关于大模型训练和推理的一些框架
DeepSpeed框架是微软推出的开源深度学习优化库,针对大规模模型训练提供高效解决方案。其核心优势在于创新的3D并行技术(数据并行、流水线并行、张量并行)和ZeRO内存优化,显著降低显存占用并提升计算效率。通过梯度累积、动态精度调整等技术,DeepSpeed能支持万亿参数级别的模型训练。实践案例展示了其与ChatGLM模型结合的微调流程,包括环境配置、分布式训练实现及推理部署。相比传统方法,De
一 训练框架概述
ChatGPT模型已成为人工智能领域的研究热点,引发各大企业竞相投入。然而,这类模型的训练面临巨大挑战:不仅需要消耗大量时间和计算资源,随着模型规模和数据量的增长,训练成本更是呈指数级上升。此外,现有开源系统普遍存在机器利用率低下、吞吐量受限等问题,严重制约了训练效率的提升。
现有分布式训练框架
训练框架地址:
Megatron-LM: https://github.com/NVIDIA/Megatron-LM
DeepSpeed: https://github.com/microsoft/DeepSpeed
mesh-tensorflow: https://github.com/tensorflow/mesh
fairscale: https://github.com/facebookresearch/fairscale


微软开发的Deepspeed框架为主流训练框架,主要原因:
具有高效、易用且功能强大的特点。
作为开源系统,Deepspeed框架在提升训练效率的同时,也显著提高了开发生产力。
采用这一框架能显著降低时间和资金投入,帮助我们更高效地进行模型构建与训练,进而提升项目整体成效。
二、Deepspeed框架介绍
DeepSpeed是微软推出的开源深度学习优化库,专注于提升大规模模型训练的效率和扩展性。该框架集成了多项创新技术,包括模型并行化、梯度累积、动态精度调整以及本地混合精度训练等,显著加速了模型训练过程。
此外,Deepspeed还提供了一系列实用工具,包括分布式训练管理、内存优化和模型压缩等功能,帮助开发者高效管理并优化大规模深度学习训练任务。作为基于PyTorch构建的框架,Deepspeed只需简单修改即可实现快速迁移。目前,该框架已成功应用于语言模型、图像分类、目标检测等多个大规模深度学习项目。在深度学习模型的软件体系架构中,Deepspeed发挥着关键作用,具体如下图所示:
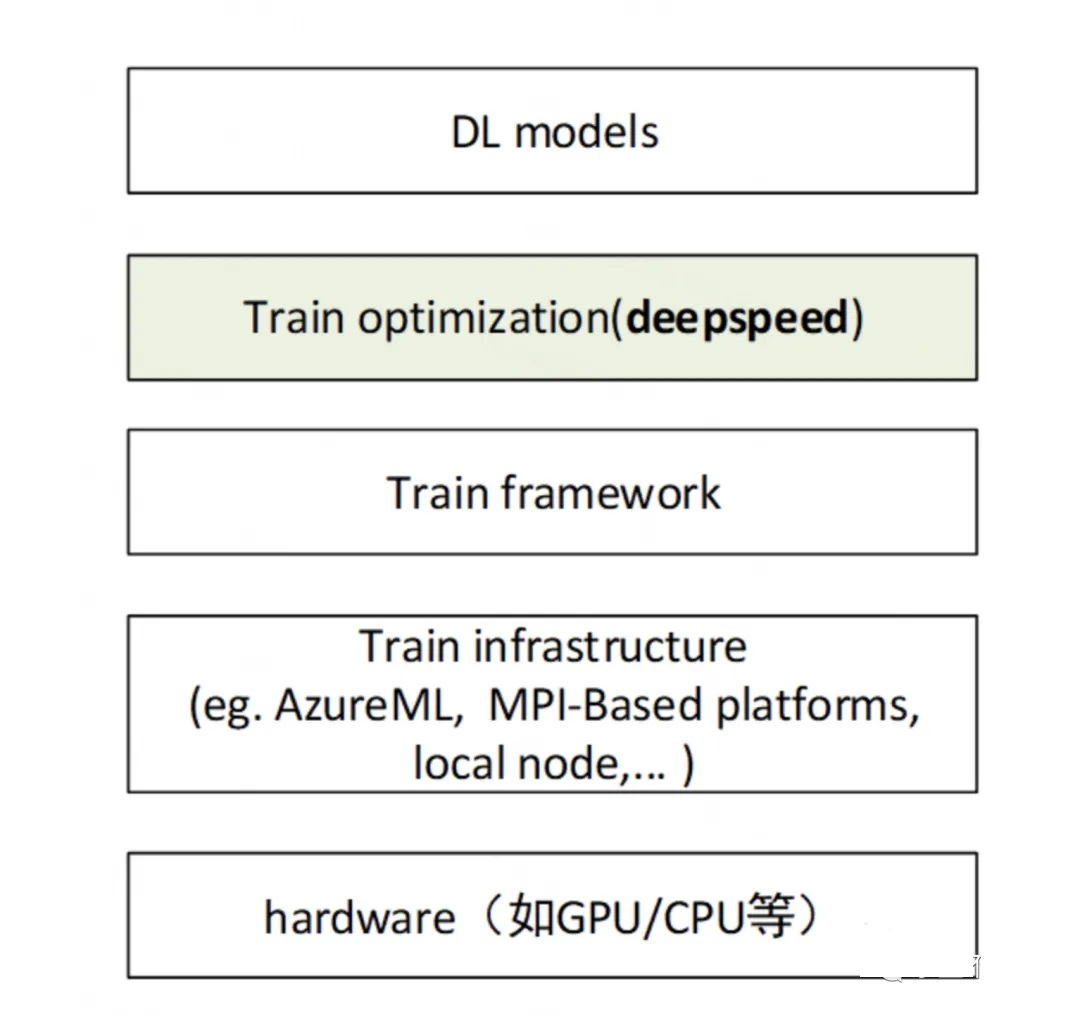
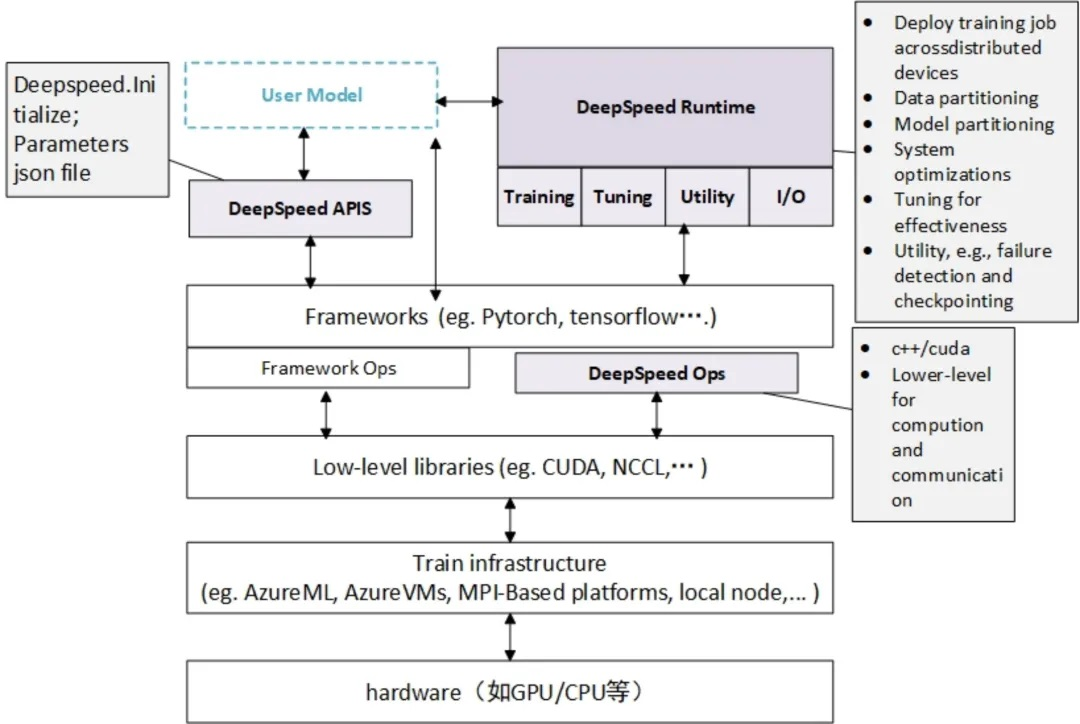
Deepspeed软件架构主要分为三个部分,如下图所示:
APIs
我们提供简洁易用的API接口,用户仅需调用少量接口即可完成模型训练和推理任务。核心接口包括:
initialize接口:用于初始化引擎,配置训练参数及优化策略- 参数配置:通过
config.json文件保存相关设置参数
Runtime
运行时组件,是Deepspeed的核心组件,主要用于管理、执行和性能优化。该组件包括将训练任务部署到分布式设备、数据分区和模型分区、系统优化、微调、故障检测、checkpoints保存和加载等功能,并使用Python语言实现。
Ops
底层内核实现,使用C++和CUDA优化计算和通信。此组件涵盖了许多关键技术。
Deepspeed是一款高效、可扩展的深度学习优化库,其中一些核心技术如下:
- ZeRO(Zero Redundancy Optimizer)
ZeRO是一种专为大规模分布式深度学习设计的内存优化技术。它通过以下方式显著提升训练效率:
- 消除数据并行进程中的内存冗余,将模型状态参数、梯度和优化器状态进行分布式划分而非复制
- 采用动态通信调度机制,在分布式设备间智能共享必要状态
- 保持数据并行原有的计算粒度和通信效率
基于ZeRO技术,DeepSpeed实现了三大并行训练方式:
- 数据并行
- 流水线并行
- 张量切片模型并行
这种创新架构不仅提高了显存和计算资源利用率,更使训练万亿参数级别的超大规模模型成为可能。
- 3D并行(DP MP PP)
DeepSpeed通过基于ZeRO的3D并行技术有效解决了数据并行和模型并行的内存冗余问题。该技术采用三维划分策略处理模型状态参数、梯度和优化器状态,并配合动态物理内存分配机制,显著降低了内存占用,同时提升了计算效率。
- 梯度累积
DeepSpeed采用梯度累积技术来扩大有效批量规模,从而提升训练效率。该方法通过多次前向和反向传播来累积梯度,最终达到较大批量的训练效果。
综合运用这些创新技术,DeepSpeed构建了高效且可扩展的深度学习训练框架,显著提升了训练速度并优化了模型性能。
三、DeepSpeed框架实践
下面以DeepSpeed框架与ChatGLM微调模型相结合的实践案例为例,演示分布式训练的过程(注意这个案例仅用于说明,实际应用时可能会有所不同)
环境准备
conda install pytorch==1.12.0 \
torchvision==0.13.0 \
torchaudio==0.12.0 \
cudatoolkit=11.3 -c pytorch
pip install deepspeed==0.8.1
sudo yum install openmpi-bin libopenmpi-dev
pip install mpi4py1 下载预训练模型
https://huggingface.co/THUDM/chatglm-6b/tree/main
2 准备样本
训练数据通常由三个部分组成:prompt、response和history。引入用户特征数据可以提升模型训练效果。
样本的格式:
{
"prompt": "什么事。\n[姓名]:张三\n[年龄]:45.0\n[性别]:男士\n[省份]:湖北",
"response": "打扰您了,给您介绍下近期的优惠活动?",
"history": [
[
"",
"您好,请问是张先生吗?"
],
[
"是。",
"喂,您好,我这是您专属客服顾问。"
]
]
}
准备训练代码
git clone https://github.com/THUDM/ChatGLM-6B.git
微调训练核心流程类代码
import torch
import deepspeed
from torch.utils.data import RandomSampler, DataLoader
from torch.utils.data.distributed import DistributedSampler
...
# 一、初始化DeepSpeed引擎
model_engine, optimizer, _, _ = deepspeed.initialize(args=cmd_args,model=model,model_parameters=params)
# 二、分布式环境设置
deepspeed.init_distributed()
....
# 三、预加载模型和训练数据
model = ChatGLMForConditionalGeneration.from_pretrained(args.model_dir)
tokenizer = ChatGLMTokenizer.from_pretrained(args.model_dir)
# DataLoaders creation:
train_dataloader = DataLoader(train_dataset,
batch_size=conf["train_micro_batch_size_per_gpu"],
sampler=RandomSampler(train_dataset),
collate_fn=coll_fn,
drop_last=True,
num_workers=0)
....
# 四、训练循环
for step, batch in enumerate(train_dataloader):
#用于向前传播和损失计算
loss = model_engine(batch)
#向后传播
model_engine.backward(loss)
#优化器更新
model_engine.step()在启动训练前,需完成以下准备工作:
- 配置服务器间SSH免密登录
- 设置.deepspeed_env环境变量
- 调整训练参数配置
nohup deepspeed --hostfile=myhostfile --master_port 9000 main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file /data/train.json \
--test_file /data/dev.json \
--prompt_column prompt \
--response_column response \
--history_column history \
--overwrite_cache \
--model_name_or_path /data/pre_model/chatglm/chatglm-6b \
--output_dir ./output/out-chatglm-6b-ft-le-4 \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 50000 \
--logging_steps 10 \
--save_steps 10000 \
--learning_rate $LR \
--fp16 &以下示例展示了如何使用ChatGLM模型进行推理服务。需要说明的是,当前示例仅作演示用途,实际生产环境通常采用TorchServing部署的分布式推理服务方案,具体实现可能有所差异。
首先需要安装额外的依赖 pip install fastapi uvicorn,然后运行仓库中的 api.py:
pip install fastapi uvicorn
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
得到的返回值为
{
"response":"你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。",
"history":[["你好","你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]],
"status":200,
"time":"2023-06-03 21:38:40"
}3 ZeRO(零冗余优化器)
推荐阅读:图解大模型训练之:数据并行( DeepSpeed ZeRO,零冗余优化)
ZeRO(Zero Redundancy Optimizer)是一项突破性的大规模深度学习模型训练优化技术。该技术通过智能地消除内存冗余、优化通信流程和平衡计算负载,显著提升了训练效率,使研究人员能够突破硬件限制,训练前所未有的超大规模模型。
ZeRO论文首先分析了模型训练中内存主要消耗在两个方面:
model states:模型状态,包括包括优化器参数(例如Adam的动量和方差)、梯度、模型参数
residual states:剩余状态,包括包括激活函数、临时缓冲区、内存碎片
ZERO分别使用ZeRO-DP和ZeRO-R来优化model states和residual states。
- ZeRO-DP包括三个阶段(以64GPU的混合精度训练举例,采用Adam优化器)

ZeRO-R采用三阶段优化策略有效降低内存占用:
- 激活值分割技术分散存储压力
- 固定缓冲区设计避免规模膨胀
- 生命周期感知的内存管理消除碎片化问题
ZeRO通过优化内存使用和动态通信机制,显著降低了模型训练的内存消耗,同时维持了计算与通信的高效性,从而能够在有限计算资源下支持更大规模模型的训练。
核心思路:如果数据在计算后即可丢弃,等需要时再从临时存储中提取,这样就能节省存储空间。
(1)ZeRO-Offload
核心思想
- 显存不够,内存来凑。
将数据存储卸载到CPU,而将计算任务集中在GPU上,相比跨机方案,是否能同时降低显存占用并减少通信压力?
基本原理
forward和backward计算量高,因此和它们相关的部分,例如参数W(fp16),activation,就全放入GPU。
update的部分计算量低,因此和它相关的部分,全部放入CPU中。例如W(fp32),optimizer states(fp32)和gradients(fp16)等。
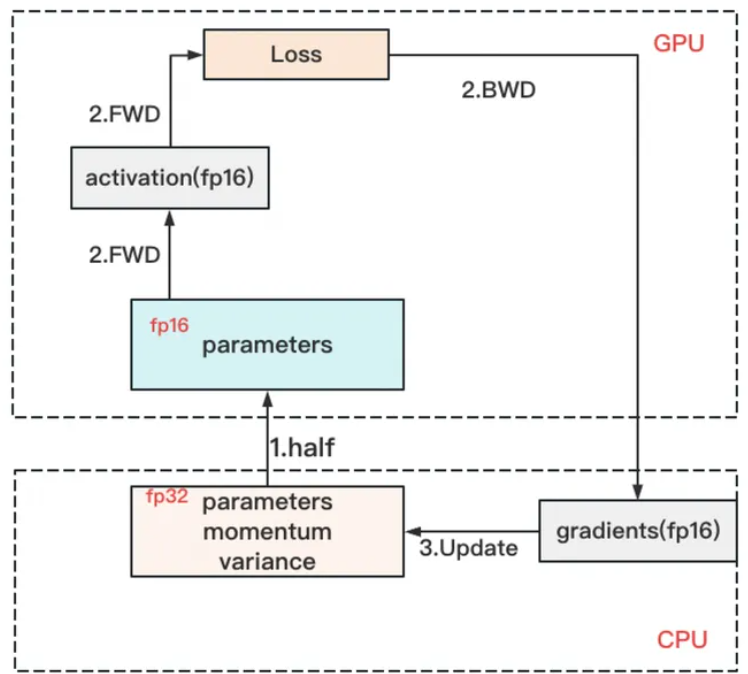
(2)ZeRO-Infinity
与ZeRO-Offload原理类似,找个除GPU之外的地方存数据,需要使用的时候再获取。
4 DP、MP、PP
推荐阅读:深度学习模型训练显存占用分析及DP、MP、PP分布式训练策略
(1)Data Parallelism (DP)数据并行
主要思想:将模型复制到多个GPU设备上,每张GPU都保存一个模型副本。这些设备可以并行处理输入的数据批次。
具体过程如下所示:
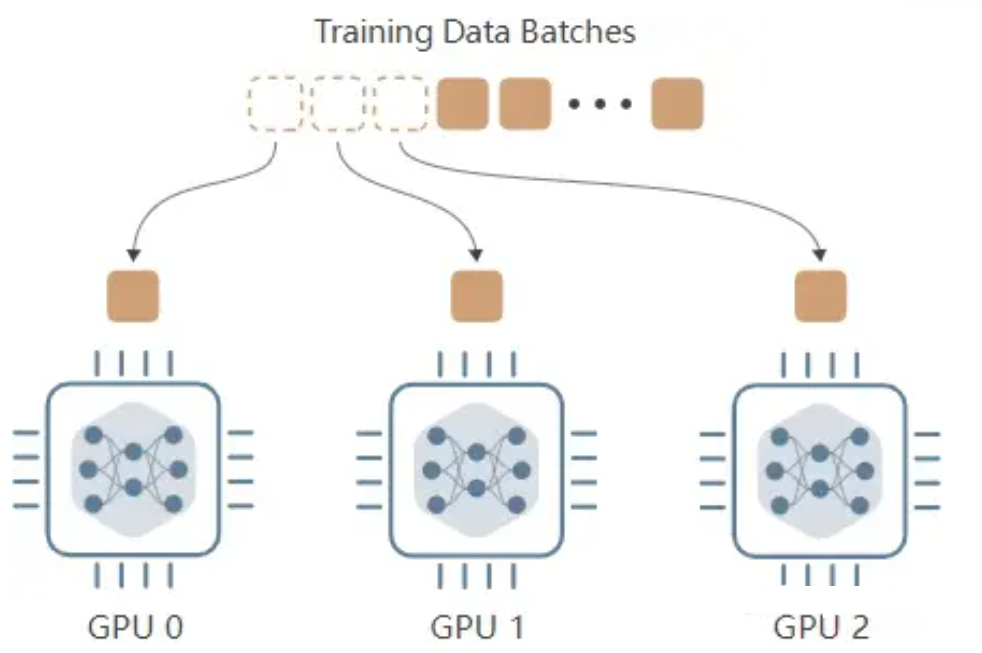
主要特点:
数据并行策略无法减少总体训练内存消耗,这是显而易见的,因为每个GPU都需要存储完整的模型副本,从而产生额外的内存开销。此外,当模型参数规模超过单张GPU的存储容量时,无论扩展到8张还是100张GPU,数据并行算法都将无法实施,训练过程自然也无法进行。
数据并行的优势在于显著提升训练速度,因为每个设备仅需处理部分训练数据。然而,由于设备间梯度交换会产生通信开销,速度提升与设备数量并非线性正比关系。
(2)Model Parallelism (MP)模型并行
当模型参数量过大时,数据并行(DP)方案将不再适用。为此,模型并行(MP)技术应运而生。与DP将完整模型复制到每个设备不同,MP采用模型拆分策略:每个GPU仅存储部分模型权重。在前向传播过程中,数据会依次流经各个设备,前一个设备的输出作为后一个设备的输入。
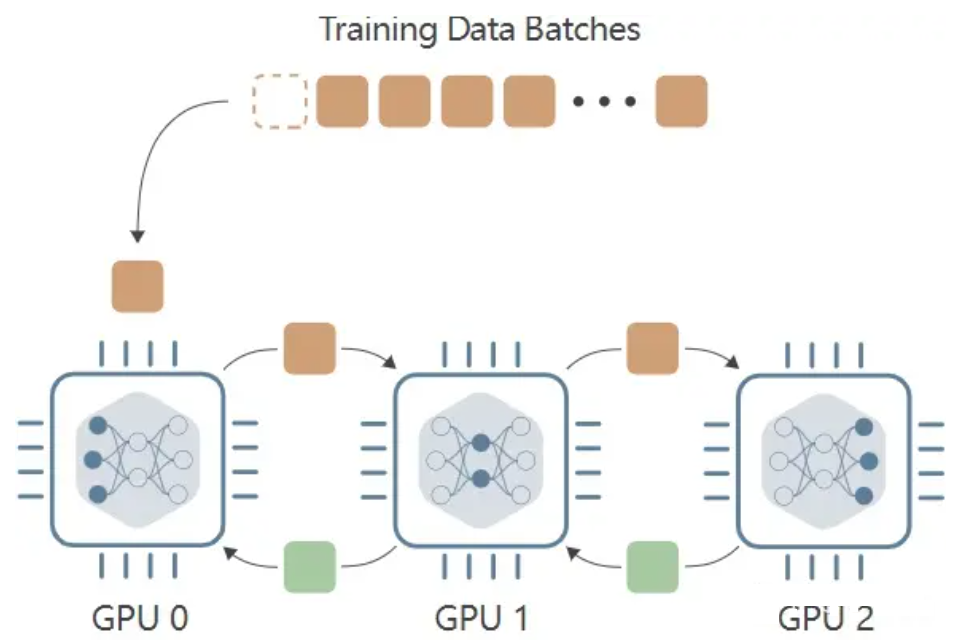
主要特点:
- 模型并行的优势在于面对参数量很大的模型,能够有效减少模型对显存的占用。
其缺点显而易见:若使用三个GPU设备,数据并行可以同时利用这三个GPU进行训练;而模型并行则需依靠这三个设备共同完成一次训练,导致显著的时间损耗。
(3)Pipeline Parallelism (PP)流水线并行
流水线并行(PP)是模型并行(MP)的一种实现方式,通过将输入数据分割为多个"微批次"(micro-batches)来优化设备利用率。该方法采用参数延迟更新机制,即仅在处理完所有微批次后才统一更新模型参数。这种设计允许设备在处理当前微批次的同时,其他设备可以并行处理后续微批次,从而有效减少设备空闲时间。
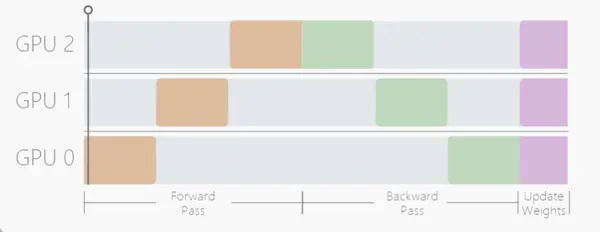
PyTorch 通过 torch.distributed.pipeline.sync.Pipe 类内置了对流水线并行性的支持。不过,该类的两个主要限制是:
(1) 它只在模型作为 torch.nn.Sequential 模块实现时起作用;
(2) 它要求每个模块的输入和输出要么是单个张量,要么是张量的元组
总结
如何选择适合的分布式训练框架,重点介绍DeepSpeed框架的核心优势。同时详细讲解如何使用DeepSpeed构建分布式训练实践
目录

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)