大模型性能优化:从入门到实践,收藏这份小白程序员进阶指南!
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?答案只有一个:人工智能(尤其是大模型方向)当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应
大模型训练与推理性能优化涉及模型架构、硬件特性、并行策略、算子设计、数据处理等多个维度。本文从大模型发展基础、训练流程优化、推理核心原理与优化策略、关键技术实践等方面进行梳理,深入浅出地介绍了大模型技术落地的理论支撑与实践指导,帮助小白程序员快速入门并提升技能。
大模型发展基础与核心概念
一、从语言模型到大语言模型
自然语言处理(NLP)技术的发展历程可分为四个关键阶段:早期基于规则和知识的方法、统计方法崛起(如HMM、CRF)、深度学习革命(如RNN、LSTM)以及预训练模型兴起(如BERT、GPT、T5)。其中,Transformer架构的提出是大模型发展的里程碑,其自注意力机制打破了传统时序模型的序列依赖限制,为并行计算和模型规模化提供了可能。
根据模型结构,主流大模型可分为三类:
1.仅解码器模型(Decoder-Only):以GPT系列、LLaMA系列、Qwen系列等为代表,采用自回归生成方式,擅长文本生成、对话交互等任务;
2.仅编码器模型(Encoder-Only):以BERT系列为代表,采用双向注意力机制,在文本理解、分类、问答等任务中表现突出;
3.编码器-解码器模型(Encoder-Decoder):以T5、GLM系列为代表,兼顾理解与生成能力,适用于机器翻译、文本摘要等任务。
大规模语言模型(LLM)通常指参数量达到亿级以上的神经网络模型,其核心优势在于通过大规模预训练习得通用语言规律和世界知识,能够通过微调或提示工程适配多种下游任务。与传统语言模型相比,LLM具备更强的泛化能力、上下文理解能力和复杂任务处理能力,但也对计算资源、存储资源和优化技术提出了更高要求。
二、核心概念
1.Transformer架构核心组件
Transformer架构的核心包括自注意力机制(Self-Attention)、多头注意力(Multi-Head Attention)、前馈网络(FFN)、层归一化(LayerNorm)和残差连接(Residual Connection)等组件:
-
自注意力机制:通过计算Query(查询)、Key(键)、Value(值)三者的相关性,实现对输入序列中所有位置的自适应关注,计算复杂度为O(n²)(n为序列长度);
-
多头注意力MHA:将Q、K、V拆分为多个独立的注意力头,并行计算后拼接结果,能够捕捉不同维度的语义关联;
-
多查询注意力MQA:所有查询头共享单一的键和值,旨在以牺牲少量模型质量为代价,大幅减少推理时的显存占用和计算量。
-
分组查询注意力GQA:将查询头分成若干组,每组共享一个键和值,在保持与MHA相近的模型性能的同时,实现了接近MQA的推理加速效果,是MHA和MQA的折中方案。
-
多头潜在注意力MLA:DeepSeek运用的注意力计算方法,通过双低秩压缩解耦技术,在极速降低 KV Cache 显存带宽压力的同时,通过矩阵吸收的方式保持了MHA的计算精度。
-
前馈网络:由两层线性变换和激活函数(如GELU)组成,对注意力输出进行非线性转换,增强模型表达能力;
-
层归一化:对每层输入进行归一化处理,稳定训练过程,加速收敛;
-
残差连接:将输入直接添加到层输出中,缓解深层网络的梯度消失问题。
2.关键训练与推理概念
- 预训练(Pre-training):在大规模无标注文本数据上训练模型,学习语言规律和通用知识,为下游任务提供基础能力;
- 微调(Fine-tuning):在预训练模型基础上,使用特定任务的标注数据调整参数,使模型适配具体任务,包括监督微调(SFT)、奖励模型微调(RM)和基于人类反馈的强化学习(RLHF)等;
- 自回归生成(Autoregressive Generation):逐一生成输出Token,每个Token的生成依赖于之前的Token序列,是Decoder-Only模型的核心生成方式;
- Prefill阶段:自回归模型推理的初始阶段,并行计算所有输入提示词(Prompt)的注意力,生成Key和Value向量并写入KV Cache,为后续生成做准备,该阶段计算密集、无Token间依赖;
- Decode阶段:在Prefill阶段之后,逐个生成输出Token的循环过程,直接读取并更新KV Cache,该阶段内存访问密集、计算量小、具有严格的序列依赖;
- KV Cache:缓存Prefill阶段生成的Key和Value向量,避免Decode阶段重复计算,是提升推理效率的关键技术,但会占用大量显存;
- 四大资源:算力(计算能力,以TFLOPs为单位)、显存(GPU物理显存容量)、显存带宽(GPU显存读写速率)、通信带宽(跨卡/机间数据传输速率),是大模型优化的核心关注对象。
- TTFT (Time To First Token):指从用户输入Prompt开始,到模型生成第一个输出token所需的时间,也即是Prefill阶段所需要的时间。
- TPOT (Time Per Output Token)指模型在Decode生成阶段,平均每个输出Token所花费的时间。衡量单Token生成的延迟情况。
- 吞吐量(Tokens Per Second, TPS):指模型在生成阶段单位时间能生成的token数,与TPOT成反比(TPS = 1 / TPOT)。
3.生成过程随机性控制参数
通过调整随机性控制参,可以控制生成文本的多样性。常见的随机性控制参数主要有如下:
-
temperature(温度):在文本生成中用于调节输出的随机性。提升温度设置会使得产生的文本更为随机和创新;降低温度生成的文本更加稳定和重复。通常设置在0.7到1之间。较低的温度(如0.7)可以使生成的文本更加连贯和准确,较高的温度(如1)则使文本更加多样和创造性。
-
top_k(Top-K Sampling):限定模型从最可能的前k个词里挑选预测词。随着k值增大,可选词的范围变宽,文本的多样性提升;减小k值则减少可选词的范围,使得生成文本更倾向于出现概率较高的词。一般设置在40到100之间。较小的k值可以提高文本的相关性和连贯性,而较大的k值则增加了文本的多样性。
-
top_p(Nucleus Sampling):限定从概率累积达到给定的p值时的一组词汇集合中选取下一个词。较低的top_p值使生成的文本更加可预测和相关;较高的值增加了文本的多样性和创造性。这种采样方式的可选词的数量是动态的,在不同的上下文中可能是不同的。通常设置在0.8到0.95之间。较低的top_p值(如0.8)使生成的文本更加可预测和相关,而较高的值(如0.95)增加了文本的多样性和创造性。
4.幻觉概念
在大模型生成过程中,最主要的问题即为幻觉问题,幻觉主要有两种类型:
-
事实性幻觉(Factuality Hallucination):主要表现为“与事实不一致”或者“捏造”,生成的内容与现实世界之间存在差异。
-
忠实性幻觉(Faithfulness Hallucination):主要表现为生成内容和用户的输入指令及上下文内容存在偏离。
幻觉与训练数据、训练/推理过程都存在关系。质量差的训练数据不可避免会影响模型。由于大模型推理方式是通过前文预测下文的形式,因此不可避免会出现当遇到一些不佳的token组合时出现幻觉情况。训练过程也有缺陷,预训练阶段的架构缺陷、自注意力模块缺陷、暴露偏差等以及微调对齐阶段的能力错位、信念错位等都会造成幻觉问题。推理阶段固有的抽样随机性、不完美的解码表示等也是造成幻觉的关键缺陷。
5.并行策略相关概念
为应对大模型参数量和计算量的爆炸式增长,分布式并行技术成为关键支撑,主流并行策略包括:
-
并行度:指某类并行策略下,参与该并行的 GPU 数量,是衡量并行规模的核心指标,比如TP8或者EP8。
-
Rank:在分布式并行计算中,唯一标识一个处理单元(通常是GPU)的编号或索引。
-
张量并行(TP, Tensor Parallelism):将单层内的权重矩阵切分到多个GPU上,通过All-Reduce通信换取显存容量和单步计算速度;
-
数据并行(DP, Data Parallelism):将不同输入样本(Batch)分配到不同GPU上,主要用于扩大吞吐量;
-
专家并行(EP, Expert Parallelism):专为MoE(混合专家)架构设计,将不同专家分配到不同GPU上,Token根据路由结果在GPU间进行All-to-All交换;
-
序列并行(SP, Sequence Parallelism):将序列在输入序列维度上切开,常与TP结合使用,解决长输入带来的显存压力;
-
上下文并行(CP, Context Parallelism):在Attention计算层面做跨卡切分,是更高级的长文本并行方案;
-
流水线并行(PP, Pipeline Parallelism):按模型层进行横切,不同层运行在不同GPU上,像流水线一样传递中间结果;
-
CPP:CP与PP的混合并行策略,适用于超大规模集群下的超长序列训练/推理。
大模型训练优化
一、训练数据构建与优化
数据是大模型训练的基础。数据的质量、规模和多样性直接决定模型性能。训练数据的构建需遵循"高质量、大规模、多样性"原则,具体优化方向包括:
1.数据集格式与统一处理
大模型微调常用的数据集格式主要有两类:
- 问答格式数据集:包含prompt(提示)和response(响应)字段,适用于对话生成、问答等任务;
- 指令微调数据集:包含instruction(指令)、input(输入)和output(输出)字段,通过多样化指令示范,让模型学会遵循用户指令完成任务。
为确保训练效果,需对数据集进行统一处理:
- 字段统一:将不同来源数据集的核心字段映射为统一格式(如instruction、input、output),处理缺失字段和格式不一致问题;
- 内容清洗:过滤语句不通顺、知识表达不充分、广告数据、答非所问等低质量数据,可通过困惑度(PPL)评估语句合理性,结合人工筛选提升数据质量;
- 数据增强:通过prompt模板多样化(如将"中译英"拓展为"翻译中文为英文")、多轮对话构造、Few-shot/COT(思维链)数据添加等方式,增强数据多样性,提升模型泛化能力。
2.数据组合策略
针对行业大模型训练,常用的数据组合方式包括:
- 开源大模型+行业数据:在开源通用大模型基础上,加入行业问答数据、专业文档等,快速构建行业定制模型,资源需求较小;
- 通用基座模型后训练+行业数据集微调:先在通用基座模型上进行行业语料预训练,扩充领域词表和语义理解能力,再通过行业指令数据集微调,提升任务执行能力。
需注意避免单一领域数据过拟合,通常需混合通用领域数据与行业数据,平衡模型的通用能力与领域适配性。
3.数据质量筛选
采用Teacher-student架构进行数据质量筛选:
- 基于生成式大模型构建判别器,过滤低质量数据;
- 训练小模型(如BERT)作为语料质量分类模型,快速筛选大批量数据中的高质量样本,实现大模型语义能力向小模型的蒸馏。
二、训练阶段优化
大模型训练阶段的核心目标是在保证精度的前提下,提升训练速度、降低显存占用、提高资源利用率。主要优化技术包括:
1.并行化训练策略
并行化是解决大模型训练算力和显存瓶颈的核心手段,实际应用中通常结合多种并行策略:
- 单节点内:采用TP分割模型权重,降低单卡显存占用,结合DP扩大Batch Size;
- 跨节点:利用PP将模型层分布到不同节点,通过数据并行提升训练吞吐量;
- MoE架构:采用EP将专家分散到多个GPU/节点,解决MoE模型显存占用大的问题。
负载均衡是并行训练的关键,例如在多模型Pipeline并行部署中,通过任务调度使不同GPU的负载趋于均衡,避免部分GPU闲置。
2.显存优化技术
- 梯度累积(Gradient Accumulation):通过累积多个小批量样本的梯度再更新参数,在不增加单Batch显存占用的前提下,实现等效大Batch训练;
- 梯度检查点(Gradient Checkpointing):选择性保存前向传播中的激活值,反向传播时重新计算未保存的激活值,以少量计算开销换取显存占用降低,可将10倍大的神经网络放入显存;
- 混合精度训练(Mixed Precision Training):部分参数使用FP16等低精度浮点数计算,减少显存占用并加速训练,同时通过FP32保存权重副本和梯度,确保训练精度;
- ZeRO内存优化(Zero Redundancy Optimizer):由DeepSpeed框架实现,通过优化器状态分区、梯度划分、参数划分等方式,减少每个GPU上的冗余数据存储,支持超大规模模型训练。
3.训练框架与工具
主流的大模型训练框架包括:
- DeepSpeed:微软开源框架,支持ZeRO内存优化、流水线并行、混合精度训练等,可大幅降低大模型训练的显存需求和计算成本;
- Megatron-LM:NVIDIA提出的基于PyTorch的框架,针对Transformer进行专门优化,支持多种并行策略,是超大规模语言模型预训练的常用选择;
- Hugging Face Transformers:提供丰富的预训练模型接口和训练工具,支持与DeepSpeed、Megatron-LM等框架集成,降低训练门槛。
4.超参数调优
关键超参数的合理调整对训练效果至关重要:
- Epochs:根据数据规模调整,小数据集可适当增加epoch促进收敛,但需避免过拟合;
- Batch Size:较大Batch Size加速训练但可能收敛于次优解,较小Batch Size有助于泛化但延长训练时间,需结合硬件资源平衡;
- 学习率:控制参数更新步长,过高导致震荡,过低减慢训练,可采用指数衰减、余弦退火等动态调整策略;
- 权重衰减(Weight Decay):通过在损失函数中添加惩罚项防止过拟合,增强模型泛化能力;
- 梯度裁剪(Gradient Clipping):设置梯度阈值防止梯度爆炸,确保参数更新稳定。
三、模型微调与价值对齐
大模型微调是提升特定任务性能的关键步骤,通常包括三个阶段:
1.监督微调(SFT)
使用精选的标注数据对预训练模型进行监督训练,使模型学会在特定任务中生成符合预期的输出。SFT的核心价值在于:
- 针对特定任务提升性能:弥补预训练模型在具体任务上的性能短板;
- 提高领域适应性:让模型适应行业专业数据、表达习惯和语义;
- 适配数据稀缺任务:在有限标注数据场景下,快速提升模型效果。
2.奖励模型微调(RM)
使用包含人类对同一问题多个答案打分的数据集,训练单独的奖励模型,用于评估生成结果的优劣。奖励模型的训练需注意:
- 数据多样性:覆盖不同场景、不同质量等级的输出样本;
- 标注一致性:确保人类打分的一致性,避免模糊标注影响模型学习;
- 排序优化:采用基于排序的奖励建模(RBRM),通过对候选输出排序赋予相对优劣,指导模型生成更好的回答。
3.基于人类反馈的强化学习(RLHF)
利用强化学习算法,根据奖励模型的反馈进一步调优模型,使模型输出与人类偏好对齐。RLHF的核心是PPO(Proximal Policy Optimization)算法,其优势在于在保持稳定性的同时实现较高性能,避免模型更新幅度过大导致性能下降。
让模型理解并遵循人类价值观、需求和期望,是大模型安全落地的关键:
- 监督微调阶段:使用具有明确道德、法律规范的标注数据;
- 奖励建模阶段:设计符合人类偏好的奖励函数,惩罚有害、误导性输出;
- 强化学习阶段:根据实际反馈调整模型策略,确保模型输出安全、可靠、有用。
四、训练框架实践示例
- DeepSpeed训练配置
DeepSpeed支持ZeRO内存优化、混合精度训练等核心功能,以下是基于DeepSpeed的SFT训练脚本示例:
deepspeed \
--include="localhost:0,1,2,3" \
./train_sft.py \
--deepspeed ./ds_config/ds_config_zero3.json \
--model_name_or_path TigerResearch/tigerbot-7b-sft \
--dataset_name TigerResearch/dev_sft \
--do_train \
--output_dir ./ckpt-sft \
--overwrite_output_dir \
--preprocess_num_workers 8 \
--num_train_epochs 5 \
--learning_rate 1e-5 \
--evaluation_strategy steps \
--eval_steps 10 \
--bf16 True \
--save_strategy steps \
--save_steps 10 \
--save_total_limit 2 \
--logging_steps 10 \
--tf32 True \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2
其中ds_config_zero3.json配置文件包含FP16/BF16设置、优化器参数、ZeRO优化阶段等核心配置,通过参数分区、优化器卸载等方式降低显存占用。
- Megatron-LM训练配置
Megatron-LM适用于大规模预训练,以下是其训练脚本核心配置示例:
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-small
VOCAB_FILE=vocab.json
MERGE_FILE=merges.txt
DATA_PATH=codeparrot_content_document
GPT_ARGS="--num-layers 12 --hidden-size 768 --num-attention-heads 12 --seq-length 1024 --max-position-embeddings 1024 --micro-batch-size 12 --global-batch-size 192 --lr 0.0005 --train-iters 150000 --lr-decay-iters 150000 --lr-decay-style cosine --lr-warmup-iters 2000 --weight-decay .1 --adam-beta2 .999 --fp16 --log-interval 10 --save-interval 2000 --eval-interval 200 --eval-iters 10"
TENSORBOARD_ARGS="--tensorboard-dir experiments/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS
该配置指定了模型层数、隐藏层维度、注意力头数等架构参数,以及学习率、Batch Size、训练迭代次数等训练参数,支持张量并行和流水线并行的灵活配置。
大模型推理优化策略
一、推理优化的思考框架
大模型推理优化的核心矛盾是算力、显存、显存带宽、通信带宽等资源的不匹配或短缺,这一矛盾在宏观(集群)、中观(单机/卡/框架)、微观(算子)等不同层级上反复重演。
| 资源类型 | 单位 | 相关评估指标举例 | 经验阈值 |
| 算力 | 计算量(TFLOPs) | MFU=实际算力 / 峰值算力 | MFU<60%,算力未饱和,需提升并行度/BatchSize等 |
| 显存 | 单卡总占用(GB) | 权重+ KV Cache + 激活值 + 系统预留 + cudagraph占用(~10GB / 卡) | >85%,易触发OOM,需压缩/复用存储 |
| 显存带宽 | GPU 核心访问其自身显存(HBM)能达到的稳定数据传输速率上限(GB/秒)。 | (显存读写量 / 带宽) ÷ (计算量 / 峰值算力) | >0.5,访存主导延迟,需算子融合、算子流程优化等 |
| 通信带宽 | 机内或者机间的卡与卡的通信带宽(GB/秒) | (通信量 / 网络带宽) ÷ (计算量 / 峰值算力) | >0.5,通信制约吞吐,需优化并行策略、减少通信量 |
- 思考框架核心步骤
- 看清楚:结合模型结构和推理过程,计算或采集四大资源的需求量,识别瓶颈点;
- 避免浪费:消除不必要的Kernel Launch、算子冗余、数据重复搬运,让资源聚焦核心计算;
- 提升利用率:通过并行策略调优、负载均衡调度、通信优化等,减少资源不匹配程度;
- 节约资源:在精度几乎无损前提下,通过量化、稀疏化、算子创新等减少资源需求量。
通过这4点思考框架,可以不受限于具体模型和硬件,能够帮助开发者在复杂优化场景中快速定位重点,避免遗漏优化机会。
2.资源占用理论分析
推理优化的前提是精准量化四大资源的需求与瓶颈,基于DeepSeek R1
MoE和MLA架构的资源测算方法如下:
(1)算力分析
算力需求与模型结构、序列长度、Batch Size密切相关,以下给出简单测量方法:
非注意力部分包括MoE+稠密FFN,其计算量 表示。
MHA注意力(用于Prefill阶段)计算量用 表示。
MLA注意力(用于Decode阶段)计算量用 表示。
则Prefill阶段算力:
Decode阶段单Token算力:
(2)显存占用分析
推理模型的显存占用主要包括模型权重、KV Cache、激活值和系统预留(约10GB/卡),以下测算均为单卡上的显存占用,计算需要注意并行策略对显存的分化:
模型权重显存用 表示。
KV Cache显存用 表示。
激活值占用用 表示。
单卡总显存占用为:这里假设Dense部分采用TP并行,MoE部分采用EP并行策略。在不同阶段,激活值占用不同,prefill阶段为MHA的激活值,decode阶段采用MLA的激活值。
(3)显存带宽占用分析
显存带宽瓶颈会导致其他资源利用率下降:
- 显存读写总量:
IOtotal = IOweight + IOKV + IOact
- 权重读写量(Prefill阶段):
IOweight ≈ Sizedense/TP + (SizeMoE/257×k)/2 GB(k为激活专家数)
- 权重读写量(Decode阶段):
IOweight ≈ (Sizedense/TP + (SizeMoE/257×k)/2) ×s GB(s为输出Token长度);
- KV Cache读写量:
IOKV = NLayer×b×s×(dc+dr)/1024³ GB;
- 激活值读写量:
Prefill阶段:
IOact ≈ (MemLinear+MemMHA_score+MemFFN) × 2 GB
Decode阶:
IOact ≈ (Memlinear+MemMLAscore+Memffn)×s×2 GB
(4)通信带宽占用分析
通信量与并行策略密切相关:
总通信量:
TrafficTotal = TrafficEP + TrafficTP;
EP并行通信量:
TrafficEP≈NLayer-MoE×2bsdmodel×(k-1)×Precision/1024³ GB;
TP并行通信量:
TrafficTP≈NLayer×2bsdmodel×Precision×(TP-1)/TP/1024³ GB。
通信瓶颈在Prefill阶段更为突出,例如TP8+EP8并行策略下,通信耗时/计算耗时=0.61,优化通信耗时或隐藏通信延迟可显著提升Prefill阶段吞吐量。
二、推理优化实施路径
基于上述思考框架,大模型推理优化可分为"看清楚-避免浪费-提升利用率-节约资源"四个递进阶段,每个阶段均需在宏观、中观、微观层级同步推进。
1.第一阶段:看清楚——模型架构解析与资源量化
优化的前提是明确模型结构和资源瓶颈,以DeepSeek R1/V3为例:
-
模型架构:61层Transformer,前3层为稠密FFN,后58层为MoE结构(257个专家,单Token激活9个专家),总参671B,激活参37B;
-
推理流程:Prefill阶段批量处理长序列,初始化KV Cache;Decode阶段单Token串行生成,复用KV Cache;
-
资源量化:通过四大资源计算公式,结合具体硬件参数(如H20 FP8峰值算力296 TFLOPs、显存带宽4TB/秒),精准定位算力、显存、带宽等瓶颈。
2.第二阶段:避免浪费——消除结构性冗余
通过消除无效开销,快速释放资源,主要优化方向:
(1)减少重复Prefill(宏观层级)
用户输入中常包含相同前缀(如系统提示词),无需重复Prefill。方案:
-
基于vLLM集成LMCache作为缓存引擎,对接NitroFS远程存储,支持本地+远程混合缓存;
-
实现PD(Prefill-Decode)分离,通过分布式KV Cache store复用相同前缀的KV Cache;
-
实践效果:在20%输入重复场景下,可减少16%的Prefill计算。
(2)消除CPU-GPU交互空隙(中观层级)
Decode阶段GPU执行Kernel速度极快,而CPU下发指令开销较大,导致GPU空闲:
-
传统优化:使用CUDA Graph捕获执行流,减少CPU介入;
-
进一步优化:CPU-GPU Overlap,在当前Step的GPU计算未结束时,CPU提前预处理下一个Step的元数据,填补时间空隙;
-
实践效果:Decode性能提升10%+,持续请求下GPU保持高负载。
(3)算子融合优化(中观-微观层级)
将多个独立算子合并为单个Kernel,减少Kernel Launch和数据搬运开销:
-
MoE专家选择算子融合:将18个独立Kernel(线性层计算、Softmax、Top-K等)融合为2个,算子级加速10倍,显存带宽节约50%;
-
Pre-Quant与Expand Row融合:在GEMM前融合为单个操作,避免重复读写,节省50% HBM读写;
-
Metadata融合:全局缓存专家索引、路由权重等Metadata,各层通过哈希映射快速查询,端到端耗时降低2%~3%。
3.第三阶段:提升利用率——软硬深度协同
通过并行策略、负载均衡、通信优化等,提升资源利用率,核心优化方向:
(1)PD分离架构(宏观层级)
Prefill与Decode阶段资源需求差异大,PD分离通过针对性硬件拓扑和软件策略提升利用率:
-
流程:用户请求→负载均衡器→Prefill节点集群(大TP+小EP)→KV Cache RDMA传输→Decode节点集群(DP+大EP)→输出结果;
-
Prefill节点优化:采用TP+EP并行缩短TTFT,Chunk调度(优先调度短prompt)优化响应时间,通过计算通信重叠、Layerwise传输、NIXL零拷贝传输优化KV Cache传输;
-
Decode节点优化:采用DP+EP并行扩大Batch Size,缓解显存墙问题;通过负载均衡调度(如基于KV Cache利用率的调度)提升GPU利用率。
(2)通信优化(中观层级)
MoE架构的通信瓶颈是性能关键,方案:
-
DeepEP通信库:专为MoE模型设计,通过Dispatch(Token路由、重排打包、异构传输)和Combine(结果收集、加权求和)流程,适配NVLink→RDMA非对称带宽;
-
TRMT优化:在DeepEP基础上,通过Bypass CPU(控制面时延从3us降至0.5us)、Bypass L2(精准缓存控制)、负载均衡与拥塞控制(跑满双端口网卡带宽),通信算子耗时减少60%;
-
NIXL零拷贝传输:直接使用KV Cache作为传输源和目的,避免NCCL的额外拷贝,实战性能提升3~4%。
(3)MoE负载均衡(中观层级)
MoE架构中专家负载不均会导致算力空转,方案:
-
静态专家放置策略:采用Round-Robin策略(Physical_GPU_ID = Global_Expert_ID % Number_of_GPUs),将专家均匀分布到各GPU;
-
结合DeepEP low-latency算法,适配vLLM的MoE执行路径;
-
实践效果:请求吞吐率提升14.03%,TTFT降低超50%,TPOT(平均每个输出Token耗时)降低8.06%。
(4)多Token预测(MTP)优化(中观层级)
一次预测多个Token,提升算力利用率,适用于长输入小并发场景(显存快满但算力闲置)。需注意高Batch Size下,MTP的额外计算开销可能抵消收益,需根据场景灵活调整。
4.第四阶段:节约资源——算法与架构创新
通过技术创新减少资源需求,在精度无损前提下实现"少做计算",主要优化方向:
(1)显存节约:MLA架构(微观层级)
传统MHA需要缓存巨大的KV Cache,MLA通过矩阵低秩分解,将KV Cache压缩为紧凑的Latent Vector,显存占用减少数倍,支持单卡超大Batch Size。
(2)算力与带宽节约:量化与稀疏化(微观层级)
-
量化压缩:MoE层采用W4A8(权重4bit,激活8bit)量化,通过AWQ(Activation-aware Weight Quantization)保护敏感通道,精度无损,显存带宽需求减半;对敏感层(如前3层稠密层)不进行INT4量化,平衡精度与性能;
-
稀疏注意力:DeepSeek提出DSA(稀疏注意力),通过Lightning Indexer快速扫描、Fine-Grained Selection筛选关键Token、Sparse Attention Calculation计算,将Attention复杂度从O(n²)降至O(nk),128K长度下带宽压力减少73.6%。
(3)新兴架构资源预分析(微观层级)
对新架构(如mHC)提前进行资源测算,避免盲目实施:
-
算力测算:FlopsmHC ≈ 2ndmodel(n²+3n+3)bs + 2(n²+2n) + Iter×n²(n通常为4,Iter为20);
-
显存占用:MemmHC = 2ndmodel + n² + 2n;
-
优化方向:逻辑降维与参数合并、全流程算子融合、高效混精训练等。
三、推理优化关键技术实践
- KV Cache优化
KV Cache是推理效率的核心,优化方向包括:
-
PagedAttention:将KV Cache拆分为固定大小的块,允许在非连续显存空间存储,通过Block Table管理逻辑与物理地址映射,内存利用率提升3~5倍,支持更大Batch Size;
-
自动前缀缓存(APC):缓存已计算的KV Cache,新请求到达时复用共享前缀的KV Cache,仅计算新增内容,适用于长文档查询、多轮对话等场景;
-
共享机制优化:在并行采样、Beam Search场景下,通过引用计数管理共享KV块,减少内存冗余。
2.分布式推理并行实践
结合多种并行策略,平衡算力、显存和通信:
-
TP+EP并行:Prefill阶段采用TP8+EP8,推理耗时从0.16秒降至0.082秒,通信耗时增加有限;
-
DP+EP并行:Decode阶段采用DP8+EP16,单卡显存占用从68.5GB降至47.5GB,支持更大Batch Size;
-
并行策略选择:中小型模型优先TP加速;超大规模模型采用PP;MoE模型必须结合EP;实际应用中需根据模型大小、硬件配置灵活组合。
3.长序列推理优化
长序列场景下(如32k以上),Attention计算复杂度和显存占用急剧增加,优化方案:
-
序列并行(SP)与上下文并行(CP):拆分长序列,缓解显存压力;
-
稀疏注意力(如DSA):降低计算复杂度;
-
可扩展位置编码:修改位置编码机制,支持动态序列长度扩展;
-
位置编码内插:调整scale参数,简单易用,适用于通用推理场景。
推理优化关键技术对比与场景选型
一、核心优化技术对比
| 优化技术 | 核心目标 | 适用场景 | 优势 | 局限 |
| 张量并行(TP) | 提升单步计算速度,降低单卡显存占用 | 模型权重较大,单卡无法容纳 | 计算速度快,易于集成 | 通信量较大,需高带宽支持 |
| 数据并行(DP) | 扩大吞吐量 | 样本量多,Batch Size 需提升 | 实现简单,通用性强 | 单卡显存占用高,不适合超大模型 |
| 专家并行(EP) | 适配 MoE 架构,分散专家显存占用 | MoE 模型推理 / 训练 | 针对性强,显存优化效果显著 | 通信复杂,需负载均衡支持 |
| 流水线并行(PP) | 拆分模型层,支持超大规模模型 | 模型层数多,单卡无法容纳 | 支持超大模型部署 | 存在气泡时间,小模型效率低 |
| 量化压缩(W4A8/FP8) | 减少显存占用和带宽需求 | 显存受限场景,精度要求适中 | 资源节约效果显著,精度损失小 | 需硬件支持,部分模型敏感层不适用 |
| 算子融合 | 减少 Kernel Launch 和数据搬运 | 所有推理场景,尤其是 Decode 阶段 | 性能提升明显,实现成本适中 | 需针对具体算子优化,通用性有限 |
| PagedAttention | 提升 KV Cache 利用率 | 长序列、多请求场景 | 内存利用率高,支持动态 Batch | 实现复杂,需推理框架支持 |
| 稀疏注意力(DSA) | 降低长序列计算复杂度 | 长序列推理(32k 以上) | 计算量大幅减少,带宽压力小 | 需模型架构适配,短序列收益有限 |
二、典型场景选型建议
1.自动驾驶模型训练
-
核心需求:大规模数据处理,训练周期短,模型精度高;
-
优化方案:DeepSpeed ZeRO+3D并行(TP+DP+PP),混合精度训练,梯度累积,数据预加载;
-
硬件选型:多节点GPU集群(如H800),高带宽网络(IB)。
2.智能座舱实时交互
-
核心需求:低延迟(百毫秒级),高吞吐,显存占用低;
-
优化方案:PD分离,TP+EP并行,算子融合,W4A8量化,CPU-GPU Overlap;
-
硬件选型:端侧/边缘GPU(如Orin),高带宽显存。
3.联网诊断高并发服务
-
核心需求:高并发处理,低硬件成本,稳定响应;
-
优化方案:Continuous Batching,APC前缀缓存,负载均衡调度,PagedAttention;
-
硬件选型:云服务器GPU集群(如H20),分布式存储。
4.长文档问答(128k序列)
-
核心需求:长序列支持,低带宽占用,高准确率;
-
优化方案:DSA稀疏注意力,CP/SP并行,Layerwise传输,KV Cache压缩;
-
硬件选型:高显存带宽GPU(如H20),大内存节点。
总结与展望
一、核心结论
大模型训练与推理优化的本质是对硬件资源的高效利用,其核心均围绕算力、显存、显存带宽、通信带宽四大资源,持续逼近硬件物理极限。
关键技术实践表明:
1.数据层面:高质量、多样化的数据是模型性能的基础,合理的数据组合和清洗能显著提升训练效率和模型效果;
2.训练层面:并行化策略、显存优化技术(梯度累积、混合精度)、训练框架(DeepSpeed、Megatron-LM)是提升训练速度、降低成本的核心;
3.推理层面:PD分离、算子融合、量化压缩、KV Cache优化(PagedAttention、APC)、通信优化(DeepEP、TRMT)是解决延迟、显存、吞吐瓶颈的关键;
4.架构层面:MoE架构通过稀疏激活平衡模型容量与计算量,MLA、DSA等创新注意力机制显著降低资源需求,是大模型规模化的重要方向。
二、未来展望
大模型优化技术仍在快速演进,未来发展方向包括:
1.更高效的模型架构:持续优化注意力机制和网络结构,在保证性能的同时进一步降低资源需求;
2.硬件-软件深度协同:针对特定硬件(如专用AI芯片)优化算子和并行策略,充分发挥硬件性能;
3.自动化优化工具:开发端到端自动化优化平台,简化并行策略选择、超参数调优、算子优化等流程;
4.低资源大模型技术:在中小算力设备上部署大模型,拓展应用场景;
5.多模态大模型优化:针对文本、图像、音频等多模态数据,优化跨模态推理的资源占用和延迟。
随着技术的不断突破,大模型将在更多行业场景中实现高效落地,为人工智能产业发展注入持续动力。在实际应用中,需根据具体场景的资源约束、性能需求和业务目标,灵活选择优化技术组合,实现模型性能与成本的平衡。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。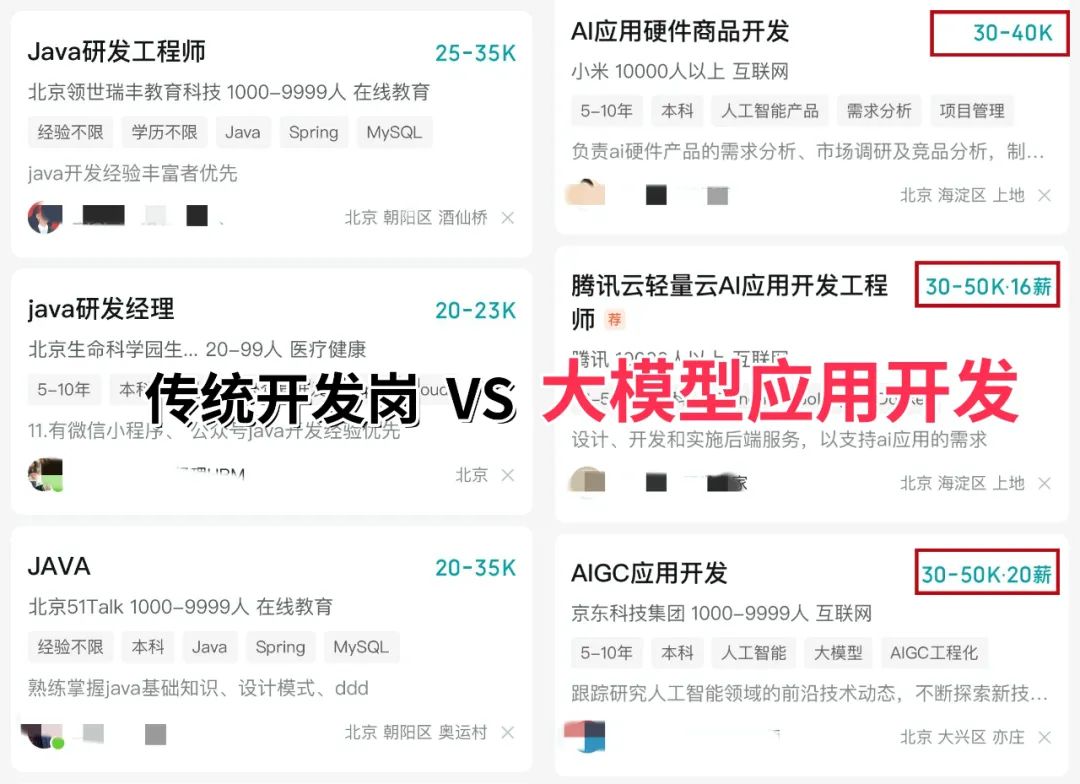
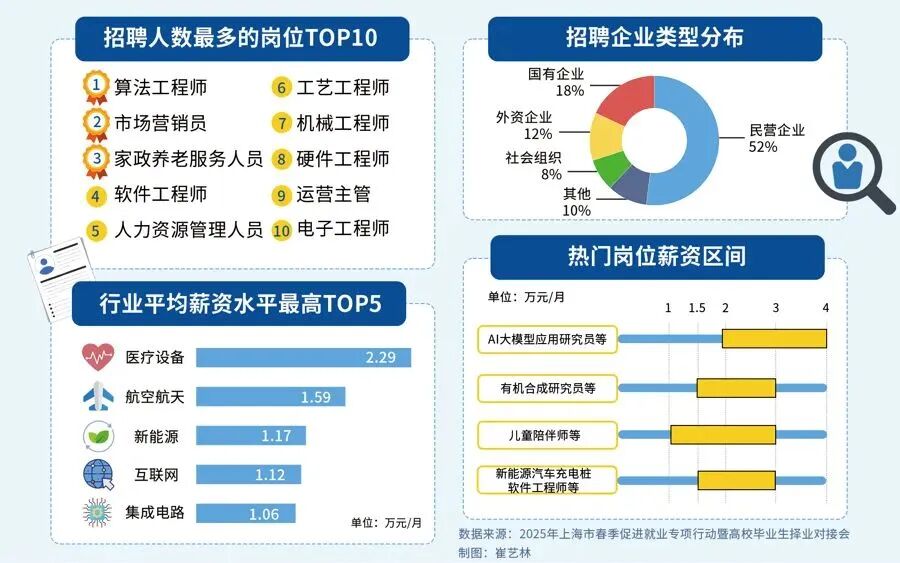
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献466条内容
已为社区贡献466条内容

所有评论(0)