具身智能:原理、算法与系统 第9章 主动感知与注意力
通过将最可能物体的模型投影到场景中,系统评估各视角下物体特征的可见性,选择能够最大化特征观测机会的视角。实验表明,该方法在82.5%的情况下成功找到导致物体识别的视角,并能在85%的试验中处理视觉遮挡。通过将点云投影到图像平面并计算跨模态注意力,系统能够利用图像的高分辨率纹理信息增强点云的语义理解,同时利用点云的精确深度信息补偿图像在远距离处的信息损失。预测误差方法面临"嘈杂电视"问题的挑战:在随
目录
第9章 主动感知与注意力
主动感知代表了具身智能体从被动接收环境信息向主动获取关键信息的范式转变。与静态传感器不同,具身智能体通过控制感知器官的运动来优化信息获取过程,这种能力在资源受限的物理世界中至关重要。注意力机制则提供了信息筛选的算法基础,使智能体能够在海量感知数据中识别与当前任务相关的关键特征。两者共同构成了感知动作循环的核心,支撑智能体在复杂环境中的自适应行为。
9.1 主动视觉
主动视觉研究如何通过控制视觉传感器的姿态和运动来优化感知性能。该领域源于对生物视觉系统的观察——人眼并非被动接收器,而是通过眼动、头动和身体移动主动获取视觉信息。在机器人学中,主动视觉系统通过控制相机位姿、调节光学参数或移动观察平台来实现类似的功能。
9.1.1 注视点控制与眼动模型
注视点控制是主动视觉的基础机制,涉及将高分辨率感知区域定向到环境中的关键位置。生物视觉系统采用中央凹视觉(foveated vision)策略,视网膜中心区域具有高密度的感光细胞,而周边区域分辨率逐渐降低。这种非均匀采样策略大幅减少了需要处理的数据量,同时保持了对关键区域的精细感知。
在机器人实现中,注视点控制通常通过云台相机、机械臂末端执行器或移动平台的运动来实现。Gaskett等人开发的闭环注视控制系统利用10个自由度(4个眼部自由度、3个头部自由度、3个躯干自由度)协同工作,将目标维持在视野中心。该系统采用级联的PD控制器网络,基于视觉坐标与关节角度之间的简化映射关系,而非完整的运动学模型。这种设计使系统对机械磨损和维护活动具有鲁棒性,因为闭环控制能够收敛到期望配置而不依赖精确的运动学参数。
眼动模型分为平滑追踪、扫视和注视三种基本模式。平滑追踪用于跟踪移动目标,保持目标在视网膜上的稳定成像;扫视是快速的视线跳跃,用于将注视点从一个兴趣区域转移到另一个;注视则是相对静止的观察状态,用于详细分析目标特征。在具身智能体中,这些眼动模式需要与身体运动协调,形成层次化的感知策略。
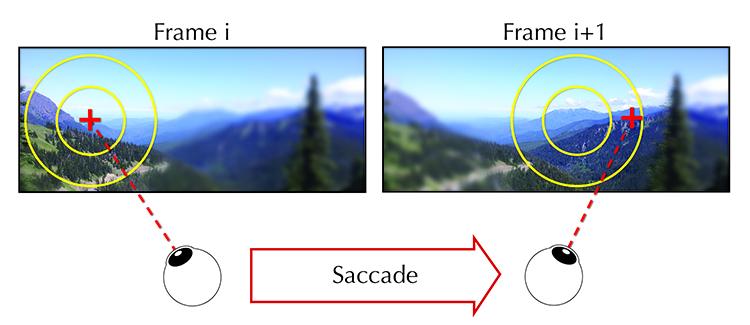
图9.1 注视点控制示意图。中央凹区域(高分辨率)与周边区域(低分辨率)的划分,以及扫视运动将注视点从一个位置快速转移到另一个位置的过程。
9.1.2 信息论视角的主动感知
信息论为主动感知提供了形式化的优化框架。在该视角下,感知动作的选择被建模为信息增益最大化问题。智能体通过评估候选观察动作对降低状态估计不确定性的贡献,选择最优的感知策略。
信息论方法的核心是量化观察动作带来的不确定性减少。对于状态估计问题,不确定性通常用熵来度量。当智能体考虑移动到某个候选视角时,它预测在该视角下获得的测量将如何改变其后验信念分布。信息增益定义为当前状态不确定性与预期未来不确定性之差。最大化信息增益等价于选择能够最大程度降低状态估计方差的观察动作。
在主动定位任务中,信息论方法已被证明优于基于几何启发式的策略。通过最大化Fisher信息或最小化熵,机器人能够选择最优的相机位姿来减少位姿估计的不确定性。这种方法特别适用于多机器人协作场景,其中团队成员需要协调各自的观察动作以最大化联合信息增益。
信息论框架还被扩展到分类和建图任务。在主动分类中,智能体选择观察动作以最大化类别分布的信息增益,从而以最少的观察次数确定目标类别。在主动建图中,机器人选择能够最大化地图不确定性减少的观察位置,实现高效的环境探索。

图9.2 多机器人主动感知中的视角选择。每个机器人通过评估候选视角的信息增益,协调选择最优观察位置以实现联合不确定性最小化。
9.1.3 下一最佳视图(NBV)规划
下一最佳视图规划是主动视觉在三维重建和物体识别中的具体应用。给定当前的部分观察,NBV算法确定下一个最优的相机位姿,以最大化重建质量或识别准确率。
NBV规划面临三个关键挑战:候选视角的生成、信息增益的预测以及运动成本的权衡。候选视角通常通过在物体周围采样球面位置或使用可达性分析生成。信息增益预测需要评估每个候选视角对减少重建不确定性的贡献,这通常通过分析表面可见性、遮挡关系和测量质量来实现。
在物体识别任务中,McGreavy等人提出的方法结合在线视角图和特征可见性分析。系统首先识别初始物体候选,然后分析从一组可达候选视角观察该候选的可见性。通过将最可能物体的模型投影到场景中,系统评估各视角下物体特征的可见性,选择能够最大化特征观测机会的视角。实验表明,该方法在82.5%的情况下成功找到导致物体识别的视角,并能在85%的试验中处理视觉遮挡。
对于抓取任务中的NBV规划,Breyer等人开发了闭环NBV规划框架。系统持续将传感器测量集成到场景的截断有符号距离函数重建中,并计算体素级的抓取可供性。基于目标物体可能占据的体素计数,系统计算期望观察到目标被遮挡部分的视角,并通过笛卡尔速度控制器跟踪该视角。与固定相机基线相比,该方法在保持相似成功率的同时将搜索时间减少了约40%。
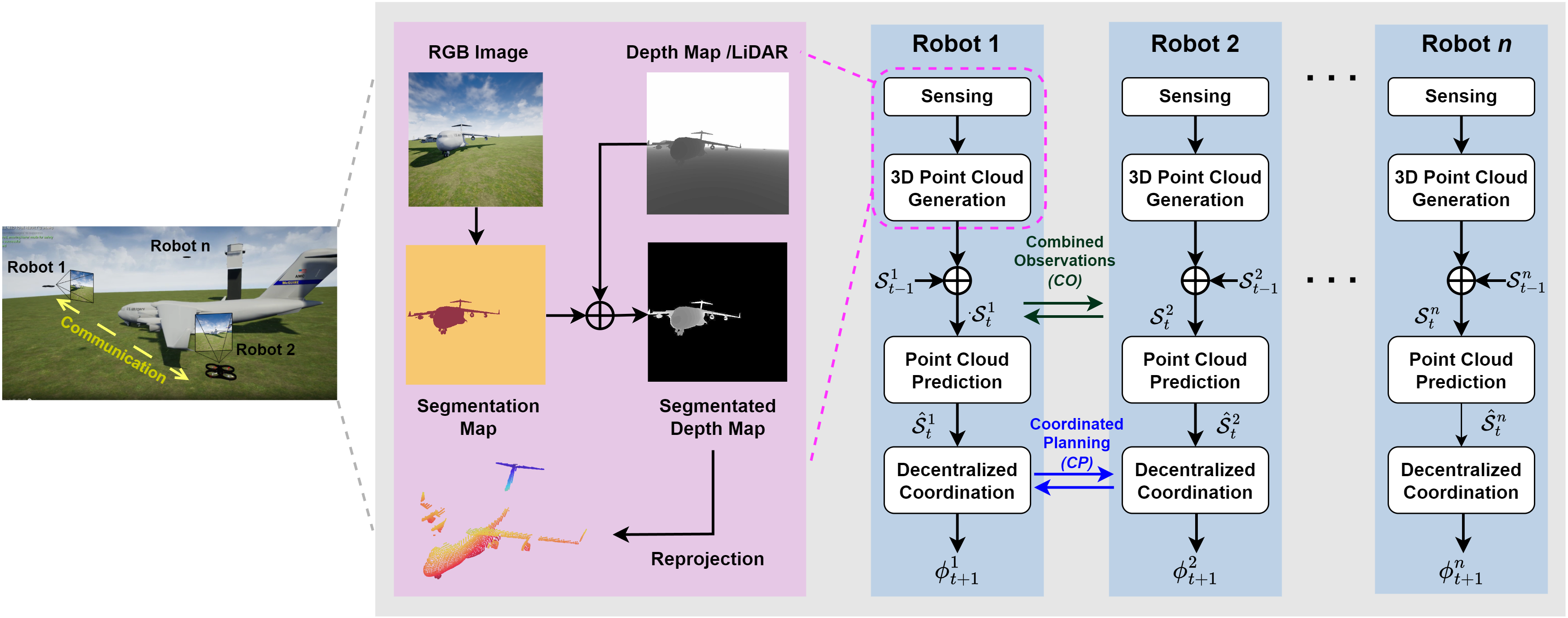
图9.3 预测引导的多智能体NBV规划框架。通过预测未观察部分的形状,智能体能够更有效地选择下一最佳视图,实现协作三维重建。
9.1.4 主动视觉的强化学习
强化学习为主动视觉提供了端到端的学习框架,使智能体能够从经验中发现最优的感知策略。与基于模型的方法不同,强化学习方法不需要显式的不确定性模型,而是通过试错学习感知动作与任务性能之间的映射关系。
在主动视觉强化学习中,智能体同时学习感知策略(控制传感器运动)和运动策略(控制身体动作)。这种双重策略学习带来了独特的挑战:感知策略需要为运动策略提供信息丰富的观察,而运动策略的进展又依赖于感知策略获取的观察质量。两者相互依赖,形成非平稳的学习环境。
Shang等人提出的SUGARL框架通过内在感知运动奖励来解决这一协调问题。该框架将智能体建模为分离的感知和运动策略,但通过可学习的感知运动奖励模块进行联合训练。该模块基于逆动力学预测任务训练,为感知策略分配内在奖励,激励其选择能够最优推断自身运动动作的观察。实验表明,学习到的感知策略展现出类似于人类注视和追踪的主动视觉技能。
在遮挡环境下的操纵任务中,主动视觉强化学习显示出显著优势。通过主动移动相机以获取被遮挡物体的视图,智能体能够发现稳定的抓取配置。与固定相机基线相比,主动视觉策略在复杂场景中表现出更高的成功率和鲁棒性。
9.2 注意力机制
注意力机制使具身智能体能够在有限的计算资源下优先处理感知数据中最相关的部分。受生物视觉注意力的启发,计算注意力系统通过动态权重分配,增强关键特征并抑制无关信息。
9.2.1 自下而上与自上而下注意力
注意力机制可分为自下而上(刺激驱动)和自上而下(目标驱动)两种类型。自下而上注意力由感知输入的显著性特征触发,例如颜色对比、运动或纹理变化。这种注意力是自动的、快速的,不依赖于当前任务目标。自上而下注意力则由当前任务需求和内部目标引导,主动搜索与任务相关的特征。
传统观点将两者视为独立的系统,但最新研究提出统一框架,认为注意力选择源于单一系统在不同时间尺度上的表达。该框架识别出三个时间尺度的优先级:进化形成的生存 imperative、学习获得的价值偏置和即时的任务需求。自下而上和自上而下过程被重新解释为同一底层机制的不同时间表达。
在具身智能体中,这种统一视角具有重要启示。智能体的注意力策略应整合本能反应(如对快速接近物体的警觉)、学习到的关联(如工具与任务目标的联系)和当前意图(如搜索特定物体)。这种整合使智能体能够在动态环境中平衡反应性和目标导向行为。
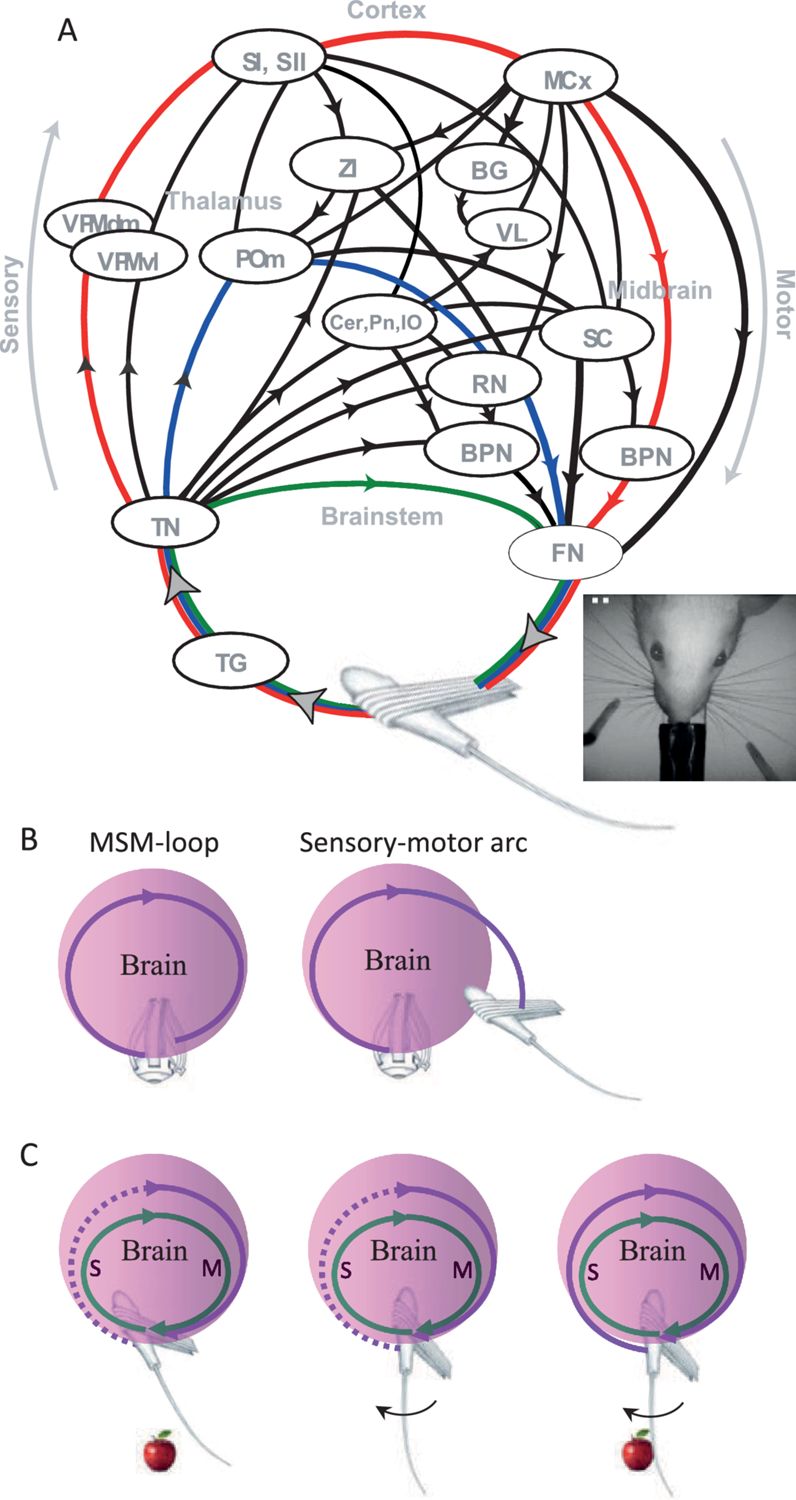
图9.4 感知动作闭环的神经机制。感觉运动弧(Sensory-motor arc)与多感觉整合环路(MSM-loop)的交互,展示了自下而上感觉输入与自上而下运动控制之间的动态耦合。
9.2.2 空间注意力与通道注意力
空间注意力机制通过生成二维注意力图来强调图像中的关键区域。该机制学习将权重分配给不同的空间位置,使后续处理集中于高权重区域。在具身视觉中,空间注意力使机器人能够聚焦于操纵目标、导航路标或交互对象,忽略背景干扰。
通道注意力则关注特征通道的重要性。深度网络的特征图包含多个通道,每个通道编码不同类型的特征(如边缘、纹理或语义信息)。通道注意力机制学习为不同通道分配权重,增强与当前任务相关的特征通道。这种机制在处理多模态感知时尤为重要,能够自动选择最可靠的感知通道。
空间注意力与通道注意力的结合形成了混合注意力机制。典型的实现采用顺序或并行的方式应用两种注意力:先使用通道注意力选择关键特征通道,再应用空间注意力定位关键区域;或分别计算两种注意力权重后进行融合。这种混合策略在视觉导航、物体抓取和场景理解任务中均显示出优越性。
9.2.3 自注意力与Transformer
自注意力机制通过计算特征之间的相互关系来捕获全局依赖。与卷积神经网络的局部感受野不同,自注意力允许每个位置直接关注所有其他位置,形成全局上下文感知。这种机制特别适用于需要理解场景整体结构的任务。
Transformer架构完全基于自注意力机制,通过多头注意力并行捕获不同类型的关系。在视觉领域,Vision Transformer将图像分割为序列化的图像块,应用自注意力建模块之间的关系。这种架构在图像分类、检测和分割任务中达到了与卷积网络相当或更优的性能。
在具身智能中,Transformer被用于视觉导航、多智能体协作和视觉语言任务。其优势在于能够建模长距离依赖,例如房间之间的空间关系、时间序列中的动作依赖或多模态特征之间的对应关系。然而,自注意力的计算复杂度与序列长度呈二次关系,这对资源受限的具身系统构成挑战。近期的研究通过稀疏注意力、线性注意力或分层注意力来降低计算成本。
9.2.4 跨模态注意力
跨模态注意力机制处理来自不同感知通道的信息融合。具身智能体通常配备多种传感器,如相机、激光雷达、触觉传感器和麦克风,跨模态注意力使这些异构数据能够在共同的空间中交互。
跨模态注意力的典型实现采用查询-键-值结构,其中一个模态的特征作为查询,另一个模态的特征作为键和值。通过计算查询与键之间的相似度,机制确定两个模态特征之间的对应关系,并基于相似度加权融合值特征。这种机制使智能体能够将视觉特征与触觉反馈对齐,或将听觉线索与视觉位置关联。
在自动驾驶场景中,跨模态注意力被用于融合相机图像和激光雷达点云。通过将点云投影到图像平面并计算跨模态注意力,系统能够利用图像的高分辨率纹理信息增强点云的语义理解,同时利用点云的精确深度信息补偿图像在远距离处的信息损失。实验表明,这种融合策略在远距离目标检测上显著优于单模态方法。
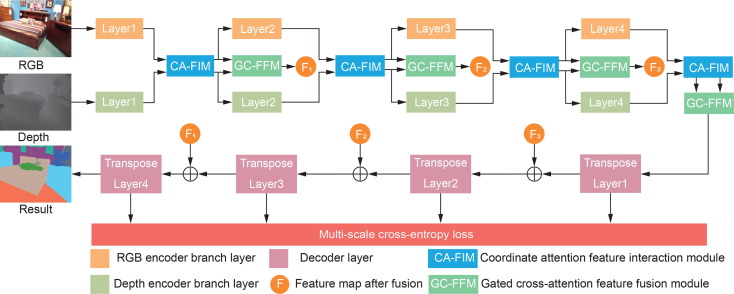
图9.5 跨模态注意力融合网络架构。RGB图像分支与点云分支通过跨模态注意力模块交互,实现视觉纹理与几何深度的互补融合。
9.3 好奇心与内在动机
内在动机驱动智能体在没有外部奖励的情况下探索环境,这种能力对开放世界学习至关重要。与依赖任务特定奖励的外在动机不同,内在动机源于智能体内部的学习需求,如减少预测误差、增加信息增益或扩展控制能力。
9.3.1 预测误差驱动的探索
预测误差是内在动机的基本形式,源于智能体对环境动态模型的预测与实际观察之间的差异。高预测误差表明智能体处于不熟悉的状态或发生了意外事件,这驱动智能体探索这些区域以改进其世界模型。
内在好奇心模块是预测误差方法的典型实现。该模块包含三个组件:特征编码器将原始观察压缩为紧凑表示,逆动力学模型预测导致状态转移的动作,前向模型预测下一状态的表示。前向模型的预测误差被用作内在奖励,激励智能体探索其预测能力较弱的区域。
预测误差方法面临"嘈杂电视"问题的挑战:在随机环境中,某些状态可能本质上是不可预测的(如电视雪花屏),导致智能体陷入无意义的探索。解决方案包括通过逆动力学模型学习仅编码与智能体动作相关的特征,过滤掉环境噪声;或使用集合模型估计认知不确定性,区分可学习的预测误差与固有随机性。
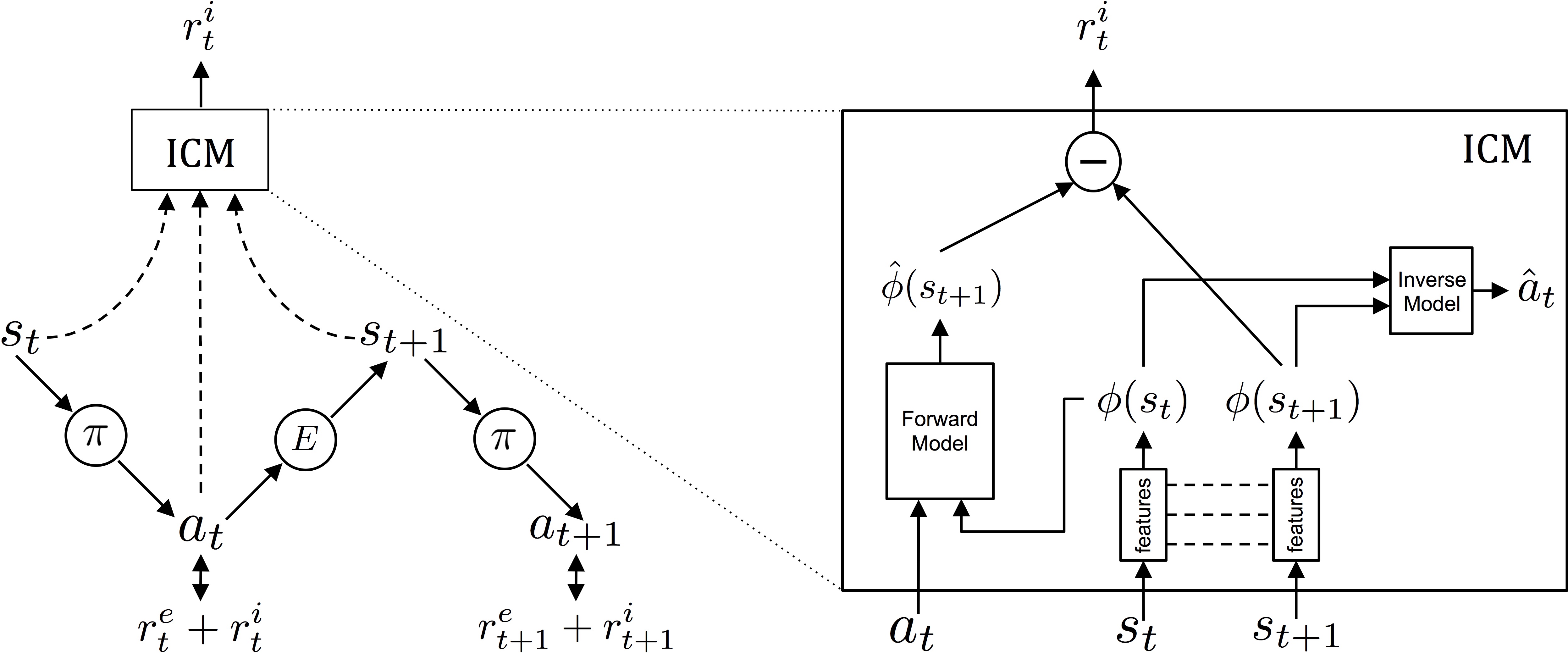
图9.6 内在好奇心模块架构。通过逆动力学模型学习动作相关的特征表示,前向模型的预测误差作为内在好奇心奖励驱动探索。
9.3.2 信息增益与贝叶斯Surprise
信息增益方法将探索形式化为减少智能体对环境信念的不确定性。与预测误差关注状态预测准确性不同,信息增益关注智能体内部模型参数的更新幅度。当观察导致信念分布的重大更新时,智能体获得高信息增益。
贝叶斯Surprise是信息增益的度量,定义为观察后验分布与先验分布之间的差异。在强化学习中,这被实现为智能体观察到新状态后,其后验信念与先验信念之间的散度。高贝叶斯Surprise表明观察提供了关于环境的新信息,值得进一步探索。
潜在贝叶斯Surprise方法将计算从参数空间转移到潜在空间,提高了计算效率。该方法学习潜在动态模型,其中潜在变量捕获环境动态的不确定性。贝叶斯Surprise被计算为潜在后验与潜在先验之间的散度,驱动智能体寻找能够最大程度更新其潜在信念的状态。实验表明,该方法对随机性具有鲁棒性,能够避免"嘈杂电视"陷阱。
9.3.3 赋能(Empowerment)最大化
赋能是另一种内在动机形式,度量智能体通过其动作对未来状态的影响力。高赋能状态是指从该状态出发,智能体的动作能够可靠地产生多样化的未来结果。最大化赋能驱动智能体维持对其未来状态的控制能力。
赋能被形式化为动作序列与未来观察之间的互信息。这种互信息度量了动作中包含的关于未来状态的信息量,反映了智能体控制环境的能力。与预测误差方法不同,赋能关注智能体的控制能力而非预测能力,鼓励智能体探索能够产生可预测且多样化结果的状态。
在机器人操纵任务中,赋能最大化显示出独特优势。通过鼓励智能体维持对物体的控制能力,该方法促进了鲁棒的抓取和操纵策略学习。与稀疏外部奖励结合时,赋能作为密集内在奖励,显著提高了学习效率。
9.3.4 技能发现与选项学习
技能发现旨在自动识别可复用的行为模式,形成层次化策略的底层基元。在选项框架中,技能被建模为选项——包含启动条件、内部策略和终止条件的完整动作序列。选项学习使智能体能够在更高抽象层次上规划,提高复杂任务的学习效率。
变分选项发现方法通过最大化潜在变量与轨迹之间的互信息来学习技能。该方法训练最大熵策略编码器,将潜在上下文向量映射为轨迹,同时训练监督解码器从轨迹恢复潜在变量。这种自监督学习使智能体能够发现可区分且有用的行为模式,无需为每个技能手工设计奖励。
在多智能体协作场景中,技能发现面临额外挑战:个体技能必须对团队目标有用,技能空间随智能体数量指数增长,且技能必须在实际多智能体环境中而非孤立单智能体场景中发现。层次化多智能体强化学习方法通过低层独立学习技能、高层集中学习技能选择策略来解决这些挑战。实验表明,该方法能够在团队体育游戏中涌现出有意义的技能和人类水平的协调。
9.4 感知动作循环
感知动作循环描述了感知与动作之间的动态交互关系。与将感知和动作视为独立模块的传统观点不同,感知动作循环强调两者的相互依赖:感知指导动作选择,动作改变感知输入,形成闭环的动态过程。
9.4.1 感知引导动作
感知引导动作强调环境观察对运动控制的约束和引导作用。在视觉伺服中,视觉特征被直接映射为控制命令,实现从感知到动作的闭环控制。这种映射可以是直接的(如基于图像的视觉伺服)或间接的(如基于位置的视觉伺服)。
在更复杂的场景中,感知提供任务相关的状态估计,用于高层决策。例如,在导航任务中,感知模块估计当前位置、构建环境地图并检测障碍物,这些信息被用于路径规划和运动控制。感知的准确性和及时性直接影响动作的质量。
主动感知扩展了感知引导动作的概念,将感知动作本身纳入控制策略。智能体不仅决定如何行动,还决定如何观察。这种联合优化使智能体能够选择最有利于任务执行的观察策略,例如将相机对准操纵目标的关键特征,或调整视角以消除遮挡。
9.4.2 动作引导感知
动作引导感知强调运动对感知的主动塑造作用。通过控制感知器官的运动,智能体能够优化采样过程,获取对任务最有价值的信息。这种主动采样策略在生物视觉中广泛存在,如眼动、头动和身体移动对视觉输入的调节。
在机器人学中,动作引导感知体现为主动视觉策略。通过控制相机运动,机器人能够跟踪移动目标、消除遮挡、优化视角或探索未知区域。这种主动控制使机器人能够在信息获取成本和感知质量之间进行权衡。
动作引导感知还体现在感觉运动协调中。智能体的运动策略考虑了感知约束,例如保持目标在视野内、维持适当的观察距离或避免运动模糊。这种协调需要感知和动作系统的紧密耦合,而非简单的顺序处理。
9.4.3 感知-动作耦合的神经机制
感知-动作耦合的神经基础涉及多个脑区的协同工作。在哺乳动物中,感觉皮层处理感知输入,运动皮层生成动作命令,而小脑和基底神经节参与感觉运动协调。这些区域通过复杂的反馈连接形成闭环,支持实时的感觉运动整合。
在计算模型中,感知-动作耦合通过递归连接实现。感觉运动弧(sensory-motor arc)表示从感觉输入到运动输出的直接通路,而多感觉整合环路(multi-sensory integration loop)则整合多种感觉模态的信息,指导运动控制。这些环路的交互使智能体能够快速响应感觉事件,同时整合上下文信息做出适应性决策。
神经形态计算试图在硬件层面实现类似的感知-动作耦合。通过使用事件驱动传感器、脉冲神经网络和模拟计算电路,神经形态系统能够以极低的功耗实现实时的感觉运动处理,为资源受限的具身智能体提供了高效的计算范式。
9.4.4 感知动作循环的学习优化
感知动作循环的学习涉及多个时间尺度的适应。在最快的时间尺度上,智能体通过反馈控制实时调整动作以响应感知变化。在中等时间尺度上,智能体学习感知-动作映射,改进从观察到行动的转换。在最慢的时间尺度上,智能体发展新的感知策略和动作技能,扩展其感知运动能力。
端到端学习方法直接从原始感知输入学习控制策略,绕过显式的状态估计和规划。深度强化学习使智能体能够从经验中发现复杂的感知-动作策略,如从视觉输入直接映射到电机命令。然而,这种黑箱方法的可解释性和泛化性仍是挑战。
模块化方法将感知动作循环分解为可学习的组件,如特征提取、状态估计、策略选择和运动控制。这种分解使学习问题更易于处理,并允许在不同任务间复用组件。然而,模块间的协调和接口设计需要仔细考虑。
元学习方法使智能体能够快速适应新的感知-动作任务。通过在一组相关任务上学习,智能体获得关于如何学习的先验知识,从而在新任务上实现少样本学习。这种能力对需要在多样化环境中部署的具身智能体尤为重要。
本章小结
主动感知与注意力机制构成了具身智能体高效交互环境的基础。主动视觉通过控制感知器官的运动优化信息获取,信息论方法为感知动作选择提供了形式化框架,强化学习使智能体能够从经验中发现最优感知策略。注意力机制通过动态资源分配处理感知数据的复杂性,跨模态注意力实现了异构感知信息的融合。内在动机驱动开放世界的自主探索,从预测误差到赋能最大化的不同形式提供了多样化的探索驱动力。感知动作循环整合了这些机制,形成闭环的动态交互系统,支撑智能体在物理世界中的自适应行为。
Aloimonos, J., Weiss, I., & Bandyopadhyay, A. (1988). Active vision. International Journal of Computer Vision, 1(4), 333-356.
Ballard, D. H. (1991). Animate vision. Artificial Intelligence, 48(1), 57-86.
Bajcsy, R. (1988). Active perception. Proceedings of the IEEE, 76(8), 966-1005.
Borji, A., & Itti, L. (2013). State-of-the-art in visual attention modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 185-207.
Breyer, M., Furrer, F., Novkovic, T., Siegwart, R., & Nieto, J. (2022). Closed-loop next-best-view planning for target-driven grasping. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 6817-6824.
Burgess, C. P., Higgins, I., Pal, A., Matthey, L., Watters, N., Desjardins, G., & Lerchner, A. (2019). Understanding disentangling in β-VAE. arXiv preprint arXiv:1804.03599.
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A simple framework for contrastive learning of visual representations. International Conference on Machine Learning (ICML), 1597-1607.
Deng, F., Chen, J., Shah, D., & Krishnamurthy, A. (2023). Planning to explore via self-supervised world models. International Conference on Machine Learning (ICML), 7913-7938.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)