深度学习篇---全模态
全模态(Omni-Modal)是人工智能的进阶形态,通过统一架构实现任意模态数据(文本、图像、音频等)的无缝交互与融合,超越多模态的“拼盘式”处理。其核心在于原生统一编码、动态跨模态注意力及混合专家技术,支持复杂场景如医疗诊断、智能座舱的“主动智能”。尽管面临数据稀缺、算力成本等挑战,全模态已在工业、医疗、内容创作等领域展现潜力,推动AI从“多模态处理”迈向“六感互通”的类人智能,开启人机协作新纪
全模态:让人工智能拥有“六感互通”的超级感知力
1. 什么是全模态?——从"多"到"全"的质变
-
全模态(Omni-Modal):指人工智能能够处理、理解和生成任意类型的模态数据,并在一个统一的架构内实现所有模态间的无缝交互与信息融合。
一个生动的类比:
-
多模态就像一个团队:有人专攻看(视觉专家),有人专攻听(听觉专家),他们开会时互相交流信息。
-
全模态就像一个天才:他本身就同时拥有完美的视觉和听觉,而且这些感官在大脑中天然融合——看到烟花时自动联想到"砰"的声音,听到雨声时脑海中自然浮现雨滴的画面。这就是"六感互通"的境界。
2. 全模态 vs. 多模态:核心区别在哪里?
为了更清晰地理解,我们用一个表格来对比:
| 维度 | 多模态 (Multimodal) | 全模态 (Omni-Modal) |
|---|---|---|
| 架构思想 | "拼盘式"融合——多个单模态模型拼接,各自处理后再对齐 | "原生式"统一——单个模型从底层设计就支持所有模态 |
| 模态范围 | 通常2-3种主流模态(如图、文、音) | 任意模态——文本、图像、音频、视频、3D点云、传感器信号、红外、雷达等 |
| 交互方式 | 多为"输入A-输出B"的跨模态检索(如图搜文) | 任意组合的输入输出——可以同时输入多种模态,并同时生成多种模态的响应 |
| 代表模型 | CLIP、DALL-E、早期紫东太初1.0 | Qwen3-Omni、紫东太初2.0/3.0、盘古大模型5.0 |
| 核心能力 | 跨模态对齐与理解 | 全模态理解+生成+推理+关联的统一智能 |
一句话总结:多模态是"能处理多种信息的AI",全模态是"天生就活在信息融合世界里的AI"。
3. 为什么全模态如此重要?
-
真正消除"数据孤岛":在医疗、工业等领域,数据常以模态划分(CT影像、病历文本、传感器数据),彼此孤立。全模态模型能像桥梁一样连接这些孤岛,挖掘深层次关联。
-
医疗场景:同时分析CT影像(图像)、病历记录(文本)、医生语音备注(音频),生成更精准的诊断建议。
-
-
实现"主动智能":全模态模型可以7×24小时持续感知多维度信息,从"你问我答"升级为"我懂你需要什么"。
-
智能座舱:通过多模态感知乘员状态(表情、姿势)、车内外环境(温度、光线),自动开启空调并避免直吹熟睡的孩子。
-
-
交互更自然、更类人:人类交流是语言、表情、手势、语调的综合体。全模态AI能同步理解这些信息,并给出融合的响应——看到你皱眉,它可能会放慢语速;听到你兴奋的语气,它的回应也会更有活力。
4. 全模态的核心技术——它是如何工作的?
全模态模型的关键在于"大一统"的技术架构:
-
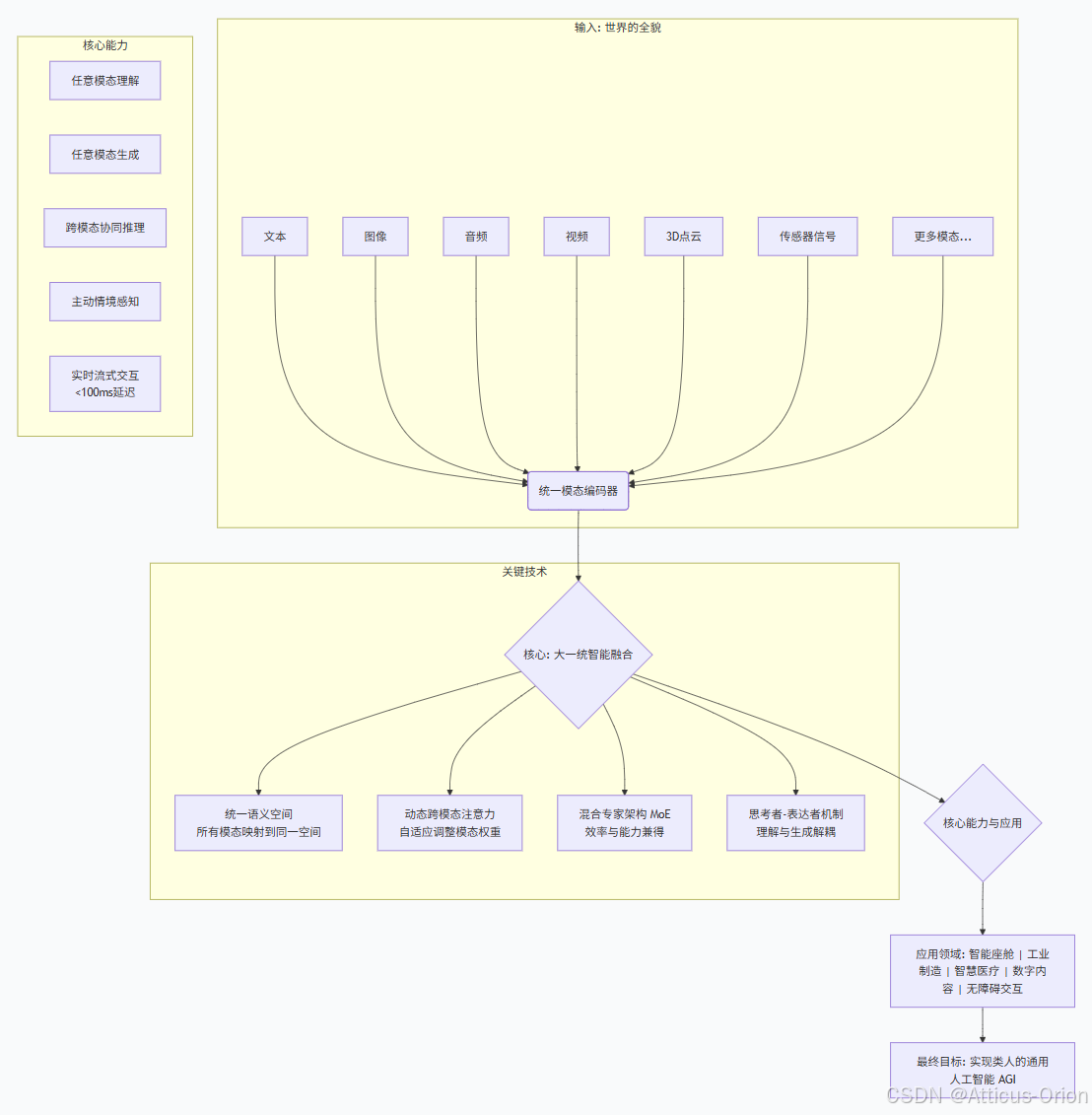
统一模态编码器:不再为每种模态单独设计编码器,而是将所有模态的数据(文本、图像块、音频片段)都转化为模型能理解的"统一语言"(向量),映射到同一个语义空间。
-
动态跨模态注意力:模型能根据输入内容,自动判断哪些模态的信息更重要,并动态调整关注权重。例如,当用户指着图片说话时,模型会重点对齐"手指的区域"和"语音的内容"。
-
混合专家架构:采用MoE技术,模型内部有多个"专家模块"分别擅长处理不同模态组合。输入数据时,只激活相关的专家,既保证了强大的多模态能力,又大幅提升了运行效率。
-
Qwen3-Omni:300亿总参数,但推理时仅激活30亿参数,效率极高。
-
-
"思考者-表达者"机制:一些先进模型采用这种创新设计——"思考者"负责深度理解多模态输入并形成语义,"表达者"负责将这些语义实时解码为文本或语音,确保多模态能力不牺牲单模态性能。
5. 全模态的应用场景——它已经在改变世界
-
智能汽车:斑马智行与阿里云合作推出的Auto Omni方案,让汽车座舱实现"主动智能"。它能理解车内对话、感知乘客状态、记住你的习惯,甚至主动提醒"车里落东西了"。
-
工业制造:湘钢盘古大模型实现全厂关键设备在线监测、提前预警,生产作业率提高20%;智能焊接系统支持25种焊接工艺自动化焊接。
-
数字内容创作:输入一句话,模型可同时生成匹配的图像、背景音乐和语音解说,支持虚拟主播、游戏NPC的智能交互。
-
智慧医疗:神经外科手术导航中,融合3D点云、CT影像和实时传感器数据,辅助医生进行精准操作。
-
无障碍交互:为听障用户提供"语音-文字-手语动画"实时转换,在医疗咨询等场景中自动生成图文报告。
全模态总结框图
挑战与未来
尽管全模态前景广阔,但仍面临挑战:
-
数据需求巨大:需要海量高质量的多模态配对数据,某些模态(如3D点云)数据稀缺。
-
计算资源昂贵:训练成本比多模态模型高数倍。
-
模态平衡难题:需避免某些模态"主导"模型,导致对其他模态的忽视。
未来方向:
-
端侧部署:让全模态模型能在手机、汽车芯片上运行,实现"断网可用、隐私无忧"。
-
具身智能融合:结合机器人本体感知(力觉、触觉),实现真正的"手眼脑协同"。
总结
全模态 是人工智能从"多才多艺"走向"浑然一体"的质变。它不再满足于处理多种信息,而是要在一个统一的智能体系中,让所有信息自由流动、深度融合、协同思考。
正如紫东太初团队所言:"全模态大模型有望解决'数据孤岛'问题,连接原本割裂的信息世界。" 当AI真正拥有了"六感互通"的超级感知力,人机协作的新纪元才刚刚开始。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)