【大模型】2026年大模型关键核心技术全景解析:从推理智能体到多模态原生架构
2026大模型关键核心技术:从推理智能体到多模态原生架构
2026年大模型关键核心技术全景解析
一、引言:大模型技术范式的根本性转移
2025-2026年,大语言模型(LLM)的发展路径发生了根本性转变:智能提升不再仅仅依赖训练阶段的参数扩展,而是更多地源于"思考"过程本身——即通过推理时的计算优化来实现。
这一转变标志着行业从"训练时扩展"(Training-time Scaling)向"测试时扩展"(Test-time Scaling)的范式迁移。
OpenAI的GPT-5、DeepSeek-R1、Anthropic的Claude 3.5 Sonnet等模型证明:让小模型在推理时"思考更久",其效果可超越大模型的快速回答。
二、推理能力革命:从"快思考"到"慢思考"
2.1 技术原理:RLVR与过程奖励模型
核心突破: 强化学习从"对齐人类偏好"(RLHF)演进为"提升内在推理能力"(RLVR, Reinforcement Learning with Verifiable Rewards)
架构:
传统RLHF:模型输出 → 人类打分 → 优化偏好(主观)
RLVR新范式:模型输出 → 自动验证(单元测试/数学证明)→ 优化正确性(客观)
关键组件:
| 组件 | 功能 | 代表实现 |
|---|---|---|
| PRM (Process Reward Model) | 过程奖励模型,对推理步骤打分 | OpenAI o1, DeepSeek-R1 |
| GRPO (Group Relative Policy Optimization) | 组相对策略优化,稳定训练 | DeepSeek-R1核心算法 |
| Self-play RL | 自我对弈生成合成数据 | Anthropic, AlphaProof |
2.2 领域技能矩阵
- 必备技能:
- 数学基础: 策略梯度、PPO、DPO、博弈论基础
- 工程实现: vLLM推理加速、Ray分布式训练、DeepSpeed ZeRO优化
- 验证器设计: 代码单元测试、数学定理证明、化学方程式配平
- 进阶能力:
- 设计过程监督信号:将复杂任务分解为可验证的子步骤
- 合成数据生成:通过Self-play产生高质量训练数据
- 推理成本优化:平衡推理深度与计算预算
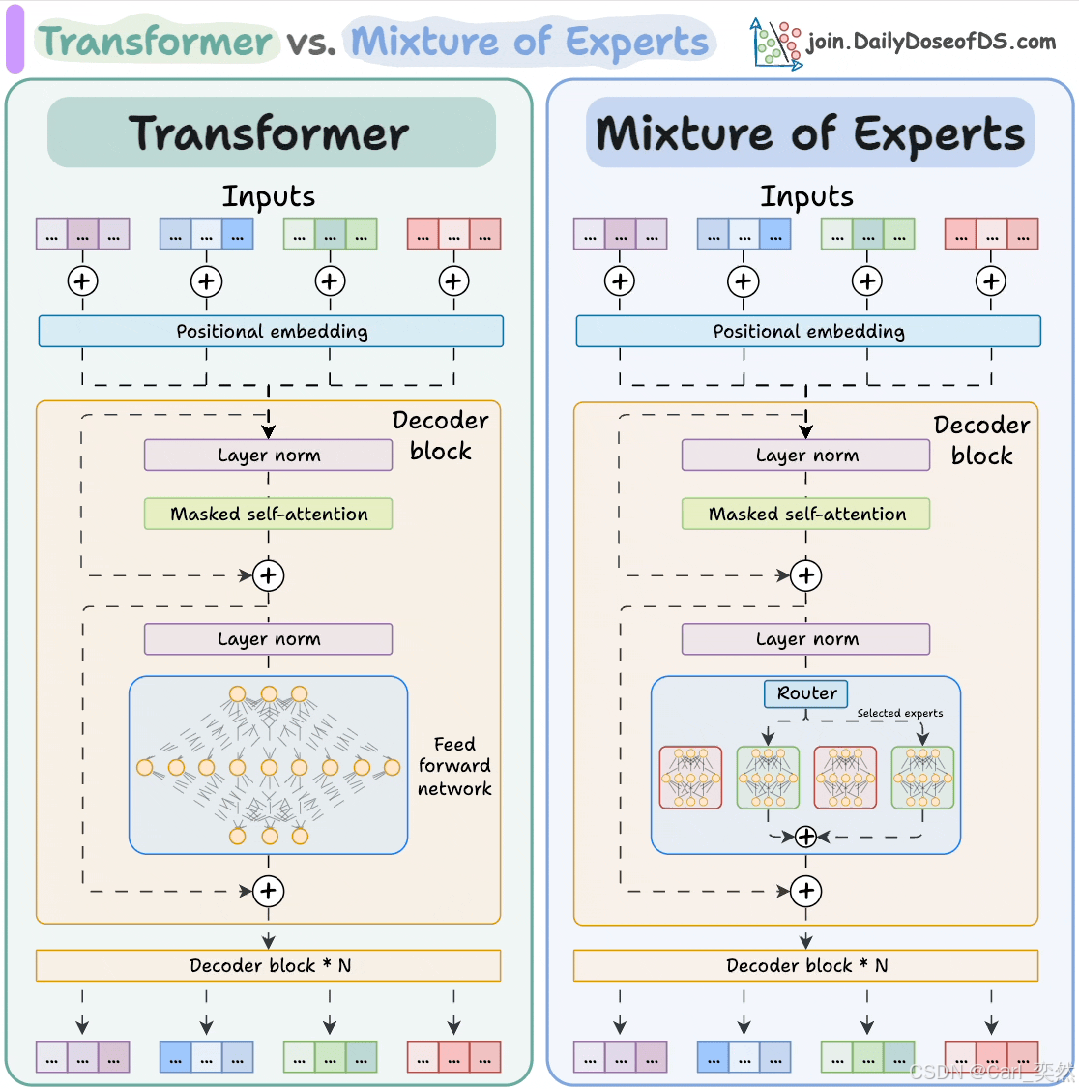
2.3 代码示例
2.3.1 GRPO算法核心逻辑
answers = model.generate(prompt, n=8) # 生成8个候选答案
scores = verify(answers) # 自动验证(精确匹配/单元测试)
best = max(scores)
loss = sum(best - s for s in scores) # 相对优势优化
2.3.2 GRPO算法完整代码
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM, AutoTokenizer
from typing import List, Tuple
class GRPOTrainer:
"""
Group Relative Policy Optimization (GRPO)
核心思想:生成一组答案,用相对优势而非绝对奖励来优化策略
"""
def __init__(
self,
model_name: str = "deepseek-ai/deepseek-llm-7b-base",
group_size: int = 8, # 每组生成8个候选答案
epsilon: float = 0.2, # PPO裁剪系数
beta: float = 0.01, # KL惩罚系数
):
self.policy_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
self.ref_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 冻结参考模型
for param in self.ref_model.parameters():
param.requires_grad = False
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.group_size = group_size
self.epsilon = epsilon
self.beta = beta
def generate_group_answers(self, prompt: str) -> List[str]:
"""生成一组候选答案"""
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.policy_model.device)
outputs = self.policy_model.generate(
**inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
num_return_sequences=self.group_size, # 关键:一次生成多个
pad_token_id=self.tokenizer.eos_token_id
)
# 解码,去掉prompt部分
answers = []
for output in outputs:
text = self.tokenizer.decode(output, skip_special_tokens=True)
answer = text[len(prompt):].strip()
answers.append(answer)
return answers
def verify_answer(self, answer: str, ground_truth: str) -> float:
"""
可验证奖励函数(Verifiable Reward)
数学问题:精确匹配
代码问题:单元测试通过
"""
# 示例:数学问题验证
try:
# 提取数字答案(简化版,实际需更鲁棒的解析)
pred = float(answer.split("####")[-1].strip())
true = float(ground_truth)
return 1.0 if abs(pred - true) < 1e-3 else 0.0
except:
return 0.0
def compute_grpo_loss(
self,
prompts: List[str],
ground_truths: List[str]
) -> torch.Tensor:
"""
GRPO核心损失函数
使用组内相对优势,而非绝对奖励
"""
total_loss = 0.0
for prompt, gt in zip(prompts, ground_truths):
# 1. 生成G个候选答案
answers = self.generate_group_answers(prompt)
# 2. 计算每个答案的奖励
rewards = [self.verify_answer(ans, gt) for ans in answers]
rewards_tensor = torch.tensor(rewards, dtype=torch.float32)
# 3. 计算组内相对优势(关键创新)
mean_reward = rewards_tensor.mean()
std_reward = rewards_tensor.std() + 1e-8
advantages = (rewards_tensor - mean_reward) / std_reward # 标准化优势
# 4. 计算每个答案的log概率
log_probs = []
ref_log_probs = []
for answer in answers:
full_text = prompt + answer
inputs = self.tokenizer(full_text, return_tensors="pt").to(self.policy_model.device)
with torch.no_grad():
# 参考模型概率(用于KL惩罚)
ref_outputs = self.ref_model(**inputs)
ref_logits = ref_outputs.logits[:, :-1, :]
ref_tokens = inputs.input_ids[:, 1:]
ref_log_prob = torch.nn.functional.log_softmax(ref_logits, dim=-1)
ref_log_prob = torch.gather(ref_log_prob, -1, ref_tokens.unsqueeze(-1)).squeeze(-1).mean()
ref_log_probs.append(ref_log_prob.item())
# 策略模型概率
outputs = self.policy_model(**inputs)
logits = outputs.logits[:, :-1, :]
tokens = inputs.input_ids[:, 1:]
log_prob = torch.nn.functional.log_softmax(logits, dim=-1)
log_prob = torch.gather(log_prob, -1, tokens.unsqueeze(-1)).squeeze(-1).mean()
log_probs.append(log_prob)
# 5. 计算PPO-clip损失
log_probs = torch.stack(log_probs)
ref_log_probs = torch.tensor(ref_log_probs)
# 重要性采样比率
ratios = torch.exp(log_probs - ref_log_probs.to(log_probs.device))
# PPO裁剪目标
surr1 = ratios * advantages.to(log_probs.device)
surr2 = torch.clamp(ratios, 1 - self.epsilon, 1 + self.epsilon) * advantages.to(log_probs.device)
policy_loss = -torch.min(surr1, surr2).mean()
# 6. KL散度惩罚(防止策略偏离太远)
kl_penalty = self.beta * (log_probs - ref_log_probs.to(log_probs.device)).mean()
total_loss += policy_loss + kl_penalty
return total_loss / len(prompts)
# 使用示例
trainer = GRPOTrainer(group_size=8)
# 训练数据:数学问题
train_data = [
{
"prompt": "问题:小明有15个苹果,给了小红6个,又买了8个,现在有几个?\n思考:",
"answer": "#### 17"
},
# ... 更多数据
]
# 训练循环
optimizer = torch.optim.AdamW(trainer.policy_model.parameters(), lr=1e-5)
for epoch in range(3):
loss = trainer.compute_grpo_loss(
[d["prompt"] for d in train_data],
[d["answer"] for d in train_data]
)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")
三、测试时计算(Test-Time Compute):小模型的"逆袭"
3.1 技术原理:计算最优的推理策略
-
核心洞察: 在FLOPs匹配的情况下,使用测试时计算扩展的小模型可以超越14倍更大的模型
-
四种核心技术
| 技术 | 方向 | 机制 | 适用场景 |
|---|---|---|---|
| Chain-of-Thought | 深度 | 生成详细推理步骤 | 数学、逻辑推理 |
| Self-Consistency | 宽度 | 采样多条路径,投票表决 | 开放式问答 |
| Tree-of-Thoughts | 搜索 | 维护推理树,启发式剪枝 | 规划、博弈 |
| Reflexion/Self-Refine | 迭代 | 根据反馈自我修正 | 代码调试、写作 |
- 计算最优策略(Compute-Optimal Scaling):
- 简单问题: 单路径快速回答(节省成本)
- 中等问题: 并行采样+投票(Self-Consistency)
- 复杂问题: 树搜索+过程奖励(Tree-of-Thoughts + PRM)
3.2 领域技能矩阵
- 系统架构能力:
- 推理引擎优化: vLLM的PagedAttention、Continuous Batching
- 投机解码(Speculative Decoding): 使用小模型草稿+大模型验证,提速2-3倍
- 动态批处理: 根据序列长度动态调整batch size
- 算法调优能力:
- 早停策略(Early Stopping): 当置信度达标时终止推理
- 自适应计算: 根据输入复杂度调整思考深度
- 缓存策略: 复用历史推理路径,避免重复计算
3.3 代码示例
3.3.1 自适应计算控制器
from enum import Enum
from typing import Callable, Optional
import numpy as np
class ComplexityLevel(Enum):
LOW = "low" # 直接回答
MEDIUM = "medium" # 多路采样投票
HIGH = "high" # 树搜索+PRM
class AdaptiveInferenceEngine:
"""
自适应推理引擎:根据问题难度动态选择计算策略
"""
def __init__(
self,
model, # 基础LLM
prm: Optional[ProcessRewardModel] = None,
complexity_threshold: dict = None
):
self.model = model
self.prm = prm
self.threshold = complexity_threshold or {
"low": 0.3, # 困惑度阈值
"medium": 0.7
}
def estimate_complexity(self, prompt: str) -> ComplexityLevel:
"""
估计问题复杂度
方法:使用基础模型的困惑度(perplexity)作为代理指标
"""
# 简化版:基于关键词和长度启发式判断
complexity_keywords = ["证明", "推导", "多步", "如果...那么", "假设"]
keyword_score = sum(1 for kw in complexity_keywords if kw in prompt) / len(complexity_keywords)
# 长度因子(长问题通常更复杂)
length_score = min(len(prompt) / 500, 1.0)
# 综合得分
complexity_score = 0.6 * keyword_score + 0.4 * length_score
if complexity_score < self.threshold["low"]:
return ComplexityLevel.LOW
elif complexity_score < self.threshold["medium"]:
return ComplexityLevel.MEDIUM
else:
return ComplexityLevel.HIGH
def fast_generate(self, prompt: str, max_tokens: int = 256) -> str:
"""快速生成:单路径,低温度"""
return self.model.generate(
prompt,
temperature=0.3, # 低温度,确定性输出
max_tokens=max_tokens,
num_samples=1
)[0]
def self_consistency(
self,
prompt: str,
n_paths: int = 5,
temperature: float = 0.7
) -> str:
"""
Self-Consistency:多路采样,多数投票
适用于中等复杂度问题
"""
# 生成多条路径
candidates = self.model.generate(
prompt,
temperature=temperature,
max_tokens=512,
num_samples=n_paths
)
# 提取最终答案(简化:最后数字或最后一行)
answers = [self._extract_answer(c) for c in candidates]
# 多数投票
from collections import Counter
vote_counts = Counter(answers)
best_answer = vote_counts.most_common(1)[0][0]
# 返回最一致的完整回答
for c in candidates:
if self._extract_answer(c) == best_answer:
return c
return candidates[0]
def tree_of_thoughts(
self,
prompt: str,
max_depth: int = 5,
branching_factor: int = 3,
beam_width: int = 2
) -> str:
"""
Tree-of-Thoughts:树搜索 + PRM评估
适用于高复杂度问题
"""
if not self.prm:
raise ValueError("Tree-of-Thoughts requires PRM")
# 初始化根节点
root = ThoughtNode(content=prompt, parent=None)
current_level = [root]
for depth in range(max_depth):
next_level = []
for node in current_level:
# 生成下一步思考
expansion_prompt = self._build_thought_prompt(node)
thoughts = self.model.generate(
expansion_prompt,
temperature=0.8,
max_tokens=128,
num_samples=branching_factor
)
for thought in thoughts:
child = ThoughtNode(content=thought, parent=node)
node.children.append(child)
next_level.append(child)
# 使用PRM评估所有节点,选择top-k
if next_level:
scores = []
for node in next_level:
# 构建完整路径
path = node.get_path()
score = self.prm.forward(prompt, path).mean().item()
scores.append(score)
# Beam Search:保留top beam_width个节点
top_indices = np.argsort(scores)[-beam_width:]
current_level = [next_level[i] for i in top_indices]
# 返回最佳路径的完整回答
best_leaf = max(current_level, key=lambda n: self.prm.forward(prompt, n.get_path()).mean())
return "\n".join(best_leaf.get_path())
def generate(self, prompt: str, max_budget: float = 1.0) -> dict:
"""
统一入口:根据复杂度自动选择策略
返回包含推理路径和成本的字典
"""
complexity = self.estimate_complexity(prompt)
result = {
"complexity": complexity.value,
"strategy": None,
"answer": None,
"cost": 0.0,
"reasoning_path": None
}
if complexity == ComplexityLevel.LOW:
result["strategy"] = "fast_generate"
result["answer"] = self.fast_generate(prompt)
result["cost"] = 0.1 * max_budget
elif complexity == ComplexityLevel.MEDIUM:
result["strategy"] = "self_consistency"
result["answer"] = self.self_consistency(prompt, n_paths=5)
result["cost"] = 0.5 * max_budget
else: # HIGH
result["strategy"] = "tree_of_thoughts"
result["answer"] = self.tree_of_thoughts(prompt)
result["cost"] = 0.9 * max_budget
return result
class ThoughtNode:
"""树搜索节点"""
def __init__(self, content: str, parent: Optional['ThoughtNode'] = None):
self.content = content
self.parent = parent
self.children = []
def get_path(self) -> List[str]:
"""获取从根到当前节点的路径"""
path = []
current = self
while current:
path.append(current.content)
current = current.parent
return list(reversed(path))
# 使用示例
engine = AdaptiveInferenceEngine(model=my_llm, prm=my_prm)
# 不同复杂度的问题
questions = [
"法国首都是哪里?", # LOW
"解方程:3x + 7 = 22", # MEDIUM
"证明:对于任意正整数n,n^3 - n能被6整除" # HIGH
]
for q in questions:
result = engine.generate(q)
print(f"问题: {q}")
print(f"复杂度: {result['complexity']}, 策略: {result['strategy']}")
print(f"答案: {result['answer'][:100]}...")
print("---")
3.3.2 投机解码(Speculative Decoding)
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
class SpeculativeDecoder:
"""
投机解码:用小模型(draft model)快速生成候选token,
用大模型(target model)并行验证,加速推理
"""
def __init__(
self,
target_model_name: str = "meta-llama/Llama-2-70b",
draft_model_name: str = "meta-llama/Llama-2-7b",
gamma: int = 4, # 每次推测的token数
):
# 大模型(慢但准确)
self.target_model = AutoModelForCausalLM.from_pretrained(
target_model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 小模型(快但质量较低)
self.draft_model = AutoModelForCausalLM.from_pretrained(
draft_model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
self.tokenizer = AutoTokenizer.from_pretrained(target_model_name)
self.gamma = gamma # 推测窗口大小
def generate(
self,
prompt: str,
max_new_tokens: int = 100,
temperature: float = 0.7
) -> str:
"""
投机解码生成
"""
input_ids = self.tokenizer.encode(prompt, return_tensors="pt").to(self.target_model.device)
accepted_tokens = 0
draft_tokens = 0
for _ in range(max_new_tokens // self.gamma):
# 1. 小模型快速生成gamma个候选token
draft_outputs = self.draft_model.generate(
input_ids,
max_new_tokens=self.gamma,
do_sample=True,
temperature=temperature,
return_dict_in_generate=True,
output_scores=True
)
draft_sequence = draft_outputs.sequences[0] # 包含输入的完整序列
draft_new_tokens = draft_sequence[len(input_ids[0]):] # 新生成的部分
# 2. 大模型并行验证(一次前向传播)
with torch.no_grad():
target_outputs = self.target_model(draft_sequence.unsqueeze(0))
target_logits = target_outputs.logits[0, len(input_ids[0])-1:-1] # 对应draft位置的logits
target_probs = torch.softmax(target_logits / temperature, dim=-1)
# 3. 接受/拒绝采样
accepted = []
for i, draft_token in enumerate(draft_new_tokens):
draft_tokens += 1
# 获取小模型该位置的概率分布
draft_prob = torch.softmax(draft_outputs.scores[i] / temperature, dim=-1)
# 计算接受概率:min(1, p_target / p_draft)
token_accept_prob = torch.min(
torch.tensor(1.0),
target_probs[i, draft_token] / draft_prob[0, draft_token]
)
if torch.rand(1).item() < token_accept_prob:
# 接受该token
accepted.append(draft_token.item())
accepted_tokens += 1
else:
# 拒绝:从调整后的分布中采样
adjusted_prob = target_probs[i] - draft_prob[0]
adjusted_prob = torch.clamp(adjusted_prob, min=0)
adjusted_prob = adjusted_prob / adjusted_prob.sum()
new_token = torch.multinomial(adjusted_prob, 1).item()
accepted.append(new_token)
break # 拒绝后停止本轮推测
# 4. 更新输入序列
new_tokens_tensor = torch.tensor([accepted]).to(input_ids.device)
input_ids = torch.cat([input_ids, new_tokens_tensor], dim=1)
# 检查是否生成结束符
if self.tokenizer.eos_token_id in accepted:
break
# 计算接受率
accept_rate = accepted_tokens / draft_tokens if draft_tokens > 0 else 0
print(f"投机解码接受率: {accept_rate:.2%}")
return self.tokenizer.decode(input_ids[0], skip_special_tokens=True)
# 性能对比
def benchmark():
decoder = SpeculativeDecoder()
prompt = "人工智能的发展历史可以追溯到"
import time
# 标准解码
start = time.time()
standard_output = decoder.target_model.generate(
decoder.tokenizer.encode(prompt, return_tensors="pt").to(decoder.target_model.device),
max_new_tokens=100,
do_sample=True,
temperature=0.7
)
standard_time = time.time() - start
# 投机解码
start = time.time()
speculative_output = decoder.generate(prompt, max_new_tokens=100)
speculative_time = time.time() - start
print(f"标准解码时间: {standard_time:.2f}s")
print(f"投机解码时间: {speculative_time:.2f}s")
print(f"加速比: {standard_time / speculative_time:.2f}x")
# benchmark()
四、自主智能体(Agentic AI):从"对话"到"行动"
4.1 技术原理:OODA循环与长期记忆
-
核心定义: 具备环境感知、自主决策、长期记忆、工具调用能力的AI实体,遵循OODA循环(观察-定向-决策-行动)。
-
2026年关键突破:长期自主性:
- 记忆机制: 上下文窗口扩展+向量数据库+记忆压缩算法
- 持续工作: 支持数周级任务连贯性,保持目标不偏离
- 自进化能力: 通过强化学习和用户反馈自动优化,月均性能提升15%
-
架构组件:
┌─────────────────────────────────────────┐
│ 规划引擎(Planning) │
│ - 目标分解:将复杂任务拆分为子任务 │
│ - 动态重规划:根据环境反馈调整策略 │
├─────────────────────────────────────────┤
│ 记忆管理(Memory) │
│ - 短期记忆:Context窗口(128K+ tokens) │
│ - 长期记忆:向量数据库(Milvus/Pinecone) │
│ - 情景记忆:时间戳+重要性评分 │
├─────────────────────────────────────────┤
│ 工具调用(Tools) │
│ - MCP协议:标准化工具接口 │
│ - 函数调用:API、数据库、代码执行 │
├─────────────────────────────────────────┤
│ 反思机制(Reflection) │
│ - ReAct:推理-行动循环 │
│ - 自我批评:评估行动结果,生成改进策略 │
└─────────────────────────────────────────┘
4.2 领域技能矩阵
- 核心技术栈:
- 开发框架: LangChain、LlamaIndex、AutoGPT、MetaGPT
- 记忆数据库: Milvus、Pinecone、Weaviate、Redis
- 工具协议: MCP(Model Context Protocol)、Function Calling
- 多Agent协作: 消息总线、角色分工、冲突解决机制
- 系统设计能力:
- 容错设计: Agent失败时的回退策略(Fallback)
- 安全沙箱: 代码执行隔离、权限控制、审计日志
- 人机协同: 关键决策点的人工确认机制(Human-in-the-loop)
4.3 代码示例
4.3.1 ReAct智能体实现
import json
import re
from typing import List, Dict, Callable, Optional
from dataclasses import dataclass
@dataclass
class Action:
name: str
input: str
observation: Optional[str] = None
class ReActAgent:
"""
ReAct (Reasoning + Acting) 智能体
交替进行思考(Thought)和行动(Action),直到完成任务
"""
def __init__(
self,
llm, # 基础语言模型
tools: Dict[str, Callable],
max_iterations: int = 10
):
self.llm = llm
self.tools = tools # 可用工具字典 {工具名: 函数}
self.max_iterations = max_iterations
self.scratchpad = [] # 思考轨迹
def _build_prompt(self, task: str) -> str:
"""构建ReAct格式的prompt"""
tool_descriptions = "\n".join([
f"{name}: {func.__doc__}"
for name, func in self.tools.items()
])
prompt = f"""解决以下任务,通过交替进行思考和行动。
可用工具:
{tool_descriptions}
任务:{task}
思考轨迹:
"""
# 添加历史思考
for item in self.scratchpad:
prompt += f"\n{item}\n"
prompt += "\n思考:"
return prompt
def _parse_action(self, text: str) -> Optional[Action]:
"""从模型输出解析行动"""
# 匹配格式:行动[工具名, 输入]
action_pattern = r"行动\[(.*?),\s*(.*?)\]"
match = re.search(action_pattern, text)
if match:
tool_name = match.group(1).strip()
tool_input = match.group(2).strip().strip('"\'')
return Action(name=tool_name, input=tool_input)
return None
def _parse_thought(self, text: str) -> str:
"""提取思考部分"""
lines = text.split("\n")
thought_lines = []
for line in lines:
if line.startswith("思考:"):
thought_lines.append(line[3:].strip())
elif "行动[" in line:
break
elif thought_lines:
thought_lines.append(line.strip())
return " ".join(thought_lines)
def run(self, task: str) -> str:
"""执行ReAct循环"""
for i in range(self.max_iterations):
# 1. 构建当前prompt
prompt = self._build_prompt(task)
# 2. LLM生成下一步
response = self.llm.generate(prompt, max_tokens=200, temperature=0.7)
text = response[0] if isinstance(response, list) else response
# 3. 解析思考
thought = self._parse_thought(text)
self.scratchpad.append(f"思考:{thought}")
# 4. 解析行动
action = self._parse_action(text)
if not action:
# 没有行动,可能是最终答案
if "答案:" in text or "完成" in text:
return text
continue
# 5. 执行工具
if action.name not in self.tools:
observation = f"错误:未知工具 '{action.name}'"
else:
try:
tool_func = self.tools[action.name]
observation = tool_func(action.input)
except Exception as e:
observation = f"错误:{str(e)}"
action.observation = observation
self.scratchpad.append(f"行动[{action.name}, {action.input}]")
self.scratchpad.append(f"观察:{observation}")
# 6. 检查是否完成
if "完成" in observation or "成功" in observation:
final_prompt = self._build_prompt(task) + "\n思考:基于以上观察,给出最终答案。\n答案:"
final_answer = self.llm.generate(final_prompt, max_tokens=200)
return final_answer[0] if isinstance(final_answer, list) else final_answer
return "达到最大迭代次数,任务未完成。"
# 工具函数定义
def search(query: str) -> str:
"""搜索互联网获取信息"""
# 实际实现应调用搜索引擎API
mock_results = {
"法国首都": "法国首都是巴黎。",
"Python": "Python是一种高级编程语言。",
"2026年AI趋势": "2026年AI趋势包括推理时计算、智能体、多模态模型。"
}
return mock_results.get(query, f"搜索结果:关于'{query}'的信息")
def calculator(expression: str) -> str:
"""计算数学表达式"""
try:
# 安全计算:只允许基本运算符
allowed_chars = set("0123456789+-*/(). ")
if all(c in allowed_chars for c in expression):
result = eval(expression)
return f"计算结果:{result}"
return "错误:表达式包含非法字符"
except Exception as e:
return f"计算错误:{str(e)}"
def get_weather(city: str) -> str:
"""获取城市天气"""
mock_weather = {
"北京": "晴天,25°C",
"上海": "多云,28°C",
"巴黎": "小雨,18°C"
}
return f"{city}天气:{mock_weather.get(city, '未知')}"
# 使用示例
tools = {
"搜索": search,
"计算": calculator,
"天气": get_weather
}
agent = ReActAgent(llm=my_llm, tools=tools)
# 执行任务
task = "法国首都的气温是多少?如果温度超过20度,计算25乘以这个温度值。"
result = agent.run(task)
print(result)
# 预期思考轨迹:
# 思考:我需要先知道法国首都,然后查天气,最后根据温度决定是否计算。
# 行动[搜索, 法国首都]
# 观察:法国首都是巴黎。
# 思考:现在我知道首都是巴黎,需要查询巴黎的天气。
# 行动[天气, 巴黎]
# 观察:巴黎天气:小雨,18°C
# 思考:温度是18度,没有超过20度,不需要计算。任务完成。
# 答案:法国首都巴黎的气温是18°C,未超过20度,无需计算。
4.3.2 多智能体风格
from enum import Enum
from typing import List, Dict, Optional
import asyncio
class Role(Enum):
PRODUCT_MANAGER = "产品经理"
ARCHITECT = "架构师"
ENGINEER = "工程师"
QA = "测试工程师"
class Message:
"""Agent间通信消息"""
def __init__(
self,
content: str,
sender: str,
receiver: Optional[str] = None,
msg_type: str = "text"
):
self.content = content
self.sender = sender
self.receiver = receiver # None表示广播
self.msg_type = msg_type # text/code/requirement/test
class Agent:
"""基础智能体类"""
def __init__(self, name: str, role: Role, llm, tools: List = None):
self.name = name
self.role = role
self.llm = llm
self.tools = tools or []
self.memory = [] # 消息历史
self.inbox = asyncio.Queue() # 消息收件箱
async def receive(self, msg: Message):
"""接收消息"""
await self.inbox.put(msg)
self.memory.append(msg)
async def think(self) -> str:
"""基于记忆生成思考"""
# 构建上下文
context = "\n".join([
f"{m.sender}: {m.content}"
for m in self.memory[-10:] # 最近10条
])
system_prompt = f"""你是{self.role.value},名为{self.name}。
你的职责:{self._get_role_prompt()}
当前对话:
{context}
请根据你的角色和上下文,生成下一步行动或回复:"""
response = self.llm.generate(system_prompt, max_tokens=500)
return response[0] if isinstance(response, list) else response
def _get_role_prompt(self) -> str:
"""获取角色特定的系统提示"""
prompts = {
Role.PRODUCT_MANAGER: "分析需求,编写PRD,明确功能点",
Role.ARCHITECT: "设计系统架构,选择技术栈,定义接口",
Role.ENGINEER: "编写代码实现功能,修复bug",
Role.QA: "编写测试用例,执行测试,报告问题"
}
return prompts.get(self.role, "协助完成任务")
async def act(self, thought: str) -> List[Message]:
"""根据思考生成行动(发送消息)"""
# 解析thought,决定发送给谁
messages = []
# 简单启发式:根据关键词决定接收者
if "需求" in thought or "PRD" in thought:
messages.append(Message(thought, self.name, "架构师", "requirement"))
elif "架构" in thought or "设计" in thought:
messages.append(Message(thought, self.name, "工程师", "design"))
elif "代码" in thought or "实现" in thought:
messages.append(Message(thought, self.name, "测试工程师", "code"))
elif "测试" in thought or "bug" in thought:
messages.append(Message(thought, self.name, "工程师", "test"))
else:
# 广播
messages.append(Message(thought, self.name, None, "text"))
return messages
async def run(self):
"""Agent主循环"""
while True:
# 检查收件箱
if not self.inbox.empty():
msg = await self.inbox.get()
print(f"[{self.name}] 收到来自 {msg.sender} 的消息: {msg.content[:50]}...")
# 思考
thought = await self.think()
print(f"[{self.name}] 思考: {thought[:50]}...")
# 行动
messages = await self.act(thought)
yield messages
else:
await asyncio.sleep(0.1)
class MultiAgentSystem:
"""多智能体协作系统"""
def __init__(self):
self.agents: Dict[str, Agent] = {}
self.message_bus = asyncio.Queue() # 全局消息总线
def register_agent(self, agent: Agent):
"""注册Agent"""
self.agents[agent.name] = agent
async def dispatch(self, msg: Message):
"""消息分发"""
if msg.receiver:
# 点对点
if msg.receiver in self.agents:
await self.agents[msg.receiver].receive(msg)
else:
# 广播给所有Agent(除发送者)
for name, agent in self.agents.items():
if name != msg.sender:
await agent.receive(msg)
async def run_workflow(self, initial_task: str, max_rounds: int = 20):
"""运行工作流"""
# 初始任务发给产品经理
initial_msg = Message(initial_task, "用户", "产品经理", "requirement")
await self.agents["产品经理"].receive(initial_msg)
# 启动所有Agent
agent_tasks = [
asyncio.create_task(self._agent_loop(name))
for name in self.agents.keys()
]
# 运行消息总线
for _ in range(max_rounds):
if not self.message_bus.empty():
msg = await self.message_bus.get()
await self.dispatch(msg)
await asyncio.sleep(0.1)
# 取消Agent任务
for task in agent_tasks:
task.cancel()
async def _agent_loop(self, agent_name: str):
"""单个Agent的消息循环"""
agent = self.agents[agent_name]
async for messages in agent.run():
for msg in messages:
await self.message_bus.put(msg)
# 使用示例:软件开发团队
async def main():
# 创建Agent
pm = Agent("产品经理Alice", Role.PRODUCT_MANAGER, llm=my_llm)
architect = Agent("架构师Bob", Role.ARCHITECT, llm=my_llm)
engineer = Agent("工程师Carol", Role.ENGINEER, llm=my_llm)
qa = Agent("测试工程师David", Role.QA, llm=my_llm)
# 创建系统
system = MultiAgentSystem()
system.register_agent(pm)
system.register_agent(architect)
system.register_agent(engineer)
system.register_agent(qa)
# 运行任务
task = "开发一个用户登录系统,支持邮箱验证和第三方登录"
await system.run_workflow(task, max_rounds=50)
# asyncio.run(main())
5、总结
评价一个 Agent 的标准,不再是它有多聪明,而是它掌握了多少技能,以及它能否自我扩展技能库。
未来的 Agent 开发者,将从编写 Prompt 转向编写 Skill Definition 和 Workflow Graph。我们正在见证软件工程从“面向对象编程”向“面向意图编程”的深刻变革。
下一篇,我们会详细聊一聊2026爆火的Skill。
我是小鱼:
- CSDN 博客专家;
- AIGC MVP技术专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【机器视觉与目标检测】 和【人工智能与大模型】最新最全的领域知识。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)