论大模型应用架构(RAG/Agent)的设计与应用——以自动驾驶数据闭环平台为例
本文介绍了基于RAG和Agent技术构建的新一代自动驾驶数据闭环平台。该平台通过多模态向量数据库实现自然语言检索PB级驾驶数据,利用智能体集群自动化完成数据清洗、标注和仿真场景生成。关键技术包括CLIP+VectorDB+LLM检索架构、基于ReAct范式的标注流水线以及仿真场景生成Agent。系统显著提升了CornerCase挖掘效率(500%提升)和自动标注准确率(达95%),大幅降低了人工成
【摘要】
2025年5月,我有幸作为核心系统架构师,主持了某新能源车企“新一代自动驾驶数据闭环平台”的重构与升级工作。该平台旨在解决海量路测数据中长尾场景(Corner Case)挖掘难、数据标注效率低以及仿真场景生成成本高等核心痛点。鉴于传统深度学习模型在复杂语义理解和逻辑推理上的局限性,我们构建了一套基于 RAG(检索增强生成) 与 Agent(智能体) 协同的 AI 原生数据闭环架构。
本文以该项目为例,论述了大模型应用架构的设计。首先,通过构建多模态向量数据库与语义索引,利用 RAG 技术实现了对 PB 级驾驶数据的自然语言检索与长尾场景挖掘;其次,基于 ReAct 范式设计了数据处理 Agent 集群,利用工具调用(Function Calling)实现了从数据清洗、自动标注到仿真场景重建的全流程自动化;最后,采用了私有化部署的 LLM(大语言模型) 与 VLM(视觉语言模型) 协同工作,配合推理加速技术,在保障数据安全的同时提升了闭环效率。系统上线后,Corner Case 挖掘效率提升 500%,自动标注准确率达到 95%,显著加速了自动驾驶算法的迭代周期。
【正文】
一、 项目背景与主要职责
随着公司 L3 级自动驾驶功能的量产落地,车队每天回传的数据量达到 PB 级别。然而,原有的数据处理链路面临巨大挑战:
-
场景挖掘难: 传统基于标签(Tag)的搜索无法处理复杂语义。例如,工程师想找“下雨天,前方有穿着雨衣的骑行者突然横穿马路”的场景,传统 SQL 或标签检索束手无策。
-
标注效率低: 依靠人工标注海量数据,成本高且周期长,无法满足模型快速迭代的需求。
-
工具链割裂: 数据挖掘、标注、仿真等环节由不同工具组成,缺乏统一的智能调度中枢。
为了解决上述问题,公司决定引入大模型技术重构数据闭环。作为架构师,我负责整体技术架构设计与核心模块落地。我制定了从“标签检索”向“语义检索 + 智能体编排”转型的技术路线,确立了以 RAG 为知识引擎、Agent 为自动化执行引擎的架构体系。
二、 RAG 与 Agent 架构的核心设计思想
在自动驾驶数据闭环中,我们将大模型定义为“驾驶脑”,RAG 是“驾驶记忆(海量场景库)”,Agent 是“数据工兵(自动化工具)”。
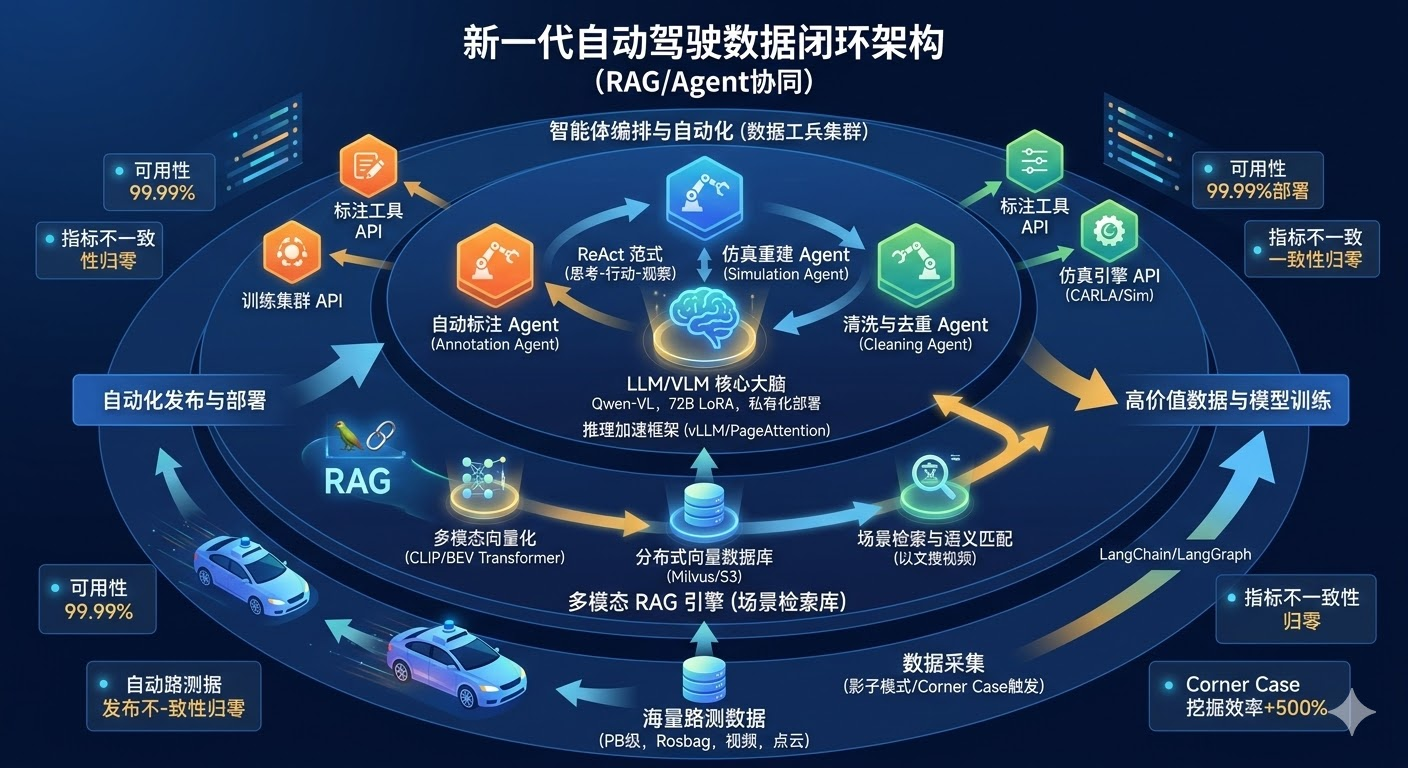
1. RAG(检索增强生成):解决“语义理解”与“场景定位” 在自动驾驶领域,RAG 不仅是检索文本,更是检索多模态数据(Video/Image/Lidar)。
-
核心思想: 将海量路测视频片段转化为多模态向量(Embeddings)存入向量数据库。当用户用自然语言描述场景时,系统先检索出最相似的视频片段,将其作为上下文(Context)输入给 VLM(视觉语言模型),让模型判断该片段是否符合需求,从而实现“以文搜图/视频”。
2. Agent(智能体):解决“工具链编排”与“复杂任务自动化” 数据闭环涉及数据清洗、自动标注、仿真生成等多个步骤。
-
核心思想: 我们基于 ReAct (Reason + Act) 范式构建 Agent。面对“找出所有闯红灯场景并生成仿真测试用例”的任务,Agent 会先思考(Thought),拆解为“检索场景 -> 调用标注工具 -> 调用仿真转换工具”三个步骤,并依次调用对应的 API(Action),最终完成任务。
三、 关键技术实施与落地
在项目中,我重点主导了以下三个关键技术模块的设计与实现:
1. 多模态 RAG 场景挖掘系统
为了让工程师能用自然语言“对话式”挖掘数据,我设计了**“CLIP + Vector DB + LLM”**的检索架构。
-
多模态向量化: 利用 CLIP 模型及其变体,将车端回传的视频关键帧(Key Frame)和激光雷达点云投影图转化为高维向量,存储在 Milvus 分布式向量数据库中。
-
语义对齐与检索: 当工程师输入“高速公路施工区域,锥桶摆放不规范”时,Query 被转化为向量,在 Milvus 中进行近似最近邻搜索(ANN)。
-
LLM 增强校验: 向量检索只能保证“相似”,不能保证“精准”。检索出的 Top 50 候选片段,会被送入私有化部署的 Qwen-VL(视觉大模型) 进行二次校验。模型会逐帧分析视频,确认是否存在“不规范锥桶”,最终返回精准的 Top 10 结果。这一设计将复杂长尾场景的挖掘准确率从 60% 提升到了 95%。
2. 基于 Agent 的自动化数据标注流水线
标注是数据闭环中最耗时的环节。我设计了一个 Annotation Agent(标注智能体) 来接管这一工作。
-
工具调用(Function Calling): 我们将现有的 2D 检测算法、3D 点云分割算法、车道线识别算法封装为 Agent 可调用的 Tools。
-
ReAct 编排: 当 Agent 接收到一段数据时,它会首先调用“初筛工具”判断数据价值;确认有价值后,调用“自动标注模型(Auto-Labeling Model)”生成预标注结果。
-
自我反思(Self-Reflection): Agent 会调用 VLM 模型对预标注结果进行“视觉查验”。例如,VLM 发现标注框漏掉了一个被遮挡的行人,Agent 会自动调用“微调工具”修正标注框,或者将该帧标记为“疑难帧”发送给人工复核。这种“AI 标注 + AI 质检”的模式,将人工介入率降低了 80%。
3. 仿真场景生成 Agent
为了将挖掘出的 Corner Case 快速转化为仿真测试用例,我设计了 Simulation Agent。
-
场景参数化: Agent 读取 RAG 检索到的真实事故视频,提取出关键要素(天气:雨天,障碍物:行人,速度:40km/h,轨迹:横穿)。
-
OpenSCENARIO 生成: 利用 LLM 强大的代码生成能力,Agent 将上述自然语言描述转化为标准的 OpenSCENARIO 格式代码(XML)。
-
虚实结合: Agent 调用仿真引擎(如 CARLA 或自研 Sim),加载生成的场景代码,自动运行数十次变异测试(如改变天气、微调行人速度),从而在虚拟世界中通过一次真实事故泛化出成千上万个测试用例。
四、 遇到的挑战与解决方案
挑战一:多模态数据的时空对齐 自动驾驶数据包含 6 路摄像头、Lidar、Radar 等,时间戳对齐困难,导致 RAG 检索时图像与点云不匹配。
解决方案: 引入 BEV(鸟瞰图) 表征。在向量化之前,先通过 Transformer 将多模态数据投影到统一的 BEV 空间,将“多路数据”融合为“一个场景特征”,再进行 Embedding 存储。这不仅解决了对齐问题,还提升了空间检索的准确度。
挑战二:私有化大模型的推理延迟 VLM 模型(如 Qwen-VL-Chat)参数量大,处理视频帧速度慢,影响数据挖掘效率。
解决方案: 采用 vLLM 框架进行推理加速,并实施 KV Cache 量化(INT8)。同时,设计了“关键帧策略”:Agent 先分析视频的运动变化率,只对变化剧烈的关键帧调用大模型,静止或匀速片段跳过。这使得处理一分钟视频的耗时从 50 秒降低至 5 秒。
【结束语】
通过构建基于 RAG + Agent 的 AI 原生数据闭环平台,我们成功将“大模型”变成了自动驾驶迭代的“加速器”。系统上线后,工程师挖掘一个复杂 Corner Case 的时间从 3 天缩短至 10 分钟,自动标注的引入节省了每年数千万的外包成本。
这次实践让我深刻体会到,在自动驾驶领域,大模型不仅仅是车端的感知算法,更是云端数据工厂的核心引擎。架构师的职责在于设计高效的“数据流转机制”,让 RAG 成为连接海量数据与场景的桥梁,让 Agent 成为连接工具与任务的双手。未来,我计划探索 World Model(世界模型) 在数据闭环中的应用,让 Agent 具备预测未来的能力,进一步提升仿真的真实性。
记忆图谱(考场速记版 - 自动驾驶版)
-
底层(数据层 - 多模态 RAG):
-
关键词: 多模态向量 (CLIP/BEV)、Milvus、语义检索 (Text-to-Video)。
-
作用: 用自然语言搜出 Corner Case(长尾场景),解决“大海捞针”难题。
-
-
中层(逻辑层 - Agent 编排):
-
关键词: ReAct 范式、Annotation Agent (自动标注)、Simulation Agent (场景重建)。
-
作用: 自动调用工具做清洗、标注、仿真,替代人工流水线。
-
-
顶层(服务层 - 效能保障):
-
关键词: VLM (视觉大模型)、vLLM 加速、OpenSCENARIO 生成。
-
作用: 这是一个“AI 标注员”和“AI 仿真工程师”,又快又准。
-
金句(背诵):
-
“RAG 将海量路测数据变成了可对话的‘场景知识库’。”
-
“Agent 将繁琐的数据处理工具链串联成了自动化的‘智能流水线’。”
-
“大模型在云端重构了自动驾驶的数据闭环,实现了从‘人工驱动’到‘数据驱动’的质变。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)