爱芯-瑞芯微工具链对比
本文介绍了三款AI芯片(AX630C、AX650N、RK1126BP)的关键参数和上市时间,重点说明了不同芯片的模型编译流程、量化方式和性能特点。其中AX630C支持W8A16量化,RK1126BP支持W4A16量化,RK182X支持多种量化配置。文章还分析了上下文长度对模型大小的影响,比较了不同芯片在小模型和大模型上的数据类型支持差异,并提供了估算大语言模型首个令牌生成时间的方法参考。
目录
|
芯片型号 |
官网算力 |
上市时间 |
|
AX630C |
最大12.8TOPs@INT4 或3.2TOPs@INT8 |
2023年10月27日 |
|
AX650N |
最大72.0TOPs@INT4 或18.0TOPs@INT8 |
2023年3月 |
|
RK1126BP |
3TOPS |
2025年6月 |
使用流程
爱芯
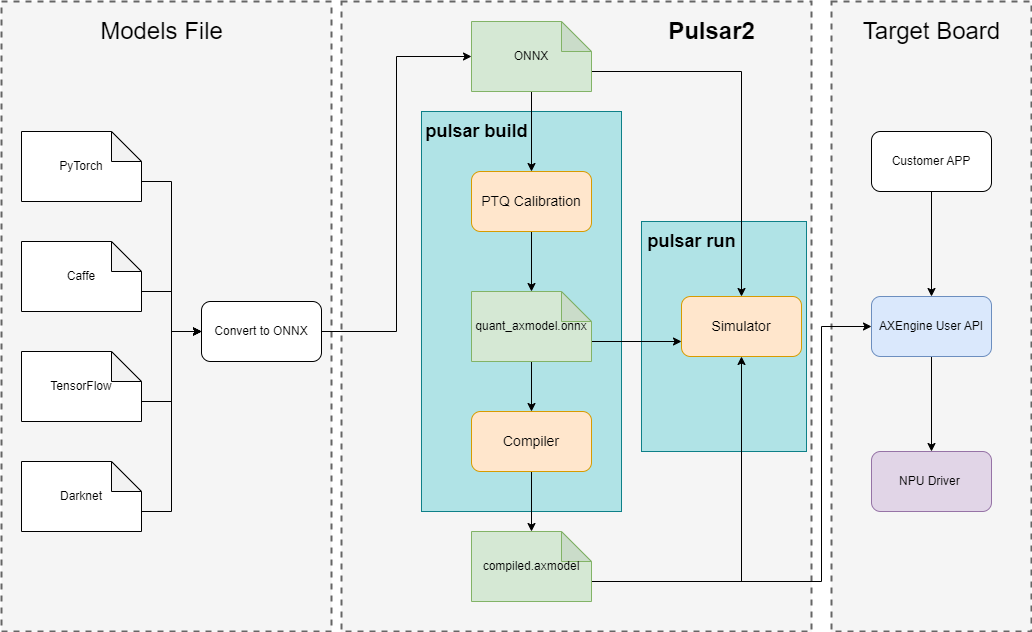
pulsar2 build: 编译传统小模型命令行
pulsar2 llm_build: 编译语言模型命令行
瑞芯微
工具链:rknn2+rkllm
芯片:RK1126BP
rknn2 支持传统视觉模型
rkllm 支持语言模型
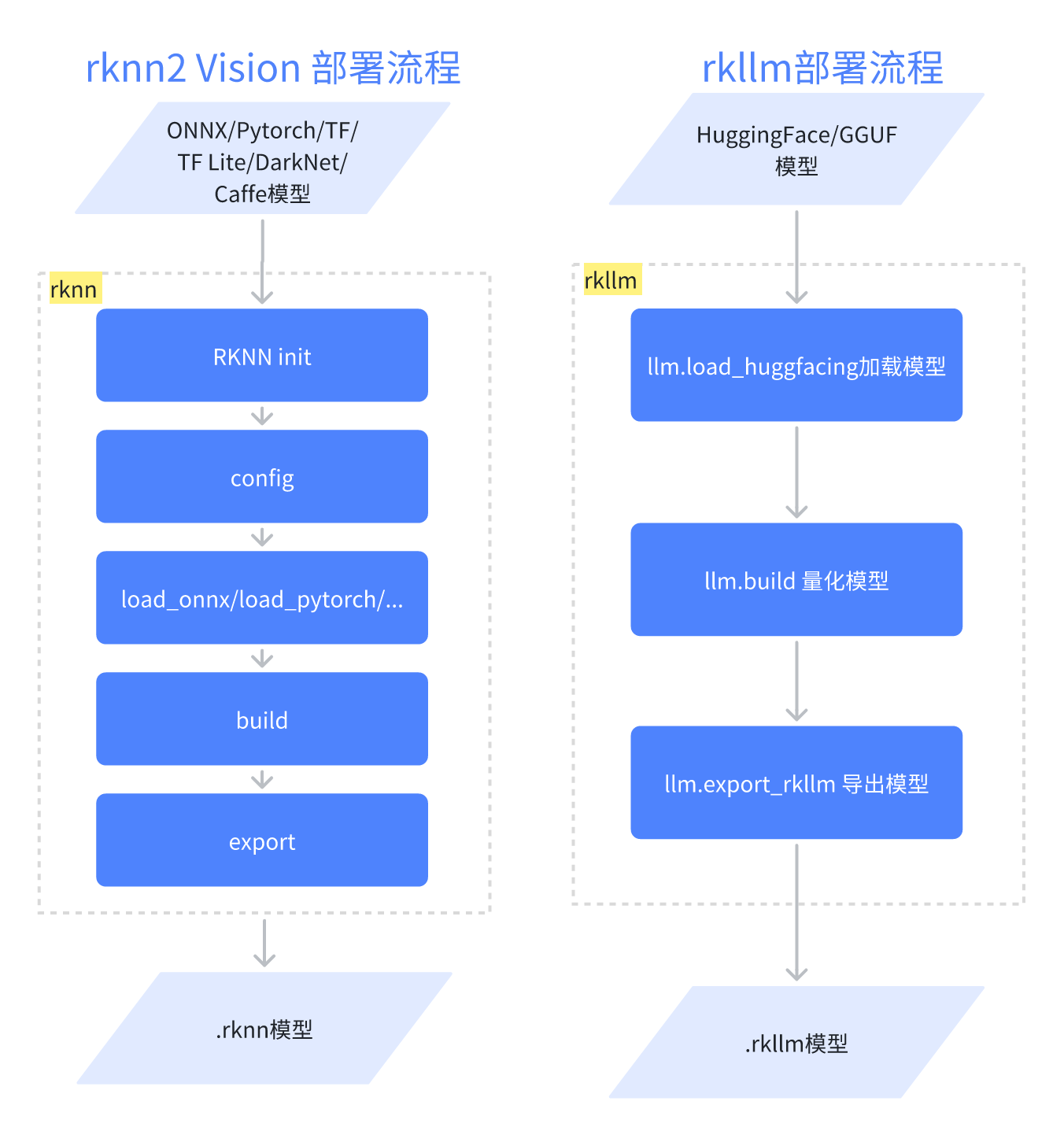
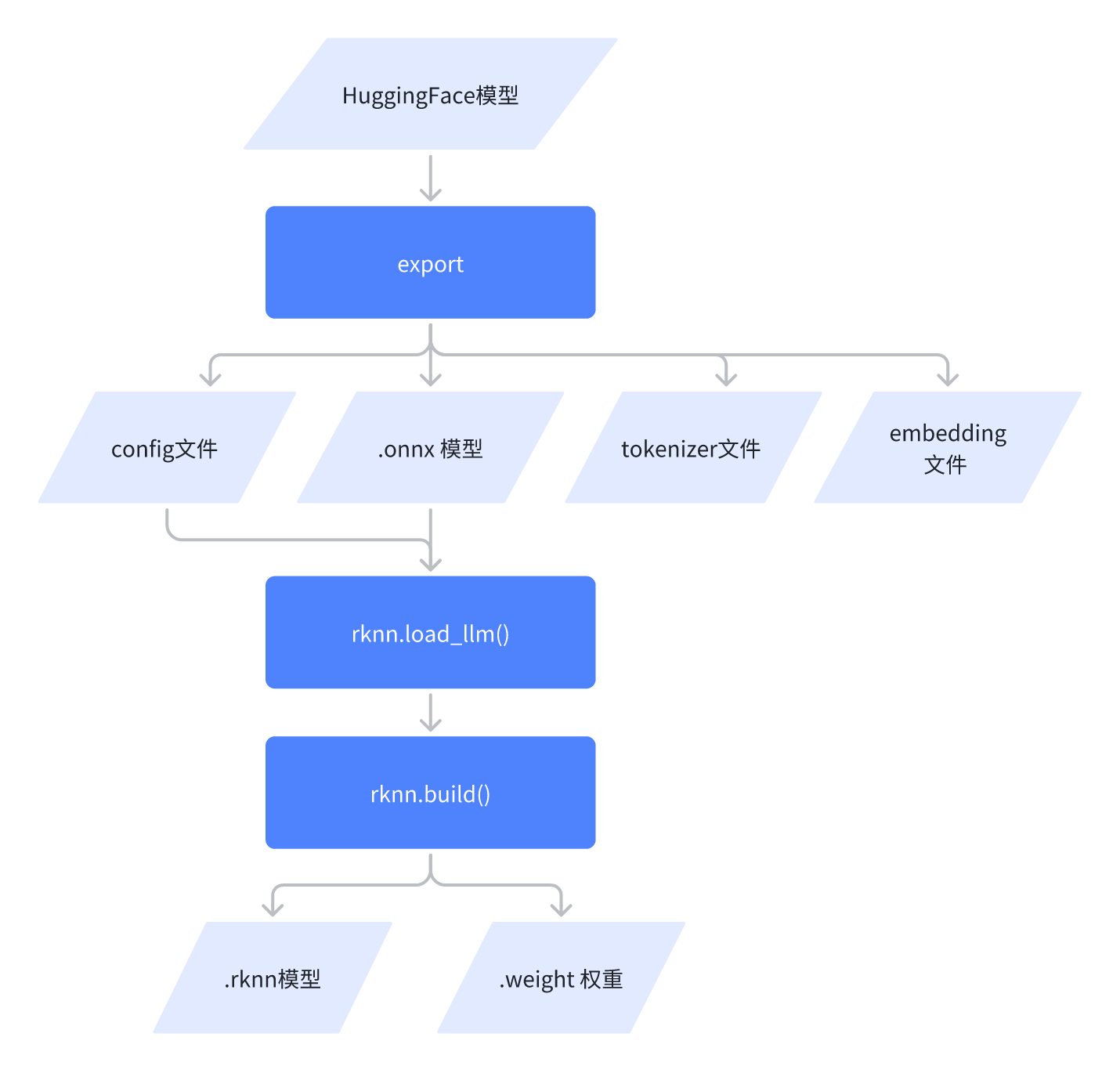
工具链:rknn3
芯片:RK1820/RK1828


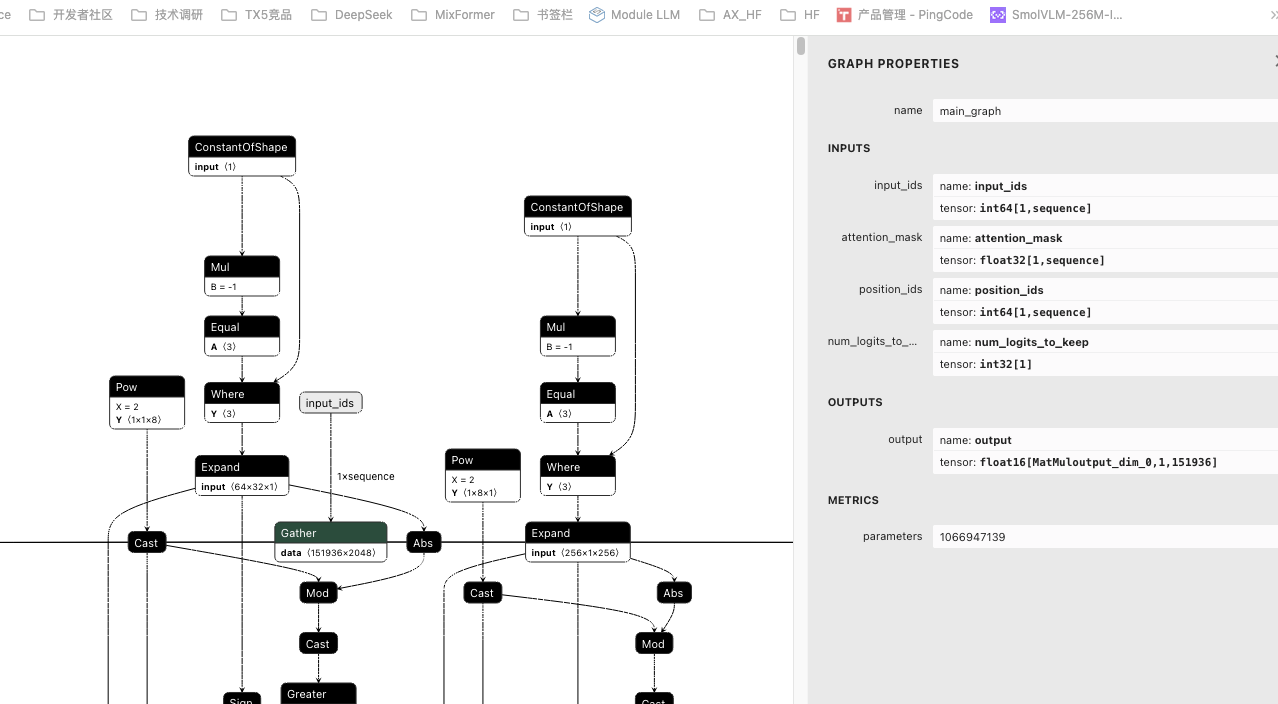
Qwen2.5-3B-Instruct 导出的onnx 模型结构
量化编译后LLM模型
以Qwen3-0.6B 举例
|
编译后模型大小(MB) |
量化方式 |
max-context |
|
|
AX630C |
724.6 |
W8A16 |
1024 |
|
RK1126BP |
702.7 |
W4A16 |
2048 |
|
RK182X |
411.2(不包含embedding) |
W4A16(g32) |
1024 |
预处理、Embedding、Head层
|
embedding运行 |
Embedding 是否量化 |
LLM Head是否支持量化 |
Tokenizer 解析器运行 |
|
|
AX630C |
板端Host运行 |
不量化 |
支持配置 |
HTTP Server |
|
RK1126BP |
板端 flash 中 |
支持量化 |
量化 |
demo示例中没有使用分词器 |
|
RK182X协处理器 |
主控SOC和板端均可 |
支持量化 |
支持配置 |
主控SOC |
上下文长度影响(现象)
|
是否影响编译模型 |
说明 |
|
|
AX630C |
影响 |
kv_cache_len参数越大模型越大 |
|
RK1126BP |
影响 |
max_context: 上下文长度的上限值, 该值越大模型越大 |
|
RK182X协处理器 |
无影响 |
max_ctx_len,指定 Kvcache 最⼤⻓度,影响模型⻓⽂本下的推理结果以及 kvcache 的内存占⽤。 |
爱芯指定不同的last_kv_cache_len 模型显示如下
系统将预填充长度上限划分为1、128、256、384、512等不同档位(grp)。
例如,一个长度为300Token的提示词,会被分配到“上限为384”的组里进行批量计算。

数据类型
|
模型类型 |
AX630C |
RK1126BP |
备注 |
|
小模型 |
U8 S 8 U16 S16 FP32:部分层支持 |
w8a8:权重为8bit非对称量化精度,激活为8bit非对称量化精度 w4a16:权重为4bit非对称量化,激活为16bit浮点精度 float16:全浮点 |
|
|
大模型 |
w4a16 w8a16 |
w4a16, w4a16_g32, w4a16_g64, w4a16_g128 w8a8 float16:全浮点 |
爱芯 hidden_state_type: fp16,bf16,fp32 weight: fp16,bf16,fp32,s8,s4,fp8_e5m2,fp8_e4m3 |

参考链接

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)