深度学习篇---多模态
多模态人工智能通过整合文本、图像、音频等多种信息形式,使AI系统能够像人类一样综合感知世界。其核心在于对齐和融合不同模态的信息,实现跨模态检索、视觉问答、图像生成等任务。多模态技术消除了单模态的局限性,让AI理解更准确、交互更自然。关键技术包括模态编码、对齐和融合,如CLIP模型通过海量图文训练实现模态对齐。这项技术正推动人工智能从感知迈向认知,未来将在智能设备、自动驾驶等领域发挥重要作用,使AI
多模态:让人工智能更懂这个“花花世界”
如果把传统的单模态人工智能比作只用一种感官感知世界的人(比如只用耳朵听,或者只用眼睛看),那么多模态人工智能就是一个眼、耳、口、鼻、身样样俱全,并能将这些感官信息融会贯通的“完整个体”。
下面,我将从四个方面,由浅入深地带你领略多模态的魅力,并在最后附上一张总结框图。
1. 什么是模态?什么是多模态?
-
模态 (Modality):简单说,就是信息的来源或形式。
-
我们最熟悉的模态有:文本、图像、音频、视频。
-
其他模态还包括:传感器数据、红外图像、深度图、触觉信号等。
-
-
单模态 (Unimodal):人工智能只处理一种类型的信息。
-
例如:只能看懂文字的BERT模型;只能识别图片内容的ResNet模型。
-
-
多模态 (Multimodal):让人工智能同时处理和关联来自不同模态的信息,从而形成对事物更全面、更准确的理解。
一个生动的例子:
想象你在看一段美食视频。
-
你看到的画面是图像和视频模态。
-
你听到的解说和背景音乐是音频模态。
-
屏幕上显示的菜谱和步骤说明是文本模态。
-
一个单模态模型只能理解其中一部分,而一个多模态模型则能将这三者结合起来,理解“这个画面上的动作对应了解说里的哪句话”,甚至推断出“这个菜的味道应该是辣的”(因为画面里有辣椒,解说也提到了)。
2. 为什么多模态如此重要?
因为我们人类天生就是多模态的。我们理解世界的方式就是通过整合各种感官信息。多模态对于人工智能的发展至关重要,原因有三:
-
信息更完整:单一模态往往只能描述事物的一部分。比如“苹果”,文本告诉你它是一种水果,图像告诉你它红红的圆圆的,而多模态告诉你它是一种吃起来脆脆甜甜的红色圆形水果。
-
理解更准确:多模态信息可以互相补充和印证,消除歧义。
-
例子:你说“我想到了!”,你的表情可能是兴奋的,也可能是沮丧的。单从文本无法判断你的真实情绪。但如果结合你的面部表情(图像模态) 和说话的语气(音频模态),人工智能就能更准确地判断你是在兴奋地发现新点子,还是在懊恼地想起一件坏事。
-
-
交互更自然:我们与人交流时,是语言、表情、手势并用的。要让机器与人自然交互,它也必须能理解和运用多模态信息。
3. 多模态的核心任务
多模态能做什么?主要有以下几类核心任务:
-
跨模态检索:用一种模态的信息去检索另一种模态的内容。
-
文搜图:输入“一只在草地上奔跑的白色小狗”,搜索出对应的图片。
-
图搜文:上传一张夕阳下的海滩照片,找到描述它的文字或诗句。
-
-
视觉问答 (VQA):给模型一张图片或一段视频,然后向它提问,它需要结合视觉信息和问题(文本)给出正确的文本回答。
-
输入:一张图片(一个小女孩在玩红色的皮球)+ 问题:“皮球是什么颜色的?”
-
输出:“红色”。
-
-
图像/视频描述:模型“看懂”图像或视频后,自动用自然语言生成一段描述它的文字。
-
输入:一张图片(一群人在海边看日出)。
-
输出:“一群朋友坐在沙滩上,共同见证太阳从海平面升起的壮丽时刻。”
-
-
文本到图像/视频生成:这是近年来最火的方向之一。模型根据一段文本描述,凭空“画”出对应的图像或视频。
-
输入:Prompt:“一只熊猫在弹吉他,赛博朋克风格”
-
输出:一张符合描述的、栩栩如生的图片。
-
-
多模态情感分析:结合用户的文本、语音语调、面部表情,综合判断其情感状态。
4. 背后的关键技术
多模态模型是如何工作的?关键在于“对齐”和“融合”。
-
模态编码:首先,需要用不同的神经网络(编码器)将不同模态的数据转化为计算机能理解的向量表示。
-
文本 $\rightarrow$ BERT、GPT等
-
图像 $\rightarrow$ ViT (Vision Transformer)、ResNet等
-
音频 $\rightarrow$ 音频频谱图编码器等
-
-
模态对齐:这是最核心的一步。模型需要学习不同模态表示之间的对应关系。
-
例子:模型需要学习“文本中的‘小狗’这个词”与“图像中那个毛茸茸的四条腿动物”是对齐的。
-
著名模型:OpenAI 的 CLIP 模型就是通过海量的图文对进行训练,让匹配的图文在向量空间中的距离更近,不匹配的则更远,从而实现了强大的图文对齐能力。
-
-
模态融合:将对齐后的多模态信息进行整合,形成一个综合的表示,用于完成下游任务。融合的方式可以是简单的拼接、加权求和,也可以是更复杂的注意力机制。
多模态总结框图
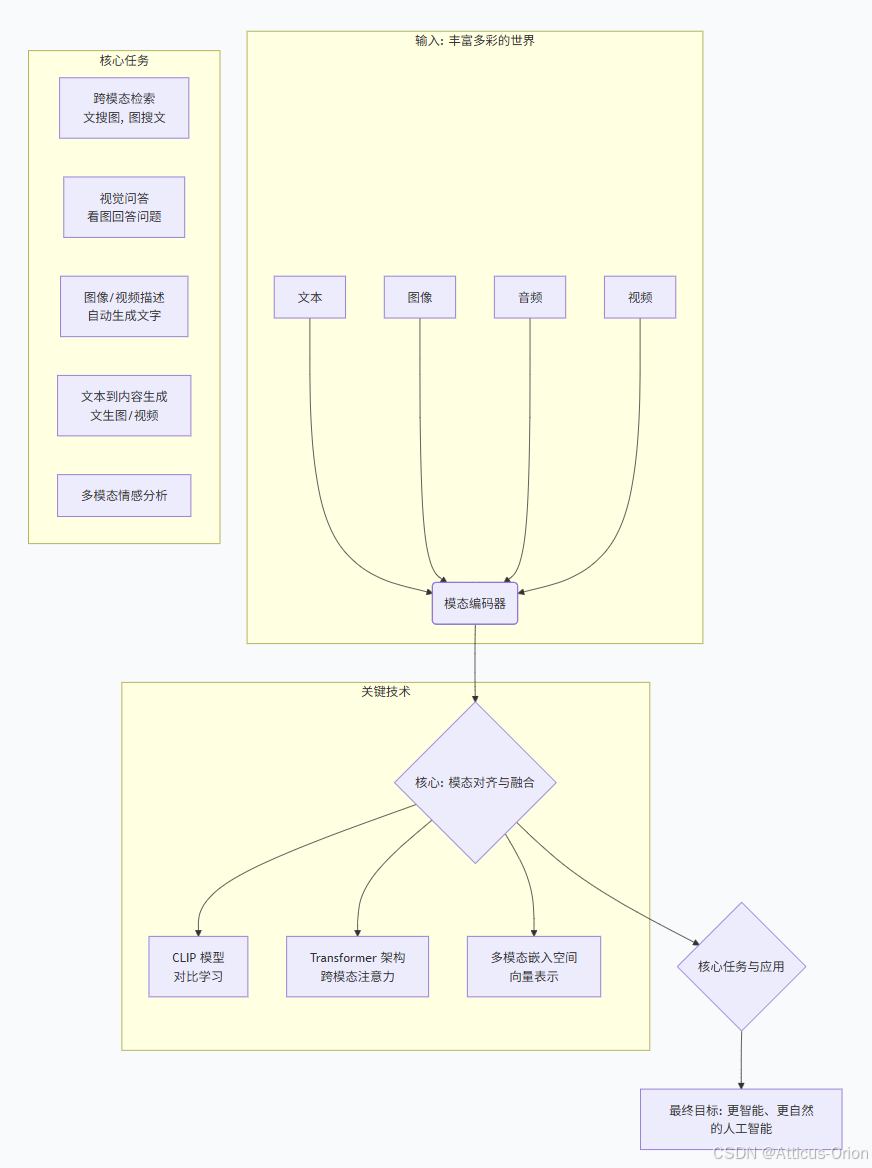
总结
多模态 是人工智能从“感知”走向“认知”的必经之路。它不再让AI局限于单一的信息孤岛,而是赋予其整合视觉、听觉、语言等多种信息的能力,让AI更接近人类的感知和认知方式。
未来,我们身边的智能设备、自动驾驶汽车、医疗诊断系统等,都将因为多模态技术而变得更加聪明、体贴和可靠。下次你再用语音助手或者看AI生成的图片时,不妨想一想,这背后可能就有着多模态技术的功劳哦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)