Gemini 3.1 Pro技术深度评测:推理能力翻倍背后的架构精进与工程突围
Gemini 3.1 Pro的升级逻辑清晰:不追求单项指标的惊艳,而是在可控成本下系统性地提升模型的可用性和可靠性。100万token上下文、64,000 token输出上限、三层思考模式、并行推理架构、多模态引擎原生整合——这些技术要素共同构成了一个更接近生产环境要求的模型形态。对于国内开发者而言,若想直接体验Gemini 3.1 Pro的推理能力与代码生成表现,可通过聚合平台RskAi(ai.
2026年2月19日,Google DeepMind发布Gemini 3.1 Pro。这是Gemini系列首次采用“.1”作为版本增量——从Gemini 1.0到1.5、2.0到2.5、3.0到3.5的0.5跨度惯例被打破,直接释放的信号是:AI竞赛已进入以周为单位的迭代周期,单次“小版本”更新的技术含量,足以抵得上竞品一次大版本重构。
如果你想体验国外顶级大模型(如Gemini 3.1 Pro、GPT-5.4、Claude 4.6),且希望国内直接访问,可以试试聚合镜像平台RskAi(ai.rsk.cn)。
本文将从模型架构、推理机制、多模态能力、代码智能、上下文理解、幻觉控制、定价策略七个维度,对Gemini 3.1 Pro进行技术向拆解。
一、推理能力的代际跃升:ARC-AGI-2翻倍背后的技术动因
1.1 核心基准测试表现
在衡量模型解决全新逻辑模式能力的ARC-AGI-2基准测试中,Gemini 3.1 Pro拿下77.1%的验证得分。这一数据的参照系是:
Gemini 3 Pro:31.1%
Claude Opus 4.6:68.8%
GPT-5.2:未公布但显著低于前者
超过一倍的性能提升,即便剔除可能的“数据污染”因素,其底层推理能力的精进也是实质性的。在另一项高难度测试“人类最后考试”(Humanity's Last Exam,HLE)中,Gemini 3.1 Pro在不借助外部工具的情况下取得44.4%的成绩,领先于Claude Opus 4.6的40.0%和GPT-5.2的34.5%。
1.2 Deep Think技术的“下放”与并行思考架构
此次推理能力跃升的技术基础,直接继承自上周发布的Gemini 3 Deep Think更新。Deep Think引入的“并行思考技术”被整合进基础模型——模型能够同时探索多条解题路径,通过内部评估机制筛选最优解,而非单链顺序推理。
这种架构设计在处理需要多步骤拆解的复杂问题时优势明显。以ML研究基准RE-Bench为例,Gemini 3.1 Pro(尤其是Deep Think模式下)取得1.27的人类标准化平均得分,显著高于Gemini 3 Pro的1.04;在优化LLM微调脚本的特定挑战中,模型将运行时间从300秒压缩至47秒,而人类参考解决方案需94秒。
二、模型架构演进:从MoE到三层思考模式的工程化设计
2.1 MoE架构延续与计算-质量-成本的显式权衡
Gemini 3.1 Pro延续了MoE(混合专家)架构路线,100万token上下文窗口和64,000 token输出上限维持不变。真正值得关注的工程创新是三层思考模式(Low/Medium/High)的引入。
这一设计本质上是对“计算-质量-成本”三角关系的显式化管理:
Low模式:追求响应速度,适合高并发、简单问答场景
Medium模式:填补此前空白,为日常复杂任务提供经济选项
High模式:调用完整推理能力,处理需要数分钟深度思考的任务
这种粒度控制让用户能够根据任务难度主动权衡成本,而非被动接受统一计价——这是模型进入生产环境后的成熟度思维体现。
2.2 技术栈的横向打通
原本用于Flash模型的强化学习技术被迁移至Pro版本,Deep Think的并行思考能力被整合进基础模型。这种技术栈的横向打通,比单纯的参数堆叠更具工程价值。参与研发的清华校友姚顺宇在X平台表示:“Gemini不仅仅是一个好模型,更好的模型正在以不可阻挡之势到来”。
三、多模态能力的原生整合:从插件到引擎
3.1 视觉引擎重构:Nano Banana的文本渲染突破
Gemini 3.1 Pro将底层的图像工具替换为Nano Banana模型,改变了图像交互的变量关系。关键差异体现在:
高保真文本渲染:在生成的图像中准确渲染指定的拼写文字(如指示牌、海报上的特定字母),大幅降低前代模型常见的“乱码字母”现象
多图组合与局部重绘:支持通过多轮对话进行迭代修改,允许组合多张图片或进行风格迁移
3.2 原生视频生成:Veo架构整合
Gemini 3.1 Pro接入了Google的Veo视频生成模型,不再依赖低帧率的GIF生成。技术特性包括:
原生音频同步:生成视频画面的同时,根据文本提示生成匹配的原生环境音
关键帧控制:支持限定视频内容的起始帧与结束帧,或输入参考图像引导视频走向
受限于算力消耗,视频生成当前施加了每日3次的调用限制。
3.3 音频链路独立:Lyria 3引擎
集成Lyria 3多模态音乐大模型,支持文本到音乐、图像/视频到听觉变量的跨模态映射。输出规格为30秒高保真音轨,声波频谱中强制嵌入SynthID水印,实现不可篡改的溯源。
四、代码智能与智能体能力:工程级应用的落地验证
4.1 基准测试的断层领先
在代码与AI智能体相关评测中,Gemini 3.1 Pro呈现断层式优势:
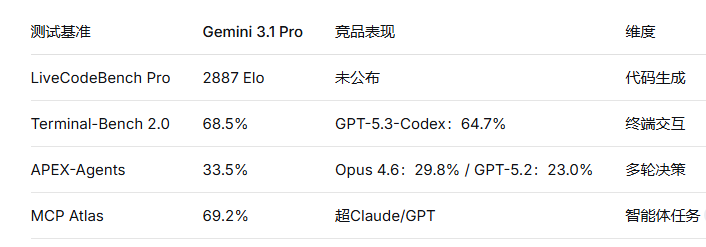
在Artificial Analysis的综合评测中,Gemini 3.1 Pro以57分居智能维度首位,编码能力56分同样排名第一。
4.2 实测案例:从SVG到复杂系统
开发者社区的实测验证了基准分数的现实意义:
SVG生成:从“鹈鹕骑自行车”的SVG动画到《呼啸山庄》主题个人网站,模型不仅完成代码编写,还能理解文学氛围并转化为视觉语言
复杂系统整合:直接接入公开遥测数据流,构建国际空间站实时轨道追踪器;生成3D椋鸟群飞模拟,支持手势追踪交互与动态配乐
工程级原型:生成3D机械级汽车悬架系统模拟器,包含真实几何结构、连杆约束与实时转向计算
这些案例的共同特征是:输出为完整可运行的系统,而非代码片段或伪代码。
五、上下文理解与幻觉控制:从“知道”到“知道不知道”
5.1 长上下文保持能力
Gemini 3.1 Pro维持100万token上下文窗口,在MRCR v2的128k长上下文测试中取得84.9%的高分;在1M token级别测试中取得26.3%,而GPT-5.2和Opus 4.6在此级别显示“不支持”。
5.2 幻觉控制的实质性突破
AA-Omniscience Index(衡量模型对自身知识边界认知能力的指标)从Gemini 3 Pro的13分跃升至30分,在主流模型中排名第一。Claude Opus 4.6此项得分为11。
这一指标的现实意义在于:大模型从“玩具”走向“工具”的过程中,知道“我不知道”往往比强行生成一个似是而非的答案更重要。在涉及金融分析、法律咨询、医疗建议等风险敏感场景时,这一能力直接决定了模型的可落地性。
结语:技术长跑的节点信号
Gemini 3.1 Pro的升级逻辑清晰:不追求单项指标的惊艳,而是在可控成本下系统性地提升模型的可用性和可靠性。100万token上下文、64,000 token输出上限、三层思考模式、并行推理架构、多模态引擎原生整合——这些技术要素共同构成了一个更接近生产环境要求的模型形态。
对于国内开发者而言,若想直接体验Gemini 3.1 Pro的推理能力与代码生成表现,可通过聚合平台RskAi(ai.rsk.cn)进行实测。该平台集成Gemini 3.1 Pro、GPT-5.4、Claude 3.5三款模型,国内可直接访问,支持文件上传与联网搜索,便于开发者进行多模型横向对比验证。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)