AI时代,传统网络运维人员的转型指南
分享对AI时代网络运维的思考。文章分析了传统CLI和SNMP协议在网络管理中的优势与局限。随着NETCONF、YANG、RESTCONF等新一代协议的出现,网络运维正从命令行向模型驱动转变。分享网络工程师如何展开学习,找到职业发展方向。
着手写这篇文章时,我是一名已过不惑之年、依然坚守在一线的通信传输工程师(OTN/PTN/SPN)。在技术上,我侥幸取得过一些成绩——几次拿到厂商全国技术比赛的冠亚军奖项,工作中也得到了用户和领导的广泛认可。但即便这样,在当前经济形势和社会快速发展的今天,我依然时常感到一丝迷惘和忧虑。
最近三两年,AI 技术迭代的速度快得让人目不暇接,各种工具、模型层出不穷。网络上隔三差五就会冒出各种“XX 已死”的论调——从“前端已死”到“后端已死”,从“运维已死”到“测试何去何从”。虽然 CT 行业因安全、稳定至上的特性,受 AI 冲击的速度比纯粹 IT 行业慢了一拍,但这股焦虑的风终究还是刮到了网络运维圈。时不时也能听到“传统网工将被 AI 取代”“CLI 已死”的声音。更何况,“ICT”这个概念早在二十多年前就已提出,通信行业早已不是单纯的 CT,而是 IT 与 CT 的深度结合——AI 注定会对这个融合的领域产生深远影响。
在这样的背景下,很多传统 CT 工程师也难免心生疑虑:网络自动化、虚拟化、网络编程、NETCONF、RESTCONF、AI 人工智能……各种新技术和协议层出不穷,而我每天还在敲命令行、用传统网管维护设备,AI 会不会哪天就把我的饭碗端走了?
作为一名在通信行业摸爬滚打多年的一线人员,我想把这些思考记录下来,整理成文章。梳理网络管理协议的演进脉络,聊聊 AI 时代通信工程师、网络运维人员该如何自处。希望也能帮你理清思路,缓解焦虑,找到属于自己的方向。
提醒
本篇文章部分段落,结构由AI进行了修改,调整,润色。
本篇文章不存在完全由AI生成的内容。
一、传统的CLI命令行
在过去数十年乃至今天,命令行(CLI)始终是网络工程师最熟悉、最依赖的工作方式,也是各设备厂商重点维护的核心管理接口。通过 CLI,工程师几乎可以执行所有查看、配置、维护操作,堪称网络运维的“万能工具”。
CLI 的优势显而易见:
- 功能全面:支持任意命令,覆盖设备的所有能力;
- 上手容易:绝大多数工程师都已熟练掌握,学习成本低;
- 信息深度:可获取设备特有的、细粒度的运行状态;
- 控制力强:各厂商均提供完备的命令体系,操作直接、反馈实时。
然而,随着网络规模持续扩大、自动化运维需求爆发,CLI 在新时代的局限性也逐渐暴露:
- 厂商命令天差地别:同样的VLAN配置,Cisco、Huawei、Juniper的语法都不一样,脚本适配累死人。
- 传输协议不安全:虽然 SSH 已普及,若配置不当,仍存在安全隐患。且很多老设备还在用Telnet。
- 没有数据模型:配置全靠工程师自己脑补,不同人写出的脚本风格各异。
- 输出解析复杂:命令行返回的是面向人的屏显文本,需用正则表达式解析,极易出错;
- 配置下发没有事务性:可能导致部分配置生效,部分配置不生效。
- 没有自动检查机制:只有敲进去才知道命令写没写错,设备不会提前告诉你语法有问题。
- 效率瓶颈:串行操作、人工介入多,不适合超大规模网络的自动化管理;
- 数据获取不便:必须回显才能获取数据,无法像 API 一样直接拿到结构化信息;
如今的技术语境中,CLI 有时会被贴上“落后”的标签。但“落后”不等于“无用”——在故障排查、紧急抢险、单点调试等场景中,CLI 依然是最高效的利器。对于新入行的朋友来说,命令行仍是必须优先熟练掌握的基本功:只有深刻理解 CLI 背后的配置逻辑和设备行为,才能更好地理解 NETCONF、RESTCONF 等模型驱动协议的设计思想。
对网络工程师而言,在复杂网络环境中,采用基于CLI方式的工具实现网络运维自动化,例如Python的Paramiko,Netmiko工具,仍然是当前的最优解。
二、SNMP协议
SNMP(简单网络管理协议)是一个专门为网络管理而生的“老牌”协议,自诞生至今已有三十余年。它由一组网络管理标准组成,涵盖应用层协议、数据库模式(SMI)和数据对象(MIB),旨在实现对网络设备的统一管理,包括结构化配置的读取和修改。然而,在实际应用中,SNMP 逐渐演变成了网络监控的事实标准,而其配置管理功能则几乎被弃用。
2.1 SNMP 的优势:监控场景的“常青树”
尽管 SNMP 在配置领域存在诸多争议,但在网络监控方面,它依然拥有不可替代的优势:
- 标准化程度高:SNMP 是业界公认的标准协议,几乎所有网络设备都支持,跨厂商兼容性极佳。
- 效率高,适合批量采集:通过 Get/GetBulk 操作,可以一次性获取大量设备的状态信息,非常适合大规模网络的性能监控。
- 实时性好:SNMP 基于 UDP 传输,开销小,响应速度快,结合 Trap 机制可实现主动告警。
- 实现简单,开发成本低:大量开源库(如 Net-SNMP)和监控工具(如 Cacti、Zabbix)原生支持 SNMP,二次开发门槛低。
2.2 SNMP 的局限性:六个无法回避的“槽点”
尽管 SNMP 在监控领域表现出色,但在配置管理方面却暴露出严重不足,这也是它逐渐被 NETCONF/RESTCONF 等新一代协议取代的原因:
- 返回结果可读性差:SNMP 使用 OID(对象标识符)来标识数据,输出的是纯数值或编码,工程师面对一堆数字和字母组合往往“头大”,难以直观理解。
- 数据模型覆盖不足:标准 MIB 库数量有限,很多厂商私有的配置参数没有对应的标准化模型,导致无法读取或需要加载私有 MIB,增加了管理复杂度。
- 安全性参差不齐:SNMP v1 和 v2c 使用明文社区串(community string)作为认证凭证,基本等于“裸奔”;v3 虽然引入了加密和认证,但配置繁琐,至今未广泛普及。
- 无法获取全局配置:SNMP 只能读取单个叶子节点或表项,无法像 CLI 的
show running-config那样获取设备完整的配置快照,因此无法用于配置备份和恢复。 - 写操作功能羸弱:虽然 SNMP 支持 Set 操作,但由于数据模型碎片化、事务性缺失(部分成功部分失败)以及易引发配置冲突,在实际生产中几乎没人用它做配置变更。
- 性能瓶颈明显:频繁的 SNMP 轮询会消耗设备 CPU 资源,当采集数据量较大时,设备可能响应缓慢甚至丢包,时延问题严重。此外,SNMP 的实现质量高度依赖厂商,部分设备存在 MIB 实现不完整、返回数据错误等问题。
2.3 使用SNMP获取数据示例
示例1,获取单节点数据,可读性差
我们使用Python中的pysnmp库,对H3C的交换机执行ObjectType(ObjectIdentity('IF-MIB', 'ifName'))查询设备的第一个端口名称,得到了以下数据:
(ObjectType(ObjectIdentity(<ObjectName value object, tagSet <TagSet object, tags 0:0:6>, payload [1.3.6.1.2.1.31.1.1.1.1.2]>), <DisplayString value object, tagSet <TagSet object, tags 0:0:4>, subtypeSpec <ConstraintsIntersection object, consts <ValueSizeConstraint object, consts 0, 65535>, <ConstraintsUnion object, consts <ValueSizeConstraint object, consts 0, 255>>>, encoding iso-8859-1, payload [GigabitEthernet1/0/1]>),)
从以上数据可以看出,我们只得到端口名称,没有其他的信息,且返回结果包含了大量其他的信息,可读性很差,我们需要专门对数据进行格式化才能更好的阅读。同时我们也没办法直接获取端口各项数据的关联性,例如你查询到的端口名称,端口状态均需要你自己去关联,输出结果需要你自己格式化。
如下图,我们使用脚本对SNMP返回结果数据格式化后的输出。
示例2,无法获取全局配置
例如我们想获得交换机中端口和状态,在CLI命令行中,使用display interface br ,可以查询到如下图内容
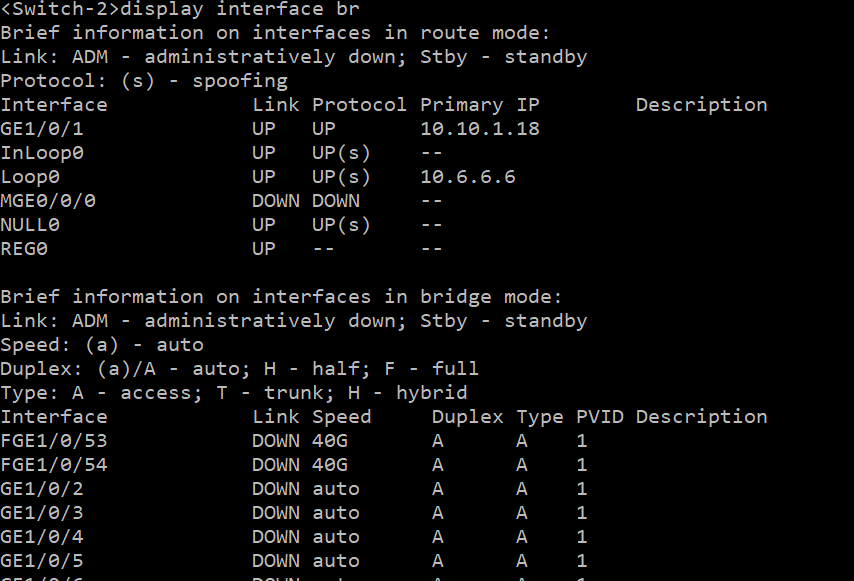
我们可以从命令返回结果中直接看到所有端口名称,状态,速率等信息,但使用SNMP时,我们只能依照节点去查询数据,每个节点数据都是独立的。
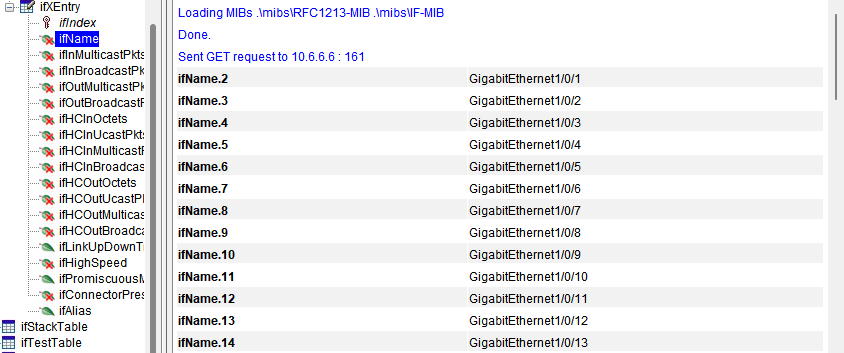
- 使用SNMP查询端口名称
- 使用SNMP查询端口状态
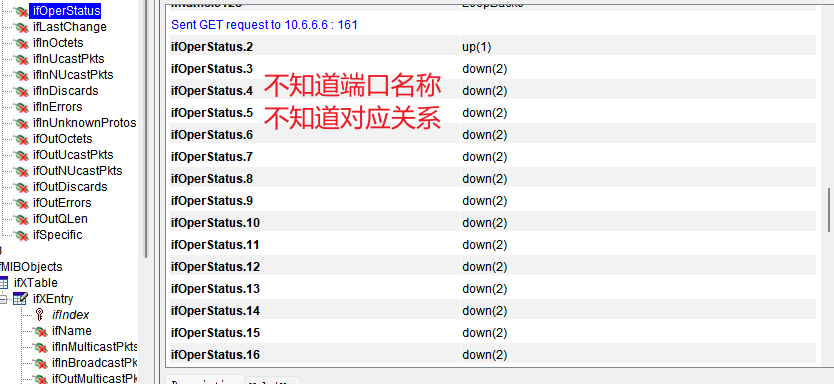
如果我们要查询像display interface br 展示的一些信息,则需要多次的进行查询,且需要手工把各项数据进行关联,格式化。
使用 SNMP 的忠告:请把它留在监控层
鉴于以上局限性,对于网络运维人员,有一条必须牢记的“铁律”:
SNMP 只适合用于巡检、性能采集和告警接收,不要用它来做配置修改!
在实际生产网络中,使用 SNMP Set 命令修改配置很可能引发意想不到的问题——比如因空格、缩进、标识符格式错误导致配置写入失败,或者导致 CLI 界面中对应的配置项变得不可用。这类故障往往排查困难,影响业务稳定。
SNMP 是网络管理史上的里程碑,它首次实现了跨厂商的设备统一监控。但在自动化配置需求爆发的今天,它的缺陷已难以掩盖。对于运维人员而言,理解 SNMP 的优劣,将其用在合适的地方(监控),同时拥抱新一代模型驱动协议(NETCONF/RESTCONF),才是顺应技术发展的明智之举。
三、NETCONF,YANG,RESTCONF
正因为CLI和SNMP有这些痛点,尤其是到了云计算,AI时代,这两样技术在网络管理维护中越来越显得力不从心。IETF在2002年专门开了个会(RFC3535),收集了运维人员的吐槽,然后陆续搞出了 NETCONF、YANG 和 RESTCONF。
3.1 新一代协议三件套:NETCONF + YANG + RESTCONF
简单回顾一下这三个家伙的诞生顺序:
- 2006年,NETCONF 1.0(RFC4741):定义了一种基于XML的RPC机制,程序可以像调用API一样配置网络设备。但当时没规定用什么语言定义数据模型,厂商自己玩自己的。
- 2010年,YANG建模语言(RFC6020):专门为NETCONF设计的数据模型语言,统一了数据定义方式。
- 2011年,NETCONF 1.1(RFC6241):正式把YANG定为NETCONF唯一的数据模型语言,协议也完善了不少。
- 2017年,RESTCONF(RFC8040):顺应RESTful API潮流,用HTTP/HTTPS + JSON的方式,降低了开发门槛。
相关标准文档的发布,确定了以YANG为建模语言、NETCONF协议为主、RESTCONF协议为辅的下一代网络配置管理架构。网络设备厂商对于网络设备的配置管理也遵循了以YANG为建模语言、NETCONF协议为管理协议的设计原则。尤其是在SDN网络环境中,控制器对所辖网络设备的自动化操作大都基于NETCONF协议。
NETCONF严谨且设计完备,已成为下一代的首选网络管理协议。
NETCONF协议的用户一般是云平台、SDN控制器的开发人员,他们将用户的常规操作封装成Web界面。用户在Web表单中填写相关信息,通过程序转换为对应的NETCONF协议操作并发送给指定的网络设备,从而实现对应资源的创建和修改,例如VPC、VXLAN、BGP对等体和云专线等的创建。
网络运维自动化开发人员应该了解NETCONF协议和RESTCONF协议,这将帮助他们加深对网络运维自动化的理解,并在特定场景下,通过这两种协议降低开发的难度(例如更容易获取结构化数据、更容易利用已有云平台或者适用SDN控制器的API编排复杂场景)。
现在的架构已经非常清晰:
YANG负责定义“数据长什么样”,NETCONF和RESTCONF负责“怎么操作这些数据”。
3.2 网管系统愈发完善,有必要学习这些新技术吗?
从技术上来说,如果我让你去努力学习CLI命令行,你可能举双手造成,但Netconf这些技术,似乎是为开发人员准备的——作为传统的通信网络工程师,你可能觉得不需要学习一门编程语言(比如 Python),也不需要深入了解 NETCONF、YANG 这些“底层协议”。毕竟,中兴、华为、H3C 等主流厂商早已将这些技术封装成了友好的 Web 界面或网管系统,日常的点一点、看一看似乎已经足够。
如果只停留在“会用界面”的层面,你可能会在不知不觉中失去对网络的深度掌控力,错失了职业发展的关键跃迁机会。为什么这么说?
第一,界面能覆盖 80% 的常规操作,却无法应对那 20% 的复杂场景。当遇到批量配置上千台设备、跨厂商数据整合、定制化巡检报告,或是需要与内部运维平台对接时,点鼠标的方式就会彻底失效。这时,唯有通过 Python 脚本调用 NETCONF/RESTCONF 接口,才能高效、精准地解决问题。
第二,理解数据模型,才能真正读懂设备的行为。YANG 模型不仅仅是给程序看的,它定义了配置和状态数据的完整结构。当你面对一个诡异的故障,厂商界面只能展示“表象”,而直接查看 YANG 模型定义的底层数据,往往能快速定位根因——这种能力,正是资深专家与普通操作员的分水岭。
第三,自动化不是可选项,而是未来网络工程师的标配技能。如今,AIOps、意图网络、数字孪生等新理念层出不穷,它们的底层都依赖标准化的数据模型和可编程接口。如果不懂 YANG,不懂 NETCONF,你将无法理解这些技术如何运作,更遑论参与设计和优化。企业需要的,早已不是只会敲命令的“手”,而是能通过代码扩展网络能力的“大脑”。
第四,厂商界面无法跨平台,而协议是通用的。今天你用熟了一家厂商的网管,明天换了设备品牌,一切又要从零开始。但 NETCONF/YANG 是 IETF 标准,无论华为、思科还是 Juniper,其底层逻辑一脉相承。掌握了这些“通用语言”,你就能在任何厂商环境中游刃有余。
所以,学习 Python、学习 NETCONF/YANG,不是为了成为开发人员,而是为了成为更强大的网络工程师——一个能在自动化浪潮中掌握主动权、能用代码延伸双手、能在复杂故障前一眼看穿本质的工程师。厂商的界面只是“快捷方式”,而协议和编程能力,才是你真正理解并驾驭网络的“底层操作系统”。
但这里有一个值得深思的问题:为什么各大厂商要投入巨大资源,打造那些功能完善、界面友好的 Web 管理系统或一站式网管平台?核心原因之一,正是为了降低运维门槛,让产品更容易推向市场——让用户无需深入理解底层协议,甚至不需要专业的网络背景,仅凭直观的点击和填写,就能完成大多数日常操作。换句话说,这些精心设计的界面,瞄准的是“让小白也能上手”的目标,甚至可以说,它们的存在,一定程度上是为了“弱化”对资深工程师的依赖。
如果我们仅仅满足于熟练使用这些厂商界面,把自己定位成一个“会点鼠标的手”,那么在即将到来的 AI 时代,我们的核心竞争力在哪里?当 AI 可以自动调用接口、甚至直接操作界面完成配置时,我们与那些“稍有基础的小白用户”之间,又有什么区别?。
淘汰“只会敲命令的手”或许不是今天的事,也不是明天的事,但技术迭代的速度远超我们的想象。那些曾经被认为“铁饭碗”的技能,在自动化浪潮面前正悄然贬值。我们无法预测那一天何时到来,但我们可以决定那一天到来时,自己身在何处。 ——选择权,就在我们每天的学习与积累之中。
四、AI时代,这些技术现在过时了吗?
4.1 技术会过时吗?——NETCONF/YANG 的“保质期”
AI 发展这么快,面对层出不穷的新技术,我该从何学起? 这一章,我们就来聊聊这两个问题。
先说结论:NETCONF/YANG/RESTCONF 完全没过时,它们是当前网络自动化的基石技术,而且在未来5-10年甚至更长时间内,依然是主流。
为什么这么肯定?
- 厂商支持已成标配:所有主流网络设备厂商——Cisco(IOS-XE、NX-OS)、Juniper(Junos)、Arista(EOS)、华为(VRP)、H3C(Comware)等——都已深度支持 NETCONF 和 RESTCONF。设备出厂即内置 YANG 模型,API 接口默认可用。这意味着你买的每一台新设备,都“天生”具备被自动化管理的能力。
- **SDN 控制器的“通用语言”**:无论是商业控制器(如华为 iMaster NCE、Cisco DNA Center)还是开源平台(如 OpenDaylight、ONAP),它们与底层设备通信时,底层协议栈基本都是 NETCONF。学会它,你就掌握了控制器的“底层逻辑”。
- 云原生网络也在借鉴:容器化网络、K8s CNI 插件(如 Calico、Cilium)正越来越多地采用基于 YANG 的模型驱动配置。就连新兴的 gNMI(gRPC Network Management Interface),其数据建模依然基于 YANG,操作语义也大量借鉴 NETCONF。所以,**学会了 NETCONF/YANG,未来再学 gNMI 就是“降维打击”**——技术会演进,但核心思想一脉相承。
当然,技术永远不会停滞。gNMI/gRPC 在性能、流式订阅方面确实比 NETCONF 更强,但它并没有颠覆 YANG,而是用更现代的传输协议(gRPC)承载了 YANG 模型。这恰恰说明:YANG 作为数据建模语言,已经成了网络领域的“SQL”——无论前端如何变化,数据描述的标准始终在那里。
4.2 传统运维人员的学习路径:七步从“鼠标手”到“自动化玩家”
第一步:打好专业理论基础——别让“半桶水”拖后腿
无论你从事的是传输网(OTN/PTN/SPN)、接入网(xPON)、移动核心网(4G/5G),还是传统数通(路由交换),扎实的理论基础永远是第一位。如果你现在还处于“一知半解、抄脚本改脚本”的状态,那么首先要做的是系统学习专业知识——参加厂商培训、考取认证(如华为 HCIP/HCIE、思科 CCNP/CCIE)、阅读官方文档。只有真正理解设备的工作原理,自动化才有意义,否则你只是在“用更快的方式犯错”。
第二步:搭建一个自己的练习环境
很明显,我们绝不能用现网做实验!推荐在你的本地电脑上搭建模拟环境:
-
安装 Python(推荐 3.8 以上版本)和必要的库(如 netmiko、、paramiko、ncclient、requests……)。
-
选择一款设备模拟器:例如 H3C 的 HCL、Cisco 的 CML/EVE-NG、华为的 eNSP(部分支持 NETCONF)。我用的是 H3C HCL,
-
准备几台虚拟设备,搭建一个小型拓扑(例如 3 台交换机组成简单网络),用于后续所有练习。
具体配置可以参考我的文章: 网络自动化学习笔记-H3C 模拟器(HCL)基础环境配置]。
第三步:从最熟悉的 CLI 自动化开始——建立信心
命令行(CLI)必定是你最熟悉的工具,那就从这里切入:
- 工具选型:Python + Paramiko(或 Netmiko)是目前最成熟的 CLI 自动化组合。Netmiko 基于 Paramiko,相当于一个增强版,封装了 SSH 连接和各种设备的命令交互,大大降低了代码复杂度。但也正因为屏蔽了许多过程细节,在学习阶段,我建议先从 Paramiko 入手,理解底层交互机制,后续再使用 Netmiko 也会非常容易上手。
- 目标:先实现非配置类操作的自动化,例如批量备份配置、定时巡检接口状态、收集版本信息。这些任务风险低、见效快,能让你迅速尝到自动化的甜头。
- 进阶:熟练后可尝试批量配置,但务必谨慎。由于 CLI 没有事务性,配置下发即生效,可能出现部分成功、部分失败的情况,只有在执行完毕后才能知道结果。建议先在模拟器或无业务边缘设备上充分测试。
第四步:(可选)了解 SNMP,但不作为重点
SNMP 在监控领域依然有用,但配置功能基本被废弃。我的建议是:简单了解即可——知道如何用 pysnmp 读取几个常用 OID(如 CPU、内存、接口流量),配合 CLI 使用即可。如果时间紧张,完全可以跳过这一步,直接进入 NETCONF 学习。
第五步:进入核心——学习模型驱动协议(NETCONF/RESTCONF)
这是你从“手工操作”迈向“编程管理”的关键一步:
- 学习 YANG 基础:了解 YANG 的核心概念——容器(container)、列表(list)、叶子(leaf)、leaf-list。不必死记语法,关键是看懂厂商提供的 YANG 模型文件,知道配置数据的树形结构。
- 动手操作 NETCONF:推荐 Python 库
ncclient。写几个小脚本:连接设备、获取接口状态、修改 VLAN 描述、保存配置。你会发现,NETCONF 返回的是结构化的 XML 数据,不再需要正则表达式解析,代码瞬间清爽。 - 尝试 RESTCONF:用
requests库发送 HTTP 请求,体验 JSON 格式的轻量操作。找一台支持 RESTCONF 的设备(如 Cisco Catalyst 9000 或启用了 RESTCONF 的华为设备),打开开关,然后用 Postman 或 Python 脚本发几个 GET/PUT 请求,立马就能感受到 RESTful API 的爽快。
第六步:拥抱自动化平台——Ansible 是个好帮手
当你熟悉了基础 API 调用后,可以尝试更高层次的自动化工具:
- Ansible:它的
network模块家族(如junos_config、iosxr_config)底层大量调用 NETCONF。你只需要写简单的 YAML 剧本,Ansible 帮你处理协议细节。这不仅提升了效率,也让你更直观地理解“声明式配置”的理念。 - Postman/Insomnia:如果你偏爱图形界面,可以用这些工具调试 RESTCONF 接口,直观地查看请求响应,加深对 RESTful API 的理解。
第七步:拥抱 AI,让它成为你的“副驾驶”
AI 不是遥远的未来,而是现在就可用上的生产力工具。你不必等到学完以上所有步骤才开始用 AI,现在就可以!
- 辅助学习:遇到不懂的 YANG 语法、Python 报错?直接问 AI(如 ChatGPT、Claude、本地部署的 DeepSeek 等),它能给出通俗的解释和示例代码。
- 辅助编写脚本:用自然语言描述你的需求(如“写一个 Python 脚本,用 ncclient 备份华为交换机的配置”),AI 能生成初稿,你只需调试和优化。
- 构建知识库:将你的设备配置模板、常见故障处理文档喂给 AI,搭建一个私有的运维知识库,以后遇到问题可以直接问“AI 同事”。
- 畅想未来:等你积累了足够多的自动化工具和脚本,完全可以搭建一个本地 AI 调度平台。只需在聊天框里说“帮我把所有设备备份一遍”或“统计全网 IP 使用情况”,AI 就会调用你写好的工具链,自动完成任务。到那时,你就是规则的制定者,AI 是你的执行者。
一个常见问题:我该学NETCONF还是RESTCONF?
-
如果你需要精细化控制,比如要锁定配置、处理多个配置集、实现回滚,NETCONF更合适(功能全,但稍复杂)。
-
如果你只是获取结构化数据,或者想快速集成到Web应用中,RESTCONF更轻量(基于HTTP,数据格式可选JSON,上手快)。
-
实际情况是,两者你都要懂一点,因为它们解决的问题有重叠,但适用场景略有不同。
于我个从建议,优先学习NETCONF,因为它和我们当前的工作内容(查询,各类配置)更贴合,可以直接为工作提供助力,而restconf基于http,可以后续学习。
五、写在最后
技术可以革命,网络只能演进。
传统 CT 行业不同于瞬息万变的 IT 行业,通信网络的第一要义永远是安全、稳定、可靠。正因如此,你大可不必为网络上那些“XX 已死”的言论过度焦虑——CLI 不会消失,因为它依然是最直接的排错手段;SNMP 在监控领域仍占有一席之地;而 NETCONF/RESTCONF 则代表了未来自动化配置的主流方向。技术的迭代从来不是“一刀切”的取代,而是渐进式的融合与演进。
但“不必焦虑”不等于“可以躺平”。演进虽慢,却从不停歇。 今天你熟练点击的每一个 Web 界面,背后都可能是一行行 YANG 模型、一次次 NETCONF 调用;未来你希望 AI 替你完成的每一个复杂任务,都需要你今天积累的代码和脚本作为支撑。
对于传统运维人员,我的建议是:以 CLI 自动化为起点,以 NETCONF/YANG 为进阶方向,以 RESTful API 为加分项。不必追求最新最炫的协议,关键是理解它们背后的思想——模型驱动、接口标准化、自动化闭环。当你发现以前需要写几百行正则匹配的脚本,现在几十行代码就能搞定,而且设备配置再也不会“敲一半失败”的时候,你就会明白,这些技术不是“过时”与否的问题,而是“你用或不用,它就在那里,帮你省下大把时间”。
学习,是唯一能穿越不确定性的力量。从理解一条命令的底层逻辑,到读懂 YANG 模型的数据结构;从用 Paramiko 备份第一份配置,到让 AI 调度你编写的工具链——每一步都在为你积累“不可替代性”。你不是在被 AI 取代,而是在学习如何驾驭 AI。
毕竟,工程师的时间,应该花在架构设计上,而不是反复敲同一段命令。在 AI 时代,这个命题有了更深的含义——让 AI 处理“如何做”,让人类专注于“为什么做”和“做什么”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)