OpenClaw技术架构分享
体现在记忆系统上就是,所有记忆以 Markdown 文件形式存储在本地,用户可以直接查看和修改 AI 对自己的"认知",记忆不再是黑盒,而是用户可以主动塑造的透明数据。相比于Mem0、Zep 等主流记忆框架把记忆存为向量嵌入,OpenClaw 的记忆被存成本地Markdown文件,用户可阅读可修改,具有。把"会回应的聊天机器人"变成了"会干活的 Agent"——一个持续运行在你自己硬件上、通过你已
1.概览
OpenClaw采用三层架构Channels-Geteway-llm层,六环节工作流。
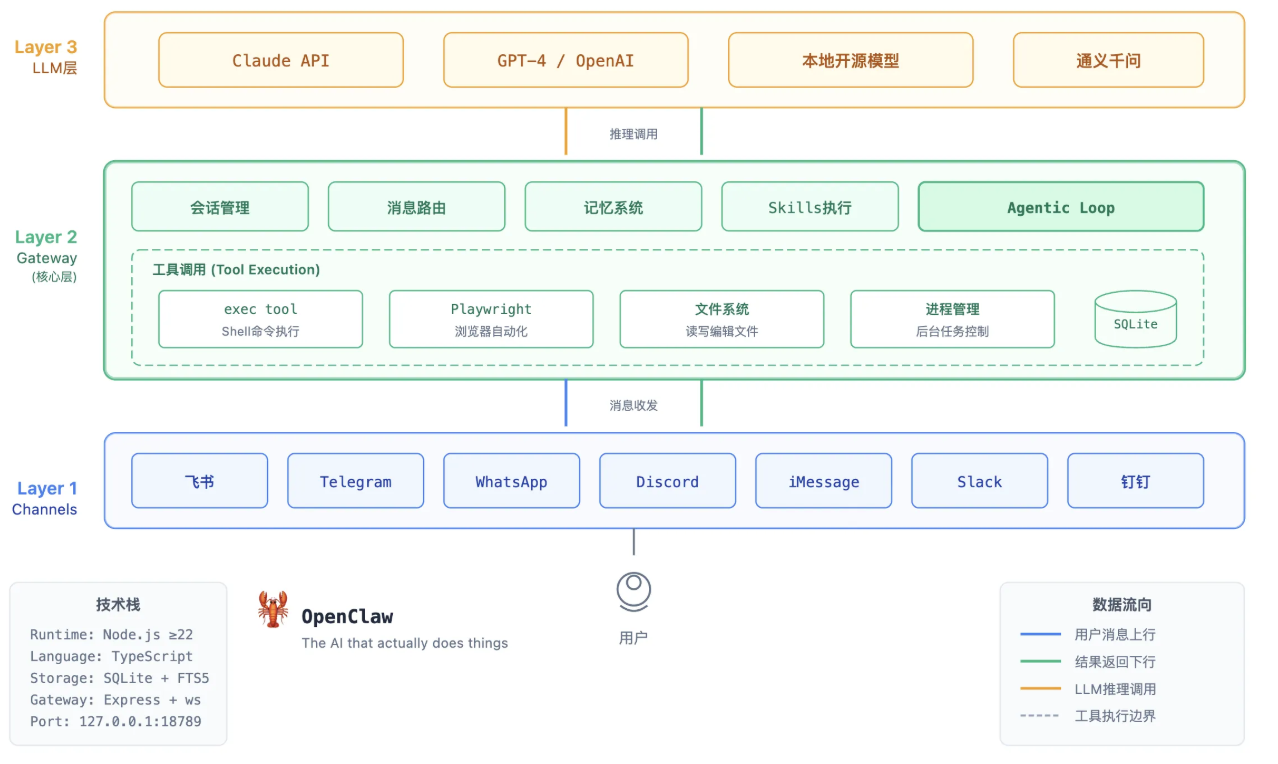
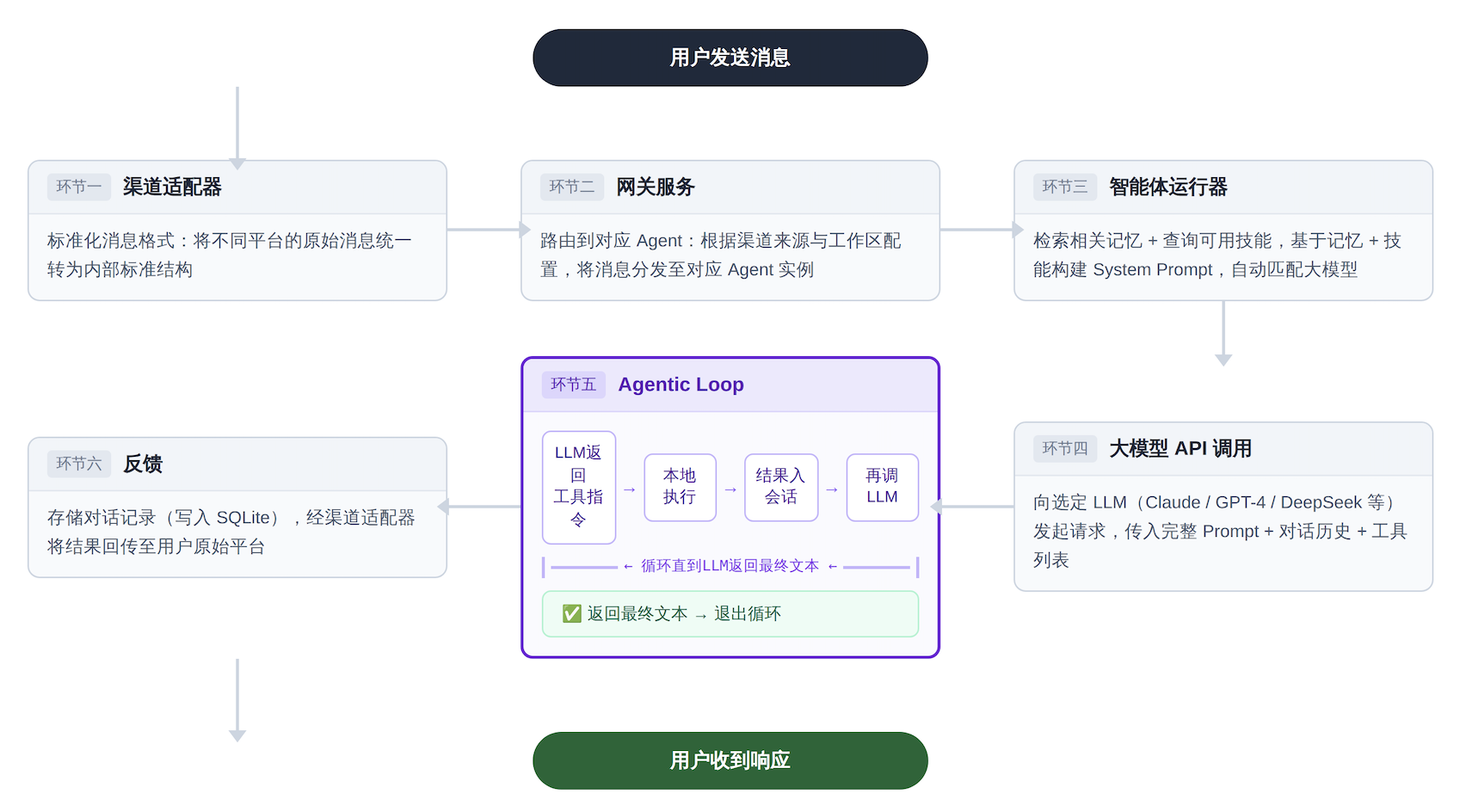
2.核心机制
2.1记忆管理
|
记忆存储 |
记忆存储分为两类文件:
三种写入触发机制
|
|
记忆检索 |
混合检索(默认使用 SQLite 作为本地数据库):两路并行检索后,对候选结果计算加权得分,向 Agent 返回最相关的若干条记忆。
结果融合:两路结果按加权公式合并打分
|
|
索引写入 |
单个文件的索引写入可以分为三个部分:
|
相比于Mem0、Zep 等主流记忆框架把记忆存为向量嵌入,OpenClaw 的记忆被存成本地Markdown文件,用户可阅读可修改,具有用户可读性与本地隐私保护。
2.2工具调用
OpenClaw 的工具调用可以分为两个层次
- skills:工具说明书
- tools:实际执行方
OpenClaw 的 Skill 架构直接基于 Pi-Agent 构建,但又有所不同
- 相同点
- 抽象化层级:两者都主张将底层的函数调用(Tools)与高层的业务逻辑(Skills)分开。
- 规划能力:都强调 Agent 的自我规划(Planning)能力,即 Agent 应该自己决定调用工具的顺序,而不是由代码写死顺序。
- Skill 格式:均遵循 AgentSkills 标准,以 SKILL.md 文件夹形式定义,自然语言描述操作逻辑,无需修改底层代码
- 不同点
- MCP 协议兼容:Pi-Agent 的工具调用往往是自建协议。OpenClaw 则相反,通过兼容 MCP 协议,支持将任意 MCP Server 接入作为工具扩展。这意味着你可以直接把别人的 MCP Server 拿来,瞬间变成 OpenClaw 的一个 Skill 插件。
- Skill 的可插拔性:Skills 以包含 SKILL.md 的文件夹形式定义,用自然语言描述操作逻辑,无需修改底层代码,像安装 App 一样即插即用,ClawHub 目前有 14, 380 个社区 Skill 可直接安装。
tools可分为四类内置工具:
|
exec tool |
直接执行 Shell 命令,读写文件系统、运行脚本、管理进程 支持三种运行环境:
|
|
浏览器工具 |
基于 Playwright 实现浏览器自动化,实现点击、填表、截图等操作。 采用语义快照技术——通过页面可访问性树生成文本化表征,避免多模态截图解析,LLM 理解效率更高。 |
|
文件系统 |
负责文件的增删改查 |
|
进程管理工具 |
支持后台长期运行命令、监控进程状态、终止指定进程等系统级操作。 |
对比分析
AutoGPT 默认在 Docker 沙箱中运行,提供了隔离保护;OpenClaw 默认直接在宿主机上运行,效率更高但没有沙箱隔离。
Manus 在托管的云端虚拟机中运行,有完全隔离的执行环境,无需本地安装任何依赖;OpenClaw 运行在用户自己的硬件上,数据不出本地,但配置和维护责任由用户承担。
对比 LangChain,OpenClaw 是开箱即用的完整产品,安装后即有 14,380 预配置技能可用,且可以自定义即插即用;LangChain 是开发框架,需要自己写代码组装功能,适合需要完全自定义工作流的开发者。
3.为什么openclaw会出现现象级爆火?
1.模型能力突破了某个阈值
在Claude Opus 4.5版本中,它实现了无需持续故障循环即可进行规划、执行和恢复。
2.产品化
OpenClaw的核心定位是"The AI that actually does things"——真正能干活的AI。把"会回应的聊天机器人"变成了"会干活的 Agent"——一个持续运行在你自己硬件上、通过你已经在用的消息应用访问的个人助手。
之前的 Agent 框架(AutoGPT、LangChain)都要求用户有相当的技术背景才能跑起来,OpenClaw 的突破是让普通人也能用 WhatsApp 发一条消息就能驱动一个 AI Agent 干活。
3.用户主导
数据上:反对主流 SaaS 模式,核心程序部署在用户自己的设备上,数据完全本地存储,用户拥有完整的数据主权和控制权。体现在记忆系统上就是,所有记忆以 Markdown 文件形式存储在本地,用户可以直接查看和修改 AI 对自己的"认知",记忆不再是黑盒,而是用户可以主动塑造的透明数据。代价是需要一定技术能力自行维护,但换来的是真正的隐私保护和独立性。
模型上:不绑定任何单一 LLM 厂商,支持按任务类型灵活路由——简单任务用便宜模型,复杂任务用顶级模型,并内置故障转移机制。本质上是把模型视为可替换的零部件,打破了大厂通过模型独占建立的用户锁定,技术实现依赖统一的接口抽象层
参考资料:
https://liuwei.blog/2026/02/10/openclaw%E6%97%B6%E5%88%BB%E4%B9%8B%E4%BA%8C/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)