什么是大语言模型?从原理到架构,一次讲清楚
大语言模型(LLM)是当前AI领域的核心技术,以ChatGPT等为代表。其核心特点在于"大":参数规模大(数十亿至千亿级)、训练数据量大(TB/PB级)、算力需求高。模型基于Transformer架构,通过自注意力机制处理文本,能并行计算并捕捉长距离依赖关系。本质上,LLM是通过海量数据训练来预测下一个最可能出现的词,而非真正"思考"。这种架构使模型具备强大
一、大语言模型到底是什么?
现在我们提到的“大模型”,通常指的是 LLM(Large Language Model) ——大语言模型。像 ChatGPT、DeepSeek这类产品,本质上都属于这一类模型。
你可以把它理解成一个读过海量书籍的超级语言学霸。它会聊天、会写文章、会翻译、会写代码、会做总结,甚至还能帮你改简历、写营销文案。但它本质上不是“思考”,而是在做一件事:
根据你说的话,预测下一句话最有可能是什么。
和早期那些专门解决单一任务的模型相比(例如OCR、搜索排序模型、广告推荐模型等),大语言模型的核心差别就在一个字——“大”。
二、大模型为什么“大”?
1️⃣ 参数规模大(相当于脑细胞多)
模型中的“参数”可以理解为模型内部的“知识存储单元”或“规则调节器”。参数数量越多,模型能够表达的模式和关系就越复杂。
比如我们经常看到模型名称中带有:
- 7B
- 72B
这里的 B 是 Billion(十亿),72B 就意味着有 720亿个参数。
可以类比为:
- 训练数据 = 学习材料
- 参数 = 大脑中总结出的规律
打个比方:
一个人看了100本书和看了10万本书,脑子里形成的知识结构肯定不一样。
参数多,就像脑回路更复杂,表达能力更强。
2️⃣ 训练数据规模大(读过的内容多)
大模型的另一个“体量”体现在训练数据上。
大模型在训练的时候,会“读取”
- 网页文本
- 书籍
- 新闻文章
- 代码仓库
- 多语言语料
- 对话数据
数据规模可以达到 TB 甚至 PB 级别。
模型在训练时并不是在“理解”内容,而是在学习词与词之间的统计关系、上下文规律、推理模式和表达结构。
就像一个小朋友看了1万张猫的图片,他不是把每只猫记住,而是总结出:
- 猫有两只耳朵
- 有胡须
- 有尾巴
这些总结出来的规律,就变成了模型的“能力”。
3️⃣ 对算力要求高(训练它很贵)
训练一个大语言模型,往往需要:
- 成千上万块高性能GPU
- 数周甚至数月训练时间
- 大规模分布式计算集群
这也是近年来GPU需求暴涨、算力成为战略资源的重要原因。
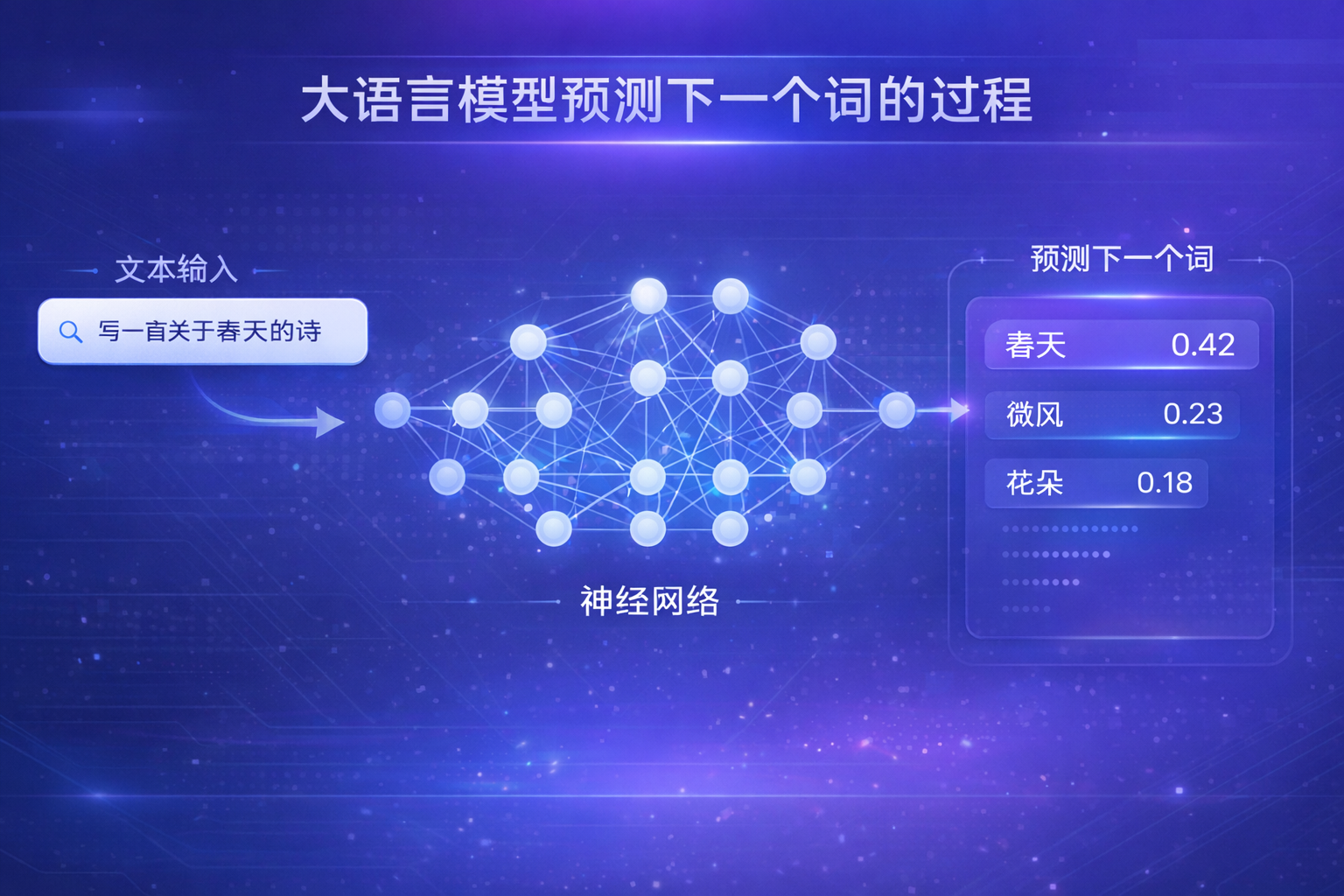
三、大语言模型的核心原理:预测下一个词
虽然大模型看起来“智能”,但它最核心的任务其实非常简单:
给定一段文本,预测下一个最有可能出现的词。
举个例子:
输入:
“人工智能正在…”
模型会想:
- 改变(概率最高)
- 发展
- 影响
- 颠覆
然后选一个出来。
生成文本的过程其实就是:
- 根据当前上下文预测下一个词
- 把这个词加入上下文
- 再预测下一个
- 循环往复
直到生成完整内容。
四、Transformer:大模型的核心架构
现代大语言模型几乎全部建立在 Transformer 架构之上。
在它出现之前,主流是RNN循环神经网络
RNN 的问题:
- 必须按顺序处理文本(一个字一个字读)
- 无法高效并行(速度慢)
- 长文本容易遗忘前文信息(长期依赖问题)(容易忘记前面说了什么)
而 Transformer 的核心思想是:
同时处理所有词,并计算它们之间的关系。
这使得:
- 可以并行计算
- 更好处理长距离依赖
- 训练效率显著提升
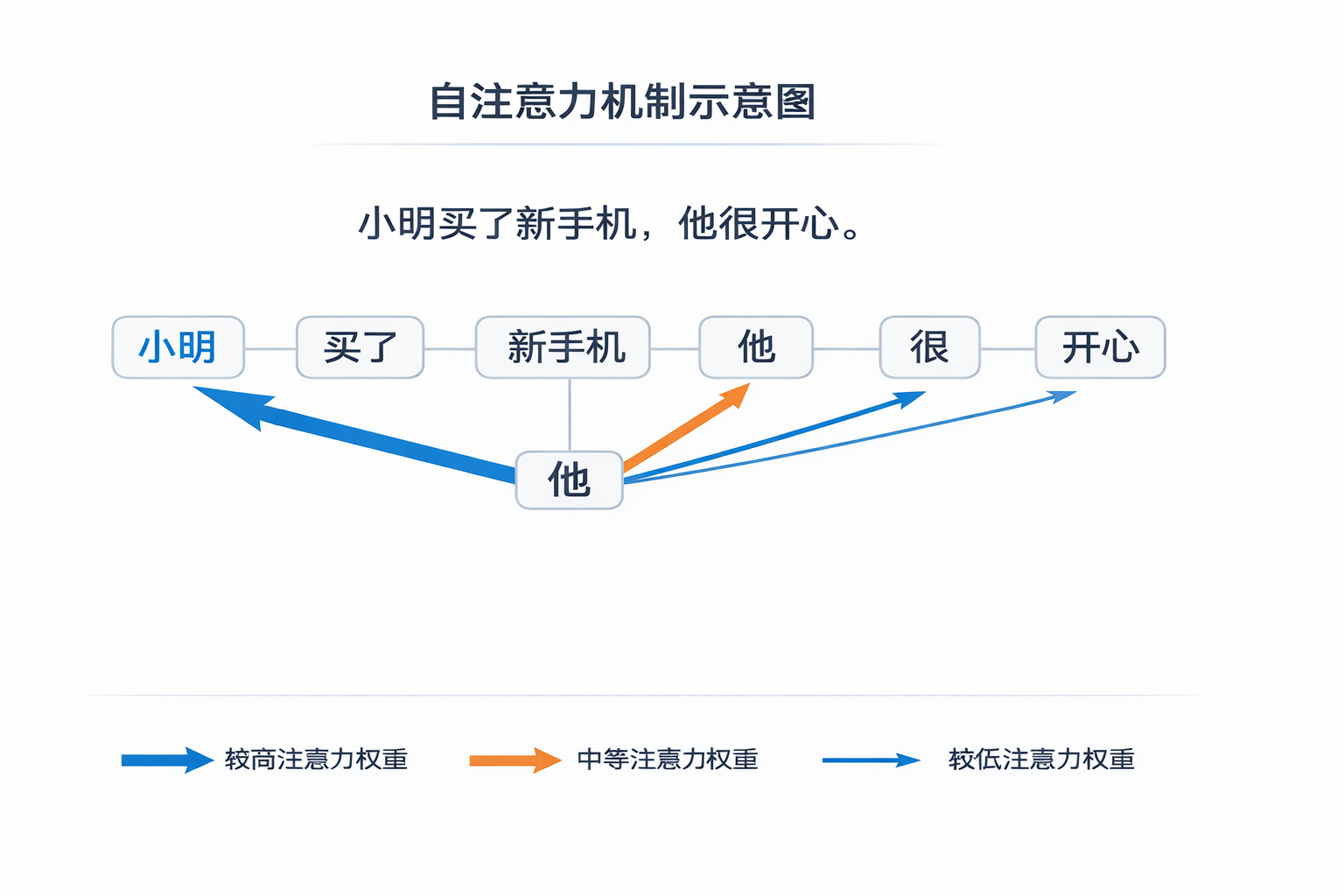
五、Self-Attention:自注意力机制
Transformer 的关键创新是 自注意力机制(Self-Attention)。
它的核心思想是:
在理解一个词时,动态计算句子中其他词对它的重要程度。
例如句子:
“小明买了新手机,他很开心。”
当模型看到“他”时,会判断:
- 是指小明
- 还是指手机?
它会给“手机”、“小明”等词打分。
分数高的,说明关联强。
这样就能知道“他”指的是“小明”。
而且这个过程不是做一次,而是做很多次(多头注意力),每一组关注不同类型的关系。
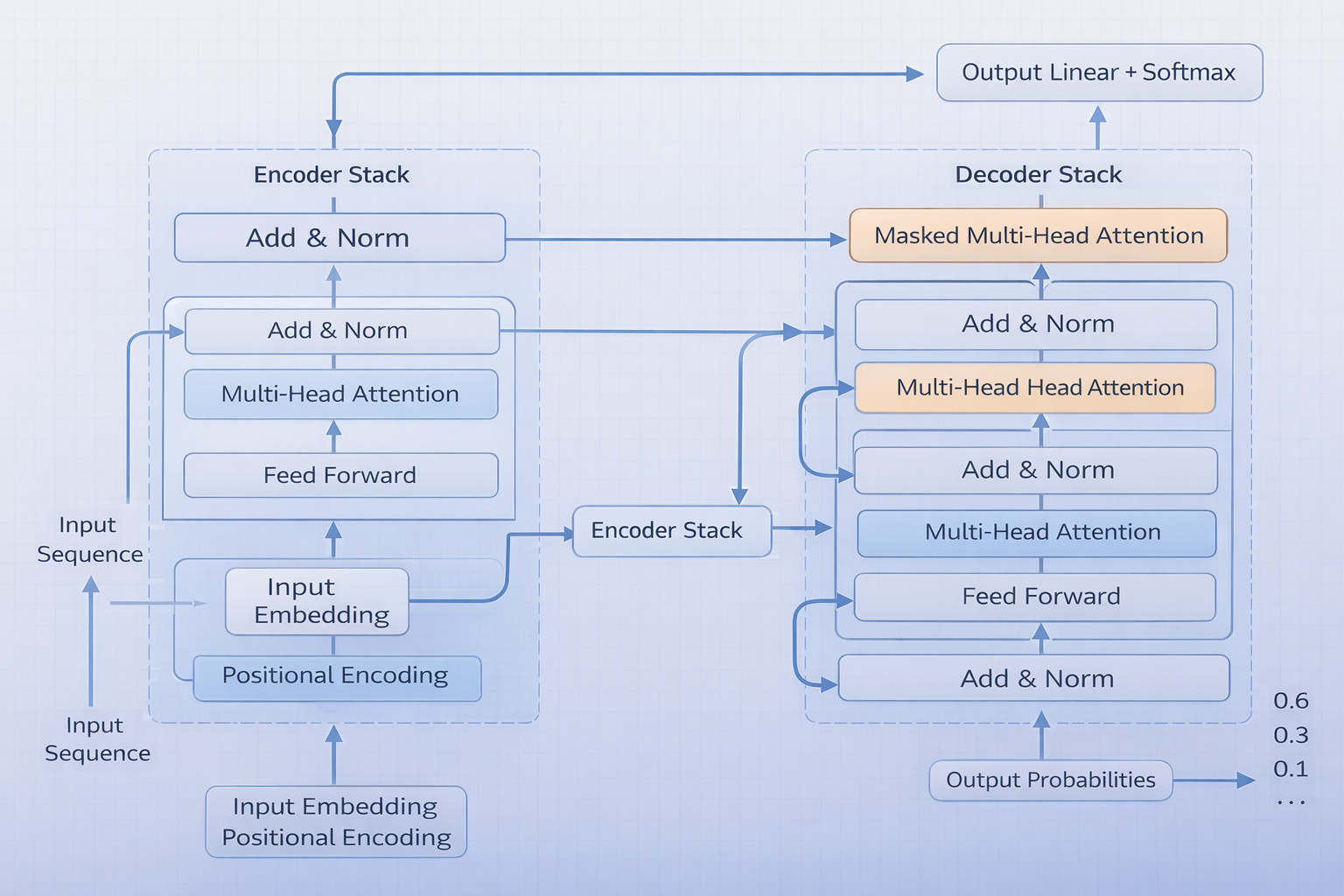
六、Transformer整体结构概览
Transformer可以理解为多层堆叠的结构,每一层都在做两件核心事情:
- 计算词与词之间的关系(多头注意力)
- 对每个词进行更深层的特征变换(前馈神经网络)
输入进来的是文字,输出出来的是“下一个词的概率”。层数越多,理解越深。
整体流程包括:
- 输入嵌入(Embedding)
- 位置编码(Positional Encoding)
- 多层编码器(核心:多头自注意力层)
- 多层解码器(也包括多头自注意力层)
- 输出预测
位置编码的作用是:
让模型知道词的顺序,否则“猫追老鼠”和“老鼠追猫”将无法区分。
七、为什么Transformer成为大模型基石?
它的优势在于:
- ✅ 可并行训练
- ✅ 能处理长文本
- ✅ 表达能力强
- ✅ 易于扩展规模
因此:
- GPT 系列
- BERT
- T5
- 绝大多数现代语言模型
都基于 Transformer 或其变体构建。a

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)