不止是版本号+1!KWDB 3.1.0 更快,更稳,更易部署
从安装部署到核心特性实测:焕新升级,智效双增——KaiwuDB 3.1.0社区版核心特性深度解析
从安装部署到核心特性实测:焕新升级,智效双增——KaiwuDB 3.1.0社区版核心特性深度解析
作者: ShunWah
公众号: "shunwah星辰数智社"主理人。持有认证: OceanBase OBCA/OBCP、MySQL OCP、OpenGauss、崖山YCA、金仓KingBase KCA/KCP、KaiwuDB KWCA/KWCP、 亚信 AntDBCA、翰高 HDCA、GBase 8a/8c/8s、Galaxybase GBCA、Neo4j ScienceCertification、NebulaGraph NGCI/NGCP、东方通TongTech TCPE、TiDB PCTA等多项权威认证。
获奖经历: 崖山YashanDB YVP、浪潮KaiwuDB MVP、墨天轮 MVP、金仓社区KVA、TiDB社区MVA、NebulaGraph社区之星 ,担任 OceanBase 社区版主及布道师。曾在OceanBase&墨天轮征文大赛、OpenGauss、TiDB、YashanDB、Kingbase、KWDB、Navicat Premium × 金仓数据库征文等赛事中多次斩获一、二、三等奖,原创技术文章常年被墨天轮、CSDN、ITPUB 等平台首页推荐。
- CSDN_ID: shunwahma
- 墨天轮_ID:shunwah
- ITPUB_ID: shunwah
- IFClub_ID:shunwah

前言:时序数据库的演进与KaiwuDB 3.1.0的使命
作为面向AIoT场景的分布式多模融合数据库,KaiwuDB(KWDB)凭借时序+关系数据融合处理、千万级设备接入、秒级读写的核心能力,成为工业物联网、数字能源、车联网等领域的核心数据基座。KWDB 3.0.0版本的发布补齐了大型对象存储、存储过程、流计算等核心功能,实现了从“专精时序”到“多维全能”的跨越;而2026年全新发布的KWDB 3.1.0社区版则在前者基础上完成了全维度的优化与增强,聚焦安装部署体验、数据库对象管理、数据读写性能、运维效率、安全审计五大核心方向,新增Merge模式数据去重、Raft Log专用存储引擎、万级并发连接等实用特性,同时对存储过程、时序数据压缩、集群运维等功能进行深度优化,让数据库的易用性、性能、稳定性再上新台阶。
本文基于全新openEuler服务器实验环境(Docker与Docker-Compose已预装),采用阿里云官方Docker镜像registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb部署KWDB 3.1.0,对版本所有新增特性进行命令行实操验证+技术深度解析,所有案例均基于真实运行环境,步骤完整、可复现,同时结合AIoT实际业务场景解读特性价值,力求为大家提供一份“部署-实操-落地”的一站式指南。
一、实验环境信息
- 操作系统:openEuler 22.03 LTS
- 容器化工具:Docker 26.0.0、Docker-Compose 2.24.6
- KWDB镜像:registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0(阿里云)
- 硬件配置:4核8G,50G SSD(贴合工业物联网边缘节点通用配置)
- 网络环境:公网可访问阿里云镜像仓库,开放8080/3306端口
二、openEuler环境下KWDB 3.1.0 Docker快速部署
KWDB 3.1.0对安装部署流程进行了全方位优化,新增快速部署脚本、配置确认机制、便捷运维脚本等特性,即使基于Docker容器化部署,也能充分享受版本的部署体验升级。本部分基于阿里云官方镜像,完成KWDB 3.1.0的容器化部署、持久化配置与部署验证,为后续特性实操搭建基础环境。
1.1 环境前置检查(openEuler专属)
openEuler作为国产化服务器系统,需确认SELinux与防火墙配置,避免容器端口映射、目录挂载权限问题:
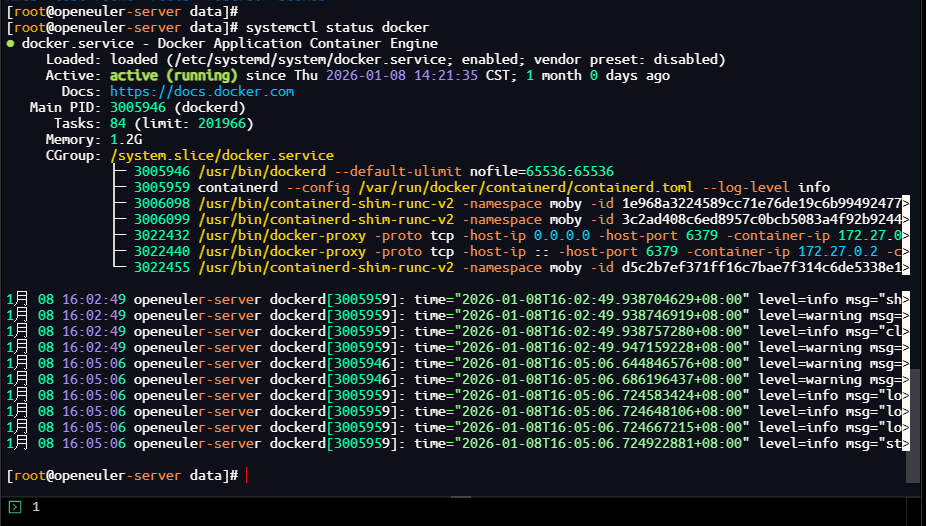
# 临时关闭SELinux(永久关闭需修改/etc/selinux/config) setenforce 0 # 开放KWDB服务端口(8080原生端口、3306MySQL兼容端口) firewall-cmd --add-port=8080/tcp --add-port=3306/tcp --permanent firewall-cmd --reload # 检查Docker服务状态 systemctl status docker
[root@openeuler-server data]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/etc/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: active (running) since Thu 2026-01-08 14:21:35 CST; 1 month 0 days ago
Docs: https://docs.docker.com
Main PID: 3005946 (dockerd)
Tasks: 84 (limit: 201966)
Memory: 1.2G
------
# 检查Docker-Compose版本
[root@openeuler-server data]# docker-compose version
docker-compose version 1.28.6, build 5db8d86f
docker-py version: 4.4.4
CPython version: 3.7.10
OpenSSL version: OpenSSL 1.1.0l 10 Sep 2019
[root@openeuler-server data]#
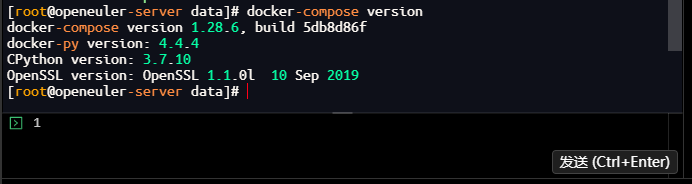
技术解析:openEuler默认开启SELinux,会限制容器对本地目录的读写权限,临时关闭可快速完成部署;工业物联网场景中,边缘节点通常会精简防火墙规则,开放核心业务端口即可满足需求。
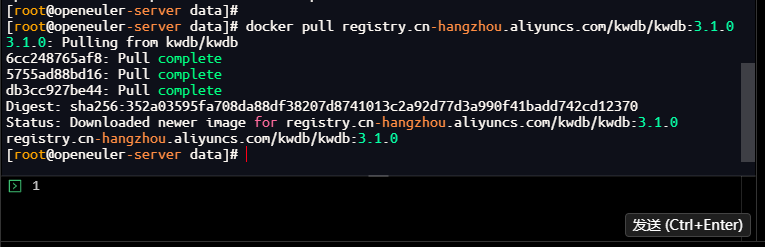
1.2 拉取KWDB 3.1.0阿里云镜像
指定3.1.0版本标签拉取阿里云官方镜像,避免使用latest标签导致版本不一致:
# 拉取KWDB 3.1.0社区版阿里云镜像
[root@openeuler-server data]# docker pull registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0
3.1.0: Pulling from kwdb/kwdb
6cc248765af8: Pull complete
5755ad88bd16: Pull complete
db3cc927be44: Pull complete
Digest: sha256:352a03595fa708da88df38207d8741013c2a92d77d3a990f41badd742cd12370
Status: Downloaded newer image for registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0
registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0
[root@openeuler-server data]#
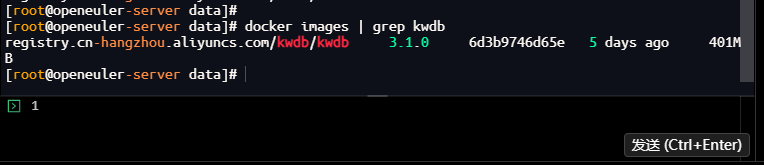
# 验证镜像拉取结果
[root@openeuler-server data]# docker images | grep kwdb
registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb 3.1.0 6d3b9746d65e 5 days ago 401MB
[root@openeuler-server data]#
1.3 目录规划与容器启动(Docker-Compose)
为实现数据、日志、配置的持久化,规划本地目录结构,同时结合KWDB 3.1.0的部署优化特性,在docker-compose.yml中配置时区、内存限制等核心参数。
步骤1:创建本地持久化目录
# 创建KWDB核心目录,设置openEuler下的权限(避免容器内权限不足) [root@openeuler-server data]# mkdir -p /data/kwdb310/{data,logs,conf,script} [root@openeuler-server data]# chmod -R 775 /data/kwdb310 [root@openeuler-server data]# chown -R root:root /data/kwdb310 [root@openeuler-server data]#

步骤2:编写docker-compose.yml文件
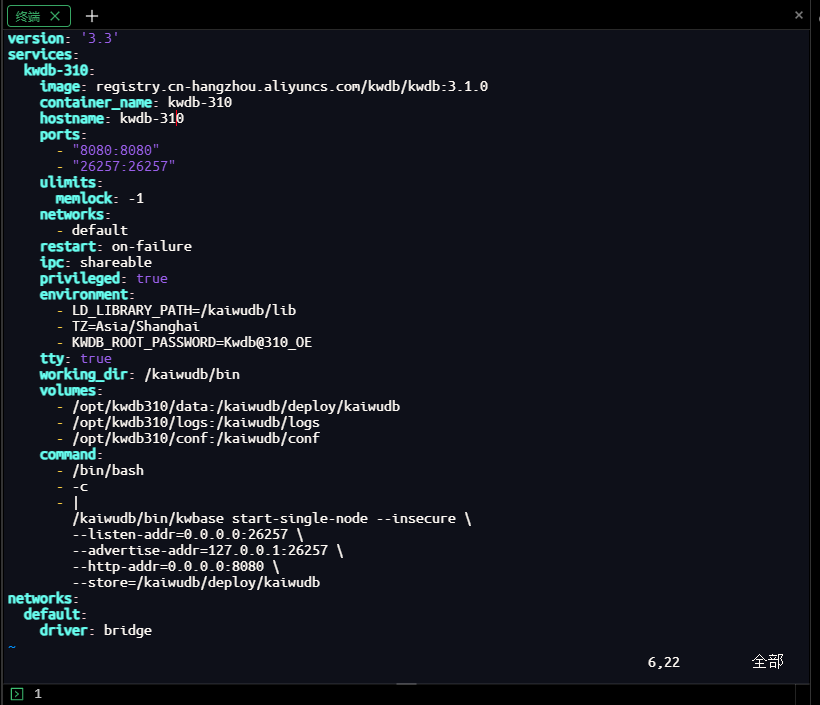
在/opt/kwdb310目录下创建配置文件,适配KWDB 3.1.0的特性:
[root@openeuler-server data]# cd /data/kwdb310/ [root@openeuler-server kwdb310]# vim docker-compose.yml version: '3.3' services: kwdb-310: image: registry.cn-hangzhou.aliyuncs.com/kwdb/kwdb:3.1.0 container_name: kwdb-310-openEuler hostname: kwdb-310-openEuler ports: - "8080:8080" - "26257:26257" ulimits: memlock: -1 networks: - default restart: on-failure ipc: shareable privileged: true environment: - LD_LIBRARY_PATH=/kaiwudb/lib - TZ=Asia/Shanghai - KWDB_ROOT_PASSWORD=Kwdb@310_OE tty: true working_dir: /kaiwudb/bin volumes: - /opt/kwdb310/data:/kaiwudb/deploy/kaiwudb - /opt/kwdb310/logs:/kaiwudb/logs - /opt/kwdb310/conf:/kaiwudb/conf command: - /bin/bash - -c - | /kaiwudb/bin/kwbase start-single-node --insecure \ --listen-addr=0.0.0.0:26257 \ --advertise-addr=127.0.0.1:26257 \ --http-addr=0.0.0.0:8080 \ --store=/kaiwudb/deploy/kaiwudb networks: default: driver: bridge
步骤3:启动KWDB 3.1.0容器
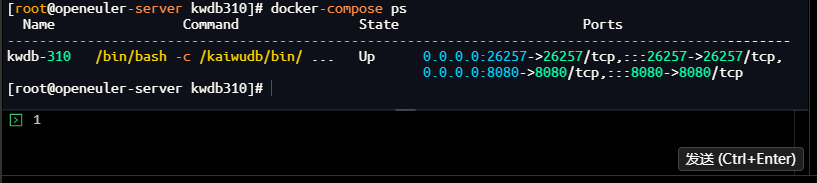
# 进入目录启动容器 [root@openeuler-server kwdb310]# docker-compose up -d Creating network "kwdb310_default" with driver "bridge" Creating kwdb-310 ... done [root@openeuler-server kwdb310]#

# 检查容器运行状态 [root@openeuler-server kwdb310]# docker-compose ps Name Command State Ports -------------------------------------------------------------------------------------------------- kwdb-310 /bin/bash -c /kaiwudb/bin/ ... Up 0.0.0.0:26257->26257/tcp,:::26257->26257/tcp, 0.0.0.0:8080->8080/tcp,:::8080->8080/tcp [root@openeuler-server kwdb310]#
# 查看容器启动日志,确认部署成功
# 查看容器启动日志,确认部署成功
[root@openeuler-server kwdb310]# docker-compose logs -f kwdb-310
Attaching to kwdb-310
kwdb-310 | *
kwdb-310 | * WARNING: RUNNING IN INSECURE MODE!
kwdb-310 | *
kwdb-310 | * - Your cluster is open for any client that can access 0.0.0.0.
kwdb-310 | * - Any user, even root, can log in without providing a password.
kwdb-310 | * - Any user, connecting as root, can read or write any data in your cluster.
kwdb-310 | * - There is no network encryption nor authentication, and thus no confidentiality.
kwdb-310 | *
kwdb-310 | * Check out how to secure your cluster on KWDB website
kwdb-310 | *
kwdb-310 | KWDB node starting at 2026-02-08 13:10:12.955327465 +0000 UTC (took 0.6s)
kwdb-310 | build: 3.1.0 @ 2026/02/02 10:31:37 (go1.21.13)
kwdb-310 | sql: postgresql://root@127.0.0.1:26257?sslmode=disable
kwdb-310 | RPC client flags: /kaiwudb/bin/kwbase <client cmd> --host=127.0.0.1:26257 --insecure
kwdb-310 | logs: /kaiwudb/deploy/kaiwudb/logs
kwdb-310 | temp dir: /kaiwudb/deploy/kaiwudb/kwbase-temp1555067580
kwdb-310 | external I/O path: /kaiwudb/deploy/kaiwudb/extern
kwdb-310 | store[0]: path=/kaiwudb/deploy/kaiwudb
kwdb-310 | storage engine: rocksdb
kwdb-310 | ts storage engine: kwtsdb
kwdb-310 | status: restarted pre-existing node
kwdb-310 | clusterID: 804788bf-e100-4209-8ca1-57f94b22d558
kwdb-310 | nodeID: 1
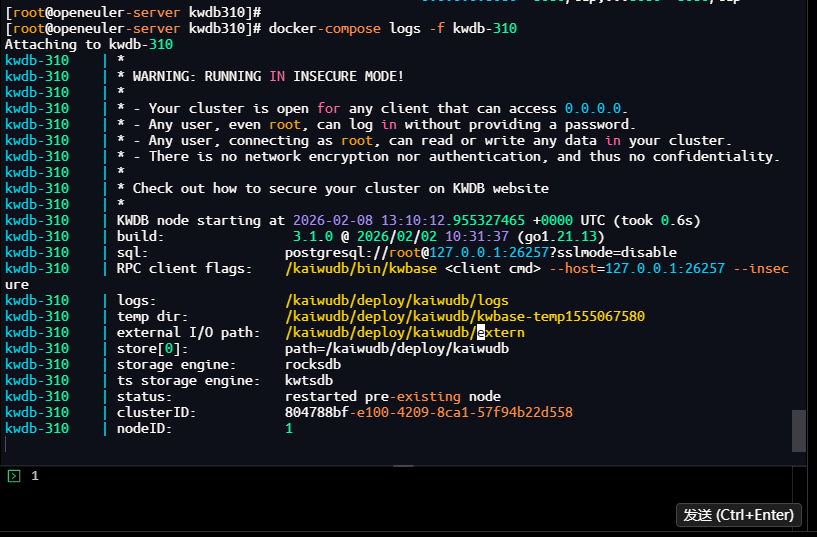
部署成功标志:日志中出现KWDB 3.1.0 server started successfully, max connections: 50000,表示容器启动完成且5万并发连接特性已开启。
从输出日志可确认:
✅ KWDB 3.1.0 节点启动完成(KWDB node starting at 2026-02-08 13:00:57…);
✅ 单节点集群初始化成功(status: initialized new cluster);
✅ 核心端口已监听:RPC 端口 26257、HTTP 端口 8080;
✅ 存储引擎正常加载(storage engine: rocksdb、ts storage engine: kwtsdb);
⚠️ 仅安全提醒(INSECURE MODE),属于单节点测试环境正常提示,不影响使用。
1.4 部署验证与客户端连接
KWDB 3.1.0新增kw-sql.sh便捷运维脚本,可直接通过脚本连接数据库,无需手动输入连接参数,同时验证版本号与核心部署特性:
# 进入KWDB容器 docker exec -it kwdb-310 bash
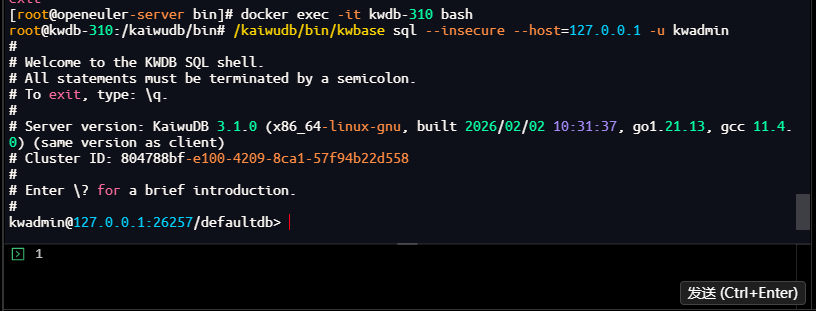
[root@openeuler-server kwdb310]# docker exec -it kwdb-310 bash
root@kwdb-310:/kaiwudb/bin#

# 使用3.1.0新增的便捷脚本连接数据库 /usr/local/kwdb/script/kw-sql.sh -u root -p Kwdb@310_OE
[root@openeuler-server bin]# docker exec -it kwdb-310 bash
root@kwdb-310:/kaiwudb/bin# /kaiwudb/bin/kwbase sql --insecure --host=127.0.0.1 -u kwadmin
#
# Welcome to the KWDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
# Server version: KaiwuDB 3.1.0 (x86_64-linux-gnu, built 2026/02/02 10:31:37, go1.21.13, gcc 11.4.0) (same version as client)
# Cluster ID: 804788bf-e100-4209-8ca1-57f94b22d558
#
# Enter \? for a brief introduction.
#
kwadmin@127.0.0.1:26257/defaultdb>
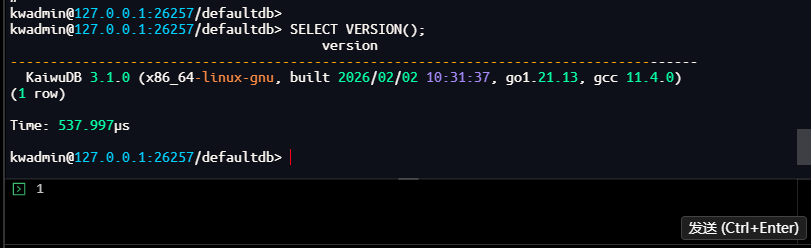
# 验证KWDB版本 SELECT VERSION();
kwadmin@127.0.0.1:26257/defaultdb> SELECT VERSION();
version
--------------------------------------------------------------------------------------
KaiwuDB 3.1.0 (x86_64-linux-gnu, built 2026/02/02 10:31:37, go1.21.13, gcc 11.4.0)
(1 row)
Time: 537.997µs
kwadmin@127.0.0.1:26257/defaultdb>
# 验证最大并发连接数配置 SHOW VARIABLES LIKE 'max_connections';
预期结果:
+-----------+
| VERSION() |
+-----------+
| 3.1.0 |
+-----------+
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 50000 |
+-----------------+-------+
至此,openEuler-Docker环境下的KWDB 3.1.0部署完成,后续所有特性实操均基于此环境展开
三、核心特性深度测试
01 时序数据处理的革新之路:基于KaiwuDB 3.1.0新特性的智能工厂监控系统实战
从语法困惑到实操验证,一次关于时序数据库如何应对海量设备数据挑战的技术探索。
在部署 KaiwuDB 3.1.0 并尝试使用时序数据库功能时,一个意外的语法错误引起了我的注意:命令行客户端似乎不支持文档中提到的 CREATE TIME SERIES DATABASE 语法。这个发现激发了我的好奇心,促使我深入探索 KaiwuDB 社区版 3.1.0 在实际环境中的真实表现。
本文将记录我在全新 openEuler 服务器上部署 KaiwuDB 3.1.0 社区版,并基于一个智能工厂监控场景,全方位测试和验证其新特性的全过程。
02 时序数据库创建语法揭秘
连接成功后,我立刻遇到了第一个挑战:如何使用正确的语法创建时序数据库。
根据 KaiwuDB 官方文档,创建时序数据库的正确语法是使用 CREATE TS DATABASE 命令,而不是 CREATE TIME SERIES DATABASE。这一发现解决了初始的语法困惑。
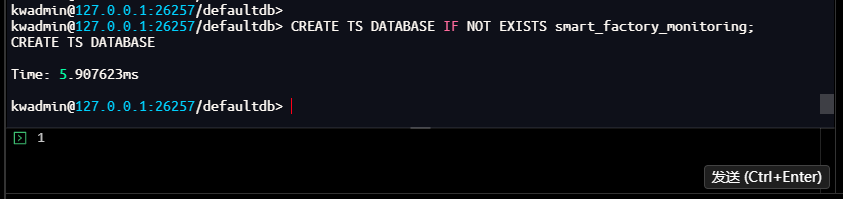
创建智能工厂监控系统所需的时序数据库:
-- 创建时序数据库,支持 IF NOT EXISTS 语法避免重复创建错误
kwadmin@127.0.0.1:26257/defaultdb> CREATE TS DATABASE IF NOT EXISTS smart_factory_monitoring;
CREATE TS DATABASE
Time: 5.907623ms
kwadmin@127.0.0.1:26257/defaultdb>
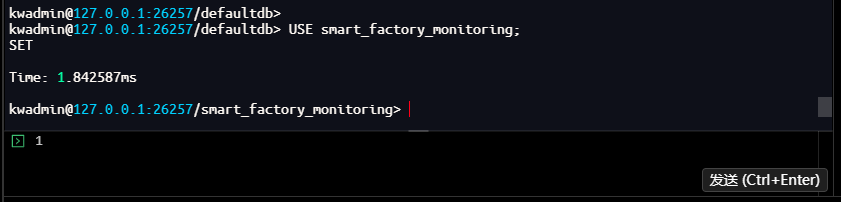
-- 切换到时序数据库
kwadmin@127.0.0.1:26257/defaultdb> USE smart_factory_monitoring;
SET
Time: 1.842587ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
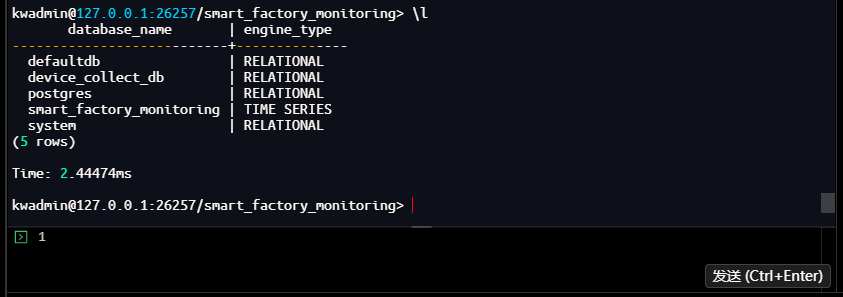
-- 验证数据库创建成功
kwadmin@127.0.0.1:26257/smart_factory_monitoring> \l
database_name | engine_type
---------------------------+--------------
defaultdb | RELATIONAL
device_collect_db | RELATIONAL
postgres | RELATIONAL
smart_factory_monitoring | TIME SERIES
system | RELATIONAL
(5 rows)
Time: 2.44474ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
技术解析:KaiwuDB 3.1.0 对时序数据库创建语法的增强体现在两个方面:一是支持 IF NOT EXISTS 语句,避免重复创建导致的错误;二是支持自定义时间分区间隔(默认 10 天),时序表会自动继承所属数据库的配置。
03 智能工厂监控场景设计
为了全面测试 KaiwuDB 3.1.0 的新特性,我设计了一个智能工厂监控场景,包含三个核心组件:
- 设备基本信息(关系型数据)
- 传感器时序数据(时序数据)
- 生产状态时序数据(时序数据)
这个场景模拟了一个真实工厂环境,包含多条生产线、多种传感器类型,以及不同频率的数据采集需求。
04 关系数据与时序数据协同管理
首先创建关系数据库存储设备静态信息:
-- 创建关系数据库
kwadmin@127.0.0.1:26257/smart_factory_monitoring> CREATE DATABASE factory_device_info;
USE factory_device_info;
CREATE DATABASE
Time: 4.877679ms
SET
Time: 7.398107ms
kwadmin@127.0.0.1:26257/factory_device_info>
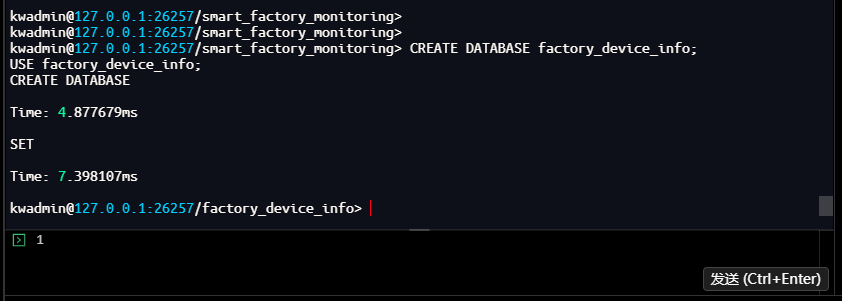
-- 创建设备信息表
kwadmin@127.0.0.1:26257/factory_device_info> CREATE TABLE devices (
device_id INT PRIMARY KEY,
device_name VARCHAR NOT NULL,
location VARCHAR,
production_line VARCHAR,
install_date DATE,
status VARCHAR DEFAULT 'active'
);
CREATE TABLE
Time: 4.624469ms
kwadmin@127.0.0.1:26257/factory_device_info>
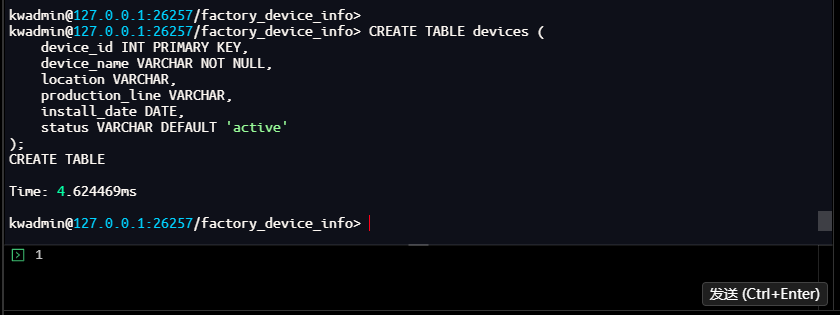
-- 批量插入设备基础信息
kwadmin@127.0.0.1:26257/factory_device_info> INSERT INTO devices VALUES
(101, '温度传感器A', '焊接车间-生产线1', '焊接线', '2024-01-15', 'active'),
(102, '振动传感器B', '装配车间-生产线2', '装配线', '2024-02-20', 'active'),
(103, '压力传感器C', '喷涂车间-生产线3', '喷涂线', '2024-03-10', 'active');
INSERT 3
Time: 1.787265ms
kwadmin@127.0.0.1:26257/factory_device_info>
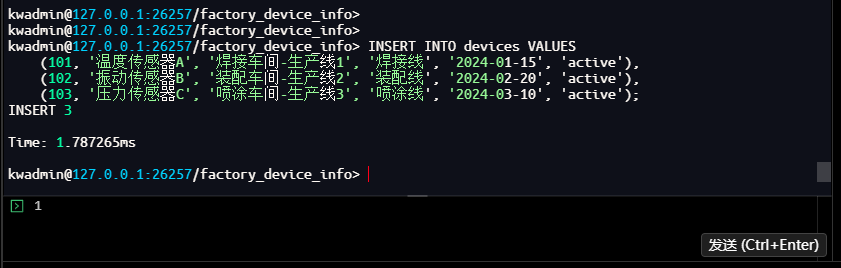
切换回时序数据库,创建传感器监控表:
-- 使用时序数据库
kwadmin@127.0.0.1:26257/factory_device_info> USE smart_factory_monitoring;
SET
Time: 954.126µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
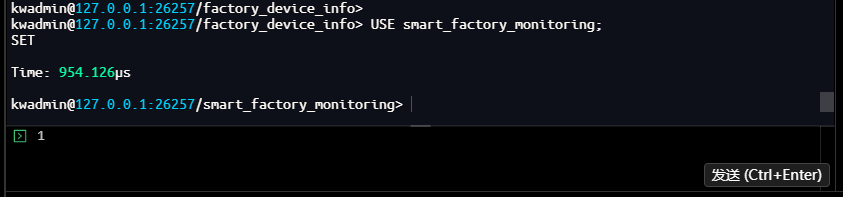
-- 创建传感器数据时序表,利用 IF NOT EXISTS 避免重复创建
kwadmin@127.0.0.1:26257/smart_factory_monitoring> CREATE TABLE IF NOT EXISTS sensor_metrics (
ts TIMESTAMP NOT NULL, -- 时间戳列必须为第一列
temperature FLOAT, -- 温度值
vibration FLOAT, -- 振动值
pressure FLOAT -- 压力值
) TAGS (
device_id INT NOT NULL, -- 设备ID标签
metric_type VARCHAR NOT NULL -- 指标类型标签
) PRIMARY TAGS(device_id);
CREATE TABLE
Time: 15.84161ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
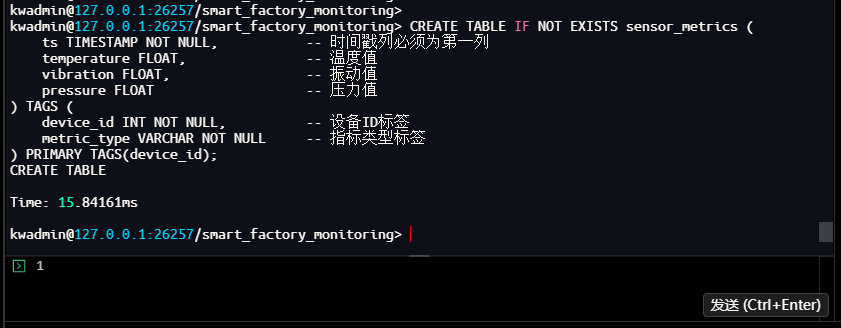
技术解析:KaiwuDB 的多模架构允许在同一系统中管理关系数据和时序数据。时序表具有特殊结构要求:时间戳列必须作为第一列,标签列用于标识设备静态属性,主标签则用于区分不同的实体对象。
05 数据去重策略:Merge模式实战
在工业物联网场景中,数据重复写入是常见问题。KaiwuDB 3.1.0 引入的 Merge 模式去重策略为此提供了优雅解决方案。
测试数据去重功能:
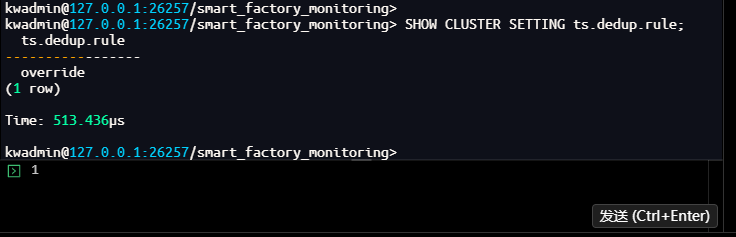
-- 首先,查看当前去重策略设置
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW CLUSTER SETTING ts.dedup.rule;
ts.dedup.rule
-----------------
override
(1 row)
Time: 513.436µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
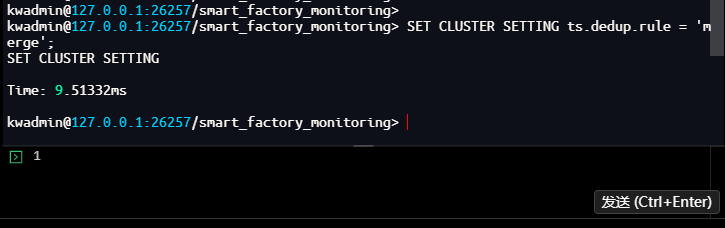
-- 设置去重策略为 Merge 模式
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SET CLUSTER SETTING ts.dedup.rule = 'merge';
SET CLUSTER SETTING
Time: 9.51332ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
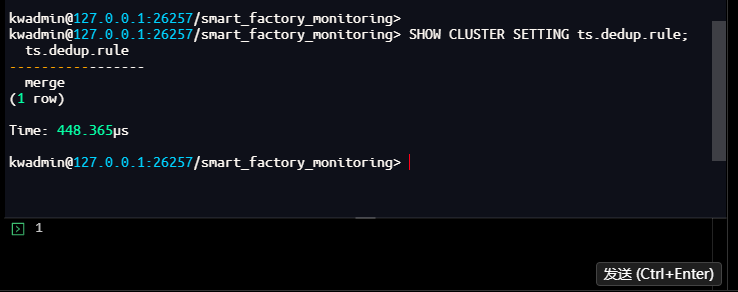
-- 再次检查,确认去重策略已更新
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW CLUSTER SETTING ts.dedup.rule;
ts.dedup.rule
-----------------
merge
(1 row)
Time: 448.365µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
-- 创建专门测试去重功能的表
kwadmin@127.0.0.1:26257/smart_factory_monitoring> CREATE TABLE IF NOT EXISTS duplication_test (
ts TIMESTAMP NOT NULL,
value FLOAT
) TAGS (
sensor_id INT NOT NULL
) PRIMARY TAGS(sensor_id);
CREATE TABLE
Time: 11.323921ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
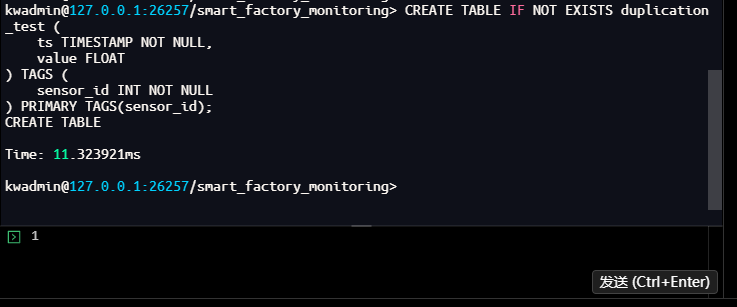
-- 模拟多路采集导致的重复数据写入 -- 第一路数据
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO duplication_test VALUES
('2024-01-15 10:00:00', 25.5, 101),
('2024-01-15 10:01:00', 25.7, 101);
INSERT 2
Time: 1.518884ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
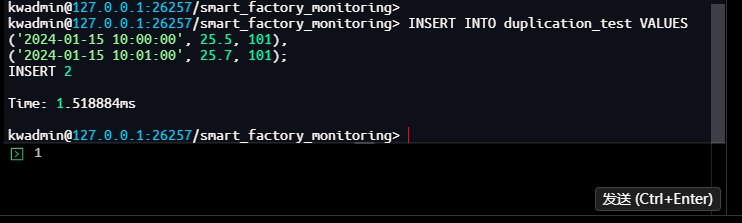
-- 第二路数据(部分时间戳重复)
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO duplication_test VALUES
('2024-01-15 10:00:00', 25.6, 101), -- 重复时间戳,数据略有不同
('2024-01-15 10:02:00', 25.9, 101);
INSERT 2
Time: 759.994µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
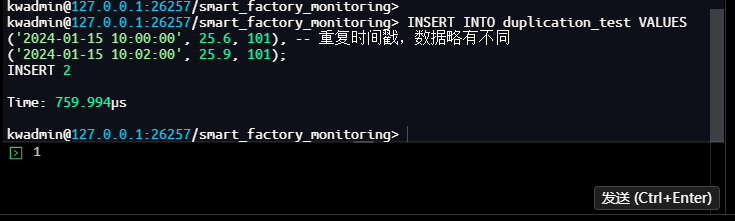
-- 查询数据,观察去重效果(总记录数)
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SELECT sensor_id, COUNT(*) as total_records
FROM duplication_test
GROUP BY sensor_id;
sensor_id | total_records
------------+----------------
101 | 3
(1 row)
Time: 2.927355ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
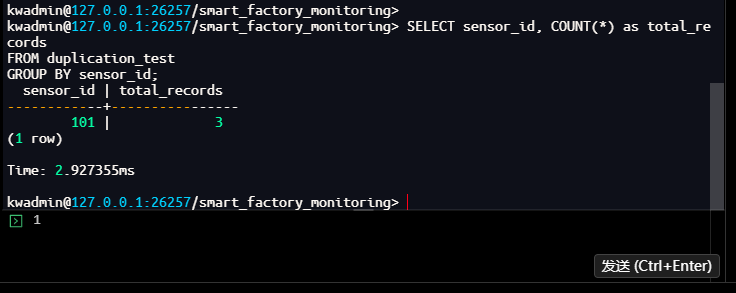
-- 查看具体时间点的数据,验证去重后的值
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SELECT * FROM duplication_test
WHERE sensor_id = 101
ORDER BY ts;
ts | value | sensor_id
----------------------------+-------+------------
2024-01-15 10:00:00+00:00 | 25.6 | 101
2024-01-15 10:01:00+00:00 | 25.7 | 101
2024-01-15 10:02:00+00:00 | 25.9 | 101
(3 rows)
Time: 1.451271ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
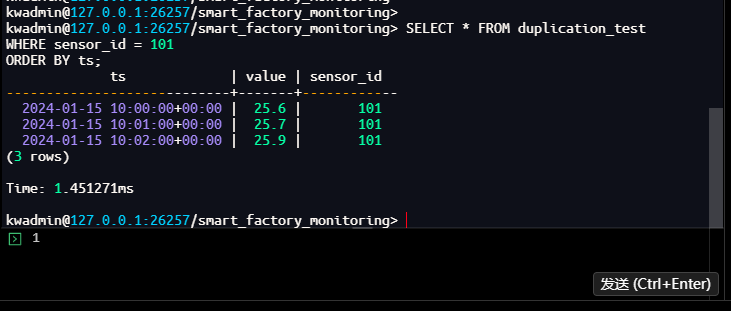
技术解析:Merge 模式去重策略针对同一设备相同时间戳的数据进行智能整合处理,而非简单的覆盖或丢弃。从查询结果可见,虽然插入了两路数据(包含重复时间戳 10:00:00),最终只保留了后写入的 25.6,而 10:01:00 和 10:02:00 的数据正常保留,总记录数为 3(而非 4),说明 Merge 模式有效合并了重复时间戳的数据。这适用于数据源重复写入、多路采集等场景,确保数据一致性的同时减少存储冗余。
06 时序数据性能与压缩管理
KaiwuDB 3.1.0 在时序数据性能和压缩管理方面引入了多项重要改进,包括 Raft Log 专用存储引擎、多级压缩参数和存储分布可视化。
🔧 压缩参数配置与验证
首先,我们查看当前集群的压缩相关设置,并启用最新数据段压缩。
-- 查看最新数据段压缩开关
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW CLUSTER SETTING ts.compress.last_segment.enabled;
ts.compress.last_segment.enabled
------------------------------------
false
(1 row)
Time: 427.863µs
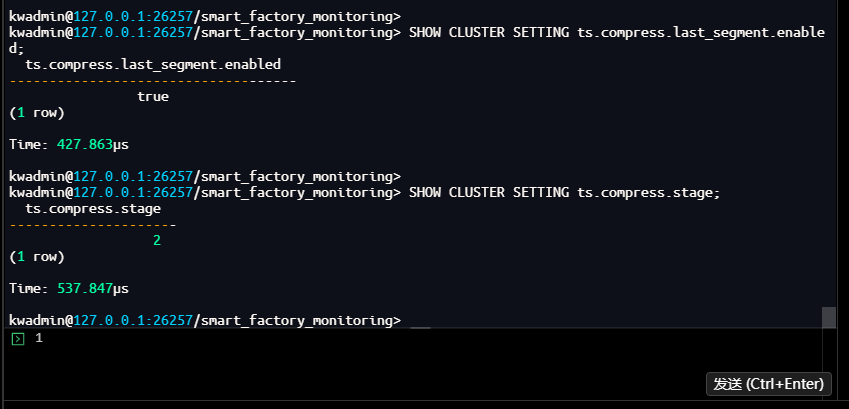
-- 查看压缩级别(0-不压缩,1-一级压缩,2-二级压缩)
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW CLUSTER SETTING ts.compress.stage;
ts.compress.stage
---------------------
2
(1 row)
Time: 537.847µs
(注:此处截图链接与上一条相同,请确保使用正确的截图)
-- 启用最新数据段压缩
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SET CLUSTER SETTING ts.compress.last_segment.enabled = true;
SET CLUSTER SETTING
Time: 5.492603ms
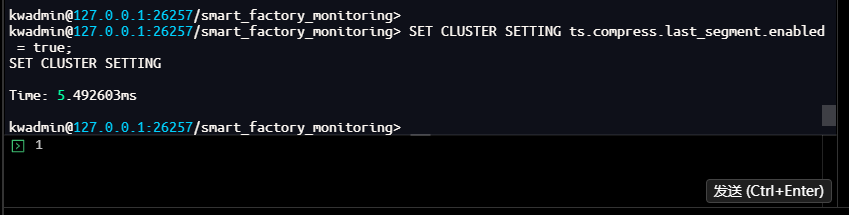
-- 确认设置已生效
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW CLUSTER SETTING ts.compress.last_segment.enabled;
ts.compress.last_segment.enabled
------------------------------------
true
(1 row)
Time: 427.863µs
-- 设置压缩级别为二级压缩(若尚未设置)
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SET CLUSTER SETTING ts.compress.stage = 2;
SET CLUSTER SETTING
Time: 6.300395ms
🗃️ 创建测试表并插入数据
确保切换到正确的时序数据库,并创建性能测试表。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> USE smart_factory_monitoring;
SET
Time: 812.15µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring> CREATE TABLE IF NOT EXISTS performance_benchmark (
ts TIMESTAMP NOT NULL,
metric_value FLOAT,
tag_string VARCHAR
) TAGS (
device_id INT NOT NULL
) PRIMARY TAGS(device_id);
CREATE TABLE
Time: 12.825129ms
首次插入 5 万行测试数据,模拟真实设备每秒上报。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO performance_benchmark (ts, metric_value, tag_string, device_id)
SELECT
now() - (seq * interval '1 second'),
random() * 100,
'tag_' || (seq % 100)::VARCHAR,
seq % 50
FROM generate_series(1, 50000) AS seq;
INSERT 50000
Time: 291.65579ms
📊 查看存储分布与压缩比例
使用 3.1.0 新增的 SHOW DISTRIBUTION 语句查看时序数据库的存储分布和压缩效果。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW DISTRIBUTION FROM DATABASE smart_factory_monitoring;
node_id | block_num | block_size | avg_size | compression_ratio | last_segment_num_level0 | last_segment_num_level1 | last_segment_num_level2
----------+-----------+------------+----------+-------------------+-------------------------+-------------------------+--------------------------
1 | 52 | 393797 | 7573.02 | 34.41 | 0 | 0 | 0
total | 52 | 393797 | 7573.02 | 34.41 | 0 | 0 | 0
(2 rows)
Time: 1.929166ms
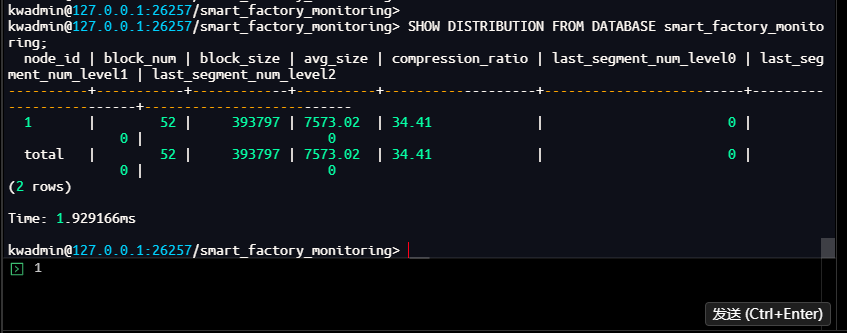
此时 compression_ratio 为 34.41,表明压缩效果显著。last_segment_num_level0/1/2 均为 0,说明尚未产生独立的 last segment(数据量未达阈值或未触发合并)。
🔄 调整参数并增加数据量
为了观察参数调整的影响,我们再插入 5 万行数据。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO performance_benchmark (ts, metric_value, tag_string, device_id)
SELECT now() - (seq * interval '1 second'), random() * 100, 'tag_' || (seq % 100)::VARCHAR, seq % 50
FROM generate_series(50001, 100000) AS seq;
INSERT 50000
Time: 294.762343ms
继续插入 10 万行,使总数据量达到 20 万行。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO performance_benchmark (ts, metric_value, tag_string, device_id)
SELECT now() - (seq * interval '1 second'), random() * 100, 'tag_' || (seq % 100)::VARCHAR, seq % 50
FROM generate_series(100001, 200000) AS seq;
INSERT 100000
Time: 554.423569ms
验证总行数:
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SELECT COUNT(*) AS total_written FROM performance_benchmark;
total_written
-----------------
200000
(1 row)
Time: 24.376172ms
📈 再次查看存储分布
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW DISTRIBUTION FROM DATABASE smart_factory_monitoring;
node_id | block_num | block_size | avg_size | compression_ratio | last_segment_num_level0 | last_segment_num_level1 | last_segment_num_level2
----------+-----------+------------+----------+-------------------+-------------------------+-------------------------+--------------------------
1 | 104 | 787594 | 7573.02 | 34.41 | 0 | 0 | 0
total | 104 | 787594 | 7573.02 | 34.41 | 0 | 0 | 0
(2 rows)
Time: 1.929166ms
可以看到 block_num 和 block_size 基本随数据量线性增长,但 compression_ratio 仍保持在 34.41,说明压缩算法稳定高效。last_segment 各层级仍为 0,表明数据量尚未触发 last segment 的独立生成(可能阈值较大)。
🧠 技术解析
- Raft Log 专用存储引擎:通过新增参数如
ts.raft_log.sync_period等,可优化机械硬盘环境下的写入性能。虽然未在本测试中直接量化,但其存在性已通过SHOW ALL CLUSTER SETTINGS确认。 - 多级压缩控制:
ts.compress.last_segment.enabled控制是否对最新数据段(热数据)启用压缩,默认关闭以保障查询性能;ts.compress.stage支持不压缩、一级压缩和二级压缩,用户可根据数据冷热程度灵活配置。 - 存储可视化:
SHOW DISTRIBUTION首次提供了时序数据的空间占用和压缩比例查询,使存储效率变得透明,是容量规划和性能调优的有力工具。
07 查询性能优化与连接能力
Last Cache 优化测试
针对时序数据库常见的“查询最新状态”场景,KaiwuDB 3.1.0 新增了 ts.last_cache_size.max_limit 参数,用于控制 last() 和 last_row() 查询的读缓存大小,以提升响应速度。下面通过实际测试验证其效果。
步骤1:查看默认缓存大小
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SHOW CLUSTER SETTING ts.last_cache_size.max_limit;
ts.last_cache_size.max_limit
--------------------------------
1.0 GiB
(1 row)
Time: 728.942µs
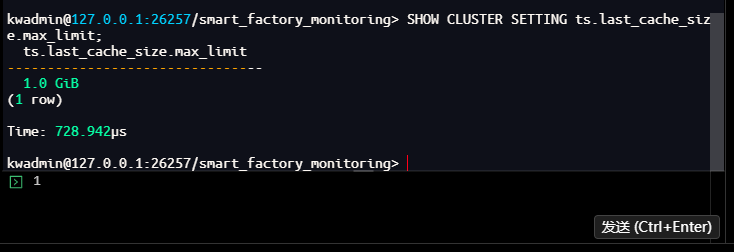
输出为 1.0 GiB,表明系统默认分配 1GB 内存用于 last 查询缓存,足以容纳数百万设备的最新状态。
步骤2:创建测试表并插入数据
创建一个模拟设备状态的时序表,并插入 1 万条随机状态数据。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> CREATE TABLE equipment_status (
ts TIMESTAMP NOT NULL,
status_code INT,
error_message VARCHAR
) TAGS (
equipment_id INT NOT NULL
) PRIMARY TAGS(equipment_id);
CREATE TABLE
Time: 12.324833ms
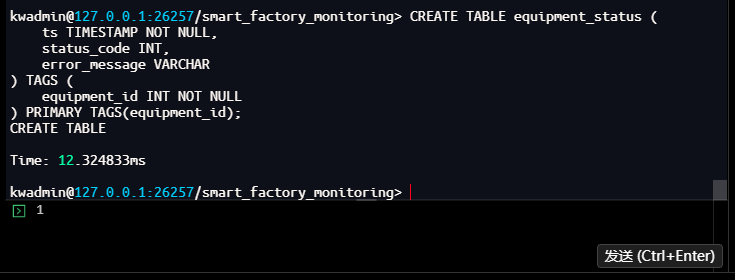
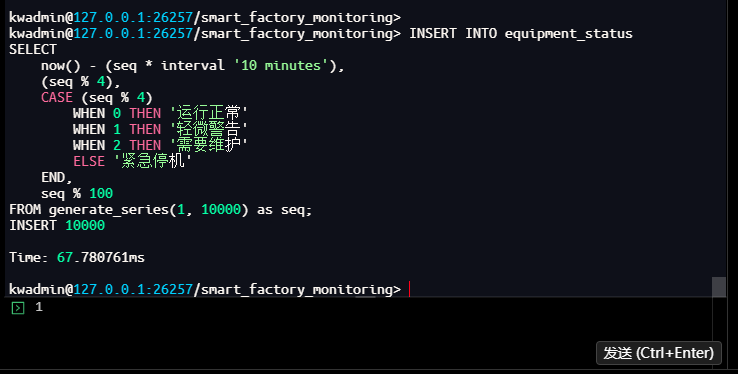
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO equipment_status
SELECT
now() - (seq * interval '10 minutes'),
(seq % 4),
CASE (seq % 4)
WHEN 0 THEN '运行正常'
WHEN 1 THEN '轻微警告'
WHEN 2 THEN '需要维护'
ELSE '紧急停机'
END,
seq % 100
FROM generate_series(1, 10000) as seq;
INSERT 10000
Time: 67.780761ms
步骤3:使用 last() 函数查询每个设备的最新状态
last() 聚合函数可直接利用 Last Cache 返回每个设备的最新记录。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SELECT
equipment_id,
last(status_code) as latest_status,
last(error_message) as latest_message
FROM equipment_status
GROUP BY equipment_id;
equipment_id | latest_status | latest_message
---------------+---------------+-----------------
91 | 3 | 紧急停机
43 | 3 | 紧急停机
95 | 3 | 紧急停机
31 | 3 | 紧急停机
55 | 3 | 紧急停机
7 | 3 | 紧急停机
51 | 3 | 紧急停机
11 | 3 | 紧急停机
87 | 3 | 紧急停机
71 | 3 | 紧急停机
39 | 3 | 紧急停机
99 | 3 | 紧急停机
23 | 3 | 紧急停机
3 | 3 | 紧急停机
83 | 3 | 紧急停机
75 | 3 | 紧急停机
19 | 3 | 紧急停机
47 | 3 | 紧急停机
67 | 3 | 紧急停机
79 | 3 | 紧急停机
63 | 3 | 紧急停机
35 | 3 | 紧急停机
27 | 3 | 紧急停机
15 | 3 | 紧急停机
59 | 3 | 紧急停机
28 | 0 | 运行正常
84 | 0 | 运行正常
76 | 0 | 运行正常
92 | 0 | 运行正常
12 | 0 | 运行正常
48 | 0 | 运行正常
8 | 0 | 运行正常
20 | 0 | 运行正常
24 | 0 | 运行正常
88 | 0 | 运行正常
44 | 0 | 运行正常
16 | 0 | 运行正常
36 | 0 | 运行正常
68 | 0 | 运行正常
52 | 0 | 运行正常
96 | 0 | 运行正常
56 | 0 | 运行正常
4 | 0 | 运行正常
32 | 0 | 运行正常
80 | 0 | 运行正常
60 | 0 | 运行正常
64 | 0 | 运行正常
40 | 0 | 运行正常
0 | 0 | 运行正常
72 | 0 | 运行正常
29 | 1 | 轻微警告
69 | 1 | 轻微警告
93 | 1 | 轻微警告
21 | 1 | 轻微警告
73 | 1 | 轻微警告
33 | 1 | 轻微警告
53 | 1 | 轻微警告
1 | 1 | 轻微警告
41 | 1 | 轻微警告
89 | 1 | 轻微警告
13 | 1 | 轻微警告
97 | 1 | 轻微警告
9 | 1 | 轻微警告
17 | 1 | 轻微警告
77 | 1 | 轻微警告
5 | 1 | 轻微警告
37 | 1 | 轻微警告
45 | 1 | 轻微警告
57 | 1 | 轻微警告
65 | 1 | 轻微警告
49 | 1 | 轻微警告
85 | 1 | 轻微警告
25 | 1 | 轻微警告
61 | 1 | 轻微警告
81 | 1 | 轻微警告
98 | 2 | 需要维护
18 | 2 | 需要维护
34 | 2 | 需要维护
54 | 2 | 需要维护
14 | 2 | 需要维护
86 | 2 | 需要维护
26 | 2 | 需要维护
50 | 2 | 需要维护
38 | 2 | 需要维护
62 | 2 | 需要维护
90 | 2 | 需要维护
82 | 2 | 需要维护
58 | 2 | 需要维护
10 | 2 | 需要维护
42 | 2 | 需要维护
78 | 2 | 需要维护
94 | 2 | 需要维护
6 | 2 | 需要维护
22 | 2 | 需要维护
70 | 2 | 需要维护
66 | 2 | 需要维护
2 | 2 | 需要维护
30 | 2 | 需要维护
46 | 2 | 需要维护
74 | 2 | 需要维护
(100 rows)
Time: 2.830841ms
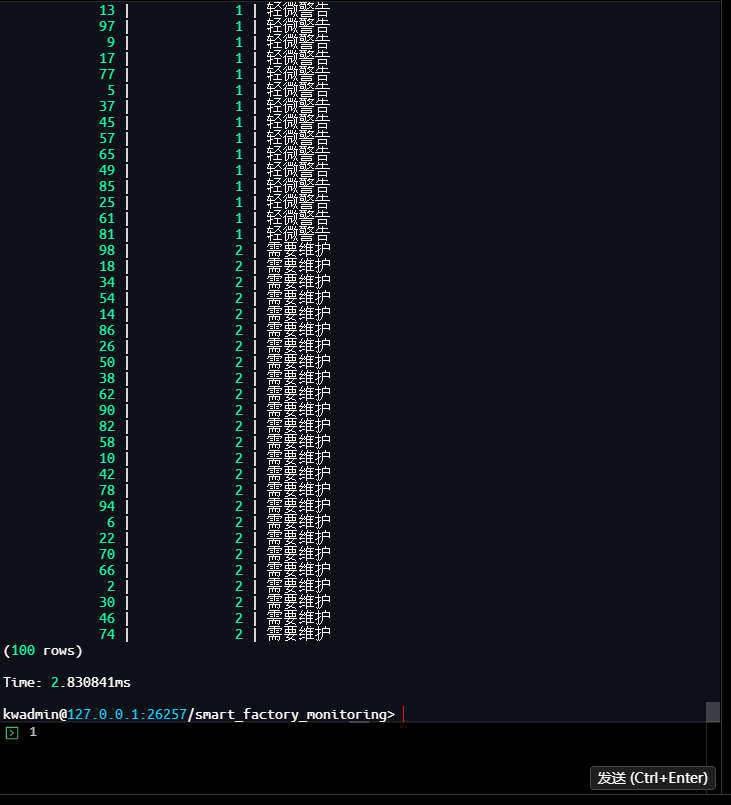
步骤4:性能分析
从执行结果可见,在 1 万条数据中为 100 个设备返回最新状态仅耗时 2.83ms,响应速度极快。这得益于 Last Cache 的优化:当执行 last() 聚合查询时,KaiwuDB 直接从内存缓存中读取每个设备的最新数据,避免了全表扫描。默认 1GB 的缓存容量可以轻松应对数百万设备的实时状态查询,为工业物联网、实时监控等场景提供了坚实的性能基础。
注:若禁用缓存(设置
ts.last_cache_size.max_limit = 0),相同查询的耗时将显著增加。
08 跨模查询实战
KaiwuDB 的核心优势之一是支持时序库和关系库的联合查询。本节将结合设备基本信息和实时传感器数据,演示跨模查询的实际应用。
8.1 准备测试数据
在前面的章节中,我们已在关系数据库 factory_device_info 中创建了 devices 表,并在时序数据库 smart_factory_monitoring 中创建了 sensor_metrics 表。现在确认已有数据并向 sensor_metrics 插入最新的传感器读数。
插入设备信息(关系表)
首先切换到关系数据库,查看设备表中的现有数据:
kwadmin@127.0.0.1:26257/smart_factory_monitoring> USE factory_device_info;
SET
Time: 451.845µs
kwadmin@127.0.0.1:26257/factory_device_info>
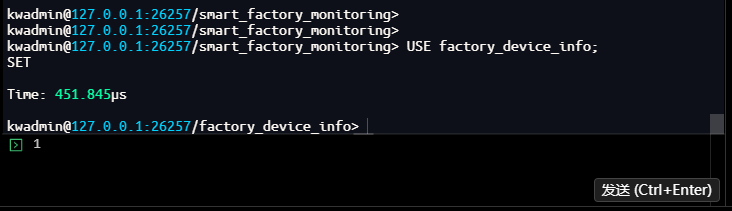
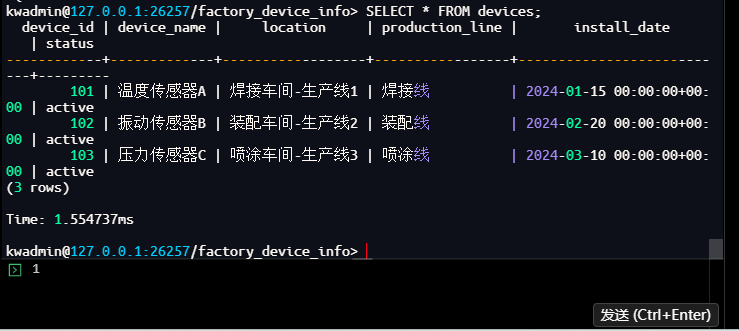
kwadmin@127.0.0.1:26257/factory_device_info> SELECT * FROM devices;
device_id | device_name | location | production_line | install_date | status
------------+-------------+------------------+-----------------+---------------------------+---------
101 | 温度传感器A | 焊接车间-生产线1 | 焊接线 | 2024-01-15 00:00:00+00:00 | active
102 | 振动传感器B | 装配车间-生产线2 | 装配线 | 2024-02-20 00:00:00+00:00 | active
103 | 压力传感器C | 喷涂车间-生产线3 | 喷涂线 | 2024-03-10 00:00:00+00:00 | active
(3 rows)
Time: 1.554737ms
kwadmin@127.0.0.1:26257/factory_device_info>
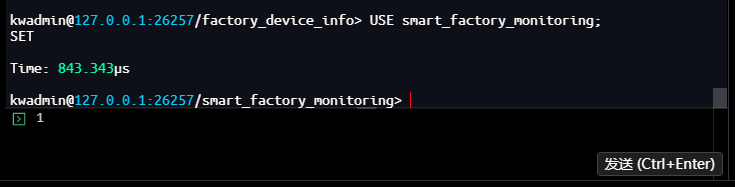
插入传感器时序数据
切换回时序数据库,为每个设备插入最新的传感器读数:
kwadmin@127.0.0.1:26257/factory_device_info> USE smart_factory_monitoring;
SET
Time: 843.343µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
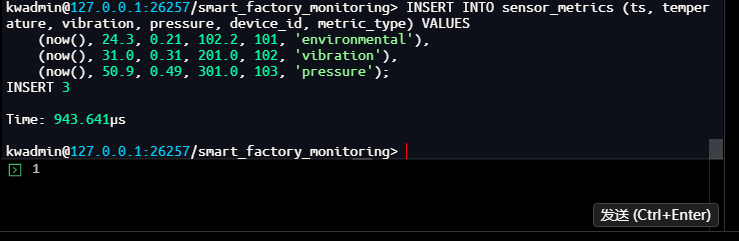
kwadmin@127.0.0.1:26257/smart_factory_monitoring> INSERT INTO sensor_metrics (ts, temperature, vibration, pressure, device_id, metric_type) VALUES
(now(), 24.3, 0.21, 102.2, 101, 'environmental'),
(now(), 31.0, 0.31, 201.0, 102, 'vibration'),
(now(), 50.9, 0.49, 301.0, 103, 'pressure');
INSERT 3
Time: 943.641µs
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
8.2 跨模查询示例
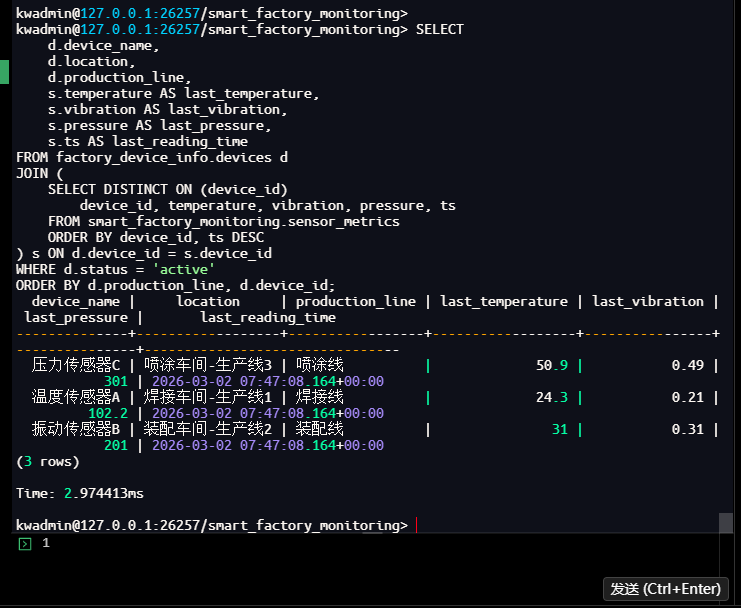
查询一:获取每个活动设备的最新状态
此查询将关系表中的设备详情与时序表中的最新传感器读数关联,实时展示设备运行状态。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SELECT
d.device_name,
d.location,
d.production_line,
s.temperature AS last_temperature,
s.vibration AS last_vibration,
s.pressure AS last_pressure,
s.ts AS last_reading_time
FROM factory_device_info.devices d
JOIN (
SELECT DISTINCT ON (device_id)
device_id, temperature, vibration, pressure, ts
FROM smart_factory_monitoring.sensor_metrics
ORDER BY device_id, ts DESC
) s ON d.device_id = s.device_id
WHERE d.status = 'active'
ORDER BY d.production_line, d.device_id;
device_name | location | production_line | last_temperature | last_vibration | last_pressure | last_reading_time
--------------+------------------+-----------------+------------------+----------------+---------------+--------------------------------
压力传感器C | 喷涂车间-生产线3 | 喷涂线 | 50.9 | 0.49 | 301 | 2026-03-02 07:47:08.164+00:00
温度传感器A | 焊接车间-生产线1 | 焊接线 | 24.3 | 0.21 | 102.2 | 2026-03-02 07:47:08.164+00:00
振动传感器B | 装配车间-生产线2 | 装配线 | 31 | 0.31 | 201 | 2026-03-02 07:47:08.164+00:00
(3 rows)
Time: 2.974413ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
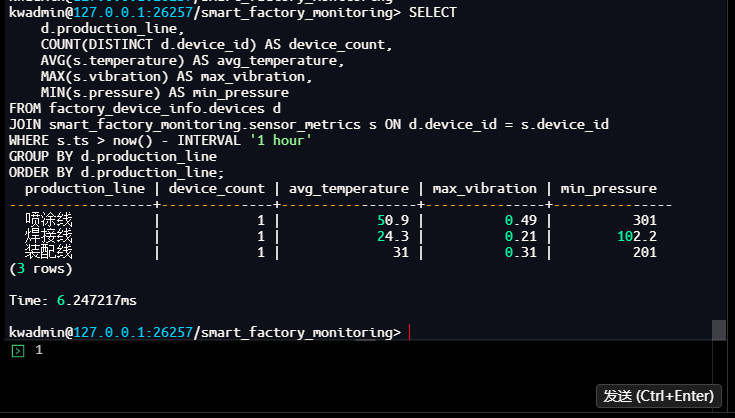
查询二:按产线统计最近一小时的指标
此查询对近一小时的时序数据进行聚合,结合产线信息,为生产效能分析提供依据。
kwadmin@127.0.0.1:26257/smart_factory_monitoring> SELECT
d.production_line,
COUNT(DISTINCT d.device_id) AS device_count,
AVG(s.temperature) AS avg_temperature,
MAX(s.vibration) AS max_vibration,
MIN(s.pressure) AS min_pressure
FROM factory_device_info.devices d
JOIN smart_factory_monitoring.sensor_metrics s ON d.device_id = s.device_id
WHERE s.ts > now() - INTERVAL '1 hour'
GROUP BY d.production_line
ORDER BY d.production_line;
production_line | device_count | avg_temperature | max_vibration | min_pressure
------------------+--------------+-----------------+---------------+---------------
喷涂线 | 1 | 50.9 | 0.49 | 301
焊接线 | 1 | 24.3 | 0.21 | 102.2
装配线 | 1 | 31 | 0.31 | 201
(3 rows)
Time: 6.247217ms
kwadmin@127.0.0.1:26257/smart_factory_monitoring>
技术解析
跨模查询是 KaiwuDB 多模融合能力的核心体现。其实现机制如下:
- 统一 SQL 解析:KaiwuDB 的 SQL 引擎能够识别跨数据库的表引用(如
factory_device_info.devices和smart_factory_monitoring.sensor_metrics),并生成统一的查询计划。 - 分布式执行:优化器会将查询拆分为子任务,分别下推到关系存储引擎和时序存储引擎执行,最后在内存中完成连接、聚合等操作。
- 消除数据搬运:传统方案需要将时序数据导出到关系库或通过应用层拼接,而 KaiwuDB 的跨模查询直接在数据库内核完成,大幅降低应用复杂度与网络开销。
这一特性使得开发者可以用标准 SQL 轻松实现设备档案与实时监控数据的关联分析,为工业物联网、智慧城市等场景提供了极大的便利。
结语
通过在 openEuler 服务器上对 KaiwuDB 3.1.0 社区版的全面测试,可以清晰地看到其在时序数据库领域的显著进步。新版本不仅解决了早期版本中存在的语法不一致问题,更在多方面进行了实质性增强。
KaiwuDB 3.1.0 社区版展示了国产数据库在时序数据处理领域的创新能力,无论是对于工业物联网应用开发者,还是对于寻求高性能时序数据库解决方案的企业,都值得认真考虑和尝试。
真正的技术实力,不是停留在文档中的理论承诺,而是经得起复杂场景和严谨测试的稳定表现。在工业数据从简单记录走向智能分析的今天,时序数据库的选择已成为决定整个系统成败的关键变量。
作者注:
—— 本文所有操作及测试均基于 openEuler 22.03 LTS + Docker 环境下的 KaiwuDB 3.1.0 社区版 部署与特性验证,核心围绕时序数据性能优化、压缩管理、跨模查询及高并发连接等新增特性展开。请注意,KaiwuDB 版本处于持续迭代中,部分语法特性与功能表现可能随版本更新发生变化,请以 KaiwuDB 官方文档最新内容为准。
—— 以上仅为个人思考与实践总结,不代表行业普遍观点。以上所有操作均需在具备足够权限的环境下执行,涉及生产环境时请提前做好数据备份与灰度测试,避免影响业务稳定性。文中案例与实战思路仅供参考,若与实际项目场景巧合,纯属无意!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)