打破桎梏!MinerU-HTML重构网页提取范式,开源超大规模高质量多语言语料AICC
摘要:上海AI实验室OpenDataLab团队提出新一代网页提取工具MinerU-HTML,通过两阶段语义感知方法解决传统HTML提取的局限性。该工具首先用0.6B参数模型标注正文节点,再精细处理代码、公式等结构化元素,最终输出Markdown格式。基于此构建的AICC语料库(7.3万亿tokens)在多项测试中超越RefinedWeb等现有语料,尤其在通用知识和阅读理解任务上表现突出。实验证明高
导言:
数据质量是决定大模型能力的关键因素之一。大规模预训练语料库(如Common Crawl)主要依赖于网页数据。然而,长期以来,相关研究将优化重心放在下游的过滤和去重策略上,对HTML提取这一重要工作却未引起足够重视。
传统网页提取方法基于启发式规则,面对万亿规模网页数据难以优化和迭代。近期推出的基于模型的内容抽取方法无法高质量还原代码、公式等重要信息。
为此,上海人工智能实验室(上海AI实验室)OpenDataLab 团队提出了一个“将内容提取任务重构为一个序列标注问题"的方法,据此研发了能够进行语义感知的新一代网页提取工具—— MinerU-HTML。该工具采用两阶段提取方法,第一阶段利用模型从HTML DOM中标注出正文节点,第二阶段对正文节点结合HTML语法进行精细识别(特别是代码和公式),转换为结构化数据供下游使用。
与此同时,OpenDataLab 开源了用该工具构建的高质量语料AICC(AI-ready Common Crawl),建立了行业新标杆。该方法及工具后续可广泛应用于DeepResearch搭建、RAG构建、网页采集与解析等场景。
-
AICC 数据集 HuggingFace链接:https://huggingface.co/datasets/opendatalab/AICC
相较于基于传统启发式规则研发的网页提取工具,MinerU-HTML可以适应多样布局的网页提取。基于 MinerU-HTML 的提取能力,团队开源了规模达 7.3 万亿 tokens 的 AICC 多语言语料库,为学术界及产业界提供了高质量的大模型预训练数据基础。
一、AICC语料库超越现有高质量语料库,建立新标杆
OpenDataLab 团队在包含7,887个标注网页的MainWebBench基准测试集上进行了评估,结果表明:MinerU-HTML在综合指标和结构化元素保留方面均建立了行业领先性能(SOTA)。而采用MinerU-HTML构建的AICC语料库,在下游任务中超越了RefinedWeb和FineWeb等公认的高质量语料库,这直接证明了高质量提取可以媲美甚至超越激进过滤策略带来的效益。不仅如此,AICC还在通用知识(General Knowledge)和阅读理解(Reading Comprehension)任务上均取得了最佳性能。
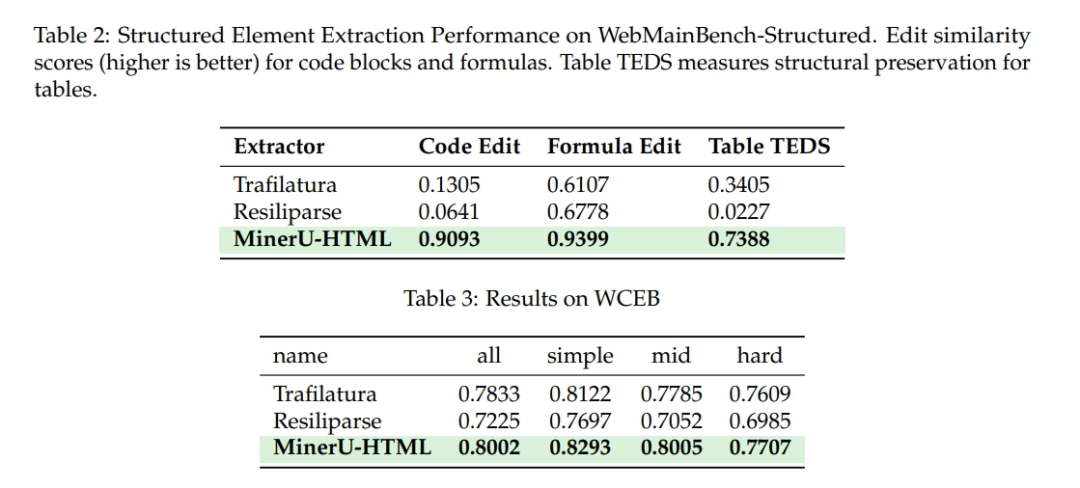
图为技术报告中结构化元素提取器的性能对比。 上方表格展示了不同提取器在 WebMainBench-Structured 基准上的代码块(Code Edit)、公式(Formula Edit)和表格(Table TEDS)的相似度得分。下方表格展示了它们在 WCEB 基准上的准确率。MinerU-HTML 在所有测试中均表现最佳。
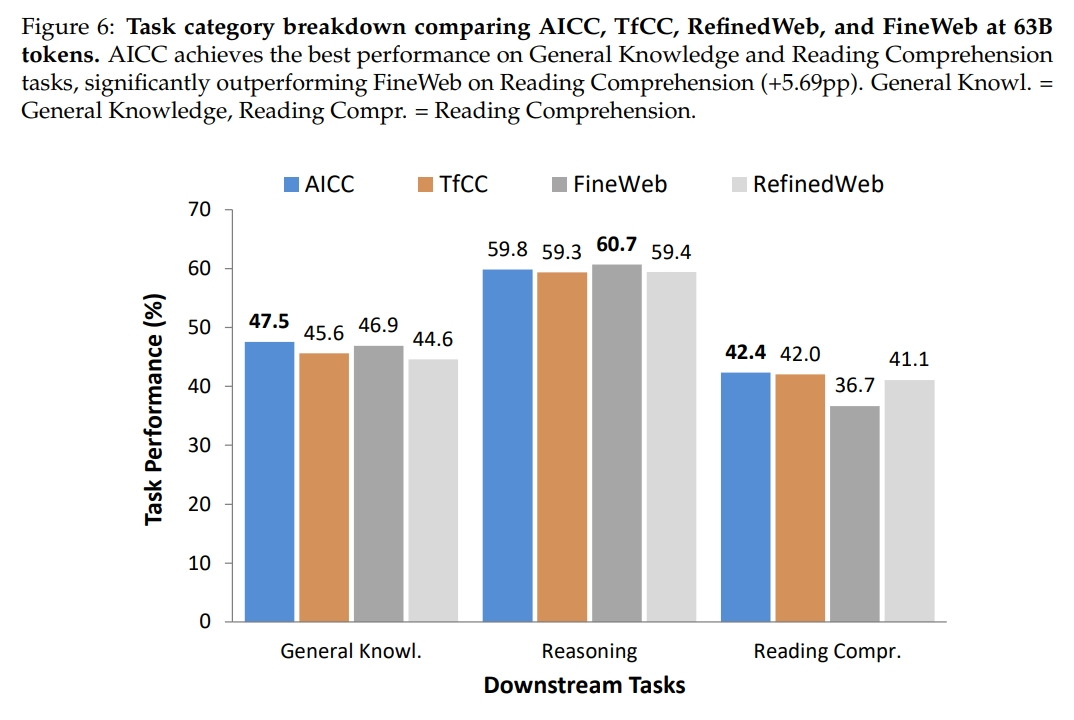
MinerU-HTML在通用知识和阅读理解上的表现
具体来说,AICC语料库基于Common Crawl 2025年的两个快照,通过MinerU-HTML进行内容提取并转换为Markdown格式。为确保对比实验的公平性,其过滤流程完全沿用RefinedWeb的严格标准,包括去重、语言识别和安全过滤等环节。质量验证采用LLM-as-Judge方法对10,000对文档进行评估,结果显示AICC在72%的案例中更受青睐,且其提取内容平均长度达到Trafilatura版本的1.16倍,表明其不仅保留更多内容,且质量显著提升。
在下游任务表现方面,基于62B token的控量训练实验表明,AICC预训练模型在13项基准测试中平均准确率达到50.82%,展现出显著优势。具体而言,其性能优于Trafilatura提取的TfCC语料(49.74%,提升1.08个百分点)、RefinedWeb(49.13%,提升1.69个百分点)以及FineWeb(49.61%,提升1.21个百分点)。尤为突出的是,AICC在通用知识任务上提升1.93个百分点,在阅读理解任务上提升5.69个百分点,有力证明了高质量内容提取对模型能力的促进作用可与激进过滤策略相媲美,甚至更具可持续性。
上述表现,有力验证了HTML提取质量对下游性能的影响与过滤策略同样重要的猜想。
二、精细化两阶段流水线:模型驱动的网页内容提取方法
MinerU-HTML采用了独特且高效的两阶段流水线设计,它将传统的网页内容提取升级为模型驱动的语义理解任务,核心流程首先是 Main-HTML 提取(语义化筛选主内容),随后是网页各类元素(图片、表格、列表、代码、公式、段落等)的格式化,最终输出大模型(LLM )友好的 Markdown 格式文本。
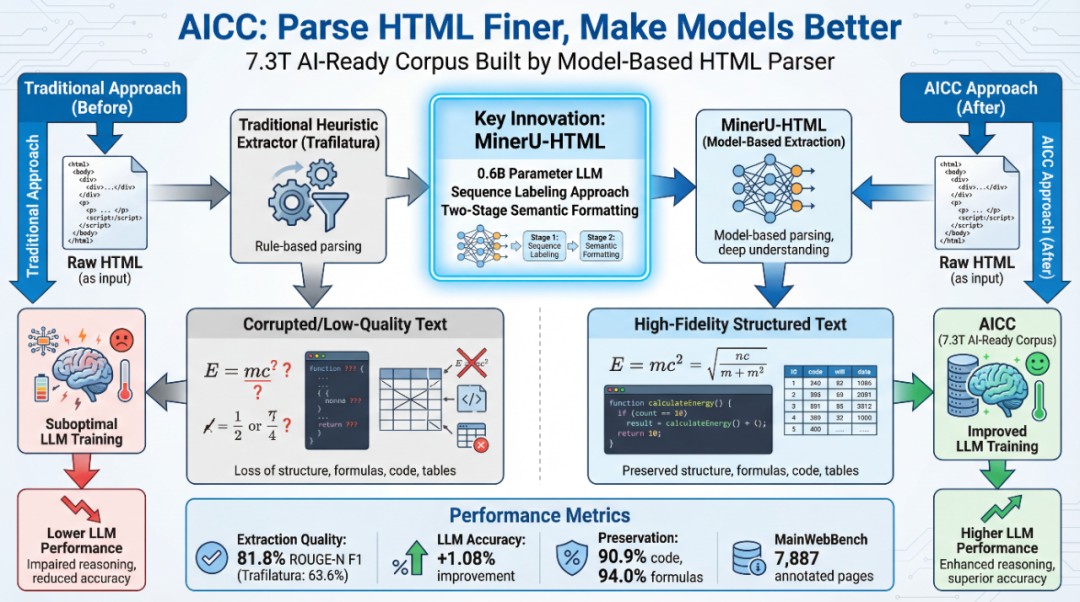
在第一阶段的 Main-HTML 提取中,旨在从原始、嘈杂的 HTML 中精准识别并剥离冗余信息(如广告和导航栏),只保留核心的主内容 (Main-HTML) 及其完整的结构。首先,为了应对原始 HTML 过于冗长和嘈杂的问题,系统首先将其转化为两种并行表示。简化 HTML (Simplified HTML) 是经过精简的输入,去除了非内容标签(如 <style>、<script>)并参照HTML开发规范进行块级分割,大幅减少了模型需要处理的 tokens 数量,提高了推理效率。同时,系统保留了映射 HTML (Mapping HTML),它忠实于原始的块级结构,用于后期的内容重建。
随后进入内容分类,这一核心步骤通过一个0.6B 参数量的仅解码器语言模型 MinerU-HTML-Classifier 来完成。该模型对简化 HTML 中的每个语义块进行二分类标注,判断其是否为“main(主内容)”或“other(冗余)”。为确保输出的准确性,系统采用了约束解码(Constrained Decoding)完全消除了模型可能产生的幻觉和格式错误。
最后在后处理阶段, 根据模型的分类结果,系统将预测标签映射回映射 HTML,剔除被标记为“other”的冗余块,最终得到 Main-HTML,它是原始文档的有效 DOM 子树,保证了内容的忠实性。
在第二阶段——文档格式化中,提取出的 Main-HTML 需要转换为 LLM 友好的 Markdown 格式。此阶段采用两步转换:先是将 Main-HTML 解析为 JSON 格式的结构化内容列表,明确标注出标题、段落、代码块、公式、表格等 11 类语义单元,并存储其专属属性。然后针对每种元素类型设计专用转换规则,将其转化为 Markdown。例如,它确保了代码块保留缩进和语法标记,数学公式保留 LaTeX/MathML 完整语法,并区分处理简单表格(可转为 Markdown 格式)和复杂表格(有单元格合并)。通过这种中间表示方法,有利于数据表达和筛选,也使其能够按需转化为下游任务所需的格式。

技术报告中,关于Json格式的示例
三、万亿级网页的高效处理:模板感知优化策略
为了能够在万亿规模网页上高效运行,MinerU-HTML 设计了模板感知优化策略。系统首先在最长子域名内对相似网页进行聚类(DOM Tree相似性)。然后在每个类别中挑选一个最具结构代表性的页面使用 MinerU-HTML 模型进行推理。最后,将模型对该代表性网页的分类结果迁移应用于所在分类内所有其他页面,从而实现大规模、高效率的 CPU 处理,大幅降低了对 GPU 资源的依赖。
上海AI实验室秉持开源开放的理念,通过MinerU-HTML的发布,进一步提升了业界大规模预训练语料库构建的质量基准,持续致力于持续构建多知识、多模态、标准化的高质量语料数据。
目前,MinerU-HTML所构建的AICC语料库demo已经上线,AICC数据集已经上架,旨在为学术界及产业界提供更符合主流中文价值对齐的预训练语料。为了更好地服务社区、精准把握用户对MinerU-HTML在线服务的使用场景,我们已发布MinerU-HTML在线服务,前往MinerU官网即可体验:https://mineru.net/。
MinerU项目的功能持续拓展与性能的不断进步,将持续为大模型时代提供坚实、可靠、无限扩展的“Tokenize Everything”基础,共同建设一个包容、开放、有序、共享的人工智能大生态。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)