掌握技能开发:Skill用工具制造工具的艺术
前言
在 AI 辅助开发的时代,技能(Skill)已经成为扩展 AI 能力的重要方式。虽然 Trae 提供了技能的使用功能,但本文将介绍如何使用anthropics的skill-creator 来创建自定义技能,然后从 Trae 中导入并使用这些技能。一句话概括就是:用工具制造工具。
本文将以 markdown_to_word 技能为例,详细介绍如何使用 skill-creator 创建、测试和优化技能,帮助你快速掌握"用工具制造工具"的全过程。
一、什么是 skill-creator?如何使用?
1.1 skill-creator 简介
根据官方文档,skill-creator 是 Anthropics 开源的一个专门用于创建新技能、修改和改进现有技能,以及衡量技能性能的核心技能。它的主要功能包括:
- 创建新技能:从无到有构建完整的技能
- 修改和改进现有技能:基于反馈迭代优化技能
- 测试技能:运行评估以测试技能性能
- 基准测试:通过方差分析衡量技能性能
- 优化技能描述:提高技能触发的准确性
skill-creator 的核心价值在于提供了一套完整的工作流程,从技能设计、测试到优化的全生命周期管理,帮助开发者构建高质量的技能,实现"用工具制造工具"的目标。
1.2 skill-creator 的使用流程
根据官方文档,使用 skill-creator 创建技能的标准流程如下:
- 明确技能目标:决定你希望技能做什么以及它应该如何实现
- 编写技能草案:创建技能的初始版本
- 设计测试用例:创建几个测试提示并在带有该技能的 Claude 上运行它们
- 评估结果:帮助用户从定性和定量两个方面评估结果
- 在运行测试的同时,起草定量评估标准
- 使用
eval-viewer/generate_review.py脚本向用户展示结果
- 优化技能:根据用户的评估反馈重写技能
- 重复迭代:直到你和用户满意为止
- 扩展测试:扩大测试集并在更大范围内尝试
- 导入到 Trae:将创建好的技能导入到 Trae 中使用
在这里有个很重要的点,导入到Trae,我们主打的是工具制造工具,既然,我们有了一个能制造工具的工具–skill-creator,那就要用起来,
1.2.1 Traec导入skill-creator
切换到Trae的SOLO模式(当然,好像不切也可而已,习惯了而已):
至于创建项目,怎么下载trae这些就不交待了,点击设置项: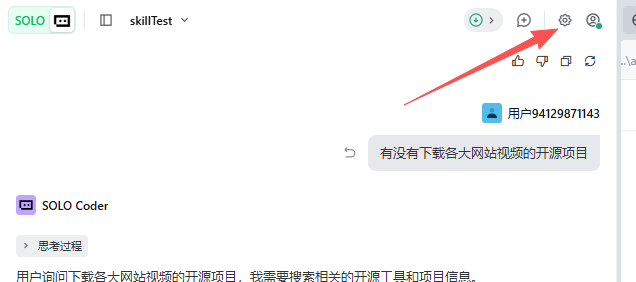
找到规则和技能,在技能这个栏目中选择创建,这样你就掌握了创建技能的第一步: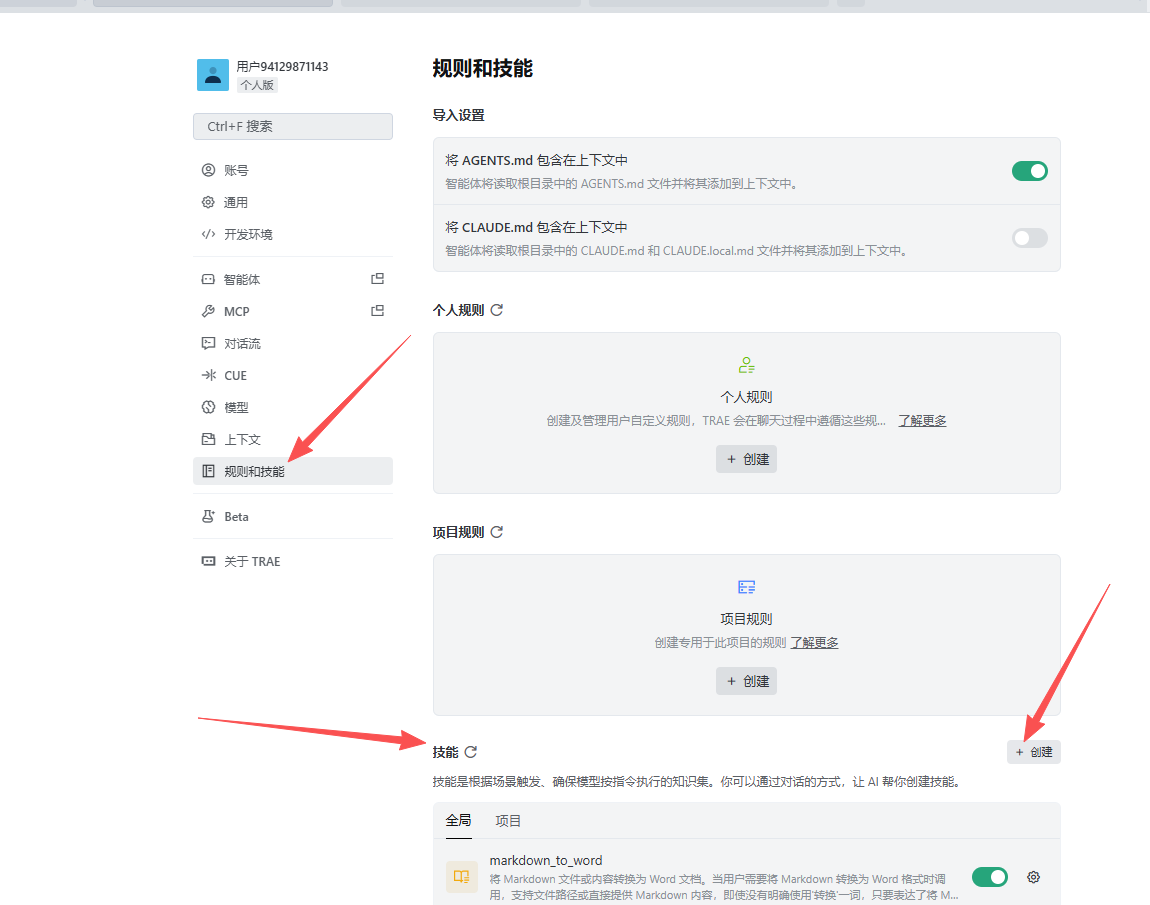
在打开创建技能的页面中,选择上传进行智能解析,选择我们下载下来的skill-creator的SKILL.MD,因为skill-creator已经是一个别人提供的技能了,就不需要自己按照创建技能的规则自己写了:
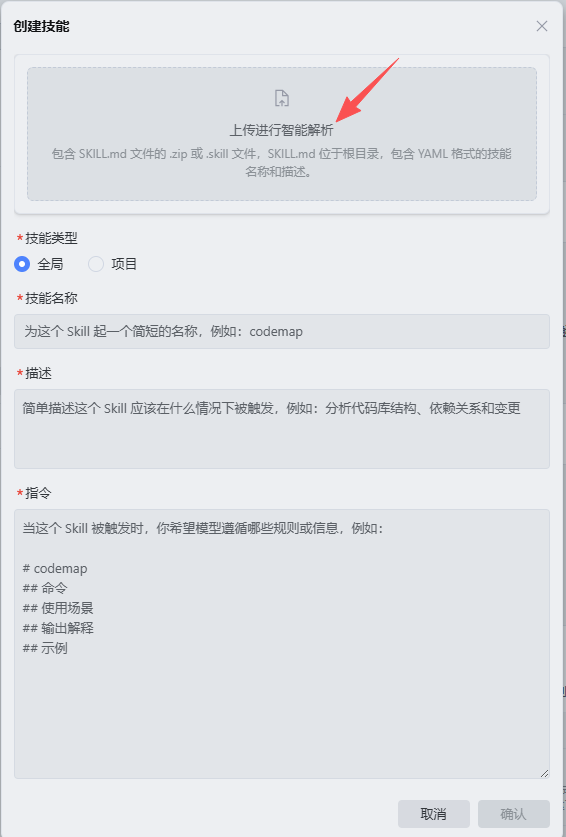
这样就可以拥有一个自己的skill-creator了: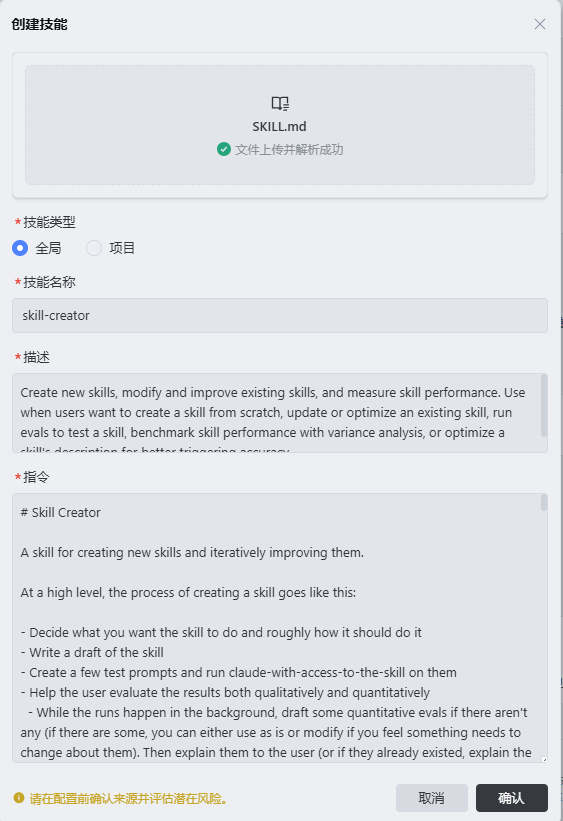
这里,技能的类型最好是使用全局。
现在就可以用了一个能制造技能的工具了。
二、如何使用 skill-creator 创建 Skill?
2.1 技能的基本结构
一个标准的技能目录结构如下:
skill-name/
├── SKILL.md (必需)
│ ├── YAML 前置元数据 (name, description 必需)
│ └── Markdown 说明文档
└── 捆绑资源 (可选)
├── scripts/ - 用于确定性/重复性任务的可执行代码
├── references/ - 必要时加载到上下文的文档
└── assets/ - 输出中使用的文件 (模板、图标、字体)
2.2 创建技能的步骤
- 确定技能名称和描述:在 SKILL.md 的 YAML 前置部分定义
- 编写技能逻辑:在 SKILL.md 主体部分详细描述技能的执行逻辑
- 添加必要的脚本:在 scripts 目录中添加可执行脚本
- 添加参考文档:在 references 目录中添加相关文档
- 测试技能:使用 skill-creator 运行测试用例
- 优化技能:根据测试结果进行迭代优化
- 打包技能:将技能打包为 .skill 文件
- 导入到 Trae:在 Trae 中导入并使用该技能
2.3 技能的加载机制
技能使用三级加载系统:
- 元数据(名称 + 描述)- 始终在上下文中(约 100 字)
- SKILL.md 主体 - 技能触发时在上下文中(理想情况下少于 500 行)
- 捆绑资源 - 根据需要加载(无限制,脚本可以在不加载的情况下执行)
2.4 工具制造工具
上面2.1到2.3,是技能的一些基本知识,你可以遵循这些知识和规则自己写技能,但是你有了skill-creator,就不需要这么麻烦啦,回到你的SOLO模式,在AI对话框里,写入一段话: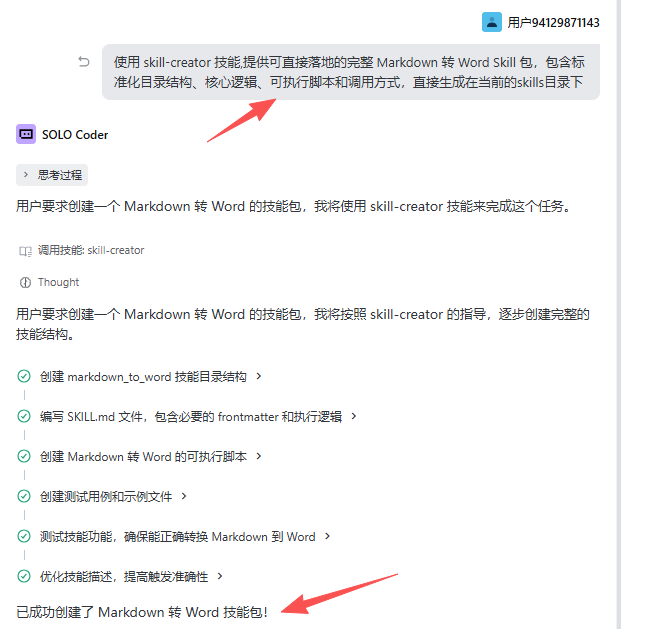
这样,一个使用工具制造工具的过程就完成了,那么在你当前目录下,就有了一个markdown_to_word技能: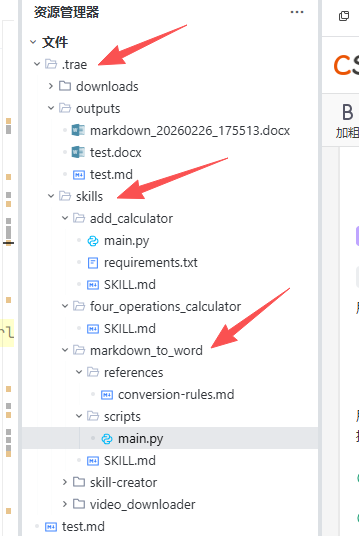
你可以测试一下,在AI对话框里输入:
转换这个markdown文件:F:\work\MCP\skillTest\.trae\outputs\test.md
那么Trae就会自动去使用技能进行转换了: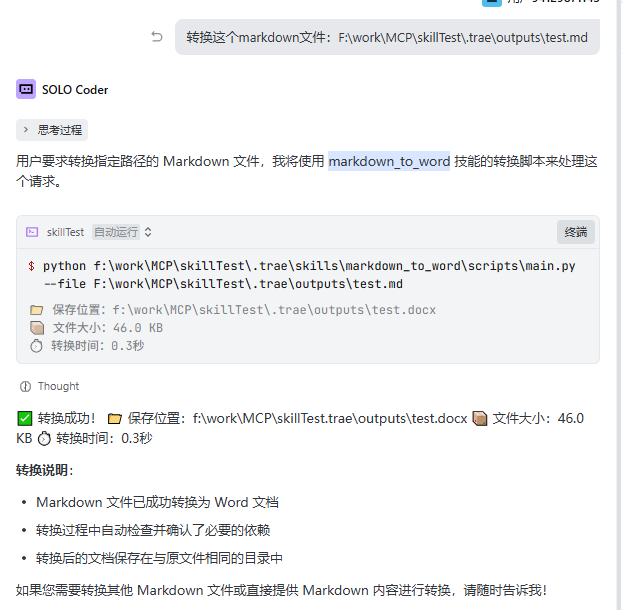
当然这里只是最初的一个版本,如果你发现转换的结果不满意,比如格式,表格等还没完全转换好,还可以继续进行优化,比如我这里第一次转换的结果就有个格式问题,你就可以继续完善markdown_to_word技能了。
三、实战案例解析:markdown_to_word 技能
按照惯例,这里还是需要对markdown_to_word 技能做一个全面的解析,这里包含了所有的技能生成的所有内容。当然,这些都是AI帮忙做的,但是还是的从Skill的创建过程来解析。
3.1 技能需求分析
我们需要创建一个将 Markdown 文件或内容转换为 Word 文档的技能,支持基本的 Markdown 语法和格式转换,然后将其导入到 Trae 中使用。
3.2 技能实现步骤
步骤 1:创建技能目录结构
首先,我们创建 markdown_to_word 技能的目录结构:
markdown_to_word/
├── SKILL.md
├── scripts/
│ └── main.py
└── references/
└── conversion-rules.md
步骤 2:编写 SKILL.md 文件
在 SKILL.md 文件中,我们定义技能的元数据、触发条件、执行逻辑等:
---
name: "markdown_to_word"
description: "将 Markdown 文件或内容转换为 Word 文档。当用户需要将 Markdown 转换为 Word 格式时调用,支持文件路径或直接提供 Markdown 内容,即使没有明确使用'转换'一词,只要表达了将 Markdown 转为 Word 的意图也应该触发此技能。"
---
# Markdown 转 Word 工具 (markdown_to_word)
## 用途
将 Markdown 文件或内容转换为 Word 文档,支持基本的 Markdown 语法和格式转换。
## 触发条件
- 用户需要将 Markdown 转换为 Word 格式
- 关键词:Markdown 转 Word、转换 Markdown 为 Word、md 转 docx
## 执行逻辑
1. **参数校验**:检查用户输入是否包含 Markdown 文件路径或 Markdown 内容
2. **依赖检查**:确保必要的依赖已安装,若未安装则自动安装
3. **转换配置**:设置转换参数,包括输出路径、样式等
4. **执行转换**:调用转换脚本将 Markdown 转换为 Word
5. **结果返回**:返回转换结果和文件保存位置
## 输入格式
用户可以提供以下两种输入方式:
1. **Markdown 文件路径**:例如 `f:\path\to\file.md`
2. **直接提供 Markdown 内容**:将 Markdown 内容直接粘贴
## 输出格式
✅ 转换成功!
📁 保存位置:[文件路径]
📦 文件大小:[文件大小]
⏱️ 转换时间:[转换时间]
## 示例
### 输入示例 1(文件路径)
- 转换这个 Markdown 文件:f:\work\example.md
- 把 f:\docs\report.md 转换为 Word
### 输入示例 2(直接提供内容)
- 把以下 Markdown 转换为 Word:
markdown
# 测试文档
## 章节 1
这是一段测试文本。
## 章节 2
- 列表项 1
- 列表项 2
### 输出示例
✅ 转换成功!
📁 保存位置:f:\work\MCP\skillTest\.trae\outputs\example.docx
📦 文件大小:25.6 KB
⏱️ 转换时间:2.3秒
## 技术实现
1. 使用 Python 脚本调用 `markdown` 和 `python-docx` 库进行转换
2. 支持自动安装必要的依赖(如果未安装)
3. 提供友好的错误处理和进度反馈
4. 自动执行转换规则,确保 Markdown 格式正确映射到 Word 格式
## 转换规则参考
详细的格式映射和常见错误解决方案请参考 `references/conversion-rules.md` 文件。转换过程中会自动执行这些规则,确保 Markdown 元素正确映射到对应的 Word 格式。
## 支持的 Markdown 语法
- 标题(#、##、### 等)
- 段落
- 列表(有序和无序)
- 粗体和斜体
- 链接
- 图片
- 代码块
- 引用
- 表格
## 可能的问题和解决方案
- **依赖安装失败**:检查网络连接,或手动安装必要的依赖
- **转换失败**:检查 Markdown 语法是否正确,或尝试使用不同的转换参数
- **样式问题**:可以尝试调整转换参数或使用自定义样式模板
- **图片不显示**:确保图片路径是绝对路径
- **编码错误**:使用 UTF-8 编码保存 Markdown 文件
## 优化建议
- **自定义样式**:支持用户提供自定义 Word 样式模板
- **批量转换**:支持多个 Markdown 文件的批量转换
- **格式保留**:进一步优化 Markdown 格式到 Word 格式的转换质量
- **导出选项**:支持更多导出选项,如页面设置、页眉页脚等
步骤 3:编写核心转换脚本
在 scripts/main.py 文件中,我们实现了核心的 Markdown 转 Word 功能:
#!/usr/bin/env python3
# Markdown 转 Word 脚本
import argparse
import subprocess
import os
import sys
import time
import re
from datetime import datetime
# 检查并安装依赖
def check_dependencies():
"""检查并安装必要的依赖"""
required_packages = ['markdown', 'python-docx']
for package in required_packages:
try:
__import__(package)
except ImportError:
print(f"❌ {package} 未安装,正在自动安装...")
try:
subprocess.run([sys.executable, '-m', 'pip', 'install', package], check=True)
print(f"✅ {package} 安装成功!")
except subprocess.CalledProcessError:
print(f"❌ {package} 安装失败,请手动安装后重试。")
return False
return True
# 处理 Markdown 格式的文本
def process_markdown_text(text):
"""处理 Markdown 格式的文本,转换为 Word 可识别的格式"""
# 处理粗体 **text**
text = re.sub(r'\*\*(.*?)\*\*', r'\1', text)
# 处理斜体 *text*
text = re.sub(r'\*(.*?)\*', r'\1', text)
# 处理链接 [text](url)
text = re.sub(r'\[(.*?)\]\((.*?)\)', r'\1', text)
# 处理行内代码 `code`
text = re.sub(r'`(.*?)`', r'\1', text)
return text
# 检测是否是 Markdown 表格行
def is_table_line(line):
"""检测是否是 Markdown 表格行"""
# 表格分隔线
if re.match(r'^\|?-+\|?-+\|?', line):
return True
# 表格数据行
if '|' in line:
return True
return False
# 解析 Markdown 表格
def parse_table(lines):
"""解析 Markdown 表格"""
table_data = []
for line in lines:
line = line.strip()
if not line:
continue
# 跳过分隔线
if re.match(r'^\|?-+\|?-+\|?', line):
continue
# 解析表格行
cells = [cell.strip() for cell in line.strip('|').split('|')]
table_data.append(cells)
return table_data
# 转换 Markdown 文件
def convert_markdown_file(file_path, output_dir):
"""转换 Markdown 文件为 Word 文档"""
from markdown import markdown
from docx import Document
start_time = time.time()
try:
# 读取 Markdown 文件
with open(file_path, 'r', encoding='utf-8') as f:
md_content = f.read()
# 创建 Word 文档
doc = Document()
# 处理 Markdown 内容
lines = md_content.split('\n')
in_code_block = False
in_table = False
table_lines = []
for line in lines:
line = line.rstrip() # 只去除右侧空白,保留左侧缩进
if not line:
# 检查是否在表格中
if in_table:
# 表格结束
in_table = False
# 解析并创建表格
table_data = parse_table(table_lines)
if table_data:
# 创建 Word 表格
rows = len(table_data)
cols = len(table_data[0]) if rows > 0 else 0
if cols > 0:
table = doc.add_table(rows=rows, cols=cols)
# 填充表格数据
for i, row_data in enumerate(table_data):
for j, cell_data in enumerate(row_data):
if j < cols: # 确保不超出列数
cell_text = process_markdown_text(cell_data)
table.cell(i, j).text = cell_text
# 清空表格行
table_lines = []
doc.add_paragraph()
continue
# 检查是否在代码块中
if line.startswith('```'):
# 检查是否在表格中
if in_table:
in_table = False
# 解析并创建表格
table_data = parse_table(table_lines)
if table_data:
# 创建 Word 表格
rows = len(table_data)
cols = len(table_data[0]) if rows > 0 else 0
if cols > 0:
table = doc.add_table(rows=rows, cols=cols)
# 填充表格数据
for i, row_data in enumerate(table_data):
for j, cell_data in enumerate(row_data):
if j < cols: # 确保不超出列数
cell_text = process_markdown_text(cell_data)
table.cell(i, j).text = cell_text
# 清空表格行
table_lines = []
in_code_block = not in_code_block
continue
if in_code_block:
# 代码块内容
para = doc.add_paragraph()
run = para.add_run(line)
# 可以设置代码块的样式,例如等宽字体
continue
# 检查是否是表格行
if is_table_line(line):
if not in_table:
in_table = True
table_lines.append(line)
continue
# 如果之前在表格中,现在不是表格行,说明表格结束
if in_table:
in_table = False
# 解析并创建表格
table_data = parse_table(table_lines)
if table_data:
# 创建 Word 表格
rows = len(table_data)
cols = len(table_data[0]) if rows > 0 else 0
if cols > 0:
table = doc.add_table(rows=rows, cols=cols)
# 填充表格数据
for i, row_data in enumerate(table_data):
for j, cell_data in enumerate(row_data):
if j < cols: # 确保不超出列数
cell_text = process_markdown_text(cell_data)
table.cell(i, j).text = cell_text
# 清空表格行
table_lines = []
# 处理标题
if line.startswith('# '):
# 一级标题
text = process_markdown_text(line[2:])
doc.add_heading(text, level=1)
elif line.startswith('## '):
# 二级标题
text = process_markdown_text(line[3:])
doc.add_heading(text, level=2)
elif line.startswith('### '):
# 三级标题
text = process_markdown_text(line[4:])
doc.add_heading(text, level=3)
elif line.startswith('#### '):
# 四级标题
text = process_markdown_text(line[5:])
doc.add_heading(text, level=4)
elif line.startswith('- '):
# 无序列表
text = process_markdown_text(line[2:])
doc.add_paragraph(text, style='List Bullet')
elif line.startswith('1. '):
# 有序列表
text = process_markdown_text(line[3:])
doc.add_paragraph(text, style='List Number')
elif line.startswith('> '):
# 引用
text = process_markdown_text(line[2:])
doc.add_paragraph(text, style='Quote')
else:
# 普通段落
text = process_markdown_text(line)
doc.add_paragraph(text)
# 处理最后可能的表格
if in_table and table_lines:
table_data = parse_table(table_lines)
if table_data:
# 创建 Word 表格
rows = len(table_data)
cols = len(table_data[0]) if rows > 0 else 0
if cols > 0:
table = doc.add_table(rows=rows, cols=cols)
# 填充表格数据
for i, row_data in enumerate(table_data):
for j, cell_data in enumerate(row_data):
if j < cols: # 确保不超出列数
cell_text = process_markdown_text(cell_data)
table.cell(i, j).text = cell_text
# 生成输出文件名
base_name = os.path.splitext(os.path.basename(file_path))[0]
output_file = os.path.join(output_dir, f"{base_name}.docx")
# 处理文件已存在或权限被拒绝的情况
counter = 1
while True:
try:
# 保存 Word 文档
doc.save(output_file)
break
except PermissionError:
# 文件被占用,生成新的文件名
output_file = os.path.join(output_dir, f"{base_name}_{counter}.docx")
counter += 1
except Exception as e:
# 其他错误
raise e
end_time = time.time()
# 计算文件大小
file_size = os.path.getsize(output_file) / 1024 # 转换为 KB
conversion_time = round(end_time - start_time, 1)
# 输出结果
print(f"✅ 转换成功!")
print(f"📁 保存位置:{output_file}")
print(f"📦 文件大小:{file_size:.1f} KB")
print(f"⏱️ 转换时间:{conversion_time}秒")
return True
except Exception as e:
print(f"❌ 转换失败:{e}")
return False
# 主函数
def main():
# 解析命令行参数
parser = argparse.ArgumentParser(description='Markdown 转 Word 工具')
parser.add_argument('--file', type=str, help='Markdown 文件路径')
parser.add_argument('--content', type=str, help='Markdown 内容')
parser.add_argument('--input', type=str, help='输入文本,包含文件路径或 Markdown 内容')
args = parser.parse_args()
# 检查依赖
if not check_dependencies():
return
# 创建输出目录
output_dir = create_output_dir()
# 处理输入
if args.file:
# 从文件路径转换
convert_markdown_file(args.file, output_dir)
elif args.content:
# 从直接提供的内容转换
convert_markdown_content(args.content, output_dir)
elif args.input:
# 从输入文本中提取文件路径或使用内容
file_path = extract_file_path(args.input)
if file_path and os.path.exists(file_path):
# 从文件路径转换
convert_markdown_file(file_path, output_dir)
else:
# 假设输入是 Markdown 内容
convert_markdown_content(args.input, output_dir)
else:
print("❌ 错误:未提供有效的输入")
return
if __name__ == '__main__':
main()
这个代码里面包含了表格以及一些格式的处理。
步骤 4:创建转换规则参考文件
在 references/conversion-rules.md 文件中,我们添加了详细的格式映射和异常处理规则:
# Markdown 转 Word 转换规则
## 格式映射表
| Markdown 元素 | Word 格式 |
|--------------|----------|
| `# Heading 1` | 标题 1 样式 |
| `## Heading 2` | 标题 2 样式 |
| `### Heading 3` | 标题 3 样式 |
| `#### Heading 4` | 标题 4 样式 |
| `**bold**` | 粗体文本 |
| `*italic*` | 斜体文本 |
| `[text](url)` | 纯文本(保留文本内容,去除链接格式) |
| `` `code` `` | 纯文本(保留代码内容,去除代码格式) |
| `- 列表项` | 无序列表 |
| `1. 列表项` | 有序列表 |
| `> 引用` | 引用样式 |
| 表格 | Word 表格 |
| 代码块 | 普通段落(保留代码内容) |
## 常见错误解决方案
### 1. 依赖安装失败
- **错误信息**:`markdown` 或 `python-docx` 安装失败
- **解决方案**:检查网络连接,或手动安装必要的依赖:
pip install markdown python-docx
### 2. 转换失败
- **错误信息**:`转换失败:[具体错误信息]`
- **解决方案**:
- 检查 Markdown 语法是否正确
- 确保文件路径正确且文件存在
- 检查文件编码是否为 UTF-8
### 3. 样式问题
- **错误信息**:转换后的 Word 文档样式不符合预期
- **解决方案**:
- 确保 Markdown 语法正确
- 检查是否使用了支持的 Markdown 元素
### 4. 图片不显示
- **错误信息**:转换后的 Word 文档中图片不显示
- **解决方案**:确保图片路径是绝对路径,或使用网络图片 URL
### 5. 编码错误
- **错误信息**:`UnicodeDecodeError` 或类似编码错误
- **解决方案**:使用 UTF-8 编码保存 Markdown 文件
## 转换注意事项
1. **格式转换**:部分 Markdown 特有格式可能无法完全转换为 Word 格式,会被转换为纯文本
2. **表格处理**:Markdown 表格会被转换为 Word 表格,但复杂的表格样式可能会丢失
3. **代码块**:代码块会被转换为普通段落,代码格式可能会丢失
4. **图片处理**:目前仅支持基本的图片引用,复杂的图片处理可能需要手动调整
5. **性能考虑**:对于大型 Markdown 文件,转换可能需要较长时间
## 优化建议
1. **使用标准 Markdown 语法**:避免使用过于复杂或非标准的 Markdown 语法
2. **合理组织文档结构**:使用清晰的标题层级和列表结构
3. **表格设计**:保持表格结构简单,避免复杂的合并单元格操作
4. **图片管理**:使用适当大小的图片,并确保路径正确
5. **定期保存**:对于大型文档,建议定期保存中间版本
3.3 遇到的问题及解决方案
在开发 markdown_to_word 技能的过程中,我们遇到了以下问题:
问题 1:转换后保留 Markdown 格式标记
症状:转换后的 Word 文档中仍保留 **bold**、*italic* 等 Markdown 格式标记。
解决方案:
- 添加
process_markdown_text()函数,使用正则表达式去除 Markdown 格式标记 - 对粗体、斜体、链接、行内代码等格式进行处理
问题 2:表格转换不正确
症状:转换后的 Word 文档中表格仍保留 Markdown 表格的分隔线和格式。
解决方案:
- 实现
is_table_line()函数,检测 Markdown 表格行 - 实现
parse_table()函数,解析 Markdown 表格数据 - 在转换过程中,将解析后的表格数据创建为 Word 表格
问题 3:文件权限被拒绝
症状:保存 Word 文件时提示权限不足或文件被占用。
解决方案:
- 修改脚本,当检测到权限错误时自动生成带计数器的新文件名
- 添加异常处理,确保转换过程不会因文件权限问题而失败
3.4 最终优化结果
经过多次迭代优化,我们的 markdown_to_word 技能最终实现了以下功能:
- 支持多种输入方式:可以从文件路径或直接提供的内容进行转换
- 自动处理依赖:检测并自动安装必要的依赖包
- 完整的格式支持:支持标题、列表、粗体、斜体、引用、表格等 Markdown 元素
- 智能表格转换:将 Markdown 表格正确转换为 Word 表格
- 友好的错误处理:提供清晰的错误信息和解决方案
- 优化的用户体验:提供详细的转换结果信息,包括文件大小和转换时间
四、总结与建议
4.1 技能开发的关键要点
- 明确技能目标:在开始开发前,清晰定义技能的功能和使用场景
- 遵循标准结构:按照技能的标准目录结构组织文件
- 编写清晰的文档:在 SKILL.md 中详细描述技能的执行逻辑和使用方法
- 实现稳健的代码:添加错误处理和边界情况的处理
- 持续测试优化:通过测试用例验证技能的有效性,并根据反馈进行优化
- 关注用户体验:提供清晰的输入输出格式和友好的错误提示
- 正确导入使用:确保技能能够正确打包并导入到 Trae 中使用
4.2 后续优化方向
对于 markdown_to_word 技能,我们可以考虑以下优化方向:
- 自定义样式:支持用户提供自定义 Word 样式模板
- 批量转换:支持多个 Markdown 文件的批量转换
- 格式保留:进一步优化 Markdown 格式到 Word 格式的转换质量
- 导出选项:支持更多导出选项,如页面设置、页眉页脚等
- 图片处理:增强图片处理能力,支持更多图片格式和布局选项
4.3 "用工具制造工具"的最佳实践
- 模块化设计:将复杂功能分解为可重用的模块
- 文档驱动开发:先编写文档,再实现功能
- 测试驱动开发:通过测试用例验证功能的正确性
- 持续集成:定期运行测试,确保技能的稳定性
- 用户反馈:收集用户反馈,持续改进技能
- 生态系统思维:考虑技能之间的协作和集成
五、延伸思考
- 如何将 markdown_to_word 技能扩展为支持更多格式的转换工具?
- 如何利用 skill-creator 创建一套完整的技能生态系统?
- 如何设计技能之间的协作机制,让多个技能可以协同工作?
通过本文的学习,你应该已经掌握了使用 skill-creator 创建技能并在 Trae 中使用的基本方法。希望你能将这些知识应用到实际项目中,开发出更多实用的技能,充分发挥"用工具制造工具"的威力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)