八、训练监控与调试
训练大模型是一个漫长且充满不确定性的过程。即使精心设计了超参数和并行策略,训练过程中仍可能出现各种问题,如损失发散、梯度爆炸、过拟合等。有效的监控与调试能够帮助我们及时发现问题、定位原因并采取纠正措施,确保训练顺利收敛。本章将介绍训练过程中的关键监控指标、常用工具以及常见问题的调试方法。
训练大模型是一个漫长且充满不确定性的过程。即使精心设计了超参数和并行策略,训练过程中仍可能出现各种问题,如损失发散、梯度爆炸、过拟合等。有效的监控与调试能够帮助我们及时发现问题、定位原因并采取纠正措施,确保训练顺利收敛。本章将介绍训练过程中的关键监控指标、常用工具以及常见问题的调试方法。
1 损失曲线
损失函数值是训练过程中最直接的反馈。通过观察损失曲线的变化,可以判断模型是否在学习、收敛速度是否正常,以及是否出现异常。
1.1 正常收敛曲线
理想形状:训练损失(training loss)和验证损失(validation loss)随迭代次数(或 step)稳步下降,最终趋于平缓。
┌─────────────────────────────────────────────────────────────────┐
│ 正常收敛曲线形态 (理想 "L" 型) │
├─────────────────────────────────────────────────────────────────┤
│ Loss 值 │
│ ▲ │
│ │ 📉 训练损失 (Training Loss) │
│ 高 │ \ │
│ │ \ 📉 验证损失 (Validation Loss) │
│ │ \ \ │
│ │ \______\___________ (两者平行,间距小) │
│ │ \ \ │
│ 低 │ \__________\________ (趋于平缓/收敛) │
│ │ │
│ └──────────────────────────────────────────────► Step/Epoch │
│ [初期: 快降] [中期: 缓降] [后期: 平稳] │
└─────────────────────────────────────────────────────────────────┘
案例解析:图像分类模型训练
场景:训练 ResNet50 识别 ImageNet 数据集。
阶段拆解
1、初期 (Step 0-2k):Loss 从 6.9 (随机猜测) 迅速降至 2.0;
含义:模型正在学习基础特征(边缘、颜色、纹理),梯度大,更新快;
2、中期 (Step 2k-10k):Loss 从 2.0 缓慢降至 0.8;
含义:模型在学习高阶语义(猫耳朵形状、车轮结构),需要精细调整权重;
3、后期 (Step 10k+):Loss 稳定在 0.75 左右,曲线变平;
含义:模型已收敛,继续训练收益极低。此时验证集 Loss 也为 0.78,间隙仅为 0.03,说明泛化能力强;
关键判断
1、整体趋势向下;
2、验证集曲线紧随训练集,未出现大幅分离;
3、允许微小的锯齿状波动(由 Batch 采样噪声引起),但不影响大局;
1.2 异常曲线:NaN 爆炸 (Loss Explosion)
现象
损失值突然变成 NaN 或 Inf,曲线中断或垂直冲出图表;
┌─────────────────────────────────────────────────────────────────┐
│ 异常曲线:NaN / 梯度爆炸 │
├─────────────────────────────────────────────────────────────────┤
│ Loss 值 │
│ ▲ │
│ │ ❌ NaN (数值溢出) │
│ 高 │ /| │
│ │ / | │
│ │ / | │
│ │ 正常下降 ___/ | (突然垂直飙升) │
│ │ / | │
│ │ / | │
│ 低 │___________________/ | │
│ │ └───► 程序报错或停止 │
│ └──────────────────────────────────────────────► Step │
│ [正常] [突发点] │
└─────────────────────────────────────────────────────────────────┘
案例解析:大语言模型预训练
场景:使用 FP16 混合精度训练 7B 参数模型;
故障复现:
训练至 Step 5432 时,Loss 突然从 2.1 跳变为 NaN。
日志报错:RuntimeError: CUDA error: device-side assert triggered 或 Gradient overflow.
根因分析:
1、梯度爆炸:某层激活值过大,反向传播时梯度呈指数级增长,超出 FP16 表示范围 (65504);
2、脏数据:该 Batch 中包含长度为 0 的文本或特殊字符,导致除以零错误;
3、学习率过高:优化器步长太大,直接跳出损失函数的定义域;
调试方案:
1、梯度裁剪 (Gradient Clipping):设置 max_norm=1.0,强制限制梯度范数;
2、检查数据:在 DataLoader 中加入断言,过滤掉空样本或异常长样本;
3、调整精度:若 FP16 不稳定,切换至 BF16 (Bfloat16),其动态范围更大,不易溢出;
4、降低学习率:将 LR 从 2e-4 降至 1e-4 重试;
1.3 异常曲线:过拟合 (Overfitting)
现象:训练损失持续下降,但验证损失在某个点后开始反弹上升,两者形成明显的“剪刀差”。
┌─────────────────────────────────────────────────────────────────┐
│ 异常曲线:过拟合 (Overfitting) │
├─────────────────────────────────────────────────────────────────┤
│ Loss 值 │
│ ▲ │
│ │ 📉 训练损失 (持续下降,甚至接近 0) │
│ 高 │ \ │
│ │ \ │
│ │ \_____________ │
│ │ \ 📈 验证损失 (开始上升!) │
│ │ \ / │
│ │ \_______/ (最佳 checkpoint 位置) │
│ │ \ │
│ 低 │ \ │
│ │ \ │
│ └──────────────────────────────────────────────► Step │
│ [学习阶段] [拐点] [过拟合阶段] │
│ 早停点 (Early Stop) │
└─────────────────────────────────────────────────────────────────┘
案例解析:小数据集上的复杂模型
场景:用只有 1000 张图片的数据集训练一个巨大的 ViT-Large 模型;
故障复现:
1、Step 0-500:训练 Loss 和验证 Loss 同步下降;
2、Step 500 (拐点):验证 Loss 达到最低点 0.4;
3、Step 500-1000:训练 Loss 继续狂跌至 0.05 (模型死记硬背了所有训练图),但验证 Loss 却回升到 0.8 (遇到新图就错);
根因分析:
1、模型容量过大 vs 数据量过小;
2、模型记住了训练集的噪声和特定细节,丧失了泛化能力;
调试方案:
1、早停 (Early Stopping):监控验证 Loss,一旦连续 N 个 epoch 不下降,立即停止训练并回滚到 Step 500 的权重;
2、正则化:增加 Dropout (如 0.1 -> 0.3) 或 权重衰减 (Weight Decay);
3、数据增强:对训练图片进行随机裁剪、翻转、色彩抖动, artificially 增加数据多样性;
1.4 异常曲线:剧烈震荡 (High Oscillation)
现象:损失曲线像“心电图”一样剧烈上下跳动,没有明显的下降趋势,或者下降极其缓慢。
┌─────────────────────────────────────────────────────────────────┐
│ 异常曲线:剧烈震荡 (Oscillation) │
├─────────────────────────────────────────────────────────────────┤
│ Loss 值 │
│ ▲ /\ /\ /\ │
│ 高 │ / \ / \ / \ (无明确下降趋势) │
│ │ / \ / \ / \ │
│ │ / \/ \/ \ │
│ │ / \ / │
│ │ / \ / │
│ 低 │/ V │
│ └──────────────────────────────────────────────► Step │
│ [学习率过高] 或 [Batch Size 过小] 导致梯度不稳定 │
└─────────────────────────────────────────────────────────────────┘
案例解析:小 Batch 训练生成模型
场景:显存受限,将 Batch Size 设为 2,学习率保持默认值 1e-3;
故障复现:
1、Loss 在 1.5 到 3.0 之间反复横跳;
2、每隔几步就有一个极高的峰值,紧接着一个极低的谷值;
根因分析:
1、Batch Size 太小:每个批次的数据代表性不足,梯度估计方差极大(噪声大);
2、学习率过高:相对于当前的梯度噪声,步长太大了,导致参数在最优解附近“反复横跳”而无法落入谷底;
3、缺少 Warmup:训练初期直接使用大学习率;
调试方案:
1、增加 Batch Size:尽可能增大单卡 Batch,或使用 梯度累积 (Gradient Accumulation) 模拟大 Batch;
2、降低学习率:将 LR 降低 10 倍 (1e-3 -> 1e-4);
3、引入 Warmup:前 5% 的步数线性增加学习率,让模型先“站稳”再跑;
4、可视化技巧:在绘图时使用 EMA (指数移动平均) 平滑曲线,以便看清背后的真实趋势;
1.5 异常曲线:平台期 (Plateau)
现象:损失值下降到一定程度后,变成一条直线,长时间不再下降。
┌─────────────────────────────────────────────────────────────────┐
│ 异常曲线:平台期 (Plateau) │
├─────────────────────────────────────────────────────────────────┤
│ Loss 值 │
│ ▲ │
│ 高 │ \ │
│ │ \ │
│ │ \____ │
│ │ \________________________________ (死水平线) │
│ │ │
│ │ │
│ 低 │ │
│ └──────────────────────────────────────────────► Step │
│ [初期下降] [陷入局部最优/学习率过低] │
└─────────────────────────────────────────────────────────────────┘
案例解析:微调预训练模型
场景:在下游任务微调 BERT,使用固定学习率 1e-5;
故障复现:
1、前 1000 step Loss 下降明显;
2、之后 5000 step Loss 恒定在 0.45,纹丝不动;
根因分析:
1、学习率过低:参数更新幅度太小,无法跳出当前的局部极小值或鞍点;
2、优化器动量耗尽:SGD 等优化器在没有梯度的方向上停止了运动;
调试方案:
1、学习率重启 (Restart):暂时提高学习率,打破僵局,然后再衰减;
2、更换调度策略:使用 Cosine Annealing with Warm Restarts;
3、检查数据标签:确认是否所有剩余样本都已被完美分类(如果是,则无需担心),或者是否存在标签噪声导致无法进一步优化;
1.6 小结
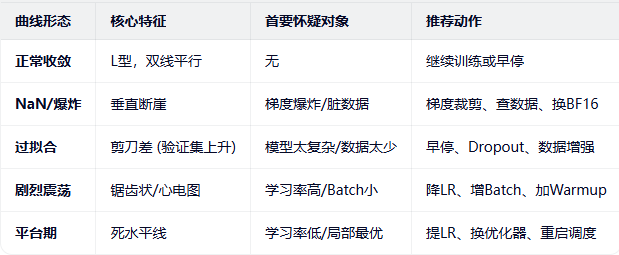
2 评估指标(Evaluation Metrics)
损失函数虽然是训练的直接目标,但并不能完全反映模型在下游任务上的表现。因此,需要定期在验证集或基准测试上计算评估指标。
┌─────────────────────────────────────────────────────────────────┐
│ 模型评估体系:从内在困惑到外在能力 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 【阶段 1: 训练监控】内在指标 (Intrinsic) │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 📊 困惑度 (Perplexity, PPL) │ │
│ │ • 定义:PPL = exp(CrossEntropyLoss) │ │
│ │ • 含义:模型对下一个词的“惊讶程度” │ │
│ │ • 趋势:越低越好 (理想值接近 1) │ │
│ │ • 局限:受分词器 (Tokenizer) 影响大,不直接等于生成质量 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ (定期保存 Checkpoint) │
│ │
│ 【阶段 2: 能力验证】外在指标 (Extrinsic / Downstream) │
│ ┌───────────────────────┬───────────────────────────────────┐ │
│ │ 理解类 (Understanding) │ 生成类 (Generation) │ │
│ ├───────────────────────┼───────────────────────────────────┤ │
│ │ • GLUE / SuperGLUE │ • BLEU / ROUGE (文本相似度) │ │
│ │ (情感/蕴含/推理) │ • HumanEval (代码通过率 @k) │ │
│ │ • MMLU │ • Truthfulness (事实性) │ │
│ │ (57 学科知识广度) │ • Coherence (流畅度/逻辑) │ │
│ └───────────────────────┴───────────────────────────────────┘ │
│ │
│ 关键洞察: │
│ Loss ↓ 且 PPL ↓ ≠ 下游任务准确率 ↑ │
│ (需警惕“过拟合训练分布”但“泛化能力差”的情况) │
│ │
└─────────────────────────────────────────────────────────────────┘
2.1 困惑度(Perplexity,PPL)
核心概念:语言模型的“不确定性”量化指标。
公式: PPL=exp(CrossEntropyLoss)
直观理解:如果 PPL=10 ,意味着模型在预测下一个词时,相当于在 10 个候选词 中随机猜测。 PPL 越低,模型越“自信”且准确;
┌─────────────────────────────────────────────────────────────────┐
│ 交叉熵损失 (Loss) vs 困惑度 (PPL) 转换 │
├─────────────────────────────────────────────────────────────────┤
│ Loss 值 (L) 计算:PPL = e^L PPL 值 │
│ │
│ 3.0 ──────────────► exp(3.0) ≈ 20.08 (模型很迷茫,约 20 选 1) │
│ 2.0 ──────────────► exp(2.0) ≈ 7.39 (中等不确定性) │
│ 1.0 ──────────────► exp(1.0) ≈ 2.72 (表现良好,约 3 选 1) │
│ 0.5 ──────────────► exp(0.5) ≈ 1.65 (非常自信) │
│ 0.0 ──────────────► exp(0.0) = 1.0 (完美预测,不可能达到) │
│ │
│ 趋势解读: │
│ 若 Training Loss 下降,但 Validation PPL 上升 --> 严重过拟合信号 │
└─────────────────────────────────────────────────────────────────┘
案例解析:分词器陷阱与过拟合
场景 A:分词器导致的数值不可比
1、现象:模型 A (BPE 分词) 的验证集 PPL 为 15.0,模型 B (WordPiece 分词) 的 PPL 为 22.0;
2、误区:直接认为模型 A 比模型 B 好;
3、真相:BPE 将单词切分得更细(如 “playing” -> “play”, “ing”),序列变长,单个 token 预测难度降低,天然导致 PPL 偏低。不同分词器的 PPL 严禁直接对比;
4、对策:对比 PPL 必须在相同分词器、相同数据集、相同预处理下进行;
场景 B:Loss 降了,PPL 涨了(过拟合)
1、现象:训练到第 10,000 step,Training Loss 从 1.2 降至 0.8,但 Validation PPL 从 8.0 升至 12.0;
2、原因:模型死记硬背了训练集中的特定句子顺序,失去了对未见文本的泛化概率估计能力;
3、动作:立即停止训练,回滚到 Validation PPL 最低点(如第 8,000 step)的 Checkpoint;
2.2 下游任务准确率 (Downstream Accuracy)
核心概念:模型解决实际问题的能力。这是衡量大模型价值的“金标准”。
┌─────────────────────────────────────────────────────────────────┐
│ 主流 NLP 基准测试能力雷达 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ [知识广度] [代码能力] │
│ ▲ ▲ │
│ │ MMLU │ HumanEval │
│ │ (57 学科选择题) │ (Python 函数生成) │
│ │ 准确率 % │ Pass@1 / Pass@10 │
│ │ │ │
│ ┌─────────┴─────────┐ ┌─────────┴─────────┐ │
│ │ │ │ │ │
│ │ 通用理解 │ │ 生成质量 │ │
│ │ │ │ │ │
│ │ GLUE / SuperGLUE │ │ BLEU / ROUGE │ │
│ │ (情感/推理/蕴含) │ │ (机器翻译/摘要) │ │
│ │ Accuracy / F1 │ │ (n-gram 重叠率) │ │
│ └─────────┬─────────┘ └─────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ [问答抽取] [常识推理] │
│ │ SQuAD │ HellaSwag │
│ │ (Exact Match) │ (多选常识) │
│ │
└─────────────────────────────────────────────────────────────────┘
案例解析:指标选择的艺术
A 案例 1:MMLU (知识广度测试)
1、任务:给模型一道医学考题:“下列哪种药物用于治疗高血压?A. 阿司匹林 B. 利血平…”
2、评估方式:Few-shot Prompting (给几个例子) + 计算准确率 (Accuracy);
3、意义:如果模型在预训练中期 MMLU 分数停滞,说明它还没有“读够”百科类数据,或者学习率调度需要调整以加强知识记忆;
B 案例 2:HumanEval (代码生成)
1、任务:输入自然语言描述 “写一个函数判断字符串是否是回文”,模型生成 Python 代码;
2、评估方式:执行测试用例。不是看代码长得像不像,而是运行代码,看是否通过所有单元测试;
3、指标:Pass@k (生成 k 个样本中至少有一个通过的概率);
4、注意:传统 BLEU 分数在此无效,因为代码差一个字符就报错,但 BLEU 可能给很高分数;
C 案例 3:生成任务的陷阱 (BLEU/ROUGE)
1、场景:训练一个对话机器人;
2、现象:模型生成的回答与参考答案重合度高,ROUGE-L 分数很高 (0.6),但人类觉得回答很生硬、甚至逻辑不通;
3、原因:BLEU/ROUGE 基于 n-gram 重叠,无法评估逻辑连贯性、事实正确性或幽默感;
4、对策:
4.1 人工评估 (Human Eval):抽样打分(相关性、安全性、有用性);
4.2 LLM-as-a-Judge:用更强的模型(如 GPT-4)来给当前模型的生成结果打分;
4.3 轻量级代理:在训练间隙,仅跑 HellaSwag (常识补全) 或 LAMBADA (长依赖预测),因为它们计算快且与最终能力相关性高;
3 梯度统计(Gradient Statistics)
梯度是反向传播的“引擎”,其统计信息(范数、分布)直接决定了模型参数更新的方向和步长。监控梯度如同监控引擎的转速和震动,是诊断训练稳定性的核心手段。
┌─────────────────────────────────────────────────────────────────┐
│ 梯度监控系统:从全局范数到层内分布 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 【输入】反向传播计算出的原始梯度 (Raw Gradients) │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 统计层 A: 全局指标 (Global Metrics) │ │
│ │ • 梯度范数 (Gradient Norm, L2) │ │
│ │ - 作用:判断“爆炸”或“消失” │ │
│ │ - 阈值参考:正常 (1~10), 爆炸 (>1000), 消失 (<1e-6) │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 统计层 B: 分布形态 (Distribution Shape) │ │
│ │ • 直方图 (Histogram) │ │
│ │ - 作用:观察是否集中在 0,是否存在长尾异常值 │ │
│ │ • 层间对比 (Layer-wise Comparison) │ │
│ │ - 作用:检测“中间层阻塞”或“头重脚轻” │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ (决策与干预) │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 优化器动作 │ │
│ │ • 梯度裁剪 (Clipping): 若 Norm > Threshold, 按比例缩放 │ │
│ │ • 学习率调整: 若持续消失/爆炸,动态调整 LR │ │
│ │ • 初始化重调: 若层间差异过大,检查 Weight Init │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
3.1 梯度范数(Gradient Norm)
核心概念:梯度的“长度”或“能量”。通常计算所有参数梯度的 L2 范数: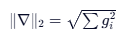
物理意义:代表参数更新的总力度;
健康范围:通常在 0.1 ~ 10.0 之间波动(取决于模型架构和学习率),应保持相对稳定;
三种典型的范数曲线
┌─────────────────────────────────────────────────────────────────┐
│ 梯度范数 (Gradient Norm) 随 Step 变化趋势 │
├─────────────────────────────────────────────────────────────────┤
│ Norm 值 │
│ ▲ │
│ │ ❌ 爆炸 (Explosion) │
│ 高 │ /| │
│ │ / | (突然垂直飙升 > 1000) │
│ │ / | │
│ │ ________/ | │
│ │ / | │
│ │ / | │
│ │ / | │
│ 中 │ /______________\________ ✅ 正常 (Normal) │
│ │ / \ (在 1~10 之间小幅波动) │
│ │/ \______ │
│ │ \ │
│ 低 │ \_______ ❌ 消失 (Vanishing) │
│ │ \ (趋近于 0, < 1e-6) │
│ │ \ │
│ └──────────────────────────────────────────────► Step │
│ [初期] [中期] [后期/异常点] │
└─────────────────────────────────────────────────────────────────┘
案例解析:范数异常的急救
场景 A:梯度爆炸 (Gradient Explosion)
1、现象:训练第 500 step,梯度范数从 2.5 瞬间跳至50,000,紧接着 Loss 变为 NaN;
2、原因:深层网络中误差信号连乘放大,或学习率过大导致参数更新越界;
3、后果:模型参数被“炸飞”,权重变成无穷大或 NaN,训练彻底崩溃;
4、解决方案:
4.2、梯度裁剪 (Gradient Clipping):最常用手段。设置 max_norm=1.0。如果当前范数 > 1.0,则将整个梯度向量按比例缩小,使其范数等于 1.0;
4.2、代码逻辑:if norm > threshold: gradient *= (threshold / norm)
降低学习率:减小步长,避免剧烈震荡;
4.3、检查激活函数:确保未使用导致输出无界的激活函数(如线性激活在深层);
场景 B:梯度消失 (Gradient Vanishing)
1、现象:训练了 10,000 step,Loss 几乎不变,梯度范数始终显示为 1e-7 或 0.0
2、原因:
2.1、网络过深,反向传播时梯度连乘趋近于 0;
2.2、使用了 Sigmoid/Tanh 等饱和激活函数,导数接近 0;
权重初始化太小;
3、后果:浅层参数几乎不更新,模型退化为只训练最后几层,学习能力极弱;
4、解决方案:
4.1、更换激活函数:全面改用 ReLU, GELU, 或 Swish,它们在正区间导数为 1,不易消失;
4.2、改进初始化:使用 Xavier 或 He (Kaiming) 初始化;
4.3、残差连接 (Residual Connection):引入 Skip Connection,让梯度可以直接流向浅层(Transformer 的核心机制);
4.4、归一化 (Normalization):使用 LayerNorm 或 BatchNorm 稳定分布;
3.2 梯度分布 (Gradient Distribution)
核心概念:不仅看整体大小,还要看梯度在参数空间是如何分布的。通过直方图观察梯度的稀疏性、对称性和层级差异。
梯度直方图对比
┌─────────────────────────────────────────────────────────────────┐
│ 梯度分布直方图 (Histogram) │
├─────────────────────────────────────────────────────────────────┤
│ │
│ √ 正常分布 (Healthy) × 异常分布 (Pathological) │
│ │
│ 频数 ▲ 频数 ▲ │
│ │ _ │ _ │
│ │ / \ │ / \ │
│ │ / \ │ / \ │
│ │/ \ │ / \ │
│ └───────┴──► 梯度值 │ / \ │
│ (-0.5, 0.5) │ / \ │
│ (钟形分布,集中在 0 附近, │ / \ │
│ 有适度的拖尾) │ / \ │
│ │ / \ │
│ │ / \ │
│ │ / \ │
│ │/ \ │
│ └───────────────────────┴──► 梯度值
│ (-100) (100) │
│ (双峰或极长尾,存在极端异常值) │
│ │
│ 📉 层间差异示意 (Layer-wise Norm) │
│ Layer 1 (Embedding): ████ (2.0) │
│ Layer 6 (Middle): ██ (0.01) <-- 中间层阻塞! │
│ Layer 12 (Output): ██████ (5.0) │
│ │
└─────────────────────────────────────────────────────────────────┘
案例解析:分布揭示的深层问题
案例 1:长尾异常值 (Outliers)
1、现象:直方图主体很窄(大部分梯度在 -0.1 到 0.1),但两端有极少量的点分布在 -1000 或 +1000。
2、含义:某些特定的参数(可能是 Embedding 层中的生僻词,或某层的 Bias)接收到了巨大的梯度信号。这通常由脏数据(如超长文本、特殊符号)引起。
3、影响:即使全局范数正常,这些异常值也会破坏对应参数的稳定性,导致模型局部行为怪异。
4、对策:检查该 Step 的 Batch 数据;使用更激进的梯度裁剪(按元素裁剪 clip_by_value 而不仅仅是全局范数裁剪)。
案例 2:层间梯度不平衡 (Layer Imbalance)
1、现象:
Output Layer 梯度范数 = 5.0
Middle Layers 梯度范数 = 0.001
Embedding Layer 梯度范数 = 0.1
2、含义:中间层阻塞。梯度无法有效传递到网络中部,导致中间层参数几乎不更新。这在非常深的网络或未正确初始化的 Transformer 中常见。
3、对策:
检查初始化:确保每层的方差一致(如使用 std = sqrt(2/d_model))。
预热 (Warmup):训练初期使用极小学习率,让各层梯度分布先稳定下来。
深度缩放 (Depth Scaling):在残差连接前乘以系数 (N 为层数),平衡深浅层梯度贡献。
案例 3:梯度集中在零 (Dead Gradients)
1、现象:直方图在 0 处有一个极高的尖峰,几乎没有任何宽度。
2、含义:大量神经元处于“死亡”状态(如 ReLU 输入全为负),导数恒为 0。
3、对策:尝试 Leaky ReLU 或增加 Bias 初始化值,激活“死”神经元。
4 参数分布(Parameter Distribution)
如果说梯度是“引擎的转速”,那么参数(权重)就是“汽车的零件”。监控参数分布,就是检查零件是否磨损、变形或卡死。这能揭示模型内部状态的健康度和学习活性。
┌─────────────────────────────────────────────────────────────────┐
│ 参数健康监控系统:从静态分布到动态更新 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 【输入】模型参数 (Weights & Biases) at Step t │
│ │ │
│ ▼ │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 监控层 A: 静态分布 (Static Distribution) │ │
│ │ • 权重直方图 (Weight Histogram) │ │
│ │ - 均值/方差:是否漂移?是否坍缩? │ │
│ │ - 异常值:是否存在 NaN/Inf 或极端离群点? │ │
│ │ - 形状:是否保持高斯分布或 Xavier/He 初始化形态? │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ (对比 Step t-1) │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 监控层 B: 动态变化 (Dynamic Update) │ │
│ │ • 更新幅度 (Update Magnitude): ||Δθ|| = ||θ_t - θ_{t-1}|| │ │
│ │ - 绝对变化量:步子迈得有多大? │ │
│ │ - 相对变化率:Δθ / θ (信噪比) │ │
│ │ - 活性检测:直方图是否“冻结”不动? │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ (诊断结论) │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 健康状态判断 │ │
│ │ • ✅ 健康:分布稳定平滑,更新幅度适中且持续 │ │
│ │ • ❌ 冻结:直方图不变,更新幅度≈0 (学习率太低/梯度消失) │ │
│ │ • ❌ 震荡:分布剧烈跳变,更新幅度过大 (学习率太高) │ │
│ │ • ❌ 污染:出现 NaN/Inf 或长尾极值 (数值溢出/脏数据) │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
4.1 权重直方图 (Weight Histogram)
核心概念:观察模型参数在数值空间中的“长相”。
理想状态:通常呈现均值为 0 的钟形分布(高斯分布),或者符合初始化策略(如 Xavier 均匀分布)的形态。随着训练进行,分布会略微变宽或偏移,但应保持连续和平滑。
┌─────────────────────────────────────────────────────────────────┐
│ 权重直方图 (Weight Histogram) 三种典型形态 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ✅ 正常演化 (Healthy Evolution) │
│ 频数 ▲ │
│ │ Step 0 (初始化) Step 5000 (训练中) │
│ │ _ _ │
│ │ / \ / \ (略微变宽,中心偏移) │
│ │ / \ / \ │
│ │___/_____\______ /_______\______ │
│ │ -0.5 0 0.5 -0.8 0 0.6 │
│ │ (平滑钟形) (平滑,无断裂) │
│ │
│ ❌ 异常形态 A: 冻结/死亡 (Frozen/Dead) │
│ 频数 ▲ │
│ │ Step 0 Step 5000 │
│ │ _ _ │
│ │ /|\ /|\ (完全重合,无变化!) │
│ │ / | \ / | \ │
│ │___/__|__\______ /__|__\______ │
│ │ (参数未更新,学习停滞) │
│ │
│ ❌ 异常形态 B: 污染/爆炸 (Corrupted/Exploded) │
│ 频数 ▲ │
│ │ │
│ │ _ _ * │
│ │ / \ / \ * (极端离群点) │
│ │ / \ / \ * │
│ │___/_____\______ /_____\________*________ │
│ │ -1000 0 1000 5000 │
│ │ (出现长尾或 NaN/Inf,分布断裂) │
│ │
└─────────────────────────────────────────────────────────────────┘
案例解析:Transformer 中的残差监控
场景 A:参数“冻结”现象
1、现象:训练了 2000 step,TensorBoard 中权重直方图与 Step 0 时完全重合,没有任何移动或变形;
2、原因:
学习率设为 0 或极低;
梯度消失:梯度传不到这一层,导致 Δθ≈0 ;
优化器故障:某些参数组被错误地设置为 requires_grad=False;
3、对策:检查 param_groups 的学习率设置;查看该层的梯度范数是否为 0;
场景 B:残差块输出分布漂移 (Residual Drift)
1、现象:在深层 Transformer 中,某一层输出的权重均值突然从 0 漂移到 5.0,标准差急剧增大;
2、原因:残差连接失效(如缩放系数错误),导致信号在层层叠加中无限放大;
3、对策:检查 Pre-LN vs Post-LN 架构实现;确保残差分支有正确的缩放;
4.2参数更新幅度 (Parameter Update Magnitude)
核心概念:衡量每一步训练参数“动了多少”。
公式:Δθ=θ t − θ t−1
更新幅度与学习率的关系
┌─────────────────────────────────────────────────────────────────┐
│ 参数更新幅度 (Update Magnitude) vs 学习率 (LR) │
├─────────────────────────────────────────────────────────────────┤
│ 更新幅度 ▲ │
│ │ │
│ 大 │ ❌ 过大 (Overshooting) │
│ │ / \ (LR 太高,参数剧烈震荡,损失不降) │
│ │ / \ │
│ │ / \ │
│ 中 │______/________\_______ ✅ 适中 (Healthy) │
│ │ \ / (LR 合适,稳步更新) │
│ │ \ / │
│ │ \ / │
│ 小 │ \__/_________ ❌ 过小 (Stagnation) │
│ │ \ (LR 太低或梯度消失,几乎不更新) │
│ │ \ │
│ └──────────────────────────────────────────────► Step │
│ [初期] [中期] [后期/异常] │
│ │
│ 📉 黄金法则: │
│ 相对更新率 (Δθ/θ) 通常应保持在 1e-3 ~ 1e-1 之间 (视任务而定) │
│ 若 < 1e-6 --> 学习无效;若 > 1.0 --> 训练崩溃风险高 │
└─────────────────────────────────────────────────────────────────┘
如何判断学习率是否合适:
A 更新幅度过大 (Learning Rate Too High)
B 更新幅度过小 (Learning Rate Too Low / Vanishing)
C 更新幅度不均匀 (Layer-wise Imbalance)
5 监控工具(Monitoring Tools)
如果说前面的指标是“数据”,那么监控工具就是“仪表盘”和“黑匣子”。它们将枯燥的数字转化为直观的图表,帮助开发者实时洞察训练状态、复现实验并协作调试。
TensorBoard 工作流
┌─────────────────────────────────────────────────────────────────┐
│ 深度学习训练监控生态系统 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 【层 1: 本地可视化 (Local Visualization)】 │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ TensorBoard │ │
│ │ • 定位:行业标准,本地优先,轻量级 │ │
│ │ • 核心:标量曲线、直方图、计算图、Embedding 投影 │ │
│ │ • 适用:单机调试、快速验证、离线分析 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 【层 2: 云端协作平台 (Cloud Collaboration)】 │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ Weights & Biases (W&B) │ │
│ │ • 定位:实验管理神器,云端同步,团队协作 │ │
│ │ • 核心:自动超参记录、系统资源监控、实验对比、报告生成 │ │
│ │ • 适用:多卡/多机分布式训练、长期项目、团队共享 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ 【层 3: 全生命周期管理 (Lifecycle Management)】 │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ 🏭 MLflow │ │
│ │ • 定位:企业级 MLOps,模型注册与部署 │ │
│ │ • 核心:实验跟踪 + 模型仓库 (Model Registry) + Serving │ │
│ │ • 适用:生产环境、模型版本控制、从训练到部署的闭环 │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │
│ 【层 4: 底层硬件监控 (System Hardware)】 │
│ ┌───────────────────────────────────────────────────────────┐ │
│ │ ⚙️ nvidia-smi / gpustat / ifstat │ │
│ │ • 关注:GPU 利用率、显存 (VRAM)、CPU 内存、网络带宽 │ │
│ │ • 目的:发现瓶颈 (IO/CPU/Network),防止 OOM │ │
│ └───────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
5.1 TensorBoard
核心概念:Google 开发的开源可视化工具,深度集成于 TensorFlow 和 PyTorch (torch.utils.tensorboard)。
┌─────────────────────────────────────────────────────────────────┐
│ TensorBoard 数据流向与工作模式 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ [训练代码] │
│ │ │
│ ▼ (写入事件文件) │
│ ./runs/exp_01/events.out.tfevents... │
│ │ │
│ ▼ (启动服务) │
│ $ tensorboard --logdir=./runs │
│ │ │
│ ▼ (浏览器访问) │
│ http://localhost:6006 │
│ │ │
│ ├── SCALARS (Loss, Acc, LR, Grad Norm) │
│ ├── GRAPHS (计算结构图,检查连接是否正确) │
│ ├── HISTOGRAMS (权重/梯度分布,检查是否消失/爆炸) │
│ ├── DISTRIBUTIONS (分位数统计) │
│ └── PROJECTOR (高维向量降维可视化,如 Embedding) │
│ │
│ 局限: │
│ • 仅限本地或需配置 SSH 转发,远程查看不便。 │
│ • 缺乏实验对比的直观界面(需手动开多个标签页)。 │
│ • 不自动记录超参数和系统资源(需手动代码实现)。 │
│ │
└─────────────────────────────────────────────────────────────────┘
5.2 Weights & Biases(W&B)
核心概念:云原生的实验管理平台。它不仅是可视化工具,更是团队的“协作中心”。
核心优势:自动记录。只需几行代码,它会自动捕获超参数、Git Commit ID、系统资源(GPU/CPU/Memory)、甚至代码差异。
W&B 云端协作面板
┌─────────────────────────────────────────────────────────────────┐
│ W&B 云端仪表盘功能全景 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ Project: "LLM-Pretraining-V1" │
│ │
│ [Runs Table] (实验列表) │
│ ┌──────┬──────────────┬─────────┬──────────┬───────────────┐ │
│ │ Run │ Config (LR) │ Status │ GPU Util │ Best Val Loss │ │
│ ├──────┼──────────────┼─────────┼──────────┼───────────────┤ │
│ │ frog │ lr=1e-4 │ ✅ Done | 98% │ 2.10 │ │
│ │ lion │ lr=5e-4 │ ❌ Crash| 100% │ NaN │ │
│ │ tiger│ lr=1e-4+WD │ 🏃 Run | 95% │ 2.05 (live) │ │
│ └──────┴──────────────┴─────────┴──────────┴───────────────┘ │
│ │ │
│ ▼ (点击对比) │
│ [Comparison Charts] │
│ • 多曲线同屏对比 (Loss, Accuracy) │
│ • 平行坐标图 (Parallel Coordinates): 寻找超参与结果的关联 │
│ • 系统资源面板:自动绘制的 GPU Memory/Utilization 曲线 │
│ │
│ 📝 Report: 一键生成包含图表、Markdown 解释的实验报告 │
│ │
└─────────────────────────────────────────────────────────────────┘
5.3 MLflow
核心概念:专注于机器学习全生命周期的管理,特别是模型上线后的版本控制和部署。
适用场景:企业需要将训练好的模型注册、版本化,并一键部署到生产环境。
功能:
MLflow 生命周期
┌─────────────────────────────────────────────────────────────────┐
│ MLflow 四大组件架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 1. MLflow Tracking (实验跟踪) │
│ [记录参数、指标、文件] ➡️ 类似 W&B/TensorBoard │
│ │
│ 2. MLflow Models (模型打包) │
│ [保存模型 + 环境依赖] ➡️ 生成 "MLmodel" 配置文件 │
│ (支持 PyTorch, TF, Sklearn 等统一格式) │
│ │
│ 3. MLflow Model Registry (模型注册) │
│ [版本控制] ➡️ Staging -> Production -> Archived │
│ (谁在什么时候发布了哪个版本的模型?) │
│ │
│ 4. MLflow Projects (项目打包) │
│ [可复现运行] ➡️ 定义 Conda/Docker 环境,确保 anywhere 可跑 │
│ │
└─────────────────────────────────────────────────────────────────┘
5.4 系统监控 (System Monitoring)
核心概念:模型跑不起来,往往不是算法问题,而是资源瓶颈。必须像监控模型指标一样监控硬件。
硬件资源瓶颈诊断树
┌─────────────────────────────────────────────────────────────────┐
│ 系统资源监控与瓶颈诊断 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 🔴 GPU 利用率 (Volatile GPU-Util) │
│ • 正常:> 90% (计算密集型) │
│ • 异常:< 50% │
│ ├─ 原因 A: CPU 数据加载太慢 (IO Bound) ➡️ 增加 num_workers │
│ ├─ 原因 B: 网络通信等待 (Distributed) ➡️ 检查 NCCL/带宽 │
│ └─ 原因 C: 代码中有同步操作 (to() 在循环内) │
│ │
│ 🟠 显存使用 (Memory-Usage) │
│ • 警戒线:> 95% │
│ • 动作:OOM (Out Of Memory) 前兆 │
│ ├─ 减小 Batch Size │
│ ├─ 开启 Gradient Checkpointing (激活重计算) │
│ └─ 使用 DeepSpeed ZeRO / FSDP 进行显存优化 │
│ │
│ 🟡 CPU 内存 & Swap │
│ • 现象:训练突然变慢十倍 │
│ • 原因:RAM 耗尽,开始使用磁盘 Swap │
│ • 动作:减少 DataLoader 的 prefetch_factor 或 num_workers │
│ │
│ 🔵 网络带宽 (Network I/O) │
│ • 场景:多机训练 │
│ • 工具:ifstat, nvidia-smi -q (BAR1 Volatile) │
│ • 瓶颈:梯度同步时间 > 计算时间 ➡️ 需升级 InfiniBand/RoCE │
│ │
└─────────────────────────────────────────────────────────────────┘
小结
| 需求场景 | 首选工具 | 理由 | 补充工具 |
|---|---|---|---|
| 个人本地调试 | TensorBoard | 无需联网,启动快,原生支持好 | nvidia-smi |
| 团队协作/多机训练 | W&B | 云端同步,自动记录超参/系统资源,对比功能强 | gpustat |
| 企业模型部署/版本管理 | MLflow | 完整的 Model Registry 和 Serving 支持 | TensorBoard (嵌入查看) |
| 性能调优 (IO/显存) | System Tools | nvidia-smi, py-spy, ifstat 直接看底层 |
Nsight Systems (硬核分析) |
6 常见问题与调试 (Common Issues & Debugging)
训练大模型如同驾驶一艘巨轮,监控指标是仪表盘,而调试技巧则是应对风暴的“航海日志”。本节将基于前文提到的 Loss、PPL、梯度、参数等指标,构建一套系统性的故障诊断与修复指南。
6.1 过拟合(Overfitting)
诊断特征:
Loss 曲线:Training Loss 持续下降(甚至接近 0),但 Validation Loss 在某个点后开始上升。
评估指标:验证集 PPL 上升,下游任务准确率(如 MMLU)停滞或下降。
参数状态:权重分布可能变得极端,某些参数值极大以“死记硬背”特定样本。
| 策略 | 具体操作 | 适用场景 | 注意事项 |
|---|---|---|---|
| 正则化增强 | 提高 Dropout (0.1→0.2~0.4) | 模型容量明显过剩 | 过高会导致欠拟合,需微调 |
| 增加权重衰减 (Weight Decay) | 参数更新幅度过大 | 默认 0.1,可尝试 0.2 或 0.3 | |
| 早停机制 | Early Stopping | 验证集 PPL 连续 N 个 epoch 不降 | 保存 PPL 最低点的 Checkpoint |
| 数据策略 | 数据增强 (Data Augmentation) | 数据量相对较少 | 文本可用回译、随机 Mask、混洗 |
| 数据去重 (Deduplication) | 训练集中有大量重复样本 | 极重要:重复数据是过拟合主因 | |
| 模型调整 | 减小模型规模 | 资源允许重训 | 最后一招,通常优先调参 |
建议
“数据去重”往往比加 Dropout 更有效。 在大模型预训练中,如果训练集包含大量重复的网页或书籍片段,模型会迅速过拟合这些重复内容,导致泛化能力大幅下降。务必在预处理阶段进行严格的 MinHash 或精确去重。
6.2 欠拟合(Underfitting)
诊断特征:
1、Loss 曲线:Training Loss 下降极其缓慢,或者很早就停滞在一个较高的值(远高于预期)。
2、评估指标:验证集 PPL 很高,模型表现得像随机猜测。
3、梯度/参数:梯度范数很小,参数更新幅度( Δθ )微乎其微。
| 策略 | 具体操作 | 适用场景 | 注意事项 |
|---|---|---|---|
| 学习率调整 | 提高 Learning Rate | 初始 LR 设置过低 | 配合 Warmup 使用,避免起步爆炸 |
| 延长 Warmup 步数 | 训练初期不稳定导致收敛慢 | 尝试将 Warmup 比例从 1% 提至 5% | |
| 模型容量 | 增加层数/隐藏维度 | 模型太小无法捕捉复杂模式 | 需更多显存和计算资源 |
| 正则化减弱 | 降低/关闭 Dropout | 正则化过强抑制了学习 | 预训练初期可暂时关闭 Dropout |
| 降低 Weight Decay | 权重衰减过大阻碍拟合 | 尝试设为 0 或 0.01 测试 | |
| 数据检查 | 检查 Tokenizer/预处理 | 最常见原因:输入全是乱码或特殊 token | 打印几个 Batch 的 decoded 文本确认 |
6.3 损失震荡 (Loss Oscillation)
诊断特征:
Loss 曲线:不是平滑下降,而是呈现剧烈的锯齿状,甚至有时不降反升;
梯度统计:梯度范数随 Loss 剧烈波动;
调试方案
1、降低学习率 (Reduce LR):最直接有效的方法。如果当前 LR 是 1e−4 ,尝试 5e−5 或 1e−5 ;
2、增大 Batch Size:小 Batch 导致梯度估计噪声大;
操作:如果显存不够,使用 梯度累积 (Gradient Accumulation)。例如,每 4 步累积一次梯度再更新,等效于 Batch Size 扩大 4 倍;
3、加强梯度裁剪 (Gradient Clipping):
操作:将 max_norm 从 1.0 降至 0.5 或 0.25,防止个别异常样本导致的梯度尖峰破坏参数;
4、清洗脏数据:
排查:震荡发生的那个 Step,对应的 Batch 里是否有空文本、超长文本、或全是标点符号的垃圾数据?
操作:添加数据过滤规则,剔除质量差的样本;
Loss
▲
│ ❌ 震荡 (LR 太大 / Batch 太小)
│ / \ / \ / \
│ / \ \ / \
│/ \ X \____ (难以收敛)
│ \ /
│
│ ✅ 平滑 (LR 合适 / Batch 适中)
│ _
│ \__
│ \___
│ \______ (稳定下降)
└──────────────────► Step
6.4 度消失/爆炸 (Vanishing/Exploding Gradients)
这是深度网络最致命的问题,直接导致训练崩溃。
| 症状 | 梯度范数 (Norm) | Loss 表现 | 核心解决方案 |
|---|---|---|---|
| 梯度爆炸 | > 1000 (甚至 Inf) | 突然变成 NaN 或极大值 | 1. 开启梯度裁剪 (clip_grad_norm_=1.0)2. 降低学习率 3. 检查混合精度:确保 Loss Scaler 工作正常,或改用 BF16 (比 FP16 更稳定,不易溢出) 4. 检查是否有未归一化的层 |
| 梯度消失 | < 1e-8 (接近 0) | 长期停滞,不下降 | 1. 检查初始化:使用 He/Xavier 初始化 2. 架构检查:确保使用了 残差连接 (Residuals) 和 LayerNorm 3. 激活函数:避免 Sigmoid/Tanh,改用 GELU/ReLU 4. Pre-Norm vs Post-Norm:深层 Transformer 推荐使用 Pre-Norm 架构,梯度流动更好 |
建议
在训练超大模型时,FP16 (Float16) 的动态范围较小,容易在梯度较大时溢出(变成 Inf)。BF16 (Bfloat16) 拥有与 FP32 相同的指数位,动态范围大得多,能显著减少梯度爆炸导致的 NaN 问题,是现代大模型训练的标配。
6.5 训练速度慢(Slow Training)
诊断特征:
吞吐量:Tokens/sec 远低于理论峰值(如 A100 应达到数百 TFLOPS,实际只有几十);
硬件监控:GPU 利用率 (Volatile GPU-Util) 长期低于 50%,或者 GPU 经常处于空闲等待状态;
瓶颈定位与优化
现象:每秒处理的 token 数远低于预期。
| 瓶颈类型 | 症状 (通过 nvidia-smi / py-spy 观察) |
优化方案 |
|---|---|---|
| CPU/IO 瓶颈 | GPU 利用率周期性波谷;CPU 满载;DataLoader 进程占用高 |
1. 增加 num_workers (如 8~16)2. 启用 pin_memory=True3. 使用 内存映射 (mmap) 数据集格式 (如 Arrow/MemoryMapped) 4. 提前预处理数据,避免在线 Tokenization |
| 通信瓶颈 | 多机训练时,GPU 频繁等待;网络带宽跑满但计算少 | 1. 优化并行策略:合理搭配 张量并行 (TP) 和 流水线并行 (PP) 2. 使用高速互联 (InfiniBand/RoCE) 3. 开启 梯度压缩 或 Overlap (通信与计算重叠) |
| 算子效率 | GPU 利用率高但 TFLOPS 低 | 1. 启用 FlashAttention (加速 Attention 计算,减少显存占用) 2. 使用融合算子 (Fused Kernels, e.g., Apex, TorchCompile) 3. 避免在训练循环中进行频繁的 CPU-GPU 数据拷贝 ( .to('cuda') 应在循环外) |
性能分析工具推荐
PyTorch Profiler: 生成火焰图 (Flame Graph),精确看到哪行代码耗时最长;
NVIDIA Nsight Systems: 系统级分析,查看 GPU Kernel 执行间隙(气泡),判断是计算慢还是通信I/O 慢;
7 实践建议
A、建立基准:在开始大规模训练前,先用小模型或小数据跑通流程,验证代码和监控设置无误。
B、自动化报警:设置关键指标(如损失为 NaN、梯度范数超过阈值)的自动报警,及时干预。
C、定期保存检查点:每隔一定步数保存模型和优化器状态,便于从故障中恢复或进行后续分析。
D、实验版本管理:使用 W&B 或 MLflow 记录每次实验的超参数、代码版本和结果,方便对比和复现。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)