AGENTS.md 真的对 AI Coding 有用吗?或许在此之前你没用对?
LLM 自动生成总体不稳,常常负收益还更贵,所以更现实的做法是:把自动生成当作“草稿”,但必须人来重新审阅并修改为更具体和更具针对性的文档,而AGENTS.md不可从代码直接推断、但会导致反复踩坑的东西。例如AGENTS.md只能跑uv而不是pip,以及这么做的原因必须用某个脚本启动集成环境,具体哪些 env var关键约束(兼容性矩阵、部署目标、性能红线、安全规则)常见任务 :对应入口文件/模块
AGENTS.md 相信大家应该不陌生,它们一般都是被放在根目录的典型 Context Files ,这些文件被默认作为 Coding Agnet 的 「README」,一般是用来提供仓库概览、工具链指令、编码规范或者设计模式等,不少 Agent 还提供 /init 之类命令自动生成这些文件。
实际上在此之前大家都是
GEMINI.md、CLAUDE.md、copilot-instructions.md之类的各自为政,而 2025 之后,OpenAI、谷歌、Cursor 和 Sourcegraph 合作制定了AGENTS.md,大家才开始统一标准。
可以说 AGENTS.md 就像是一个大家都默认的必需品,根据统计,根据 2026 年的统计数据,已经有超过 60,000 个开源项目在 root 目录下包含了 AGENTS.md 文件,但问题是,这些“ Context Files 到底能不能让 Coding Agnet 更容易把 issue/任务做对?还是只会增加 token 成本?
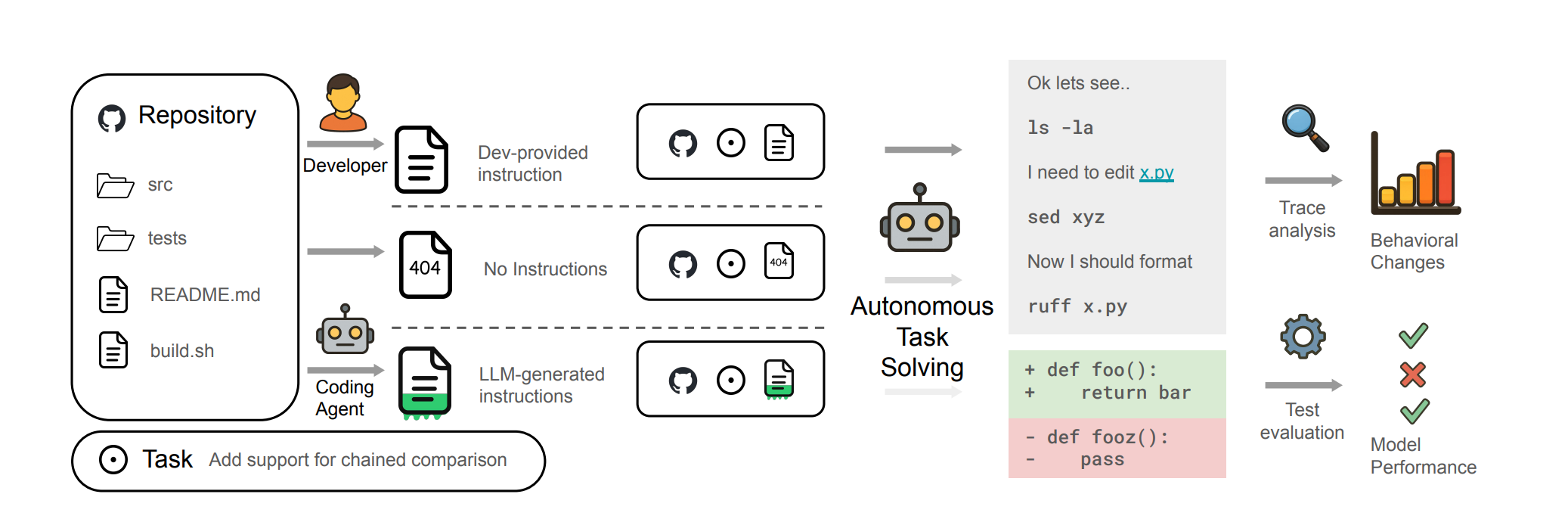
测试条件
论文 《Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?》 针对这个问题做了测试,他们采用了两套互补数据集 + 对照设置:
-
两个数据集
-
SWE-Bench Lite:经典的 300 个 Python repo-level 任务(热门仓库),这些仓库本来没有开发者写的 context file,论文在这里评测“自动生成 context file”的效果。
-
AGENTBENCH:他们专门去挖了 12 个带开发者自带 context file 的 Python 仓库,从真实 PR/issue 里构造出 138 个实例(bugfix + feature)
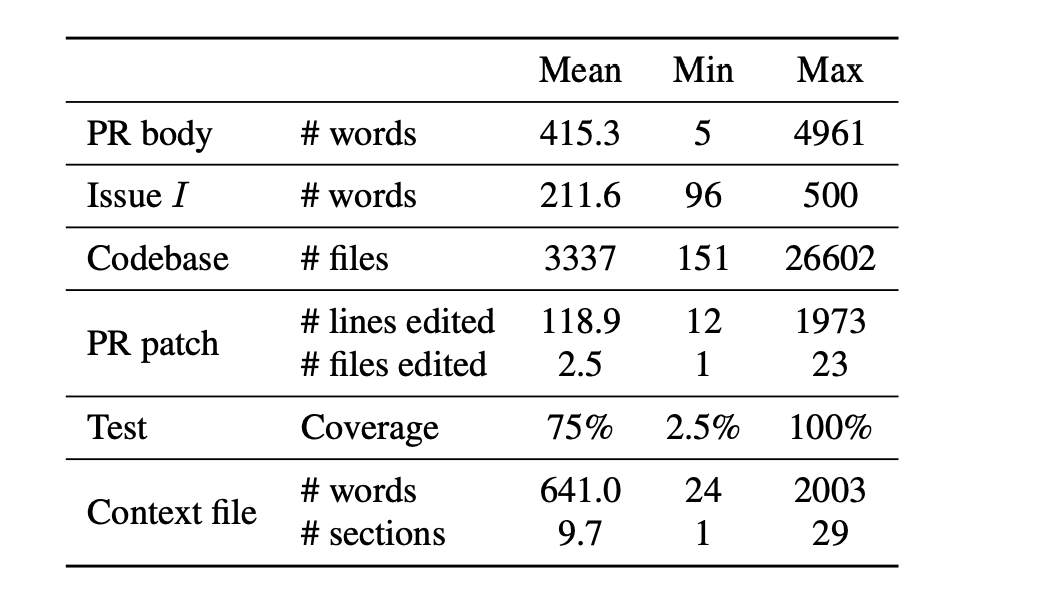
-
这里 AGENTBENCH 的意义:以前 benchmark 没赶上 AGENTS.md 流行,所以你没法直接测真实世界开发者写的 AGENTS.md 到底有没有用,所以他们为此新做了数据集。
-
三种对照设置(同一任务跑三遍)
-
NONE:完全不提供 context file
-
LLM:按 agent 开发者推荐流程,用对应 agent 的推荐
init/提示词自动生成 context file -
HUMAN:使用仓库里开发者自己提交的 context file(仅 AGENTBENCH 有)
-
然后就是被测 agents / models,这里采用了四套组合:
Claude Code + Sonnet-4.5,Codex + GPT-5.2 / GPT-5.1 Mini,Qwen Code + Qwen3-30B-Coder,并强调各模型在「自家 harness」里测试。
结论
而得到的结论很有意思,和之前在 《你现在给 AI 用的 Agent Skills 可能毫无作用,甚至还拖后腿?》 聊过的一结论类似:LLM 自动生成总体的效果“负收益”,人写的“微弱正收益但不稳定”,并且成本都更高 。
这就前面聊过的 Agent Skills 的论文一样,让 AI 自己实现 skills 然后在自己持续维护 skills ,结果是起不了正向作用,反而还会有负面作用,因为模型不能可靠地“写出”自己在执行时真正会受益的程序性知识。
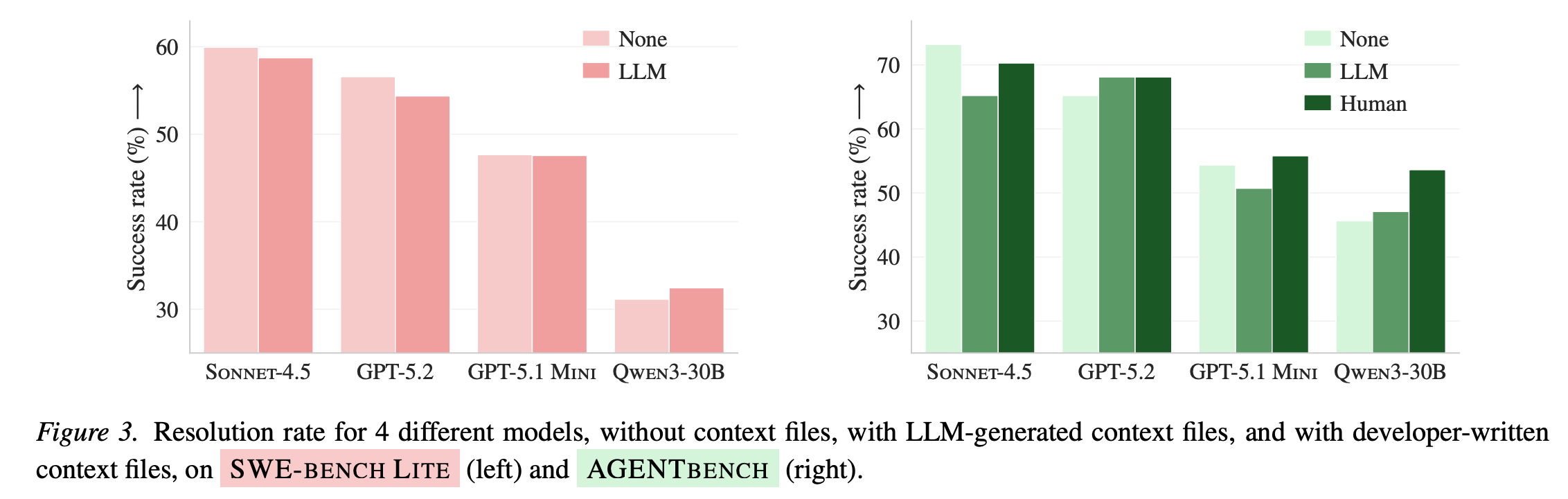
对于这个结论,这篇论文说的很直观:
- LLM 生成的 context files 往往让成功率更低(平均下降了 3%),同时推高推理成本 20%+
- 开发者写的 context files 相比 NONE 平均带来小幅提升(平均 +4% 左右),但也会让步骤/成本上涨
最有意思的是,他们在实验里量化了“更贵”这件事:
- LLM context file 会让平均 steps 增加
- 成本增加(SWE-Bench Lite 平均约 +20%,AGENTBENCH 平均约 +23% 的量级)
- 开发者文件同样增加成本
你是不是觉得这个成本也没什么?但是从数据可以直观体现:
- 输入 Token 增加:例如 Claude Opus 4.6,输入超过 200K Token 时,计费单价会直接翻倍
- 执行步骤增多:在有上下文文件引导时,智能体倾向于进行更广泛的探索,平均每项任务多执行 2.45 到 3.92 个步骤
这其实很有意思,因为在很多推广里,大家会说 AI 可以维护一切,但是目前的结果看来,AI 在持续维护过程中,如果没有人的干预,那么这个偏差值可能随着时间不断放大,成本也会不断增加。
为什么
那 “为什么会这样”?论文的 trace 证据主要体现在:context file 让 agent 更“谨慎/折腾”,但不更“聪明/精准” ,主要可以体现在三个范畴:
1、 context file 会显著改变 Agent 行为:产生更多探索、更多测试、更多工具调用,当 context file 存在时:
- agent 更频繁地跑测试
- grep / read / write 更多(更广泛地翻仓库、改文件)
- 更多使用 repo 特定工具(如 uv / repo_tool 等)
而且他们发现:context file 里写了某个工具的时候,agent 真的会更常用它,这说明“没提升”不是因为 agent 不听话,而更像是“听话但被加了不必要的工作”。
就像是幻觉反而增多。
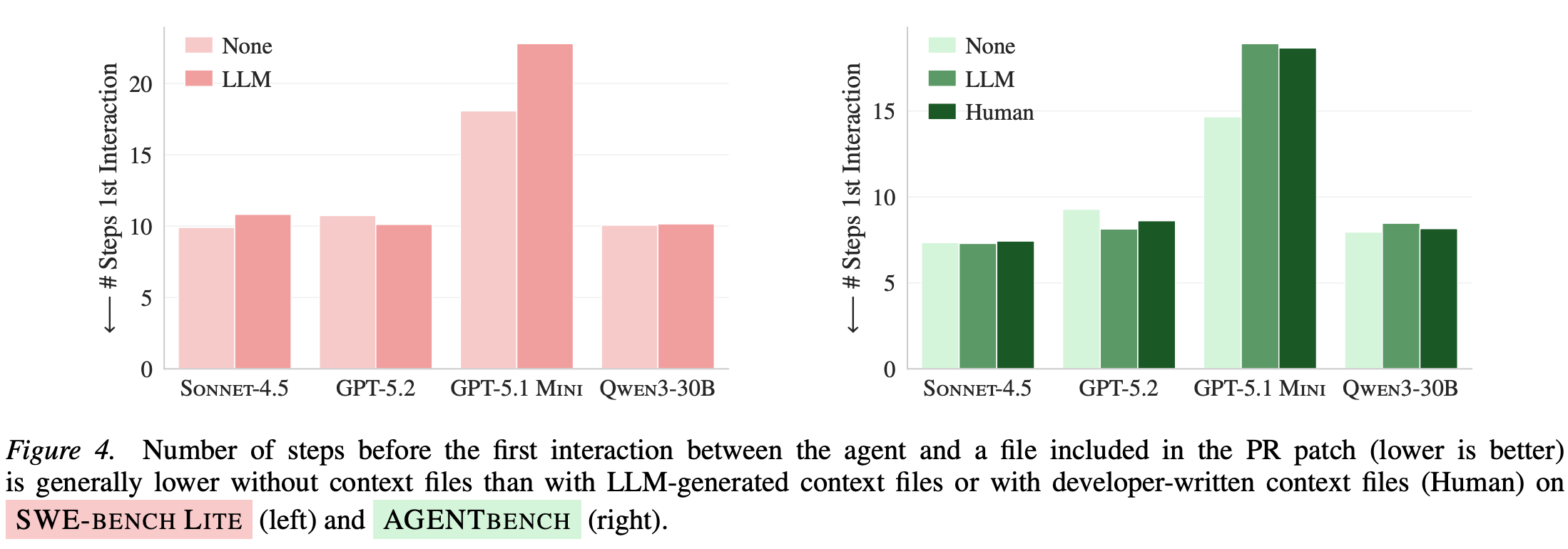
2、“仓库 overview” 并没有让 agent 更快找到关键文件,很多推荐写法会要求 context file 提供代码结构概览,但他们用一个很直观的指标测「是否更快碰到 PR 真正修改过的文件」:
结果是 有无 context file 并没让这件事明显变快(甚至更慢)。
3、推理 token 明显上涨,他们用 GPT-5.2 / GPT-5.1 Mini 的「自适应推理 token」现象来佐证「任务变难了」: context file 会让推理 token 平均上涨一截:
GPT-5.2 的平均推理 Token 增加了 22%,GPT-5.1 Mini 增加了 14% 。
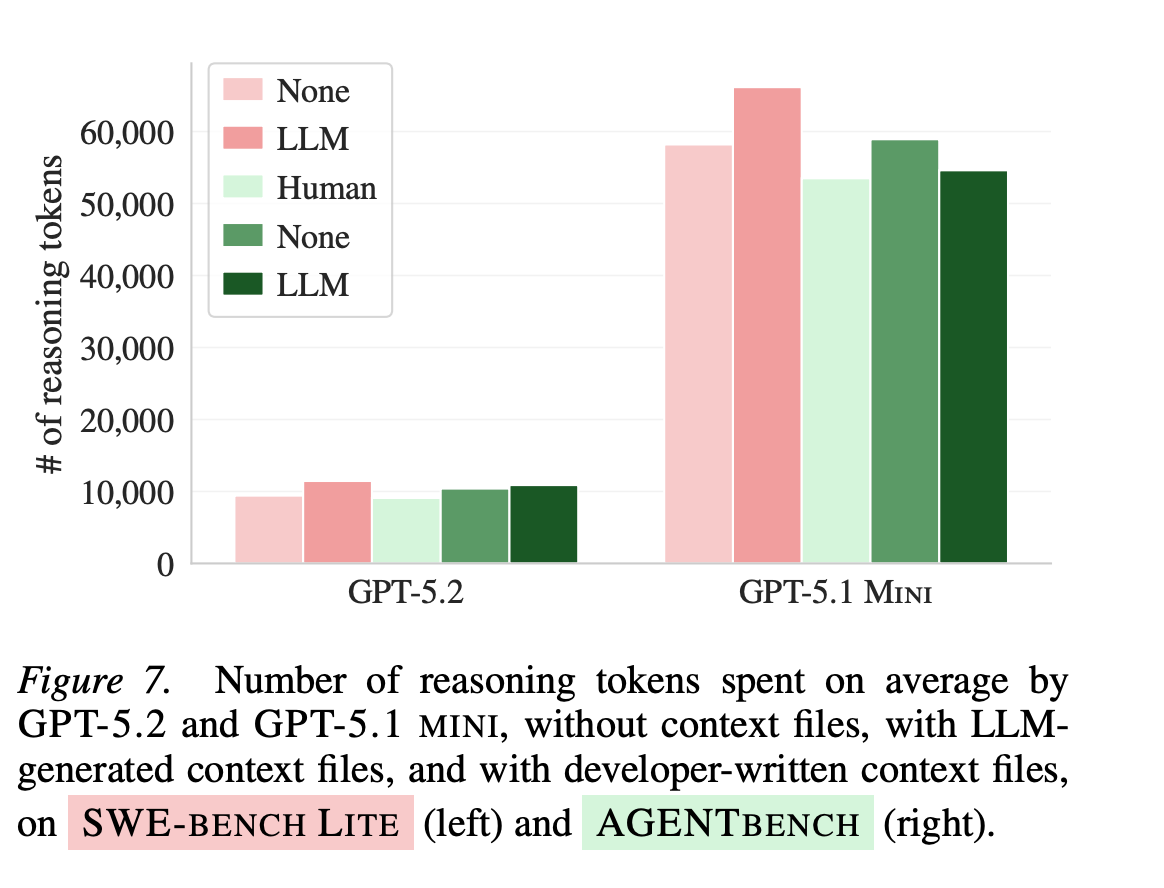
因为 context file(尤其自动生成的)往往加入了“额外流程/要求/检查点”,agent 又会遵守,于是探索/测试/步骤/推理都上去了,但这些动作并不等价于更高的任务命中率,反而让任务更容易超时、跑偏或把精力花在无关紧要的规范上。
例外
当然,这里有一点例外的是:当仓库文档删掉,LLM 生成的 context file 反而有用。
其实这也很好理解,对于项目原本文档很差/缺失的情况,LLM 生产的 md 反而会能补上大量关键操作信息(怎么装依赖、怎么跑测试、目录大概干嘛),这时候的 AGENTS.md 自然反而体现了作用。
所以反而是越烂的文档项目越有收益,这就像是 20 分到 70 分,和 70 分到 90 分的区别。
同时,他们还测了更强模型 / 换 meta-prompt :
- 用更强模型(如 GPT-5.2)来生成 context file,不等于更好:在一个数据集上可能涨,在另一个上可能跌,所以并不是一个稳定收益
- 用 Codex 的生成提示词 vs Claude Code 的生成提示词,也没有稳定的输赢,这体了现在 AI 还是一个概率预测是本质
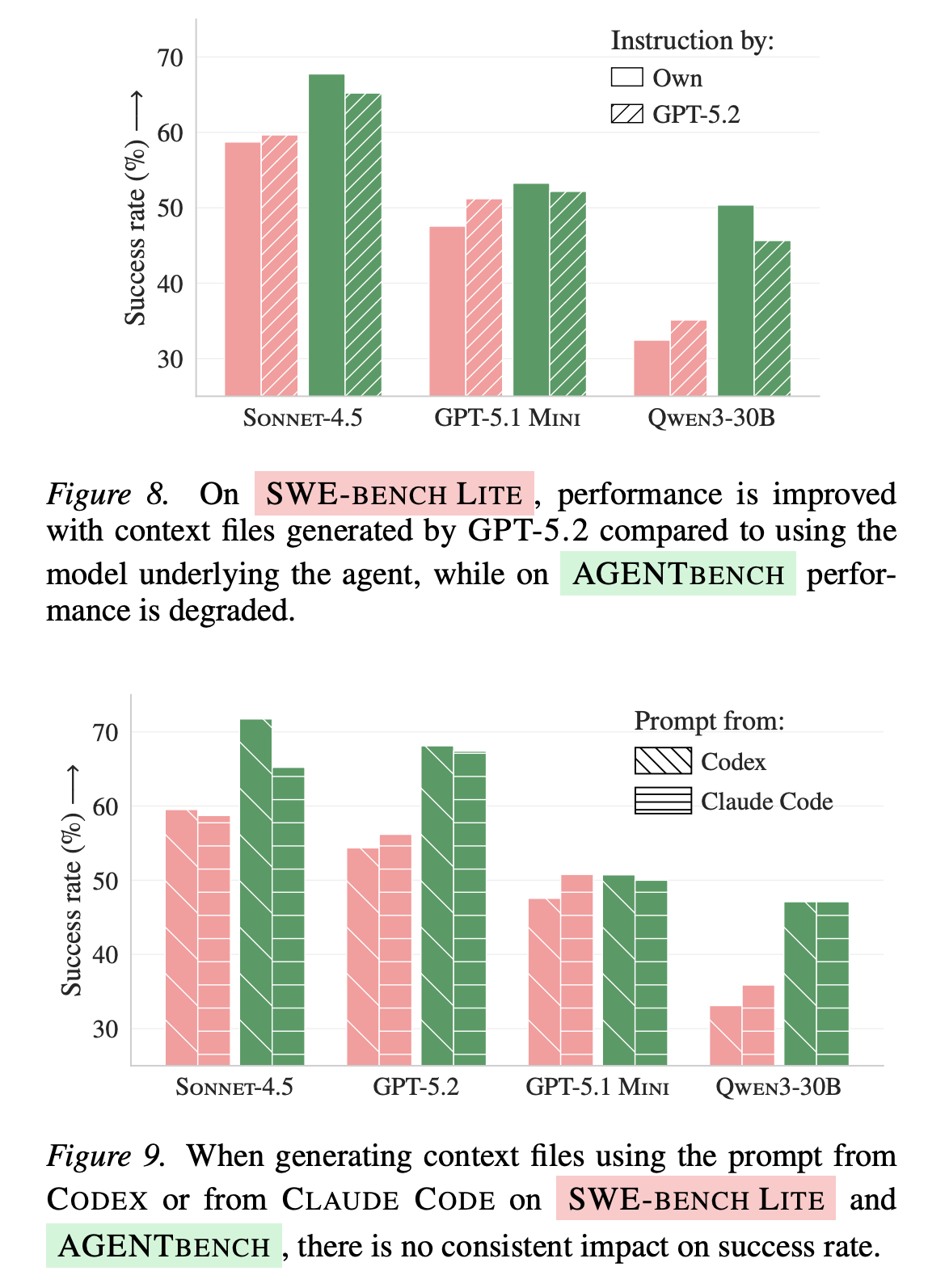
所以,问题不在“提示词不够好”和“模型不够好”这种浅层因素,更像是“自动生成这件事本身”还缺少可靠方法 。
通过这个,其实我们也可以得到一个启示:实际上我们日常开发中,使用相对便宜的模型来做文档工作,确实会是一个更有性价比的选择。
争议
当然,对于论文的结论:
- 大模型自己维护并生产的
AGENTS.md,在文档齐全的项目下没有收益,还增加成本,这个大家都还能够接受 - 但是对于开发者写的 context files 相比 NONE 平均带来 +4% 左右收益这个,在 HN 上大家还是觉得很大争议
目前 HN 上主要的核心讨论点有三个:
1、AGENTS.md 最大价值是 domain knowledge,而开源仓库很少有这种东西 ,对于 AI 来说,最有用的是模型无法从 repo 直接推断的业务/历史原因/隐含约束,这在闭源大项目常见,但在很多开源(尤其新做的小项目)里稀缺,所以 benchmark 里看不到收益。
所以实际上不是
AGENTS.md收益太低,而是大家手写的太少,并且没有针对性写。
2、有人说自己用 CLAUDE.md 主要是为了避免蠢错、减少后续 cleanup/refactor,而不是为了跑分意义上的“performance”,因为论文指标的边界测的是 exec(test)=PASS 的任务完成率,而不是“代码质量/可维护性/团队规范遵守度/后续返工成本”。
但是其实论文也确实测了“成本/步骤”与“行为变化”,并且发现 context file 会让 agent 更爱跑质量检查/测试/工具链,当然这某种程度上支持了“它可能更谨慎”,问题是这种谨慎在他们的任务里并未转化为更高完成率,反而经常只是更高成本。
3、页有人直觉认为:仓库越大,越需要 AGENTS.md ,否则 agent 会浪费很多上下文去找命令、找入口,但论文在“是否更快找到关键文件”这个指标上,给出了相反的证据:**overview 并没有显著加速触达关键文件,对此他们认为:
- overview 的写法不对:列目录树/泛泛描述,信息密度低,不能直接指向“任务常改哪里”
- benchmark 任务分布的现实差异:SWE-Bench Lite 的热门仓库本身文档/惯例更成熟,agent 已经有“先验”,而很多人说的“大闭源仓库痛点”在 benchmark 里不充分
4、手工写的 4% 的成功率提升真的是微不足道吗?不少人认为,如果一个 md 文档就可以提高 4% 的成功率,这其实已经是一个非常大的收益,当然,4% 的提升并不具备跨模型的一致性,所以这个数据不能看作是一种普适的工程增量。
最后
实际上这篇论文和之前 Skills 那篇都指向同一个观点:LLM 自动生成总体不稳,常常负收益还更贵 ,所以更现实的做法是:把自动生成当作“草稿”,但必须人来重新审阅并修改为更具体和更具针对性的文档,而 AGENTS.md 最值得写的内容:
不可从代码直接推断、但会导致反复踩坑的东西。
例如 AGENTS.md 可以表述:
- 只能跑
uv而不是pip,以及这么做的原因 - 必须用某个脚本启动集成环境,具体哪些 env var
- 关键约束(兼容性矩阵、部署目标、性能红线、安全规则)
另外**少写“目录导览”,多写“任务路由” **, 更有效的结构往往是:
- 常见任务 :对应入口文件/模块(例如“新增 API → 先看
api/routes.py+schemas.py”) - 常见 bug 类型 : 排查路径(日志在哪,feature flag 在哪)
更最重要的是,冗长的文档反而会产生副作用,建议只在 AI 犯错后才添加针对性的补丁指令,然后支持在子目录中使用嵌套的 AGENTS.md,实现“按需加载”上下文,避免全局上下文污染,类似于:
之前有人提到的 Claude Code 的上下文压缩盲区,在上下文过长后的压缩里,你给它几千字符的代码,压缩后变成一句话:「用户提供了代码」,而这里的根本原因就是内容太长了,而压缩是单向的,所以如果是加一行:
[transcript:lines 847-1023],那么反而不容易丢失。
另外还有一个小 tip 就是:「不要做 xxx 」的收益其实很一般,在 AI 上更建议使用正面引导或结合 Pre-commit Hooks 进行硬性拦截。
最后,事实上 AI 很多时候是会偷懒和「作弊」的,虽然它会说「我已经读过并理解了需求」,但实际执行时依然没有任何约束,这其实就是它直接忽略了 AGENTS.md ,因为此时它已经进入了 LLM 的炼丹玄学层面。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)