OpenClaw × Kimi 2.5:一次可复现的 Agent 工程实践记录
Coding 稳定性前端代码生成不追求炫技,但结构稳定、可运行率高。任务拆解能力对“多步骤 + 状态依赖”的任务,有明显工程感,而不是一口气输出。计费与可控性从按次计费升级为 Token 计费后,更适合 Agent 长时间运行场景。在 OpenClaw 中,模型不是“回答者”,而是决策器 + 调度器,这一点非常关键。适合:想研究Agent 工程化的人需要长期运行自动化任务的团队对 IM / Wor
关注 霍格沃兹测试学院公众号,回复「资料」, 领取人工智能测试开发技术合集
从模型接入、Gateway 机制,到多 IM 通道与 Skills 驱动的自动化执行 ——这不是“又一个 AI 工具”,而是一套可以嵌入真实工作流的 Agent 运行模型
目录
-
背景:为什么重新看 OpenClaw
-
架构视角:OpenClaw 在解决什么问题
-
模型选择:Kimi 2.5 的工程表现
-
部署实战:云服务器 / 本地统一流程
-
Gateway 与 Discord:一次完整的通道打通
-
关键配置与常见坑位
-
能力验证:从自然语言到可执行结果
-
Skills:OpenClaw 真正的“能力放大器”
-
Moltbook 与多 Agent 社交的现实意义
-
总结:它适合谁,不适合谁
1. 背景:为什么重新看 OpenClaw
最近在 X 上看到 OpenClaw 官方推荐 Kimi 2.5 作为可用模型之一,同时 Artificial Analysis 的榜单也给了一个明确结论:
Kimi 2.5 当前是综合表现最强的开源模型之一
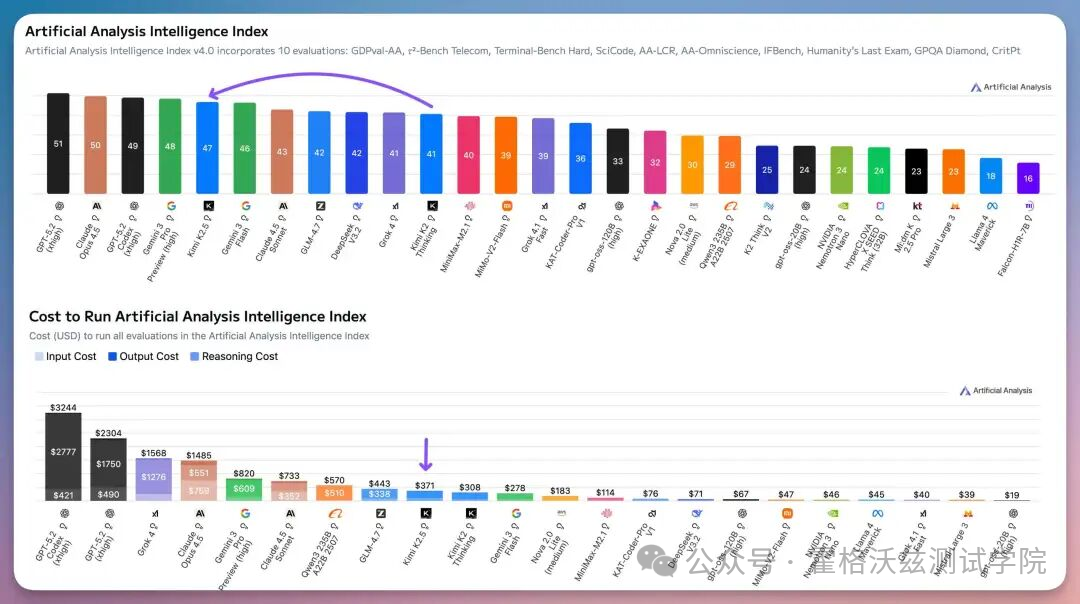
这件事本身并不稀奇,真正让我重新关注 OpenClaw 的,是两个变化:
-
官方开始主动推荐模型组合,而不是“模型随便接”
-
社区的实践重心,从“能跑起来”,转向了长期运行、通道接入与自动化任务
这意味着它正在从 Demo 阶段,走向工程试验阶段。
2. 架构视角:OpenClaw 在解决什么问题
如果只从表面看,OpenClaw 像是一个“能操作电脑的 AI”。 但从代码结构和运行方式看,它解决的其实是三个更工程化的问题:
-
Agent 如何长期运行(而不是一次性对话)
-
Agent 如何安全地接入外部世界(IM、文件、系统)
-
Agent 如何通过 Skills 执行确定性动作
核心不在模型,而在它的 Gateway + Channels 架构。
Gateway 是唯一入口,负责:
-
会话管理
-
通道接入(Discord / Telegram / 飞书等)
-
Agent 与外部世界的权限边界
这也是为什么在 OpenClaw 的代码中,Gateway 与 Channels 的体量甚至超过 Agent 本身。
3. 模型选择:为什么是 Kimi 2.5
在实际接入前,对 Kimi 2.5 的判断基于三点:
-
Coding 稳定性前端代码生成不追求炫技,但结构稳定、可运行率高。
-
任务拆解能力对“多步骤 + 状态依赖”的任务,有明显工程感,而不是一口气输出。
-
计费与可控性从按次计费升级为 Token 计费后,更适合 Agent 长时间运行场景。
在 OpenClaw 中,模型不是“回答者”,而是决策器 + 调度器,这一点非常关键。
4. 部署实战:统一安装流程
无论是本地(Mac / Windows / Linux),还是云服务器,官方流程已经高度统一:
curl -fsSL https://openclaw.bot/install.sh | bash
openclaw onboard --install-daemon
安装过程中最重要的不是命令,而是几个不能选错的点:
-
模型选择:Kimi Code API
-
模型名称:
kimi-code/kimi-for-coding -
Hooks:必须启用
session-memory
这一步决定了 Agent 是否具备跨会话记忆能力。
5. Gateway 与 Discord:通道不是“聊天窗口”
OpenClaw 对 IM 的理解,不是“聊天 UI”,而是远程控制通道。
这里以 Discord 为例:
-
Discord Bot ≠ 聊天机器人
-
它只是 Gateway 的一个 Channel
配置流程的本质是三步:
-
创建 Bot,获取 Token
-
完成 OAuth2 授权,将 Bot 加入服务器
-
通过 Pairing Code 建立 Gateway ↔ Channel 的信任关系
完成后,你在手机端发的每一句话,都会变成 Gateway 中的一次 Agent 调度。
6. 关键配置与常见坑位
几个实践中必踩的点,直接给结论:
-
云服务器断连重新执行
openclaw onboard --install-daemon -
进程被干掉不要用 nohup 侥幸运行,直接上 systemd
-
Node / nvm 不生效systemd 不会加载用户环境变量,PATH 必须写死
这些都不是 OpenClaw 的“坑”,而是长期运行服务的通用工程问题。
7. 能力验证:从一句话到可执行结果
几个典型验证场景:
-
一句话生成带交互的前端页面
-
上传文件 → 解析 → 生成站点 → 自动部署
-
定时任务:信息抓取、整理、推送
-
条件触发:行情波动 → 通知
这里最重要的不是“它能不能做”,而是:
它能否在无人干预的情况下,把流程跑完
这一点,OpenClaw + Kimi 2.5 是合格的。
8. Skills:真正决定上限的东西
如果说模型决定下限,那么 Skills 决定上限。
OpenClaw 的执行逻辑是:
语言理解 → 任务规划 → Skill 选择 → 执行
一旦 Skill 足够明确,Agent 的行为就会高度确定。
一些可用的 Skill 集合:
-
https://www.clawhub.ai/skills
-
https://github.com/VoltAgent/awesome-openclaw-skills
这也是为什么它在非 Coding 场景下,反而更有潜力。
9. Moltbook:多 Agent 社交不是噱头
Moltbook 看起来像个“AI 自嗨社区”,但它验证了一件事:
Agent 可以在没有人类参与的情况下,形成长期行为模式
当 Agent 能发帖、回复、跟踪话题,本质上就是:
-
定时任务
-
状态记忆
-
行为策略
这些能力,一旦回到工程系统中,意义就完全不同了。
10. 总结:它适合谁,不适合谁
适合:
-
想研究 Agent 工程化 的人
-
需要 长期运行自动化任务 的团队
-
对 IM / Workflow / 自动执行有需求的场景
不适合:
-
只想“试试 AI 能多聪明”
-
不能接受权限与安全边界成本
-
不愿意为稳定性做工程投入
一句话总结:
OpenClaw 把 AI 从“会聊天”,推进到了“能干活”。 而 Kimi 2.5,让这件事在工程上变得可控、可复现。
这条路刚刚开始,但已经不再是玩具了。
关于我们
霍格沃兹测试开发学社,隶属于 测吧(北京)科技有限公司,是一个面向软件测试爱好者的技术交流社区。
学社围绕现代软件测试工程体系展开,内容涵盖软件测试入门、自动化测试、性能测试、接口测试、测试开发、全栈测试,以及人工智能测试与 AI 在测试工程中的应用实践。
我们关注测试工程能力的系统化建设,包括 Python 自动化测试、Java 自动化测试、Web 与 App 自动化、持续集成与质量体系建设,同时探索 AI 驱动的测试设计、用例生成、自动化执行与质量分析方法,沉淀可复用、可落地的测试开发工程经验。
在技术社区与工程实践之外,学社还参与测试工程人才培养体系建设,面向高校提供测试实训平台与实践支持,组织开展 “火焰杯” 软件测试相关技术赛事,并探索以能力为导向的人才培养模式,包括高校学员先学习、就业后付款的实践路径。
同时,学社结合真实行业需求,为在职测试工程师与高潜学员提供名企大厂 1v1 私教服务,用于个性化能力提升与工程实践指导。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献202条内容
已为社区贡献202条内容

所有评论(0)