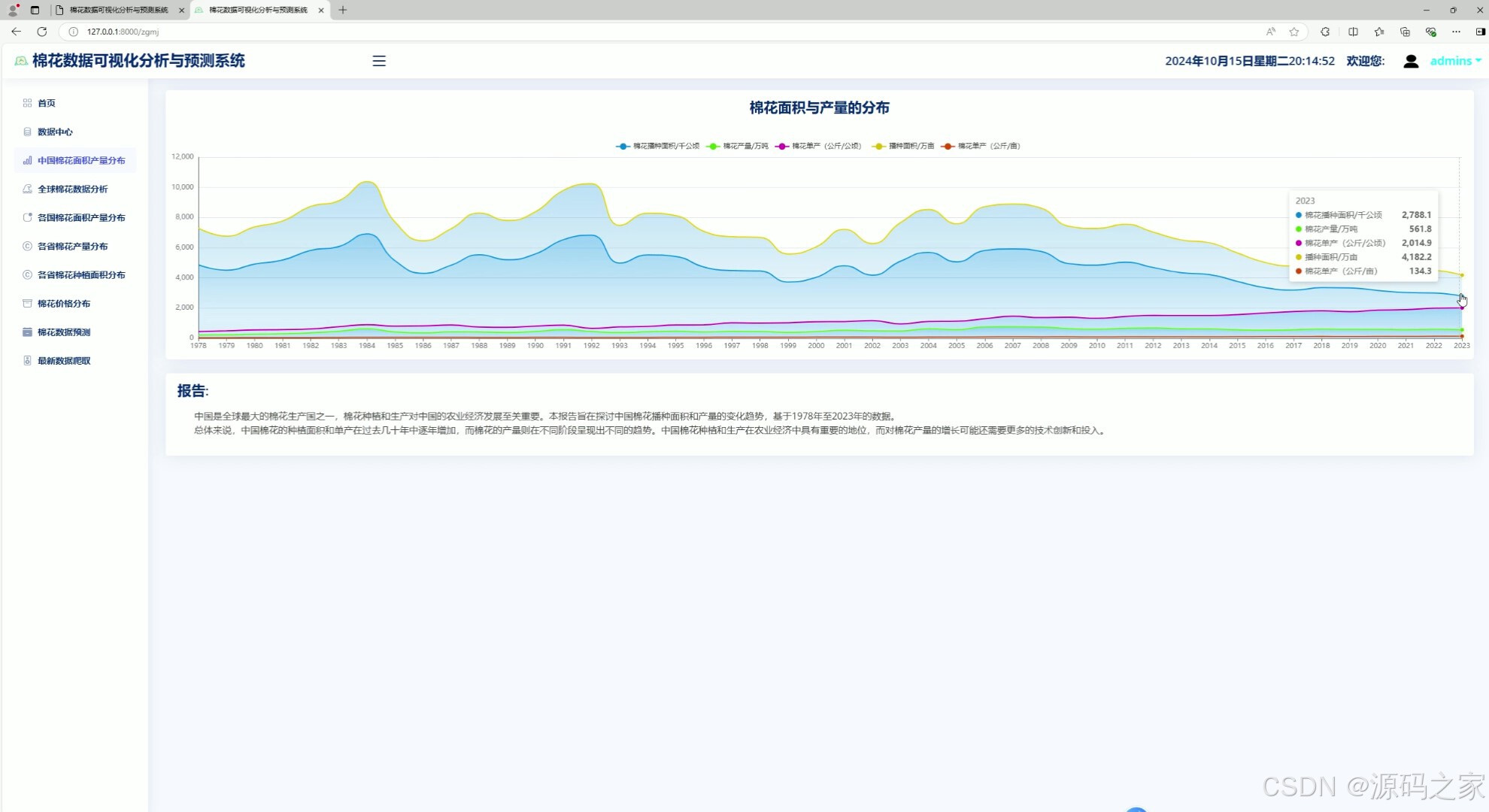
2、面积与产量分布分析
该页面为棉花数据可视化分析系统的中国棉花面积与产量分析模块,通过多折线图呈现棉花种植面积、产量、单产等数据的长期变化趋势,并搭配分析报告,直观展示棉花产业相关指标的动态变化规律。
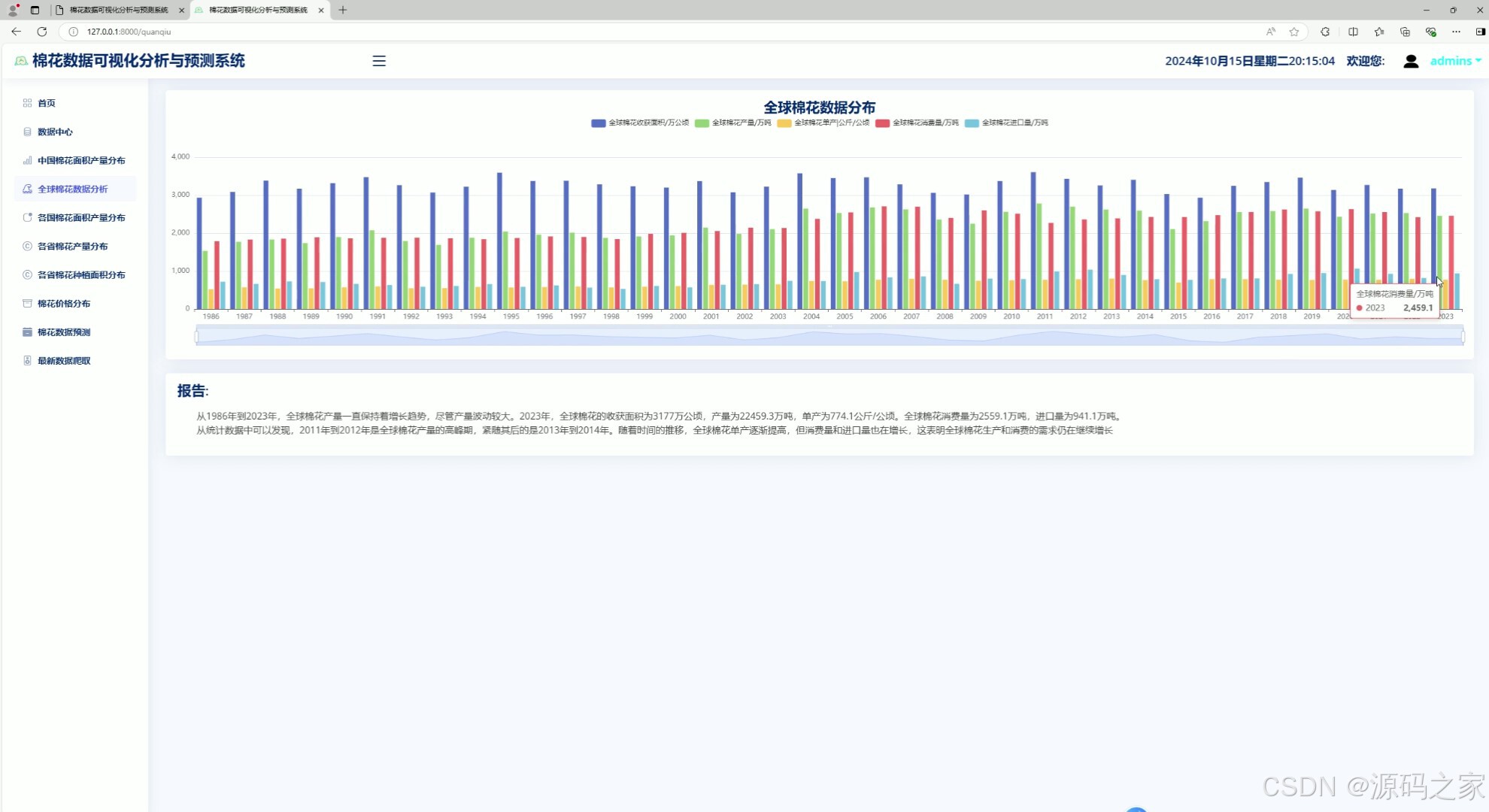
3、各国棉花数据分布分析
该页面为棉花数据可视化分析系统的全球棉花数据分布模块,通过多组柱状图呈现全球棉花种植面积、产量、单产、消费量、进口量等多项指标的历年变化趋势,并搭配分析报告,直观展示全球棉花产业相关数据的动态变化规律。
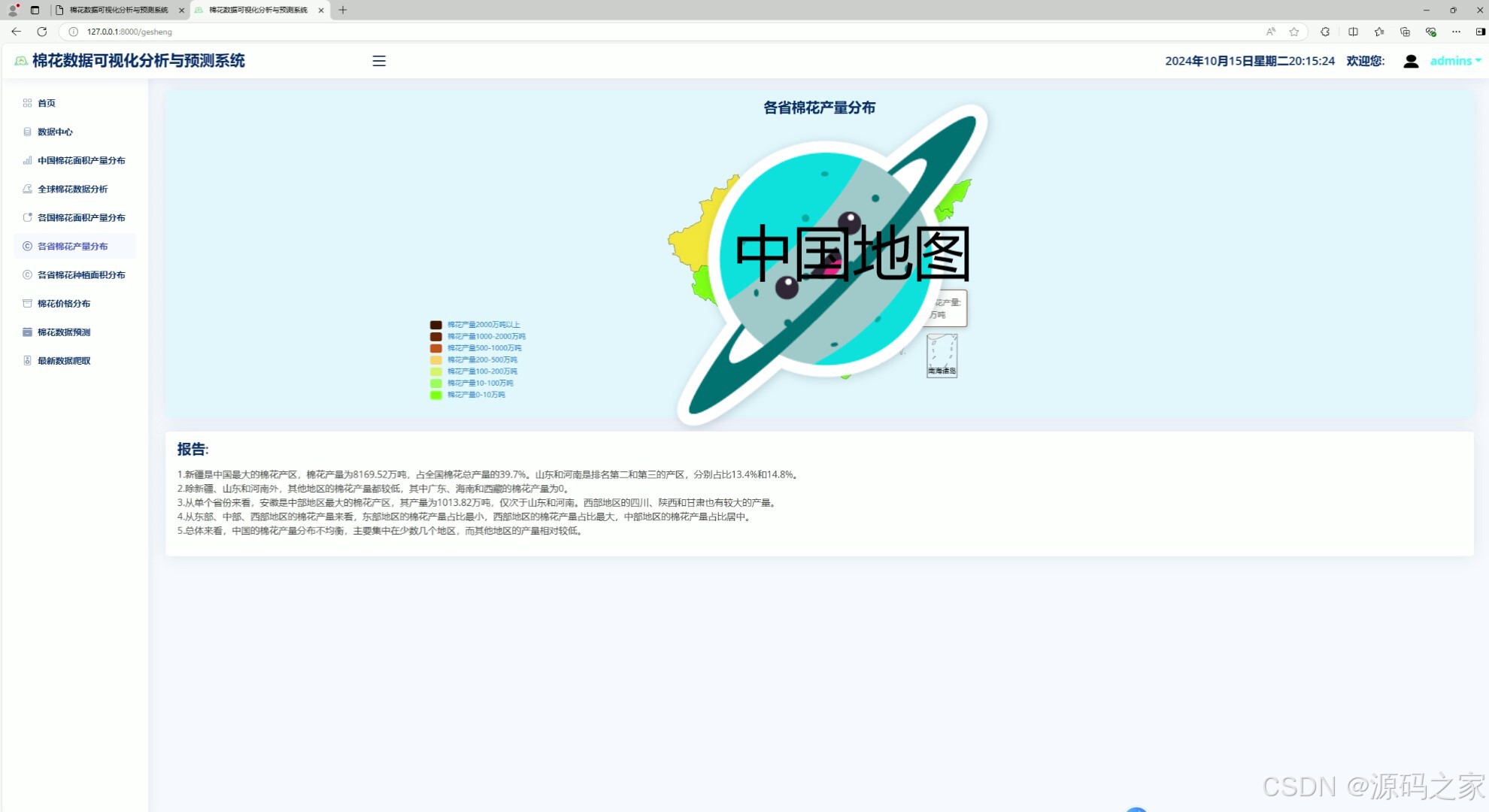
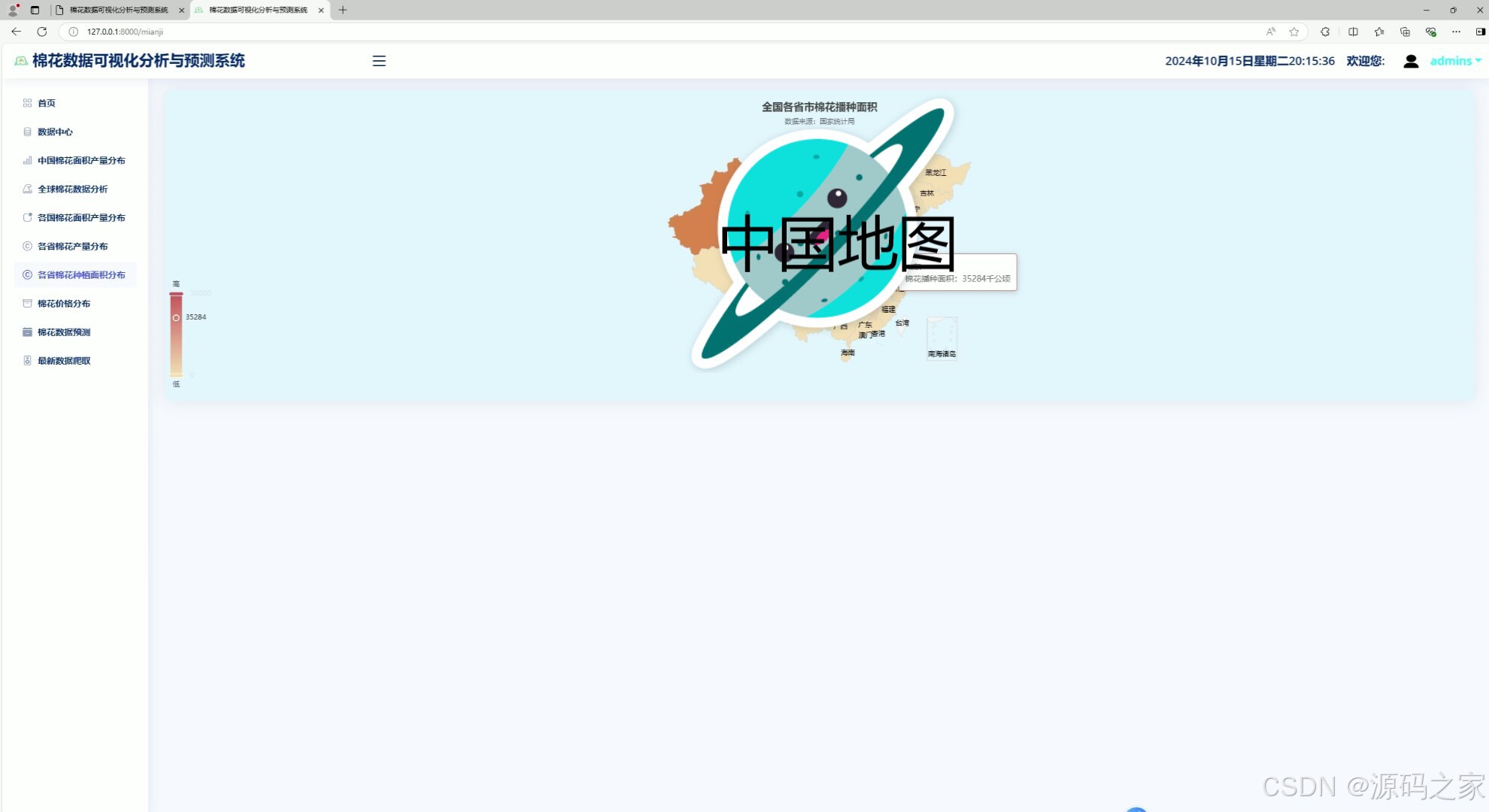
4、中国地图—各省份产量分布分析
该页面为棉花数据可视化分析系统的各省棉花产量分布模块,通过中国地图热力图直观呈现不同省份的棉花产量分布情况,并搭配分析报告,帮助用户了解国内棉花产量的区域差异与分布特征。
5、中国地图—各省份种植面积分布分析
该页面为棉花数据可视化分析系统的各省棉花种植面积分布模块,通过中国地图热力图直观呈现不同省份的棉花种植面积分布情况,可帮助用户清晰了解国内棉花种植的区域差异与分布特征。
6、棉花价格分布分析
该页面为棉花数据可视化分析系统的棉花价格分析模块,通过多折线图呈现棉花价格的历史走势与未来三年的预测趋势,并搭配分析报告,直观展示棉花价格的波动规律与预测变化。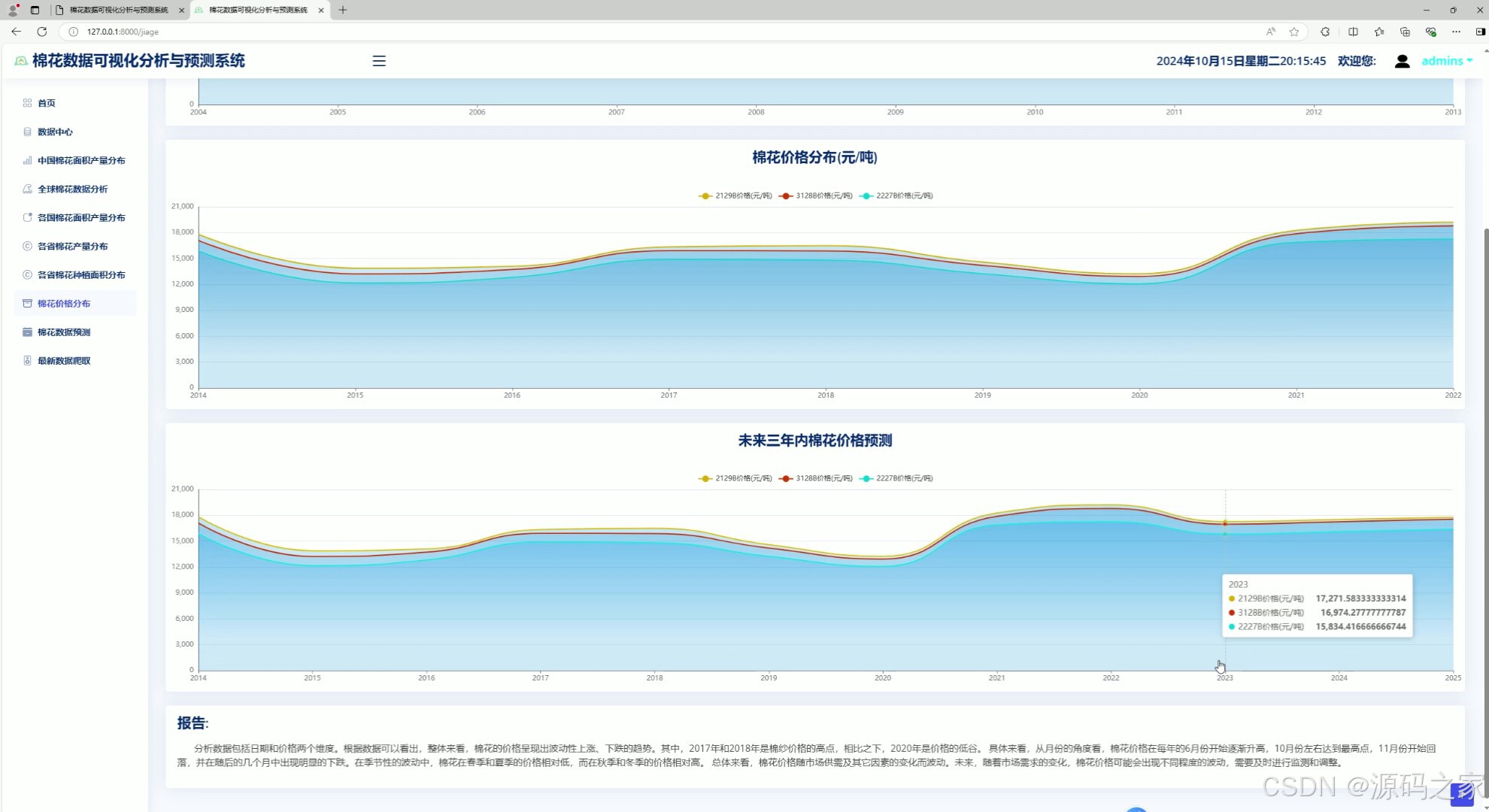
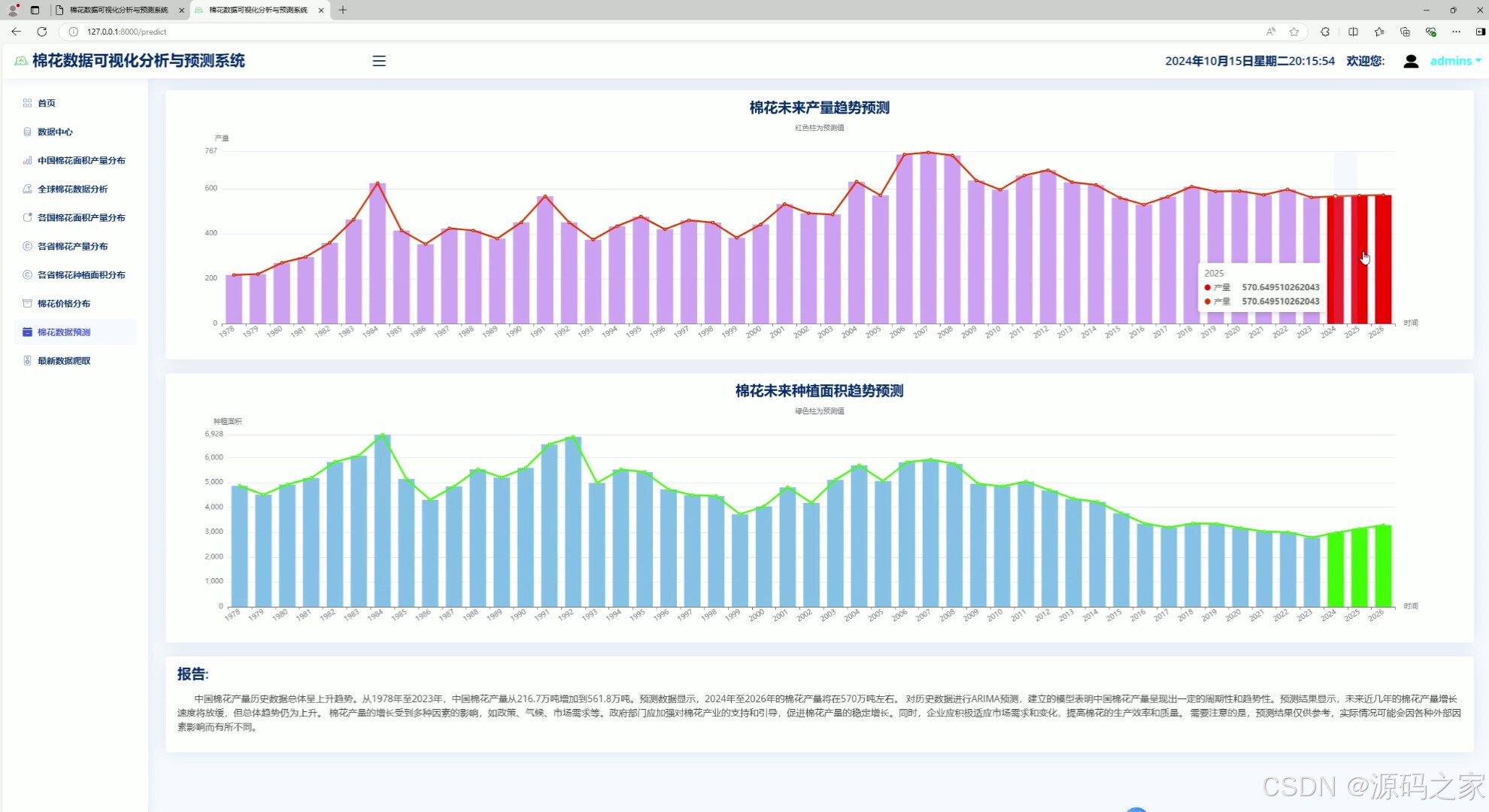
7、棉花预测----产量预测、种植面积预测
该页面为棉花数据可视化分析系统的棉花数据预测模块,通过柱状图与折线图结合的形式,分别呈现棉花未来产量与种植面积的历史数据及预测趋势,并搭配分析报告,直观展示相关指标的变化规律与预测走向。
8、数据采集
该页面为棉花数据可视化分析系统的最新数据爬取模块,提供数据爬取控制按钮,可启动或停止爬取,下方表格展示爬取到的历年棉花种植面积、产量、单产等最新数据,方便用户获取和查看更新后的棉花产业信息。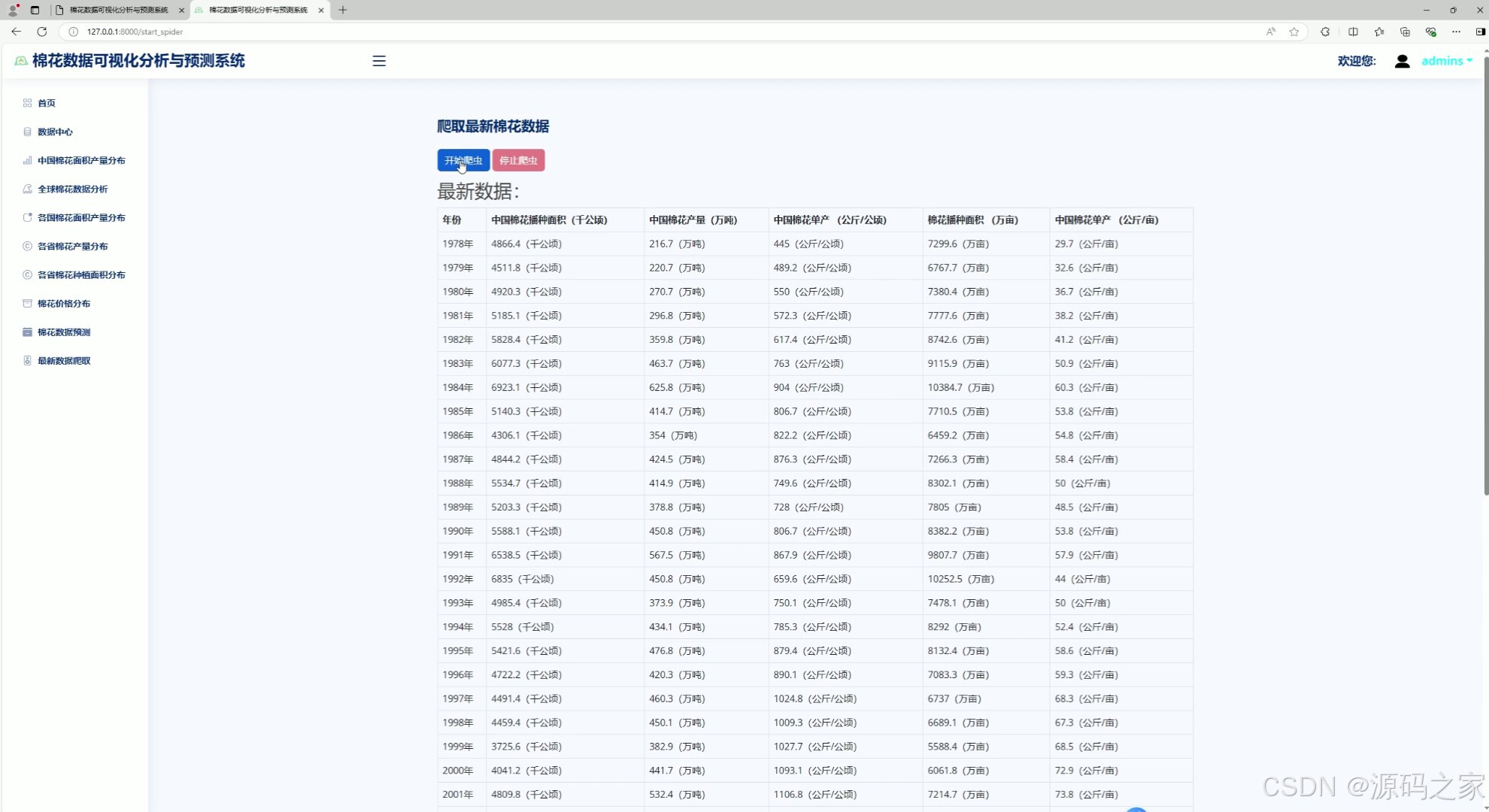
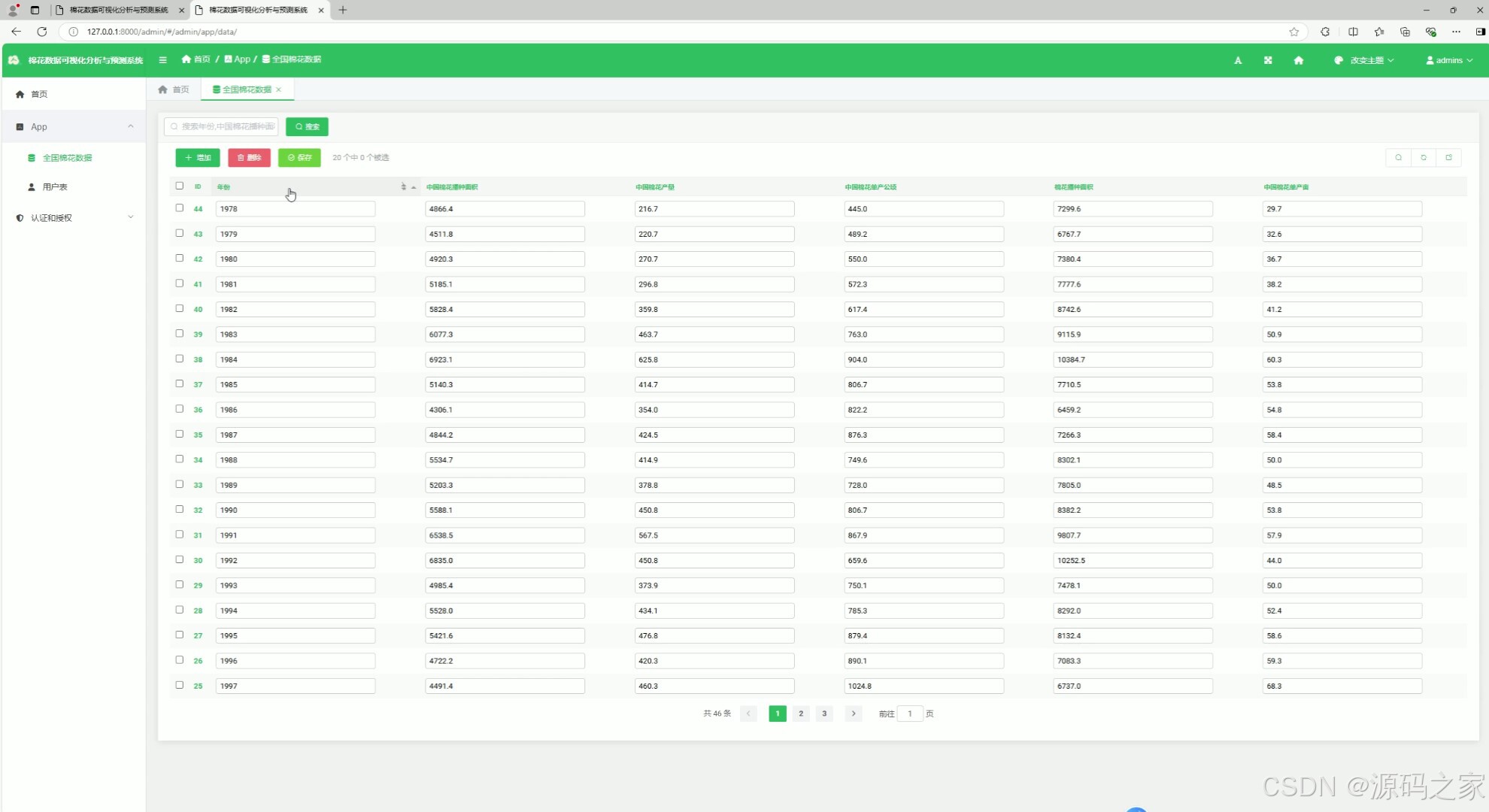
9、后台数据管理
该页面为棉花数据可视化分析系统的后台数据管理模块,提供全国棉花数据的表格展示与管理功能,支持数据搜索、增删、保存操作,可对历年棉花种植面积、产量、单产等数据进行查看、编辑与维护。
10、注册登录
该页面是棉花数据可视化分析与预测系统的用户登录界面,提供用户名和密码输入框,支持记住密码、普通用户与管理员两种登录类型选择,还有注册入口,用户可在此输入信息完成身份验证,进入系统。

3、项目说明
一、技术栈简要说明
本系统采用 Python 语言开发,基于 Django 框架搭建后端服务,使用 MySQL 数据库进行数据存储,通过 requests 爬虫技术从棉花产业经济信息网采集数据,运用时间序列 ARIMA 预测算法模型进行产量与价格预测,前端结合 Echarts 实现数据可视化。
二、功能模块详细介绍
· 各国棉花面积产量分布分析
该页面为全球棉花数据分布模块,通过环形图和金字塔图分别展示全球棉花产量与种植面积分布,并搭配分析报告,直观呈现各国棉花产业数据对比与分布情况,帮助用户了解国际棉花市场的整体格局。
· 面积与产量分布分析
该页面为中国棉花面积与产量分析模块,通过多折线图呈现棉花种植面积、产量、单产等数据的长期变化趋势,并搭配分析报告,直观展示棉花产业相关指标的动态变化规律,辅助用户把握国内棉花生产的发展脉络。
· 各国棉花数据分布分析
该页面通过多组柱状图呈现全球棉花种植面积、产量、单产、消费量、进口量等多项指标的历年变化趋势,并搭配分析报告,直观展示全球棉花产业相关数据的动态变化规律,支持多维度跨国对比分析。
· 中国地图各省份产量分布分析
该页面通过中国地图热力图直观呈现不同省份的棉花产量分布情况,并搭配分析报告,帮助用户了解国内棉花产量的区域差异与分布特征,识别主要产棉区及其产量贡献。
· 中国地图各省份种植面积分布分析
该页面通过中国地图热力图直观呈现不同省份的棉花种植面积分布情况,帮助用户清晰了解国内棉花种植的区域差异与分布特征,为种植规划与政策制定提供参考。
· 棉花价格分布分析
该页面通过多折线图呈现棉花价格的历史走势与未来三年的预测趋势,并搭配分析报告,直观展示棉花价格的波动规律与预测变化,辅助用户把握市场价格动态。
· 棉花产量预测与种植面积预测
该页面通过柱状图与折线图结合的形式,分别呈现棉花未来产量与种植面积的历史数据及预测趋势。基于 ARIMA 时间序列模型对历史数据进行拟合训练,预测未来几年的指标变化,并搭配分析报告,直观展示相关指标的变化规律与预测走向。
· 数据采集
该页面提供数据爬取控制按钮,可启动或停止爬取,下方表格展示爬取到的历年棉花种植面积、产量、单产等最新数据。通过 requests 爬虫技术从棉花产业经济信息网自动采集数据,支持定时更新,方便用户获取和查看更新后的棉花产业信息。
· 后台数据管理
该页面提供全国棉花数据的表格展示与管理功能,支持数据搜索、增删、保存操作,可对历年棉花种植面积、产量、单产等数据进行查看、编辑与维护。管理员可通过该模块对数据进行系统化管理,保证数据的准确性和时效性。
· 注册登录
该页面是用户登录界面,提供用户名和密码输入框,支持记住密码、普通用户与管理员两种登录类型选择,还有注册入口,用户可在此输入信息完成身份验证,进入系统,保障系统访问安全与权限管理。
三、项目总结
本系统基于 Django 框架构建棉花数据可视化分析与预测平台,通过 requests 爬虫从棉花产业经济信息网采集国内及国际棉花种植面积、产量、单产、价格等数据,存入 MySQL 数据库。系统提供全球及中国棉花数据的多维度可视化分析,包括各国产量面积环形图与金字塔图、中国各省份产量与种植面积地图热力图、棉花价格走势折线图等。基于 ARIMA 时间序列模型,对棉花产量、种植面积及价格进行未来趋势预测,为用户提供科学的决策参考。系统还包含数据采集控制、后台数据管理及用户注册登录功能,为棉花产业的种植规划、市场分析及政策制定提供了全面的数据支持。
4、核心代码
def pred(df, col):
# 差分操作
diff_data = df.diff().dropna()
# 建立ARIMA模型并拟合
model = ARIMA(df[col], order=(1, 1, 1))
result = model.fit()
# 预测结果
pred = result.predict(start='2024', end='2026', typ='levels')
# pred = result.predict(start='2022', end='2024', typ='levels')
# 将“年份”转换为一列
df = df[[col]].reset_index()
# 修改列名为“年份”
df.rename(columns={'index': '年份'}, inplace=True)
# 输出结果
print(df)
# 将时间索引转换为一列
s = pred.reset_index()
# 修改列名
s = s.rename(columns={'index': '年份'})
s = s.rename(columns={'predicted_mean': col})
print(s)
# 合并DataFrame和Series
res_df = pd.concat([df, s], axis=0, ignore_index=True, sort=False)
res_df['年份'] = res_df['年份'].dt.strftime('%Y')
return res_df
@login_required
def jiage(request):
query1 = 'select * from 棉花价格04到13'
query2 = 'select * from 棉花价格14到23'
df = query_database(query1)
df = df.sort_values(by='年份', ascending=True)
date = df['年份'].tolist()
col_list = df.columns.tolist()
df1_list = [df[col].values.tolist() for col in col_list]
print(df1_list[1:])
df2 = query_database(query2)
df2 = df2.sort_values(by='年份', ascending=True)
date2 = df2['年份'].tolist()
col_list2 = df2.columns.tolist()
df2_list = [df2[col].values.tolist() for col in col_list2]
print(df2_list[1:])
df2 = df2.sort_values(by='年份', ascending=True)
print(df2)
X_train, y_train = df2[['年份']], df2[['2129B价格(元/吨)', '3128B价格(元/吨)', '2227B价格(元/吨)']]
X_test = pd.DataFrame({'年份': [2023, 2024, 2025]})
models = {}
for col in y_train.columns:
model = LinearRegression().fit(X_train, y_train[col])
models[col] = model
predictions = {}
for col, model in models.items():
predictions[col] = model.predict(X_test)
print(pd.DataFrame(predictions, index=[2023, 2024, 2025]))
pre_df = pd.DataFrame(predictions, index=[2023, 2024, 2025]).reset_index().rename(columns={'index': '年份'})
res_df = pd.concat([df2, pre_df])
print(res_df)
res_date = res_df['年份'].tolist()
res_col = res_df.columns.tolist()
res_list = [res_df[col].values.tolist() for col in res_col]
return render(request, 'jiage.html', locals())
@login_required
def predict(request):
# 读取数据并设置DateTimeIndex
query1 = 'select * from 全国棉花数据'
df = query_database(query1)
df = df.sort_values(by='年份', ascending=True)
df = df.set_index('年份')
df.index = pd.to_datetime(df.index, format='%Y')
res_df = pred(df, '中国棉花产量')
res_df2 = pred(df, '中国棉花播种面积')
# 输出结果
print(res_df)
years = res_df['年份'].tolist()
data = res_df['中国棉花产量'].tolist()
data2 = res_df2['中国棉花播种面积'].tolist()
return render(request, 'predict.html', locals())
@login_required
def spider(request):
return render(request, 'spider.html')
def start_spider(request):
if request.method == 'POST':
response = requests.get('http://www.chinacotton.org/db/DB_010.aspx')
df = pd.read_html(response.text)
df = pd.read_html(response.text)
df = df[1]
df = df.iloc[2:-2] # 删除前两行
df.columns = df.iloc[0]
df = df[1:] # 删除第一行
response = requests.get('http://www.chinacotton.org/db/DB_010.aspx')
df = pd.read_html(response.text)
df = df[1]
df = df.iloc[2:-2] # 删除前两行
df.columns = df.iloc[0]
df = df[1:] # 删除第一行
df = df.sort_values(by='年份', ascending=True)
data = df.values.tolist()
for d in data:
time.sleep(0.1)
print({
'年份': d[0],
'中国棉花播种面积(千公顷)': d[1],
'中国棉花产量 (万吨)': d[2],
'中国棉花单产 (公斤/公顷)': d[3],
'棉花播种面积 (万亩)': d[4],
'中国棉花单产 (公斤/亩)': d[5],
})
return render(request, 'spider.html', locals())
def stop_spider(request):
if request.method == 'POST':
return JsonResponse({'status': 'success'})
else:
# 返回错误响应
return HttpResponseBadRequest('Invalid request method')
5、源码获取方式

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)