【深度长文】大模型分布式训练通信原语及其应用
本文会从基础概念→基础原语→核心进阶原语→大模型训练落地场景,逐层系统讲解,完全贴合新手学习的大模型分布式训练场景。
本人最近在看 Megatron 框架,被里面很多分布式训练通信原语搞的头晕眼花,于是决定系统地学习与总结一遍常用的通信原语,并整理成适合自己的笔记以之后查阅,也分享给大家。
通信原语,是多GPU/多进程分布式训练中,数据传输与聚合的标准化、原子化操作,是NVIDIA NCCL通信库的核心,更是Megatron等大模型框架实现TP/PP/DP/SP混合并行的底层基石。一些同样基础的概念,如梯度规约、张量分片传输、流水线激活值传递,最终都会落到这些通信原语上。
本文会从基础概念→基础原语→核心进阶原语→大模型训练落地场景,逐层系统讲解,完全贴合新手学习的大模型分布式训练场景。
一、前置核心基础概念
所有通信原语的理解,都基于这几个核心概念,避免后续认知混乱:
-
通信域(Process Group/进程组)
通信的「边界」,只有同一个组内的rank才能互相通信,组外进程完全无感知。比如Megatron里的TP_GROUP(张量并行组)、DP_GROUP(数据并行组)、PP_GROUP(流水线并行组),都是独立的通信域,通信只在组内发生,互不干扰。 -
Rank
通信域内的唯一进程编号,从0开始。比如一个TP=2的张量并行组,就有rank0和rank1两个进程,对应2张GPU。 -
张量分片(Chunk/Slice)
把一个完整大张量,沿某个维度切成多个等长的小块,每个rank持有其中一块。比如完整张量shape=[8],TP=2时切成2块,每块shape=[4],rank0拿前4个元素,rank1拿后4个元素。 -
规约操作(Reduce Operation)
把多个张量合并成一个张量的计算操作,从数学上来讲有点像向量->值的概念。 -
通信的两大核心成本
- 带宽成本:传输的数据量越大,耗时越长;
- 延迟成本:通信的启动固定开销,和数据量无关,和通信次数正相关。
所有分布式通信优化,本质都是围绕降低这两个成本展开。
二、基础集体通信原语
先讲4个最基础的集体通信原语,后续的核心进阶原语,都是它们的组合与扩展。
集体通信:通信域内所有rank都必须参与的通信操作,是分布式训练的核心。
1. Broadcast(广播)
- 核心定义:一对多的单向通信。从一个根节点(Root Rank),把完全相同的数据,发送给通信域内所有其他rank,最终所有rank都持有和root完全一致的数据。
- 直观示例(4个rank,root=0)
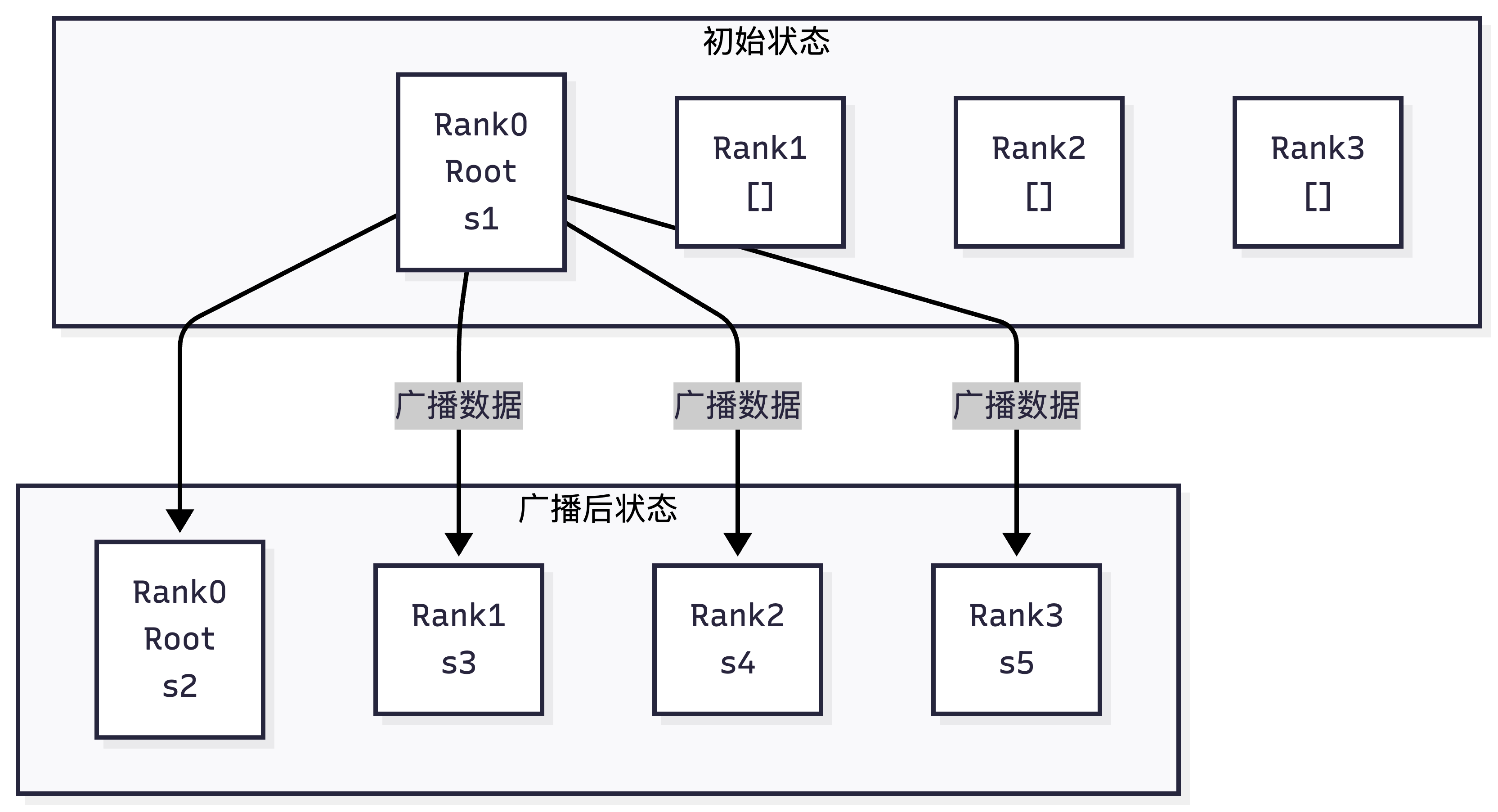
初始状态:
Rank0: [A0, A1, A2, A3] (root,持有完整数据)
Rank1: []
Rank2: []
Rank3: []
广播后状态:
Rank0: [A0, A1, A2, A3]
Rank1: [A0, A1, A2, A3]
Rank2: [A0, A1, A2, A3]
Rank3: [A0, A1, A2, A3]
- 核心特性:只有root发送数据,其他rank只接收;所有rank最终数据完全一致。
- 大模型训练典型场景:
- 训练初始化时,root rank加载预训练权重,广播给其他所有rank,保证初始参数完全一致;
- 数据加载时,root rank读取全局配置/数据元信息,广播给同组其他rank。
2. Reduce(规约)
- 核心定义:多对一的通信。通信域内所有rank的输入数据,按指定规约操作(如SUM)聚合,最终把聚合结果只发送给根节点Root Rank。
- 直观示例(4个rank,root=0,规约操作SUM)
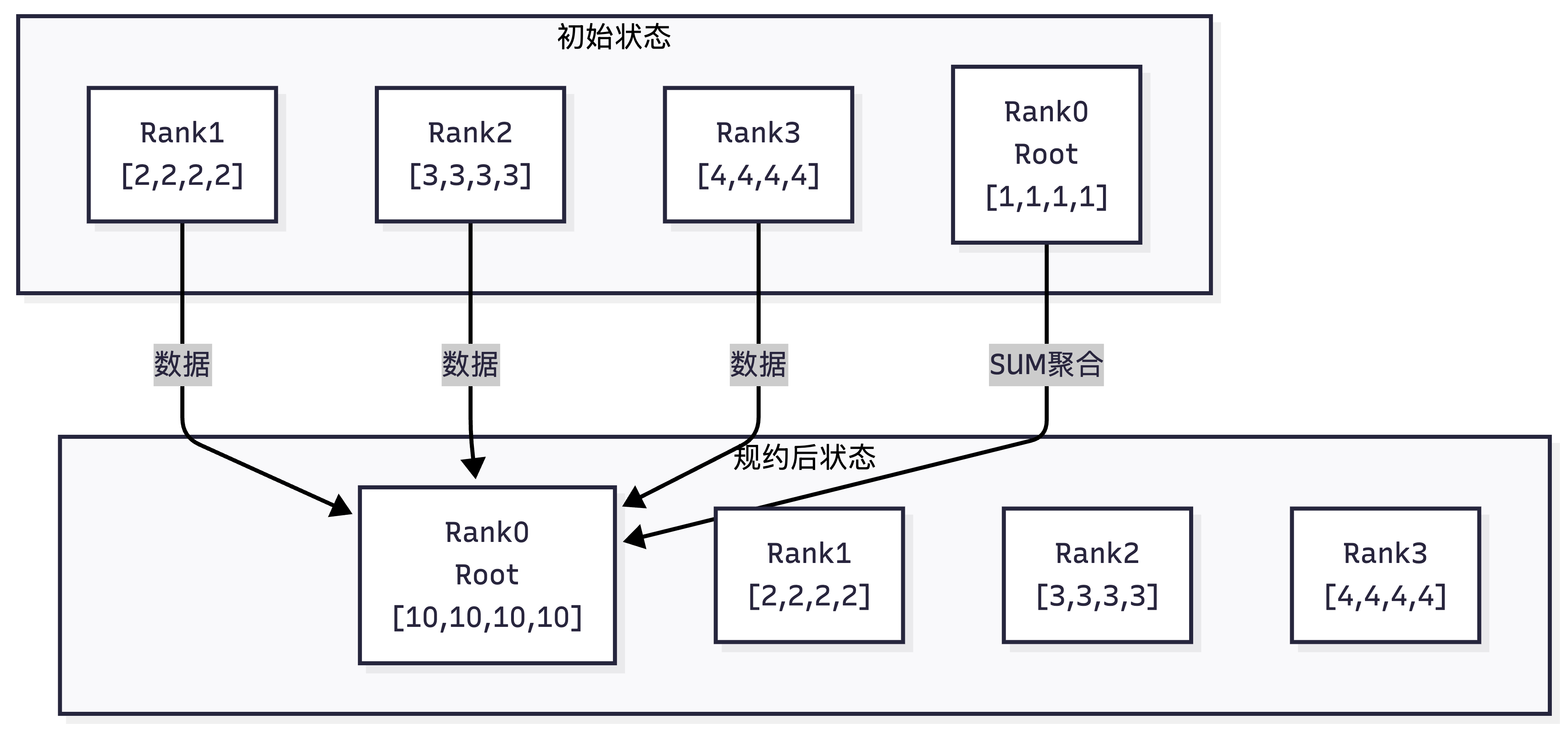
初始状态:
Rank0: [A0, A1, A2, A3]
Rank1: [B0, B1, B2, B3]
Rank2: [C0, C1, C2, C3]
Rank3: [D0, D1, D2, D3]
Reduce后状态:
Rank0: [A0+B0+C0+D0, A1+B1+C1+D1, A2+B2+C2+D2, A3+B3+C3+D3](root,拿到聚合结果)
Rank1: [B0, B1, B2, B3] (数据不变)
Rank2: [C0, C1, C2, C3] (数据不变)
Rank3: [D0, D1, D2, D3] (数据不变)
- 核心特性:只有root拿到最终聚合结果,其他rank数据不变;必须指定规约操作。
- 大模型训练典型场景:
- 训练时,把所有rank的loss规约到root rank,用于打印日志、记录TensorBoard,避免重复输出;
- 分布式评估时,把所有rank的准确率、PPL等指标规约到root,计算全局评估结果。
3. Scatter(分发)
- 核心定义:一对多的分片分发。根节点Root Rank把一个完整大张量,按rank数量切成等长的分片,把每个分片定向分发给对应的rank,最终每个rank只拿到属于自己的那一个分片。
- 直观示例(4个rank,root=0)
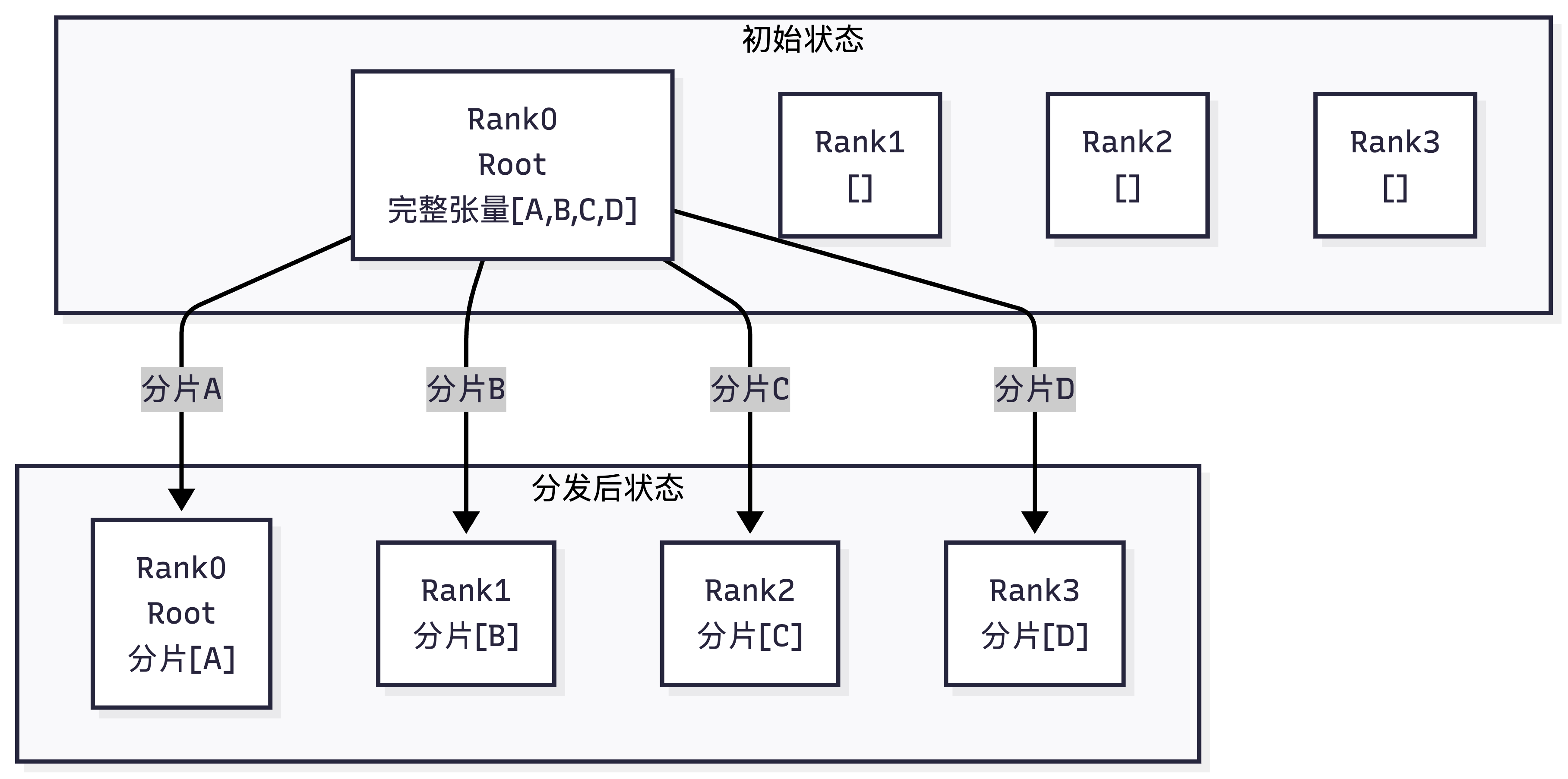
初始状态:
Rank0: [A0,A1,A2,A3, B0,B1,B2,B3, C0,C1,C2,C3, D0,D1,D2,D3] (root,完整张量)
Rank1: []
Rank2: []
Rank3: []
Scatter后状态:
Rank0: [A0, A1, A2, A3] (第0个分片)
Rank1: [B0, B1, B2, B3] (第1个分片)
Rank2: [C0, C1, C2, C3] (第2个分片)
Rank3: [D0, D1, D2, D3] (第3个分片)
- 核心特性:root持有完整张量,每个rank最终只拿到自己的分片;分片数量必须等于rank数量。
- 大模型训练典型场景:
- 数据并行中,root rank把全局Batch切分成微批次,分发给每个DP rank;
- 序列并行中,把完整的序列张量切分成分片,分发给TP组内的每个rank。
4. Gather(收集)
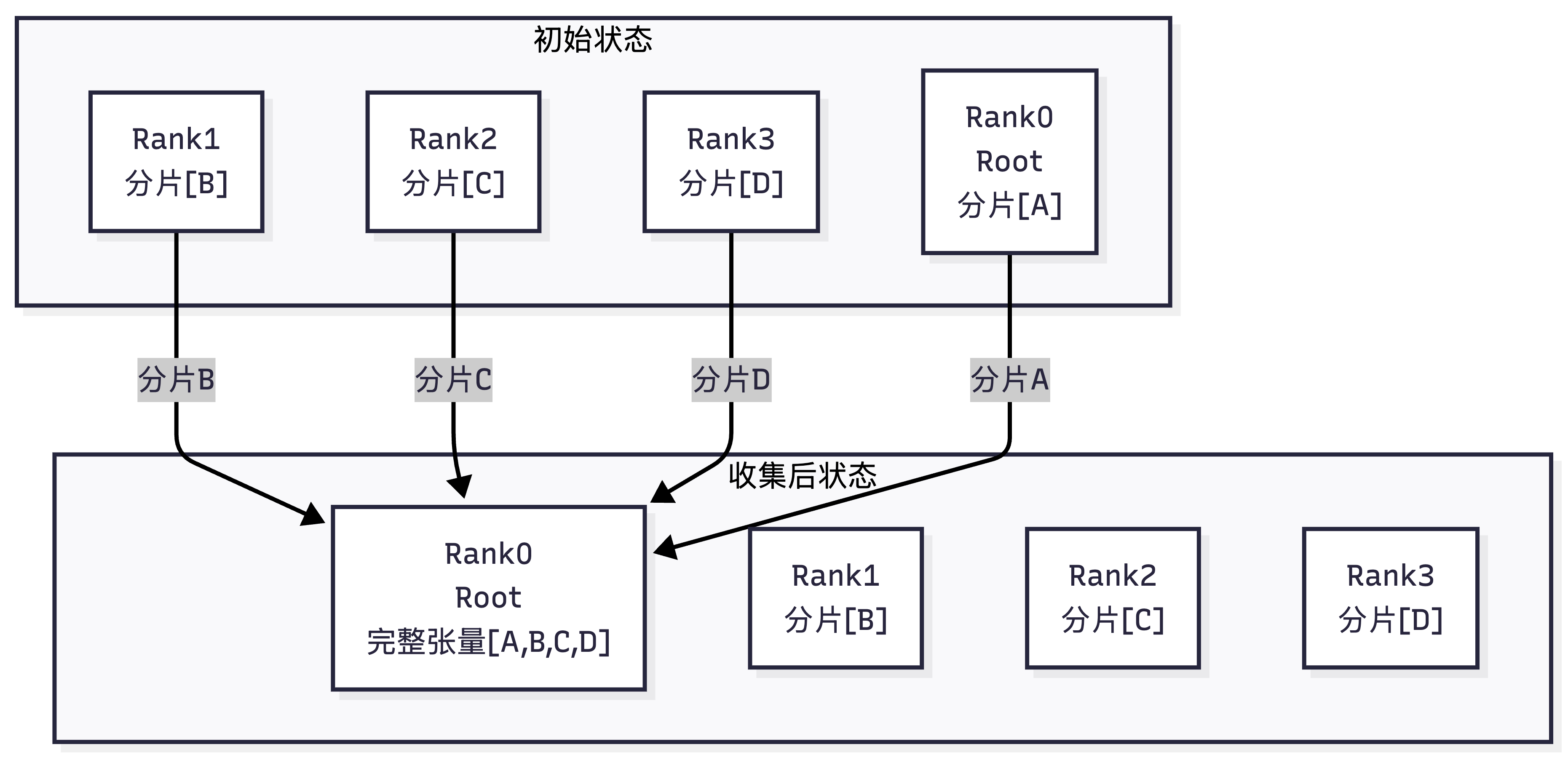
- 核心定义:Scatter的逆操作,多对一的分片收集。通信域内每个rank把自己持有的分片,发送给根节点Root Rank,root把所有分片按顺序拼接成完整的大张量。
- 直观示例(4个rank,root=0)
初始状态:
Rank0: [A0, A1, A2, A3]
Rank1: [B0, B1, B2, B3]
Rank2: [C0, C1, C2, C3]
Rank3: [D0, D1, D2, D3]
Gather后状态:
Rank0: [A0,A1,A2,A3, B0,B1,B2,B3, C0,C1,C2,C3, D0,D1,D2,D3] (root,完整拼接张量)
Rank1: [B0, B1, B2, B3] (数据不变)
Rank2: [C0, C1, C2, C3] (数据不变)
Rank3: [D0, D1, D2, D3] (数据不变)
- 核心特性:只有root拿到拼接后的完整张量,其他rank数据不变;是Scatter的逆操作。
- 大模型训练典型场景:
- 分布式推理时,把每个rank生成的文本分片,收集到root rank拼接成完整输出;
- 调试时,把每个rank的中间结果收集到root,用于可视化和问题定位。
三、大模型训练核心进阶通信原语
这是Megatron混合并行的核心。这类原语的核心特点是:全对等通信,没有root节点,通信域内所有rank都参与,最终所有rank都拿到一致的结果。
1. AllGather(全收集)
张量并行TP、序列并行SP的核心原语,解决「分片张量拼接成完整张量」的需求。
- 核心定义:Gather的全对等版本。通信域内每个rank把自己持有的分片,发送给其他所有rank,最终所有rank都拿到全部分片,拼接成完整的大张量。
- 一句话记忆:每个rank出一个分片,所有rank都拿到完整的拼接张量。
- 直观示例(4个rank,每个rank持有1个分片)
Mermaid 图见第四章节 Ring AllReduce
初始状态:
Rank0: [A0, A1, A2, A3] (分片0)
Rank1: [B0, B1, B2, B3] (分片1)
Rank2: [C0, C1, C2, C3] (分片2)
Rank3: [D0, D1, D2, D3] (分片3)
AllGather后状态:
Rank0: [A0,A1,A2,A3, B0,B1,B2,B3, C0,C1,C2,C3, D0,D1,D2,D3] (完整张量)
Rank1: [A0,A1,A2,A3, B0,B1,B2,B3, C0,C1,C2,C3, D0,D1,D2,D3]
Rank2: [A0,A1,A2,A3, B0,B1,B2,B3, C0,C1,C2,C3, D0,D1,D2,D3]
Rank3: [A0,A1,A2,A3, B0,B1,B2,B3, C0,C1,C2,C3, D0,D1,D2,D3]
-
核心特性:
- 输入:每个rank持有相同shape的分片;输出:所有rank持有相同的完整张量,shape是输入的N倍(N是rank数量);
- 是Scatter的逆操作,也是ReduceScatter的逆操作。
-
大模型训练典型场景:
- TP行并行线性层的前向传播:把输入的分片通过AllGather拼接成完整输入,再和自己的权重分片做矩阵乘法;
- TP列并行线性层的反向传播:用AllGather把输入的梯度分片拼接成完整梯度,用于计算权重梯度;
- 序列并行SP的前向传播:把序列维度的分片AllGather成完整序列,用于需要全序列信息的算子(如Attention Softmax)。
2. ReduceScatter(规约分发)
大模型通信优化、分布式优化器的核心原语,也是Ring AllReduce的核心组成部分。
- 核心定义:先做Reduce规约,再做Scatter分发。通信域内所有rank的输入数据,先按维度分片做规约,再把每个规约后的分片分发给对应的rank,最终每个rank只拿到对应维度的规约后的分片。
- 一句话记忆:先按分片规约,再把规约后的分片分发给对应rank,每个rank只拿一个分片。
- 直观示例(4个rank,规约操作SUM)
Mermaid 图见第四章节 Ring AllReduce
初始状态(每个rank的输入按4个维度分片,对应rank0~3):
Rank0输入:[A0, A1, A2, A3] → 分片0:A0, 分片1:A1, 分片2:A2, 分片3:A3
Rank1输入:[B0, B1, B2, B3] → 分片0:B0, 分片1:B1, 分片2:B2, 分片3:B3
Rank2输入:[C0, C1, C2, C3] → 分片0:C0, 分片1:C1, 分片2:C2, 分片3:C3
Rank3输入:[D0, D1, D2, D3] → 分片0:D0, 分片1:D1, 分片2:D2, 分片3:D3
ReduceScatter操作:
1. 对分片0做SUM规约:A0+B0+C0+D0 → 分发给Rank0
2. 对分片1做SUM规约:A1+B1+C1+D1 → 分发给Rank1
3. 对分片2做SUM规约:A2+B2+C2+D2 → 分发给Rank2
4. 对分片3做SUM规约:A3+B3+C3+D3 → 分发给Rank3
最终状态:
Rank0: [A0+B0+C0+D0] (仅分片0的规约结果)
Rank1: [A1+B1+C1+D1] (仅分片1的规约结果)
Rank2: [A2+B2+C2+D2] (仅分片2的规约结果)
Rank3: [A3+B3+C3+D3] (仅分片3的规约结果)
-
核心特性:
- 输入:每个rank持有相同shape的完整张量;输出:每个rank只持有一个分片的规约结果,shape是输入的1/N(N是rank数量);
- 是AllGather的逆操作,也是AllReduce的前半段。
-
大模型训练典型场景:
- 分布式优化器(ZeRO):用ReduceScatter把梯度规约后分发给每个rank,每个rank只负责更新自己的那部分参数,大幅节省显存;
- TP列并行线性层的反向传播:用ReduceScatter把权重梯度规约后分发给对应的rank,每个rank只更新自己的权重分片;
- 序列并行SP的反向传播:用ReduceScatter把激活值梯度规约后分发给TP组内的每个rank,节省显存;
- Ring AllReduce的前半段:Ring AllReduce的本质就是「先ReduceScatter,再AllGather」。
3. AllReduce(全规约)
分布式训练中最常用、最核心的通信原语,所谓的「梯度规约」,本质就是AllReduce。
- 核心定义:Reduce的全对等版本。通信域内所有rank的输入数据,按指定规约操作聚合,最终所有rank都拿到完全相同的聚合结果。
- 一句话记忆:所有rank输入数据,所有rank都拿到规约后的结果。
- 直观示例(4个rank,规约操作SUM)
Mermaid 图见第四章节 Ring AllReduce
初始状态:
Rank0: [1, 1, 1, 1]
Rank1: [2, 2, 2, 2]
Rank2: [3, 3, 3, 3]
Rank3: [4, 4, 4, 4]
AllReduce后状态(SUM):
Rank0: [10, 10, 10, 10] (1+2+3+4的聚合结果)
Rank1: [10, 10, 10, 10]
Rank2: [10, 10, 10, 10]
Rank3: [10, 10, 10, 10]
-
核心特性:
- 所有rank输入相同shape的张量,输出相同shape、相同数值的张量;
- 底层默认用Ring AllReduce算法,把通信负载均匀分散到所有rank,带宽利用率远高于「先Reduce到root再Broadcast」的传统实现。
-
大模型训练典型场景:
- 数据并行DP/DDP:反向传播后,DP组内所有rank用AllReduce对梯度求和/求平均,保证所有rank的梯度完全一致,这就是DDP的核心功能;
- 张量并行TP:MLP行并行层的前向传播,用AllReduce对TP组内两张卡的输出求和,得到完整的输出张量;
- 序列并行SP:LayerNorm的反向传播,用AllReduce对TP组内的梯度求和,保证未切分参数的梯度一致,对应 Megatron 代码里的
finalize_model_grads。
4. Send/Recv(点对点P2P通信)
流水线并行PP的核心原语,实现Stage之间的定向数据传输。
- 核心定义:两个rank之间一对一的定向通信,一个rank(发送方)执行Send发送数据,另一个rank(接收方)执行Recv接收数据,是最基础的通信原语。
- 两种核心模式:
- 阻塞模式:Send必须等Recv收到数据才返回,Recv必须等Send发数据才返回,同步通信,逻辑简单但容易闲置硬件;
- 非阻塞模式:Send/Recv立刻返回,后台异步执行通信,后续再等待同步,Megatron的PP流水线用的就是这种模式,实现通信和计算重叠。
- 直观示例(Rank0发送给Rank1)
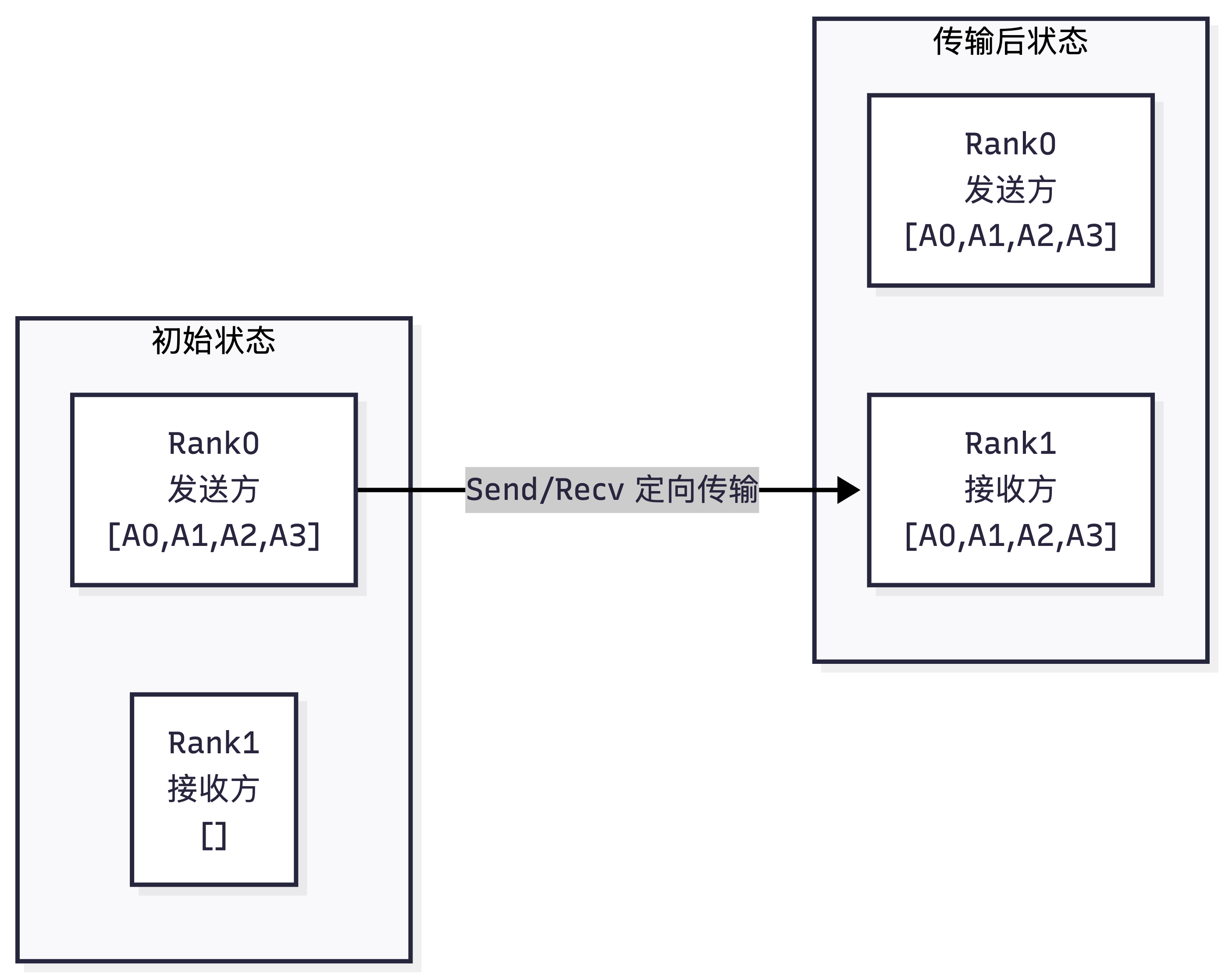
初始状态:
Rank0: [A0, A1, A2, A3]
Rank1: []
Send/Recv后状态:
Rank0: [A0, A1, A2, A3]
Rank1: [A0, A1, A2, A3]
- 核心特性:只有两个rank参与,定向传输,不影响通信域内其他rank。
- 大模型训练典型场景:
- 流水线并行PP:Stage之间的激活值和梯度传递。前向时前一个Stage把激活值Send给后一个Stage,后一个Stage用Recv接收;反向时后一个Stage把梯度Send给前一个Stage,前一个Stage用Recv接收,对应PP拓扑里的Stage间通信;
- 多机训练时,不同节点之间的定向数据传输。
5. AllToAll(全交换)
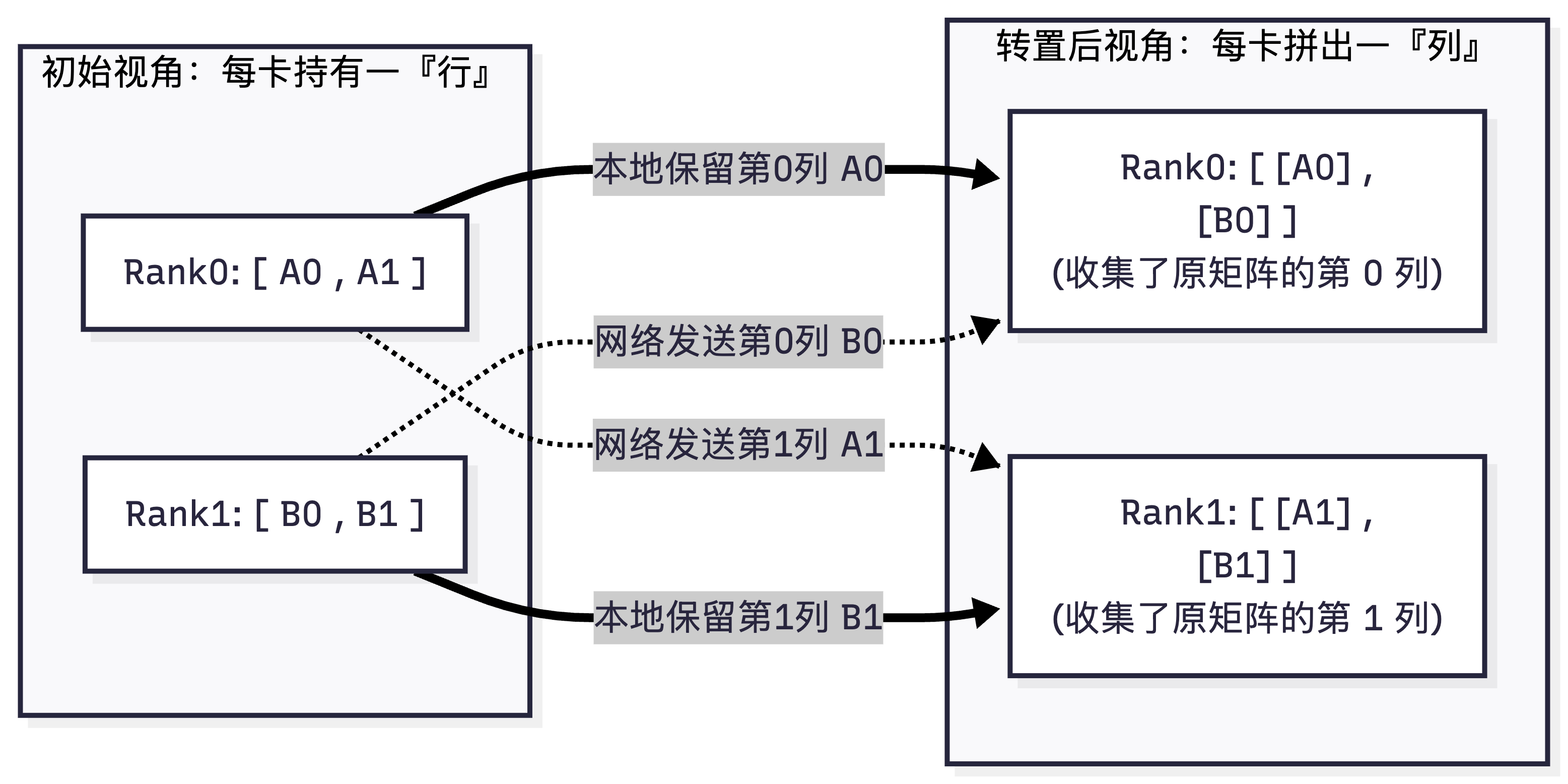
MoE混合专家模型、长序列并行的核心原语,是最复杂的集体通信原语。
- 核心定义:通信域内每个rank,把自己的输入张量按rank数量切成分片,把第i个分片发送给第i个rank;同时接收所有其他rank发来的对应分片,最终拼接成输出张量。
- 一句话记忆:每个rank给其他所有rank发一个分片,同时接收所有rank发来的分片,最终拼接成结果。
- 直观示例(2个rank)
初始状态:
Rank0: [A0, A1] (分片0:A0留给自己,分片1:A1发给Rank1)
Rank1: [B0, B1] (分片0:B0发给Rank0,分片1:B1留给自己)
AllToAll后状态:
Rank0: [[A0],
[B0]]
Rank1: [[A1],
[B1]]
- 大模型训练典型场景:
- MoE混合专家模型:每个rank把token分发给对应的专家所在的rank,用AllToAll实现全交换;
- 长序列并行(ULysses/DeepSpeed-Ulysses):长文本训练时,用AllToAll实现序列维度的全并行;
- 多机张量并行时,跨节点的张量分片交换。
四、Ring AllReduce 原理
这里要讲最关键的底层逻辑:AllReduce = ReduceScatter + AllGather,这是Ring AllReduce的核心,也是大模型通信优化的基石。
为什么要拆分成两个阶段?
传统的AllReduce实现是「先Reduce到root,再Broadcast给所有rank」,这种方式的瓶颈是root rank的带宽,rank越多,通信效率越低。
而Ring AllReduce把AllReduce拆成ReduceScatter和AllGather两个阶段,把通信负载均匀分散到所有rank,带宽利用率能达到100%,且和rank数量无关,是目前工业界的标准实现。
底层实现:Ring AllReduce 两阶段详解
前置核心前提
- 环形拓扑:Rank0 连 Rank1,Rank1 连 Rank2,Rank2 连 Rank3,Rank3 连回 Rank0,形成闭合环,无中心节点。
- 数据分片:将完整张量沿维度切分成与 Rank 数量相等的
N个小分片(4 个 Rank 切 4 个分片,记为Chunk0~Chunk3)。 - 两个核心阶段:
- 第一阶段:Scatter-Reduce(规约分发):每个 Rank 只负责规约自己的 “目标分片”,通过环形传输聚合所有 Rank 的对应分片,最终每个 Rank 仅持有一个完整规约后的分片。
- 第二阶段:AllGather(全收集):每个 Rank 将自己持有的规约后分片传给其他所有 Rank,最终每个 Rank 都拿到所有分片。
逐时间步具象演示(4 个 Rank,SUM 规约)
前置配置
-
初始数据(每个 Rank 的梯度分片):
- Rank0:
[A0, A1, A2, A3](Chunk0=A0, Chunk1=A1, Chunk2=A2, Chunk3=A3) - Rank1:
[B0, B1, B2, B3](Chunk0=B0, Chunk1=B1, Chunk2=B2, Chunk3=B3) - Rank2:
[C0, C1, C2, C3](Chunk0=C0, Chunk1=C1, Chunk2=C2, Chunk3=C3) - Rank3:
[D0, D1, D2, D3](Chunk0=D0, Chunk1=D1, Chunk2=D2, Chunk3=D3)
- Rank0:
-
目标:每个 Rank 最终拿到
[A0+B0+C0+D0, A1+B1+C1+D1, A2+B2+C2+D2, A3+B3+C3+D3]
第一阶段:Scatter-Reduce(规约分发)
规则:
- 每个 Rank 的 “目标分片” 与自己编号相同(Rank0 目标 Chunk0,Rank1 目标 Chunk1…)。
- 数据沿环形顺时针传输:Rank0→Rank1,Rank1→Rank2,Rank2→Rank3,Rank3→Rank0。
- 每个时间步同时做 3 件事:
- 发送:将自己上一时间步刚刚更新完的分片(第1步则是固定的初始分片)发给下一 Rank。
- 接收:接收来自上一 Rank 传出的分片。
- 规约:将接收到的分片,与自己本地对应的分片(而非目标分片)进行 SUM 规约。
=====================================================================
【第一阶段:Scatter-Reduce 逐时间步演示】
=====================================================================
初始状态(时间步0前):
Rank0: [A0, A1, A2, A3] 目标Chunk0
Rank1: [B0, B1, B2, B3] 目标Chunk1
Rank2: [C0, C1, C2, C3] 目标Chunk2
Rank3: [D0, D1, D2, D3] 目标Chunk3
环形拓扑:Rank0 ↔ Rank1 ↔ Rank2 ↔ Rank3 ↔ Rank0
─────────────────────────────────────────────────────────────────────
时间步1(每个节点向右发送目标Chunk的前一个Chunk):
- Rank0收D2,发A3;Chunk2 = A2 + D2
- Rank1收A3,发B0;Chunk3 = B3 + A3
- Rank2收B0,发C1;Chunk0 = C0 + B0
- Rank3收C1,发D2;Chunk1 = D1 + C1
状态:
Rank0: [A0, A1, A2+D2, A3]
Rank1: [B0, B1, B2, B3+A3]
Rank2: [C0+B0, C1, C2, C3]
Rank3: [D0, D1+C1, D2, D3]
─────────────────────────────────────────────────────────────────────
时间步2(每个节点发送上一步刚刚更新的Chunk):
- Rank0收D1+C1,发A2+D2;Chunk1 = A1 + D1 + C1
- Rank1收A2+D2,发B3+A3;Chunk2 = B2 + A2 + D2
- Rank2收B3+A3,发C0+B0;Chunk3 = C3 + B3 + A3
- Rank3收C0+B0,发D1+C1;Chunk0 = D0 + C0 + B0
状态:
Rank0: [A0, A1+D1+C1, A2+D2, A3]
Rank1: [B0, B1, B2+A2+D2, B3+A3]
Rank2: [C0+B0, C1, C2, C3+B3+A3]
Rank3: [D0+C0+B0, D1+C1, D2, D3]
─────────────────────────────────────────────────────────────────────
时间步3(Scatter-Reduce完成,发送上一步更新的Chunk,补齐最后一块拼图):
- Rank0收D0+C0+B0,发A1+D1+C1;Chunk0 = A0 + D0 + C0 + B0(完整规约)
- Rank1收A1+D1+C1,发B2+A2+D2;Chunk1 = B1 + A1 + D1 + C1(完整规约)
- Rank2收B2+A2+D2,发C3+B3+A3;Chunk2 = C2 + B2 + A2 + D2(完整规约)
- Rank3收C3+B3+A3,发D0+C0+B0;Chunk3 = D3 + C3 + B3 + A3(完整规约)
【Scatter-Reduce最终状态】:
Rank0: [S0, ?, ?, ?] (S0 = A0+B0+C0+D0,仅持有S0)
Rank1: [?, S1, ?, ?] (S1 = A1+B1+C1+D1,仅持有S1)
Rank2: [?, ?, S2, ?] (S2 = A2+B2+C2+D2,仅持有S2)
Rank3: [?, ?, ?, S3] (S3 = A3+B3+C3+D3,仅持有S3)
第二阶段:AllGather(全收集)
规则:
- 数据沿环形顺时针传输。
- 每个时间步同时做 3 件事:
- 发送:将自己刚刚获取的完整分片(第1步是自己算完的目标分片,后续步骤是上一步刚收到的分片)发给下一 Rank。
- 接收并存储:接收上一 Rank 传来的完整分片,并直接覆盖/存储到本地对应的 Chunk 位置。
- 无规约:不做任何计算,只做搬运。
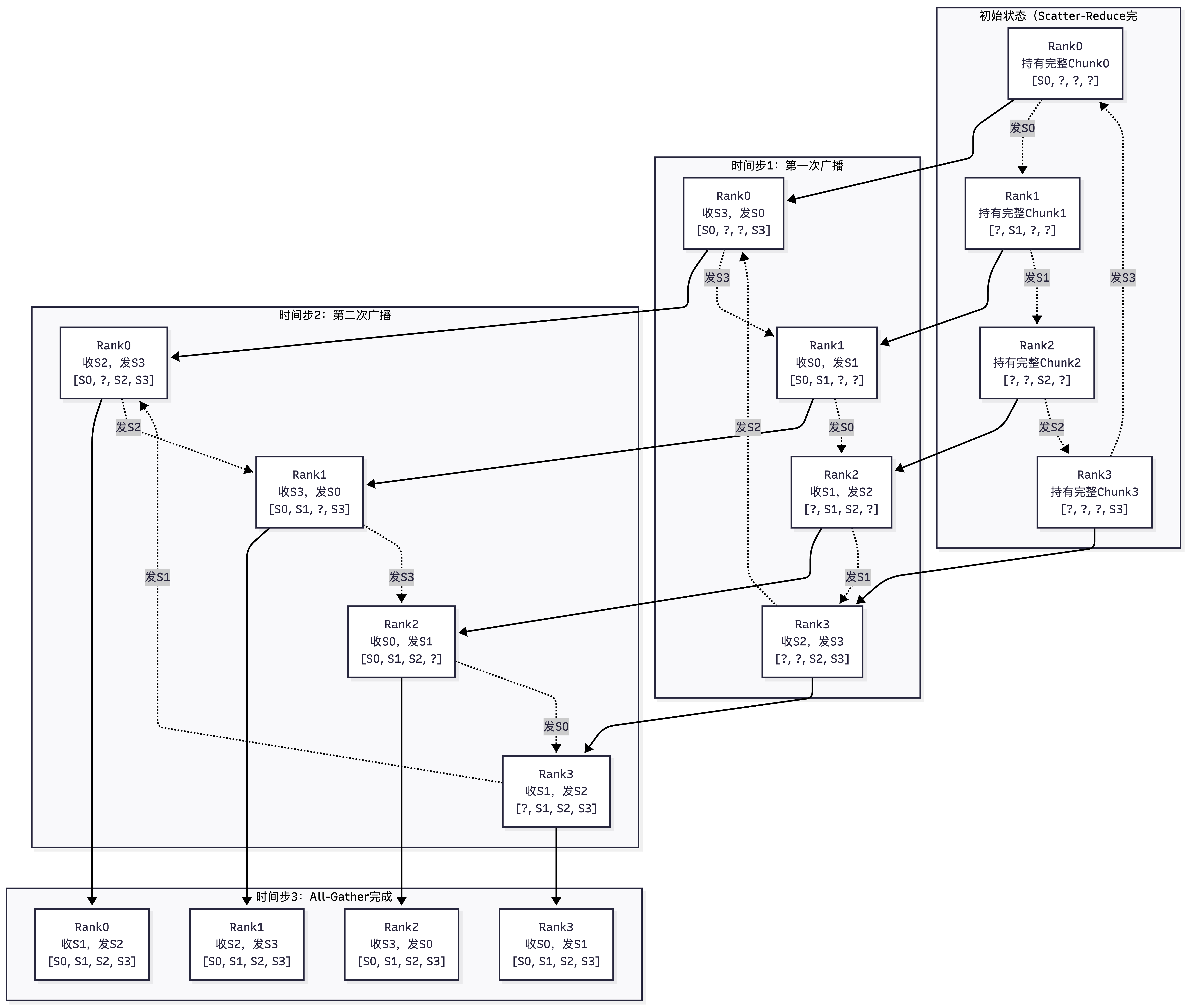
=====================================================================
【第二阶段:AllGather 逐时间步演示】
=====================================================================
【AllGather初始状态(承接第一阶段)】:
Rank0: [S0, ?, ?, ?]
Rank1: [?, S1, ?, ?]
Rank2: [?, ?, S2, ?]
Rank3: [?, ?, ?, S3]
─────────────────────────────────────────────────────────────────────
时间步1:
- Rank0收S3,发S0;存储S3
- Rank1收S0,发S1;存储S0
- Rank2收S1,发S2;存储S1
- Rank3收S2,发S3;存储S2
状态:
Rank0: [S0, ?, ?, S3]
Rank1: [S0, S1, ?, ?]
Rank2: [?, S1, S2, ?]
Rank3: [?, ?, S2, S3]
─────────────────────────────────────────────────────────────────────
时间步2:
- Rank0收S2,发S3;存储S2
- Rank1收S3,发S0;存储S3
- Rank2收S0,发S1;存储S0
- Rank3收S1,发S2;存储S1
状态:
Rank0: [S0, ?, S2, S3]
Rank1: [S0, S1, ?, S3]
Rank2: [S0, S1, S2, ?]
Rank3: [?, S1, S2, S3]
─────────────────────────────────────────────────────────────────────
时间步3(AllGather完成,所有Rank拿到所有分片):
- Rank0收S1,发S2;存储S1
- Rank1收S2,发S3;存储S2
- Rank2收S3,发S0;存储S3
- Rank3收S0,发S1;存储S0
【AllGather最终状态】:
Rank0: [S0, S1, S2, S3] = [A0+B0+C0+D0, A1+B1+C1+D1, A2+B2+C2+D2, A3+B3+C3+D3]
Rank1: [S0, S1, S2, S3] = [A0+B0+C0+D0, A1+B1+C1+D1, A2+B2+C2+D2, A3+B3+C3+D3]
Rank2: [S0, S1, S2, S3] = [A0+B0+C0+D0, A1+B1+C1+D1, A2+B2+C2+D2, A3+B3+C3+D3]
Rank3: [S0, S1, S2, S3] = [A0+B0+C0+D0, A1+B1+C1+D1, A2+B2+C2+D2, A3+B3+C3+D3]
大模型中的应用
Megatron、DeepSpeed中的很多显存优化,都基于这个拆分:比如梯度规约时,先做ReduceScatter把梯度分发给每个rank,每个rank只存自己的那部分梯度,再做AllGather,能大幅节省显存,这就是ZeRO分布式优化器的核心原理。
五、关于 AllToAll 与 AllGather 的思辨
从维度变换与通信复杂度的视角来看,AllToAll 与 AllGather 在序列并行(Sequence Parallelism)中扮演着截然不同的角色:
1. 维度视角:转置 vs. 拼接
- AllToAll(分布式转置):
- 假设有两个正交的维度 D1D_1D1 和 D2D_2D2。初始时,Rank 在 D1D_1D1 维度上持有 P×S1P \times S_1P×S1 数据,而在 D2D_2D2 维度上只有切片 S2S_2S2。通信结束后,Rank 在 D1D_1D1 维度上缩小为 S1S_1S1,但在 D2D_2D2 维度上拼接成了 P×S2P \times S_2P×S2。从某种意义上来说,有点类似于转置的操作。
- 映射到 DeepSpeed-Ulysses:在 Attention 计算前,节点在 Attention Head 维度上持有全部的
nheads,但在 Sequence 维度上只有局部的seq/P。通过 AllToAll,Head 维度被切分为nheads/P,而 Sequence 维度被拼接为完整的seq。这本质上是在 Sequence 和 Head 维度之间完成了一次分布式矩阵转置。 - AllGather(全量收集):
- 初始时,Rank 在目标维度上仅持有切片 SSS。通信结束后,该维度被补全为 P×SP \times SP×S,其他维度的大小保持不变。这是一种纯粹的维度扩展与拼接。
2. 通信复杂度视角:O(M/P)O(M/P)O(M/P) vs. O(M)O(M)O(M)
设 MMM 为全局完整序列的激活值总数据量,每个 Rank 初始分配到的本地数据量均为 M/PM/PM/P。
- Megatron-SP (AllGather + Reduce-Scatter):
- 为了做完整的 Attention,每个 Rank 必须通过 AllGather 收集全局的 Sequence。其单卡发送(Send)的数据量为 P−1P×M≈M\frac{P-1}{P} \times M \approx MPP−1×M≈M。因此,通信复杂度为 O(M)O(M)O(M),即消息总量 MMM 并没有被网络带宽稀释。
- DeepSpeed-Ulysses (AllToAll):
- 由于采用了“转置”逻辑,每个 Rank 只需将本地的 M/PM/PM/P 数据均分成 PPP 份,并将其中的 P−1P-1P−1 份发送给其他节点。其单卡发送的数据量为 P−1P×MP≈MP\frac{P-1}{P} \times \frac{M}{P} \approx \frac{M}{P}PP−1×PM≈PM。因此,通信复杂度降维至 O(M/P)O(M/P)O(M/P)。这意味着随着 GPU 数量 PPP 的增加,单卡的通信负担不仅没有加重,反而被 PPP 条链路“均分”了。
补充一点延伸思考:
虽然 Ulysses 凭借 O(M/P)O(M/P)O(M/P) 在大集群长文本上占据优势,但 AllToAll 操作是一个典型的密集型全互联通信(每个节点都要同时和所有其他节点建立连接)。这意味着它非常吃集群的网络拓扑结构和小包延迟。如果在跨机(跨交换机)的网络下,AllToAll 容易引发网络拥塞(Incast),这也是为什么实际工程中 Ulysses 往往受限于单机内的 NVLink 数量(通常 P≤8P \le 8P≤8),如果要突破单机,常常需要结合 Megatron-SP 做混合并行(Ring-Attention 也是类似的考量)。
六、Megatron混合并行中的原语落地对照表
把常用的TP/PP/DP/SP,和通信原语一一对应,彻底串起整个知识体系:
| 并行策略 | 核心通信原语 | 具体使用场景 |
|---|---|---|
| 数据并行DP/DDP | AllReduce | 反向传播后,DP组内所有rank用AllReduce规约梯度,保证参数一致 |
| 张量并行TP(列并行) | AllReduce | 前向传播结束后,TP组内用AllReduce对输出求和 |
| 张量并行TP(行并行) | AllGather | 前向传播开始时,TP组内用AllGather拼接输入张量 |
| 张量并行TP(列并行反向) | ReduceScatter | 反向传播时,用ReduceScatter分发规约后的权重梯度 |
| 流水线并行PP | Send/Recv | Stage之间的激活值(前向)和梯度(反向)的点对点传输 |
| 序列并行SP | ReduceScatter + AllGather | 前向用AllGather拼接序列,反向用ReduceScatter分发梯度 |
| 分布式检查点 | AllGather | 加载检查点时,用AllGather拼接分片的权重张量 |
| Loss/指标打印 | Reduce | 把所有rank的loss规约到root rank,用于日志输出 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)