《Vibe Coding:AI编程时代的认知重构》笔记
Vibe Coding
1.什么是Vibe Coding
氛围的阶段:编码氛围、应用氛围、需求氛围。
VibeCoding强调:
- 直觉驱动:不需要精确地描述每一个技术细节,只需要表达想要的“感觉”;
- 快速迭代:通过不断地对话和调整来完善应用;
- 结果导向:关注最终效果而非实现过程;
- 创意优先:让想法的表达不受技术限制。
如果用一个词来定义Vibe的终极形态,我认为是resonance(共振):AI能力的提升带动人类编程能力迭代,人类通过转变观念来适应AI,人机协作由此迈向新的境界。
Vibe Coding也是一样,AI的能力提升与开发者的协同心态缺一不可:
- AI编码大模型能理解大型仓库,且具备完整编写、构建大中型应用的能力;
- 开发者能充分理解大模型的能力边界,最大限度地利用AI能力帮助自己快速落地实现。
Amazon发布Kiro IDE产品后,将Vibe和Spec定义为两种开发模式:
- Vibe:沟通即开发,即自由快速地通过实践来探索想法,通过持续提出新需求来迭代产品;
- Spec:先计划后开发,即通过编写严格的需求文档、设计文档并确认步骤制定计划,然后再启动编码步骤。
Vibe Coding是两者的综合。
2.若AI取代初级程序员,那高级程序员从何而来
布鲁诺·拉图尔(Bruno Latour)等人提出的行动者网络理论(ANT),可将软件工程视为由人和非人行动者共同构成的动态网络,在这个网络中,人的品位、责任感与AI等技术要素相互作用,共同塑造了现代软件开发的人文温度与工程品质。
3.在AI之前,你们都是手敲代码的吗
代码克隆技术,即比较两段代码的逻辑相似度。能力分为4级:
- L1:除空白字符、布局和注释有所不同外,其他代码片段完全相同;
- L2:除标识符、文字、类型、空格、布局和注释有所不同外,语法结构完全相同;
- L3:复制后经过进一步修改(如增删语句,或标识符、文字、注释等的变化)的代码片段;
- L4:执行相同计算但由不同的语法变体实现的代码片段(如冒泡排序与快速排序,或用不同的语言实现相同的逻辑)。
氛围模型:可看作过程高度压缩的瀑布模型和更加并行灵活的敏捷模型,最大价值在于“更快”。创业者的想法能够快速转化为原型演示,实现落地交付。
把AI编码领域的人机协同模式大致分为如下5个阶段:
- Resource:非大模型时代的资源辅助定位,如代码搜索和文档搜索;
- Copilot:短平快的合作,快速审阅,如代码补全;
- Workflow:既定的工作流,如基于仓库理解的代码生成、单测生成;
- Co-Agent:协作式智能体,当前所处的阶段,需融入传统IDE和开发过程,人工干预间隔在1小时内;
- Agent:智能体,类CLI形态,“天”级别的干预间隔,AI主动要求人类进一步明确需求。下面分别看一下。
Workflow分两种:
- 应用逻辑构建的流程化编排(类似Dify、n8n等),属于低代码形态;
- 模拟Agent运行过程的定制流程,注定成为Agent时代注脚的产物,但又是人类在模型效果欠佳或需求表达能力较弱时的合理选择。
4.Vibe Coding最信达雅的翻译是什么
氛围编程?灵码!哈哈。
氛围感是双向概念:
- AI角度
- 自然语言交互
- 实时响应
- 过程可见:过程感知依旧是人类最为朴素的协同需求,AI工具也通过多种交互形式来呈现改动内容:
- 配色和结构化展示
- 会话总结
- 代码改动总结
- 代码内容折叠
- 任务完成的提示音
- 人的角度
- 创造力的释放
- 沉浸式体验
5.谁在Vibe Coding
用户
- 创业者:从想法到现实的捷径
- 初学者:编程世界的新型入口
- 产品经理:需求实现的加速器
- 程序员:效率提升的得力助手
新机会:人人都是数字创造者
- 个人创造力的释放
- 创业门槛的降低
- 个性化解决方案的普及
新行业:催生全新商业模式
- AI编程顾问
- 解决方案提供商
- 技术教育转型
新业态:重构数字服务生态
- 独立开发者生态的繁荣
- 小型创新工作室的兴起
- 技术赋能服务的普及
6.Vibe Coding需要使用者拥有哪些能力
死亡螺旋
- 上下文错误的连锁反应
- 现象与实现的认知鸿沟
- AI的自证陷阱
- 人类介入的无力感
AI时代程序员的新定位
- 系统性思维的不可替代性
- 业务逻辑的深度理解
- 搜集上下文的能力
- 工程质量的把控
必备的核心技能体系
- 系统架构能力
- 调试和问题诊断能力
- 安全意识和实践
- DevOps和部署能力
Vibe Coding的能力模型
- 技术能力
- 协作能力
- 业务能力
7.是AI不理解你,还是你不理解AI
软件工程领域的课题研究子领域:代码合成、编程语言、缺陷检测、代码克隆检测、代码搜索、代码评审、静态分析、软件安全、形式化方法、软件测试等。
研究趋势大致是:从概念和数据集定义,到规则匹配的大幅进步,再到瓶颈期的特定领域约束求解,最终到如今AI驱动下的百花齐放。
8.为什么AI接手大工程这么费劲
现代AI SaaS的黄金技术栈:
Next.js:建立在React之上的全栈框架,具备服务端渲染、API路由和高效的构建工具;新特性(如Server Actions[服务端操作],无须单独编写API即可在前端直接调用服务端逻辑)进一步简化前后端逻辑的整合,有助于提升开发效率和代码可维护性- TailwindCSS:采用原子化设计,便于通过类名快速组合样式,降低样式生成与维护复杂度
shadcn/ui:基于Radix UI,提供高质量、可定制的组件,既能直接复用,也支持灵活调整- Supabase:参考BaaS
- Prisma:类型安全的ORM,能够通过简洁的API实现结构化的数据库操作,降低数据层开发难度
- Vercel AI SDK:针对AI应用场景设计,统一对OpenAI、Anthropic、Google等主流大模型厂商旗下产品的接入方式,简化多模型适配流程
- Clerk:实现现代化的用户管理与认证流程
- Stripe则专注于支付处理
- Sentry:负责错误监控与性能追踪,为项目的稳定性和可维护性提供保障。
这套技术栈之所以对AI格外友好,核心源于4点特性:
- 标准化程度高:每个工具都有清晰的API和约定,降低AI的理解复杂度。
- 文档丰富:大量示例代码和最佳实践为AI提供充足的训练素材。
- 社区活跃:Stack Overflow、GitHub上的海量问题及解决方案,进一步补充AI的知识储备。
- 设计哲学一致:从前端到后端,整体架构和编程模式高度统一,让AI能在统一逻辑下处理不同环节的代码生成。
上下文理解的鸿沟
- “貌似正确但实际错误”的陷阱
- 过度自信
- 复杂性与上下文的指数级增长
- 隐式依赖关系
- 历史决策的积累
- 业务规则的演进
- 团队知识的分散
一些建议:
- 使用具备深度思考能力的模型或MCP工具
- 使用Memory(记忆系统)或者Rule(规则文档)引导模型想清楚再行动
- 采用Plan(计划)模式,禁用代码编辑工具
人类与AI对可维护性的理解存在微妙却关键的差异,反映出两种不同的认知架构
| 人类的可维护性观念 | AI的可维护性观念 |
|---|---|
| 优先考虑抽象和模块化 | 偏好显式和详细的文档 |
| 依赖隐式知识和交互协同 | 需要明确提供所有上下文 |
| 重视代码的优雅和简洁 | 注释和孪生文档也很重要 |
| 能够容忍一定程度的隐性约定 | 缺乏低频交互和隐式知识 |
TODO
9.AI写代码时,你在干什么
三个阶段
- Copilot:辅助编程的初级阶段
- Composer/Edit:控制权的初次转移
- Agent:失速感强烈
- 速度差异带来的认知挑战
- 从过程监督到结果验证的角色转换
在Vibe Coding时代,更重要的能力:
- 需求表达:如何准确、清晰地向AI描述想要实现的功能;
- 质量判断:如何快速评估AI生成代码的质量和正确性;
- 架构思维:如何在宏观层面把控项目的整体方向;
- 问题诊断:当出现问题时,如何快速定位和解决。
并行项目开发:多线程的开发模式
- 多项目开发:扩展创造边界
- 单项目多feature(功能)开发:深度并行的艺术
- 并行开发的最佳实践
金融等敏感场景中测试验收十分重要
- 人工的代码审查
- 逐行检查AI生成的代码,验证业务逻辑的正确性;
- 进行代码静态分析、安全漏洞扫描和业务逻辑测试;
- 检查代码规范,确保命名一致、结构规范、注释文档完整;
- 完善防错设计,降低后续代码或用户操作引入的风险;
- 开展必要的架构审核与安全审核。
- 自动化门禁措施
- 配置各类Hook(钩子)保证测试左移;
- 检测算法复杂度和数据库查询效率;
- 实施严格的性能模拟检测和放行机制;
- 执行历史教训类代码规范检测。
Agentic DevOps:多层次的智能协作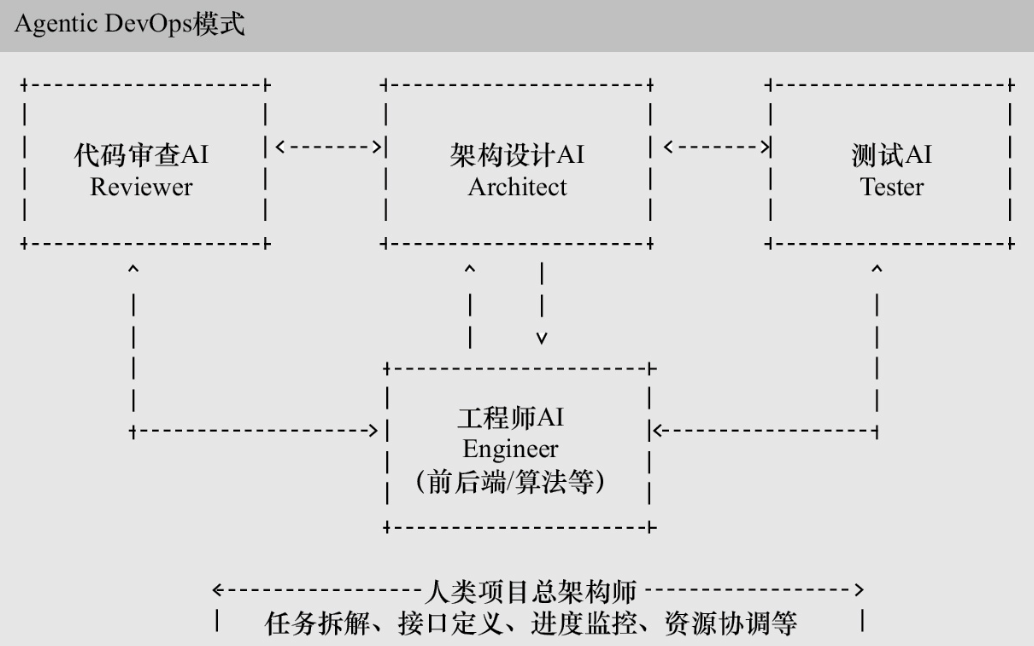
包括
- 代码审查AI(Reviewer)
- 专门负责代码质量检查;
- 发现潜在的bug和安全漏洞;
- 评估代码的可维护性和可扩展性。
- 架构设计AI(Architect)
- 负责系统架构的设计和优化;
- 监控模块间的依赖关系;
- 确保架构的合理性和可扩展性。
- 测试AI(Tester)
- 自动生成测试用例;
- 执行各种类型的测试;
- 分析测试结果并提供改进建议;
- 通过日志观察和巡检验证来监控运维机器。
- 工程师AI(Engineer)
- 涵盖广义的软件工程师能力(包含前后端和算法);
- 负责根据需求生成代码;
- 优化算法选择与实现效率;
- 保持代码风格的一致性;
- 可分饰前后端、算法等不同角色。
人类角色升级
- 战略指导者
- 质量仲裁者
- 创新催化者
当AI编码能力迈向更复杂的协作模式时,人类对开发过程的感知方式也需同步升级。从逐行代码的微观关注到系统全局的宏观把控,可视化工具将成为连接人类与AI的关键桥梁,帮助更高效地理解、监控和决策。
- 多维度的可视化界面
- 代码架构地图(Code Architecture Map)
- 依赖关系图(Dependency Graph)
- 进度仪表板(Progress Dashboard)
- 智能化的异常检测
- 架构偏移检测
- 性能回归检测
- 安全风险检测
- 预测性的项目管理
- 需求变更影响分析
- 资源优化建议
- 质量趋势分析
认知角色的根本性转变
- 从代码工匠到系统指挥官
- 技能结构的迁移升级
- 工作方式的根本改变
- 价值创造的重新定位
- 迭代过程的重心偏转
- 学习路径与知识维度的适应
- 深度优先转为广度优先
- 静态知识转为动态习得
- 注意力层面的项目管理
- 人机协同的时间管理
- 跨应用的项目管理:Agent任务上下文模块
- Agent的有限责任制
10.如何与AI一起Vibe Coding
人类与AI协同编程的过程中,两个核心原则:
- 组织或让AI自行感知上下文输入,以实现高质量启动;
- 验证或让AI自我衡量生产物输出,形成正循环反馈。
模型选择:
- 不要盲目相信榜单和评测
- 模型效果大于成本
- 根据场景挑选适合的模型
抛开上下游的衍生平台不谈,单纯的代码生成主战场(也是Vibe Coding实践者停留时间最多的编码应用工具)主要分为3类
- IDE集成型
- CLI驱动型
- 低代码型
OpenAI科学家Jason Wei提出验证者定律:
训练AI解决某个任务的容易程度,与该任务的可验证性成正比。所有既可能解决又容易验证的任务,都将被AI解决。
11.对人类友好的设计模式,AI应该继续遵循吗
人机协同沟通的局限
- 框架枷锁
- 信息衰减
- 用更严谨的表达方式
- 提供更强的目标感:提示词增强(Prompt Enhancement,让另一个AI先完成网络搜索和调研,帮助生成更具体的提示词输入,效果可能更理想且交互更友好。)、任务拆分、长期记忆
- 密度瓶颈:代码库索引(Codebase Indexing)或仓库记忆(Repository Memory)
- 物理屏障
如何调和人脑的局限与AI的优势,成为Vibe Coding时代设计模式演进的核心议题:
- 有限的短期记忆
- 脆弱的注意力
- 协同损耗
设计模式的终极目的正在从弥补人类缺陷转向释放人机协同势能。
保留模式中的思想内核(如解耦/封装),但摒弃其形式枷锁(如固定实现),才能抵达Vibe Coding的至高境界。
12.AI能否从0到1搭建大型工程
现实中的软件复杂度与迭代过程中的熵增往往是不可控的。
AI从0到1构建大型工程,究竟面临哪些阻塞性的挑战?
- 局部关注导致架构腐化
- 需求模糊和人的因素
与AI共建阶段性的评估机制,提升项目的目标感和架构整洁度
- 代码坏味道评估机制:Linter检查、重复代码检测、死代码识别,以及圈复杂度、扇入扇出、测试覆盖率等指标。
- 建立改动追溯
- 清理多余代码
- 带上优化意识
- 强化流程,固化记忆:提高模型能力,增强提示词引导,注重流程管理与文档机制
- 自定义Agent和钩子机制
- 项目规则和记忆沉淀
- 需求目标和待办任务列表
引入人机协同管理机制
- Agentic DevOps
- 人类管理
- 用户视角聊需求,技术视角讲问题
- 及时止损
- 给上下文留足保护空间
- 版本控制,定时总结
- 推倒重来
- 维护上下文和修改记录
13.我们真的希望AI完全和人类一样吗
图灵测试本身并不代表AI达到最高智能:
- 图灵测试的评判标准过于主观
- 图灵测试鼓励欺骗性设计
- 图灵测试忽略AI的独特价值
升级版本,经济图灵测试(Economic Turing Test),以AI能否胜任高价值的岗位为标准,衡量其是否达到类人智能。即,作为雇主,你是否愿意将AI用于实际经济活动,以提升生产力、降低成本、创造价值。这一原理也体现在AI应用产品的定价上——不少产品常会锚定人工成本来设定价格,让定价与“替代人工”的价值直接挂钩。
Vibe Coding评价体系
- 需求完成能力
- 协作效率
- 创新潜力
- 适应性
这种讨好型人格的形成有深层的技术和商业原因:
- 训练数据的偏向性:AI的训练数据主要来自互联网上的文本,其中包含大量的客服对话、帮助文档等,这些内容天然具有讨好用户的倾向。
- RLHF的导向作用:在人类反馈强化学习(RLHF)过程中,人类标注者更倾向于奖励那些友好、有帮助的回应,这进一步强化AI的讨好倾向。
- 商业竞争的压力:在激烈的AI市场竞争中,用户体验成为关键的差异化因素,讨好用户也因此成为商业成功的必要条件。
超越人类局限的可能性
- 超强的记忆能力
- 无疲劳的工作状态
- 多维度的并行处理
- 无偏见的客观分析
AI is not going to replace humans, it’s going toaugment humans.(人工智能不会取代人类,它会增强人 类的能力。)——李飞飞
AI的独特优势
- 代码质量的一致性保证
- 全局视角的架构优化
- 实时的知识更新
- 跨领域的知识整合
在理想的Vibe Coding环境中,人类与AI应是各自发挥优势的协作关系。
人类的优势:
- 创造性思维和直觉;
- 业务理解和用户同理心;
- 战略思考和长远规划;
- 伦理判断和价值取向。
AI的优势:
- 大规模信息处理;
- 一致性和准确性;
- 24×7的可用性;
- 客观分析能力。
14.我们会迎来AI取代人类编程的那一天吗
软件工程从来不是关于代码的。工程是人类对人类问题的软件解决方案的精确探索。——肖恩·格罗夫(Sean Grove)在OpenAI的演讲The NewCode。
人类编程的本质包含3个层次:
- 表达层:将抽象的想法转化为计算机可以理解的指令。
- 逻辑层:构建解决问题的算法和数据结构。
- 愿景层:理解真实世界的需求并设计相应的解决方案。
编程的终极目的:解决人类问题
- 理解用户需求:洞察用户的真实诉求(而非表面表述),学会将原始诉求转化为产品需求;
- 设计系统架构:在复杂性和可维护性之间找到平衡,保证持续迭代的稳定性和协作沟通的流畅性;
- 预见未来变化:构建能够快速适应需求变化的系统,预留扩展接口;
- 承担社会责任:确保技术发展符合人类的价值观和伦理标准,以解决现实问题、服务人类为宗旨。
模型的不足由应用层通过工程手段解决,应用的复杂度则由模型能力的通用化来解决。
- 模型层的进步。主要围绕代码理解与生成能力的提升展开。
- 上下文窗口扩展:从4K到2M以上token的上下文窗口,让AI能够充分理解更大的代码库,减少不必要的复杂代码仓库索引。
- 推理能力增强:从简单的模式匹配升级到复杂的逻辑推理,配合更强的工具调用和意图识别,使应用层面无须设计复杂的意图识别链路和工具协议。
- 速度提升:加速首包计算与整体输出速度,通过控制思考程度、采用投机解码等方式,大幅提升文件修改的应用效率。
- 记忆加强:借助小模型的内部集成,从模型层面增强长短期记忆的综合能力。
- 多模态融合:整合代码、文档、图像等多种信息源,减少应用层不必要的多模态模型切换与总结记忆,并且能够深入理解软件产出物,推动后续迭代优化。
- 专业化训练:针对编程任务进行专门优化,学习编程领域的工具调用逻辑与用户偏好,更好地应对不同难度的任务——简单任务快速解决,困难任务深度分析。
- 应用层的创新。聚焦于降低人机协作门槛、拓展使用场景,创新方向体现在如下几个方面。
- 远端沙箱:提供远程运行、并行任务处理等功能。
- 代码理解:通过深度索引与语义分析理解大型项目,快速召回上下文,生成高质量仓库文档和架构记忆。
- 自动化工具链:与即时通信软件、代码托管及CI/CD平台集成,实现从代码生成到评审、测试、部署的全流程自动化。
- 协作平台:支持多人、多AI的协同开发。
- 上下文管理系统:借鉴操作系统的理念管理会话长短期记忆,采用文件系统和Git版本管理机制更自然地管理上下文。
- 多端支持:覆盖不同操作系统及移动端编程的需求。
正所谓“行百里者半九十”,虽然AI在编程领域已经取得显著进展且进步迅速,但我们仍需审视当前存在的“最后一公里”挑战。
- 上下文扩充
当前挑战
虽然模型的上下文窗口在不断扩大,但如何在保证理解到位的前提下进一步提升窗口大小,以及如何有效利用这些上下文仍然是一个挑战——单纯扩大上下文窗口、塞入更多内容未必能提升生成质量。
解决方向
- 智能上下文选择算法:评估上下文的价值,筛选淘汰低质量的上下文。
- 分层的信息组织结构:结构化上下文信息,主动向人类索取缺失的信息,追求无歧义的表达。
- 动态上下文更新机制:基于用户追问进行反馈分析,动态评估并更新上下文对生成结果的影响,动态组装高质量上下文。
- 更高效的上下文利用:将注意力机制聚焦在召回文档与目标需求上,忽略辅助文档之间的注意力计算。
- 多模态混合理解:结合多模态信息,提升上下文的表达维度。
- 长短期记忆
当前挑战
AI缺乏对项目历史以及演进过程的长期记忆,难以理解代码的历史背景和设计决策。
解决方向
- 构建项目记忆和个人偏好系统:以文本形式持久化存储项目信息和个人偏好。
- 更高效的记忆管理:建立“内存态”“磁盘态”等不同形态的记忆管理机制,根据上下文重要程度决定其是向量化表示还是原文召回,扩大存储空间、加速记忆高质量召回。
- 结合文件与版本管理系统:利用文件系统的目录、读写机制以及Git等版本控制手段,优化记忆存储与召回。
- 历史决策和文档追溯:将长远的历史代码提交、研发文档作为冷存储归档,按需召回。
- 多模态理解和生成
当前挑战
软件开发不仅涉及代码,还包括设计图、架构图、用户界面等多种形式的信息,对这些信息的理解和生成能力决定Agent的上限。
解决方向
- 代码垂直领域的图像理解:重点支持UML图、报错信息、代码内容和框架的理解。
- 设计稿和交互稿的理解:明确产出物操作验证和原始交互稿的对应关系,理解交互时序。
- 自然语言与仓库信息到UML图的生成:打通“从工程信息生成图片到图片理解”的完整闭环。
- 软件产物理解和类人操作辅助:比截图更上层的多模态理解,包括但不限于对电脑操作录屏的理解,以及外置辅助设备对真实环境的感知——例如AI眼镜、AI摄像机感知机器人、移动端真机操作等设备获取的信息。
- 部署运维等全生命周期串联
当前挑战
AI目前主要专注于代码编写,对软件完整生命周期的支持有限。
解决方向
- Agentic DevOps的发展:由多个AI Agent协同流转DevOps流程,推动项目进展。
- 智能监控和故障诊断:关联线上监控数据、用户日志和本地仓库代码以及近期改动,以识别性能问题和缺陷风险。
- 自动化的性能优化:AI通过智能插桩感知用户高频使用场景,定位并验证性能问题的解决方案。
- 多应用的综合开发、部署与运维:同步管理前后端、算法模型端及数据分析端的软件应用矩阵。
- 世界物理模型
当前挑战
AI缺乏对现实世界的深度理解,难以处理涉及物理世界交互的复杂系统。
对计算机而言,实现逻辑推理等人类高级智慧只需要相对很少的计算能力,而实现感知、运动等低等级智慧却需要巨大的计算资源。——莫拉维克悖论(Moravec’s paradox)
解决方向
- 物理仿真的集成:支持机器人开发、AI硬件评测、真机调试等场景。
- 实时数据的处理能力:更及时地感知并理解线上运行结果。
- 线上数据与线下开发的辅助:分析静态代码和线上用户日志的关联,识别代码逻辑问题,构思改进方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)