推理平台全景
本次分享介绍了常见的开源推理平台项目: NVIDIA Dynamo, llm-d, Kthena, RoleBasedGroup, OME, AiBrix, KServe
推理平台(Inference Platform)是位于推理引擎(如 vLLM、SGLang)之上、面向生产环境的基础设施层。推理引擎专注于模型加载和推理计算本身,而推理平台则在此之上提供生产级的编排和管理能力,例如:
- 多推理引擎支持:支持 vLLM、SGLang、TensorRT-LLM 等不同推理引擎。
- 智能路由与负载均衡:提供面向 LLM 推理优化的路由策略,如 Prefix Cache 感知、KV Cache 利用率、请求队列深度、LoRA 亲和性路由等。
- 流量管理与发布策略:支持金丝雀发布、加权流量分配,以及零停机的滚动更新。
- 容错机制:支持请求迁移、请求取消、优雅关闭、过载拒绝等自动故障转移能力,保障生产环境的高可用性。
- PD 分离:支持通过分离 Prefill 和 Decode 节点来优化大模型服务以提升性能。
- 分布式推理编排:支持多节点、多 GPU 的分布式推理编排,例如通过 Ray 等管理分布式工作负载的创建和生命周期,使得超大模型(如 DeepSeek V3 685B)可以跨多节点部署和服务。
- 弹性伸缩:基于 GPU 利用率、KV Cache 占用率、请求队列深度等指标自动扩缩容。
- 模型与 KV Cache 管理:支持本地缓存预热模型加速推理服务启动,提供中心化的分布式 KV Cache Pool 实现跨推理实例的 KV Cache 共享和复用。
- LoRA Adapter 管理:动态路由和管理 LoRA Adapter,无需中断服务即可加载、卸载 LoRA Adapter。
- 可观测性:通过 Prometheus 等采集 LLM 推理指标(如 GPU/KV Cache 利用率、TTFT、TPOT、请求队列深度等),实现生产环境的监控和告警。
- 多租户与资源管理:通过配额、队列/优先级、隔离与抢占等机制,实现多团队共享 GPU 资源时的可控性与公平性。
1. NVIDIA Dynamo
Dynamo 是 NVIDIA 开源的高吞吐、低延迟推理框架,专为在多节点分布式环境中服务生成式 AI 和推理模型而设计。Dynamo 支持多种推理引擎(例如 TensorRT-LLM、vLLM、SGLang),使用 Rust 构建核心以保证性能,Python 提供可扩展性,主要特性包括:
- Prefill-Decode 分离:在延迟和吞吐之间灵活权衡,最大化 GPU 吞吐。
- 动态 GPU 调度:根据波动的需求动态优化性能。
- LLM 感知的请求路由:消除不必要的 KV Cache 重计算。
- 加速数据传输:通过 NIXL 减少推理响应时间。
- KV Cache 卸载:利用多级内存层次提高吞吐。
安装 Dynamo 可以参考 Installation Guide for Dynamo Kubernetes Platform。
1.1 使用 DynamoGraphDeployment 部署推理服务
Dynamo 提供了 DynamoGraphDeployment CRD,用于在 Kubernetes 中声明式地部署推理服务。用户只需定义推理图中的各个组件(Frontend、Worker 等)及其资源需求,Dynamo Operator 会自动创建和管理对应的工作负载资源。
1.1.1 聚合模式
以下是一个最简单的聚合部署示例,包含一个 Frontend 和一个 vLLM Worker:
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: vllm-agg
spec:
services:
Frontend:
componentType: frontend
replicas: 1
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0
VllmDecodeWorker:
envFromSecret: hf-token-secret
componentType: worker
replicas: 1
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0
workingDir: /workspace/examples/backends/vllm
command:
- python3
- -m
- dynamo.vllm
args:
- --model
- Qwen/Qwen3-0.6B
1.1.2 PD 分离模式
Dynamo 的 PD 分离由 PrefillRouter 协调,整体流程如下:
- Worker 选择:PrefillRouter 通过 KV Cache 感知路由(基于缓存命中率和负载)或简单负载均衡选择一个 Prefill Worker。
- Prefill 执行:PrefillRouter 将请求发送到选定的 Prefill Worker,Prefill Worker 计算 KV Cache 并返回
disaggregated_params(包含后端特定的传输元数据)。 - Decode 路由:PrefillRouter 将 Prefill 结果注入 Decode 请求,然后路由到 Decode Worker。
- KV Cache 传输:Decode Worker 使用传输元数据与 Prefill Worker 协调,NIXL 使用最优的可用传输方式(NVLink、InfiniBand/UCX 等)处理 GPU-to-GPU 的直接传输。
- Token 生成:Decode Worker 执行 Decode 阶段,生成并返回 token。
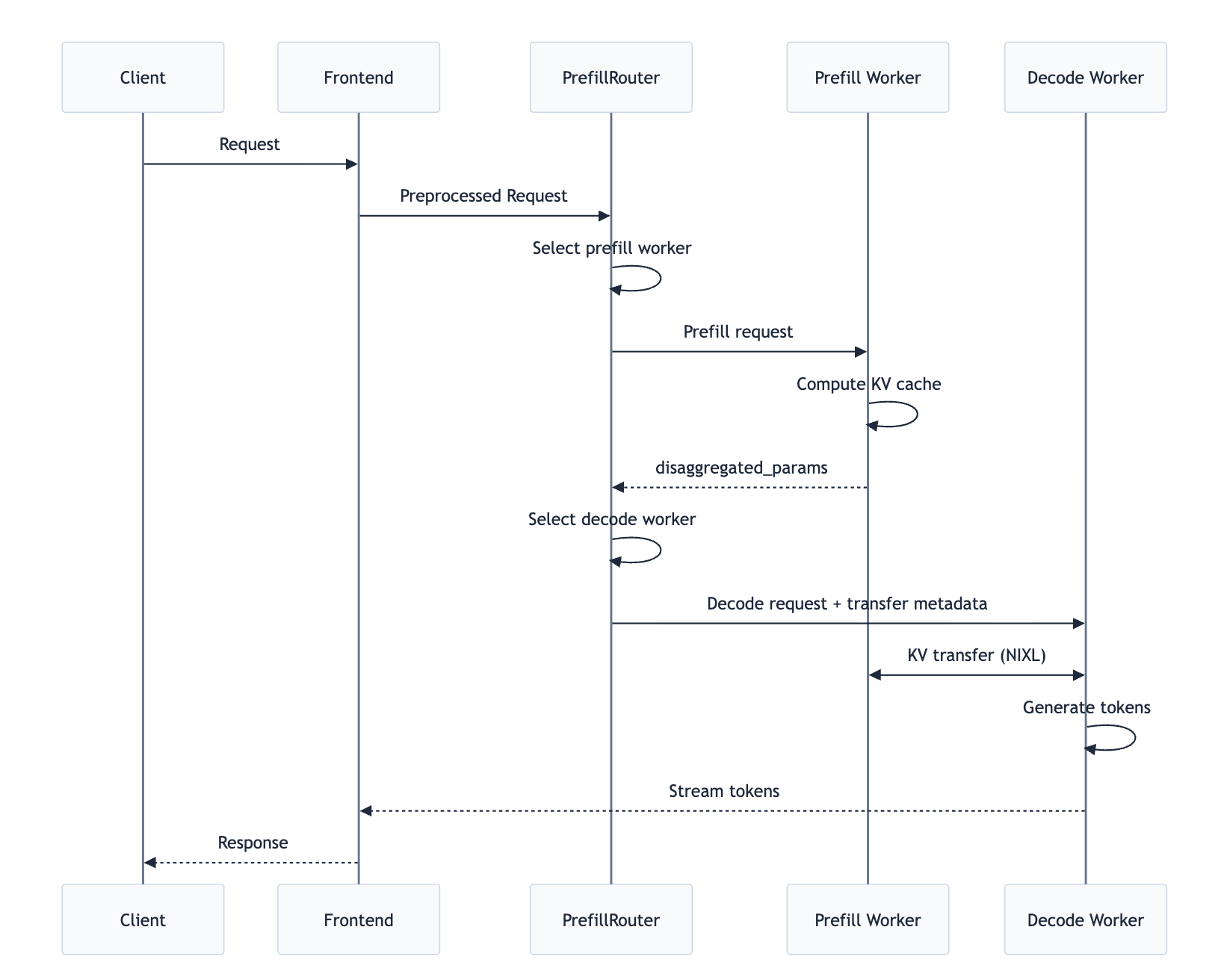 PrefillRouter 运行在 Frontend 进程内部,不是独立部署的组件。
PrefillRouter 运行在 Frontend 进程内部,不是独立部署的组件。
以下是 PD 分离的 DynamoGraphDeployment 配置示例。与聚合模式相比,PD 分离的关键配置差异在于:
subComponentType: prefill/decode:Operator 层面的身份标识,用于服务发现和编排(如为 Prefill 和 Decode Worker 创建不同的 Service,让 PrefillRouter 能正确发现和路由到对应的 Worker)。--is-prefill-worker/--is-decode-worker:dynamo.vllm(Dynamo 对 vLLM 的封装模块)的运行时参数,决定该进程在 Dynamo 服务发现中注册为 Prefill 或 Decode 角色,从而只接收对应类型的请求。注意 vLLM 引擎本身以kv_role: kv_both运行,Prefill/Decode 的分工完全由 Dynamo 的 PrefillRouter 在请求路由层面控制。
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: vllm-disagg
spec:
services:
Frontend:
componentType: frontend
replicas: 1
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0
VllmDecodeWorker:
envFromSecret: hf-token-secret
componentType: worker
subComponentType: decode
replicas: 1
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0
workingDir: /workspace/examples/backends/vllm
command:
- python3
- -m
- dynamo.vllm
args:
- --model
- Qwen/Qwen3-0.6B
- --is-decode-worker
VllmPrefillWorker:
envFromSecret: hf-token-secret
componentType: worker
subComponentType: prefill
replicas: 1
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.9.0
workingDir: /workspace/examples/backends/vllm
command:
- python3
- -m
- dynamo.vllm
args:
- --model
- Qwen/Qwen3-0.6B
- --is-prefill-worker
1.2 Prefix Cache Aware Routing
Dynamo KV Router 通过评估请求在不同 Worker 上的计算成本来智能路由请求,综合考虑 Decode 成本(来自活跃 Blocks)和 Prefill 成本(来自新计算的 Blocks),在最大化 Prefix Cache 命中率的同时保持负载均衡。
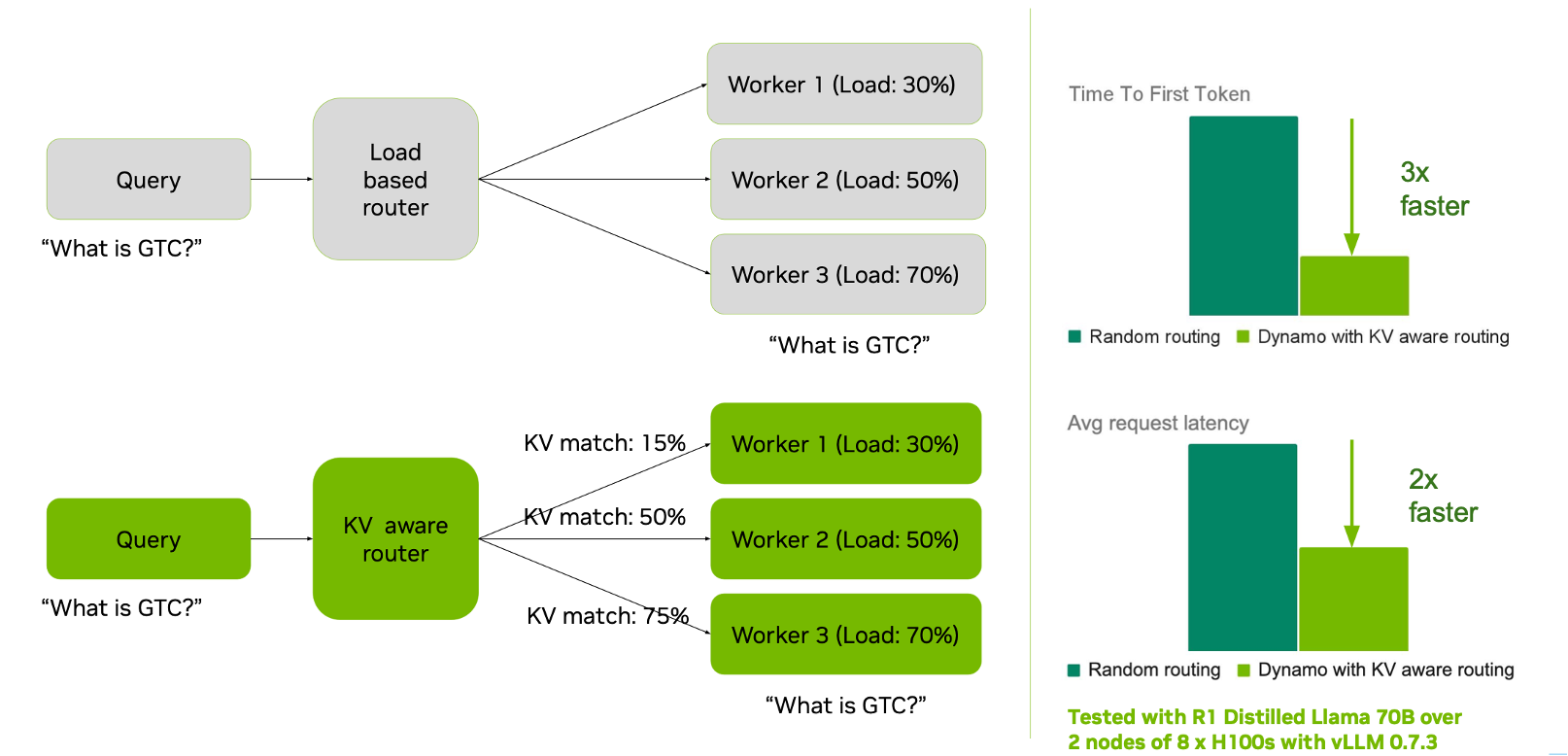
1.2.1 路由计算公式
Router 为每个 Worker 计算一个 logit 分数,选择分数最低的 Worker(即预估计算成本最低)来处理请求:
logit = kv_overlap_score_weight × potential_prefill_blocks + potential_active_blocks
- logit:值越低越好(计算成本越低)。
- potential_prefill_blocks:需要计算的 Prefill Block 数量(KV Cache 匹配越长,需要计算的越少),通过将需要 Prefill 处理的 Token 数除以 Block 大小来计算。
- potential_active_blocks:当前正在处理请求的 Block 数量,反映 Worker 负载,根据请求的输入 Token 和每个工作节点的活动 Sequence 估算。
- kv_overlap_score_weight(默认 1.0):
> 1.0:注重 TTFT,优先选择 KV Cache 匹配长的 Worker。< 1.0:注重 ITL,优先选择负载低的 Worker。
1.2.2 路由模式
Prefix Cache Aware Routing 可分为精确模式和近似模式两种:
-
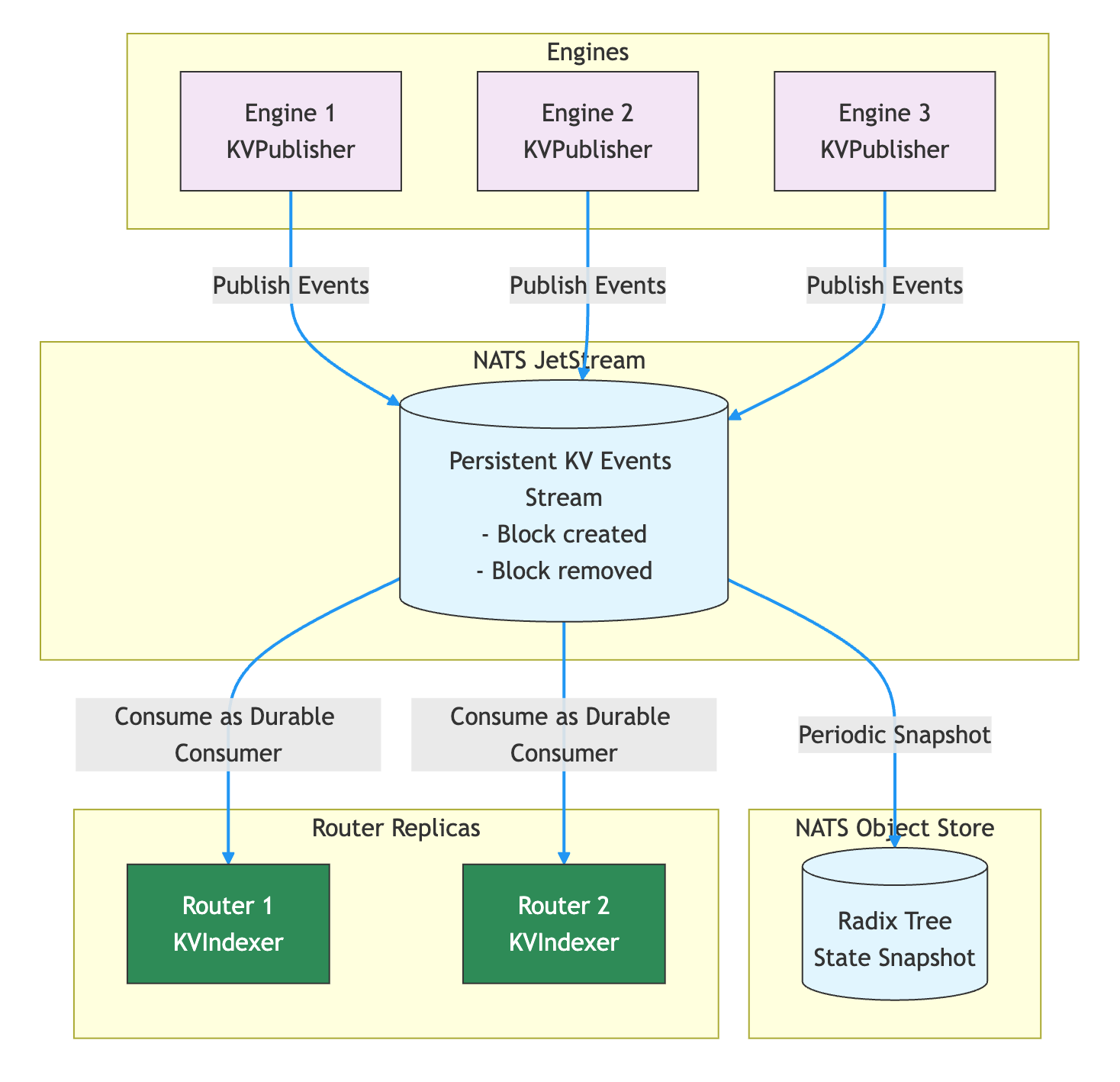
精确模式:Worker 上报 KV Cache 事件,Router 维护准确的全局 Cache 状态。根据状态存储位置的不同,分为两种子模式:
- JetStream 模式(
--durable-kv-events):Worker 将 KV 事件写入 NATS JetStream 持久化流,每个 Router 副本通过 durable consumer 独立消费事件流并更新自身索引。Router 重启后可以从 JetStream 重放未消费的事件,也支持 snapshot 快速恢复。适用于多副本 Router、需要一致性保证的生产环境。
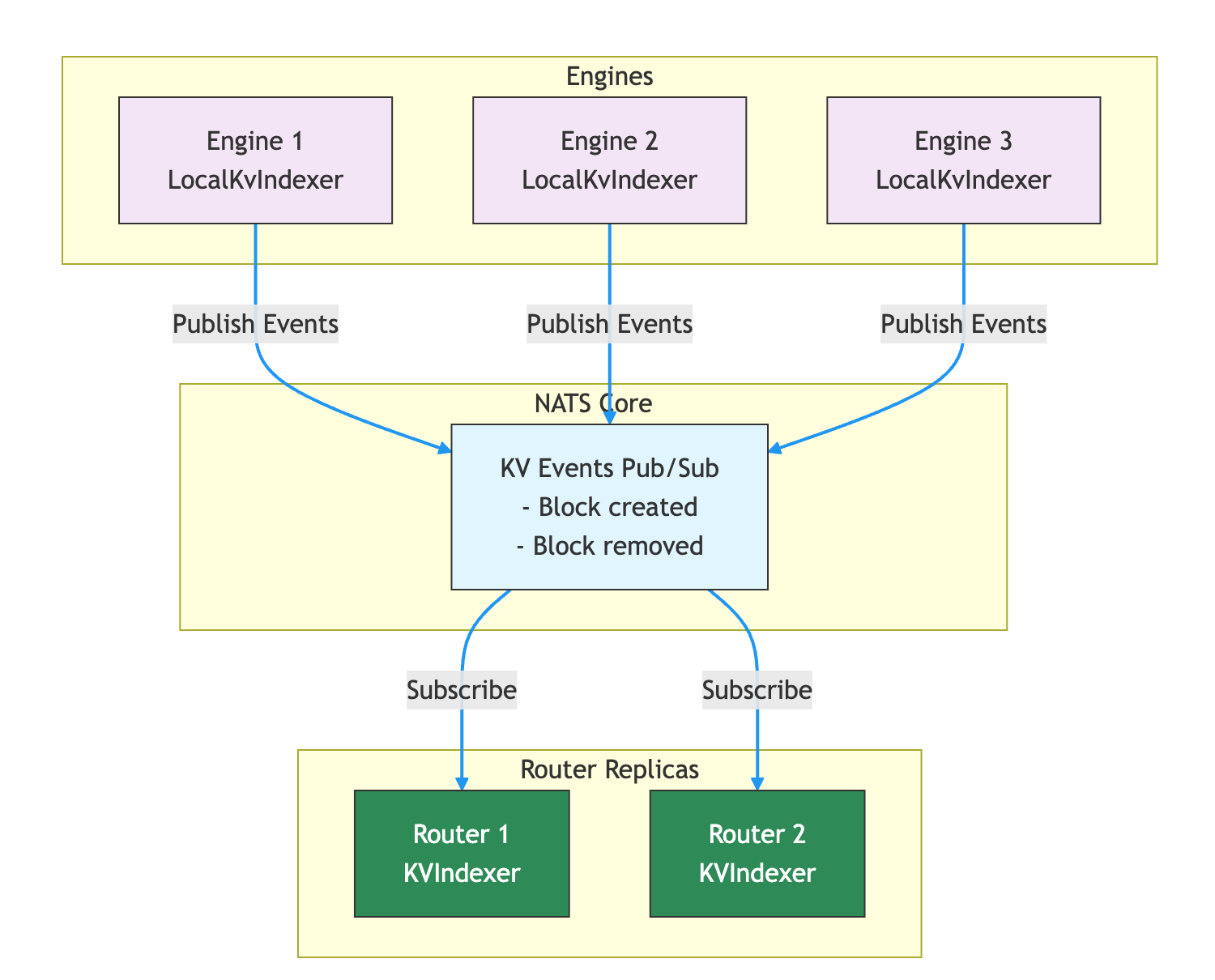
- Local Indexer 模式(默认):Worker 通过 NATS Core 或 ZMQ 发布 KV 事件,Router 接收事件后更新自身索引。由于 NATS Core 不持久化消息,如果 Router 重启或短暂掉线导致事件丢失,Router 会主动查询 Worker 本地的 LocalKvIndexer(Radix Tree)恢复缺失状态。更轻量,不依赖 JetStream。
- JetStream 模式(
-
近似模式(
--no-kv-events):禁用 KV 事件追踪。默认情况下(不提供此标志时),Router 使用 KV 事件监控 Worker 的 Block 创建和删除。启用此标志后,Router 将根据路由决策并结合基于 TTL 的过期(默认 120 秒)和修剪来预测缓存状态。如果你的 Backend 不支持 KV 事件(或对事件的准确性或响应性没有信心),请使用此标志。
1.2.3 配置示例
以下是启用 KV Router 的 DynamoGraphDeployment 配置示例:
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: my-deployment
spec:
services:
Frontend:
dynamoNamespace: my-namespace
componentType: frontend
replicas: 1
envs:
- name: DYN_ROUTER_MODE
value: kv # 启用 KV Cache Aware Routing
- name: DYN_ROUTER_TEMPERATURE
value: "0.5" # 增加随机性防止 Worker 饱和
- name: DYN_KV_OVERLAP_SCORE_WEIGHT
value: "1.5" # 优先 TTFT 而非 ITL
- name: DYN_KV_CACHE_BLOCK_SIZE
value: "16"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.6.0
参考资料:
1.3 SLA Planner
SLA Planner 是 Dynamo 的智能自动扩缩容系统,使用预测建模和性能插值来主动调整 Prefill 和 Decode Worker 数量,确保推理服务满足指定的 TTFT 和 ITL 目标。
1.3.1 扩缩容算法
SLA Planner 使用复杂的扩缩容算法。在每个调整间隔,SLA Planner 执行以下操作:
1. 指标收集
每个调整间隔收集:
- 平均 Time to First Token (TTFT)
- 平均 Inter-Token Latency (ITL)
- 请求数量和持续时间
- 输入/输出序列长度
2. 校正因子计算
校正因子是用生产环境的实际表现去修正理想条件下的 profiling 预测。具体做法是计算 `实际值 / 预期值` 得到校正系数,然后在计算所需副本数时将其带入公式,调整每 GPU 的吞吐量估算,使扩缩容决策更贴近真实情况。使用收集的指标,SLA Planner 应用 Interpolator 找出预期的 TTFT/ITL 并校准插值模型。这一步很重要,因为实际的 TTFT/ITL 通常与理想情况不同:
- TTFT:实际 TTFT 严重依赖于请求排队和 Prefix Cache 命中率(如果使用 KV 复用)。例如,如果所有请求都在调整间隔开始时到达,由于当前 Worker 数量是基于上一周期的负载预测的,Planner 还没来得及扩容,请求只能排队等待,TTFT 会显著更高。如果 Prefix Cache 命中率很高,Prefill 中的实际 token 数量会很低,TTFT 会显著更低。
- ITL:实际 ITL 可能受 Decode 引擎中 Chunked 小 Prefill 请求的影响。
- 指标方差:请求率、ISL 和 OSL 的大方差可能导致 TTFT/ITL 估计不准确,因为 SLA 在插值时只考虑平均值。
SLA Planner 计算校正因子:
- Prefill correction:
actual_ttft / expected_ttft - Decode correction:
actual_itl / expected_itl
3. 负载预测
SLA Planner 使用 Load Predictor 预测下一个调整间隔的请求数量、ISL 和 OSL。目前支持三种负载预测模型:
| Predictor | 算法 | 适用场景 |
|---|---|---|
| Constant | next = current | 稳定负载、长调整间隔 |
| ARIMA | Auto-ARIMA(可选 log1p 变换) | 具有趋势和季节性的模式 |
| Kalman | 局部线性趋势 Kalman 滤波器 | 突发流量 |
| Prophet | Facebook Prophet 时间序列模型 | 复杂的季节性模式 |
4. 计算所需副本数
Prefill 副本数:SLA Planner 假设 Prefill 校正因子对每 GPU 的 Prefill 吞吐量有线性影响,因为通常Prefill 是单批处理的。
predicted_load = next_requests * next_isl / interval * min(1, prefill_correction)
prefill_replicas = ceil(predicted_load / interpolated_throughput / gpus_per_engine)
计算逻辑:
predicted_load:预测的 Prefill 吞吐量需求(tokens/s)next_requests × next_isl:下个时间窗口需要 Prefill 处理的总 token 数(预测请求数 × 预测平均输入序列长度)/ interval:转换为每秒的吞吐量需求× min(1, prefill_correction):用校正因子调整。correction_factor = 实际 TTFT / Interpolator 预测的 TTFT,取min(1, ...)意味着只在性能不如预期时上调负载预测(保守策略)
prefill_replicas:所需副本数predicted_load / interpolated_throughput:预测吞吐量需求 / 从 Interpolator 查表得到的每 GPU 吞吐量/ gpus_per_engine:除以每个 Prefill 实例的 GPU 数ceil(...):向上取整,确保有足够的副本
Decode 副本数:与 Prefill 不同,Decode 是显存带宽密集型操作,使用 Continuous Batching 多请求共享 GPU。ITL 受 KV Cache 占用率和 Context Length 双重影响,因此需要通过 2D 插值反向查找满足 ITL 目标的吞吐量,且校正因子应用于 ITL 目标而非负载。
# 1. 将 d_correction_factor 应用到 ITL SLA
corrected_itl = self.args.itl / self.d_correction_factor
# 2. 反向查找在预测的 context length 下能达到 corrected_itl 的最佳吞吐量/GPU
pred_decode_thpt_per_gpu = self.decode_interpolator.find_best_throughput_per_gpu(
itl=corrected_itl,
context_length=next_isl + next_osl / 2
)
# 3. 计算所需的 decode 副本数
next_num_d = math.ceil(next_num_req * next_osl / self.args.adjustment_interval / pred_decode_thpt_per_gpu / self.args.decode_engine_num_gpu)
5. 执行扩缩容
最后,SLA Planner 通过扩缩容 Prefill 和 Decode Worker 数量到计算出的副本数来应用变更。
1.3.2 使用 DynamoGraphDeploymentRequest 进行 SLA 的性能分析
SLA Planner 要求在部署前完成 Profiling。Profiling 过程分析模型的性能特征,确定最优的并行配置和 Planner 运行时使用的扩缩容参数。
你可以使用 DynamoGraphDeploymentRequest (DGDR) 来部署满足 SLA 优化的 Dynamo DynamoGraphDeploymentRequest 工作流自动化从 SLA 定义到部署的全过程:
- 定义 SLA:在 DynamoGraphDeploymentRequest 中指定性能需求(TTFT、ITL)和模型信息。
- 自动 Profiling:Dynamo Operator 自动对模型进行性能分析,找到最优配置。
- 自动部署:Profiling 完成后,系统自动创建并部署满足 SLA 的 DynamoGraphDeployment(包含最优并行配置和 Planner 组件)和
planner-profile-dataConfigMap(性能插值数据)。
DynamoGraphDeploymentRequest 支持两种性能分析方式:
- Online Profiling (AIPerf):在 Kubernetes 中部署真实推理实例进行性能分析,耗时 2-4 小时,精度最高,支持 vLLM、SGLang、TensorRT-LLM。
- Offline Profiling (AI Configurator):使用性能模拟器快速估算,仅需 20-30 秒,目前仅支持 TensorRT-LLM。
在线性能分析
通过在 Kubernetes 中创建真实的测试部署并测量性能。耗时 2-4 小时,精度最高,支持 vLLM、SGLang、TensorRT-LLM。
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeploymentRequest
metadata:
name: vllm-dense-online
spec:
model: "Qwen/Qwen3-0.6B" # 模型名称
backend: vllm # 推理后端:vllm / sglang / trtllm
profilingConfig:
profilerImage: "nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.7.1" # Profiling 使用的镜像
config:
sla: # SLA
isl: 3000 # 输入序列长度
osl: 150 # 输出序列长度
ttft: 200.0 # 首 Token 延迟目标 (ms)
itl: 20.0 # Token 间延迟目标 (ms)
hardware: # 硬件配置
min_num_gpus_per_engine: 2 # 每实例最小 GPU 数(未指定时根据模型和显存自动确定)
max_num_gpus_per_engine: 8 # 每实例最大 GPU 数
num_gpus_per_node: 8 # 每节点 GPU 数(用于多节点 MoE)
gpu_type: h200_sxm # GPU 类型
sweep:
use_ai_configurator: false # 在线性能分析
deploymentOverrides:
workersImage: "nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.7.1" # 部署时使用的镜像
autoApply: true # Profiling 完成后自动部署 DynamoGraphDeployment
使用 AI Configurator 进行离线模拟分析
使用性能模拟快速估算最优配置,无需运行真实部署。耗时仅 20-30 秒,目前仅支持 TensorRT-LLM。
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeploymentRequest
metadata:
name: trtllm-aic-offline
spec:
model: "Qwen/Qwen3-32B"
backend: trtllm
profilingConfig:
profilerImage: "nvcr.io/nvidia/ai-dynamo/tensorrtllm-runtime:0.6.1"
config:
sla:
isl: 4000
osl: 500
ttft: 300.0
itl: 10.0
sweep:
use_ai_configurator: true # 使用 AI Configurator 离线模拟
aic:
system: h200_sxm
model_name: QWEN3_32B
backend_version: "0.20.0"
deploymentOverrides:
workersImage: "nvcr.io/nvidia/ai-dynamo/tensorrtllm-runtime:0.6.1"
autoApply: true
参考资料:
- SLA-Driven Profiling and Planner Deployment Quick Start Guide
- SLA-Driven Profiling with DynamoGraphDeploymentRequest
- SLA-based Planner
- Planner Design
1.4 KVBM (KV Block Manager)
Dynamo KV Block Manager (KVBM) 是一个可扩展的运行时组件,用于处理跨异构和分布式环境的推理任务中 KV Block 的内存分配、管理和远程共享。KVBM 的架构分为三层:
- LLM 推理运行时层:包括推理运行时(TensorRT-LLM、vLLM),通过专用的 connector 模块与 Dynamo KVBM 集成。这些 connector 充当翻译层,将运行时特定的操作和事件映射为 KVBM 的面向 block 的内存接口。这将内存管理与推理运行时解耦,实现后端可移植性和内存分层。
- KVBM 逻辑层:封装了核心 KV Block Manager 逻辑,作为管理 block 内存的运行时基底。KVBM adapter 将来自不同运行时的传入请求的表示和数据布局进行标准化,并转发给核心内存管理器。该层实现了表查找、内存分配、block 布局管理、生命周期状态转换,以及 block 复用/驱逐策略。
- NIXL 层:为所有数据和存储事务提供统一支持。NIXL 支持 P2P GPU 传输、RDMA 和 NVLink 远程内存共享、动态 block 注册和元数据交换,并提供存储后端的插件接口,包括 block 内存(GPU HBM、Host DRAM、Remote DRAM、Local SSD)、本地/远程文件系统、对象存储和云存储。
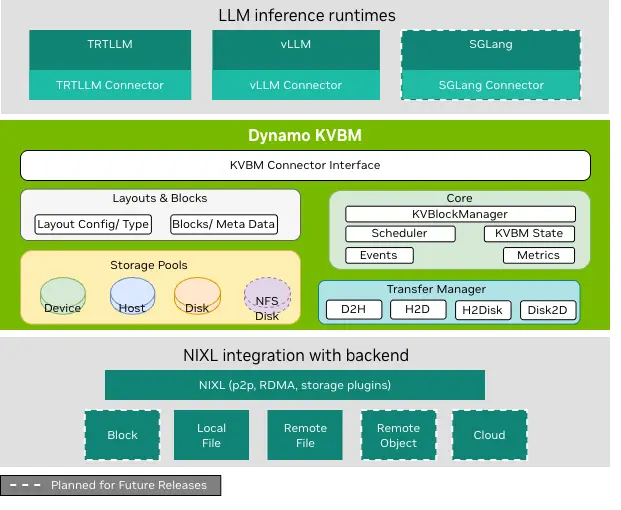
1.4.1 KVBM 内存层级
KVBM 跨多个内存层级协调 KV Block:GPU 显存 (G1)、本地/跨节点 CPU 内存 (G2)、本地/池化 SSD (G3) 和远程存储 (G4)。需要注意的是,KVBM 将 G4 存储视为不透明的 Blob 存储,不感知其内部布局优化。
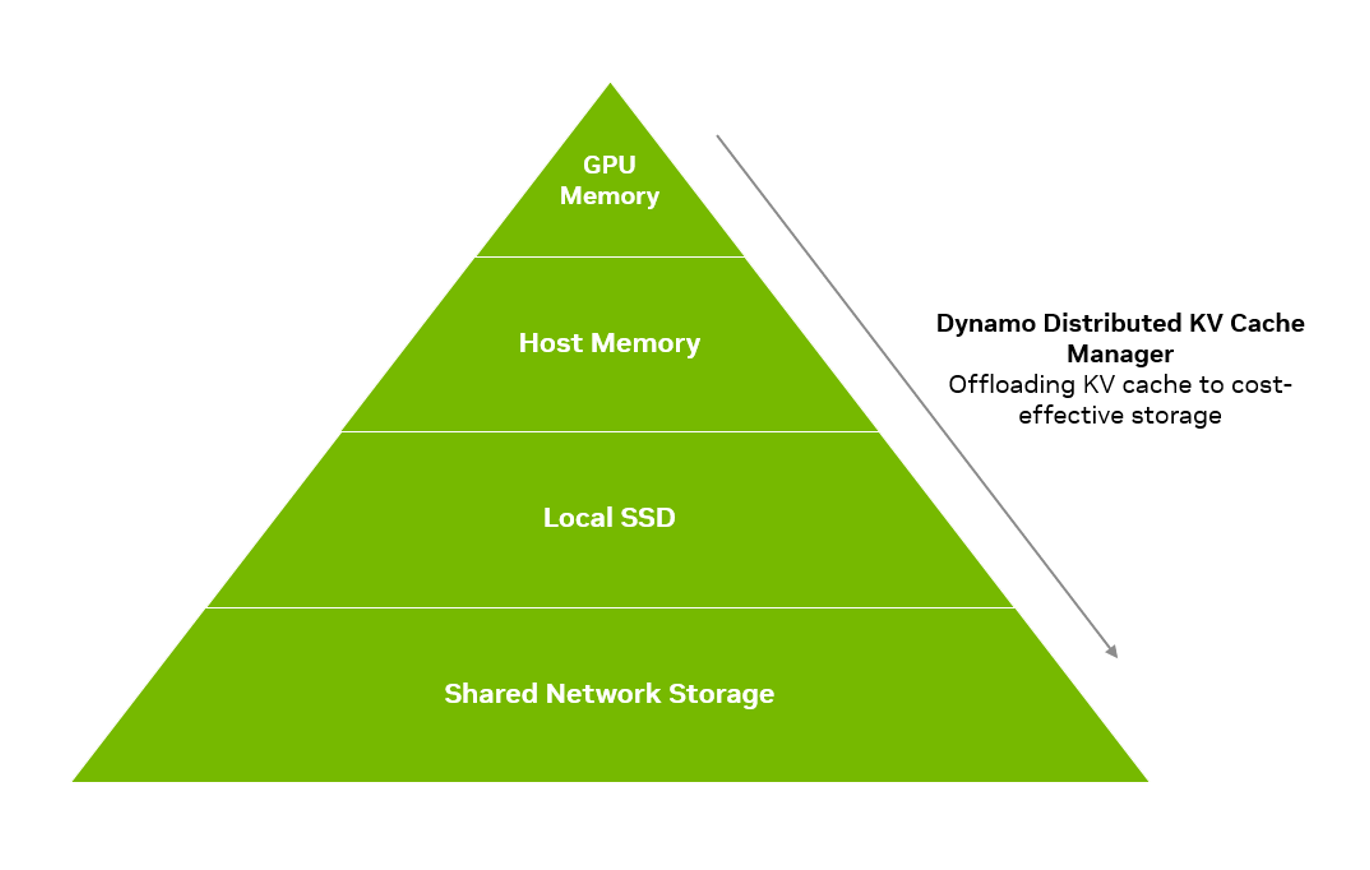
1.4.2 KV Cache Offloading 场景
当 KV Cache 超出 GPU 显存且缓存复用收益大于数据传输开销时,将 KV Cache Offload 到 CPU 或存储最为有效。在长上下文、高并发或资源受限的推理环境中尤其有价值:
- 长会话和多轮对话:Offloading 保留大型 Prompt 前缀,避免重计算,改善首 Token 延迟和吞吐量。
- 高并发(未来):空闲或部分会话可移出 GPU 显存,让活跃请求继续处理而不触及内存限制。
- 共享或重复内容(未来):跨用户/会话复用(如系统 Prompt 和模板)提高缓存命中率,尤其在远程或跨实例共享场景。
- 内存或成本受限部署:Offloading 到 RAM 或 SSD 降低 GPU 需求,允许更长的 Prompt 或更多用户而无需增加硬件。
1.4.3 使用 KVBM
以下示例展示如何在聚合模式下启用 KVBM,将 GPU HBM 中的 KV Cache block offload 到 CPU DRAM,实现内存分层。关键配置:
DYN_KVBM_CPU_CACHE_GB:分配给 KVBM 的 CPU 内存大小,这里配置 100GB。需要确保 Pod 的memory资源请求足够容纳这部分 CPU cache。--kv-transfer-config:vLLM 提供的 KV Cache 传输配置接口,接受一个 JSON 字符串来指定 connector 的类型和行为:kv_connector: DynamoConnector:使用 Dynamo 实现的 KVBM connector,负责将 KV Cache block 在 GPU HBM 和 CPU DRAM 之间进行 offload。这不是 vLLM 内置的 connector,而是 Dynamo 自己实现的。kv_connector_module_path: kvbm.vllm_integration.connector:告诉 vLLM 从该 Python 模块路径加载DynamoConnector。这是 vLLM 提供的外部插件机制——允许第三方在不修改 vLLM 源码的情况下注入自定义的 KV Cache connector。kv_role: kv_both:表示该实例既可以写入也可以读取 KV Cache(区别于 vLLM 原生 PD 分离中的kv_producer/kv_consumer角色)。
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: vllm-agg-kvbm
spec:
services:
Frontend:
componentType: frontend
replicas: 1
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:my-tag
VllmDecodeWorker:
envFromSecret: hf-token-secret
componentType: worker
replicas: 1
resources:
requests:
gpu: "1"
memory: "200Gi" # 需要足够的 CPU 内存容纳 KVBM cache
limits:
gpu: "1"
memory: "250Gi"
envs:
- name: DYN_KVBM_CPU_CACHE_GB # 分配 100GB CPU 内存作为 KV Cache 二级存储
value: "100"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:my-tag
workingDir: /workspace/examples/backends/vllm
command:
- python3
- -m
- dynamo.vllm
args:
- --model
- Qwen/Qwen3-8B
- --max-model-len
- "32000"
- --enforce-eager
- --kv-transfer-config # 通过 vLLM KV Transfer 接口启用 KVBM
- '{"kv_connector":"DynamoConnector","kv_connector_module_path":"kvbm.vllm_integration.connector","kv_role":"kv_both"}'
1.4.4 KV 布局转置
在 PD 分离场景中,Prefill 和 Decode 可以使用不同的 TP 大小(如 Prefill TP=2,Decode TP=8),以分别优化计算密集和内存带宽密集的工作负载。但不同 TP 下每个 GPU 上的 KV Cache 数据切分方式不同,直接传输无法使用。
Dynamo KVBM 通过 block_copy.cu 高性能 CUDA kernel,在 NIXL 传输完成后、数据写入本地 KV Cache 之前,自动将 KV Block 转置为接收方匹配的内存布局。
参考资料:
1.5 NIXL (NVIDIA Inference tranXfer Library)
高性能 P/D 分离的关键是高效的 KV 传输。Dynamo 利用 NIXL 将 KV Cache 直接从 Prefill 实例的显存传输到 Decode 实例的显存。此外,KV 传输是非阻塞的,允许 GPU 在 KV 传输的同时继续执行其他请求的前向传播。
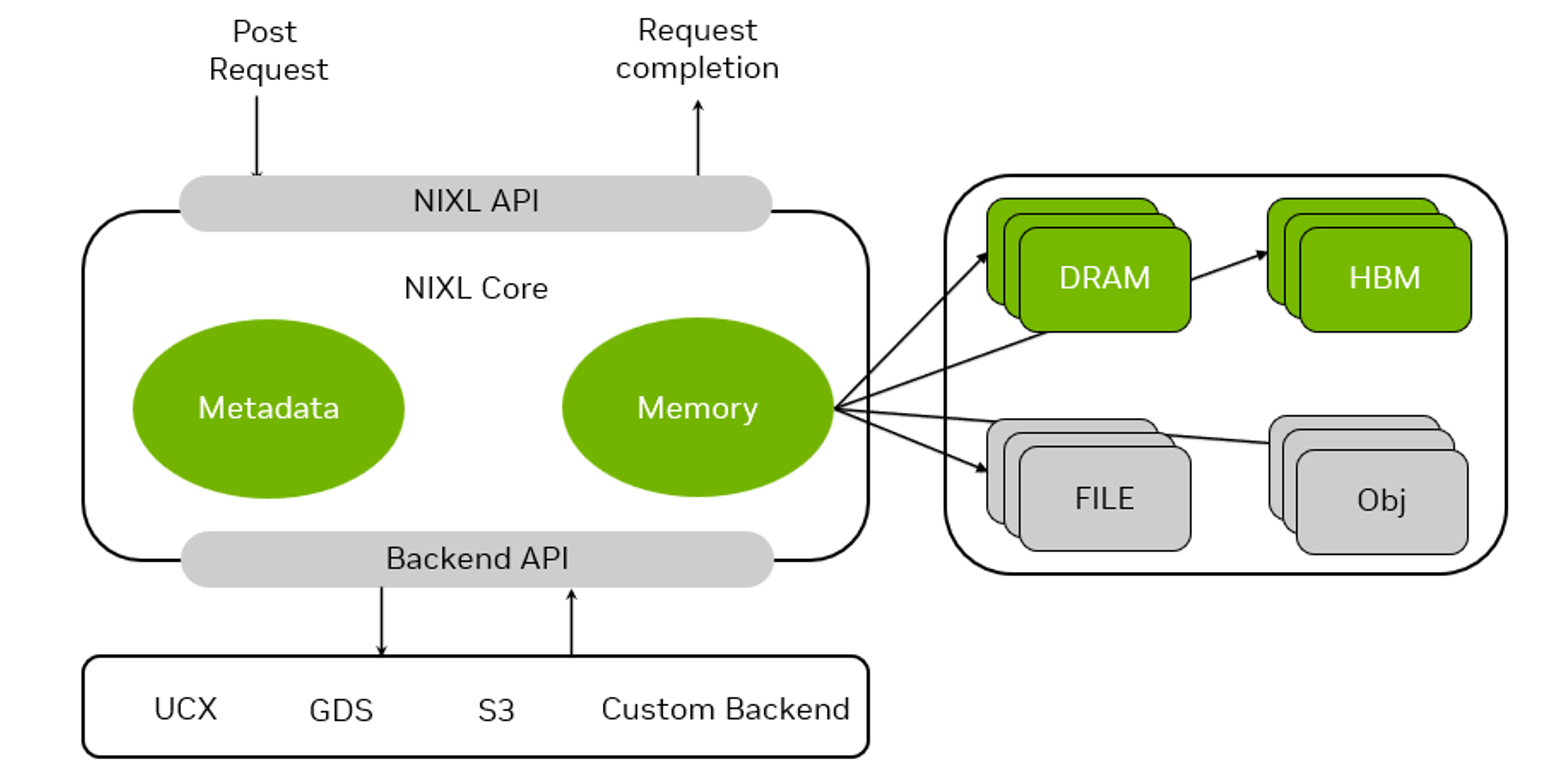
1.5.1 NIXL 支持的后端
NIXL 支持多种后端:
- 块存储(GPU HBM、Host DRAM、Remote DRAM、Local SSD)
- 本地文件系统(POSIX)
- 远程文件系统(NFS)
- 对象存储(S3 兼容)
- 云存储(Blob Storage API)
1.5.2 元数据优化
为了减少内存描述符的大小,Dynamo 采用了两项优化:
-
ETCD 元数据存储:每个 Worker 完成初始化并分配所有 KV Cache 池后,将所有 Block 的内存描述符(也称为 NIXL 元数据)存储到 ETCD(分布式键值存储)中。Prefill Worker 在首次处理某个 Worker 发起的远程 Prefill 请求时,加载并缓存该 Worker 的内存描述符。因此,发起远程 Prefill 请求时只需传递 KV Block ID,而非完整的内存描述符。
-
连续块合并:Dynamo 优化 Prefill 实例中的内存分配器,分配连续的块并将连续块合并为更大的块,以减少 KV Block 的总数。
参考资料:
- NIXL GitHub
- Dynamo Disaggregation: Separating Prefill and Decode for Enhanced Performance
- KVBM components
1.6 Fault Tolerance(容错机制)
Dynamo 提供了全面的容错机制,以确保在生产部署中对 LLM 推理的可靠性。
1.6.1 Request Migration(请求迁移)
Request Migration 允许正在进行的请求在原始 Worker 不可用时迁移到其他 Worker 继续执行,实现故障容错和无缝用户体验。
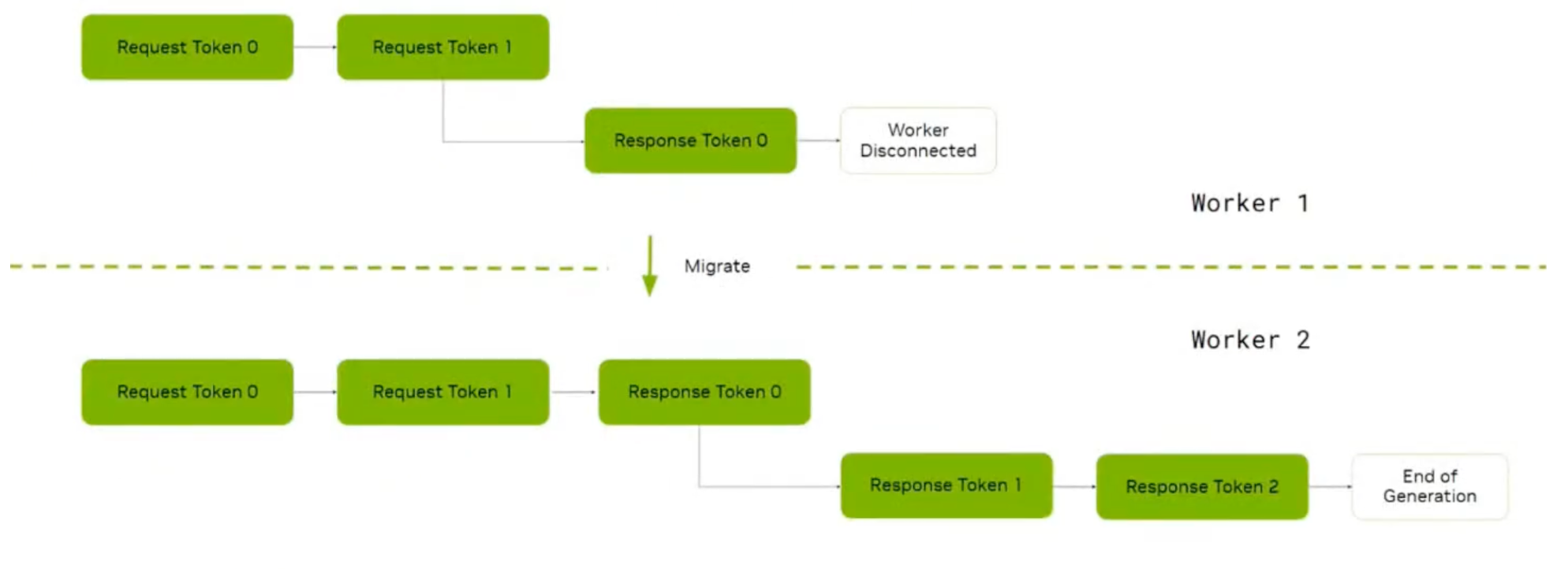
两种迁移场景:
-
New Request Migration(初始连接失败):Worker 在建立初始连接时不可达,系统检测到连接失败后递减重试计数,使用原始请求尝试连接其他 Worker。由于生成尚未开始,无需保存部分状态。
-
Ongoing Request Migration(中途断连):生成过程中连接断开。系统检测到 Stream 终止后,保留已累积的 token 序列(包含原始 prompt 和已生成的所有 token),使用累积状态在新 Worker 上重建 Stream,从断点继续生成。
配置:使用 --migration-limit 参数指定最大迁移次数(默认为 0,即禁用迁移)。
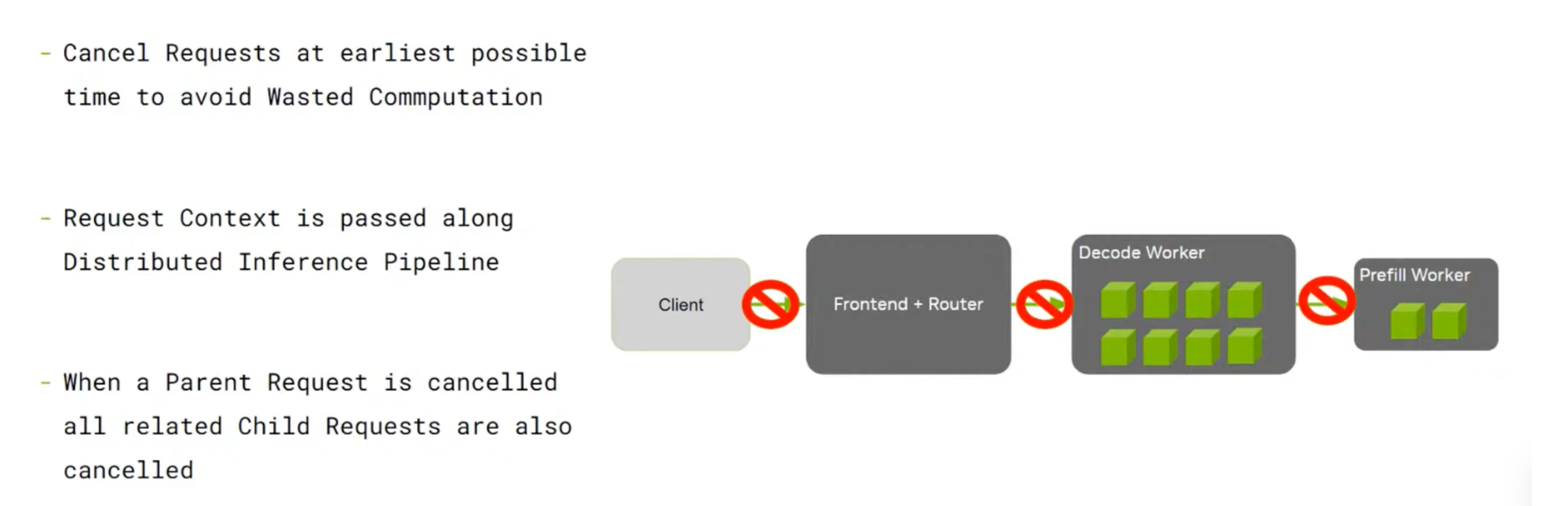
1.6.2 Request Cancellation(请求取消)
Request Cancellation 允许取消正在进行的请求,节省计算资源。使用 HTTP 接口时,如果客户端断开连接,Dynamo 会自动取消发送给 Worker 的下游请求,确保计算资源不会浪费在不再需要的响应生成上。
参考资料:
- Request Migration Architecture
- Request Cancellation Architecture
- Inference Office Hours: Building Fault Tolerance in Systems of Scale for LLM inference
1.6.3 Graceful Shutdown(优雅关闭)
Dynamo 的 Graceful Shutdown 机制确保服务在停止或重启时不会丢失请求:
- 停止接收新请求:端点立即标记为不可用,不再接收新的推理请求。
- 等待在途请求完成:已接收的请求继续处理直到完成(等待时间可配置)。
- 清理资源:释放推理引擎、网络连接和临时文件等资源。
- 正确退出:返回合适的退出码,让 Kubernetes 正确处理 Pod 重启行为。
在生产环境中,建议配置足够的终止宽限期(terminationGracePeriodSeconds),确保在途请求有时间完成处理:
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
spec:
services:
VllmWorker:
extraPodSpec:
terminationGracePeriodSeconds: 60 # Allow time for request draining
1.6.4 Request Rejection(请求拒绝)
Request Rejection是一种容错机制,在 Worker 过载时主动拒绝新请求,这可以防止:
- 资源耗尽导致的级联故障。
- 所有请求的延迟恶化。
- GPU Worker 的 OOM。
当所有 Worker 超过配置的繁忙阈值时,新请求会收到 HTTP 503(Service Unavailable)响应,提示客户端稍后重试。
在启动 Router 时可以配置繁忙阈值,例如当 Worker 的 KV Cache block 利用率超过 85% 或正在处理的 Prefill token 数超过 10000 时,Router 认为该 Worker 繁忙,不再向其分发新请求:
python -m dynamo.frontend \
--active-decode-blocks-threshold 0.85 \
--active-prefill-tokens-threshold 10000
1.7 多节点部署
当模型参数量超出单个 GPU 甚至单台机器的显存容量时,需要通过多节点部署将模型分布在多个 GPU 或者多个服务器上进行推理。
1.7.1 多节点编排方案
Dynamo 支持两种多节点编排方案:
- Grove + KAI-Scheduler(默认)
- Grove:Grove 提供单一声明式接口编排 AI 推理工作负载,从简单单 Pod 部署到复杂多节点 P/D 分离系统。Grove 支持从单副本扩展到数据中心规模(数万 GPU),提供多级自动扩缩容和显式启动顺序。
- KAI-Scheduler:KAI-Scheduler 是一个强大、高效且可扩展的 Kubernetes 调度器,旨在为 AI 和机器学习工作负载优化 GPU 资源分配。KAI-Scheduler 支持 Gang 调度、拓扑感知放置,管理大规模 GPU 集群,在确保不同使用者之间资源公平性的同时实现资源的最佳分配。
- LWS + Volcano
当两者都可用时,Grove 默认被选中(推荐用于高级 AI 工作负载)。可通过 nvidia.com/enable-grove: "false" 注解强制使用 LWS。
1.7.2 DynamoGraphDeployment 配置
用户只需在 DynamoGraphDeployment 中通过 multinode 字段声明节点数量,Dynamo Operator 会自动将其转换为底层的 LeaderWorkerSet (LWS) / Grove 配置,无需手动管理分布式编排细节:
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: my-multinode-deployment
spec:
services:
my-service:
multinode: # 多节点配置
nodeCount: 2 # 节点数量
resources:
limits:
gpu: "4" # 每节点 GPU 数量
extraPodSpec:
mainContainer:
args:
- "--tp-size"
- "8" # 必须等于 nodeCount × gpu
GPU 分配关系:总 GPU 数 = multinode.nodeCount × gpu
1.7.3 自动注入分布式参数
Dynamo Operator 会根据 Backend 自动注入分布式执行参数:
vLLM(使用 Ray):
- Leader 节点:
ray start --head --port=6379 && <vllm-command> --distributed-executor-backend ray - Worker 节点:
ray start --address=<leader-hostname>:6379 --block
SGLang:
- 自动注入:
--dist-init-addr <leader-hostname>:29500 --nnodes <count> --node-rank <rank>
TensorRT-LLM(使用 MPI):
- 自动配置 SSH 密钥和
mpirun命令
参考资料:
1.8 LoRA Adapter
Dynamo 通过 DynamoModel CRD 实现动态模型管理,主要用于在运行中的推理服务上动态加载/卸载 LoRA Adapter,无需重启 Pod。
1.8.1 工作流程
创建 DynamoModel 时,Dynamo Operator 会执行以下操作:
- 发现端点:通过匹配 DynamoGraphDeployment 中的
modelRef.name找到所有运行baseModelName的 Pod。 - 创建 Service:自动创建 Kubernetes Service 来追踪这些 Pod。
- 加载 LoRA:对每个端点调用 LoRA 加载 API(仅
lora类型)。 - 更新状态:报告哪些端点已就绪。
1.8.2 配置示例
# 1. 部署基础模型
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: my-deployment
spec:
services:
Worker:
modelRef:
name: Qwen/Qwen3-0.6B # 关联 DynamoModel
componentType: worker
replicas: 2
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.7.1
args:
- --model
- Qwen/Qwen3-0.6B
- --enable-lora # 启用 LoRA
- --max-lora-rank
- "64"
---
# 2. 部署 LoRA Adapter
apiVersion: nvidia.com/v1alpha1
kind: DynamoModel
metadata:
name: my-lora
spec:
modelName: my-custom-lora # LoRA 模型标识符
baseModelName: Qwen/Qwen3-0.6B # 必须匹配 DynamoGraphDeployment 中的 modelRef.name
modelType: lora
source:
uri: s3://my-bucket/loras/my-lora # 支持 s3:// 或 hf://
1.8.3 多 LoRA 场景
同一基础模型可加载多个 LoRA Adapter:
# LoRA 1: 客服场景
apiVersion: nvidia.com/v1alpha1
kind: DynamoModel
metadata:
name: support-lora
spec:
modelName: support-adapter
baseModelName: Qwen/Qwen3-0.6B
modelType: lora
source:
uri: s3://models/support-lora
---
# LoRA 2: 代码场景
apiVersion: nvidia.com/v1alpha1
kind: DynamoModel
metadata:
name: code-lora
spec:
modelName: code-adapter
baseModelName: Qwen/Qwen3-0.6B # 同一基础模型
modelType: lora
source:
uri: s3://models/code-lora
请求时通过 model 字段指定使用哪个 LoRA:
curl -X POST http://localhost:8000/v1/completions \
-d '{"model": "support-adapter", "prompt": "Hello"}'
参考资料:
2. llm-d
llm-d 是一个可扩展的架构,旨在跨模型服务 Pod 高效路由推理请求。该架构的核心组件是 Inference Gateway,它基于 Kubernetes 原生的 Gateway API Inference Extension 构建,实现可扩展、灵活且可插拔的请求路由。
2.1 Inference Scheduler
Inference Scheduler 为 llm-d 推理框架提供 Endpoint Picker (EPP) 组件,为推理请求做出优化的路由决策。
EPP 扩展了 Gateway API Inference Extension (GIE) 项目,该项目提供调度所需的 API 资源和机制。llm-d 在此基础上添加了特定功能,如 P/D 分离。两个项目紧密协作,llm-d 中的功能通常需要在 GIE 代码库中进行支持和扩展。独特的实验性功能可能先在 llm-d 中实现,随着时间推移迁移到 GIE。
2.1.1 EPP 配置示例
EPP 配置主要由 plugins 和 schedulingProfiles 组成:
- plugins:定义可用的插件实例及其参数。
- schedulingProfiles:定义调度配置文件,指定请求处理时使用哪些插件。
路由决策通过可插拔组件实现:
- Filter:根据条件排除 Pod(如
decode-filter仅保留 Decode 角色的 Pod)。 - Scorer:为候选 Pod 评分(如
prefix-cache-scorer基于 KV Cache 命中率评分),通过weight指定权重。
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: prefix-cache-scorer
parameters:
hashBlockSize: 5
maxPrefixBlocksToMatch: 256
lruCapacityPerServer: 31250
- type: decode-filter
- type: max-score-picker
- type: single-profile-handler
schedulingProfiles:
- name: default
plugins:
- pluginRef: decode-filter
- pluginRef: max-score-picker
- pluginRef: prefix-cache-scorer
weight: 50
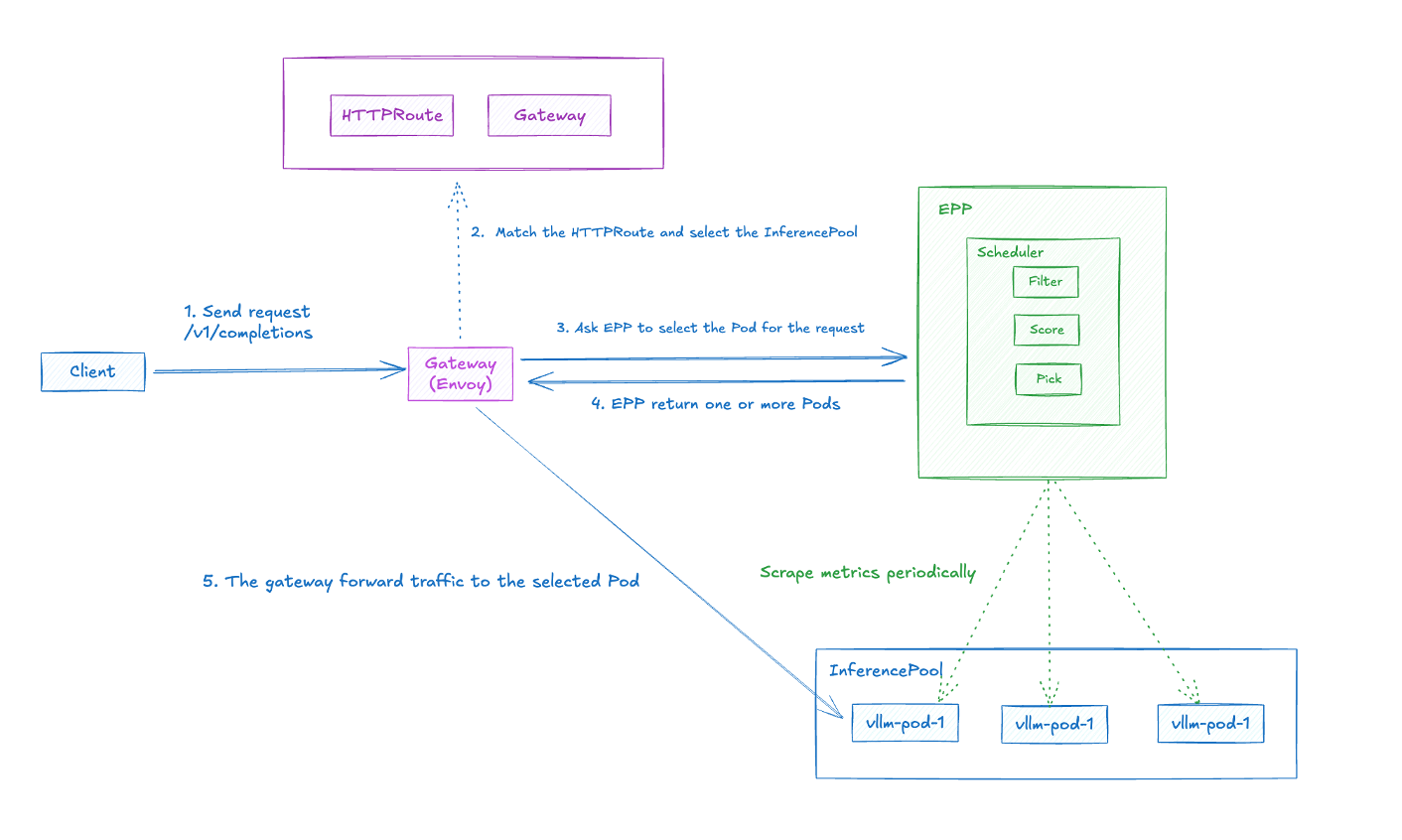
2.1.2 请求流程
一次请求的流程如下:
- Client 发送请求(如
/v1/completions)到 Gateway(Envoy)。 - Gateway 匹配 HTTPRoute 并选择对应的 InferencePool。
- Gateway 通过 ext-proc 询问 EPP 应该路由到哪个 Pod,EPP 内部执行 Filter → Score → Pick 流程。
- EPP 返回选中的 Pod。
- Gateway 将请求转发到选中的 Pod。
EPP 会周期性地从 InferencePool 中的 Pod 抓取 metrics,用于评分决策。
2.2 KV-Cache Indexer
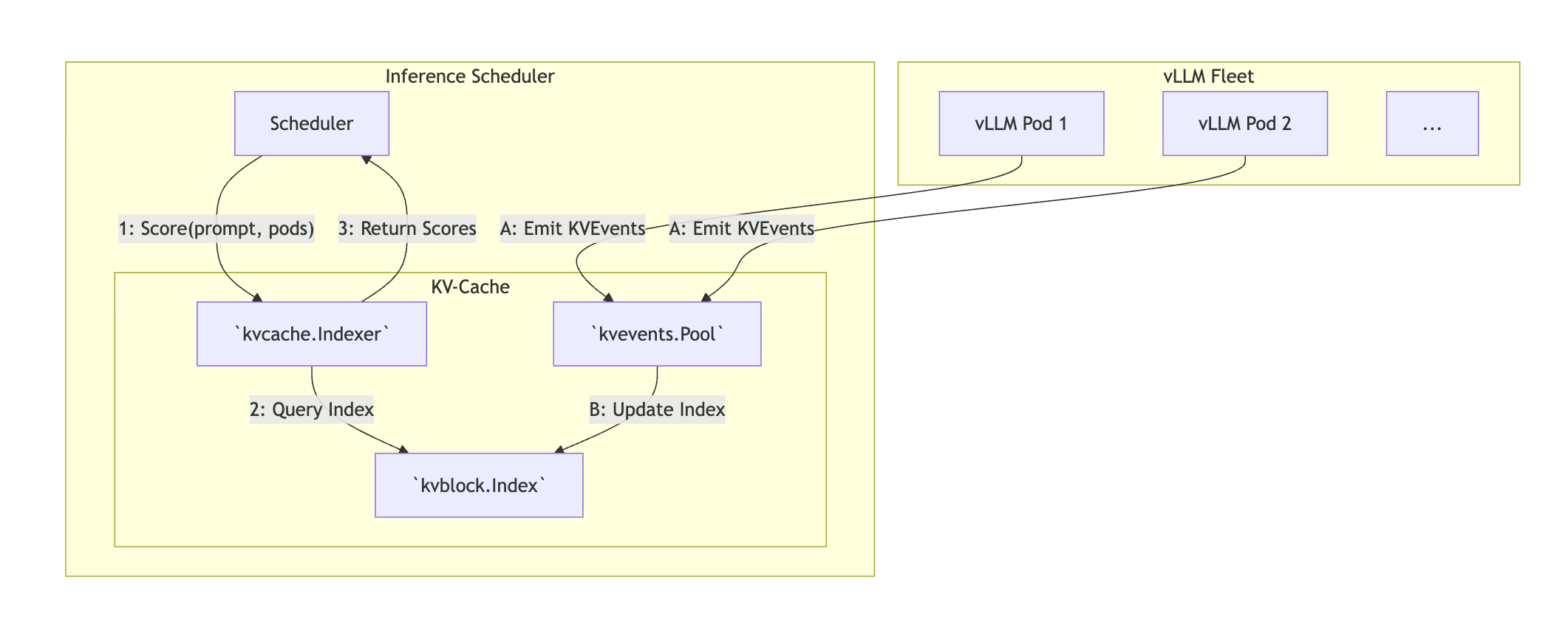
KV-Cache Indexer 是一个高性能库,用于维护跨多个 vLLM Pod 的 KV-Cache Block 位置的全局近实时视图。其目的是通过提供基于缓存 KV-Blocks 的快速智能评分机制,实现对 vLLM Pod 的智能路由和调度。
Indexer 由 vLLM 流式传输的 KV Event 驱动 – 当 KV Block 在 vLLM 实例中创建或驱逐时,会发出结构化元数据事件。Indexer 据此追踪每个 Block 所在的节点和存储层(GPU/CPU),为 KV Cache 感知的路由决策提供依据。
2.3 PD 分离
请求流程如下:
- Client 发送推理请求到 Gateway (Envoy)。
- Gateway 将请求转发给 EPP 调度器进行端点选择。
- EPP 执行两阶段调度:
- 首先,使用 decode profile 选择一个 Decode Pod。
- 然后,根据 prompt 长度、prefix cache 命中率和 pdThreshold 判断是否需要 Prefill Pod。
- 如果需要,运行 prefill profile 选择 Prefill Pod。
- EPP 仅将 Decode Pod 的端点返回给 Gateway,但通过
prefill-header-handler插件将 Prefill Pod 地址(如已选择)注入 HTTP headerx-prefiller-host-port。 - Gateway 将请求转发到 Decode Pod 的 sidecar。
- Sidecar 检查
x-prefiller-host-portheader:- 如果存在,先联系 Prefill Pod 执行 prefill(设置
max_output_tokens=1)并获取 KV cache 信息。 - 然后将包含 prefill 结果的完整请求转发到本地 Decode Pod。
- 如果存在,先联系 Prefill Pod 执行 prefill(设置
- Decode Pod 生成最终响应,通过 sidecar → gateway → client 返回。
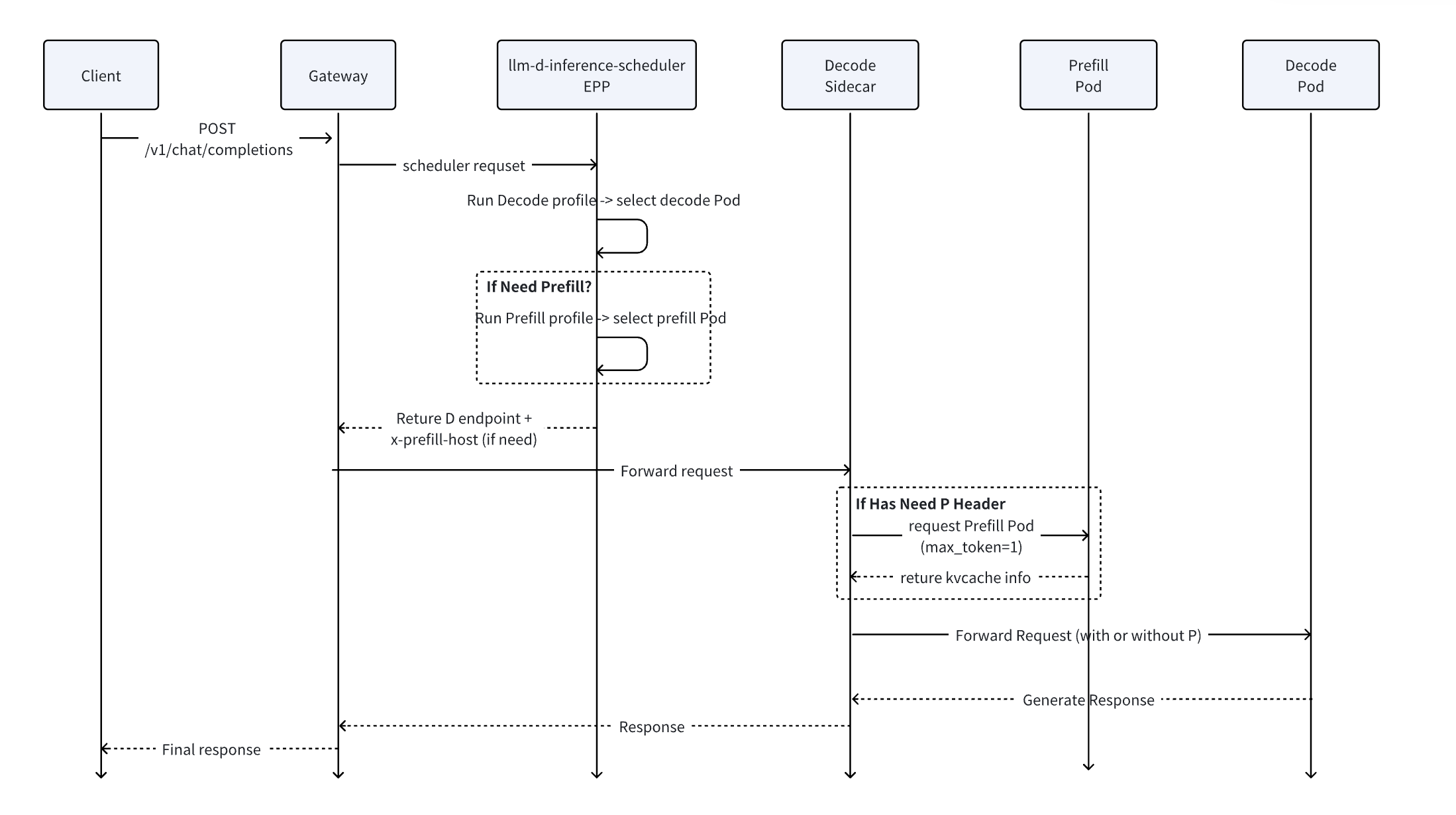
P/D 分离的 EPP 配置示例如下:
apiVersion: inference.networking.x-k8s.io/v1alpha1
kind: EndpointPickerConfig
plugins:
- type: prefill-header-handler # 注入 x-prefiller-host-port header
- type: prefix-cache-scorer
parameters:
hashBlockSize: 5
maxPrefixBlocksToMatch: 256
lruCapacityPerServer: 31250
- type: prefill-filter # Prefill 角色过滤器
- type: decode-filter # Decode 角色过滤器
- type: max-score-picker
- type: pd-profile-handler # P/D 配置文件处理器
parameters:
threshold: 10 # pdThreshold,决定是否需要 Prefill
hashBlockSize: 5
schedulingProfiles:
- name: prefill # prefill-profile
plugins:
- pluginRef: prefill-filter # 仅保留 Prefill 角色的 Pod
- pluginRef: max-score-picker
- pluginRef: prefix-cache-scorer
weight: 50
- name: decode # decode-profile
plugins:
- pluginRef: decode-filter # 仅保留 Decode 角色的 Pod
- pluginRef: max-score-picker
- pluginRef: prefix-cache-scorer
weight: 50
P/D 分离的组件关系如下图所示:
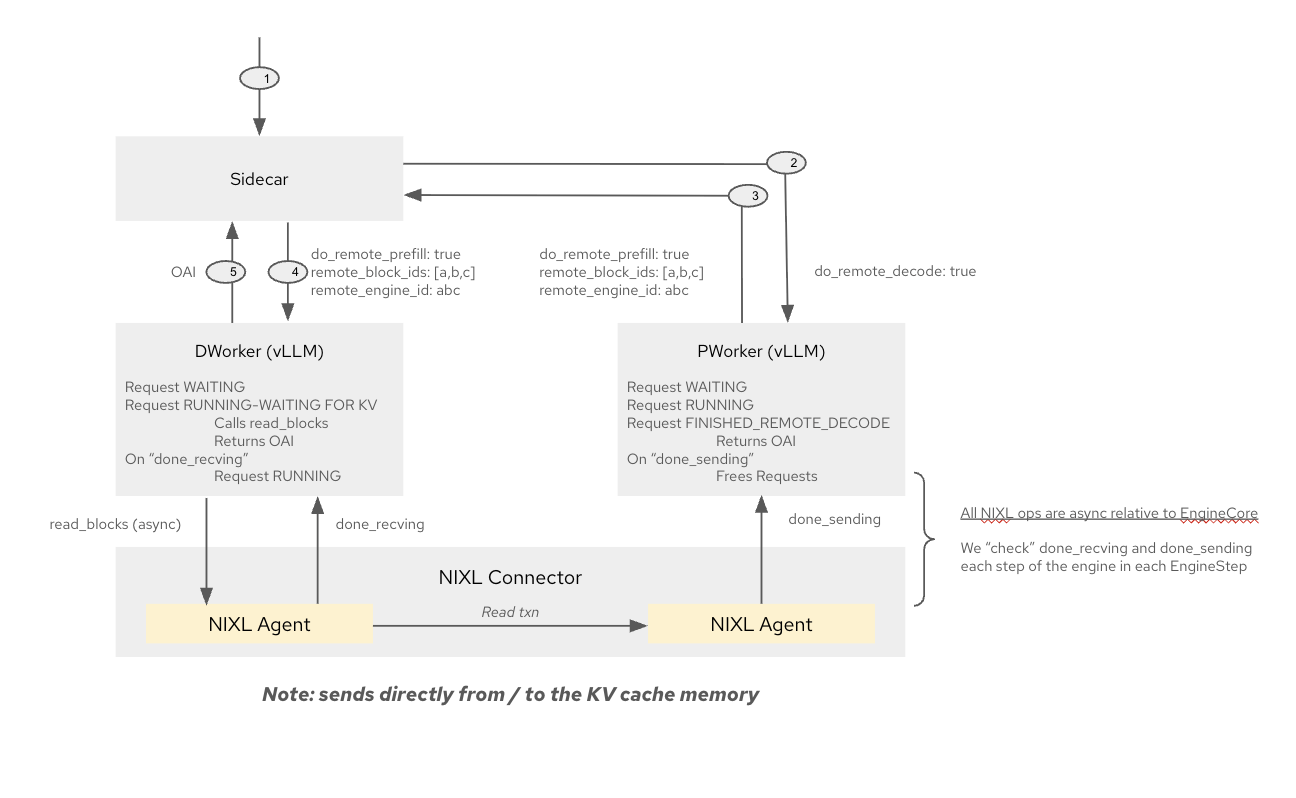
参考资料:Disaggregated Prefill/Decode Inference Serving in LLM-D
2.4 vLLM Simulator
vLLM Simulator 是一个轻量级 vLLM 模拟器,用于在无需真实 GPU 资源的情况下模拟 vLLM 实例。
核心功能:
- API 兼容:实现
/v1/completions、/v1/chat/completions、/v1/models端点。 - Prometheus Metrics:通过
/metrics端点暴露 vLLM 兼容的指标,包括vllm:num_requests_running、vllm:e2e_request_latency_seconds、vllm:time_to_first_token_seconds等。 - 响应模式:
- Echo 模式:响应返回请求中的相同文本,对于
/v1/chat/completions使用最后一条role=user的消息。 - Random 模式:从预定义的句子集合中随机选择响应。
- Echo 模式:响应返回请求中的相同文本,对于
- LoRA 支持:可模拟 LoRA 适配器的加载/卸载。
- P/D 分离:支持 P/D 分离部署模拟。
使用场景:
- 开发和测试 LLM 推理基础设施。
- 在 Kind 等环境中进行 Kubernetes 部署测试。
3. Kthena
Kthena 是一个专为 Kubernetes 设计的云原生、高性能 LLM 推理路由和编排、调度系统。作为 Volcano 的子项目,Kthena 致力于帮助 Volcano 扩展除 AI 训练之外的边界,打造训推一体的完整解决方案。
3.1 网络拓扑感知调度
在分布式 AI 推理中,节点间的通信延迟直接影响推理效率。通过感知网络拓扑,可以将频繁通信的任务调度到网络距离较近的节点上,从而显著降低通信开销。由于不同网络链路的带宽各异,高效的任务调度能够避免网络拥塞,充分利用高带宽链路,提升整体数据传输效率。
Kthena 利用 Volcano 实现网络拓扑感知调度。为了屏蔽数据中心网络类型的差异,Volcano 定义了一个新的 CRD HyperNode 来表示网络拓扑,提供标准化的 API 接口。HyperNode 代表一个网络拓扑性能域,通常映射到交换机或 TOR。多个 HyperNode 以层级方式连接形成树状结构:
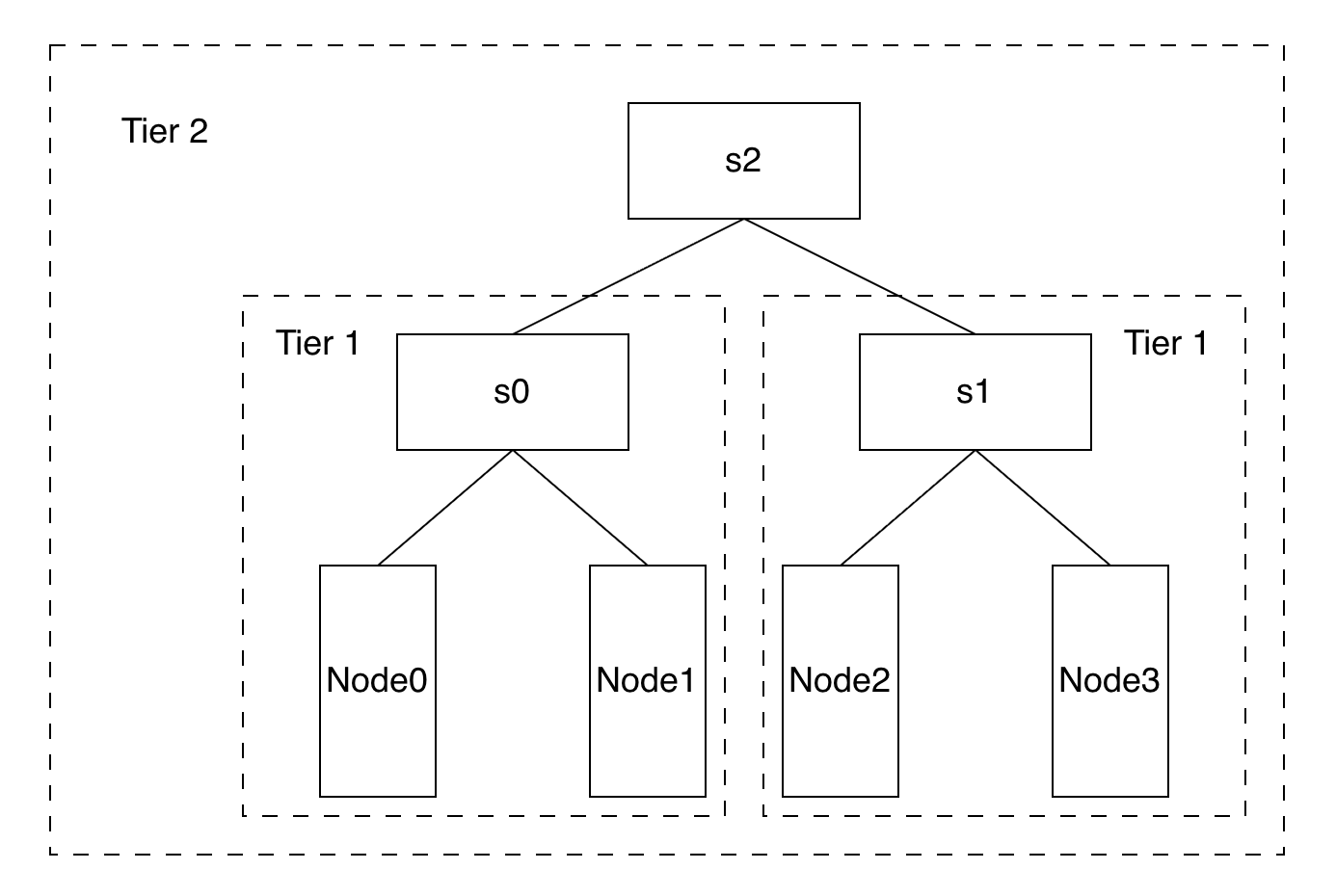
在这个结构中,节点间的通信效率取决于它们之间跨越的 HyperNode 层级。例如:
- node0 和 node1 属于 s0,通信效率最高。
- node1 和 node2 需要跨越两层
HyperNode(s0→s2→s1),通信效率较低。
其中 Tier 表示 HyperNode 的层级,层级越低,HyperNode 内节点间的通信效率越高。以下是一个 HyperNode 配置示例:
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s0
spec:
tier: 1 # s0 位于 Tier 1
members:
- type: Node # 成员类型为 Node
selector: # 假设 Node 有 name: <node-name> 的 label
exactMatch:
name: node0
- type: Node
selector:
exactMatch:
name: node1
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s1
spec:
tier: 1 # s1 位于 Tier 1
members:
- type: Node
selector:
exactMatch:
name: node2
- type: Node
selector:
exactMatch:
name: node3
---
apiVersion: topology.volcano.sh/v1alpha1
kind: HyperNode
metadata:
name: s2
spec:
tier: 2 # s2 位于 Tier 2
members:
- type: HyperNode # 成员类型为 HyperNode
selector:
exactMatch:
name: s0 # 引用下层的 HyperNode s0
- type: HyperNode
selector:
exactMatch:
name: s1 # 引用下层的 HyperNode s1
更多关于 HyperNode CRD 的细节请参考 Volcano Network Topology Aware Scheduling。
Kthena 的 ModelServing 提供了 networkTopology 字段来配置 ServingGroup 级别和 Role 级别的网络拓扑约束。下面配置表示整个 ServingGroup 的 Pod 允许跨越 Tier 2 的 HyperNode(s2),即可以分布在 s0 和 s1 之间;而同一 Role 内的 Pod 只能在 Tier 1 的 HyperNode 内(必须在同一个 s0 或 s1 内)。
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: ModelServing
metadata:
name: sample
namespace: default
spec:
schedulerName: volcano
replicas: 1 # servingGroup replicas
template:
networkTopology:
groupPolicy: # ServingGroup 级别的网络拓扑
mode: hard
highestTierAllowed: 2
rolePolicy: # Role 级别的网络拓扑
mode: hard
highestTierAllowed: 1
roles:
- name: prefill
replicas: 2 # 2 个 prefill 实例
workerReplicas: 1 # 每个实例 1 entry + 1 worker = 2 Pod
entryTemplate:
# ......
workerTemplate:
# ......
- name: decode
replicas: 1 # 1 个 decode 实例
workerReplicas: 1 # 每个实例 1 entry + 1 worker = 2 Pod
entryTemplate:
# ......
workerTemplate:
# ......
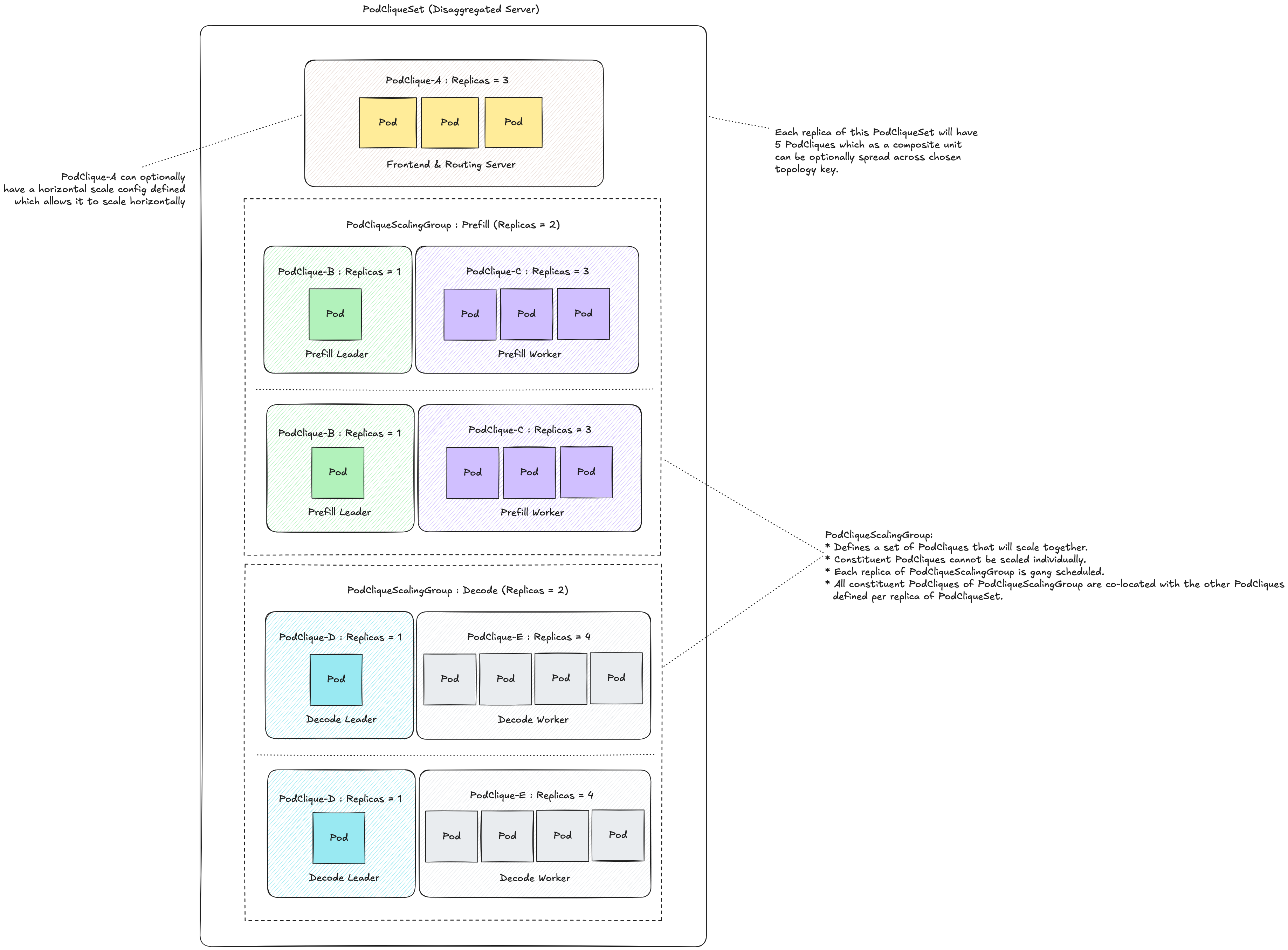
Kthena 中 ModelServing、ServingGroup、Role 和 Pod 的层级关系如下:
ModelServing: sample
├── ServingGroup: sample-0 (replicas 中的第 1 个)
│ ├── Prefill Role
│ │ ├── prefill-0: sample-0-prefill-0-0, sample-0-prefill-0-1
│ │ └── prefill-1: sample-0-prefill-1-0, sample-0-prefill-1-1
│ └── Decode Role
│ └── decode-0: sample-0-decode-0-0, sample-0-decode-0-1
│
├── ServingGroup: sample-1 (如果 replicas=2)
│ ├── Prefill Role
│ │ └── ...
│ └── Decode Role
│ └── ...
基于上述网络拓扑和 ModelServing 配置,Pod 可能的调度情况如下。这个调度结果体现了 groupPolicy 和 rolePolicy 的区别:
groupPolicy.highestTierAllowed: 2:整个 ServingGroup 的所有 Pod 可以分布在 s2 内的不同 Tier 1 HyperNode(s0 和 s1)中。rolePolicy.highestTierAllowed: 1:同一 Role 的所有 Pod 必须在同一个 Tier 1 HyperNode 内。因此 prefill 的所有 Pod 都在 s0 内,decode 的所有 Pod 都在 s1 内。
关键字段说明:
groupPolicy:ServingGroup 级别的网络拓扑约束,约束整个 ServingGroup 内所有 Pod 的网络拓扑距离。rolePolicy:Role 级别的网络拓扑约束,约束同一 Role 内所有 Pod 的网络拓扑距离。mode:调度模式。hard:硬约束,作业内的任务必须部署在同一 HyperNode 内。soft:软约束,尽可能将任务部署在同一 HyperNode 内。
highestTierAllowed:与hard模式配合使用,表示作业部署允许的最高 HyperNode 层级。
更多 Kthena 网络拓扑细节参考:https://kthena.volcano.sh/docs/user-guide/network-topology
3.2 Autoscaler
Kthena Autoscaler 根据实时负载动态调整推理实例数量,在维护健康的业务指标(如 SLO)的同时优化计算资源消耗。Autoscaler 通过两个 CRD 进行配置:
- AutoscalingPolicy:定义核心扩缩容策略、指标和行为参数。
- AutoscalingPolicyBinding:将策略绑定到目标资源并指定扩缩容的副本数边界。
Kthena Autoscaler 提供两种扩缩容粒度:同构实例扩缩容 和 异构实例扩缩容。
3.2.1 同构实例扩缩容(Homogeneous)
针对单一类型推理实例的扩缩容,类似于 Knative 的 KPA,支持 Stable 和 Panic 两种模式:
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: AutoscalingPolicy
metadata:
name: scaling-policy
spec:
metrics:
- metricName: kthena:num_requests_waiting # 监控指标
targetValue: 10.0 # 目标值
tolerancePercent: 10 # 容忍度,防止频繁扩缩容
behavior:
scaleUp:
panicPolicy: # Panic 模式:流量突增时快速扩容
panicThresholdPercent: 150 # 超过目标值 150% 时触发
panicModeHold: 5m
stablePolicy: # Stable 模式:稳定扩容
stabilizationWindow: 1m
period: 30s
scaleDown:
stabilizationWindow: 5m # 缩容稳定窗口,避免过早缩容
period: 1m
---
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: AutoscalingPolicyBinding
metadata:
name: scaling-binding
spec:
policyRef:
name: scaling-policy
homogeneousTarget:
target:
targetRef:
kind: ModelServing
name: example-model-serving
minReplicas: 2
maxReplicas: 10
3.2.2 异构实例扩缩容(Heterogeneous)
对于同一模型,推理实例可以部署在多种配置上:
- 异构资源类型(GPU/NPU)
- 不同推理引擎(vLLM/SGLang)
- 不同运行时参数(如 TP/DP 配置)
这些不同部署的实例提供相同的推理服务,但在硬件资源需求和性能上有所不同。使用异构扩缩容时,需要为每种配置分别创建一个 ModelServing(如 gpu-serving-instance 和 cpu-serving-instance),然后通过 AutoscalingPolicyBinding 的 heterogeneousTarget 将它们绑定到同一个扩缩容策略。Autoscaler 通过成本优化算法,在满足性能需求的同时最小化资源成本:
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: AutoscalingPolicyBinding
metadata:
name: optimizer-binding
spec:
policyRef:
name: optimizer-policy
heterogeneousTarget:
costExpansionRatePercent: 20 # 成本扩展率
params:
- target:
targetRef:
kind: ModelServing
name: gpu-serving-instance # GPU 实例
minReplicas: 1
maxReplicas: 5
cost: 100 # 成本权重
- target:
targetRef:
kind: ModelServing
name: cpu-serving-instance # CPU 实例
minReplicas: 2
maxReplicas: 8
cost: 30 # 成本更低
3.2.3 Role 级别扩缩容
对于 P/D 分离场景,可以针对特定 Role(如 Prefill 或 Decode)独立配置扩缩容策略:
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: AutoscalingPolicyBinding
metadata:
name: role-binding
spec:
policyRef:
name: scaling-policy
homogeneousTarget:
target:
targetRef:
kind: ModelServing
name: example-model-serving
subTargets:
kind: Role
name: prefill # 仅针对 prefill role 扩缩容
minReplicas: 1
maxReplicas: 5
参考资料:
4. RoleBasedGroup
RoleBasedGroup (RBG) 用于编排分布式、有状态的 AI 推理工作负载,支持多角色协同和内置服务发现。它为生产环境中的大语言模型推理(尤其是解耦架构,如 Prefill/Decode 分离场景)提供了通用的部署范式。
4.1 Instance 和 InstanceSet
RoleBasedGroup 支持为每个 Role 指定不同的底层 workload 类型,默认使用 StatefulSet,也可以指定 Deployment、LeaderWorkerSet 或 InstanceSet。
InstanceSet 是 RBG 引入的新 workload 类型,管理多个 Instance 副本,支持原地更新和滚动更新。每个 Instance 是一个逻辑推理实例,可以包含多个 Pod(如 leader + worker),这些 Pod 的生命周期同步(Gang Scheduling、同步启停、一个 Pod 失败时整个 Instance 重启):
InstanceSet: deepseek (replicas: 3)
├── Instance: deepseek-0
│ ├── Pod: deepseek-0-leader-0
│ ├── Pod: deepseek-0-worker-0
│ ├── Pod: deepseek-0-worker-1
│ └── Pod: deepseek-0-worker-2
├── Instance: deepseek-1
│ ├── Pod: deepseek-1-leader-0
│ └── ...
└── Instance: deepseek-2
└── ...
对应的 RoleBasedGroup 配置(使用 leaderWorkerSet 配置模式)。注意:这里的 leaderWorkerSet 是 RBG 自己的配置字段,用于描述 leader-worker 拓扑,而不是使用外部的 LeaderWorkerSet (LWS) workload。实际创建的是 RBG 的 InstanceSet 资源:
apiVersion: workloads.x-k8s.io/v1alpha1
kind: RoleBasedGroup
metadata:
name: deepseek
spec:
roles:
- name: engine
replicas: 3 # 3 个 Instance
workload:
apiVersion: workloads.x-k8s.io/v1alpha1
kind: InstanceSet
template: # 基础模板(Leader 和 Worker 共用)
spec:
containers:
- name: main
image: vllm/vllm-openai:v0.8.0
resources:
limits:
nvidia.com/gpu: "8"
leaderWorkerSet:
size: 4 # 每个 Instance 包含 4 个 Pod (1 leader + 3 workers)
patchLeaderTemplate: # Leader 差异化配置(patch 到基础模板)
spec:
containers:
- name: main
command:
- bash
- -c
- |
ray start --head --port=6379
python -m vllm.entrypoints.openai.api_server --model=Qwen/Qwen2.5-7B-Instruct --tensor-parallel-size=4
patchWorkerTemplate: # Worker 差异化配置(patch 到基础模板)
spec:
containers:
- name: main
command:
- bash
- -c
- ray start --address=$(LWS_LEADER_ADDRESS):6379 --block
为什么使用
patchLeaderTemplate/patchWorkerTemplate?与 LWS 需要分别定义完整的
leaderTemplate和workerTemplate不同,RBG 采用基础模板 + patch 的方式:
template:定义 Leader 和 Worker 共用的配置(镜像、资源、卷挂载等)。patchLeaderTemplate/patchWorkerTemplate:只定义差异部分(如启动命令)。这种设计减少了 YAML 重复,当 Leader 和 Worker 大部分配置相同时(通常只有启动命令不同),不需要写两份完整的模板。
4.2 原地更新
InstanceSet 支持 In-place Update(原地更新),当修改 Pod Template 的 metadata 或 image 时,只重启容器而不删除重建 Pod。
重建升级 vs 原地升级
传统的重建升级需要删除旧 Pod、创建新 Pod,会带来以下变化:
- Pod 名字和 UID 发生变化(如 Deployment 升级),或 Pod 名字不变但 UID 变化(如 StatefulSet 升级)。
- Pod 所在 Node 可能变化,因为新 Pod 大概率不会调度到原来的节点。
- Pod IP 发生变化,因为新 Pod 大概率不会被分配到原来的 IP 地址。
而原地升级复用同一个 Pod 对象,只修改其中的字段,因此:
- 避免额外操作:无需重新调度、分配 IP、挂载磁盘等。
- 更快的镜像拉取:可复用已有镜像的大部分 layer,只需拉取变化的 layer。
- 其他容器不受影响:当一个容器原地升级时,Pod 中的其他容器仍然正常运行。
- 复用本地缓存:可保留本地已加载的模型参数、KVCache 等数据。
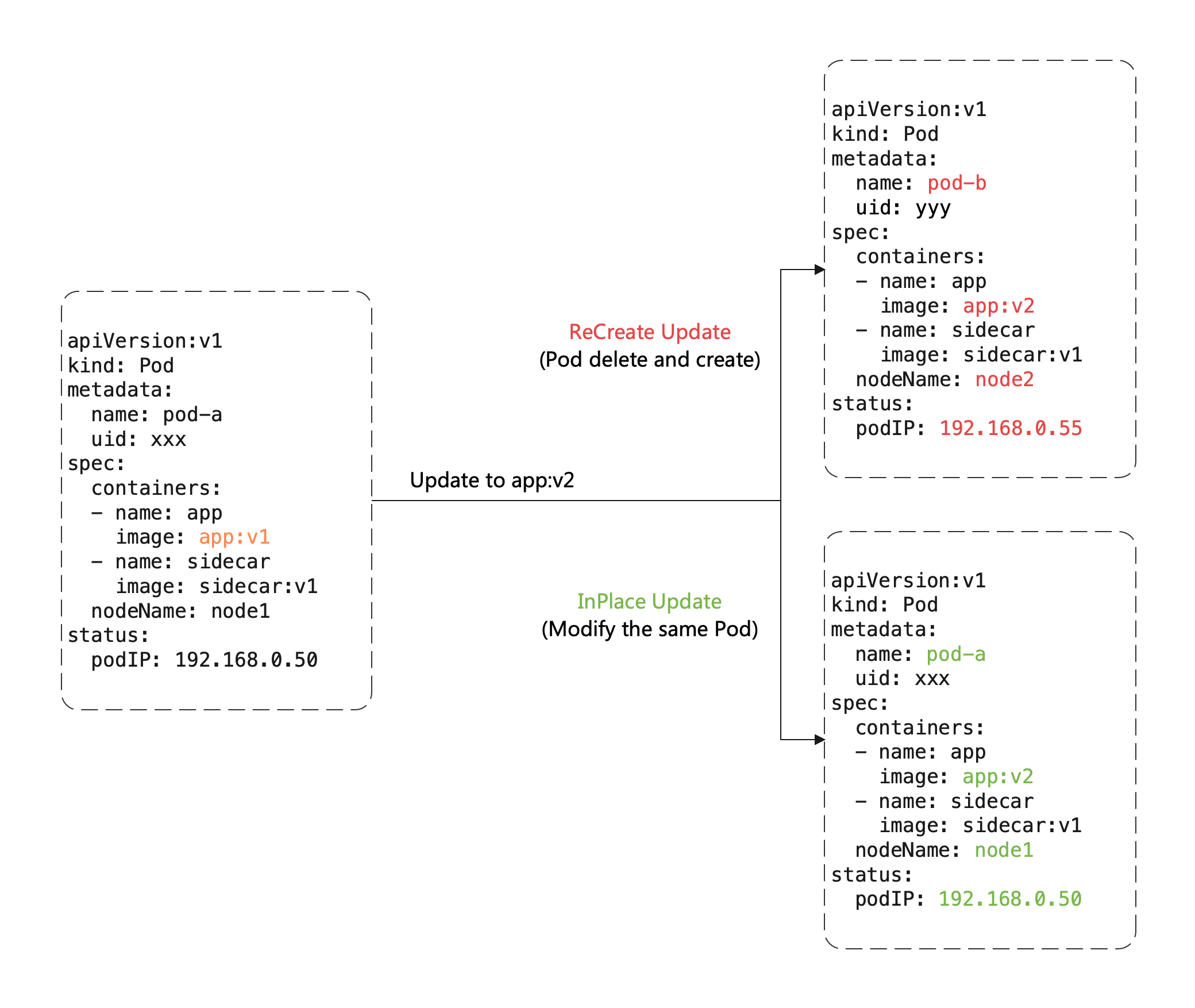
在 RoleBasedGroup 中启用原地更新,需要指定 workload.kind: InstanceSet 和 rollingUpdate.type: InPlaceIfPossible:
apiVersion: workloads.x-k8s.io/v1alpha1
kind: RoleBasedGroup
metadata:
name: demo
spec:
roles:
- name: engine
replicas: 3
workload:
apiVersion: workloads.x-k8s.io/v1alpha1
kind: InstanceSet # 使用 InstanceSet 作为底层工作负载
rolloutStrategy:
type: RollingUpdate
rollingUpdate:
type: InPlaceIfPossible # 启用原地更新
template:
spec:
containers:
- name: main
image: vllm/vllm-openai:v0.8.0 # 更新镜像会触发原地更新
args:
- --model=Qwen/Qwen2.5-7B-Instruct
4.3 Engine Runtime
ClusterEngineRuntimeProfile 是一个集群级别的 CRD,定义可复用的 sidecar 容器配置。RBG 会将这些容器注入到 Pod 中,用于处理分布式推理场景下的运行时协调工作。
1. 定义 ClusterEngineRuntimeProfile(集群级别,可被多个 RoleBasedGroup 复用)。支持配置 initContainers(初始化容器)、containers(sidecar 容器)、volumes(卷)和 updateStrategy(更新策略):
apiVersion: workloads.x-k8s.io/v1alpha1
kind: ClusterEngineRuntimeProfile
metadata:
name: sglang-pd-runtime
spec:
containers: # Sidecar 容器,与主容器并行运行
- name: patio-runtime
image: rolebasedgroup/rbgs-patio-runtime:v0.5.0
env:
- name: TOPO_TYPE
value: "sglang"
updateStrategy: NoUpdate # NoUpdate: Profile 更新不触发 Pod 重建
2. 在 RoleBasedGroup 中引用。通过 engineRuntimes.profileName 引用上面定义的 Profile,RBG 会自动将 sidecar 容器注入到该 Role 的所有 Pod 中:
roles:
- name: prefill
replicas: 1
engineRuntimes:
- profileName: sglang-pd-runtime # 引用 ClusterEngineRuntimeProfile
template:
spec:
containers:
- name: sglang-prefill
image: lmsysorg/sglang:v0.5.3.post3
RBG 提供的 Patio Runtime 是一个 Python sidecar,主要功能:
| 功能 | 说明 |
|---|---|
| Topology Management | 管理分布式推理的拓扑发现(如 P/D 分离场景中 Decode 发现 Prefill) |
| LoRA Adapter Management | 动态加载/卸载 LoRA 适配器 |
| Prometheus Metrics | 从推理引擎(vLLM/SGLang)收集指标并暴露给 Prometheus |
| Health Check | 提供健康检查和就绪探测端点 |
Engine Runtime 让推理引擎专注于推理本身,运行时协调工作由 sidecar 自动处理。
5. OME (Open Model Engine)
OME(Open Model Engine) 是一个用于企业级管理和部署 LLM 的 Kubernetes Operator。它通过自动化模型管理、智能运行时选择、高效资源利用和复杂的部署模式来优化 LLM 的部署和运行。
5.1 核心理念
在大型组织部署 LLM 时,通常存在两个需求冲突的团队:
ML 工程师花费数月时间进行模型基准测试、实验各种推理技术、制定最优部署策略。每个模型都需要不同的配置——Llama 70B 需要 Tensor 并行,DeepSeek V3/R1 需要 Expert 并行,多模态模型需要特殊设置。参数配置层出不穷:batch size、KV Cache 配置、量化级别。更麻烦的是,这些配置在不同 GPU 类型(H100 vs A100 vs L40S)之间差异巨大。
平台工程师和数据科学家只想快速部署模型。他们不应该需要理解 Tensor 并行的复杂性,或者为什么某个模型需要 4 张带 NVLink 的 GPU。他们有客户在等待、应用要构建、业务价值要交付。
这种差距产生了一个根本性问题:ML 工程师需要一种方式将来之不易的推理知识编码为可复用的"蓝图";平台团队需要在不成为分布式系统专家的情况下部署模型。
突破来自一个简单的洞察:模型本身应该驱动部署。一个 Llama 模型不只是一个文件——它包含关于架构、参数量和运行需求的元数据。通过让系统"理解模型"而非"驱动部署",可以弥合 ML 专业知识与生产简单性之间的鸿沟。
模型驱动架构使得编码和复用复杂部署策略变得简单:
- 多节点推理:通过简单配置部署 DeepSeek V3(685B)等超大模型跨多节点运行。
- Prefill-Decode 分离:将计算密集的 Prefill 与内存密集的 Decode 分开,各自独立扩缩。
- 灵活架构:Prefill 和 Decode 都可根据需求选择单节点或多节点配置。
- Serverless 部署:模型空闲时缩容至零,降低成本。
- 业务驱动扩缩:基于 KV Cache、tokens/秒、延迟目标或任意自定义指标的复杂自动扩缩。
模型驱动方法不是限制,而是解放——因为 OME 深度理解模型,它可以支持 ML 工程师设计的任何部署模式,同时为生产团队保持简洁的接口。
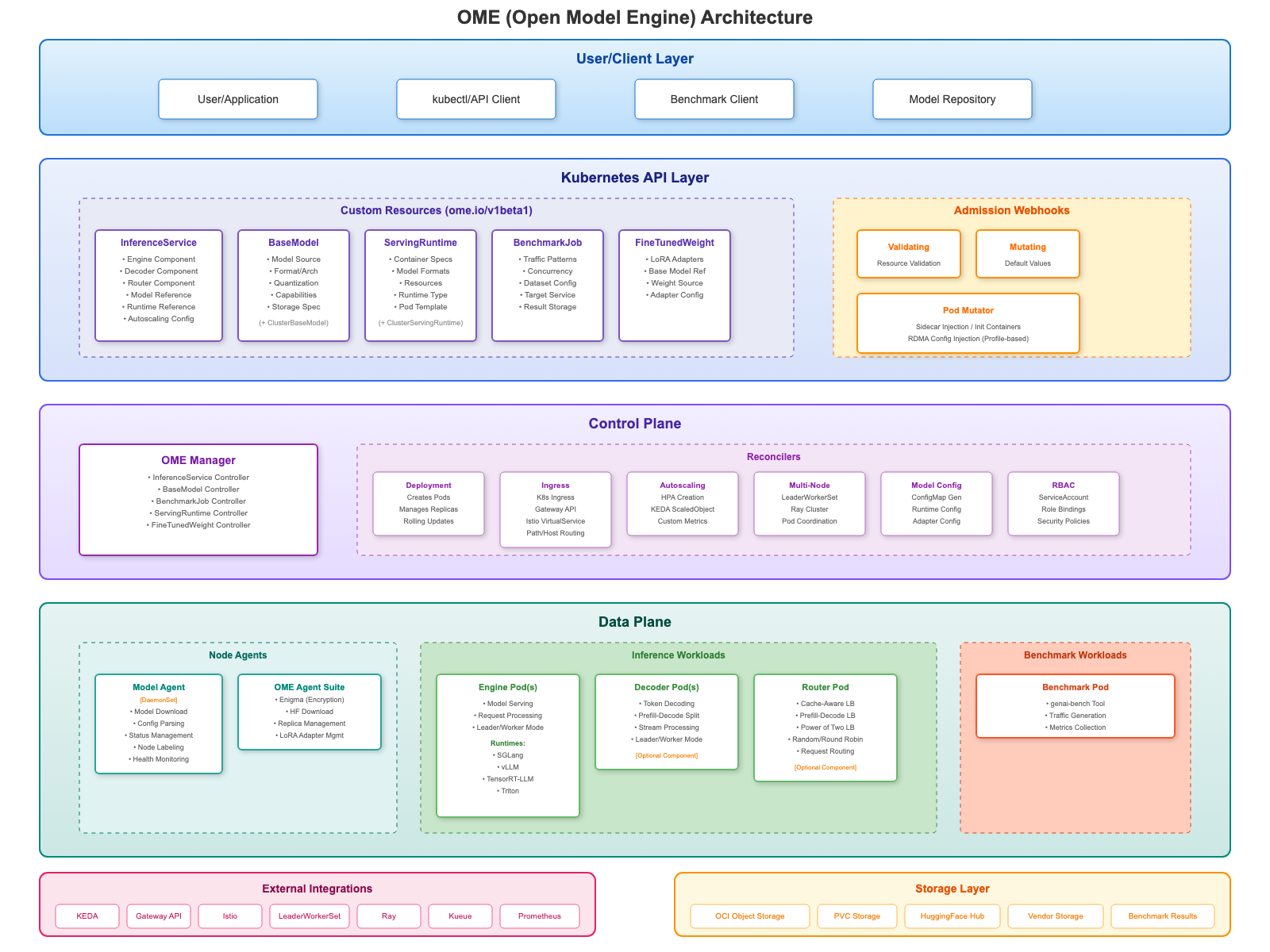
5.2 BaseModel / ClusterBaseModel - 模型定义
BaseModel 是 OME 中代表基础 LLM(如 Llama、Qwen、Mistral)的 Kubernetes 资源。它告诉 OME 在哪里找到模型、如何下载、以及存储在哪里。当创建 BaseModel 资源时,OME 自动处理模型文件的下载、解析模型配置以理解其能力,并使其在集群节点上可用。
OME 提供两种模型资源:BaseModel(Namespace 级别,团队专用)和 ClusterBaseModel(Cluster 级别,组织共享),两者 spec 格式完全相同,仅可见性范围不同。
最简配置:
apiVersion: ome.io/v1beta1
kind: ClusterBaseModel
metadata:
name: qwen2-7b-instruct
spec:
storage:
storageUri: hf://Qwen/Qwen2-7B-Instruct # 模型来源 URI
path: /raid/models/Qwen/Qwen2-7B-Instruct # 节点本地存储路径
| 字段 | 说明 |
|---|---|
storage.storageUri |
模型来源地址,支持 hf://(HuggingFace)、oci://(OCI Object Storage)、pvc://(PVC) |
storage.path |
模型下载到节点的本地路径,会作为 $(MODEL_PATH) 注入到 Engine 容器 |
更复杂的配置示例:
apiVersion: ome.io/v1beta1
kind: ClusterBaseModel
metadata:
name: qwen2-7b-instruct
labels:
vendor: "Qwen"
model-family: "qwen2"
spec:
# 基本信息
vendor: Qwen
version: "1.0.0"
disabled: false
displayName: "Qwen2 7B Instruct"
# 模型标识(用于 Runtime 自动匹配)
modelType: qwen2
modelArchitecture: Qwen2ForCausalLM
modelParameterSize: 7B
maxTokens: 32768
modelCapabilities:
- TEXT_TO_TEXT
# 模型格式(用于 Runtime 自动匹配)
modelFormat:
name: safetensors
version: "1.0.0"
modelFramework:
name: transformers
version: "4.41.2"
# 存储配置
storage:
storageUri: hf://Qwen/Qwen2-7B-Instruct
path: /raid/models/Qwen/Qwen2-7B-Instruct
key: "hf-token" # Secret 引用(用于私有/gated 模型)
Runtime 自动选择:当 InferenceService 不显式指定 runtime 时,OME Controller 根据 modelArchitecture + modelParameterSize + modelFormat + modelFramework 匹配最合适的 ServingRuntime。
自动模型发现:如果不填这些可选字段,Model Agent 下载模型时会自动解析 config.json,提取模型架构、参数量、上下文长度等信息,支持 Llama、DeepSeek、Mistral、Qwen、Phi 等主流模型家族。
可选字段说明:
| 字段 | 类型 | 说明 |
|---|---|---|
| 基本信息 | ||
vendor |
string | 模型厂商(如 meta, mistral, Qwen) |
version |
string | 模型版本(如 “3.1”, “1.0”) |
disabled |
boolean | 是否禁用该模型,默认 false |
displayName |
string | 用户友好的显示名称 |
| 模型标识 | ||
modelType |
string | 架构家族(如 llama, mistral, deepseek_v3) |
modelArchitecture |
string | 具体实现(如 LlamaForCausalLM, Qwen2ForCausalLM) |
modelParameterSize |
string | 可读的参数量(如 7B, 70B, 405B) |
maxTokens |
int32 | 模型可处理的最大 token 数 |
modelCapabilities |
[]string | 模型能力(如 TEXT_TO_TEXT, IMAGE_TEXT_TO_TEXT) |
| 模型格式与框架 | ||
modelFormat.name |
string | 格式名称(如 safetensors, onnx, pytorch) |
modelFormat.version |
string | 格式版本 |
modelFramework.name |
string | 框架名称(如 transformers, tensorrt) |
modelFramework.version |
string | 框架版本(如 4.36.0) |
quantization |
string | 量化方案(如 fp8, fbgemm_fp8, int4) |
| 存储配置 | ||
storage.storageUri |
string | 模型来源 URI |
storage.path |
string | 模型在节点上的本地存储路径 |
storage.key |
string | 包含存储凭证的 Kubernetes Secret 名称 |
storage.parameters |
map | 存储相关参数(如 region, auth_type) |
storage.nodeSelector |
map | 节点标签选择器,控制模型下载到哪些节点 |
storage.nodeAffinity |
NodeAffinity | 高级节点选择规则 |
支持的存储后端:
| 协议 | 格式 | 示例 |
|---|---|---|
| HuggingFace | hf://{model-id}[@{branch}] |
hf://meta-llama/Llama-3.1-8B-Instruct |
| OCI Object Storage | oci://n/{namespace}/b/{bucket}/o/{path} |
oci://n/ai-models/b/llm/o/llama-70b/ |
| PVC | pvc://[{namespace}:]{pvc-name}/{path} |
pvc://model-storage/llama-models/ |
5.3 ServingRuntime / ClusterServingRuntime - 运行时模板
ServingRuntime 封装了 ML 工程师的调优经验,定义如何运行特定类型的模型。与模型资源类似,ServingRuntime(Namespace 级别)和 ClusterServingRuntime(Cluster 级别)spec 格式相同,仅可见性范围不同。
最简配置:
apiVersion: ome.io/v1beta1
kind: ClusterServingRuntime
metadata:
name: srt-qwen2-7b-instruct
spec:
engineConfig:
runner:
image: docker.io/lmsysorg/sglang:v0.5.5.post3-cu129-amd64
command:
- python3
- -m
- sglang.launch_server
- --model-path
- $(MODEL_PATH) # OME 自动注入模型路径
- --host
- "0.0.0.0"
- --port
- "8080"
| 字段 | 说明 |
|---|---|
engineConfig.runner.image |
推理引擎容器镜像 |
engineConfig.runner.command |
启动命令,$(MODEL_PATH) 由 Controller 自动注入 |
runner内嵌标准 Kubernetes Container spec,可按需添加resources、env、volumeMounts等字段。如需 Runtime 自动匹配,可添加supportedModelFormats字段(见下方示例)。
包含可选字段的配置示例:
apiVersion: ome.io/v1beta1
kind: ClusterServingRuntime
metadata:
name: srt-qwen2-7b-instruct
spec:
# 支持的模型格式(用于自动匹配)
supportedModelFormats:
- modelFramework:
name: transformers
version: "4.41.2"
modelFormat:
name: safetensors
modelArchitecture: Qwen2ForCausalLM # 匹配特定架构
autoSelect: true # 允许自动选择
priority: 1 # 优先级
# 模型大小范围(用于自动匹配)
modelSizeRange:
min: 5B
max: 9B
# 协议版本
protocolVersions:
- openAI
# Engine 配置
engineConfig:
runner:
image: docker.io/lmsysorg/sglang:v0.5.5.post3-cu129-amd64
command:
- python3
- -m
- sglang.launch_server
- --model-path
- $(MODEL_PATH)
- --host
- "0.0.0.0"
- --port
- "8080"
resources:
limits:
nvidia.com/gpu: 1
# Router 配置(可选,用于多副本智能路由)
routerConfig:
runner:
image: fra.ocir.io/idqj093njucb/smg:v0.2.4.post1-dev
command:
- python3
- -m
- sglang_router.launch_router
- --service-discovery
- --service-discovery-namespace
- $(NAMESPACE) # OME 自动注入
- --selector
- component=engine ome.io/inferenceservice=$(INFERENCESERVICE_NAME) # OME 自动注入
PD Disaggregated 配置示例(Prefill-Decode 分离):当 ServingRuntime 同时配置 engineConfig 和 decoderConfig 时,OME 自动识别为 PD Disaggregated 部署模式。
apiVersion: ome.io/v1beta1
kind: ClusterServingRuntime
metadata:
name: srt-llama-pd
spec:
# Prefill 组件(Engine)
engineConfig:
runner:
image: docker.io/lmsysorg/sglang:v0.5.5.post3-cu129-amd64
command:
- python3
- -m
- sglang.launch_server
- --model-path
- $(MODEL_PATH)
- --host
- "0.0.0.0"
- --port
- "8080"
- --disaggregation-mode
- prefill # Prefill 模式
# Decode 组件
decoderConfig:
runner:
image: docker.io/lmsysorg/sglang:v0.5.5.post3-cu129-amd64
command:
- python3
- -m
- sglang.launch_server
- --model-path
- $(MODEL_PATH)
- --host
- "0.0.0.0"
- --port
- "8080"
- --disaggregation-mode
- decode # Decode 模式
# Router(PD 分离模式)
routerConfig:
runner:
image: fra.ocir.io/idqj093njucb/smg:v0.2.4.post1-dev
command:
- python3
- -m
- sglang_router.launch_router
- --pd-disaggregation # 启用 PD 分离路由
- --service-discovery
- --service-discovery-namespace
- $(NAMESPACE)
- --prefill-selector
- component=engine ome.io/inferenceservice=$(INFERENCESERVICE_NAME)
- --decode-selector
- component=decoder ome.io/inferenceservice=$(INFERENCESERVICE_NAME)
Multi-Node 多节点部署:OME 支持两种多节点部署方式,适用于不同的推理引擎:
| 推理引擎 | 多节点协调方式 | OME 部署模式 | 配置方式 |
|---|---|---|---|
| SGLang | NCCL 原生通信 | MultiNode (LeaderWorkerSet) |
engineConfig.leader + engineConfig.worker |
| vLLM | Ray 分布式框架,底层 GPU 通信仍使用 NCCL,但用户无需配置 NCCL 参数,Ray 自动处理。 | MultiNodeRayVLLM (KubeRay) |
annotation + engineConfig.runner |
Multi-Node (SGLang + LWS) 配置示例:当 engineConfig 配置了 leader 和 worker 字段时,OME 自动识别为 Multi-Node 模式,并创建 LeaderWorkerSet 资源来协调多节点启动。
apiVersion: ome.io/v1beta1
kind: ClusterServingRuntime
metadata:
name: srt-deepseek-v3-multinode
spec:
engineConfig:
# Leader(Head)节点配置
leader:
hostNetwork: true
runner:
image: docker.io/lmsysorg/sglang:v0.5.5.post3-cu129-amd64
command:
- python3
- -m
- sglang.launch_server
- --model-path
- $(MODEL_PATH)
- --host
- "0.0.0.0"
- --port
- "8080"
- --tp-size
- "8" # 单节点 8 GPU
- --nnodes
- $(LWS_GROUP_SIZE) # OME 自动注入总节点数
- --node-rank
- $(LWS_WORKER_INDEX) # OME 自动注入节点序号
- --nccl-init
- $(LWS_LEADER_ADDRESS):5000 # OME 自动注入 Leader 地址
resources:
limits:
nvidia.com/gpu: 8
# Worker 节点配置
worker:
size: 1 # Worker 节点数量(总节点数 = 1 leader + 1 worker = 2)
hostNetwork: true
runner:
image: docker.io/lmsysorg/sglang:v0.5.5.post3-cu129-amd64
command:
- python3
- -m
- sglang.launch_server
- --model-path
- $(MODEL_PATH)
- --host
- "0.0.0.0"
- --port
- "8080"
- --tp-size
- "8"
- --nnodes
- $(LWS_GROUP_SIZE)
- --node-rank
- $(LWS_WORKER_INDEX)
- --nccl-init
- $(LWS_LEADER_ADDRESS):5000
resources:
limits:
nvidia.com/gpu: 8
Multi-Node (vLLM + Ray) 配置示例:通过 annotation 指定 MultiNodeRayVLLM 模式,OME 自动创建 RayCluster 资源。需要预先安装 KubeRay Operator。
apiVersion: ome.io/v1beta1
kind: ClusterServingRuntime
metadata:
name: srt-vllm-multinode
spec:
engineConfig:
annotations:
ome.io/deployment-mode: "MultiNodeRayVLLM" # 指定使用 Ray 多节点模式
runner:
image: vllm/vllm-openai:latest
command:
- python3
- -m
- vllm.entrypoints.openai.api_server
- --model
- $(MODEL_PATH)
- --host
- "0.0.0.0"
- --port
- "8080"
- --tensor-parallel-size
- "8"
# 无需配置 NCCL 参数,Ray 自动处理分布式协调
resources:
limits:
nvidia.com/gpu: 8
注意:vLLM 多节点模式下,OME 会自动创建 RayCluster(包含 Head 和 Worker 节点),用户只需提供标准的容器配置,Ray 负责节点发现和通信协调。
5.4 InferenceService - 部署编排
InferenceService 是 OME 中编排模型服务完整生命周期的核心 Kubernetes 资源。它是一个声明式规范,描述了如何在集群中部署、扩缩容和服务 LLM。
可以将 InferenceService 理解为 AI 工作负载的"部署蓝图"。它将模型(BaseModel/ClusterBaseModel)、运行时(ServingRuntime/ClusterServingRuntime)和基础设施配置整合在一起,形成完整的服务方案。
OME 采用组件化架构,InferenceService 可由多个专用组件组成:
- Model:引用要服务的 LLM(
BaseModel/ClusterBaseModel)。 - Runtime:引用运行时环境(
ServingRuntime/ClusterServingRuntime)。 - Engine:主推理组件,处理推理请求。
- Decoder:可选组件,用于 PD 分离部署(Prefill-Decode 分离)。
- Router:可选组件,用于请求路由和负载均衡。
配置示例:
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: qwen2-7b-instruct
namespace: qwen2-7b-instruct
spec:
# 引用模型
model:
name: qwen2-7b-instruct # → ClusterBaseModel
# 引用运行时(可选,不指定则自动选择)
runtime:
name: srt-qwen2-7b-instruct # → ClusterServingRuntime
# Engine 配置
engine:
minReplicas: 1
maxReplicas: 1
# Router 配置
router:
minReplicas: 1
maxReplicas: 1
OME 支持多种部署模式,大部分模式由 ServingRuntime 的配置字段决定:
| 模式 | 场景 | 配置方式 |
|---|---|---|
| Standard | 单节点小模型 (7B-13B) | ServingRuntime: 只有 engineConfig |
| Standard + Router | 需要负载均衡 | ServingRuntime: engineConfig + routerConfig |
| PD Disaggregated | 高吞吐场景 | ServingRuntime: engineConfig + decoderConfig |
| Multi-Node (SGLang) | 使用 SGLang 部署超大模型 | ServingRuntime: engineConfig.leader + engineConfig.worker |
| Multi-Node (vLLM) | 使用 vLLM 部署超大模型 | ServingRuntime: annotation + engineConfig.runner |
| Serverless | 成本优化 (Scale-to-Zero) | InferenceService: engine.minReplicas: 0 |
ML 工程师在 ServingRuntime 中预先配置好部署模式,平台团队的 InferenceService 只需引用该 Runtime,即可获得对应的部署架构。Multi-Node 模式支持两种方案:SGLang 使用 NCCL 原生通信(配置 leader/worker),vLLM 使用 Ray 分布式框架(配置 annotation ome.io/deployment-mode: MultiNodeRayVLLM)。Serverless 模式通过在 InferenceService 中设置 minReplicas: 0 启用,利用 Knative Serving 实现自动扩缩容(包括缩容到零)。
Standard 示例(最简配置):
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: qwen2-7b-instruct
namespace: qwen2-7b-instruct
spec:
model:
name: qwen2-7b-instruct # 引用 ClusterBaseModel,获取模型存储路径
runtime:
name: srt-qwen2-7b-instruct # 引用 ClusterServingRuntime,获取容器镜像、启动命令、资源配置
engine:
minReplicas: 1 # Engine 副本数配置
maxReplicas: 1
model.name:引用ClusterBaseModel,Controller 从中获取模型存储路径(storage.path),注入为$(MODEL_PATH)环境变量runtime.name:引用ClusterServingRuntime,Controller 从中获取容器镜像、启动命令、资源配置等engine:指定推理引擎的副本数范围
Standard + Router 示例:当有多个 Engine 副本时,可以通过 Router 提供 KV Cache-Aware Routing 等智能路由能力。
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: qwen2-7b-instruct
namespace: qwen2-7b-instruct
spec:
model:
name: qwen2-7b-instruct
runtime:
name: srt-qwen2-7b-instruct
engine:
minReplicas: 2 # 多个 Engine 副本
maxReplicas: 4
router:
minReplicas: 1
maxReplicas: 1
PD 分离示例(来自 config/samples/isvc/deepseek-ai/deepseek-v3-pd.yaml):
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: deepseek-v3
namespace: deepseek-v3
spec:
model:
name: deepseek-v3
runtime:
name: srt-deepseek-rdma-pd # 引用 PD 分离模式的 ServingRuntime
engine: # Prefill 节点
minReplicas: 1
maxReplicas: 1
decoder: # Decode 节点
minReplicas: 1
maxReplicas: 1
router: # 协调 P/D 请求分发
minReplicas: 1
maxReplicas: 1
Multi-Node (SGLang) 示例:部署超大模型(如 DeepSeek V3 685B),使用 SGLang + LeaderWorkerSet 进行多节点分布式推理。
Multi-Node 模式下,engine.minReplicas 指定的是 LeaderWorkerSet 的 replica 数量,每个 replica 包含 1 个 Leader 节点和 N 个 Worker 节点(由 ServingRuntime 中 worker.size 决定)。
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: deepseek-v3
namespace: deepseek-v3
spec:
model:
name: deepseek-v3
runtime:
name: srt-deepseek-v3-multinode # 引用 Multi-Node 模式的 ServingRuntime(SGLang + LWS)
engine:
minReplicas: 1 # 每个 replica 包含 1 leader + N workers
maxReplicas: 1
Multi-Node (vLLM + Ray) 示例:使用 vLLM + KubeRay 进行多节点分布式推理。OME 自动创建 RayCluster 资源。
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: llama-405b
namespace: llama-405b
spec:
model:
name: llama-3-1-405b-instruct
runtime:
name: srt-vllm-multinode # 引用 Multi-Node 模式的 ServingRuntime(vLLM + Ray)
engine:
minReplicas: 1 # RayCluster 副本数
maxReplicas: 1
Serverless 示例:利用 Knative Serving 实现自动扩缩容,包括缩容到零以优化成本。
apiVersion: ome.io/v1beta1
kind: InferenceService
metadata:
name: llama-chat
spec:
model:
name: llama-3-70b-instruct
engine:
minReplicas: 0 # 启用 Scale-to-Zero
maxReplicas: 10
scaleTarget: 10 # 每个 Pod 的并发请求数
6. AiBrix
AIBrix 是字节跳动开源的项目,旨在提供构建可扩展 GenAI 推理基础设施的核心组件。AIBrix 提供了一套云原生解决方案,专为部署、管理和扩展 LLM 推理而优化,面向企业级需求。
6.1 Batch API
AIBrix Batch API 提供了一种高效的方式来异步处理大量 LLM 推理请求。它完全兼容 OpenAI Batch API,允许用户提交批量请求在后台处理,稍后获取结果。
批处理适用于不需要即时响应的工作负载,具有以下优势:
- 成本效率:在非高峰时段处理请求,优化资源利用率。
- 更高吞吐量:处理大量请求而无需担心速率限制。
- 简化工作流:通过单次批量操作提交数千个请求。
- 保证处理:内置重试机制和失败处理。
Batch API 接受包含多个推理请求的 JSONL(JSON Lines)文件,使用 Kubernetes Jobs 异步处理,并在对应的 JSONL 输出文件中返回结果。
import json
import time
from openai import OpenAI
# Configure client for AIBrix
client = OpenAI(
base_url="http://your-aibrix-endpoint:80/v1",
api_key="dummy-key" # Replace with actual key if authentication is enabled
)
# Step 1: Create batch input file
batch_requests = [
{
"custom_id": f"request-{i}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-oss-120b",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Tell me a fact about the number {i}."}
],
"max_tokens": 100
}
}
for i in range(1, 11) # 10 requests
]
# Write to JSONL file
with open("batch_requests.jsonl", "w") as f:
for request in batch_requests:
f.write(json.dumps(request) + "\n")
# Step 2: Upload file
with open("batch_requests.jsonl", "rb") as f:
batch_file = client.files.create(
file=f,
purpose="batch"
)
print(f"Uploaded file: {batch_file.id}")
# Step 3: Create batch
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
print(f"Created batch: {batch.id}")
# Step 4: Wait for completion
while batch.status not in ["completed", "failed", "expired", "cancelled"]:
time.sleep(10)
batch = client.batches.retrieve(batch.id)
print(f"Status: {batch.status}")
if batch.status == "completed":
print(f"Batch completed!")
print(f"Total requests: {batch.request_counts.total}")
print(f"Completed: {batch.request_counts.completed}")
print(f"Failed: {batch.request_counts.failed}")
# Step 5: Download results
output_file_id = batch.output_file_id
result_content = client.files.content(output_file_id)
# Save results
with open("batch_results.jsonl", "wb") as f:
f.write(result_content.content)
# Process results
with open("batch_results.jsonl", "r") as f:
for line in f:
result = json.loads(line)
custom_id = result["custom_id"]
content = result["response"]["body"]["choices"][0]["message"]["content"]
print(f"{custom_id}: {content}")
else:
print(f"Batch failed with status: {batch.status}")
6.2 分布式 KV Cache
随着大语言模型需求的增长,高效的内存管理和缓存对于优化推理性能、降低成本变得至关重要。在多轮对话(如聊天机器人、Agent 系统)等场景中,重叠的 token 序列会导致 prefill 阶段的冗余计算,浪费资源并限制吞吐量。
许多推理引擎(如 vLLM)使用内置 KV Cache 来缓解此问题,利用空闲的 HBM 和 DRAM。然而,单节点 KV Cache 面临关键限制:内存容量受限、引擎级别的存储无法跨实例共享,以及难以支持 KV 迁移和 Prefill-Decode 分离等场景。
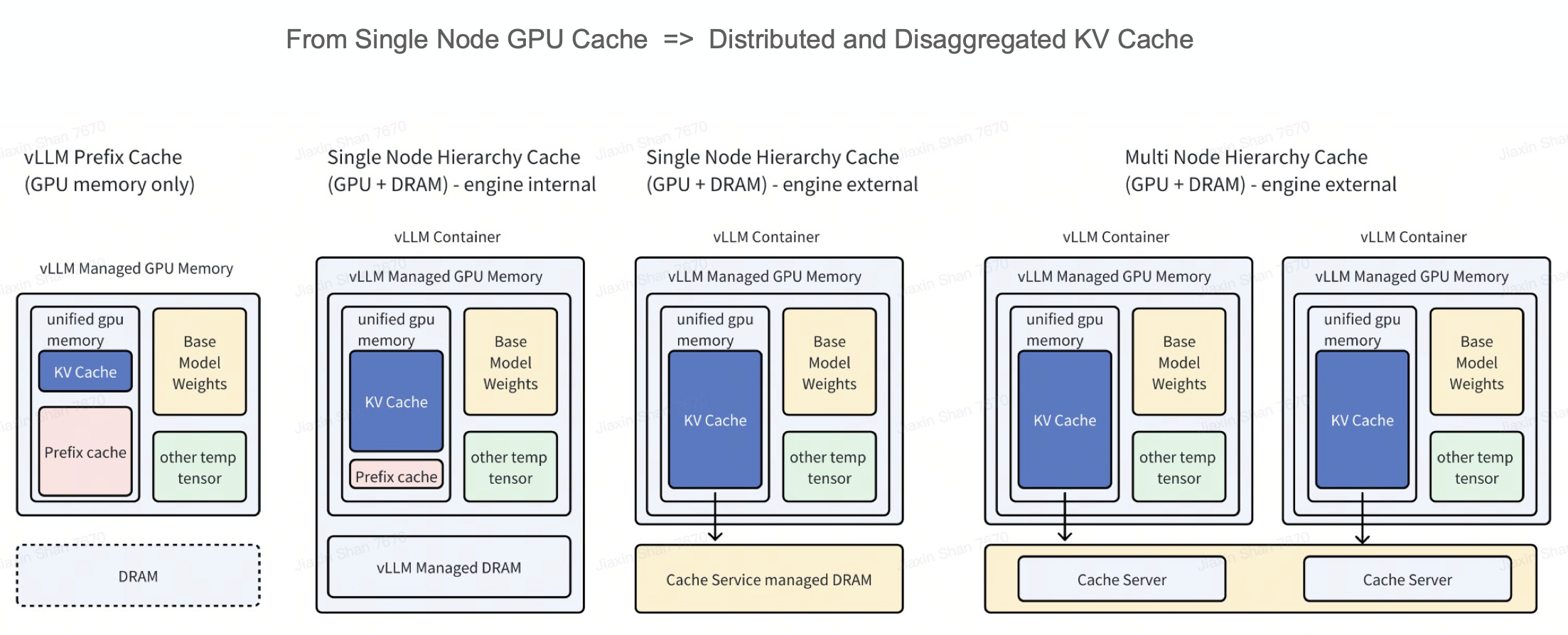
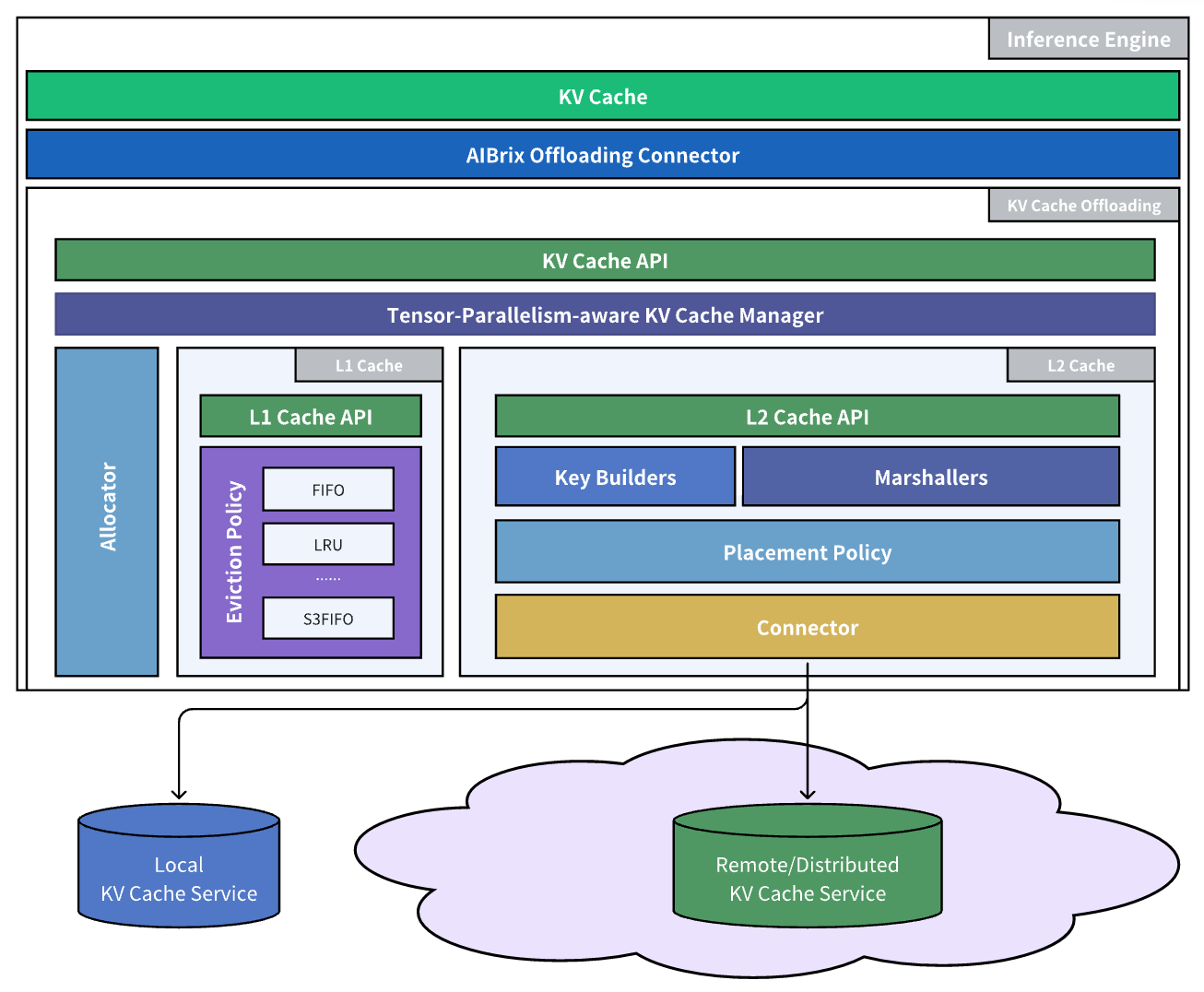
AIBrix 引入了生产级的 KV Cache Offloading 框架,实现高效的内存分层和低开销的跨引擎复用:
- 数据平面:通过 AIBrix Offloading Connector 与推理引擎(如 vLLM)紧密集成,使用优化的 CUDA 内核加速 GPU 与 CPU 之间的数据移动。
- 多层缓存管理器:在存储层之间动态平衡工作负载,缓解 GPU 内存容量限制同时最小化延迟损耗。默认启用 L1 DRAM 缓存,已能显著减轻 GPU 内存压力;对于需要多节点共享的场景,可选启用 L2 远程缓存(如 InfiniStore),解锁分布式 KV Cache 层的能力。
- 可插拔淘汰策略:支持 LRU、S3FIFO 等策略,以及多种后端存储选项,实现选择性 KV Cache Offloading 以减少网络和 PCIe 争用。
- 缓存放置模块:与集中式分布式 KV Cache 集群管理器协调,最大化全局 KV Cache 利用率,实现跨引擎 KV 复用和集群级资源效率,将孤立的 KV Cache 实例转变为可扩展的共享 KV Cache 基础设施。
7. KServe
KServe 是一个 Kubernetes 原生的模型推理平台,最初由 Google、IBM、Bloomberg 等公司发起,现为 CNCF 孵化项目。KServe 同时支持传统 ML 模型(sklearn、TensorFlow、PyTorch 等)和 LLM 推理,通过 InferenceService(v1beta1)提供通用的模型推理能力,并新增了 LLMInferenceService(v1alpha2)专门面向 LLM 场景,集成 llm-d 架构支持 PD 分离、多节点推理和智能调度。
7.1 传统 ML 框架支持
KServe 通过内置的 ClusterServingRuntime 开箱即用地支持多种 LLM 推理引擎和传统 ML 框架:
| Runtime | 支持的模型格式 |
|---|---|
kserve-huggingfaceserver |
HuggingFace Transformer Models(vLLM 后端) |
kserve-huggingfaceserver-multinode |
HuggingFace Transformer Models(vLLM + Ray 多节点) |
kserve-tritonserver |
TensorFlow, ONNX, PyTorch, TensorRT |
kserve-tensorflow-serving |
TensorFlow |
kserve-torchserve |
PyTorch |
kserve-predictiveserver |
SKLearn, XGBoost, LightGBM |
kserve-sklearnserver |
SKLearn |
kserve-xgbserver |
XGBoost |
kserve-lgbserver |
LightGBM |
kserve-mlserver |
SKLearn, XGBoost, LightGBM, MLflow |
kserve-openvino |
OpenVINO, ONNX, TensorFlow |
kserve-paddleserver |
Paddle |
kserve-pmmlserver |
PMML |
KServe 通过 supportedModelFormats 实现自动匹配:用户在 InferenceService 中指定 modelFormat(如 sklearn、pytorch),KServe 自动选择对应的 ClusterServingRuntime 来部署,无需手动指定 runtime。
7.2 InferenceGraph
随着 ML 推理系统日益庞大和复杂,往往需要多个模型协作完成一次预测。例如:人脸识别流水线需要先检测图片中的人脸,再提取人脸特征与数据库匹配;NLP 流水线需要先做文档分类,再根据分类结果进行下游的命名实体识别。
**InferenceGraph 和 Agent 框架对比**:InferenceGraph 是为传统 ML 推理管道设计的(预处理 → 模型推理 → 后处理、模型融合等),它是预定义的静态 DAG。而 LangGraph 等框架是为 LLM Agent 设计的,支持动态决策、循环、工具调用、有状态对话等能力。在 LLM 时代,InferenceGraph 的场景可能比较有限——大多数 LLM 应用直接调用单个推理端点,复杂的编排逻辑放在应用层(LangGraph、CrewAI 等)。InferenceGraph 更适合传统 ML 场景下的多模型串联/并联。KServe 在构建分布式推理图方面有独特优势:自动扩缩容的图路由器、与 InferenceService 的原生集成、以及用于模型串联的标准推理协议。基于这些能力,KServe 提供了 InferenceGraph,让用户以声明式、可扩缩的方式将复杂 ML 推理流水线部署到生产环境。
为什么使用 InferenceGraph?
- 多阶段流水线:串联多个模型,前一个模型的输出作为下一个模型的输入
- 条件路由:根据预测结果或输入特征决定请求走向
- 模型融合:组合多个模型的预测结果
- A/B 测试:按权重在不同模型版本之间分流
- 独立扩缩容:图中每个模型可以独立扩缩
- 可复用性:单个 InferenceService 可以被多个 Graph 共享
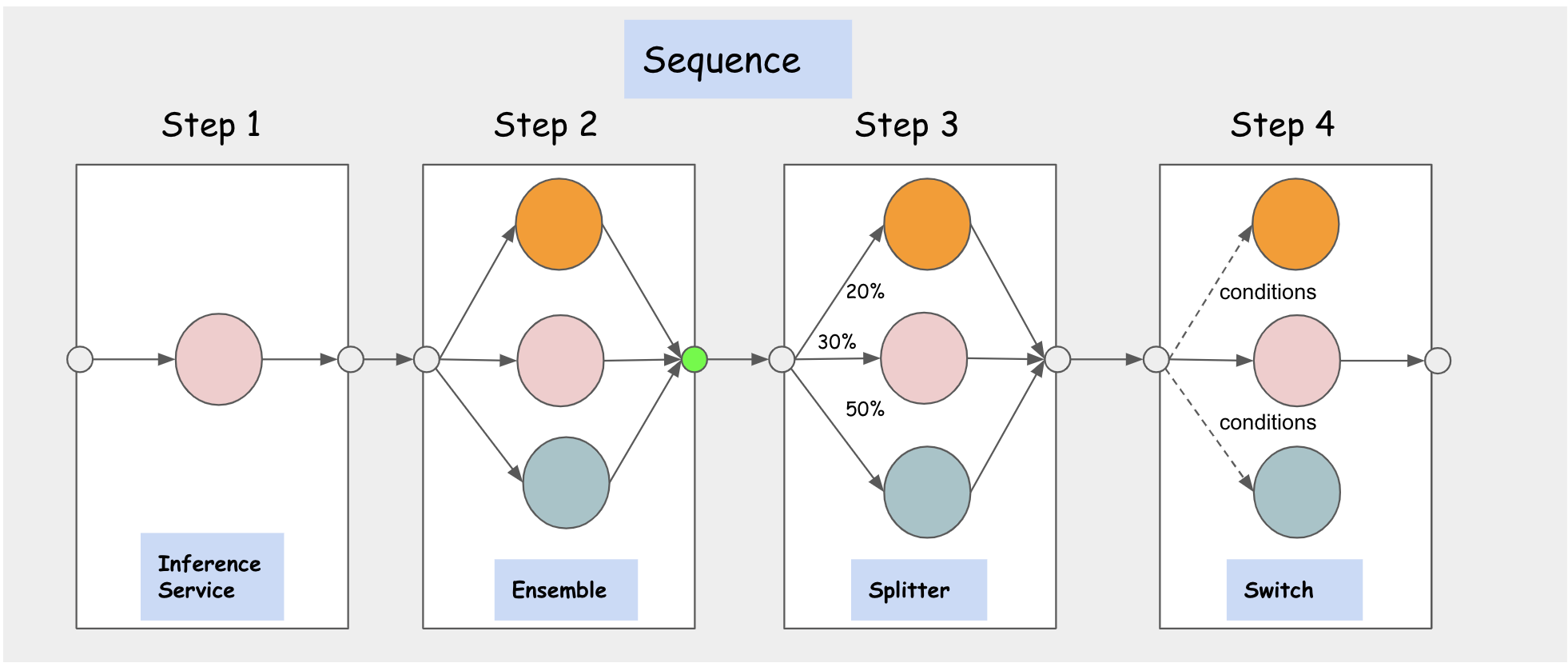
核心概念
- InferenceGraph:由一组路由 Node 组成,每个 Node 包含一组路由 Step。每个 Step 可以路由到一个 InferenceService 或图上定义的另一个 Node,这使得 InferenceGraph 具备高度可组合性。图路由器部署在一个 HTTP 端点之后,可根据请求量动态扩缩容。
- Sequence Node:按顺序依次执行多个 Step,前一步的 request/response 可以作为下一步的输入传递。
- Switch Node:根据条件表达式选择匹配的 Step 执行,返回第一个匹配的结果;如果没有条件匹配,则返回原始请求。
- Ensemble Node:对每个模型分别评分,然后将结果组合为一个预测响应(如多棵分类树的"多数投票",多棵回归树的"平均"等)。
- Splitter Node:按权重将流量分发到多个目标(权重之和为 100)。
示例:模型链式调用(Sequence)
一个典型的预处理 → 推理 → 后处理流水线:
apiVersion: serving.kserve.io/v1alpha1
kind: InferenceGraph
metadata:
name: model-chaining
spec:
nodes:
root:
routerType: Sequence
steps:
- serviceName: preprocessing
- serviceName: model-server
data: $response
- serviceName: postprocessing
data: $response
示例:条件路由(Switch)+ 子图嵌套
根据图像分类结果,将请求路由到不同的下游检测模型:
apiVersion: serving.kserve.io/v1alpha1
kind: InferenceGraph
metadata:
name: image-pipeline
spec:
nodes:
root:
routerType: Sequence
steps:
- serviceName: image-classifier
- nodeName: content-router
data: $response
content-router:
routerType: Switch
steps:
- serviceName: nsfw-detector
condition: "predictions.#(label==\"person\")"
- serviceName: fake-ad-detector
condition: "predictions.#(label==\"product\")"
- serviceName: general-detector
condition: "predictions.#(label==\"other\")"
示例:A/B 测试(Splitter)
将 80% 流量发送到新版模型,20% 到旧版模型:
apiVersion: serving.kserve.io/v1alpha1
kind: InferenceGraph
metadata:
name: ab-testing
spec:
nodes:
root:
routerType: Splitter
steps:
- serviceName: model-v1
weight: 20
- serviceName: model-v2
weight: 80
示例:模型融合(Ensemble)
并行调用多个模型,合并结果:
apiVersion: serving.kserve.io/v1alpha1
kind: InferenceGraph
metadata:
name: model-ensemble
spec:
nodes:
root:
routerType: Ensemble
steps:
- serviceName: sklearn-model
name: sklearn
- serviceName: xgboost-model
name: xgboost
7.3 Local Model Cache
通过将 LLM 模型缓存到本地存储,可以大幅缩短 InferenceService 的启动时间。对于多副本部署,本地持久卷可以为多个 Pod 提供已预热的模型缓存。
该功能引入了以下 CRD:
- LocalModelCache:指定将哪个模型(如 Hugging Face Hub 上的模型)下载并缓存到 Kubernetes 节点的本地存储。
- LocalModelNodeGroup:管理用于缓存模型和本地持久存储的节点组。
- LocalModelNode:跟踪给定节点上模型缓存的状态。
工作流程:
- 创建
LocalModelNodeGroup,定义节点选择条件和本地存储配置(如 NVMe)。KServe 会在匹配的节点上创建 Agent DaemonSet 来监控本地模型缓存生命周期。 - 创建
LocalModelCache,指定模型源地址(sourceModelUri)和目标节点组。KServe 自动在各节点上创建下载 Job,将模型预下载到本地存储。 - 部署
InferenceService时,只要storageUri与LocalModelCache的sourceModelUri匹配,KServe 就会自动使用本地缓存,跳过远程下载。
Step 1: 配置模型下载凭证
ClusterStorageContainer 用于定义模型下载所使用的存储初始化容器(storage initializer),包括容器镜像、认证凭证和支持的模型来源(如 hf:// 对应 Hugging Face Hub,s3:// 对应 AWS S3 等)。这里创建一个 ClusterStorageContainer 引用 Hugging Face Token Secret,supportedUriFormats 指定匹配 hf:// 开头的模型 URI,workloadType: localModelDownloadJob 表示该配置用于本地模型下载 Job。
apiVersion: "serving.kserve.io/v1alpha1"
kind: ClusterStorageContainer
metadata:
name: hf-hub
spec:
container:
name: storage-initializer
image: kserve/storage-initializer:latest
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: hf-secret
key: HF_TOKEN
resources:
requests:
memory: 2Gi
cpu: "1"
limits:
memory: 4Gi
cpu: "1"
supportedUriFormats:
- prefix: hf://
workloadType: localModelDownloadJob
Step 2: 创建 LocalModelNodeGroup
创建 LocalModelNodeGroup 定义用于缓存模型的节点组和本地持久存储。通过 nodeAffinity 选择哪些节点用于模型缓存,local.path 指定本地 NVMe 卷的挂载路径。LocalModelNodeGroup 创建后,KServe 会在每个匹配 nodeAffinity 的节点上创建 Agent DaemonSet,用于监控本地模型缓存的生命周期。
apiVersion: serving.kserve.io/v1alpha1
kind: LocalModelNodeGroup
metadata:
name: workers
spec:
storageLimit: 1.7T
persistentVolumeClaimSpec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1700G
storageClassName: local-storage
persistentVolumeSpec:
capacity:
storage: 1700G
local:
path: /models
storageClassName: local-storage
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu-product
operator: In
values:
- NVIDIA-A100-SXM4-80GB
Step 3: 创建 LocalModelCache
创建 LocalModelCache 指定要预下载到本地存储的模型。sourceModelUri 为模型的远程存储地址,nodeGroups 指定将模型缓存到哪些节点组。
apiVersion: serving.kserve.io/v1alpha1
kind: LocalModelCache
metadata:
name: meta-llama3-8b-instruct
spec:
sourceModelUri: 'hf://meta-llama/meta-llama-3-8b-instruct'
modelSize: 10Gi
nodeGroups:
- workers
LocalModelCache 创建后,KServe 自动在节点组中的每个节点上创建下载 Job,将模型预下载到本地存储。可以通过 LocalModelCache 的 status 查看各节点的下载状态:
status:
copies:
available: 1
total: 1
nodeStatus:
kind-worker: NodeDownloaded
Step 4: 部署 InferenceService
部署 InferenceService 时,只要 storageUri 与 LocalModelCache 的 sourceModelUri 匹配,KServe 就会自动使用本地缓存,跳过远程下载。
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: huggingface-llama3
spec:
predictor:
model:
modelFormat:
name: huggingface
storageUri: hf://meta-llama/meta-llama-3-8b-instruct
resources:
limits:
cpu: "6"
memory: 24Gi
nvidia.com/gpu: "1"
参考资料:
7.4 LLMInferenceService
LLMInferenceService 是 KServe 面向 GenAI 场景推出的新一代 CRD,基于 llm-d 架构构建。llm-d 结合了 vLLM 推理引擎、Kubernetes 编排和智能路由能力,提供 KV Cache 感知调度、Prefill-Decode 分离部署、分布式推理等生产级特性。LLMInferenceService 将这些能力封装为 Kubernetes 原生 CRD,降低了使用门槛。
为什么需要新的 CRD?
KServe 采用双轨策略:
- InferenceService:面向传统预测型 AI(sklearn、TensorFlow、PyTorch 等),也可以用于简单的 LLM 单节点部署。
- LLMInferenceService:专为生成式 AI 设计,提供 PD 分离、多节点编排、智能调度等 LLM 特有能力,不会给传统
InferenceServiceAPI 增加复杂度。
核心特性:
- 多种部署模式:单节点、多节点(LeaderWorkerSet)、Prefill-Decode 分离、DP+EP(数据并行 + 专家并行,用于 MoE 模型)。
- 分布式推理:支持 Tensor Parallelism(TP)、Data Parallelism(DP)、Expert Parallelism(EP)。
- 智能路由:集成 Gateway API + Inference Gateway Extension,支持 KV Cache 感知调度、负载均衡路由、PD 分离自动路由。
- 可组合配置:通过 LLMInferenceServiceConfig +
baseRefs实现配置模板继承和覆盖。 - LoRA 适配器:原生支持在模型规格中定义 LoRA 适配器。
- 模型存储集成:支持 HuggingFace Hub(
hf://)、S3(s3://)、PVC(pvc://)、OCI Modelcar(oci://)。
核心配置:
spec.model:定义模型来源(URI)、名称、LoRA 适配器等。spec.template+spec.worker:定义 Decode 工作负载,worker存在时触发多节点部署(LWS)。spec.prefill:定义 Prefill 工作负载(PD 分离模式),可独立配置副本数、并行度和多节点。spec.parallelism:定义并行策略(tensor / pipeline / data / dataLocal / expert)。spec.router:定义路由配置(Gateway、HTTPRoute、Scheduler/EPP)。
以下配置 Kserve 会创建:3 个推理副本(各 1 GPU)、引用已有的 Gateway 并自动创建 HTTPRoute、智能调度器(EPP)用于负载均衡,以及 Storage Initializer 自动下载模型。
apiVersion: serving.kserve.io/v1alpha2
kind: LLMInferenceService
metadata:
name: llama-3-8b
spec:
model:
uri: hf://meta-llama/Llama-3.1-8B-Instruct
name: meta-llama/Llama-3.1-8B-Instruct
replicas: 3
template:
containers:
- name: main
image: vllm/vllm-openai:latest
resources:
limits:
nvidia.com/gpu: "1"
cpu: "8"
memory: 32Gi
router:
gateway: {} # 引用已有的 Gateway
route: {} # Kserver 自动创建和管理 HTTPRoute
scheduler: {} # Kserver 自动创建 InferencePool + EPP Scheduler
8 总结
各推理平台在多引擎支持、PD 分离、多节点推理、Prefix Cache 智能路由等核心功能上已高度趋同,但各自仍有独到之处:
- NVIDIA Dynamo:以 Rust 构建高性能核心,提供 KVBM 多级 KV Cache 管理和 NIXL 高性能数据传输库,并通过 SLA Planner 自动完成性能分析与扩缩容决策。此外 Dynamo 还具备请求迁移、请求取消、优雅关闭、过载拒绝等完善的容错机制。
- llm-d:架构轻量可插拔,支持 Prefix Cache 感知路由、LoRA 亲和性路由等策略,并在 Gateway API Inference Extension (GIE) 基础上扩展了 PD 分离和 Precise Prefix Cache 感知路由等能力。
- Kthena:通过 Volcano 实现网络拓扑感知调度,并支持同构、异构、Role 级别的多维度弹性伸缩。
- RoleBasedGroup:支持原地更新(In-place Update),更新镜像时只重启容器而不重建 Pod,避免重新调度和 IP 变化,同时保留本地已加载的模型和 KV Cache。
- OME:通过 BaseModel、ServingRuntime、InferenceService 三层抽象分离关注点,ML 工程师将调优经验编码为可复用的蓝图,平台工程师无需理解底层细节即可部署模型。
- AiBrix:提供 OpenAI 兼容的 Batch API 实现离线批量推理,以及分布式 KV Cache Pool 支持跨实例的 KV Cache 共享与复用。
- KServe:除 LLM 外还广泛支持传统 ML 框架(SKLearn、XGBoost、TensorFlow 等),并通过 InferenceGraph 实现多模型编排。
欢迎关注


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)